| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌжївЊЮЊЖдHBase
МђНщЃЌHBase Ъ§ОнФЃаЭМАЮяРэФЃаЭЃЌHBase МмЙЙМАЙЄзїдРэЁЃ
|
|
вЛЁЂHBase МђНщ
1.HBase ИХЪі
HBase ЪЧвЛИіЙЙНЈдкHDFSжЎЩЯЕФЃЌЗжВМЪНЕФЁЂУцЯђСаЕФПЊдДЪ§ОнПт
HBase ЪЧ Google BigTableЕФПЊдДЪЕЯжЃЌЫќжївЊгУгкДцДЂКЃСПЪ§Он
ИіШЫРэНтЃК
ЗжВМЪНЃКВЩгУЗжЖјжЮжЎЕФЫМЯыЃЌБШШчЫЕЮвУЧвЊНЋ10ИіGЕФЪ§ОнШЋВПаДШыЕНHBaseЃЌЖдгкетбљЕФвЛИіШЮЮёЮвУЧПЩвдЭЈЙ§10ИіНкЕуРДДІРэЃЈВЂааДІРэЃЉЃЌетбљПЩвдДѓДѓЕФЬсИпжДаааЇТЪЁЃ
УцЯђСаЃКвЛИіБэжаЪЧгаКмЖрааКмЖрСаЃЌУцЯђСаЕФДцДЂОЭЪЧНЋЖрИіСаДцДЂдквЛПщЃЌHBaseРяЪЧЭЈЙ§СазхРДзщжЏЕФЃЌЪЕМЪПЊЗЂжаЮвУЧВщбЏПЩФмжЛЛсВщбЏФГМИИіСаЃЌУцЯђСаДцДЂКѓЃЌЛсМѕЩйДХХЬКЭЭјТчIOЕФПЊЯњДгЖјЬсИпаЇТЪЁЃУцЯђСаЪЧЮоФЃЪНЕФЃЌМДСаПЩвдИљОнЪЕМЪЧщПіШЮвтЬэМгЁЃ
2.HBase ЕФЬиЕу
(1).ДѓЃКвЛИіБэПЩвдгаЩЯАйЭђЁЂЩЯАйвкааСаЃЈСаЖрЪБЃЌВхШыБфТ§ЃЉ
(2).УцЯђСаЃКЪ§ОнЙЙГЩЪЧСазхЃЌСазхжаАќКЌNИіСа
(3).ЯЁЪшЃКдкHBaseжаСаЕФжЕЮЊnullЪБЃЌЪЧВЛеМДцДЂПеМфЕФЃЌЖјЙиЯЕаЭЪ§ОнПтеМгУ
(4).Ъ§ОнРраЭЕЅвЛЃКHBase жаЕФЪ§ОнРраЭжЛгавЛжжString
(5).ЮоФЃЪНЃКУПааЪ§ОнЖдгІЕФСаПЩвдВЛЯрЭЌЃЌДДНЈБэЪБВЛашвЊжИЖЈСаЃЌВхШыЪ§ОнЪБСаПЩвдШЮвтЬэМг
(6).Ъ§ОнЖрАцБОЃКСажаЕФЪ§ОнПЩвдгаЖрИіАцБОЃЌВщбЏЪБПЩвдЭЈЙ§жИЖЈАцБОКХЛёШЁЃЈАцБОКХВЛЭЌЃЌЛёШЁЕНЕФЪ§ОнВЛЭЌЃЉ
3.HBase гы RDBMSЖдБШ
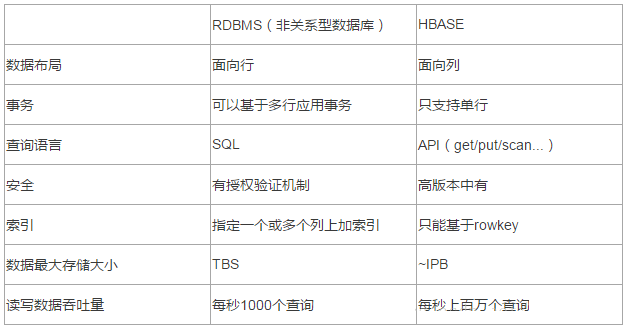
ДЋЭГЪ§ОнПтгіЕНЕФЮЪЬтЃК
1ЃЉЪ§ОнСПКмДѓЕФЪБКђЮоЗЈДцДЂ
2ЃЉУЛгаКмКУЕФБИЗнЛњжЦ
3ЃЉЪ§ОнДяЕНвЛЖЈЪ§СППЊЪМЛКТ§ЃЌКмДѓЕФЛАЛљБОЮоЗЈжЇГХ
HBASEгХЪЦЃК
1ЃЉЯпадРЉеЙЃЌЫцзХЪ§ОнСПдіЖрПЩвдЭЈЙ§НкЕуРЉеЙНјаажЇГХ
2ЃЉЪ§ОнДцДЂдкhdfsЩЯЃЌБИЗнЛњжЦНЁШЋ
3ЃЉЭЈЙ§zookeeperаЕїВщевЪ§ОнЃЌЗУЮЪЫйЖШПщЁЃ
4.HBase гы HDFS ЧјБ№
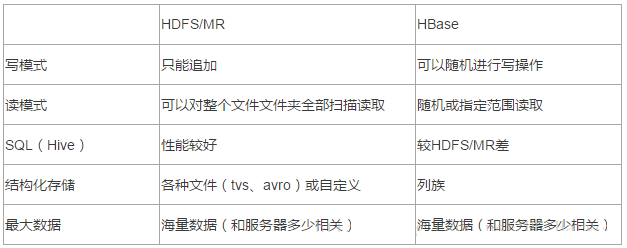
ЖўЁЂHBase Ъ§ОнФЃаЭМАЮяРэФЃаЭ
1.Ъ§ОнФЃаЭ
HBase Ъ§ОнФЃаЭЭМШчЯТ

ТпМЪ§ОнФЃаЭЖдгІЮяРэЪ§ОнФЃаЭ
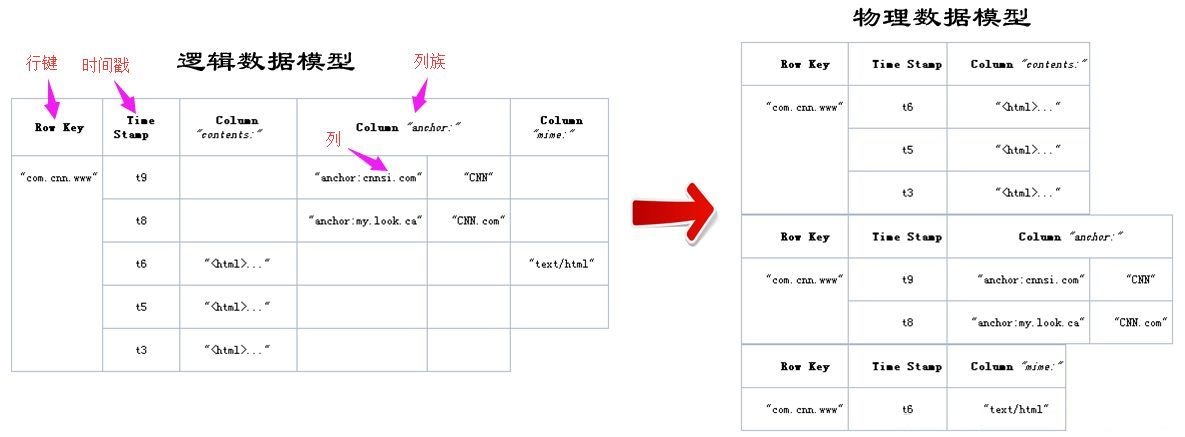
HBase КЫаФЪѕгяНщЩм
Row KeyЃЈааНЁЃЉ
гыnosqlЪ§ОнПтУЧвЛбљ,row keyЪЧгУРДМьЫїМЧТМЕФжїМќЁЃЗУЮЪHBASE tableжаЕФааЃЌжЛгаШ§жжЗНЪНЃК
1.ЭЈЙ§ЕЅИіrow keyЗУЮЪ
2.ЭЈЙ§row keyЕФrangeЃЈе§дђЃЉ
3.ШЋБэЩЈУш
row keyааМќ (Row key)ПЩвдЪЧШЮвтзжЗћДЎ(зюДѓГЄЖШ ЪЧ 64KBЃЌЪЕМЪгІгУжаГЄЖШвЛАуЮЊ
10-100bytes)ЃЌдкHBASEФкВПЃЌrow keyБЃДцЮЊзжНкЪ§зщЁЃДцДЂЪБЃЌЪ§ОнАДееrow keyЕФзжЕфађ(byte
order)ХХађДцДЂЁЃЩшМЦkeyЪБЃЌвЊГфЗжХХађДцДЂетИіЬиадЃЌНЋОГЃвЛЦ№ЖСШЁЕФааДцДЂЗХЕНвЛЦ№ЁЃ(ЮЛжУЯрЙиад)
Columns FamilyЃЈСазхЃЉ
СаДи ЃКHBASEБэжаЕФУПИіСаЃЌЖМЙщЪєгкФГИіСазхЃЈБэжаЕФУПИіСаЖМБЃДцЕНФГвЛИіЮФМўжаЃЌМДвЛИіСазхЖдгІвЛИіЮФМўЃЉЁЃСазхЪЧБэЕФschemaЕФвЛВП
Зж(ЖјСаВЛЪЧ)ЃЌБиаыдкЪЙгУБэжЎЧАЖЈвхЁЃСаУћЖМвдСазхзїЮЊЧАзКЁЃР§Шч courses:historyЃЌcourses:mathЖМЪєгкcourses
етИіСазхЁЃ
CellЃЈСаЃЉ
гЩ{row key, columnFamily, version} ЮЈвЛШЗЖЈЕФЕЅдЊЁЃcellжа
ЕФЪ§ОнЪЧУЛгаРраЭЕФЃЌШЋВПЪЧзжНкТыаЮЪНДцДЂЁЃ
ЙиМќзжЃКЮоРраЭЁЂзжНкТы
Time StampЃЈЪБМфДСЃЉ
hbase жа УПБЃДцвЛЬѕЪ§ОнЃЌЫќЛсФЌШЯЮЊЩњГЩвЛИіЪБМфДСЃЌвВПЩвдздМКЩшжУЁЃУПИі cellжаЃЌВЛЭЌАцБОЕФЪ§ОнАДееЪБМфЕЙађХХађЃЌМДзюаТЕФЪ§ОнХХдкзюЧАУц
2.ЮяРэФЃаЭ
ЖдгкHBase ЕФЮяРэФЃаЭЮвУЧЗжБ№ДгTableЕФЗжИюЁЂRegionЕФВ№ЗжЁЂRegionЕФЗжВМЃЌRegionЕФЙЙГЩЫФИіВПЗжНщЩмЃЌЯТЭМЮЊHBaseЕФЮяРэФЃаЭЭМ
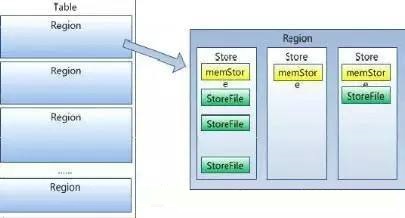
TableЕФЗжИю
Table жаЕФЫљгаааЖМАДее rowkey ЕФзжЕфађХХСаЃЌTable дкааЕФЗНЯђЩЯЗжИюЮЊЖрИіRegionЃЌвЛИіRegionдкЭЌвЛЪБПЬжЛФмБЛЭЌвЛИіRegionServerЙмРэЃЌRegionServerПЩвдЙмРэЖрИіRegionЃЈвЛЖдЖрЃЉ

RegionЕФВ№Зж
RegionЪЧАДДѓаЁЗжИюЕФЃЌаТДДНЈЕФБэжЛгавЛИіregionЃЈЪ§ОнЮЊПеЃЉЃЌЫцзХЪ§ОндіЖрЃЌregionВЛЖЯдіДѓЃЌЕБдіДѓЕНвЛИіЗЇжЕЪБЃЌregionОЭЛсВ№ЗжЮЊСНИіаТЕФregionЃЌжЎКѓЛсгадНРДдНЖрЕФregionЁЃ
ФЧУДregionЮЊЪВУДвЊНјааВ№ЗжФХЃПЫцзХЪ§ОндНРДдНЖрЃЌregionдНРДдНЖрЃЌФЧУДЖдregionЕФЙмРэОЭБШНЯТщЗГЃЌдкЮвУЧЕФДѓЪ§ОнЛЗОГЯТЃЌОГЃЛсУцСйДѓСПЕФЪ§ОнДІРэЃЌВ№ЗжregionЪЧЮЊСЫВЂааДІРэЃЌЬсИпаЇТЪЁЃ
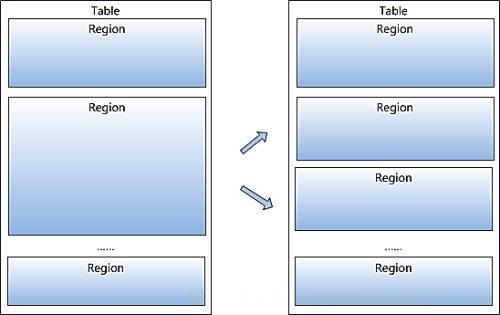
Region ЕФЗжВМ
Region ЪЧ HBase жаЗжВМЪНДцДЂКЭИКдиОљКтЕФзюаЁЕЅдЊЃЌВЛЭЌЕФRegionЗжВМЕНВЛЭЌЕФRegionServer
ЩЯЃЌШчЯТЭМTable1 ЁЂTable2 жаОљгаЖрИіRegionЃЌетаЉRegion ЗжВМдкВЛЭЌЕФRegionServer
жа
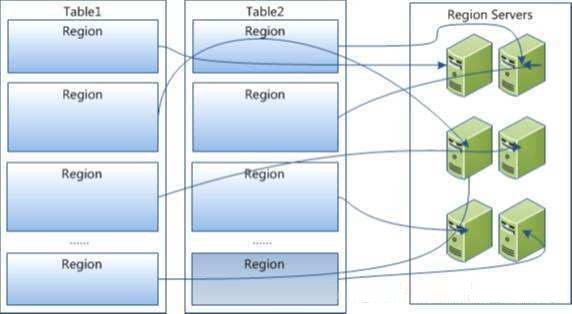
RegionЕФЙЙГЩ
RegionЫфШЛЪЧЗжВМЪНЗжВМЪНДцДЂЕФзюаЁЕЅдЊЃЌЕЋВЂВЛЪЧДцДЂЕФзюаЁЕЅдЊЃЌStoreЪЧДцДЂЕФзюаЁЕЅдЊ
RegionгЩвЛИіЛђепЖрИіStoreзщГЩЃЌУПИіStoreЛсБЃДцвЛИіColumn
FamilyЃЛУПИіStoreгжгЩвЛИіMemStore Лђ0жСЖрИіStoreFile зщГЩЃЛMemStore
ДцДЂдкФкДцжаЃЌStoreFileДцДЂдкHDFSжаЃЌЯТЭМЮЊRegion ЕФЙЙГЩЃЌЕБЮвУЧЯђHBase ВхШыЪ§ОнЪБЃЌЛсЯШДцЗХЕН
memStoreЃЈФкДцЃЉжаЃЌШЛКѓдйДгФкДцжаДцЗХЕНДХХЬЮФМўStoreFile жаЃЌДХХЬЮФМўТњСЫжЎКѓдйДцЗХЕНHDFS
жа
Ш§ЁЂHBase МмЙЙМАЙЄзїдРэ
1.HBase МмЙЙ
HBase ШдШЛВЩгУMaster/SlaveМмЙЙЃЌЫќСЅЪєгкHadoopЩњЬЌЯЕЭГЁЃHBaseНЋТпМЩЯЕФБэЛЎЗжГЩЖрИіЪ§ОнПщМДHRegionЃЌДцДЂдкHRegionServerжаЁЃ
HMasterИКд№ЙмРэЫљгаЕФHRegionServerЃЌЫќБОЩэВЂВЛДцДЂШЮКЮЪ§ОнЃЌЖјжЛЪЧДцДЂЪ§ОнЕНHRegionServerЕФгГЩфЙиЯЕЃЈдЊЪ§ОнЃЉЁЃМЏШКжаЕФЫљгаНкЕуЭЈЙ§ZookeeperНјаааЕїЃЌВЂДІРэHBaseдЫааЦкМфПЩФмгіЕНЕФИїжжЮЪЬтЁЃHBase
МмЙЙЭМШчЯТ
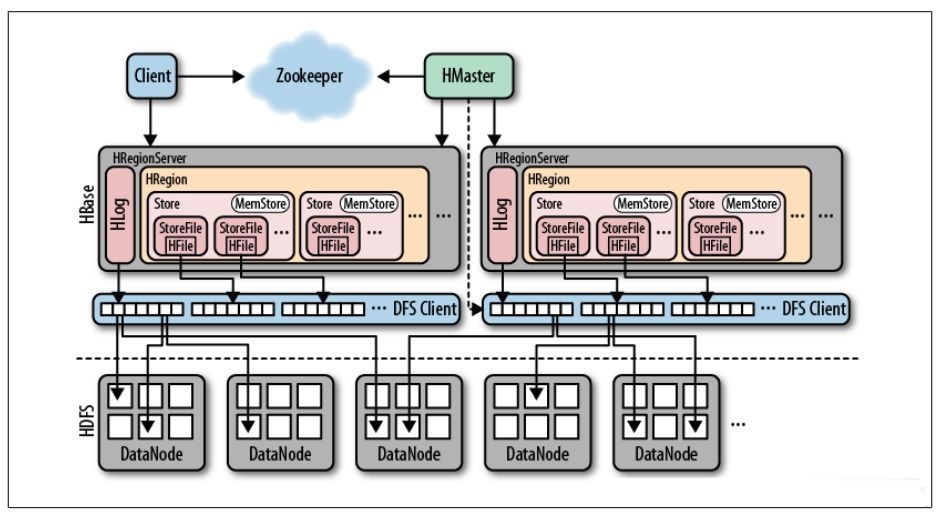
ИїИізщМўЕФзїгУШчЯТ
Client
Client Ъ§СПЮЊвЛИіЛђЖрИіЃЌHBase Client ЪЙгУ HBase ЕФ RPC ЛњжЦгыHMasterКЭHRegionServerНјааЭЈаХЁЃ
(1).ЖдгкЙмРэРрВйзїClientгыHMasterНјааRPCЭЈаХ
(2).ЖдгкЪ§ОнЖСаДВйзїClientгыHRegionServerНјааRPCЭЈаХ
Zookeeper
(1).БЃжЄМЏШКжажЛгавЛИіе§дкдЫааЕФHMasterЃЌШчЙћHMasterЙвСЫЃЌЭЈЙ§ZookeeperЕФбЁОйЛњжЦБЃжЄМЏШКжазмгавЛИіHMasterдЫааЃЌБмУтЕЅЕуЮЪЬт
(2).ЭЈЙ§НЋМЏШКИїНкЕузДЬЌаХЯЂзЂВсЕНZookeeperжаЃЌЪЙЕУHMasterПЩЫцЪБИажЊИїИіHRegionServerЕФНЁПЕзДЬЌ
HMaster
(1).ЮЊHRegionServerЗжХфRegionЃЌЕїећRegionЕФЗжВМЃЌЙмРэHRegionServerЕФИКдиОљКт
(2).HMasterжаМЧТМСЫRegionдкФФЬЈHregion serverЩЯЃЌЫќЙмРэЫљгаЕФHRegionServerВЂИцЫпHRegionServerЮЌЛЄФЧаЉRegion
(3).дкHRegion ServerхДЛњКѓЃЌНЋЪЇаЇHRegion Server ЩЯЕФRegionsЧЈвЦЕНЦфЫќЕФHRegionServer
HRegionServer
(1).ЮЌЛЄRegionЃЌДІРэВЂЯьгІетаЉRegionЕФIOЧыЧѓМАЯьгІ
(2).HRegionServerЙмРэСЫКмЖрTableЕФЗжЧјЃЌМДRegionЃЌИКд№ЖдГЌЙ§ЗЇжЕЕФRegionНјааЧаЗж(split)
HRegion
ЕББэЕФДѓаЁГЌЙ§дЄЩшжЕЕФЪБКђЃЌHRegionЛсздЖЏАДааЖдrowkeyЖдгІЕФЪ§ОнНјааВ№Зж
HLog
HLog ЪЧвЛИіЪЕЯжСЫWALЃЈWrite Ahead LogЃЉЕФдЄаДШежОРрЃЌЦфФкВПЪЧвЛИіМђЕЅЕФЫГађШежОЁЃУПИіHRegionServerЩЯЖМгавЛИіHLogЃЌРрЫЦгкmysqlжаЕФbinlogЁЃИУШежОжЛЛсзЗМгФкШнЃЌгУгкМЧТМВйзїШежОЃЌФмгУРДзіджФбЛжИДЃЈЪ§ОнЛиЙіЕНГѕЪМзДЬЌЃЉЁЃ
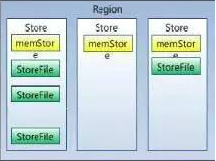
HStore
ЫќЪЧHBaseЕФДцДЂКЫаФЃЌДцДЂЕФзюаЁЕЅдЊЃЌгЩMemStoreЛђ0жСЖрИіStoreFileзщГЩЁЃ
MemStoreЪЧФкДцЛКГхЧјЃЌгУЛЇаДШыЕФЪ§ОнЪзЯШЛсЗХШыMemStoreЃЌЕБMemStoreТњСЫвдКѓЛсFlushГЩвЛИіStoreFileЃЈЕзВуЪЕЯжЪЧHFileЃЌЪЧHBaseДцДЂЪ§ОнЕФЮФМўзщжЏаЮЪНЃЉЃЌЕБStoreFileЕФЮФМўЪ§СПдіГЄЕНвЛЖЈуажЕКѓЃЌЛсДЅЗЂCompactКЯВЂВйзїЃЌНЋЖрИіStoreFilesКЯВЂГЩвЛИіStoreFileЃЌКЯВЂЙ§ГЬжаЛсНјааАцБОКЯВЂКЭЪ§ОнЩОГ§ВйзїЁЃ
вђДЫЃЌПЩвдПДГіHBaseЦфЪЕжЛгадіМгЪ§ОнЃЌЫљгаЕФИќаТКЭЩОГ§ВйзїЖМЪЧдкКѓајЕФCompactЙ§ГЬжаНјааЕФЃЌетбљЪЙЕУгУЛЇЕФаДВйзїжЛвЊНјШыФкДцОЭПЩвдСЂМДЗЕЛиЃЌБЃжЄСЫHBaseI/OЕФИпадФмЁЃ
Ъ§ОнflushЙ§ГЬШчЯТЃК
(1).ЕБmemstoreЪ§ОнДяЕНуажЕЃЈФЌШЯЪЧ64MЃЉЃЌНЋЪ§ОнЫЂЕНгВХЬЃЌНЋФкДцжаЕФЪ§ОнЩОГ§ЃЌЭЌЪБЩОГ§HlogжаЕФРњЪЗЪ§ОнЁЃ
(2).ВЂНЋЪ§ОнДцДЂЕНhdfsжаЁЃ
(3).дкhlogжазіБъМЧЕуЁЃ
Ъ§ОнCompactКЯВЂЙ§ГЬШчЯТЃК
(1).ЕБЪ§ОнПщДяЕН4ПщЃЌhmasterНЋЪ§ОнПщМгдиЕНБОЕиЃЌНјааКЯВЂ
(2).ЕБКЯВЂЕФЪ§ОнГЌЙ§256MЃЌНјааВ№ЗжЃЌНЋВ№ЗжКѓЕФregionЗжХфИјВЛЭЌЕФhregionserverЙмРэ
(3).ЕБhregionserхДЛњКѓЃЌНЋhregionserverЩЯЕФhlogВ№ЗжЃЌШЛКѓЗжХфИјВЛЭЌЕФhregionserverМгдиЃЌаоИФ.META.ЃЈHBase
ЕФФкжУБэЃЌДцДЂHBase ФкВПЕФЯЕЭГаХЯЂЁЊЁЊRegionЕФЗжВМЧщПівдМАУПИіRegionЕФЯъЯИаХЯЂЃЉ
(4).зЂвтЃКhlogЛсЭЌВНЕНhdfs
HBase ШнДэ
(1).HMaster ШнДэ
ЭЈЙ§ZookeeperЪЕЯжЃЌШчЙћHMasterЙвЕєЃЌЭЈЙ§ZookeeperЕФбЁОйЛњжЦжиаТбЁдёвЛИіаТЕФHMaster
(2).HRegionServerШнДэ
RegionServerЛсЖЈЪБЯђZookeeperЗЂЫЭаФЬјЃЌШчЙћвЛЖЮЪБМфФкЮДГіЯжаФЬјЃЌMasterНЋИУRegionServerЩЯЕФRegionжиаТЗжХфЕНЦфЫћRegionServerЩЯЁЃ
(3).ZookeeperШнДэ
zookeeperЪЧЮЊЦфЫќЗжВМЪНПђМмЬсЙЉЗжВМЪНаЕїЗўЮёЕФЃЌБОЩэВЂВЛЪЧЕЅЕуЃЌвЛАуЖМЪЧЦцЪ§ИіzkзщГЩЕФМЏШКЃЌШчЙћФГвЛИіЙвЕєКѓЃЌzkЛсЭЈЙ§бЁОйЛњжЦжиаТбЁдёвЛИіleaderЁЃ
2.HBase ЙЄзїдРэ
аДЪ§ОнСїГЬЃК
(1).clientЯђhregionserverЗЂЫЭаДЧыЧѓЁЃ
(2).RegionserverевЕНФПБъRegionЁЃ
(3).RegionЛсМьВщЪ§ОнЪЧЗёгыSchemaвЛжТЁЃ
(4).ШєПЭЛЇЖЫУЛгажИЖЈЪБМфДСЃЌФЌШЯШЁЕБЧАЪБМфЁЃ
(5).hregionserverНЋЪ§ОнаДЕНhlogЃЈwrite ahead logЃЉЁЃЮЊСЫЪ§ОнЕФГжОУЛЏКЭЛжИДЁЃ
(7).hregionserverНЋЪ§ОнаДЕНФкДцmemstoreЃЈХаЖЯMemstoreЪЧЗёашвЊFlushЮЊStorefileЮФМўЃЉ
(8).ЯьгІПЭЛЇЖЫClientЧыЧѓ
ЖСЪ§ОнСїГЬЃК
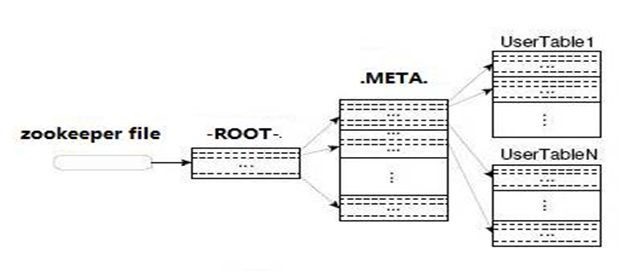
(1).ClientЗУЮЪZKЃЌВщев-ROOT-БэЃЌЛёШЁ.META.БэаХЯЂ
(2).Дг.META.БэВщевЃЌЛёШЁДцЗХФПБъЪ§ОнЕФHRegionаХЯЂЃЌДгЖјевЕНЖдгІЕФHRegionServer
(3).ЭЈЙ§HRegionServerЛёШЁашвЊВщевЕФЪ§Он
(4).RegionЛсЯШДгMemstoreжаВщбЏЃЌУќжадђЗЕЛиЃЈЯШВщMemstoreЕФКУДІЪЧдкФкДцжаЃЌВщбЏПьЃЉЁЃ
(5).ШєMemstoreУЛгаЃЌдђЩЈУшStoreFileЃЈетИіЙ§ГЬПЩФмЛсЩЈУшКмЖрStoreFIleЃЉЃЌЪ§ОнДгФкДцКЭгВХЬКЯВЂКѓЛКДцЕНФкДцжаЕФЪ§ОнПщжазюКѓЯьгІИјПЭЛЇЖЫ
ЖСШЁЪ§ОнЪБzookeeperШчКЮЖЈЮЛЕНRegionЃЌЗЕЛиИјClientЪ§ОнЃП
-ROOT-КЭ.META.ЪЧHBaseФкжУЕФСНеХБэЃЌДцДЂСЫHBaseФкВПЕФвЛаЉЯЕЭГаХЯЂЃЌ.META.ДцДЂRegionЕФдЊЪ§ОнЃЈRegionЕФЗжВМЧщПівдМАУПИіRegionЕФЯъЯИаХЯЂЃЉЃЌЫцзХHRegionЕФдіЖрЃЌ.META.БэжаЕФЪ§ОнвВЛсдіДѓЃЌВЂВ№ЗжГЩЖрИіаТЕФHRegionЁЃЮЊСЫЖЈЮЛ.META.БэжаИїИіHRegionЕФЮЛжУЃЌАб.META.БэжаЫљгаHRegionЕФдЊЪ§ОнБЃДцдк-ROOT-БэжаЁЃ
ЫљгаПЭЛЇЖЫЗУЮЪгУЛЇЪ§ОнЧАЃЌашвЊЪзЯШЗУЮЪZookeeperЛёЕУ-ROOT-ЕФЮЛжУЃЌШЛКѓЗУЮЪ-ROOT-БэЛёЕУ.META.БэЕФЮЛжУЃЌзюКѓИљОн.META.БэжаЕФаХЯЂШЗЖЈгУЛЇЪ§ОнДцЗХЕФЮЛжУЃЌВщевЕНгУЛЇЪ§ОнЃЌзюКѓЗХЛиИјClientЃЌСїГЬЭМШчЯТ
|








