| БрМЭЦМі: |
| БОЮФРДздгкЭјТчЃЌБОЮФжївЊДгHbaseЕФЪ§ОнФЃаЭЁЂЯЕЭГМмЙЙЁЂдЫЮЌКЭИпПЩгУЕШСљИіЗНУцНщЩмСЫHbaseдРэЁЃ |
|
вЛЁЂHBaseМђНщ
HbaseЪЧЪВУД
HBaseЪЧвЛжжЙЙНЈдкHDFSжЎЩЯЕФЗжВМЪНЁЂУцЯђСаЁЂЖрАцБОЁЂЗЧЙиЯЕаЭЕФЪ§ОнПтЁЃдкашвЊЪЕЪБЖСаДЁЂЫцЛњЗУЮЪГЌДѓЙцФЃЪ§ОнМЏЪБЃЌПЩвдЪЙгУHBaseЁЃHBase
ЪЧGoogle Bigtable ЕФПЊдДЪЕЯжЁЃ
HBaseЕФЬиЕу
ДѓЃКвЛИіБэПЩвдгаЩЯвкааЃЌЩЯАйЭђСаЁЃ
УцЯђСаЃКУцЯђСаЃЈзщЃЉЕФДцДЂКЭШЈЯоПижЦЃЌСаЃЈзщЃЉЖРСЂМьЫїЁЃ
ЯЁЪшЃКЖдгкЮЊПеЃЈNULLЃЉЕФСаЃЌВЂВЛеМгУДцДЂПеМфЃЌвђДЫЃЌБэПЩвдЩшМЦЕФЗЧГЃЯЁЪшЁЃ
ЮоФЃЪНЃКУПвЛааЖМгавЛИіПЩвдХХађЕФжїМќКЭШЮвтЖрЕФСаЃЌСаПЩвдИљОнашвЊЖЏЬЌдіМгЃЌЭЌвЛеХБэжаВЛЭЌЕФааПЩвдгаНиШЛВЛЭЌЕФСаЁЃ
Ъ§ОнЖрАцБОЃКУПИіЕЅдЊжаЕФЪ§ОнПЩвдгаЖрИіАцБОЃЌФЌШЯЧщПіЯТЃЌАцБОКХздЖЏЗжХфЃЌАцБОКХОЭЪЧЕЅдЊИёВхШыЪБЕФЪБМфДСЁЃ
Ъ§ОнРраЭЕЅвЛЃКHBaseжаЕФЪ§ОнЖМЪЧзжЗћДЎЃЌУЛгаРраЭЃЌДцДЂдкhbaseЩЯЕФЖМЪЧзжНкЪ§зщЁЃ
ЖўЁЂHBaseЪ§ОнФЃаЭ
HBase вдБэЕФаЮЪНДцДЂЪ§ОнЁЃБэгЩааКЭСазщГЩЁЃСаЛЎЗжЮЊШєИЩИіСазхЃЈrow
familyЃЉЃЌШчЯТЭМЫљЪОЁЃ

1) HBaseЕФТпМЪ§ОнФЃаЭ
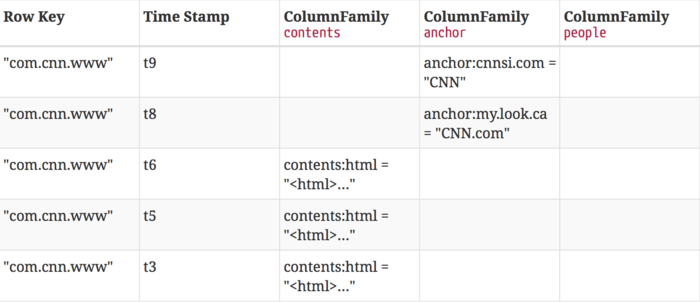
2) HBaseЕФЮяРэЪ§ОнФЃаЭ
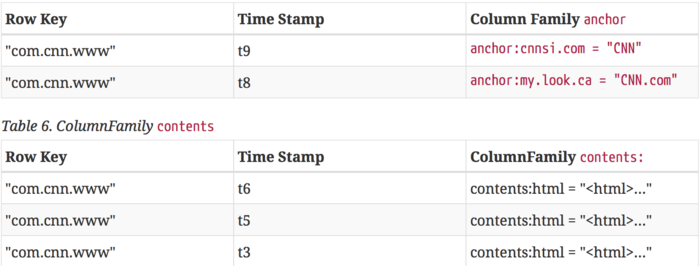
ТпМЪ§ОнФЃаЭжаПеАзcellдкЮяРэЩЯЪЧВЛДцДЂЕФЃЌвђДЫШєвЛИіЧыЧѓЮЊвЊЛёШЁt8ЪБМфЕФcontents:htmlЃЌЫћЕФНсЙћОЭЪЧПеЁЃЯрЫЦЕФЃЌШєЧыЧѓЮЊЛёШЁt9ЪБМфЕФanchor:my.look.caЃЌНсЙћвВЪЧПеЁЃЕЋЪЧЃЌШчЙћВЛжИУїЪБМфЃЌНЋЛсЗЕЛизюаТЪБМфЕФааЃЌУПИізюаТЕФЖМЛсЗЕЛи
Row Key
гы NoSQL Ъ§ОнПтвЛбљЃЌRow Key ЪЧгУРДМьЫїМЧТМЕФжїМќЁЃМИжжЗУЮЪ HBase table
жаЕФааЗНЪНЃК
1)ЭЈЙ§ЕЅИі Row Key ЗУЮЪЁЃ
2)ЭЈЙ§ Row Key ЕФ range ШЋБэЩЈУшЁЃ
3)Row Key ПЩвдЪЙШЮвтзжЗћДЎЃЈзюДѓГЄЖШЪЧ64KBЃЌЪЕМЪгІгУжаГЄЖШвЛАуЮЊ 10 ~ 100bytesЃЉЃЌдкHBase
ФкВПЃЌRow Key БЃДцЮЊзжНкЪ§зщЁЃ
Сазх
HBase БэжаЕФУПИіСаЖМЙщЪєгкФГИіСазхЁЃСазхЪЧБэЕФ Schema ЕФвЛВПЗжЃЈЖјСаВЛЪЧЃЉЃЌБиаыдкЪЙгУБэжЎЧАЖЈвхЁЃСаУћЖМвдСазхзїЮЊЧАзКЃЌР§Шч
courses:historyЁЂcourses:math ЖМЪєгк courses етИіСазхЁЃ
ЗУЮЪПижЦЁЂДХХЬКЭФкДцЕФЪЙгУЭГМЦЖМЪЧдкСазхВуУцНјааЕФЁЃдкЪЕМЪгІгУжаЃЌСазхЩЯЕФПижЦШЈЯоФмАяжњЮвУЧЙмРэВЛЭЌРраЭЕФгІгУЃЌ
Р§ШчЃЌдЪаэвЛаЉгІгУПЩвдЬэМгаТЕФЛљБОЪ§ОнЁЂвЛаЉгІгУПЩвдЖСШЁЛљБОЪ§ОнВЂДДНЈМЬГаЕФСазхЁЂ вЛаЉгІгУдђжЛдЪаэфЏРРЪ§ОнЃЈЩѕжСПЩФмвђЮЊвўЫНЕФдвђВЛФмфЏРРЫљгаЪ§ОнЃЉЁЃ
Cell
ЪБМфДСHBase жаЭЈЙ§ Row КЭ Columns ШЗЖЈЕФвЛИіДцДЂЕЅдЊГЦЮЊ CellЁЃУПИі Cell
ЖМБЃДцзХЭЌвЛЗнЪ§ОнЕФЖрИіАцБОЁЃ АцБОЭЈЙ§ЪБМфДСРДЫїв§ЃЌЪБМфДСЕФРраЭЪЧ 64 ЮЛећаЭЁЃЪБМфДСПЩвдгЩHBaseЃЈдкЪ§ОнаДШыЪБздЖЏЃЉИГжЕЃЌ
ДЫЪБЪБМфДСЪЧОЋШЗЕНКСУыЕФЕБЧАЯЕЭГЪБМфЁЃЪБМфДСвВ ПЩвдгЩПЭЛЇЯдЪОИГжЕЁЃШчЙћгІгУГЬађвЊБмУтЪ§ОнАцБОГхЭЛЃЌОЭБиаыздМКЩњГЩОпгаЮЈвЛадЕФЪБМфДСЁЃУПИі
Cell жаЃЌВЛЭЌАцБОЕФЪ§ОнАДееЪБМфЕЙађХХађЃЌМДзюаТЕФЪ§ОнХХдкзюЧАУцЁЃ
ЮЊСЫБмУтЪ§ОнДцдкЙ§ЖрАцБОдьГЩЕФЙмРэЃЈАќРЈДцДЂКЭЫїв§ЃЉИКЕЃЃЌHBase ЬсЙЉСЫСНжжЪ§ОнАцБОЛиЪеЗНЪНЁЃ
вЛЪЧБЃДцЪ§ОнЕФзюКѓ n ИіАцБОЃЌЖўЪЧБЃДцзюНќвЛЖЮЪБМфФкЕФАцБОЃЈБШШчзюНќЦпЬьЃЉЁЃгУЛЇПЩвдеыЖдУПИіСазхНјааЩшжУЁЃ
3) HBaseЮяРэДцДЂ
Table дкааЕФЗНЯђЩЯЗжИюЮЊЖрИіHRegionЃЌУПИіHRegionЗжЩЂдкВЛЭЌЕФRegionServerжаЁЃ
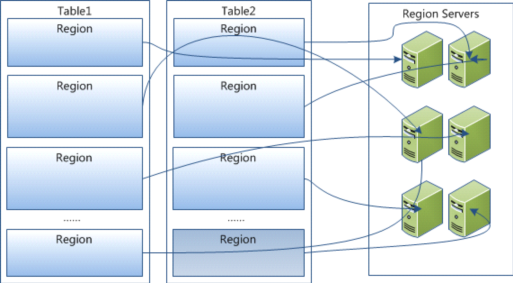
УПИіHRegionгЩЖрИіStoreЙЙГЩЃЌУПИіStoreгЩвЛИіmemStoreКЭ0ЛђЖрИіStoreFileзщГЩЃЌУПИіStoreБЃДцвЛИіColumns
Family

Ш§ЁЂHBaseЯЕЭГМмЙЙ
1) HBaseМмЙЙЭМ

ДгHBaseЕФМмЙЙЭМЩЯПЩвдПДГіЃЌHBaseжаЕФзщМўАќРЈClientЁЂZookeeperЁЂHMasterЁЂHRegionServerЁЂHRegionЁЂStoreЁЂMemStoreЁЂStoreFileЁЂHFileЁЂHLogЕШЃЌНгЯТРДНщЩмЫћУЧЕФзїгУЁЃ
HBaseжаЕФУПеХБэЖМЭЈЙ§ааМќАДеевЛЖЈЕФЗЖЮЇБЛЗжИюГЩЖрИізгБэЃЈHRegionЃЉЃЌФЌШЯвЛИіHRegionГЌЙ§256MОЭвЊБЛЗжИюГЩСНИіЃЌетИіЙ§ГЬгЩHRegionServerЙмРэЃЌЖјHRegionЕФЗжХфгЩHMasterЙмРэЁЃ
Client
АќКЌЗУЮЪHBaseЕФНгПкЃЌВЂЮЌЛЄcacheРДМгПьЖдHBaseЕФЗУЮЪЁЃ
Zookeeper
HBaseвРРЕZookeeperЃЌФЌШЯЧщПіЯТHBaseЙмРэZookeeperЪЕР§(ЦєЖЏЛђЙиБеZookeeper),MasterгыRegionServersЦєЖЏЪБЛсЯђZookeeperзЂВсЁЃ
БЃжЄШЮКЮЪБКђЃЌМЏШКжажЛгавЛИіmaster
ЪЕЪБМрПиRegion serverЕФЩЯЯпКЭЯТЯпаХЯЂЁЃВЂЪЕЪБЭЈжЊИјmaster
ДцДЂHBaseЕФschemaКЭtableдЊЪ§Он
HMaster
ЮЊRegion serverЗжХфregion
ИКд№Region serverЕФИКдиОљКт
ЗЂЯжЪЇаЇЕФRegion serverВЂжиаТЗжХфЦфЩЯЕФregionЁЃ
ДІРэschemaИќаТЧыЧѓЁЃ
HRegionServer
ЮЌЛЄmasterЗжХфИјЫћЕФregionЃЌДІРэЖдетаЉregionЕФioЧыЧѓЁЃ
ИКд№ЧаЗже§дкдЫааЙ§ГЬжаБфЕФЙ§ДѓЕФregionЁЃ
зЂвтЃКclientЗУЮЪhbaseЩЯЕФЪ§ОнЪБВЛашвЊmasterЕФВЮгыЃЌвђЮЊЪ§ОнбАжЗЗУЮЪzookeeperКЭregion
serverЃЌЖјЪ§ОнЖСаДЗУЮЪregion serverЁЃmasterНіНіЮЌЛЄtableКЭregionЕФдЊЪ§ОнаХЯЂЃЌЖјtableЕФдЊЪ§ОнаХЯЂБЃДцдкzookeeperЩЯЃЌвђДЫmasterИКдиКмЕЭЁЃ
HRegion
tableдкааЕФЗНЯђЩЯЗжИєЮЊЖрИіRegionЁЃRegionЪЧHBaseжаЗжВМЪНДцДЂКЭИКдиОљКтЕФзюаЁЕЅдЊЃЌМДВЛЭЌЕФregionПЩвдЗжБ№дкВЛЭЌЕФRegion
ServerЩЯЃЌЕЋЭЌвЛИіRegionЪЧВЛЛсВ№ЗжЕНЖрИіserverЩЯЁЃ
RegionАДДѓаЁЗжИєЃЌУПИіБэвЛАуЪЧжЛгавЛИіregionЁЃЫцзХЪ§ОнВЛЖЯВхШыБэЃЌregionВЛЖЯдіДѓЃЌЕБregionЕФФГИіСазхДяЕНвЛИіуажЕЪБОЭЛсЗжГЩСНИіаТЕФregionЁЃ
УПИіregionгЩвдЯТаХЯЂБъЪЖЃК< БэУћ,startRowkey,ДДНЈЪБМф>
гЩФПТМБэ(-ROOT-КЭ.META.)МЧТМИУregionЕФendRowkey
Store
УПвЛИіregionгЩвЛИіЛђЖрИіstoreзщГЩЃЌжСЩйЪЧвЛИіstoreЃЌhbaseЛсАбвЛЦ№ЗУЮЪЕФЪ§ОнЗХдквЛИіstoreРяУцЃЌМДЮЊУПИі
ColumnFamilyНЈвЛИіstoreЃЌШчЙћгаМИИіColumnFamilyЃЌвВОЭгаМИИіStoreЁЃвЛИіStoreгЩвЛИіmemStoreКЭ0Лђеп
ЖрИіStoreFileзщГЩЁЃ HBaseвдstoreЕФДѓаЁРДХаЖЯЪЧЗёашвЊЧаЗжregion
MemStore
memStore ЪЧЗХдкФкДцРяЕФЁЃБЃДцаоИФЕФЪ§ОнМДkeyValuesЁЃЕБmemStoreЕФДѓаЁДяЕНвЛИіЗЇжЕЃЈФЌШЯ128MBЃЉЪБЃЌmemStoreЛсБЛflushЕНЮФ
МўЃЌМДЩњГЩвЛИіПьееЁЃФПЧАhbase ЛсгавЛИіЯпГЬРДИКд№memStoreЕФflushВйзїЁЃ
StoreFile
memStoreФкДцжаЕФЪ§ОнаДЕНЮФМўКѓОЭЪЧStoreFileЃЌStoreFileЕзВуЪЧвдHFileЕФИёЪНБЃДцЁЃ
HFile
HBaseжаKeyValueЪ§ОнЕФДцДЂИёЪНЃЌHFileЪЧHadoopЕФ ЖўНјжЦИёЪНЮФМўЃЌЪЕМЪЩЯStoreFileОЭЪЧЖдHfileзіСЫЧсСПМЖАќзАЃЌМДStoreFileЕзВуОЭЪЧHFile
HFileЕФДцДЂИёЪНШчЯТЃК

HFileгЩЖрИіData BlockЁЂMeta BlockЁЂFileInfoЁЂData IndexЁЂMeta
IndexЁЂTrailerзщГЩЃЌЦфжаData BlockЪЧHBaseЕФзюаЁДцДЂЕЅдЊЃЌдкЧАЮФжаЬсЕНЕФBlockCacheОЭЪЧЛљгкData
BlockЕФЛКДцЕФЁЃвЛИіData BlockгЩвЛИіФЇЪ§КЭвЛЯЕСаЕФKeyValue(Cell)зщГЩЃЌФЇЪ§ЪЧвЛИіЫцЛњЕФЪ§зжЃЌгУгкБэЪОетЪЧвЛИіData
BlockРраЭЃЌвдПьЫйМрВтетИіData BlockЕФИёЪНЃЌЗРжЙЪ§ОнЕФЦЦЛЕЁЃData BlockЕФДѓаЁПЩвддкДДНЈColumn
FamilyЪБЩшжУ(HColumnDescriptor.setBlockSize())ЃЌФЌШЯжЕЪЧ64KBЃЌДѓКХЕФBlockгаРћгкЫГађScanЃЌаЁКХBlockРћгкЫцЛњВщбЏЃЌвђЖјашвЊШЈКтЁЃMetaПщЪЧПЩбЁЕФЃЌFileInfoЪЧЙЬЖЈГЄЖШЕФПщЃЌЫќМЭТМСЫЮФМўЕФвЛаЉMetaаХЯЂЃЌР§ШчЃКAVG_KEY_LEN,
AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEYЕШЁЃData
IndexКЭMeta IndexМЭТМСЫУПИіDataПщКЭMetaПщЕФЦфЪЕЕуЁЂЮДбЙЫѕЪБДѓаЁЁЂKey(Ц№ЪМRowKeyЃП)ЕШЁЃTrailerМЭТМСЫFileInfoЁЂData
IndexЁЂMeta IndexПщЕФЦ№ЪМЮЛжУЃЌData IndexКЭMeta IndexЫїв§ЕФЪ§СПЕШЁЃЦфжаFileInfoКЭTrailerЪЧЙЬЖЈГЄЖШЕФЁЃ
HFileРяУцЕФУПИіKeyValueЖдОЭЪЧвЛИіМђЕЅЕФbyteЪ§зщЁЃЕЋЪЧетИіbyteЪ§зщРяУцАќКЌСЫКмЖрЯюЃЌВЂЧвгаЙЬЖЈЕФНсЙЙЁЃЮвУЧРДПДПДРяУцЕФОпЬхНсЙЙЃК

ЩЯЭМПЩжЊЃЌПЊЪМЪЧСНИіЙЬЖЈГЄЖШЕФЪ§жЕЃЌЗжБ№БэЪОkeyЕФГЄЖШКЭalueЕФГЄЖШЁЃНєНгзХЪЧKey,ПЊЪМЪЧЙЬЖЈГЄЖШЕФЪ§жЕЃЌБэЪОRowKeyЕФГЄЖШЃЌНєНгзХЪЧRowKeyЃЌШЛКѓЪЧЙЬЖЈГЄЖШЕФЪ§жЕЃЌБэЪОFamilyЕФГЄЖШЃЌШЛКѓЪЧFamily,НгзХЪЧQualifierЃЌШЛКѓЪЧСНИіЙЬЖЈГЄЖШЕФЪ§жЕЃЌБэЪОTime
StampКЭKey Type(Put/Delete)ЁЃValueВПЗжУЛгаФЧУДИДдгЕФНсЙЙЃЌОЭЪЧДПДтЕФЖўНјжЦЪ§ОнЁЃ
HLog
HLog(WAL log)ЃКWALвтЮЊwrite ahead logЃЌгУРДзіджФбЛжИДЪЙгУЃЌHLogМЧТМЪ§ОнЕФЫљгаБфИќЃЌвЛЕЉregion
server хДЛњЃЌОЭПЩвдДгlogжаНјааЛжИДЁЃ
HLogЮФМўОЭЪЧвЛИіЦеЭЈЕФHadoop Sequence FileЃЌ
Sequence FileЕФvalueЪЧkeyЪБHLogKeyЖдЯѓЃЌЦфжаМЧТМСЫаДШыЪ§ОнЕФЙщЪєаХЯЂЃЌГ§СЫtableКЭregionУћзжЭтЃЌЛЙЭЌЪБАќРЈsequence
numberКЭtimestampЃЌtimestampЪЧаДШыЪБМфЃЌsequence numberЕФЦ№ЪМжЕЮЊ0ЃЌЛђепЪЧзюНќвЛДЮДцШыЮФМўЯЕЭГжаЕФsequence
numberЁЃ Sequence FileЕФvalueЪЧHBaseЕФKeyValueЖдЯѓЃЌМДЖдгІHFileжаЕФKeyValueЁЃ

ЩЯЭМжаЪЧHLogЮФМўЕФНсЙЙЃЌЦфЪЕHLogЮФМўОЭЪЧвЛИіЦеЭЈЕФHadoop Sequence FileЃЌSequence
FileЕФKeyЪЧHLogKeyЖдЯѓЃЌHLogKeyжаМЧТМСЫаДШыЪ§ОнЕФЙщЪєаХЯЂЃЌГ§СЫtableКЭRegionУћзжЭтЃЌЭЌЪБЛЙАќРЈsequence
numberКЭtimestamp,timestampЪЧЁБаДШыЪБМфЁБЃЌsequence number
ЕФЦ№ЪМжЕЮЊ0ЃЌЛђепЪЧзюНќвЛДЮДцШыЮФМўЯЕЭГжаЕФsequence numberЁЃ
HLog Sequence File ЕФValueЪЧHBaseЕФKeyValueЖдЯѓАКЃЌМДЖдгІHFileжаЕФKeyValueЁЃ
2) HRegionЖЈЮЛ

ЭЈЙ§zkРяЕФЮФМў/hbase/rsЕУЕН-ROOT-БэЕФЮЛжУЁЃ-ROOT-БэжЛгавЛИіregionЁЃ
ЭЈЙ§-ROOT-БэВщев.META.БэЕФЕквЛИіБэжаЯргІЕФregionЕФЮЛжУЁЃЦфЪЕ-ROOT-БэЪЧ.META.БэЕФЕквЛИіregionЃЛ.META.БэжаЕФУПвЛИіregion
дк-ROOT-БэжаЖМЪЧвЛааМЧТМЁЃ
ЭЈЙ§.META.БэевЕНЫљвЊЕФгУЛЇБэregionЕФЮЛжУЁЃгУЛЇБэжаЕФУПИіregionдк.META.БэжаЖМЪЧвЛааМЧТМЁЃ
-ROOT-БэгРдЖВЛЛсБЛЗжИєЮЊЖрИіregionЃЌБЃжЄСЫзюЖрашвЊШ§ДЮЬјзЊЃЌОЭФмЖЈЮЛЕНШЮвтЕФregionЁЃclientЛсНЋВщбЏЕФЮЛжУ
аХЯЂБЃДцЛКДцЦ№РДЃЌЛКДцВЛЛсжїЖЏЪЇаЇЃЌвђДЫШчЙћclientЩЯЕФЛКДцШЋВПЪЇаЇЃЌдђашвЊНјаа6ДЮЭјТчРДЛиЃЌВХФмЖЈЮЛЕНе§ШЗЕФregionЃЌЦфжаШ§ДЮгУРДЗЂЯж
ЛКДцЪЇаЇЃЌСэЭтШ§ДЮгУРДЛёШЁЮЛжУаХЯЂЁЃ
ЬсЪОЃК
-ROOT-БэЃКБэАќКЌ.META.БэЫљдкЕФregionСаБэЃЌИУБэжЛгавЛИіRegion;ZookeeperжаМЧТМСЫ-ROOT-БэЕФlocation
.META.БэЃКБэАќКЌЫљгаЕФгУЛЇПеМфregionСаБэЃЌвдМАRegion ServerЕФЗўЮёЦїЕижЗ
hbase:metaБэЃКИпАцБОжавбОЩсЦњСЫROOTКЭMETAБэСЫЃЌВЩгУСЫетИіБэ
ЫФЁЂHBaseЙЄзїСїГЬ
HBaseЕФСїГЬЭМ

Client
ЪзЯШЕБвЛИіЧыЧѓВњЩњЪБЃЌHBase ClientЪЙгУRPC(дЖГЬЙ§ГЬЕїгУ)ЛњжЦгыHMasterКЭHRegionServerНјааЭЈаХЃЌЖдгкЙмРэРрВйзїЃЌClientгыHMasterНјааRPC;ЖдгкЪ§ОнЖСаДВйзїЃЌClientгыHRegionServerНјааRPCЁЃ
Zookeeper
HBase ClientЪЙгУRPC(дЖГЬЙ§ГЬЕїгУ)ЛњжЦгыHMasterКЭHRegionServerНјааЭЈаХЃЌЕЋШчКЮбАжЗФиЃПгЩгкZookeeperжаДцДЂСЫ-ROOT-БэЕФЕижЗКЭHMasterЕФЕижЗЃЌЫљвдашвЊЯШЕНZookeeperЩЯНјаабАжЗЁЃ
HRegionServerвВЛсАбздМКвдEphemeralЗНЪНзЂВсЕНZookeeperжаЃЌЪЙHMasterПЩвдЫцЪБИажЊЕНИїИіHRegionServerЕФНЁПЕзДЬЌЁЃДЫЭтЃЌZookeeperвВБмУтСЫHMasterЕФЕЅЕуЙЪеЯЁЃ
HMaster
ЕБгУЛЇашвЊНјааTableКЭRegionЕФЙмРэЙЄзїЪБЃЌОЭашвЊКЭHMasterНјааЭЈаХЁЃHBaseжаПЩвдЦєЖЏЖрИіHMaster,ЭЈЙ§ZookeeperЕФMaster
EletionЛњжЦБЃжЄзмгавЛИіMasterдЫааЁЃ
ЙмРэгУЛЇЖдTableЕФдіЩОИФВщВйзї
ЙмРэHRegionServerЕФИКдиОљКтЃЌЕїећRegionЕФЗжВМ
дкRegion SplitКѓЃЌИКд№аТRegionЕФЗжХф
дкHRegionServerЭЃЛњКѓЃЌИКд№ЪЇаЇHRegionServerЩЯЕФRegionsЧЈвЦ
HRegionServer
ЕБгУЛЇашвЊЖдЪ§ОнНјааЖСаДВйзїЪБЃЌашвЊЗУЮЪHRegionServerЁЃHRegionServerДцШЁвЛИізгБэЪБЃЌЛсДДНЈвЛИіHRegionЖдЯѓЃЌШЛКѓЖдБэЕФУПИіСазхДДНЈвЛИіStoreЪЕР§ЃЌУПИіStoreЖМЛсгавЛИі
MemStoreКЭ0ИіЛђЖрИіStoreFileгыжЎЖдгІЃЌУПИіStoreFileЖМЛсЖдгІвЛИіHFileЃЌ
HFileОЭЪЧЪЕМЪЕФДцДЂЮФМўЁЃвђДЫЃЌвЛИіHRegionгаЖрЩйИіСазхОЭгаЖрЩйИіStoreЁЃ вЛИіHRegionServerЛсгаЖрИіHRegionКЭвЛИіHLogЁЃ
зЂвтЃКHStoreДцДЂгЩСНВПЗжзщГЩЃКMemStoreКЭStoreFilesЁЃ MemStoreЪЧSorted
Memory Buffer,гУЛЇ аДШыЪ§ОнЪзЯШ ЛсЗХдкMemStore,ЕБMemStoreТњСЫвдКѓЛсFlushГЩвЛИі
StoreFileЃЈЪЕМЪДцДЂдкHDHSЩЯЕФЪЧHFileЃЉЃЌЕБStoreFileЮФМўЪ§СПдіГЄЕНвЛЖЈЗЇжЕЃЌОЭЛсДЅЗЂCompactКЯВЂВйзїЃЌВЂНЋЖрИіStoreFileКЯВЂГЩвЛИіStoreFileЃЌКЯВЂЙ§ГЬжаЛсНјааАцБОКЯВЂКЭЪ§ОнЩОГ§ЃЌвђДЫПЩвдПДГіHBaseЦфЪЕжЛгадіМгЪ§ОнЃЌЫљгаЕФИќаТКЭЩОГ§ВйзїЖМЪЧдкКѓајЕФcompactЙ§ГЬжаНјааЕФЃЌетЪЙЕУгУЛЇЕФ
ЖСаДВйзї*жЛвЊНјШыФкДцжаОЭПЩвдСЂМДЗЕЛиЃЌБЃжЄСЫHBase I/OЕФИпадФмЁЃ
ЮхЁЂHBaseЕФИпПЩгУ
HDFSЛњМмЪЖБ№ВпТдЃКЕБЪ§ОнЮФМўЫ№ЛЕЪБЃЌЛсевЯрЭЌЛњМмЩЯБИЗнЕФЪ§ОнЮФМўЃЌШчЙћЯрЭЌЛњМмЩЯЕФЪ§ОнЮФМўвВЫ№ЛЕЛсевВЛЭЌЛњМмБИЗнЪ§ОнЮФМўЁЃ
HBaseЕФRegionПьЫйЛжИДЃКЕБregionserverЫ№ЛЕЪБЃЌmasterЛсЖдИУregionserverЩЯЕФregionНјаажиаТЗжХфЃЌЧЈвЦЕНЦфЫћПЩгУЕФregionserverЩЯВЂЛжИДregionЁЃ
MasterНкЕуЕФHAЛњжЦЃКMasterЮЊвЛжїЖрБИЁЃЕБMasterжїНкЕухДЛњКѓЃЌЪЃЯТЕФБИНкЕуЭЈЙ§бЁОйЃЌВњЩњжїНкЕуЁЃ
СљЁЂHBaseдЫЮЌ
ЪБжгЭЌВН
ЪжЖЏmajorcompact
region holeаоИД
region overlapаоИД
ЖСаДМЏШКХфжУвЊЧјЗж
memstore flushЪБЛњ |








