| БрМЭЦМі: |
БОЮФРДздгкЭјТчЃЌНщЩмвЛИіЪБМфађСаЪ§ОнДІРэЦНЬЈАИР§ЃЌЬНЬжетРрДѓЪ§ОнЦНЬЈдкМмЙЙЁЂбЁаЭКЭЩшМЦЩЯЕФвЛаЉЪЕМљОбщЁЃ
|
|
в§бд
дкДѓЪ§ОнЕФЩњЬЌЯЕЭГРяЃЌЪБМфађСаЪ§Он(Time Series DataЃЌМђГЦTSD)ЪЧКмГЃМћвВЪЧЫљеМБШР§зюДѓЕФвЛРрЪ§ОнЃЌМИКѕГіЯждкПЦбЇКЭЙЄГЬЕФИїИіСьгђЃЌвЛаЉГЃМћЕФЪБМфађСаЪ§ОнгаЃКУшЪіЗўЮёЦїдЫаазДПіЕФMetricsЪ§ОнЁЂИїжжIoTЯЕЭГЕФжеЖЫЪ§ОнЁЂФдЕчЭМЁЂЛуТЪЁЂЙЩМлЁЂЦјЯѓКЭЬьЮФЪ§ОнЕШЕШЃЌЪБађЪ§ОндкЪ§ОнЬиеїКЭДІРэЗНЪНЩЯгаКмДѓЕФЙВадЃЌвђДЫвВДпЩњСЫвЛаЉУцЯђУцЯђЪБађЪ§ОнЕФЬиЖЈЙЄОпЃЌБШШчЪБађЪ§ОнПтКЭЪБађЪ§ОнПЩЪгЛЏЙЄОпЕШЕШЃЌдкдЦЦНЬЈЩЯвВПЊЪМГіЯжУцЯђЪБађЪ§ОнЕФSaaS/PaaSЗўЮёЃЌР§ШчЮЂШэзюНќИеИеЗЂВМЕФAzure
Time Series InsightЁЃБОЮФЛсНщЩмвЛИіЪБМфађСаЪ§ОнДІРэЦНЬЈАИР§ЃЌЬНЬжетРрДѓЪ§ОнЦНЬЈдкМмЙЙЁЂбЁаЭКЭЩшМЦЩЯЕФвЛаЉЪЕМљОбщвдЙЉВЮПМЁЃ
вЕЮёГЁОА
БОЮФНщЩмЕФАИР§ЪЧвЛИіУцЯђДѓаЭЦѓвЕITЯЕЭГдЫЮЌЕФМрПиЦНЬЈЃЌЪ§ОнРДдДгкЖржжМрПижеЖЫВњЩњЕФЪБађЪ§ОнЃЌЩцМАЕФЪ§ОндДКИЧСЫSCOMЁЂAppDynamicsЁЂWebsite
PulseЁЂPiwikвдМАAWS Cloud WatchЕШЖржжжїСїЕФЕкШ§ЗНМрПиЙЄОпЃЌЛљгкзщжЏФкВПЕФITЙцЗЖЃЌЫљгагІгУЯЕЭГЖМАВзАСЫЩЯЪівЛжжЛђЖржжМрПиЙЄОпЃЌетЮЊНЈСЂвЛИіЭГвЛЕФЖрЮЌЖШЕФМрПиЦНЬЈЬсЙЉСЫБЃжЄЃЌИУЦНЬЈЛљгкЖржжМрПиЪ§ОнЃЌЖдЭЌвЛгІгУ/ЗўЮёЯЕЭГНјаазлКЯЕФНЁПЕЦРЙРЃЌдкЗЂЩњЙЪеЯЪБЛсИљОнВЛЭЌЕФЪ§ОндДНјааНЛВцбщжЄЃЌДгЖјАяжњдЫЮЌШЫдБПьЫйКЭзМШЗЕиЖЈЮЛЙЪеЯдвђЁЃ
МмЙЙЩшМЦ
ЭъећЕФДѓЪ§ОнЯЕЭГЭљЭљАќКЪ§ОнВЩМЏЃЌЯћЯЂЖдСаЃЌЪЕЪБСїДІРэЃЌРыЯпХњДІРэЃЌЪ§ОнДцДЂКЭЪ§ОнеЙЪОЕШЖрИізщМўЃЌЮЊСЫТњзувЕЮёЩЯЖдЪЕЪБМрПиКЭРњЪЗЪ§ОнЛузмЗжЮіЕФашЧѓЃЌЯЕЭГзёбСЫLambdaМмЙЙЃЌНЋЪЕЪБСїДІРэгыРыЯпХњДІРэНјааСЫЗжРыЁЃДЫЭтЃЌМјгкЦНЬЈДІРэЕФЫљгаЪ§ОнОљЮЊЪБађЪ§ОнЃЌдкМмЙЙЩЯеыЖдетИіЬиЕузХжиНјааСЫЕїећКЭгХЛЏЃЌЦфжаживЊЕФвЛЛЗЪЧв§ШыЁАЪБМфађСаЪ§ОнПтЁБзїЮЊКЫаФЕФЪ§ОнДцДЂгыВщбЏв§ЧцЁЃ
ЯЕЭГЭъећЕФЪ§ОнСїШчЯТЃКЪзЯШЃЌЪ§ОнБЛЪ§ОнВЩМЏзщМўДгЭтВПЯЕЭГВЩМЏВЂРДЗХШыЯћЯЂЖгСаЃЌНгзХЃЌСїДІРэзщМўДгЖгСажаШЁГіЪ§ОнНјааСїЪНМЦЫуЃЌЯћЯЂЖгСаДгжаЕФЦ№ЕНЕФзїгУЪЧЦНКтЁАЩњВњепЁБЁЊЁЊЪ§ОнВЩМЏзщМўКЭЁАЯћЗбепЁБЁЊЁЊСїДІРэзщМўдкЯћЯЂДІРэЩЯЕФЫйТЪВюЃЌЬсЩ§ЯЕЭГЕФЮШЖЈадКЭПЩППадЁЃЪ§ОндкСїДІРэзщМўжаЛсОРњЧхЯДЁЂЙ§ТЫЁЂзЊЛЛЁЂвЕЮёДІРэЕШжюЖрЛЗНкЃЌжЎКѓАДTSDв§ЧцЙцЖЈЕФБъзМTSDИёЪНЭЦЫЭЕНTSDв§ЧцЃЌгЩTSDв§ЧцзюжеаДШыКѓЖЫЪ§ОнПтЁЃ
ЪЕЪБСїДІРэВПЗжвЊЧѓЪ§ОнДгВЩМЏЕНзюКѓЕФеЙЪОПижЦдкУыМЖбгГйЃЌбЯИёРДЫЕЃЌетЪЧвЛЬзНќЪЕЪБЯЕЭГЃЌЕЋЦфЪЕЪБадвбОзуЙЛТњзувЕЮёЩЯЕФашЧѓЃЌЮЊСЫБЃжЄДІРэЫйТЪЃЌЪЕЪБСДЬѕЩЯЕФЪ§ОнДѓЖрЪ§ЪБМфЪЧзЄСєдкФкДцжаЕФЃЌКУдкЪЕЪБВПЗжжЛЙизЂНќСНжмЕФЪ§ОнЃЌЫљвдзмЕФФкДцЯћКФДІдкПЩПиЕФЗЖЮЇжЎФкЁЃ
дкХњДІРэЪ§ОнЯпЩЯЃЌРћгУЪ§ОнПтЕФЭЌВНЛњжЦНЋЪЕЪБВПЗжТфЕиЕФЪ§ОнГжајЭЌВНЕНХњДІРэЕФЪ§ОнПтЩЯЃЌетИіПтДцДЂзХЪ§ОнШЋМЏЃЌЫљгаХњДІРэЯрЙиЕФВщбЏЖМдкетИіПтЩЯжДааЃЌгыЪЕЪБВПЗжЕФзщМўЭъШЋИєРыЁЃХњДІРэЛсБЃДцЙ§ШЅШ§ФъЕФЪ§ОнЃЌЗжЮіГпЖШЖрЮЊШеЃЌжмЃЌдТЩѕжСФъЁЃВЛЭЌгквЛАуРыЯпЗжЮіЯЕЭГбЁаЭHiveвЛРрЕФЪ§ОнВжПтЃЌЮвУЧЯЃЭћдкРыЯпЗжЮіЪБМЬајГфЗжРћгУЪБађЪ§ОнПтДјРДЕФжжжжКУДІЃЌБШШчОЙ§ЬиЪтгХЛЏЕФЪБађЪ§ОнВщбЏЃЌПЊЯфМДгУЕФВщбЏНгПкЕШЕШЃЌЫљвддкРыЯпВПЗжЮвУЧвРШЛХфБИTSDв§ЧцЃЌХњДІРэзщМўдкЪЕЯжвЕЮёашЧѓЪБПЩвдЩюЖШРћгУTSDв§ЧцЖдЪБађЪ§ОнНјааОлКЯдЫЫуЃЌдкОлКЯжЎКѓЕФНсЙћЩЯдйНјааИќМгИДдгЕФЗжЮіВЂаДЛиЪ§ОнПтЃЌЭЌЪБвВПЩвддкЦеЭЈВщбЏЮоЗЈЪЕЯжашЧѓЪБдНЙ§TSDв§ЧцжБНгЖдЕзВуЪ§ОнЮФМўНјааMRМЦЫуЁЃ
зюКѓЃЌЪ§ОнеЙЪОзщМўЛсДгTSDв§ЧцжаЬсШЁЪ§ОнЃЌвдИїжжаЮЪНЕФЭМБэеЙЪОИјгУЛЇЁЃдкЪЕМЪЕФПЊЗЂжаЮвУЧЗЂЯжTSDв§ЧцЖдЪ§ОнИёЪНгажюЖрЕФЯожЦЃЌгаЕФTSDашвЊНјааФГаЉзЊЛЛКЭЪЪХфВХФмеЙЪОЃЌвђДЫЮвУЧдкTSDв§ЧцКЭЪ§ОнеЙЪОзщМўжаМфв§ШыСЫвЛИіЧсСПЕФЧ§ЖЏГЬађРДЭИУїЕиНтОіетаЉЮЪЬтЁЃ
ЛљгкЩЯЪіЗжЮіКЭЪЕМЪЕФдаЭбщжЄЃЌдкЖрТжЕќДњжЎКѓЃЌЮвУЧзюжеГЩаЮЕФЯЕЭГМмЙЙШчЯТЃК

НгЯТШЅЮвУЧЛсЖдУПИізщМўж№вЛНјааНщЩмЁЃ
зщМўгыбЁаЭ
Ъ§ОнВЩМЏ
ЦНЬЈЕФЪ§ОнРДдДЗЧГЃЖрЃЌЩцМАЕНЕФавщРраЭздШЛОЭЖрЃЌВЂЧвАщЫцзХвдКѓЕФГжајНЈЩшЃЌЛсгадНРДдНЖраТЕФЪ§ОндДКЭДЋЪфавщашвЊБЛжЇГжЃЌвђДЫЮвУЧЯЃЭћбЁЖЈЕФзщМўФмЙЛжЇГжЗЧГЃЗсИЛЕФавщРраЭЃЌЭЌЪБОЁПЩФмЕиЭЈЙ§ХфжУШЅМЏГЩЪ§ОндДВЂВЩМЏЪ§ОнЃЌБмУтБраДДѓСПЕФДњТыЁЃФПЧАвЕНчНЯЮЊжїСїЕФЪ§ОнВЩМЏЙЄОпгаFlumeЁЂLogstashвдМАKafka
ConnectЕШЕШЃЌетаЉЙЄОпИїгаИїЕФЬиЕуКЭЩУГЄСьгђЃЌЕЋЪЧдкжЇГжавщЕФЗсИЛадКЭПЩХфжУадЩЯЃЌгыЮвУЧЕФашЧѓгавЛЖЈЕФВюОрЁЃ
ЦфЪЕгавЛИівЛжББЛШЫКіЪгЕЋШДЪЧЗЧГЃРэЯыЕФЪ§ОнВЩМЏзщМўЁЊЁЊApache CamelЃЌЫќжївЊгІгУгкЦѓвЕгІгУМЏГЩСьгђЃЌвВБЛвЛаЉЯЕЭГзїЮЊESBЃЈЦѓвЕЗўЮёзмЯпЃЉЪЙгУЃЌЦфзїгУЪЧдкгІгУЯЕЭГСжСЂЕФЦѓвЕITЛЗОГжаАчбнвЛИіЁАЭђЯђНгЭЗЁБЕФНЧЩЋЃЌШУЪ§ОнКЭаХЯЂдкИїжжВЛЭЌЕФЯЕЭГМфЦНЛЌЕиНЛЛЛКЭСїзЊЃЌОЙ§ЖрФъЕФЛ§РлЃЌCamelвбОжЇГжНќ200жжавщЛђЪ§ОндДЃЌВЂЧвПЩвдЭъШЋЛљгкХфжУЪЕЯжЃЌетЧЁКУТњзуСЫЮвУЧЪ§ОнВЩМЏЕФашЧѓЃЌОЙ§даЭбщжЄЃЌвВжЄУїСЫЮвУЧЕФбЁдёЪЧУїжЧЕФЁЃ
зюКѓЃЌзїЮЊвЛИіЗЧДѓЪ§ОнзщМўЃЌЖдгкCamelЕФадФмКЭЭЬЭТСПЮвУЧЪЧгаЧхЮњШЯЪЖЕФЃЌЭЈЙ§ЖдЪ§ОндДНјааЗжзщЃЌЪЙгУЖрИіCamelЪЕР§ЗжЧјВЩМЏЪ§ОнЃЌЮвУЧДгМмЙЙЩЯЧсЫЩЕиНтОіСЫетаЉЮЪЬтЁЃ
ЯћЯЂЖгСа
дкЯћЯЂЖгСаЕФбЁдёЩЯУЛгаПЩвдЬжТлЕФЃЌKafkaМИКѕЪЧВЛЖўЕФбЁдёЃЌЮвУЧвВВЛР§ЭтЁЃ
СїДІРэ
СїДІРэКЭХњДІРэЖМЪЧвЕЮёТпМзюМЏжаЕФЕиЗНЃЌвВЪЧЯЕЭГЕФКЫаФЁЃФПЧАгУгкСїДІРэЕФжїСїММЪѕЪЧStormКЭSpark
StreamingЃЌЖдСНепНјааБШНЯЕФЮФеТКмЖрЃЌЭЈГЃШЯЮЊStormОпгаИќИпЕФЪЕЪБадЃЌПЩвдзіЕНзюЕЭбЧУыМЖЕФбгГйЃЌЯрБШжЎЯТSpark
StreamingЕФЪЕЪБадвЊВювЛаЉЃЌвђЮЊЫќвдЁБmicro batchЁБЕФЗНЪННјааСїДІРэЕФЃЌЕЋЪЧвРЭаSparkетИіДѓЦНЬЈЃЌДгЭГвЛММЪѕЖбеЛКЭгыЦфЫћSparkзщМўНЛЛЅЕФНЧЖШПМТЧЃЌSpark
StreamingБфЕУдНРДдНСїааЃЌМјгкдквЕЮёЩЯУыМЖбгГйвбОПЩвдТњзуашЧѓЃЌЮвУЧзюжебЁдёСЫКѓепЁЃ
ХњДІРэ
ДЋЭГДѓЪ§ОнЕФРыЯпДІРэЖрбЁдёвдHiveЮЊДњБэЕФЪ§ОнВжПтНјааНЈФЃКЭЗжЮіЃЌетдкКмЖрЯюФПЩЯБЛжЄУїЪЧПЩППЕФНтОіЗНАИЁЃКѓРДЫцзХSparkЕФВЛЖЯзГДѓЃЌSpark
SQLЕФЪЙгУдНРДдНЙуЗКЃЌВЂЧвSpark SQLЭъШЋМцШнHiveЃЌетЪЙЕУЧЈвЦЙЄзїМИКѕУЛгаШЮКЮеЯАЁЃЖдгкИДдгЕФЗЧНсЙЙЛЏЪ§ОнЃЌHadoopЦНЬЈЩЯЭЈЙ§MRБрГЬШЅДІРэЃЌSparkЪЧЭЈЙ§Spark
CoreЕФRDDБрГЬЪЕЯжЁЃШчНёSparkдкДѓЪ§ОнДІРэЕФКмЖрЗНУцвбОШЁДњHadoopГЩЮЊДѓЪ§ОнЕФЪзбЁММЪѕЦНЬЈЃЌЮвУЧдкХњДІРэЕФбЁаЭЩЯвВУЛгаЙ§ЖрЕФЬжТлЃЌЪЙгУSpark
Core + Spark SQLЪЧвЛИіздШЛЖјШЛЕФОіЖЈЁЃ
ЕЋЪЧПМТЧЕНЯЕЭГДІРэЕФЪЧTSDЪ§ОнЃЌШчЧАЮФЫљЪєЃЌдкХњДІРэЕФЪ§ОнСДЬѕЩЯЃЌTSDв§ЧцвРШЛЪЧвЛИіБиВЛПЩЩйЕФНЧЩЋЃЌЮвУЧЩшМЦЕФВпТдЪЧ:
1.ЫљгаTSDв§ЧцПЩвджБНгжЇГжЕФВщбЏНЛгЩTSDв§ЧцжБНгДІРэ
2.ИДдгЕФвЕЮёДІРэПЩвдЭЈЙ§TSDв§ЧцНјаадЄДІРэЃЌНЋдЄДІРэНсЙћНЛИјSpark
CoreНјааЩюЖШЗжЮіВЂНЋНсЙћаДЛиЪ§ОнПт
3.еыЖдTSDв§ЧцЮоЗЈЭъГЩЕФЗжЮіТпМЃЌгЩSpark CoreЛђSpark
SQLШЦЙ§TSDв§ЧцЃЌжБСЌКѓЖЫЕФHBaseНјааЗжЮіДІРэЃЌНсЙћЭЌбљжБНгаДЕНHBaseЩЯ
4.ЮЊЬсЩ§адФмЃЌЖдЗжЮіжаЪЙгУЕНЕФвдШе/жм/дТ/ФъЮЊЕЅЮЛЕФжаМфБэНјаадЄЩњГЩМЦЫуЁЃ
жїЪ§ОнЙмРэ
жїЪ§ОнЪЧжИРДздЪ§ОндДЕФКЫаФвЕЮёЖдЯѓЃЌЖдгкЮвУЧетИівдМрПиЮЊКЫаФЕФЦНЬЈЃЌжїЪ§ОнАќРЈЃКЗўЮёЦїЁЂЯЕЭГЭиЦЫНсЙЙЁЂеОЕуЁЂЭјТчЩшЪЉЕШЕШЃЌжїЪ§ОнЭљЭљЖМПчдНЖржжВЛЭЌЕФЪ§ОндДЃЌВЂЧвОГЃЗЂЩњБфИќЃЌашвЊЖдЦфНјааЖЈЦкЮЌЛЄЁЃ
ЮЊДЫЃЌЮвУЧЙЙНЈСЫвЛИіЭГвЛЕФжїЪ§ОнЙмРэзщМўЃЌВЂЭЈЙ§Web ServiceЕФЗНЪНЯђЭтЬсЙЉжїЪ§ОнЃЌгЩгкЦНЬЈдкСїДІРэКЭХњДІРэЙ§ГЬжаашвЊЦЕЗБЕиЪЙгУжїЪ§ОнЃЌЖјжїЪ§ОнЕФЬхСПВЂВЛДѓЃЌЫљвдЮвУЧЛсШУСїДІРэКЭХњДІРэзщМўвЛДЮадЕиНЋжїЪ§ОнМгдиЕНФкДцжаЃЌЭЌЪБЮЊЫќУЧМгШыУќСюааКЭRestful
APIНгПкЃЌдЪаэЫќУЧдкжїЪ§ОнЗЂЩњБфИќЪБжиаТМгдижїЪ§ОнЁЃ
жїЪ§ОнЙмРэФЃПщЪЧвЛИіДЋЭГЕФWebгІгУЃЌЛљгкSpring-BootЙЙНЈЃЌЪЙгУMySQLДцДЂЕМШыЕФжїЪ§ОнЃЌЖдЭтЭЈЙ§Restful
APIЬсЙЉжїЪ§ОнЙЉИјЗўЮёЃЌЫќЛЙгавЛИіЙмРэвГУцЗНБуЙмРэдБЮЌЛЄжїЪ§ОнЁЃ
TSDв§ЧцгыЪ§ОнДцДЂ
TSDв§ЧцИКд№TSDЕФаДШыКЭВщбЏЃЌКмЖрTSDЪ§ОнПтЛсРћгУвЛИіГЩЪьЕФNoSQLЪ§ОнПтНјааЪ§ОнДцДЂЃЌЖјTSDв§ЧцдђзЈзЂдкTSDЪ§ОнЕФДІРэЩЯЁЃетСНВПЗжУмВЛПЩЗжЃЌвђДЫЮвУЧЗХдквЛЦ№ЬжТлЁЃ
ЮвУЧЖдЪБМфађСаЪ§ОнПтЕФбЁаЭжївЊЪЧдкФПЧАвЕНчзюжїСїЕФСНИіВњЦЗInfluxDBКЭOpenTSDBжЎМфеЙПЊЕФЁЃ
ЧАепЪЙгУGOгябдБраДЃЌКѓЖЫДцДЂЯШКѓЪЙгУЙ§LevelDBКЭBoltDBЃЌЯждкЪЙгУЕФдђЪЧInfluxDBздМКЪЕЯжЕФTime
Structured Merge Treeв§ЧцЃЌOpenTSDBЪЙгУJavaБраДЃЌКѓЖЫДцДЂЪЙгУHBaseЁЃдкЕЅЛњадФмЩЯЃЌЖржжЖдБШВтЪдЯдЪОInfluxDBОпгаИќИпЕФадФмЃЌЕЋЮвУЧзюжебЁдёЕФЪЧOpenTSDBЃЌжївЊдвђЪЧПМТЧЕНдкМЏШККЭЫЎЦНЩьЫѕЗНУцЃЌБГППHBaseЕФOpenTSDBгаУїЯдЕФгХЪЦЃЌЯрБШжЎЯТInfluxDBжЛдкЪеЗбЕФЦѓвЕАцЬсЙЉМЏШКЙІФмЃЌЭЌЪБдкМЏШКЙцФЃКЭжЇГХЕФЪ§ОнСПЩЯУЛгаЙЋПЊЯъЪЕЕФВЮПМЪ§ОнЃЌЖјHBaseдчвбдкжкЖрЪЕМЪЯюФПЬиБ№ЪЧЙњФквЛаЉжЊУћЛЅСЊЭјЙЋЫОжаЙуЗКЪЙгУВЂЕУЕНСЫбщжЄЁЃСэвЛЗНУцЃЌOpenTSDBКЭHBaseЖМЪЙгУJavaБраДЃЌетЖдгкЮвУЧећИіДѓЪ§ОнММЪѕЭХЖгРДЫЕдкЮЌЛЄКЭаоИДвЛаЉЕзВуBugЩЯвВЯрЖдШнвзвЛаЉЁЃ
TSDв§ЧцЧ§ЖЏ
етЪЧвЛИіЖЈжЦПЊЗЂЕФзщМўЃЌЦфзїгУЪЧЖдTSDЪ§ОнНјаазЊЛЛКЭАќЙќЃЌвдБугкИќКУЕиНјааЪ§ОнеЙЪОЃЌЕБЪ§ОнВщбЏЧыЧѓЕНДяЪБЃЌЫќЛсИљОнЧыЧѓЕФФкШнКЭЪБМфПчЖШАбЧыЧѓТЗгЩЕНЪЕЪБПтЛђХњДІРэПтЃЌЕБЧыЧѓЗЕЛиЪБЃЌЫќЭЌбљЛсЙ§ТЫЯьгІФкШнЃЌЖдФГаЉзжЖЮКЭжЕНјаагГЩфКЭзЊТыЃЌШчЧАЫљЪіЃЌвђЮЊЪБМфађСаЪ§ОнПтЖдДцДЂЕФTSDгаКмЖраЮЪНЩЯЕФЯожЦЃЌФГаЉЪ§ОнВЛПЩвджБНгДцДЂЃЌЫќУЧдкШыПтЧАвбОзіСЫЯргІЕФИёЪНЛЏДІРэЃЌдкЬсШЁеЙЪОЪБашвЊНјааЯргІЕФЗДДІРэЁЃ
TSDв§ЧцЧ§ЖЏБОжЪЩЯЪЧвЛИіWeb ServiceЃЌДгФГжжвтвхЩЯЫЕЃЌетИіWeb ServiceЯёЪЧTSDв§ЧцЕФвЛИіЗДЯђДњРэЃЌЫќФмСщЛюКЭЭИУїЕиНтОівЛаЉЖЈжЦЛЏашЧѓвдМАЗЧБъзМЪ§ОнЕФЪЪХфЙЄзїЃЌДгЖјБмУтЖдTSDв§ЧцКЭЧАЖЫеЙЪОНјааЧжШыадЕФаоИФЁЃ
дкММЪѕбЁаЭЩЯЃЌЫљгажЇГжWeb ServiceЕФПђМмЖМПЩвдЪЄШЮетИіЙЄзїЃЌПМТЧЕНЮвУЧећИіДѓЦНЬЈЕФММЪѕЖбеЛЖМвдsbt-native-packager/JavaЮЊжїЃЌЮвУЧЪЕбщадЕибЁдёСЫAkka-HttpЃЌЭЈЙ§РћгУAkka-HttpЕФHTTP
DSLКЭsbt-native-packagerЕФФЃЪНЦЅХфЃЌЮвУЧгУКмЩйЕФДњТыОЭЪЕЯжСЫМШЖЈФПБъЃЌаЇЙћЗЧГЃКУЁЃ
Ъ§ОнеЙЪО
зюКѓЃЌдкЪ§ОнеЙЪОЩЯЃЌGrafanaЪЧЮвУЧзюМбЕФбЁдёЁЃЫќЪЧвЛИізЈУХЕФЪБађЪ§ОнеЙЪОЙЄОпЃЌПЩвджБСЌOpenTSDBЃЌЭМБэЕФжЦзїЖМЪЧЭЈЙ§ЭЯЗХЭъГЩЕФЃЌЫќЛЙгавЛИівьГЃЧПДѓЕФЁАФЃАцЁБЛњжЦЃЌПЩвдЭЈЙ§вЛДЮЩшЖЈЩњГЩЖреХЭМБэЁЃШчЙћМШгаВхМўЮоЗЈТњзуеЙЪОашЧѓЃЌЭХЖгЛЙвдПЊЗЂздЖЈвхВхМўЁЃ
злЩЯЫљЪіЃЌећИіЯЕЭГЕФММЪѕЖбеЛШчЯТЫљЪОЃК
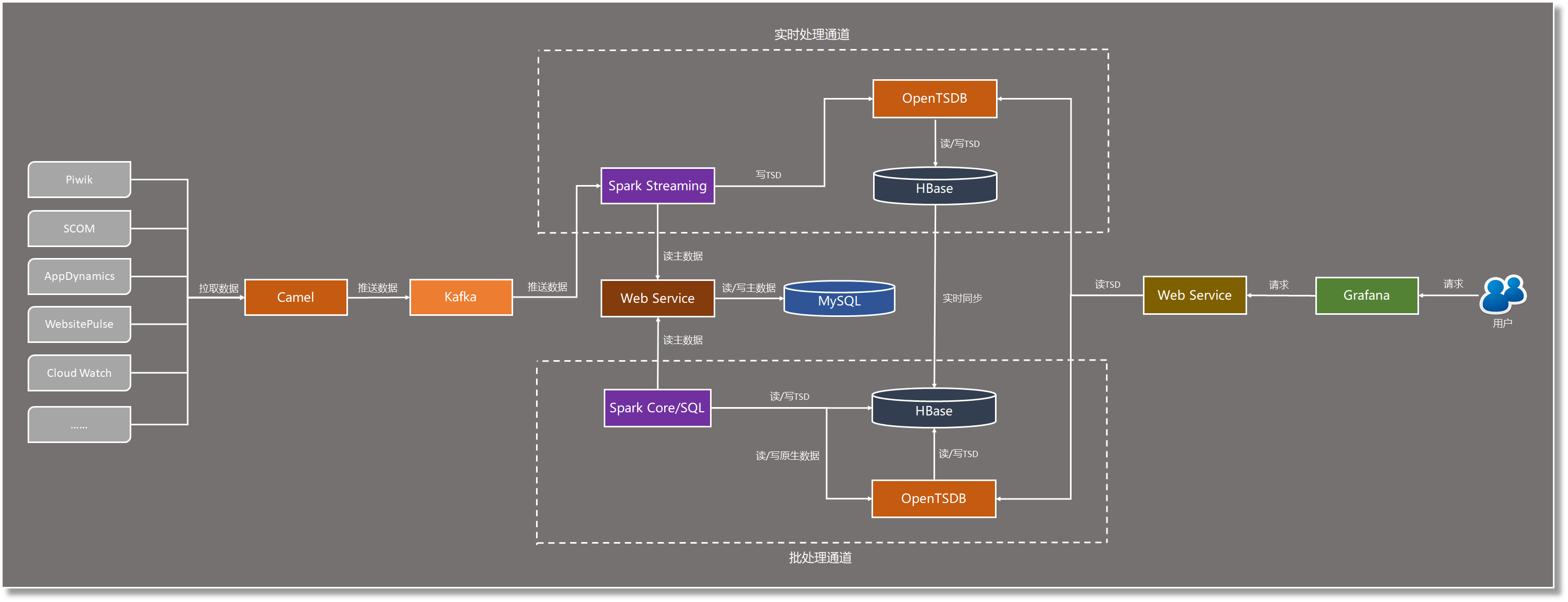
ЮяРэМмЙЙ
ЖдгкЦНЬЈЕФЮяРэМмЙЙЮвУЧВЛДђЫуНјааЙ§ЖрЕФНщЩмЃЌвђЮЊHadoop/SparkМЏШКЖМДѓЭЌаЁвьЃЌЮвУЧетРявЊЬжТлЕФЪЧетИіЦНЬЈдкЮяРэМмЙЙЩЯЕФвЛИіЯджјЕФЬиЕуЃЌОЭЪЧЮвУЧЙЙНЈСЫСНИіЖРСЂЕФHadoop/SparkМЏШКЃЌвЛИіИКд№СїДІРэЃЌСэвЛИіИКд№ХњДІРэЃЌетвВЪЧМљааLambdaМмЙЙдкЮяРэВуУцЩЯЕФвЛИіздШЛЕФНсЙћЃЌСНИіМЏШКЕФЪ§ОнНЛЛЅвРППHBaseЕФReplicationЛњжЦЭИУїЕиЪЕЯжЁЃЦфЫћЕФЗЧHadoop/SparkзщМўЛсВПЪ№дкРыЩЂЕФЗўЮёЦїЩЯЁЃ

ЪЕЪБДІРэМЏШККЭХњДІРэМЏШКГ§СЫЗжЙЄЩЯЕФВЛЭЌЃЌдкМЏШКНсЙЙКЭНкЕуХфжУЩЯвВгаКмДѓЕФЧјБ№ЃЌЬиБ№ЪЧдкМЦЫузЪдДКЭДцДЂзЪдДЕФЗжХфЩЯЁЃЭЈГЃЃЌHadoopМЏШКЕФМЦЫуЗўЮёКЭДцДЂЗўЮёЪЧЙВЩњдквЛЦ№ЕФЃЌМДHDFSЕФDataNodeКЭYARNЕФNodeManagerзмЪЧcollocateЕФ,
етбљзіЕФФПЕФЪЧШУЗжВМЪНМЦЫуОЁПЩФмЕиДгБОЕиЖСШЁЪ§ОнНјааДІРэЃЌМѕЩйЭјТчIOЃЌЬсЩ§адФмЁЃЮвУЧЕФХњДІРэМЏШКОЭЪЧАДетбљЕФФЃЪННјаазЪдДХфжУЕФЃКЛљгкSparkЕФХњДІРэГЬађХмдкYarnЕФNodeManagerЩЯЃЌОЁСПЖСаДБОЕиDataNodeЩЯЕФЪ§ОнЃЌЖдгкHBaseвВЪЧЭЌбљЕФТпМЃЌШУNodeManagerвВгыDataNodeЙВЩњдквЛЦ№ЁЃ

дкЪЕЪБДІРэМЏШКЩЯЧщПідђДѓВЛЯрЭЌЁЃЪзЯШЃЌдкСїДІРэЙ§ГЬжаЪ§ОнЪЧВЛТфЕиЕФЃЌвђДЫдкСїМЦЫуЕФНкЕуЩЯжЛЛсЗжХфNodeManagerЃЌЖјВЛЛсгаDataNode,
ЕНСЫЪ§ОнДцДЂЛЗНкВХЛсШУHBaseЕФNodeManagerгыDataNodeЙВЩњЁЃЫљвдЫЕNodeManagerКЭDataNodeзмЪЧcollocateЕФЫЕЗЈЬЋОјЖдЃЌвЛЧаЛЙЪЧвЊИљОнЪЕМЪЧщПіСщЛюДІРэЁЃ
ЦНЬЈНЈЩш
ДгЧАУцНщЩмЕФММЪѕМмЙЙКЭбЁаЭЩЯВЛФбПДГіетИіЯЕЭГЕФИДдгадЃЌдкНЈЩшЙ§ГЬжаЮвУЧгіЕНСЫКмЖрРЇФбЃЌвВЛ§РлСЫвЛаЉБІЙѓЕФОбщЃЌЯогкЦЊЗљЃЌЮвУЧбЁШЁСЫвЛаЉгаМлжЕЕФЛАЬтКЭДѓМвНјааЗжЯэЁЃ
ЮЇШЦжїЪ§ОнНјааСьгђНЈФЃ
ЁАУЛгаСьгђФЃаЭЕФЩшМЦЖМЪЧЫЃСїУЅЁБЃЌетОфПДЫЦЕїйЉЕФЛАБэДяЕФШДЪЧЖдШэМўЩшМЦЕФвЛжжбЯЫрЬЌЖШЃЌСьгђФЃаЭдкШЮКЮРраЭЕФЯЕЭГРяЖМЦ№зХКЫаФзїгУЃЌДѓЪ§ОнЯЕЭГвВВЛР§ЭтЃЌФуПЩвдВЛШЅЩшМЦЫќЃЌЕЋетВЂВЛБэЪОЫќВЛДцдкЃЌвЛИіВЛФмШчЪЕЗДгГвЕЮёТпМЕФФЃаЭзЂЖЈЛсЕМжТећИіЯЕЭГЕФЪЇАмЁЃдкЮвУЧетИіУцЯђЪБађЪ§ОнЕФДѓЪ§ОнЦНЬЈЩЯЃЌЫљгаЕФTSDЖМГіздгкЛђУшЪіСЫФГвЛРржїЪ§ОнЕФзДЬЌЛђааЮЊЃЌЛђепЫЕЫќУЧЖМЪЧжїЪ§ОнЫљДњБэЕФвЕЮёЪЕЬхЕФВњЮяЃЌБШШчЗўЮёЦїЕФMetricsЪ§ОнЃЌетЪЧЕфаЭЕФTSDЃЌЫќУЧУшЪіЕФОЭЪЧвЕЮёЖдЯѓЃКЁБЗўЮёЦїЁБЕФзДЬЌЁЃДгOOНЈФЃЕФНЧЖШРДЫМПМетИіЮЪЬтЃЌШчЙћМрПиЯЕЭГашвЊНЈСЂеыЖдетИіЗўЮёЦїЕФвЛећЬзМрПиКЭБЈОЏЙцдђЃЌФЧУДЫљгаЯргІЕФТпМБиШЛЛсзЗМгЕНЁАЗўЮёЦїЁБвдМАвЛаЉКЭЫќЯрЙиСЊЕФЪЕЬхЩЯЃЌетОЭЪЧЮвУЧЫљЫЕЕФЁАЮЇШЦжїЪ§ОнНјааСьгђНЈФЃЁБЁЃ
етвЛЕуЗЧГЃживЊЧвгааЇЃЌвђЮЊЫќЪЧЖдЫљгавЕЮёТпМЕФвЛжжздШЛЕФЪсРэКЭЛЎЗжЃЌзюФмЙЛЗДгГСьгђЕФБОРДУцФПЃЌдНЪЧИДдгЕФвЕЮёГЁОАдНФмЬхЯжгХдНадЁЃЫљгаетаЉЫМПМКЭЧуЯђадЖМдкв§ЕМЮвУЧНЅНЅЕиЯђЁАСьгђЧ§ЖЏЩшМЦЁБЃЈDomain
Driven DesignЃЉЕФЗНЯђЧАНјЃЌетЪЧвЛИіЗЧГЃЗсИЛВЂЧвОпгаЪЕМЪвтвхЕФЛАЬтЃЌСюШЫИаПЎЕФЪЧЮвУЧдкДѓЪ§ОнЦНЬЈЩЯШУЁАСьгђЧ§ЖЏЩшМЦЁБдйвЛДЮЛРЗЂСЫЩњЛњЃЌвдСьгђФЃаЭЮЊКЫаФЧ§ЖЏвЕЮёДІРэКЭЪ§ОнЗжЮіЪЧвЛИіЗЧГЃУїжЧЕФбЁдёЃЌОЁЙметЖдЭХЖгећЬхЕФЫижЪгаИќИпЕФвЊЧѓЃЌЪЕЪЉФбЖШвВИќДѓЃЌЕЋЪЧЛиРЁвВЪЧОоДѓЕФЁЃ
ЮвУЧгавЛИіЩњЖЏЕФЪЕР§ЃКдкЦНЬЈНЈЩшЕФдчЦкЃЌЯогкУПИіЪ§ОндДЕФИёЪНКЭДІРэТпМЩЯЕФВювьЃЌУПИіЪ§ОндДЖМздМКЕФвЕЮёДІРэДњТыКЭЖРСЂЕФвЕЮёЙцдђБэЃЌетжжДІРэЗНЪНЗЧГЃРрЫЦгкДЋЭГЦѓвЕгІгУМмЙЙжаЕФЁАTransaction
ScriptЁБФЃЪН(ЙигкTransaction ScriptЧыВЮПМMartin FowlerЕФЁЖPatterns
of Enterprise Application ArchitectureЁЗвЛЪщЕФЕк9еТЃЉЃЌАщЫцзХЪ§ОндДЕФВЛЖЯв§ШыЃЌЮвУЧЗЂЯжгІгУдкКмЖрВЛЭЌЪ§ОндДЩЯЕФМрПиКЭБЈОЏТпМЖМЗЧГЃРрЫЦЃЌВЂЧвеыЖдЕФвЕЮёЖдЯѓвВЖМЪЧвЛбљЕФЃЌР§ШчВЛЭЌЕФЪ§ОндДЖМЛсУцЯђФГЬЈЗўЮёЦїЛђФГИіеОЕуВњЩњБЈОЏЯћЯЂЃЌЖјЮвУЧЖдетаЉБЈОЏЯћЯЂЕФДІРэгазХКмДѓЕФЯрЫЦадЃЌетДйЪЙЮвУЧвджїЪ§ОнЮЊЖдЯѓНјааСЫСьгђНЈФЃЃЌАбТпМНјааСЫЭГвЛЪсРэЃЌдкВЛвЛжТЕФЕиЗНдЫгУЪЪХфЦїЁЂаоЪЮЦїКЭВпТдЕШФЃЪННјааЖдНгЃЌзюжеНЋдРДРыЩЂЕФДњТыКЭХфжУЭГвЛдкСЫвЛИіСьгђФЃаЭЩЯЃЌДѓДѓМђЛЏСЫБрГЬКЭЮЌЛЄГЩБОЃЌдкДІРэаТМгШыЕФЪ§ОндДЪББфЕУИќМгМђБуПьНнЁЃ
зюКѓЃЌВЙГфвЛЕуШЯЪЖЃЌдкДЋЭГЦѓвЕМЖгІгУРяНјааСьгђЧ§ЖЏЩшМЦгажюЖрЕФРЇФбЃЌЦфжавЛИіБШНЯЭЛГіЕФЮЪЬтОЭЪЧСьгђЖдЯѓЕФГжОУЛЏЃЌгЩгкЪ§ОнДцЗХдкЙиЯЕаЭЪ§ОнПтжаЃЌСьгђЖдЯѓЕФаДШыКЭМгдиЖМДцдквЛИіЁАЖдЯѓЙиЯЕгГЩфЁБЕФЮЪЬтЃЌОЁЙмгаКмЖрГЩЪьЕФORMПђМмФмдквЛЖЈГЬЖШЩЯЛКНтетИіЮЪЬтЃЌЕЋЪЧдкДЋЭГЦѓвЕМЖгІгУРяТфЕивЛИіДПе§ЕФСьгђФЃаЭвРШЛЪЧвЛИіВЛаЁЕФЬєеНЃЌЖјДѓЪ§ОнЦНЬЈЮЊСьгђЧ§ЖЏЩшМЦЬсЙЉСЫвЛИіИќМгздгЩЕФПеМфЃЌБШШчДѓЪ§ОнЕФМЦЫуНкЕуПЩвдЬсЙЉзуЙЛЕФФкДцНЋСьгђЖдЯѓвЛДЮадШЋВПМгдиЃЌУтШЅСЫORMжаЖдЙиСЊЖдЯѓМгдиВпТдЕФОРНсЃЌЖјСьгђЖдЯѓЛсдкДѓЪ§ОнДІРэЙ§ГЬжаЗДИДЪЙгУЃЌПЭЙлЩЯвВашвЊжБНгАбЫќУЧМгдиЕНФкДцжаЪЙгУЃЌдйБШШчЃЌдквЕЮёДІРэКЭЗжЮіНзЖЮЃЌМИКѕЫљгаСьгђЖдЯѓЖМЪЧжЛЖСЕФЃЌЫќУЧжЛЛсдкЭЌВНжїЪ§ОнЪББЛИќаТЃЌетЬьШЛЕиаЮГЩСЫЖСаДЗжРыЃЌИќМгЪЪКЯCQRSМмЙЙЁЃ
СїДІРэЕФЙЄГЬНсЙЙ
КмЖрЭХЖгдкГѕДЮЪЙгУСїМЦЫуПђМмЙЙНЈЯюФПЪБЭљЭљЛсдкШчКЮзщжЏЙЄГЬНсЙЙЩЯИаЕНУдУЃЃЌВЛЭЌгкДЋЭГЦѓвЕМЖгІгУОЙ§ЖрФъЛ§РлаЮГЩЕФЁАЬзТЗЁБЃЌСїДІРэЯюФПЕФЙЄГЬНсЙЙВЂУЛгавЛИідМЖЈЫзГЩЕФзюМбЪЕМљЃЌЮвУЧдкетРяЗжЯэЮвУЧЕФЙЄГЬНсЙЙзїЮЊвЛИіВЮПМЃЌЯЃЭћЖдФугаЫљЦєЗЂЁЃ

вВаэФуЛсОѕЕУетИіЙЄГЬНсЙЙЗЧГЃУцЪьЃЌЪЧЕФЃЌЮвУЧГфЗжНшМјСЫДЋЭГЦѓвЕМЖгІгУЕФЗжВуНсЙЙЃЌУПвЛИіЩЋПщЖМДњБэзХвЛРрзщМўЃЌгГЩфЕНЙЄГЬЩЯОЭЪЧвЛИіpackageЃЌШУЮвУЧж№вЛНщЩмвЛЯТЃК
StreamЃК ЯЕЭГжаЕФУПвЛИіСїЖМЛсЗтзАдквЛИіРржаЃЌЮвУЧАбетаЉРрЭГвЛАДЁАXxxStreamЁБаЮЪННјааУќУћЃЌЗХдкstreamАќРяЃЌStreamРрРяГіЯжЕФЖрЪЧгыSpark
StreamingЯрЙиЕФAPIЃЌдкЩцМАЪЕМЪЕФвЕЮёДІРэЪБЃЌЛсЕїгУЯргІЕФServiceЗНЗЈЃЌетжжЩшМЦЗДгГСЫЮвУЧЖдСїДІРэЕФвЛИіЛљБОШЯЪЖЃЌФЧОЭЪЧСїМЦЫужаЕФAPIЪЧвЛИіЁАУХУцЁБ(Facade)ЃЌКёжиЕФвЕЮёДІРэВЛгІдкетаЉAPIЩЯжБНгвдLambdaБэДяЪНЕФЗНЪНБраДЃЌЖјгІИУЗтзАЕНзЈУХЕФServiceРяЁЃетгыWebгІгУжаActionКЭServiceЕФЙиЯЕМЋЮЊРрЫЦЁЃ
ServiceЃК гывЕЮёЯрЙиЕФДІРэТпМЛсЗтзАЕНServiceРрРяЃЌетЪЧКмДЋЭГЕФзіЗЈЃЌЕЋЪЧгЩгкЮвУЧЩюЖШЕигІгУСЫСьгђЧ§ЖЏЩшМЦЃЌЫљвдОјДѓВПЗжЕФвЕЮёТпМвбОздШЛЕиЮЏХЩЕНСЫСьгђЖдЯѓЕФЗНЗЈЩЯСЫЃЌвђДЫServiceвВБфГЩСЫКмБЁЕФвЛВуЗтзАЁЃгаИіжЕЕУвЛЬсЕФЯИНкЃЌЮвУЧАбЫљгаЕФServiceЖМзіГЩСЫobject(sbt-native-packagerжаЕФobjectЖдЯѓЃЉЃЌвВОЭЪЧЕЅЬЌЃЌ
етбљзіЕФжївЊЕФЖЏЛњЪЧШУЫљгаЕФExecutorНкЕудкБОЕиМгдиШЋОжЮЈвЛЕФServiceЪЕР§ЃЌБмУтServiceЪЕР§ДгDriverЖЫЕНExecutorЖЫзіЮоЮНЕФађСаЛЏгыЗДађСаЛЏВйзїЁЃ
RepositoryЃКдкЯрЖдМђЕЅЕФЯЕЭГРяЃЌФуПЩвдРћгУRepositoryжБНгЖСШЁДцЗХгкЪ§ОнПтжаЕФжїЪ§ОнКЭХфжУаХЯЂЃЌШчЙћФуЕФЦНЬЈгаЖрДІзщМўЖМашвЊЪЙгУжїЪ§ОнЃЌЮвУЧНЈвщФуЮёБиНЈСЂЭГвЛЕФжїЪ§ОнКЭХфжУаХЯЂЖСаДзщМўЃЌШчЙћЪЧетбљЃЌдђзЈЪєгкСїДІРэЕФRepositoryНЋВЛИДДцдкЁЃ
DomainЃКСьгђФЃаЭЩцМАЕФЪЕЬхКЭжЕЖдЯѓЖМЛсЗХдкетИіАќРяЃЌвЕЮёДІРэКЭЗжЮіЕФТпМЛсАДееУцЯђЖдЯѓЕФЩшМЦРэФюЗжЩЂЕНСьгђЖдЯѓЕФвЕЮёЗНЗЈЩЯЁЃЭЌбљЕФЃЌШчЙћНЈСЂСЫЭГвЛЕФжїЪ§ОнКЭХфжУаХЯЂЕФЖСаДзщМўЃЌдђDomainвВНЋВЛИДДцдк
DTOЃК СїДІРэжаЕФDTOВЂВЛЪЧЮЊДЋЪфСьгђЖдЯѓЖјЩшМЦЕФЃЌЫќЪЧЭтВПВЩМЏЕФдЩњЪ§ОнОЙ§НсЙЙЛЏДІРэжЎКѓдкСїЩЯЕФЪ§ОнЖдЯѓЁЃ
ЯюФПЙЙНЈЃКSbt vs. Maven
гЩгкЮвУЧЕФЦНЬЈММЪѕЖбеЛвдSparkЮЊКЫаФЃЌЮвУЧЕФМИИіКЫаФзщМўЖМЪЧЪЙгУsbt-native-packagerБраДЕФЃЌдкЯюФПЙЙНЈЩЯвВЛ§РлСЫвЛаЉБІЙѓЕФОбщЃЌдчЦкЮвУЧЪЙгУЕФЪЧsbt-native-packagerЕФФЌШЯЙЙНЈЙЄОпsbtЃЌ
зїЮЊаТвЛДњЕФЙЙНЈЙЄОпЃЌsbtЮќЪеСЫжкЖрЧАБВЕФгХЕуЃЌМђЕЅвзгУЃЌФмЙЛТњзуЛљБОЕФгІгУГЁОАЃЌЕЋдкЪЕМЪЕФЯюФПЙЙНЈжаЃЌЕБУцСйвЛаЉЯрЖдИДдгЕФГЁОАЪБЃЌФъЧрЕФsbtЛсЯдЕУБШНЯЮоСІЃЌЦфжазюЮЊЮвУЧВЛФмНгЪмЕФЪЧУцЯђЖрЛЗОГЕФЙЙНЈЁЃОЁЙмЩчЧјЬсГіЙ§вЛаЉНтОіЗНАИЃЌР§Шчhttp://stackoverflow.com/questions/17193795/how-to-add-environment-profile-config-to-sbt
ЃЌ ЕЋЪЧетИіЗНАИЕФШБЯндкгкЖдгкУПвЛЬзЛЗОГЖМвЊЬсЙЉШЋЬзЕФХфжУЃЌМДЪЙЫќУЧдкЖрЪ§ОнЛЗОГжаЕФжЕЪЧвЛбљЕФЁЃЪЕМЪЩЯетИіЮЪЬтЕФБОжЪдвђЪЧsbtЩаУЛгаРрЫЦMavenФЧбљдкЙЙНЈЪБЛљгкФГИіХфжУЮФМўЖдвЛаЉБфСПНјааЙ§ТЫКЭЬцЛЛЕФResource+ProfileЙІФмЃЌетЪЧКмживЊЕФвЛИіашЧѓЁЃ
дкДђАќЗНУцЃЌЮвжИЕФЪЧЙЙНЈвЛИіАќКЌУќСюааЙЄОпЁЂХфжУЮФМўКЭИїжжlibЕФАВзААќЃЌsbtЕФsbt-native-packagerШЗЪЕЗЧГЃЧПДѓЃЌСюШЫгЁЯѓЩюПЬЁЃЭЌбљЃЌдкУцЯђВЛЭЌЛЗОГЕФЧАЬсЯТЃЌДђАќВЛЭЌгУЭОЕФpackageЪБЃЌsbt-native-packagerЕФСщЛюадЛЙгаД§МьбщЁЃР§ШчЃЌЛљгкЮвУЧЙ§ШЅЕФзюМбЪЕМљЃЌУцЯђУПвЛжжЛЗОГЃЌЮвУЧГЂГЂЛсРћгУsbt-native-packagerЙЙНЈСНжжpackageЃЌвЛжжЪЧАќКЌШЋВПВњГіЮяЕФБъзМВПЪ№АќЃЌвЛжжЪЧНіНіАќКЌУПДЮЙЙНЈЖМгаПЩФмЗЂЩњБфЛЏЕФЮФМўЃЌР§ШчЯюФПздЩэЕФjarАќКЭвЛаЉХфжУЮФМўЃЌЮвУЧАбетжжАќГЦЮЊзюаЁЛЏЕФpackageЃЌетжжpackageЛсгУгкШеГЃГжајМЏГЩЕФВПЪ№ЃЌЫќЕФЬхЛ§КмаЁЃЌдкЭјТчДјПэгаЯоЕФЛЗОГРяЃЌЫќЛсДѓДѓНкдМВПЪ№ЪБМфЁЃ
ЛиЕНMavenЃЌдкЙ§ШЅЪ§ФъЕФПЊЗЂЙЄзїжаЃЌMavenТњзуСЫЮвУЧИїЪНИїбљЕФЙЙНЈашЧѓЃЌДгУЛгаШУЮвУЧЪЇЭћЙ§ЃЌЫќЕФдМЖЈДѓгкХфжУЕФЫМЯыКЭЗсИЛЕФжмБпВхМўеце§ЪЕМљСЫЃКЁБMake
simple things simpleЃЌ complex things possibleЃЁЁБДгЪЕМЪаЇЙћПДЃЌЪЙгУMavenЙЙНЈsbt-native-packagerЯюФПУЛгаШЮКЮеЯАЃЌЫќГЩЪьЖјЧПДѓЕФИїЯюЙІФмПЩвдНтОіЪЕМЪЯюФПЩЯИїЪНИїбљЕФашЧѓЃЌетвЛЧаШУЮвУЧзюжеЛиЙщСЫMavenЁЃ
ЕЋЪЧетВЂВЛДњБэЮвУЧЛсдкMavenЩЯЭЃжЭВЛЧАЃЌЪЕМЪЩЯЮвУЧЖдsbtвРШЛБЇгаЦкЭћЃЌжЛЪЧЫќашвЊЪБМфБфЕУИќМгЧПДѓЁЃдкЮДРДФГИіКЯЪЪЕФЪБЛњЃЌЮвЯыЮвУЧЛсЧЈвЦЕНsbtЁЃ
Ъ§ОнВЩМЏЕФЭДЕуКЭгІЖдВпТд
Ъ§ОнВЩМЏЭљЭљЪЧДѓЪ§ОнЦНЬЈЩЯЕФдрЛюЁЂРлЛюЃЌГ§СЫНтОіММЪѕЩЯЕФЮЪЬтЃЌЭХЖгЛЙашвЊНјааДѓСПаЕїКЭЙЕЭЈЙЄзїЃЌвђЮЊЭтВПЪ§ОндДЖМгЩЦфЫћЭХЖгЙмРэЃЌашвЊДгИќИпЕФзщжЏВуУцНјааЪшЭЈЃЌВЂЧвКмЖрЪ§ОндДашвЊЭЌЪБЮЊЖрИіЭтВПЯЕЭГЙЉИјЪ§ОнЃЌЮЊСЫШЗБЃЪ§ОндДЕФПЩгУадЃЌЛсЖдЭтВПЕФЪ§ОнВЩМЏзївЕНјааПижЦЃЌБШШчЯожЦВЩМЏЦЕТЪЕШЁЃЮвУЧЯТУцЛсЬжТлСНИіМЌЪжЕФЮЪЬтЃЌВЂЗжЯэЮвУЧЕФНтОіЗНАИЁЃ
Ъ§ОнВЩМЏзївЕГЌЪБ
дкЮвУЧВЩМЏЕФЭтВПЪ§ОндДжаЃЌгавЛИіЪ§ОнПтдкФГаЉЪБПЬвђЮЊашвЊЭЌЪБДІРэЖрИіЭтЮЇЯЕЭГЕўМгЕФВщбЏЧыЧѓЖјОГЃЯьгІЛКТ§ЃЌНјЖјЕМжТСЫЮвУЧЕФЪ§ОнВЩМЏзївЕГЌЪБЃЌЖјетИіJobдРДЕФЩшМЦЪЧУПЗжжгжДаавЛДЮЃЌУПДЮжДааЪБЛсДгФПБъЪ§ОнПтжаВщбЏзюНќ1ЗжжгФкЕФЪ§ОнЃЌетИіВщбЏЧыЧѓЭЈГЃдк1УывдФкОЭПЩвдЗЕЛиЃЌЕЋЪЧЕБЪ§ОнПтЯьгІЛКТ§ЪБЃЌвЛИіJobЕФКФЪБЭљЭљвЊГЌЙ§1ЗжжгЃЌЖјКѓајЦєЖЏЕФJobШдШЛАДЦєЖЏЪБЕФЪБМфЕуЯђЧА1ЗжжгзїЮЊЪБМфДАПкНјааВщбЏЃЌетОЭГіЯжСЫЪ§ОнЖЊЪЇЁЃ
гІЖдетИіЮЪЬтЕФвЛИіМђЕЅЗНАИЪЧНЋJobЕФжДааБфЮЊвьВНЗЧзшШћФЃЪНЃЌУПвЛИіJobБЛДЅЗЂКѓЖМдквЛИіЖРСЂЕФЯпГЬжадЫааЁЃЕЋЪЧетИіЗНАИВЛЪЪгУгкЮвУЧЕФЯЕЭГЃЌвђЮЊетбљВЩМЏЕНЕФЪ§ОнВЛФмБЃжЄЪБМфЩЯЕФгаађадЃЌЖјетЖдвЛИіЪБађЪ§ОнЯЕЭГжСЙиживЊЁЃЫљвдетвЛЗНАИБЛЗёОіЁЃ
ОЙ§заЯИЕФЫМПМЃЌЮвУЧШЯЮЊБиаывЊНЋетИіJobЧаЗжГЩСНИізгЕФJobЃКЕквЛИіJobИКд№жЦЖЈжмЦкадЕФМЦЛЎЃЌзМШЗЕиЫЕЪЧжмЦкадЕиЩњГЩЪБМфДАПкВЮЪ§ЃЌЕкЖўИіJobИКд№ЖСШЁЪБМфДАПкВЮЪ§жДааВщбЏЃЌетвЛВПЗжЕФЙЄзїВЂВЛЪЧжмЦкадЕФЃЌддђЩЯЃЌжЛвЊгаЪБМфВЮЪ§ЩњГЩОЭгІИУСЂМДжДааЃЌШчЙћжДааГЌЪБЃЌдкГЌЪБЦкМфЃЌЮвУЧашвЊЛКДцЕквЛИіJobЩњГЩЕФЪБМфВЮЪ§ЃЌЖјЕБЫљгаЕФВщбЏЖММАЪБЭъГЩУЛгаД§жДааЕФВщбЏМЦЛЎЪБЃЌЕкЖўИіJobашвЊЕШД§аТЕФВщбЏВЮЪ§ЕНДяЃЌЪЧЕФЃЌетЪЕМЪЩЯЪЧвЛИіЩњВњеп-ЯћЗбепФЃаЭЃЌжЛЪЧЩњВњепЪЧдкЁАгаНкзрЁБЕиЩњВњЃЌдкетИіФЃЪНРяЃЌЕкШ§ИіВЮгыепЃКВжПтЃЌЛђепЫЕДЋЫЭДјЃЌЦ№ЕНСЫЙиМќЕФЕїНкзїгУЃЌЖјвЛИіЯжГЩЕФЪЕЯжОЭЪЧJDKздДјЕФBlockingQueueЃЁгкЪЧЮвУЧЕФТфЕиЗНАИЪЧЃК
1.ЕквЛИіJobгЩЖЈЪБЦїжмЦкадДЅЗЂЃЌУПДЮДЅЗЂЪБЛсАбЕБЧАЪБМфЗХЕНвЛИіBlockingQueueЕФЖгЮВЁЃ
2.ЕкЖўИіJobбЛЗжДааЃЌУПДЮжДааЕФЙЄзїОЭЪЧДгBlockingQueueЕФЖгЭЗШЁГіЪБМфВЮЪ§ЃЌзщзАSQLВЂжДааЁЃЕБЖгСаЮЊПеЪБЃЌгЩBlockingQueueРДзшШћЕБЧАЯпГЬЃЌЕШД§ЪБМфВЮЪ§НјШыЖгСаЁЃ
3.ЕБЕкЖўИіJobжДааЭъвЛДЮЪБЃЌШчЙћЖгСажаЛЙгаЪБМфВЮЪ§ЃЌЛсМЬајжДааВНжш2ЃЌЗЂЩњДЫРрЧщПіЪБОЭЫЕУїЧАвЛДЮЕФжДааГЌЙ§СЫ1ЗжжгЁЃ
Ъ§ОнбгГйОЭаї
ЮвУЧвЛжБЮЊНЕЕЭЦНЬЈЕФЪ§ОнбгГйзізХИїжжХЌСІЃЌЕЋзюШУШЫИаЕНЮоСІЕФЪЧЭтВПЪ§ОндДБОЩэдкЪ§ОнаДШыЪБЗЂЩњСЫбгГйЁЃОйИіР§згЃЌЛЙЪЧЧАУцЬсЕНЕФЪ§ОнПтЃЌУПДЮВЩМЏЪ§ОнЩшЖЈЕФЪБМфЧјМфЪЧДгЕБЧАЪБМфЕНЧАвЛЗжжгЃЌМйЖЈЕБЧАЪБМфЪЧ00:10ЃЌдђжДааЕФSQLжаЪБМфДАПкВЮЪ§ЪЧ(00:09ЃЌ00:10]ЃЌДЫЪБФуПЩФмЛсВщбЏЕН1000ЬѕЪ§ОнЃЌЕЋШчЙћФудк00:11вдЭЌбљЕФВЮЪ§(00:09ЃЌ00:10]дйДЮжДааетЬѕSQLЃЌ
ЗЕЛиЕФЪ§ОнЬѕФПОЭПЩФмБфГЩСЫ1200ЬѕЃЌетЫЕУїЪ§ОнПтжаЕФЪ§ОнДгЫќдквЕЮёЯЕЭГжаЩњГЩЕНзюКѓаДШыЪ§ОнПтЕФЙ§ГЬжаЗЂЩњСЫбгГйЃЌдьГЩетжжЧщПіЕФдвђгаКмЖрЃЌБШШчЯЕЭГДцдкадФмЮЪЬтЕШЕШЃЌзмжЎЯжзДОЭЪЧЃКЪ§ОнОЭаїЗЂЩњСЫбгГйЃЌЖјЖдгкЪ§ОнВЩМЏЗНетЭъШЋВЛПЩПиЁЃ
УцЖдетжжЮЪЬтЃЌЮвУЧЕФгІЖдВпТдЪЧЃКШчЙћЪ§ОнМАЪБЕиОЭаїСЫЃЌЮвУЧвЊБЃжЄФмМАЪБЕФВЖЛёЃЌШчЙћЪ§ОнбгГйОЭаїЃЌЮвУЧвЊБЃжЄжСЩйВЛЛсЖЊЕєЫќЁЃЛљгкетбљЕФПМТЧЃЌЮвУЧАбЭЌвЛИіЪ§ОндДЕФЪ§ОнВЩМЏЗжГЩСЫСНЕНШ§ИіЁАВЈДЮЁБНјааЃЌЕквЛВЈДЮЕФВЩМЏНєНєЬљНќЕБЧАЪБМфЃЌВЂЧвБЃГжМЋИпЕФЦЕТЪЃЌетвЛВЈДЮЪЧвЊБЃжЄзюдчзюПьЕиВЩМЏЕНЕБЧАЕФаТЩњЪ§ОнЃЌЕкЖўВЈДЮВЩМЏЕФЪЧЙ§ШЅФГИіЪБМфЧјМфЩЯЕФЪ§ОнЃЌЪБМфЦЋвЦПЩФмдкЪЎМИУыЕНМИЗжжгВЛЕШЃЌетШЁОігкФПБъЪ§ОндДЕФЪ§ОнбгГйГЬЖШЃЌЕкЖўВЈДЮЪЧвЛИіУїЯдЕФЁАВЙГЅЁБВйзїЃЌгУгкВЩМЏдкЕквЛВЈДЮНјааЪБЛЙЮДдкЪ§ОнПтжаОЭаїЕФЪ§ОнЃЌЕкШ§ВЈДЮдђЪЧзюКѓЕФЁАЭаЕзЁБВйзїЃЌЫќЕФЪБМфЦЋвЦЛсИќДѓЃЌФПЕФЪЧзюКѓвЛДЮВЙТМЪ§ОнЃЌБЃжЄЪ§ОнЕФЭъећадЁЃ
ЖрВЈДЮВЩМЏЕФЗНАИЛсЕМжТГіЯжжиИДЪ§ОнЃЌвђДЫашвЊНјааШЅжиВйзїЃЌЮвУЧАбетИіЙЄзїНЛИјСЫСїДІРэзщМўЃЌРћгУSpark
StreamingЕФcheckpointЛњжЦЃЌЮвУЧЛсдкСїЩЯcacheзЁНќвЛЖЮЪБМфФкЕФЪ§ОнзїЮЊШЅжиЪБЕФБШЖдЪ§ОнЃЌЕБГЌЙ§ЩшЖЈЕФTTLЃЈTime-To-LiveЃЉЪБЃЌЪ§ОнЛсДгСїЩЯвЦГ§ЁЃ |








