| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌЮФеТеыЖдWindowsАцЕФeclipseЃЌНщЩмвЛжжВЛЭЌЕФАВзАЗНЪНЁЂЕМШыКЭЪЙгУЗНЪНЁЃ |
|
Hadoop Development Tools (HDT)ЪЧПЊЗЂhadoopгІгУЕФeclipseВхМўЃЌhttp://hdt.incubator.apache.org/НщЩмСЫЦфЬиЕуЃЌАВзАЃЌЪЙгУЕШЃЌеыЖдWindowsАцЕФeclipseЃЌНщЩмвЛжжВЛЭЌЕФАВзАЗНЪНЁЂКЭЪЙгУЗНЪНЁЃ
1 ЯТдиHDT
ДђПЊЃКhttp://hdt.incubator.apache.org/download.htmlЃЌВПЗжвГУцЃК
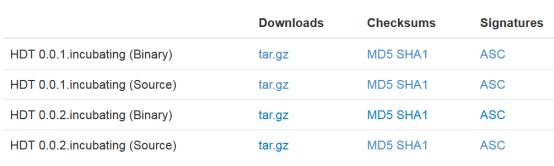
ЯТдиHDT 0.0.2.incubating (Binary)АцЁЃЕуЛїЁАtar.gzЁБ,ЬјзЊЕНЃК
http://www.apache.org/dyn/closer.cgi/incubator/hdt/hdt-0.0.2.incubating/hdt-0.0.2.incubating-bin.tar.gzЃЌВПЗжвГУцЃК

ЕуЛїКьПђВПЗжЕФСЌНгЃЌЯТдиHDTЃЌНтбЙПДЕНЮФМўМаФкШнЃК

2 АВзАHDTВхМў
ЯТдиЕБЧАзюаТАцЃЈeclipse oxygenЃЉ

ЕуЛїDownload PackagesЁЃ

ЯТди64bitАцБОЁЃЮФМўЮЊЃКeclipse-jee-oxygen-3a-win32-x86_64.zipЃЌНтбЙЃК
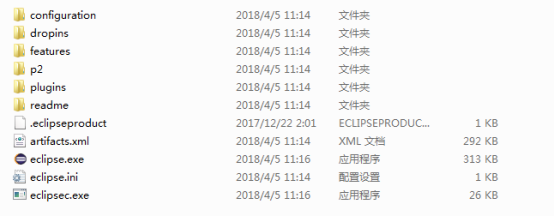
НЋHDTЕФfeaturesКЭpluginsжаЕФЮФМўЃЌЖдгІЗХЕНЩЯУцЕФЮФМўМаФкЁЃ
3 ЯТдиhadoopВЂХфжУЛЗОГБфСП
ЯТдиHadoop
ЪфШыЭјжЗЃКhttp://hadoop.apache.org/ЃЌПДЕНЯТУцЕФВПЗжЁЃ
ЕуЛїDownloadНјШыЯТдивГУцЃК
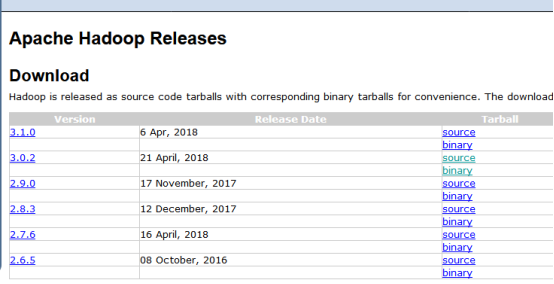
ЯТди2.6.5АцБОЕФbinaryЃЌзЂвтЯТдиЕФЪБКђбЁдёвЛИіЙњФкЕФОЕЯёЃЌетбљЯТдиЕФЫйЖШЛсБШНЯПьЁЃНтбЙЕНжИЖЈФПТМЃЌР§ШчЃКE:\hadoop-2.6.5ЁЃЮФМўМаАќРЈЃК
ХфжУЛЗОГБфСП
ХфжУHADOOP_HOMEЁЂHADOOP_USER_NAMEЛЗОГБфСПЁЂPATHЃЈЯЕЭГБфСПЃЉ
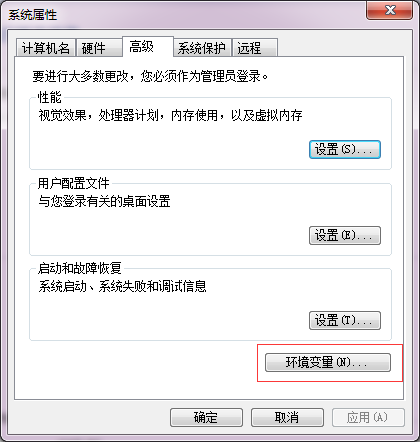
HADOOP_HOMEХфжУЮЊE:\hadoop-2.6.5,PATHЬэМг%HADOOP_HOME%\bin
WindowsЯТПЊЗЂ
ЮЊСЫФмдкWindowsЦНЬЈЯТзіПЊЗЂЃЌЛЙашвЊСНИіЮФМўwinutils.exeКЭhadoop.dll
НЋwinutils.exeЗХдкE:\hadoop-2.6.0\binФПТМЯТЃЌНЋhadoop.dllЗХдкC:\Windows\System32ЯТ
4 АВзАHDT
1ЃЉЕуЛїЫГађЃКFile->Other->еЙПЊHadoopЃЌШыЯТУцСНЗљЭМЫљЪОЃК
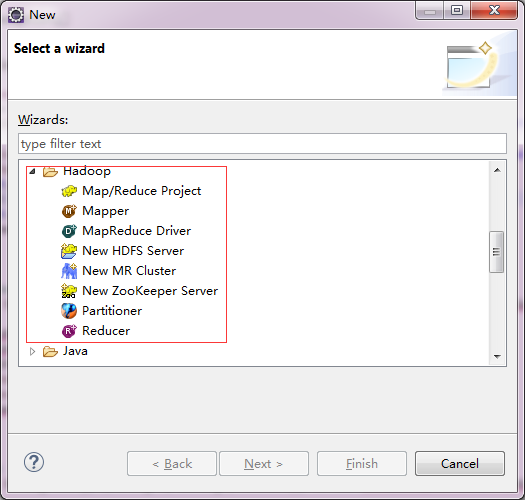
2ЃЉбЁдёЃЌ ШчЯТЭМЃК ШчЯТЭМЃК
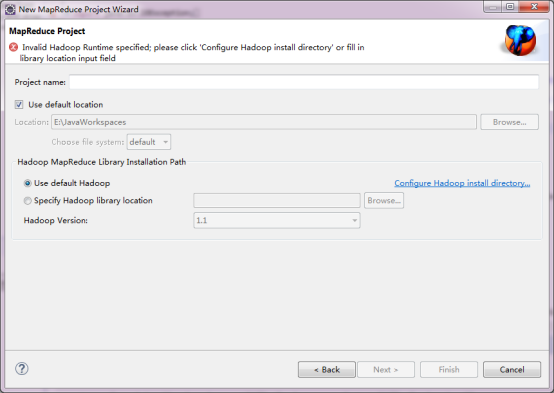
ИјЯюФПШЁвЛИіУћГЦЃКMapReduce_4_27ЃЌВЂбЁдёЁАUse default HadoopЁБЃЈФЌШЯЕФЩшжУЃЉЁЃ
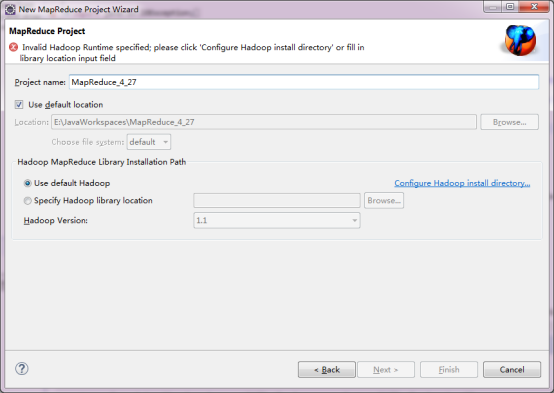
3ЃЉХфжУHadoopАВзАФПТМ
ЕуЛї2ЃЉВНзржаЕФНјааХфжУЃЌЦфжаХфжУЕФОЭЪЧИеВХhadoopНтбЙЮФМўЕФТЗОЖЁЃ
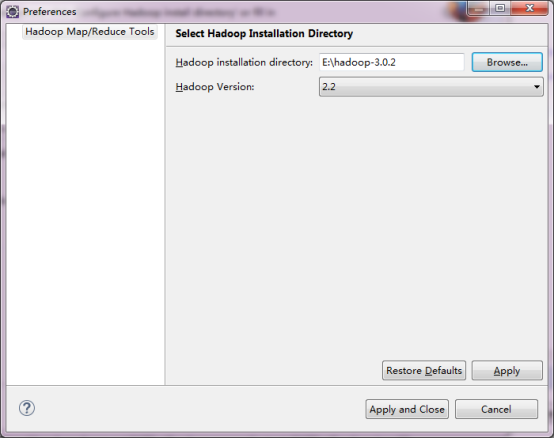
ЕуЛїЁАApply and CloseЁБЃЌЯдЪОШчЯТНчУцЃК
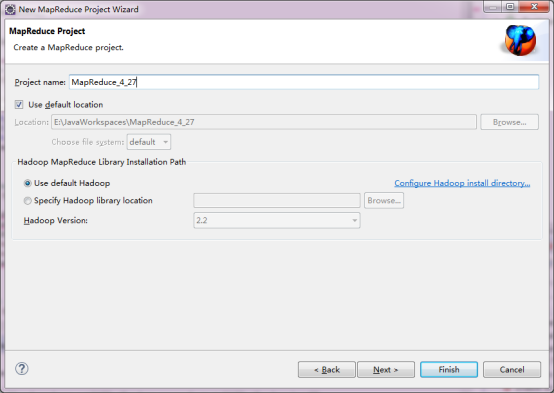
ЕуЛїЃЌ ЯдЪОШчЯТНчУцЃК ЯдЪОШчЯТНчУцЃК
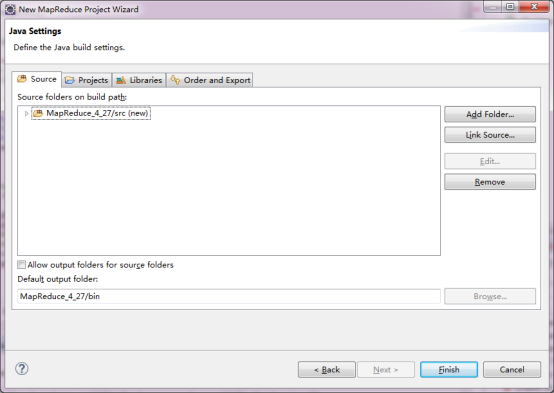
зюКѓЕуЛїЁАFinishЁБЁЃ
4ЃЉЕМШыПЊЗЂАќКЭjavadocЮФЕЕ
гвМќ->ЯюФПЪєад-> бЁдё Property->
дкЕЏГіЕФЖдЛАПђзѓВрСаБэжабЁдёJava Build Path-> бЁдёLibraries->
бЁдёAdd Library->ЕЏГіДАПкФкбЁдёUser Library-> ЕуЛїNext->
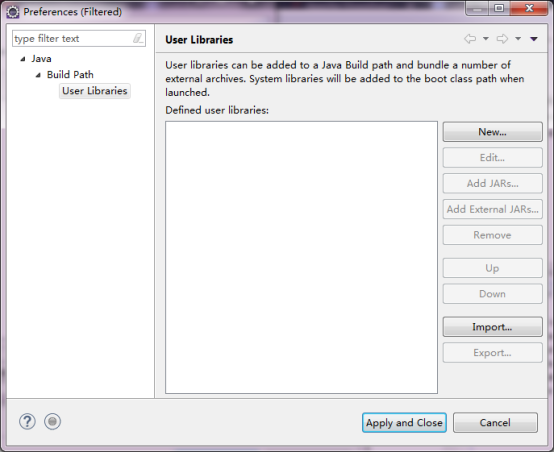
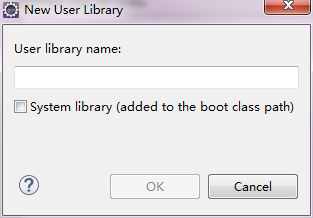
ЕуЛїUser Libraries-> ЕуЛїNew->дкЕЏГіЕФДАПкФкЪфШыБивЊаХЯЂ->
НЋБивЊЕФjarАќЬэМгНјШЅЁЃ
ЫљашЕФПЊЗЂАќдкE:\hadoop-3.0.2\share\hadoopЃЌетИіЮФМўМаЪЧИеВХНтбЙhadoopАВзААќНтбЙЕФЮФМўМаЁЃ
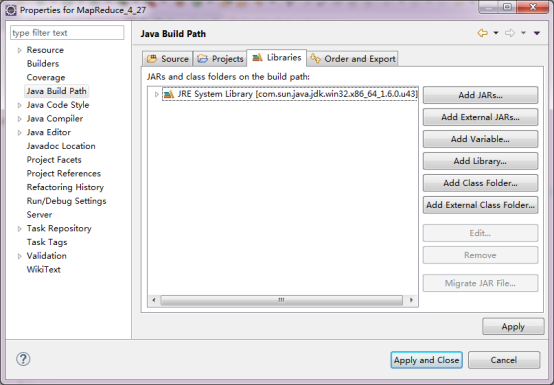
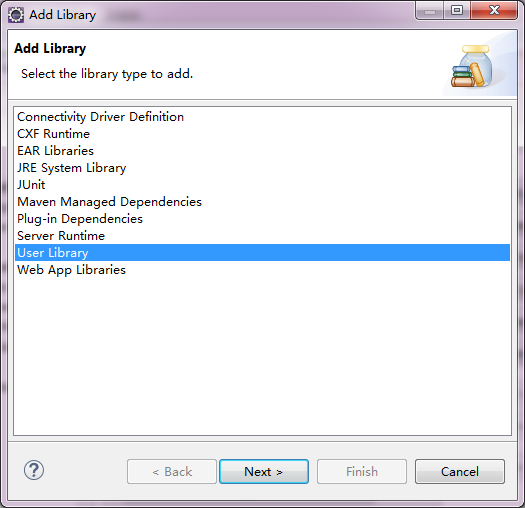
ЕМШыdocЮФЕЕ
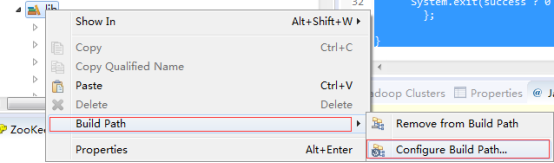
гвМќlibЮФМўМа->ЕуЛїBuild Path->ЕуЛїConfig Build Path
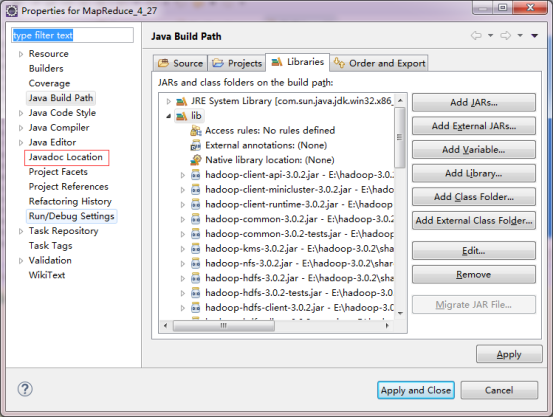
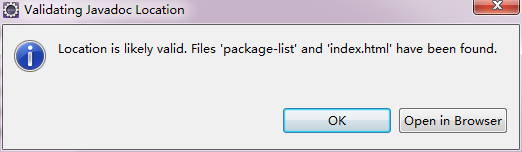
ЕуЛїJavadoc Location->ЕуЛїBrowseбЁдёdocЮФЕЕТЗОЖЁЃ
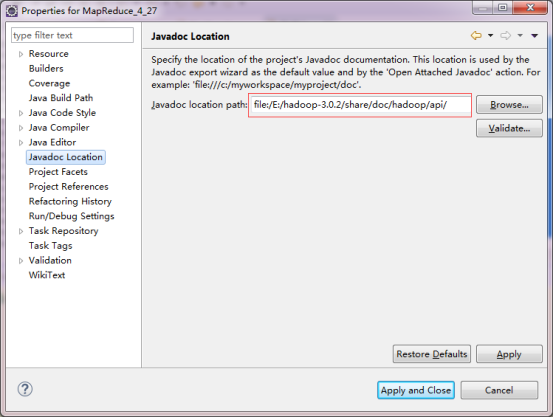
ЕуЛїvalidateПЩвдбщжЄЪЧЗёЪЧе§ШЗЕФТЗОЖЃЌЯТУцЗжБ№еЙЪОСЫе§ШЗЕФТЗОЖКЭЗЧе§ШЗЕФТЗОЖбщжЄаХЯЂЁЃ
5 ЪЙгУHDTЃЈMapReduceБрГЬЃЉ
ЩшжУJVMВЮЪ§
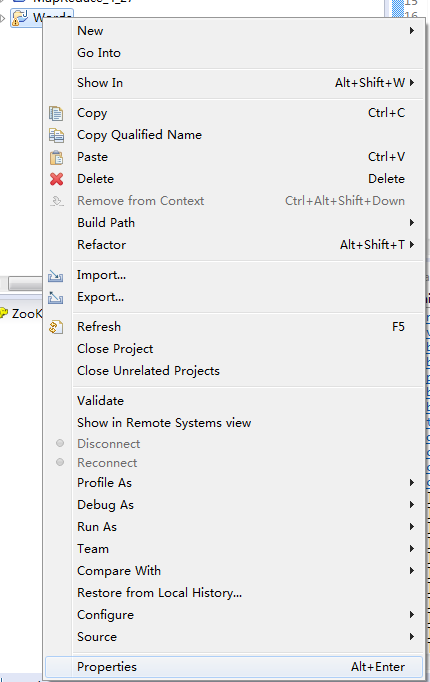
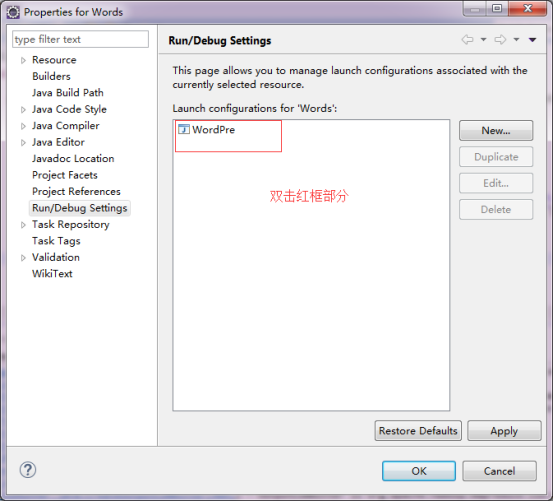
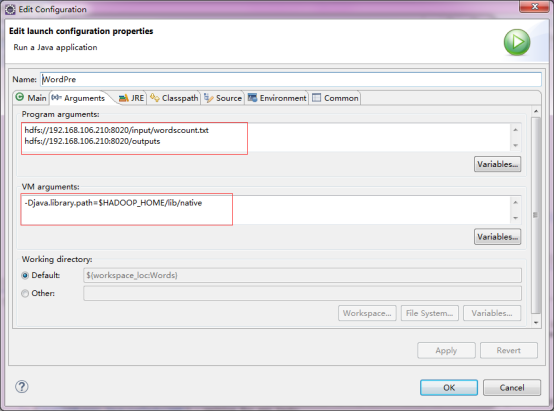
ДДНЈКУMap/Reduce ProjectКѓвЊЩшжУJVMВЮЪ§ЩшжУЮЊЃК
-Djava.library.path=$HADOOP_HOME/lib/native
MapperЃКДДНЈMapperРрЕФзгРр
Р§ЃЌФЃАхздЖЏЩњГЩЕФmapКЏЪ§ПђМм
import java.io.IOException;
import org.apache.hadoop.io .IntWritable;
import org.apache.hadoop.io .LongWritable;
import org.apache.hadoop.io .Text;
import org.apache.hadoop.mapreduce .Mapper;
public class Tmap extends Mapper <LongWritable,
Text , Text, IntWritable > {
public void map (LongWritable key, Text value,
Context context) throws IOException, InterruptedException
{
}
} |
ReducerЃКДДНЈReducerРрЕФзгРр
Р§ЃКФЃАхздЖЏЩњГЩЕФreduceКЏЪ§ПђМм
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class Treduce extends Reducer<Text,
IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable>
values, Context context)
throws IOException, InterruptedException {
while (values.iterator().hasNext()) {
// replace ValueType with the real type of your
value
// process value
}
}
} |
MapReduce DriverЃКДДНЈЧ§ЖЏ
Р§ЃКФЃАхздЖЏЩњГЩЕФЧ§ЖЏПђМм
import org.apache.hadoop.fs
.Path;
import org.apache.hadoop.io .IntWritable;
import org.apache.hadoop.io .Text;
import org.apache.hadoop.mapreduce .Job;
import org .apache .hadoop .mapreduce .lib.input
. File InputFormat ;
import org.apache .hadoop.mapreduce .lib.output.
File OutputFormat;
public class TMR {
public static void main (String[] args) throws
IOException ,InterruptedException , Class NotFound
Exception {
Job job = new Job();
job.setJarByClass ( ... );
job.setJobName ( "a nice name" );
FileInputFormat.setInputPaths (job, new Path(args[0]));
FileOutputFormat.setOutputPath (job, new Path(args[1]));
// TODO: specify a mapper
job. setMapperClass( ... );
// TODO : specify a reducer
job. setReducerClass( ... );
job. setOutputKeyClass(Text.class);
job. setOutputValueClass(IntWritable.class);
boolean success = job.waitForCompletion (true);
System.exit (success ? 0 : 1);
};
} |
New MR ClusterЃКМЏШКХфжУ
ПЩвдЕуЛїЯТЭМжаЕФNew MR ClusterХфжУМЏШК
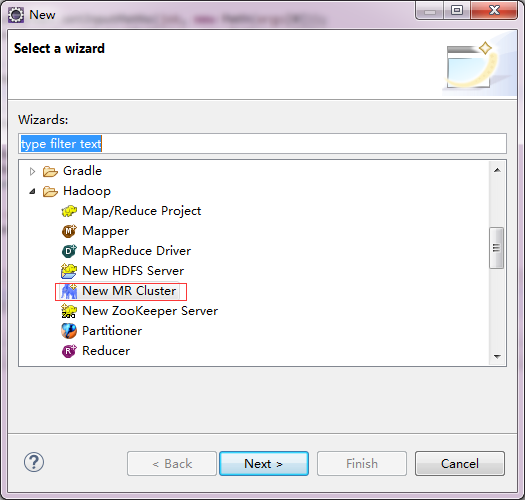
вВПЩвдЕуЛїeclipseЕФЭМБъРДХфжУМЏШКЃК
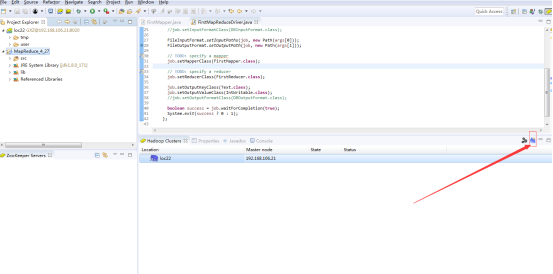
ХфжУвГУцШчЯТЃК
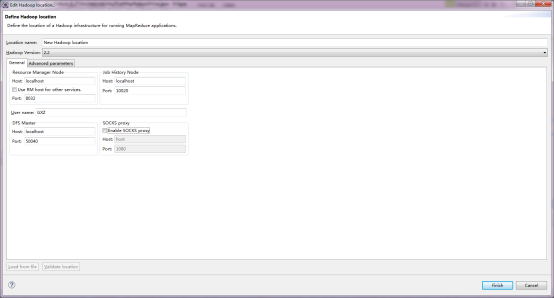
Resource Manager NodeЃКХфжУзЪдДЙмРэНкЕуЃЌЖдгІHadoopХфжУЮФМў
DFS MasterЃКХфжУЗжВМЪНЮФМўЯЕЭГжїНкЕуЃЌМДNameNodeНкЕуЕФЖЫПкКХЁЃЖдгІХфжУЮФМўfs.default.nameЕФжЕЁЃ |








