| 编辑推荐: |
| 来源网络,Marmaray是Uber开源的Apache
Hadoop数据提取和分散框架。Marmaray由我们的Hadoop平台团队设计和开发,是一个建立在Hadoop生态系统之上的基于插件的框架。 |
|
AI前线导读:
三年前,Uber采用Apache Hadoop作为数据平台,从而可以跨计算机集群管理数PB的数据。但是,因为我们有很多团队、工具和数据源,所以需要一种可靠的方式来摄取和分散数据。Marmaray是Uber开源的Apache
Hadoop数据提取和分散框架。Marmaray由我们的Hadoop平台团队设计和开发,是一个建立在Hadoop生态系统之上的基于插件的框架。用户可以新增插件以便从任何来源摄取数据,并利用Apache
Spark将数据分散到接收器上。Marmaray这个名字源于土耳其的一条连接欧洲和亚洲的隧道,在Uber内部,我们将Marmaray设想为根据客户偏好将数据从任何来源连接到任何接收器的管道。数据湖的数据通常在质量方面存在很大差异。Marmaray可以确保所有摄取的原始数据都符合适当的源模式,保持高质量水平,从而带来可靠的分析结果。数据科学家可以将时间花在从这些数据中提取有用的见解上,而不是用来处理数据质量问题。
在Uber,Marmaray以聚合的方式连接各种系统和服务:
通过我们的模式管理库和服务生成高质量的模式化数据。
通过Marmaray的摄取组件将多个数据存储中的数据摄取到我们的Hadoop数据湖中。
使用Uber的内部工作流程编排服务来构建管道,用以处理摄取的数据,以及根据这些数据保存和计算业务指标。
将处理的结果提供给在线数据存储,内部客户可以通过Marmaray查询数据并获得近乎实时的结果。

图1:Marmaray将数据摄取到Hadoop数据湖中,并分散到数据存储中。
虽然Marmaray实现了任意数据源到任意数据槽的连接,但我们还需要构建一个自助服务平台,为来自不同背景、团队和技术专业知识的用户提供无缝的使用体验。
大规模数据摄入的挑战
Uber的业务生成大量的原始数据,并将它们存储在各种数据源中,例如Kafka、Schemaless和MySQL。我们需要将这些数据摄取到Hadoop数据湖中,以进行业务分析。随着Uber业务的垂直增长,数据摄取的规模呈现出指数级的增长。面对大规模数据可靠性的需求,我们不得不重新构建我们的摄取平台,以确保能够跟上公司增长的步伐。

图2:随着Uber继续扩展全球业务,存储在Hadoop数据湖中的原始数据呈指数级增长。
之前的数据架构需要运行和维护多个数据管道,每个管道对应不同的生产代码库,随着数据量的增加,这些管道变得越来越繁琐。MySQL、Kafka和Schemaless等数据源包含需要被摄取到Hive中的原始数据,以支持整个公司团队的各种分析需求。每个数据源都有自己的代码库和相关的复杂性,以及一组独有的配置、图表和警报。添加新的摄取源迫在眉睫,维护的开销要求我们的大数据生态系统支持所有这些系统。轮班待命的负担十分繁重,有时每周会收到200多个警报。

图3:Hadoop平台团队的轮班待命警报图表,可见维护系统需要多大的开销。
随着Marmaray的推出,我们将摄取管道整合到一个与源无关的管道和代码库中,以此来提高可维护性和资源利用率。
无论源数据存储是什么,单一摄取管道都将执行相同的有向非循环图作业(DAG)。在运行时,摄取行为将根据特定源(类似于策略设计模式)而有所变化,以协调摄取过程,并使用一种通用的灵活配置来适应未来不同的需求和用例。
Uber的数据分散需求
我们的很多内部数据用户,例如Uber Eats和Michelangelo机器学习平台团队,他们使用Hadoop与其他工具来构建和训练机器学习模型,以生成有价值的衍生数据集,从而提高效率并改善用户体验。为了最大化这些衍生数据集的价值,需要将这些数据分散到在线数据存储中,这些数据存储通常要求比Hadoop生态系统低得多的延迟。
在引入Marmaray之前,每个团队都需要构建自己的临时扩散系统。这些重复性工作和不具有通用性的功能通常导致工程资源的极度浪费。Marmaray于2017年底发布,以满足对灵活的通用分散平台的需求,它将Hadoop数据传输到任何一个在线数据存储,以此来完善Hadoop生态系统。
跟踪端到端数据传输
我们的很多内部用户需要保证将数据源的数据传输到目标接收器,他们还需要完整性指标,包括数据传输到最终接收器的可靠性。从理论上讲,这意味着数据被100%传输到目的地,但实际上我们的目标是提供99.99%到99.999%的可靠性。当记录数量非常少时,可以直接对源系统和接收器系统运行查询来验证数据是否已送达。
在Uber,我们每天摄取数PB的数据和超过1000亿条消息,因此无法通过查询的方式进行数据验证。面对这么大规模的数据,我们需要一个能够跟踪数据传输而不会显著增加延迟的系统。Marmaray通过自定义Spark累加器来桶分化记录,让用户能够以最小的开销监控数据传输。
Marmaray的架构
下面的架构图说明了Marmaray的基本构建块和抽象。我们可以通过这些通用组件向Marmaray添加扩展,以便支持新的数据源和接收器。

图4:Marmaray的架构,包含各种组件。
DataConverters
摄取和分散作业主要对来自数据源的记录执行转换,以确保在将数据写入目标接收器之前具备所需格式。Marmaray将多个转换器链接在一起执行多次转换,并且可以写入多个接收器。
DataConverters的一个关键的作用是在转换时生成错误记录。为了保证分析结果更准确,所有原始数据在被摄入到Hadoop数据湖之前必须符合一定的模式。任何包含错误格式、缺少必需字段或被视为有问题的数据都将被过滤掉并写入错误表。
WorkUnitCalculator
Marmaray按照批次来移动数据,批次大小是可配的。为了计算需要处理的数据量,我们引入了WorkUnitCalculator的概念。WorkUnitCalculator将检查输入源的类型和之前的检查点,然后计算下一个工作单元或批次。工作单元可以是Kafka的偏移范围或Hive/HDFS的HDFS文件集合。
在计算下一批数据时,WorkUnitCalculator还可以应用限流信息,例如,要读取的最大数据量或要从Kafka读取的消息数。这些限流信息可根据具体用例进行灵活配置,从而确保工作单元的大小不会压垮源系统或接收系统。
Metadata Manager

图5:Marmaray的Metadata Manager用于存储运行中作业的相关元数据。
所有Marmaray作业都需要一个持久存储(我们称之为Metadata Manager)来缓存作业的元数据信息。作业可以在执行期间更新状态,并在作业执行成功后替换旧状态,否则将无法修改状态。在Uber,我们使用Metadata
Manager存储检查点信息(或Kafka的分区偏移量)、平均记录大小和平均消息数等元数据。元数据存储是通用的,可以存储任何相关的度量指标,这些度量指标可用于根据用例和用户需求跟踪、描述或收集作业的状态。
ForkOperator和ForkFunction
ForkOperator使用ForkFunction将输入的记录流拆分为多个输出流,并验证符合模式的记录和错误的记录,然后可以单独处理这些记录。
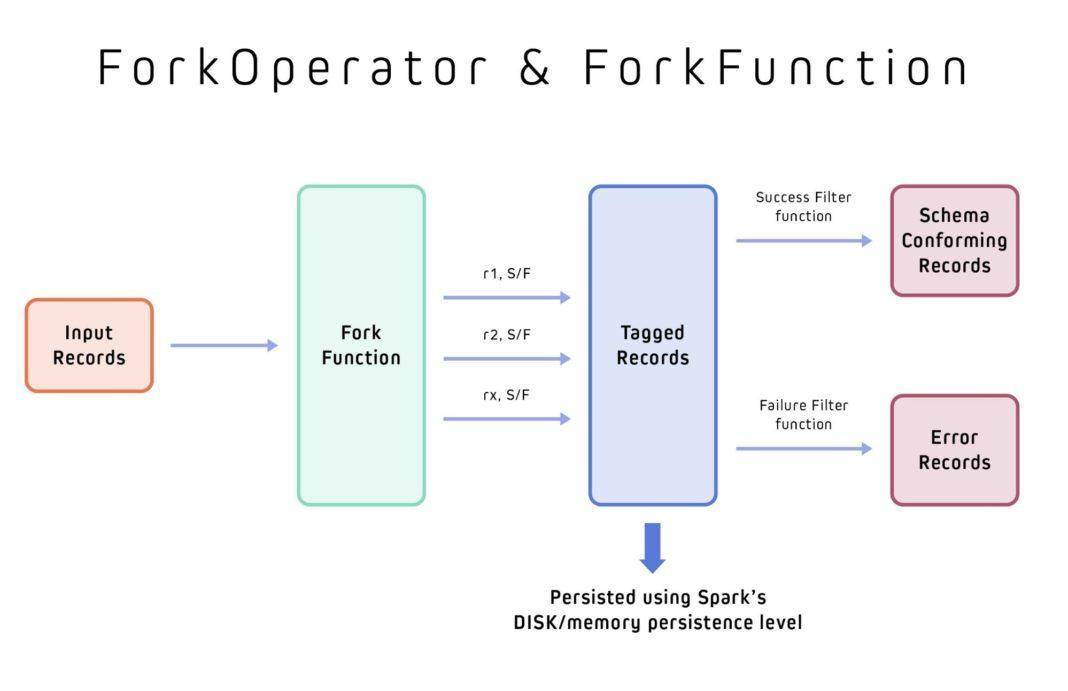
图6:ForkOperator和ForkFunction用于将原始数据记录拆分为符合模式的记录和错误的记录。
ISource和ISink
ISource包含工作单元所需的源数据信息,ISink包含有关如何写入接收器的必要信息。例如,Cassandra接收器可能需要包含集群、表、分区键和集群键的信息。Kafka源需要包含主题名称、要读取的最大消息数、群集信息和偏移量初始化策略以及其他元数据信息。
数据模型和工作流
AvroPayload是Marmaray架构的核心组件,它是Avro GenericRecord二进制编码格式的包装器,包含了需要处理的数据的元数据信息。

图7:AvroPayload使用元数据包装GenericRecord。
Avro数据(GenericRecord)的主要优点是它在内存存储和网络传输方面都很高效,与JSON相比,二进制编码数据通过线路发送需要更小的模式开销。在Spark架构之上使用Avro数据意味着我们还可以利用Spark的数据压缩和加密功能。这些优势有助于我们的Spark作业更有效地处理大规模数据。
为了支持连接任何数据源和任意接收器的架构,我们要求所有摄取源将转换器定义为从自己的格式到Avro,所有分散接收器将转换器定义为从Avro到本地数据模型(对于Cassandra来说就是ByteBuffers)。
要求所有转换器将数据转换为AvroPayload格式或从AvroPayload格式转换为数据为形成了松散耦合的数据模型。在定义了数据源及其相关的转换器后,就可以将数据分散到任何受支持的接收器,因为所有接收器都是源不可知的,它们只关心AvroPayload格式的数据。下图描绘了Marmaray的数据模型:

图8:对于摄取和分散,Marmaray要求将数据转换为AvroPayload,这是一个基于Avro的GenericRecord格式的包装器。
下图描绘了Marmaray作业是如何独立于特定的数据源或接收器进行编排的。

图9:Marmaray独立于数据源或接收器运行摄取和分散作业。
在这个过程中,每个数据源和接收器的属性配置将指向作业的下一个步骤,包括计算需要处理的数据量(即其工作单元)、应用ForkFunction将原始数据拆分为“有效”和“错误”记录以确保数据的质量、将数据转换为适当的目标格式、更新元数据并报告指标以便跟踪进度。在Uber,所有Marmaray作业都运行在Apache
Spark上,并使用YARN作为资源管理器。
自助服务平台
由于我们的很多数据平台用户不熟悉我们的技术栈中所使用的语言(如Python和Java),因此我们的团队必须构建一个自助服务平台,用户只需通过鼠标点击就可以建立端到端的管道,确保来自所需源的数据最终能够到达目标接收器,以便进行后续的分析工作和查询。

图10:我们的自助服务UI让数据科学家和其他用户能够将数据从任何源移动到任何接收器,而无需了解特定的数据格式。
在上线之后的七个月时间里,已经有超过3300个作业通过我们的自助服务平台加入到我们的系统中。
数据删除
在Uber,所有的Kafka数据都是以追加的方式进行存储,并使用了日期分区。用户数据可以跨越多个日期分区,并且每个分区通常会包含很多Kafka记录。如果底层存储没有内置的索引和更新支持,那么扫描和更新这些分区以便进行用户数据的更正、更新或删可能会非常耗费资源。Hadoop使用的Parquet数据存储不支持索引,所以我们根本无法直接更新Parquet文件。为了便于索引和更新,Marmaray使用了Hadoop
Updates和Incremental(Hudi),Uber开发的另一个开源库,用于管理大型分析数据集的存储,将原始数据存储在Hive中。
数据生产者使用Hive来扫描数据表,识别要删除的记录,并将它们发布到Kafka集群。Marmaray的Kafka摄取管道依次从Kafka集群中读取它们。然后,Marmaray使用Hudi的批量插入功能摄取新记录,保持较低的摄取延迟,并使用Hudi的upsert功能处理更新的记录,将Kafka的旧记录替换为更新过的数据。

图11:Marmaray利用Hudi存储格式来支持数据删除。
Marmaray的下一个篇章
Marmaray对任意源到任意接收器数据管道的支持适用于Hadoop生态系统(主要针对使用了Hive的场景)以及数据迁移的各种用例。我们已经向开源社区发布了Marmary,并期待收到更多反馈,然后不断改进Marmaray平台。与此同时,我们正在弃用传统管道,并将我们所有的工作流程迁移到Marmaray平台上,以简化我们的整体数据架构,并确保随着数据需求的增长,我们能够轻松地扩展。
Marmaray GitHub地址 |








