| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊНВШчКЮНЋApache
Kylin ЩЯЯпгІгУвдМАKylin ЕФЦНЬЈМмЙЙдк4399ДѓЪ§ОнЦНЬЈгІгУЁЃ |
|
БГ ОА
дкПЊЪМАИР§ЗжЯэЧАЃЌЯШМђЕЅНщЩмвЛЯТ 4399 вдМА 4399 ЕФДѓЪ§ОнЭХЖг
1.4399 ЪЧжаЙњзюдчЕФКЭСьЯШЕФдкЯпанЯааЁгЮЯЗЦНЬЈЃЌШеЛюдОДя 2000
ЖрЭђ
2.4399 гЮЯЗКаЪЧ 4399 ЦьЯТЕФЪжгЮЗжЗЂЦНЬЈЃЌШеЛюЙ§ 350w
3.4399 ЕФДѓЪ§ОнЭХЖгЙцФЃдк 15 ШЫзѓгвЃЌжївЊЙЄзїФкШнЮЊгЮЯЗЭЦМіЁЂгЮЯЗЫбЫїЁЂОКМлЙуИцЃЌЖрЮЌЗжЮіЁЂДѓЪ§ОнЦНЬЈЕШЕШ
4399 Дг Kylin v1.5 АцБОПЊЪМЪЙгУЃЌЪЙгУАцБОвВЫцзХЙйЗНАцБОЕФЩ§МЖдкЩ§МЖЃЌЯжЩњВњЯЕЭГСНИіАцБОЭЌЪБдкдЫааЃКKylin
v2.0.0ЁЂKylin v2.3.0ЃЌЙВга 20 Иі Cube ЮЊЮвУЧЕФДѓЪ§ОнЦНЬЈЬсЙЉЗжЮіЗўЮёЃЌШчТЉЖЗФЃаЭЗжЮіЕШЁЃЦфжазюДѓЕФ
CubeЃЌУПЕНжмФЉашвЊЙЙНЈ 2.5 вкЬѕЕФЪ§ОнЃЌ18 ИіЮЌЖШЃЌ9 ИіжИБъЃЌЙЙНЈКФЪБ 80 ЗжжгзѓгвЁЃKylin
ЕФв§ШыЪЙгУжївЊАяЮвУЧНтОіСЫШ§ДѓЮЪЬтЃК
ЬсЙЉ ANSI-SQL НгПкЃЌШУЭГМЦЗжЮігЩЗБдгБфЕУМђЕЅЁЃ
1.НтОіПкОЖВЛвЛжТЮЪЬтЁЃдЯШУПИіашЧѓЙ§РДЃЌашвЊжиаДЭГМЦТпМЃЌБраДШЫдБВЛЭЌОЭЛсЕМжТПкОЖВЛвЛжТЃЌЪ§ОнГіШыНЯДѓЃЌаЃзМЙЄзїСПДѓЁЃЯждкЭГвЛећРэвЛеХЪТЪЕБэЃЌЯрЙиашЧѓЭЈЙ§
SQL ВщбЏЭЌвЛеХБэЃЌПкОЖвЛжТЃЌаЃзММђвзЁЃ
2.діМгЮЌЖШЛђепжИБъЪБЃЌДѓДѓНЕЕЭСЫЫљашЙЄзїСПЁЃ
3.НтОіетШ§ДѓЮЪЬтЕФЭЌЪБЃЌKylin ЛЙБЃжЄСЫПьЫйЕФЯьгІЪБМфЁЃKylin
ЮЌЖШзщКЯЩшМЦЕФКЯРэадЬиЕуЃЌВЛНіФмЙЛМѕЩй Cube ЙЙНЈЪБМфЃЌЛЙФмШУЮвУЧЛёЕУКЯРэЕФВщбЏЯьгІЪБМфЁЃЯжЩњВњзюДѓЕФЪТЪЕБэЃЌАќКЌ
18 ИіЮЌЖШЁЂ9 ИіжИБъЃЌ95% ЕФ SQL Фмдк 3 УывдФкЗЕЛие§ШЗНсЙћЁЃ
4399 ДѓЪ§ОнЦНЬЈНщЩм
ЫцзХвЕЮёЕФдіМгЃЌ4399 ЕФЪ§ОнЙцФЃГЪБЌеЈЪНдіГЄЃЌЯывЊЭъећЕФЪеМЏЪ§ОнЃЌВЂДгЪ§ОнжаЭкОђГіЩЬвЕМлжЕЃЌДѓЪ§ОнЦНЬЈЕФв§ШыЪЦдкБиааЁЃЮвЫОдкЧАМИФъПЊЪМв§ШыДѓЪ§ОнЦНЬЈЃЌЪЙгУСїааЕФПЊдДЕФзщМўЃЌДюНЈГіЗћКЯЙЋЫОвЕЮёашЧѓЕФЦНЬЈЁЃЮЊСЫБЃжЄЪ§ОнТфХЬУнЕШВйзїЁЂаДШыЯћЗбЕФ
Exactly-OneЃЌЮвУЧЯргІЕиПЊЗЂвЛаЉаЁЙЄОпЁЃ

ЗЂеЙЕНЯждкЃЌЙЋЫОДѓЪ§ОнЦНЬЈвбОгЕга 50 ЖрИіНкЕуЃЌжївЊжАд№АќКЌШ§ДѓПщЃК
1.ЪеМЏдЪМШежОЃЌУПЬьаТдіШежЪСПдк 5T зѓгв
2.OLAP - ЖдШежОзіЖрЮЌЪ§ОнЗжЮіЃЌетВПЗжЪЙгУЕФЪЧ Kylin
3.гУЛЇЛЯёЃЌЛњЦїбЇЯАЁЃЗЂОђгУЛЇМлжЕ
Apache Kylin ЩЯЯпгІгУ
дк 4399 ЕФДѓЪ§ОнЦНЬЈжаЃЌHadoop ЮЊЮвУЧЬсЙЉСЫЪ§ОнЙмРэЙІФмЃЌЕЋЪЧЯжгаЕФвЕЮёЗжЮіЙЄОпЃЈШч
TableauЁЂMicrostrategy ЕШЃЉДцдкКмДѓЕФОжЯоадЃЌР§ШчФбвдЫЎЦНРЉеЙЁЂЮоЗЈДІРэГЌДѓЙцФЃЪ§ОнЁЂШБЩйЖд
Hadoop ЕФжЇГжЕШЁЃЪ§ОнВжПт Hive ЫфШЛвВЬсЙЉСЫ SQL ВщбЏНгПкЃЌЕЋЪЧЯьгІЪБМфВюЧПШЫвтЁЃдкетбљЕФБГОАЯТЃЌKylin
ФмЙЛдкбЧУыМЖВщбЏОоДѓЕФ Hive БэЃЌВЂжЇГжИпВЂЗЂ, ПЩвдЫЕЪЧгІдЫЖјЩњСЫЁЃ
a) Kylin ЦНЬЈМмЙЙ
ШчЭМ 2-1 Kylin дк 4399 гІгУЕФММЪѕМмЙЙЭМЃЌжївЊАќКЌВщбЏКЭЙЙНЈЗўЮёЦїЁЃ
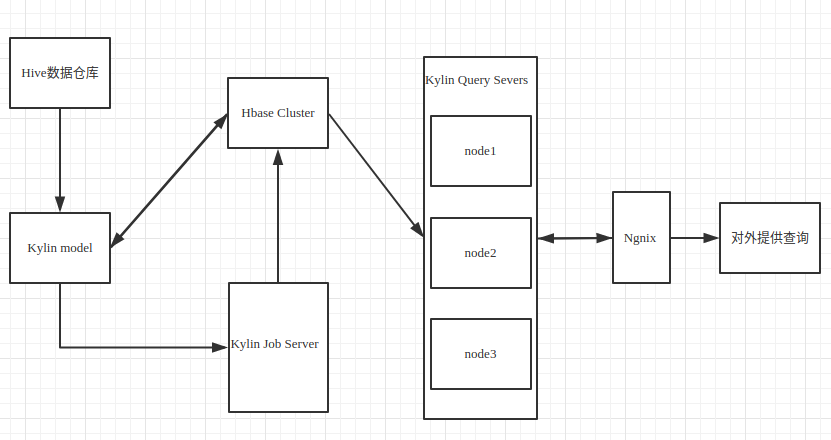
ЭМБэ 2-1 Kylin ЦНЬЈМмЙЙЭМ
i. ВПЪ№ЧщПі
ЮЊСЫБЃжЄВщбЏЗўЮёЕФЮШЖЈадЃЌЮвУЧЪЙгУ Nginx ХфжУИКдиОљКтЁЃ
ЩњВњЛЗОГЃКШ§ЬЈВщбЏЁЂвЛЬЈЙЙНЈЃЛHBase МЏШКАќКЌ 23 НкЕуЁЃ
ВтЪдЛЗОГЃКвЛЬЈВщбЏЁЂвЛЬЈЙЙНЈКЭВщбЏЁЃ
ЖрАцБОЭЌЪБВПЪ№ЃЌашвЊаоИФХфжУЃЌЪЙЕУ Zookeeper ЕФ znode ТЗОЖвдМА kylin_metadata
ЗжПЊЃЌБмУтЯрЛЅгАЯьЁЃ
ii. Ъ§ОнСїЯђ
вдЮвУЧгІгУЦНЬЈ 4399 гЮЯЗКаЕФТЉЖЗФЃаЭЗжЮіЃЈДгеЙЪОЕНЕуЛїЯТдиЦєЖЏСєДцЃЉЮЊР§ЃЌЗжЮіЪ§ОнСїЯђЁЃ

ЭМБэ 2-2 ТЉЖЗФЃаЭЪ§ОнСїЯђЭМ
ШчЭМБэ 2-2ЃЌЪзЯШвЊећРэКУЪТЪЕБэКЭЮЌЖШБэЃЌЙЙГЩаЧаЭФЃаЭЃЈЛђбЉЛЈФЃаЭЃЉЃЌЗжЮіЫљашЕФЮГЖШКЭжИБъЃЌХфжУ
Kylin ФЃаЭЃЌНгзХХфжУЯргІЕФ cubeЁЃОЙ§ Kylin ЕФЙЙНЈЃЌОЭФмЪЙгУ SQL гяОфВщбЏ KylinЁЃ
b) еЙЪОвГУц
ЮЊСЫЗНБудЫгЊШЫдБЕФВщПДЪ§ОнЃЌЬхЯжГі Apache Kylin ЕФЖрЮЌЗжЮів§ЧцгХЪЦЃЌздМКПЊЗЂСЫвЛЬзЖрЮЌЗжЮіеЙЪОвГУцЁЃЃЈЯТСаЭМБэЪЙгУСЫФЃФтЪ§ОнЁЃЃЉ
ШчЭМБэ 2-3ЃЌетЪЧЯТдиЭъГЩЕФЗжЮіФЃаЭЁЃЩЯУцЪЧЮЌЖШЯрЙиЕФЬѕМўЩИбЁКЭЗжзщеЙПЊЁЃзѓЯТНЧЪЧааЮЊТЗОЖЭГМЦЪїзДЭМЃЌИїТЗОЖЯТдизмСПКЭеМБШвЛФПСЫШЛЃЌгвЯТНЧжИБъЕФзпЪЦЭМКЭжИБъЮЌЖШЯТзъСаБэЁЃЫљгаЕФЮЌЖШЖМжЇГжЬѕМўЩИбЁКЭЗжзщеЙПЊЃЌИїЮЌЖШЕФжИБъЖдБШЃЌЪЙЕУЗжЮіФмИќжБЙлЕФИаЪмЪ§ОнЧїЪЦЕФФкдкдвђЁЃ

ЭМБэ 2-3 ЖрЮЌЗжЮіНчУц
АДеегЮЯЗЮЌЖШЗжзщеЙПЊЕФаЇЙћШчЭМБэ 2-4ЁЃ

ЭМБэ 2-4 гЮЯЗЮЌЖШЗжзщеЙПЊ
c) Apache Kylin гХЛЏНЈвщ
жкЫљжмжЊЃЌKylin ЕФКЫаФЫМЯыЪЧдЄМЦЫуЃЌМДЖдЖрЮЌЗжЮіПЩФмгУЕНЕФЖШСПжЕНјаадЄМЦЫуЃЌНЋМЦЫуКУЕФНсЙћБЃДцГЩ
CubeЃЌЬсЙЉВщбЏЁЃЫљвдЩцМАЕНСНИіЗНУцЕФадФмЮЪЬтЃК
ВщбЏЪБЕФЯьгІЪБМфЁЃ
дЄМЦЫуЛЈЗбЕФЪБМфКЭПеМфЁЃ
i. ВщбЏЪБМфгХЛЏ
Kylin ЕФВщбЏЙ§ГЬжївЊАќКЌЫФИіВНжшЃКНтЮі SQLЃЌДг HBase ЛёШЁЪ§ОнЃЌЖўДЮОлКЯдЫЫуЃЌЗЕЛиНсЙћЁЃЯдШЛгХЛЏЕФжиЕуОЭТфдкШчКЮМгПь
HBase ЛёШЁЪ§ОнЕФЫйЖШКЭМѕЩйЖўДЮОлКЯдЄЫуЁЃ
ЬсИп HBase ЯьгІЪБМфЃКаоИФХфжУЃЌаоИФ Cache ЕФВпТдЃЌдіМг Block Cache ЕФШнСП
МѕЩйЖўДЮОлКЯдЫЫуЃККЯРэЩшМЦЮГЖШЃЌЪЙВщбЏЪБОЁСПФмОЋШЗУќжа CuboidЁЃШЅжижЕЪЙгУгаЫ№ЫуЗЈЁЃ
d) дЄМЦЫугХЛЏ
дЄМЦЫуЕФгХЛЏЃЌжївЊПМТЧгаКЮЫѕЖЬЙЙНЈЛЈЗбЕФЪБМфЃЌвдМАжаМфНсЙћКЭзюжеНсЙћеМгУЕФПеМфЁЃУПИівЕЮёЕЅЖРвЛИі
CubeЃЌБмУтУПИі Cube ДѓЖјШЋЃЌМѕЩйВЛБивЊЕФМЦЫуЁЃ
i.Cube гХЛЏ
ЫцзХЮЌЖШЪ§ФПЕФдіМгЃЌCuboid ЕФЪ§СПГЩжИЪ§МЖдіГЄЁЃЮЊСЫЛКНт Cube ЕФЙЙНЈбЙСІЃЌKylin
ЬсЙЉСЫ Cube ЕФИпМЖЩшжУЁЃетаЉИпМЖЩшжУАќРЈОлКЯзщЃЈAggregation GroupЃЉЁЂСЊКЯЮЌЖШЃЈJoint
DimensionЃЉЁЂВуМЖЮЌЖШЃЈHierarchy DimensionЃЉКЭБивЊЮЌЖШЃЈMandatory
DimensionЃЉЕШЁЃ
КЯРэЕїећЮГЖШХфжУЃЌЖдашЙЙНЈЕФ Cuboid НјааМєжІЃЌЫЂбЁГіеце§ашвЊЕФ CuboidЃЌгХЛЏЙЙНЈадФмЃЌНЕЕЭЙЙНЈЪБМфЃЌДѓДѓЬсИпСЫМЏШКзЪдДЕФРћгУаЇТЪЁЃгХЛЏЧАКѓЕФаЇЙћЖдБШШчБэ
2-5ЃК

ЭМБэ 2-5 гХЛЏКѓаЇЙћЖдБШ
1. БиаыЮЌЖШ
ВщбЏЪБЃЌОГЃЪЙгУЕФЮЌЖШЃЌвдМАЕЭЛљЪ§ЮГЖШЁЃШчИУЮЌЖШЛљЪ§<10ЃЌПЩвдПМТЧзїЮЊБиаыЮЌЖШЁЃ
2. ВуМЖЮЌЖШ
ЮЌЖШЙиЯЕгавЛЖЈВуМЖадЁЂЛљЪ§гааЁЕНДѓЧщПіПЩвдЪЙгУВуМЖЮЌЖШЁЃ
3.Joint ЮЌЖШ
ЮЌЖШжЎМфЪЧЭЌЪБГіЯжЕФЙиЯЕЃЌМАВщбЏЪБЃЌОјДѓВПЗжЧщПіЖМЪЧЭЌЪБГіЯжЕФЁЃПЩвдЪЙгУ joint ЮЌЁЃ
4. ЮЌЖШзщКЯзщ
НЋЮЊЮЌЖШНјааЗжзщЃЌВщбЏЪБзщгызщжЎМфЕФЮЌЖШВЛЛсЭЌЪБГіЯжЁЃ
ii. ХфжУгХЛЏ
ХфжУгХЛЏЃЌАќРЈ Kylin зЪдДЕФХфжУвдМА Hadoop МЏШКХфжУЯрЙиаоИФЁЃ
1. ЙЙНЈзЪдД
УПИі Cube ЙЙНЈЪБЃЌЫљашЕФзЪдДВЛЬЋвЛбљЃЌашвЊНјааЯргІЕФзЪдДЕїећЁЃ
2. ЕїећИББО
МЏШКФЌШЯЕФЮФМўИББОЪ§ЮЊ 3ЃЌCube ЙЙНЈЪБЃЌНЋИББОЪ§ЕїЮЊ 2ЃЌИіБ№жаМфШЮЮёЛЙПЩвдЕїећЮЊ 1ЃЌетбљПЩвдНЕЕЭЙЙНЈШЮЮёЪБМЏШК
IOЁЃЮЊСЫБЃжЄВщбЏЕФЮШЖЈадЃЌHBase ИББОЪ§вРШЛЮЊ 3ЁЃ
3. ЦєгУбЙЫѕ
Hadoop МЏШКЦєгУ Snappy бЙЫѕЃЌHBase вВЦєгУ SnappyЃЌзюжеЩњГЩЕФ HFILEЃЌзюДѓбЙЫѕТЪПЩДя
70% зѓгвЃЌДѓДѓНЕЕЭСЫМЏШК IO ИКдиЁЃ
КѓМЧ
дк 4399 ДѓЪ§ОнЦНЬЈЩЯЯждкЛЙДцдкМИИіЮЪЬтЃКHBase МЏШКВЛЙЛЮШЖЈЃЌВщбЏЯьгІЪБМфВЛЙЛЮШЖЈЃЌИіБ№гяОфЯьгІЪБМфВЛРэЯыЃЌCube
segment жиаТЙЙНЈдБО HBase БэВЛЛсздЖЏЩОГ§ЁЃЮЇШЦетМИИіЮЪЬтЃЌЮвУЧКѓајЛсдйНјаавЛаЉгХЛЏЁЃ
HBase МЏШКЖРСЂГіРДЃЌБмУтБЛМЏШКЦфЫћШЮЮёЫљгАЯьЃЌЕїећХфжУгХЛЏВщбЏЃЌдіМгВщбЏЕФ cache ФкДцБШР§ЁЃ
ИіБ№зМЪЕЪБЙЙНЈШЮЮёНсЙћЕїећЮЊ HBase ЕФФкДцБэЃЌМѕЩйЯьгІЪБМфЃЌФмДѓЗљЖШЬсИпЯьгІЪБМфЕФЮШЖЈадЁЃ
аоИФдДТыЃЌжиаТЙЙНЈНсЪјКѓздЖЏЧхРэЙ§Цк HBase БэЃЌНЕЕЭ HBase Ыїв§ЕФбЙСІЁЃ |








