| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмСЫFlinkЯюФПЕФвЛаЉЙиМќЬиадЃЌЯЃЭћЭЈЙ§БОЮФЕФНщЩмФмЙЛШУЖСепЖдFlinkгаИќЖрЕФСЫНтЃЌвВШУИќЖрЕФШЫЪЙгУЩѕжСВЮгыЕНFlinkЯюФПжаШЅЁЃ
|
|
Apache FlinkЃЈЯТМђГЦFlinkЃЉЯюФПЪЧДѓЪ§ОнДІРэСьгђзюНќШНШНЩ§Ц№ЕФвЛПХаТаЧЃЌЦфВЛЭЌгкЦфЫћДѓЪ§ОнЯюФПЕФжюЖрЬиадЮќв§СЫдНРДдНЖрШЫЕФЙизЂЁЃБОЮФНЋЩюШыЗжЮіFlinkЕФвЛаЉЙиМќММЪѕгыЬиадЃЌЯЃЭћФмЙЛАяжњЖСепЖдFlinkгаИќМгЩюШыЕФСЫНтЃЌЖдЦфЫћДѓЪ§ОнЯЕЭГПЊЗЂепвВФмгаЫљёдвцЁЃБОЮФМйЩшЖСепвбЖдMapReduceЁЂSparkМАStormЕШДѓЪ§ОнДІРэПђМмгаЫљСЫНтЃЌЭЌЪБЪьЯЄСїДІРэгыХњДІРэЕФЛљБОИХФюЁЃ
FlinkМђНщ
FlinkКЫаФЪЧвЛИіСїЪНЕФЪ§ОнСїжДаав§ЧцЃЌЦфеыЖдЪ§ОнСїЕФЗжВМЪНМЦЫуЬсЙЉСЫЪ§ОнЗжВМЁЂЪ§ОнЭЈаХвдМАШнДэЛњжЦЕШЙІФмЁЃЛљгкСїжДаав§ЧцЃЌFlinkЬсЙЉСЫжюЖрИќИпГщЯѓВуЕФAPIвдБугУЛЇБраДЗжВМЪНШЮЮёЃК
DataSet APIЃЌ ЖдОВЬЌЪ§ОнНјааХњДІРэВйзїЃЌНЋОВЬЌЪ§ОнГщЯѓГЩЗжВМЪНЕФЪ§ОнМЏЃЌгУЛЇПЩвдЗНБуЕиЪЙгУFlinkЬсЙЉЕФИїжжВйзїЗћЖдЗжВМЪНЪ§ОнМЏНјааДІРэЃЌжЇГжJavaЁЂScalaКЭPythonЁЃ
DataStream APIЃЌЖдЪ§ОнСїНјааСїДІРэВйзїЃЌНЋСїЪНЕФЪ§ОнГщЯѓГЩЗжВМЪНЕФЪ§ОнСїЃЌгУЛЇПЩвдЗНБуЕиЖдЗжВМЪНЪ§ОнСїНјааИїжжВйзїЃЌжЇГжJavaКЭScalaЁЃ
Table APIЃЌЖдНсЙЙЛЏЪ§ОнНјааВщбЏВйзїЃЌНЋНсЙЙЛЏЪ§ОнГщЯѓГЩЙиЯЕБэЃЌВЂЭЈЙ§РрSQLЕФDSLЖдЙиЯЕБэНјааИїжжВщбЏВйзїЃЌжЇГжJavaКЭScalaЁЃ
ДЫЭтЃЌFlinkЛЙеыЖдЬиЖЈЕФгІгУСьгђЬсЙЉСЫСьгђПтЃЌР§ШчЃК
Flink MLЃЌFlinkЕФЛњЦїбЇЯАПтЃЌЬсЙЉСЫЛњЦїбЇЯАPipelines APIВЂЪЕЯжСЫЖржжЛњЦїбЇЯАЫуЗЈЁЃ
GellyЃЌFlinkЕФЭММЦЫуПтЃЌЬсЙЉСЫЭММЦЫуЕФЯрЙиAPIМАЖржжЭММЦЫуЫуЗЈЪЕЯжЁЃ
FlinkЕФММЪѕеЛШчЭМ1ЫљЪОЃК
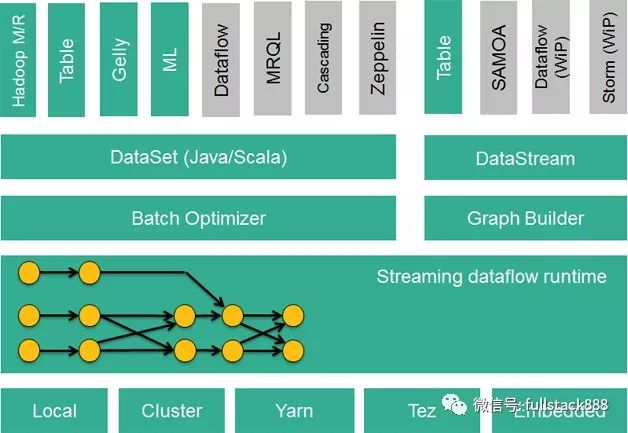
ЭМ1 FlinkММЪѕеЛ
ДЫЭтЃЌFlinkвВПЩвдЗНБуЕиКЭHadoopЩњЬЌШІжаЦфЫћЯюФПМЏГЩЃЌР§ШчFlinkПЩвдЖСШЁДцДЂдкHDFSЛђHBaseжаЕФОВЬЌЪ§ОнЃЌвдKafkaзїЮЊСїЪНЕФЪ§ОндДЃЌжБНгжигУMapReduceЛђStormДњТыЃЌЛђЪЧЭЈЙ§YARNЩъЧыМЏШКзЪдДЕШЁЃ
ЭГвЛЕФХњДІРэгыСїДІРэЯЕЭГ
дкДѓЪ§ОнДІРэСьгђЃЌХњДІРэШЮЮёгыСїДІРэШЮЮёвЛАуБЛШЯЮЊЪЧСНжжВЛЭЌЕФШЮЮёЃЌвЛИіДѓЪ§ОнЯюФПвЛАуЛсБЛЩшМЦЮЊжЛФмДІРэЦфжавЛжжШЮЮёЃЌР§ШчApache
StormЁЂApache SmazaжЛжЇГжСїДІРэШЮЮёЃЌЖјAapche MapReduceЁЂApache
TezЁЂApache SparkжЛжЇГжХњДІРэШЮЮёЁЃSpark StreamingЪЧApache SparkжЎЩЯжЇГжСїДІРэШЮЮёЕФзгЯЕЭГЃЌПДЫЦвЛИіЬиР§ЃЌЪЕдђВЛШЛЁЊЁЊSpark
StreamingВЩгУСЫвЛжжmicro-batchЕФМмЙЙЃЌМДАбЪфШыЕФЪ§ОнСїЧаЗжГЩЯИСЃЖШЕФbatchЃЌВЂЮЊУПвЛИіbatchЪ§ОнЬсНЛвЛИіХњДІРэЕФSparkШЮЮёЃЌЫљвдSpark
StreamingБОжЪЩЯЛЙЪЧЛљгкSparkХњДІРэЯЕЭГЖдСїЪНЪ§ОнНјааДІРэЃЌКЭApache StormЁЂApache
SmazaЕШЭъШЋСїЪНЕФЪ§ОнДІРэЗНЪНЭъШЋВЛЭЌЁЃЭЈЙ§ЦфСщЛюЕФжДаав§ЧцЃЌFlinkФмЙЛЭЌЪБжЇГжХњДІРэШЮЮёгыСїДІРэШЮЮёЁЃ
дкжДаав§ЧцетвЛВуЃЌСїДІРэЯЕЭГгыХњДІРэЯЕЭГзюДѓВЛЭЌдкгкНкЕуМфЕФЪ§ОнДЋЪфЗНЪНЁЃЖдгквЛИіСїДІРэЯЕЭГЃЌЦфНкЕуМфЪ§ОнДЋЪфЕФБъзМФЃаЭЪЧЃКЕБвЛЬѕЪ§ОнБЛДІРэЭъГЩКѓЃЌађСаЛЏЕНЛКДцжаЃЌШЛКѓСЂПЬЭЈЙ§ЭјТчДЋЪфЕНЯТвЛИіНкЕуЃЌгЩЯТвЛИіНкЕуМЬајДІРэЁЃЖјЖдгквЛИіХњДІРэЯЕЭГЃЌЦфНкЕуМфЪ§ОнДЋЪфЕФБъзМФЃаЭЪЧЃКЕБвЛЬѕЪ§ОнБЛДІРэЭъГЩКѓЃЌађСаЛЏЕНЛКДцжаЃЌВЂВЛЛсСЂПЬЭЈЙ§ЭјТчДЋЪфЕНЯТвЛИіНкЕуЃЌЕБЛКДцаДТњЃЌОЭГжОУЛЏЕНБОЕигВХЬЩЯЃЌЕБЫљгаЪ§ОнЖМБЛДІРэЭъГЩКѓЃЌВХПЊЪМНЋДІРэКѓЕФЪ§ОнЭЈЙ§ЭјТчДЋЪфЕНЯТвЛИіНкЕуЁЃетСНжжЪ§ОнДЋЪфФЃЪНЪЧСНИіМЋЖЫЃЌЖдгІЕФЪЧСїДІРэЯЕЭГЖдЕЭбгГйЕФвЊЧѓКЭХњДІРэЯЕЭГЖдИпЭЬЭТСПЕФвЊЧѓЁЃFlinkЕФжДаав§ЧцВЩгУСЫвЛжжЪЎЗжСщЛюЕФЗНЪНЃЌЭЌЪБжЇГжСЫетСНжжЪ§ОнДЋЪфФЃаЭЁЃFlinkвдЙЬЖЈЕФЛКДцПщЮЊЕЅЮЛНјааЭјТчЪ§ОнДЋЪфЃЌгУЛЇПЩвдЭЈЙ§ЛКДцПщГЌЪБжЕжИЖЈЛКДцПщЕФДЋЪфЪБЛњЁЃШчЙћЛКДцПщЕФГЌЪБжЕЮЊ0ЃЌдђFlinkЕФЪ§ОнДЋЪфЗНЪНРрЫЦЩЯЮФЫљЬсЕНСїДІРэЯЕЭГЕФБъзМФЃаЭЃЌДЫЪБЯЕЭГПЩвдЛёЕУзюЕЭЕФДІРэбгГйЁЃШчЙћЛКДцПщЕФГЌЪБжЕЮЊЮоЯоДѓЃЌдђFlinkЕФЪ§ОнДЋЪфЗНЪНРрЫЦЩЯЮФЫљЬсЕНХњДІРэЯЕЭГЕФБъзМФЃаЭЃЌДЫЪБЯЕЭГПЩвдЛёЕУзюИпЕФЭЬЭТСПЁЃЭЌЪБЛКДцПщЕФГЌЪБжЕвВПЩвдЩшжУЮЊ0ЕНЮоЯоДѓжЎМфЕФШЮвтжЕЁЃЛКДцПщЕФГЌЪБуажЕдНаЁЃЌдђFlinkСїДІРэжДаав§ЧцЕФЪ§ОнДІРэбгГйдНЕЭЃЌЕЋЭЬЭТСПвВЛсНЕЕЭЃЌЗДжЎврШЛЁЃЭЈЙ§ЕїећЛКДцПщЕФГЌЪБуажЕЃЌгУЛЇПЩИљОнашЧѓСщЛюЕиШЈКтЯЕЭГбгГйКЭЭЬЭТСПЁЃ

ЭМ2 FlinkжДаав§ЧцЪ§ОнДЋЪфФЃЪН
дкЭГвЛЕФСїЪНжДаав§ЧцЛљДЁЩЯЃЌFlinkЭЌЪБжЇГжСЫСїМЦЫуКЭХњДІРэЃЌВЂЖдадФмЃЈбгГйЁЂЭЬЭТСПЕШЃЉгаЫљБЃеЯЁЃЯрЖдгкЦфЫћдЩњЕФСїДІРэгыХњДІРэЯЕЭГЃЌВЂУЛгавђЮЊЭГвЛжДаав§ЧцЖјЪмЕНгАЯьДгЖјДѓЗљЖШМѕЧсСЫгУЛЇАВзАЁЂВПЪ№ЁЂМрПиЁЂЮЌЛЄЕШГЩБОЁЃ
FlinkСїДІРэЕФШнДэЛњжЦ
ЖдгквЛИіЗжВМЪНЯЕЭГРДЫЕЃЌЕЅИіНјГЬЛђЪЧНкЕуБРРЃЕМжТећИіJobЪЇАмЪЧОГЃЗЂЩњЕФЪТЧщЃЌдквьГЃЗЂЩњЪБВЛЛсЖЊЪЇгУЛЇЪ§ОнВЂФмздЖЏЛжИДВХЪЧЗжВМЪНЯЕЭГБиаыжЇГжЕФЬиаджЎвЛЁЃБОНкжївЊНщЩмFlinkСїДІРэЯЕЭГШЮЮёМЖБ№ЕФШнДэЛњжЦЁЃ
ХњДІРэЯЕЭГБШНЯШнвзЪЕЯжШнДэЛњжЦЃЌгЩгкЮФМўПЩвджиИДЗУЮЪЃЌЕБФГИіШЮЮёЪЇАмКѓЃЌжиЦєИУШЮЮёМДПЩЁЃЕЋЪЧЕНСЫСїДІРэЯЕЭГЃЌгЩгкЪ§ОндДЪЧЮоЯоЕФЪ§ОнСїЃЌДгЖјЕМжТвЛИіСїДІРэШЮЮёжДааМИИідТЕФЧщПіЃЌНЋЫљгаЪ§ОнЛКДцЛђЪЧГжОУЛЏЃЌСєД§вдКѓжиИДЗУЮЪЛљБОЩЯЪЧВЛПЩааЕФЁЃFlinkЛљгкЗжВМЪНПьеегыПЩВПЗжжиЗЂЕФЪ§ОндДЪЕЯжСЫШнДэЁЃгУЛЇПЩздЖЈвхЖдећИіJobНјааПьееЕФЪБМфМфИєЃЌЕБШЮЮёЪЇАмЪБЃЌFlinkЛсНЋећИіJobЛжИДЕНзюНќвЛДЮПьееЃЌВЂДгЪ§ОндДжиЗЂПьеежЎКѓЕФЪ§ОнЁЃFlinkЕФЗжВМЪНПьееЪЕЯжНшМјСЫChandyКЭLamportдк1985ФъЗЂБэЕФвЛЦЊЙигкЗжВМЪНПьееЕФТлЮФЃЌЦфЪЕЯжЕФжївЊЫМЯыШчЯТЃК
АДеегУЛЇздЖЈвхЕФЗжВМЪНПьееМфИєЪБМфЃЌFlinkЛсЖЈЪБдкЫљгаЪ§ОндДжаВхШывЛжжЬиЪтЕФПьееБъМЧЯћЯЂЃЌетаЉПьееБъМЧЯћЯЂКЭЦфЫћЯћЯЂвЛбљдкDAGжаСїЖЏЃЌЕЋЪЧВЛЛсБЛгУЛЇЖЈвхЕФвЕЮёТпМЫљДІРэЃЌУПвЛИіПьееБъМЧЯћЯЂЖМНЋЦфЫљдкЕФЪ§ОнСїЗжГЩСНВПЗжЃКБОДЮПьееЪ§ОнКЭЯТДЮПьееЪ§ОнЁЃ

ЭМ3 FlinkАќКЌПьееБъМЧЯћЯЂЕФЯћЯЂСї
ПьееБъМЧЯћЯЂбизХDAGСїОИїИіВйзїЗћЃЌЕБВйзїЗћДІРэЕНПьееБъМЧЯћЯЂЪБЃЌЛсЖдздМКЕФзДЬЌНјааПьееЃЌВЂДцДЂЦ№РДЁЃЕБвЛИіВйзїЗћгаЖрИіЪфШыЕФЪБКђЃЌFlinkЛсНЋЯШЕжДяЕФПьееБъМЧЯћЯЂМАЦфжЎКѓЕФЯћЯЂЛКДцЦ№РДЃЌЕБЫљгаЕФЪфШыжаЖдгІИУДЮПьееЕФПьееБъМЧЯћЯЂШЋВПЕжДяКѓЃЌВйзїЗћЖдздМКЕФзДЬЌПьееВЂДцДЂЃЌжЎКѓДІРэЫљгаПьееБъМЧЯћЯЂжЎКѓЕФвбЛКДцЯћЯЂЁЃВйзїЗћЖдздМКЕФзДЬЌПьееВЂДцДЂПЩвдЪЧвьВНгыдіСПЕФВйзїЃЌВЂВЛашвЊзшШћЯћЯЂЕФДІРэЁЃЗжВМЪНПьееЕФСїГЬШчЭМ4ЫљЪОЃК

ЭМ4 FlinkЗжВМЪНПьееСїГЬЭМ
ЕБЫљгаЕФData SinkЃЈжеЕуВйзїЗћЃЉЖМЪеЕНПьееБъМЧаХЯЂВЂЖдздМКЕФзДЬЌПьееКЭДцДЂКѓЃЌећИіЗжВМЪНПьееОЭЭъГЩСЫЃЌЭЌЪБЭЈжЊЪ§ОндДЪЭЗХИУПьееБъМЧЯћЯЂжЎЧАЕФЫљгаЯћЯЂЁЃШєжЎКѓЗЂЩњНкЕуБРРЃЕШвьГЃЧщПіЪБЃЌжЛашвЊЛжИДжЎЧАДцДЂЕФЗжВМЪНПьеезДЬЌЃЌВЂДгЪ§ОндДжиЗЂИУПьеевдКѓЕФЯћЯЂОЭПЩвдСЫЁЃ
Exactly-OnceЪЧСїДІРэЯЕЭГашвЊжЇГжЕФвЛИіЗЧГЃживЊЕФЬиадЃЌЫќБЃжЄУПвЛЬѕЯћЯЂжЛБЛСїДІРэЯЕЭГДІРэвЛДЮЃЌаэЖрСїДІРэШЮЮёЕФвЕЮёТпМЖМвРРЕгкExactly-OnceЬиадЁЃЯрЖдгкAt-Least-OnceЛђЪЧAt-Most-Once,
Exactly-OnceЬиадЖдСїДІРэЯЕЭГЕФвЊЧѓИќЮЊбЯИёЃЌЪЕЯжвВИќМгРЇФбЁЃFlinkЛљгкЗжВМЪНПьееЪЕЯжСЫExactly-OnceЬиадЁЃ
ЯрЖдгкЦфЫћСїДІРэЯЕЭГЕФШнДэЗНАИЃЌFlinkЛљгкЗжВМЪНПьееЕФЗНАИдкЙІФмКЭадФмЗНУцЖМОпгаКмЖргХЕуЃЌАќРЈЃК
ЕЭбгГйЁЃгЩгкВйзїЗћзДЬЌЕФДцДЂПЩвдвьВНЃЌЫљвдНјааПьееЕФЙ§ГЬЛљБОЩЯВЛЛсзшШћЯћЯЂЕФДІРэЃЌвђДЫВЛЛсЖдЯћЯЂбгГйВњЩњИКУцгАЯьЁЃ
ИпЭЬЭТСПЁЃЕБВйзїЗћзДЬЌНЯЩйЪБЃЌЖдЭЬЭТСПЛљБОУЛгагАЯьЁЃЕБВйзїЗћзДЬЌНЯЖрЪБЃЌЯрЖдгкЦфЫћЕФШнДэЛњжЦЃЌЗжВМЪНПьееЕФЪБМфМфИєЪЧгУЛЇздЖЈвхЕФЃЌЫљвдгУЛЇПЩвдШЈКтДэЮѓЛжИДЪБМфКЭЭЬЭТСПвЊЧѓРДЕїећЗжВМЪНПьееЕФЪБМфМфИєЁЃ
гывЕЮёТпМЕФИєРыЁЃFlinkЕФЗжВМЪНПьееЛњжЦгыгУЛЇЕФвЕЮёТпМЪЧЭъШЋИєРыЕФЃЌгУЛЇЕФвЕЮёТпМВЛЛсвРРЕЛђЪЧЖдЗжВМЪНПьееВњЩњШЮКЮгАЯьЁЃ
ДэЮѓЛжИДДњМлЁЃЗжВМЪНПьееЕФЪБМфМфИєдНЖЬЃЌДэЮѓЛжИДЕФЪБМфдНЩйЃЌгыЭЬЭТСПИКЯрЙиЁЃ
FlinkСїДІРэЕФЪБМфДАПк
ЖдгкСїДІРэЯЕЭГРДЫЕЃЌСїШыЕФЯћЯЂВЛДцдкЩЯЯоЃЌЫљвдЖдгкОлКЯЛђЪЧСЌНгЕШВйзїЃЌСїДІРэЯЕЭГашвЊЖдСїШыЕФЯћЯЂНјааЗжЖЮЃЌШЛКѓЛљгкУПвЛЖЮЪ§ОнНјааОлКЯЛђЪЧСЌНгЁЃЯћЯЂЕФЗжЖЮМДГЦЮЊДАПкЃЌСїДІРэЯЕЭГжЇГжЕФДАПкгаКмЖрРраЭЃЌзюГЃМћЕФОЭЪЧЪБМфДАПкЃЌЛљгкЪБМфМфИєЖдЯћЯЂНјааЗжЖЮДІРэЁЃБОНкжївЊНщЩмFlinkСїДІРэЯЕЭГжЇГжЕФИїжжЪБМфДАПкЁЃ
ЖдгкФПЧАДѓВПЗжСїДІРэЯЕЭГРДЫЕЃЌЪБМфДАПквЛАуЪЧИљОнTaskЫљдкНкЕуЕФБОЕиЪБжгНјааЧаЗжЃЌетжжЗНЪНЪЕЯжЦ№РДБШНЯШнвзЃЌВЛЛсВњЩњзшШћЁЃЕЋЪЧПЩФмЮоЗЈТњзуФГаЉгІгУашЧѓЃЌБШШчЃК
ЯћЯЂБОЩэДјгаЪБМфДСЃЌгУЛЇЯЃЭћАДееЯћЯЂБОЩэЕФЪБМфЬиадНјааЗжЖЮДІРэЁЃ
гЩгкВЛЭЌНкЕуЕФЪБжгПЩФмВЛЭЌЃЌвдМАЯћЯЂдкСїОИїИіНкЕуЕФбгГйВЛЭЌЃЌдкФГИіНкЕуЪєгкЭЌвЛИіЪБМфДАПкДІРэЕФЯћЯЂЃЌСїЕНЯТвЛИіНкЕуЪБПЩФмБЛЧаЗжЕНВЛЭЌЕФЪБМфДАПкжаЃЌДгЖјВњЩњВЛЗћКЯдЄЦкЕФНсЙћЁЃ
FlinkжЇГж3жжРраЭЕФЪБМфДАПкЃЌЗжБ№ЪЪгУгкгУЛЇЖдгкЪБМфДАПкВЛЭЌРраЭЕФвЊЧѓЃК
Operator TimeЁЃИљОнTaskЫљдкНкЕуЕФБОЕиЪБжгРДЧаЗжЕФЪБМфДАПкЁЃ
Event TimeЁЃЯћЯЂздДјЪБМфДСЃЌИљОнЯћЯЂЕФЪБМфДСНјааДІРэЃЌШЗБЃЪБМфДСдкЭЌвЛИіЪБМфДАПкЕФЫљгаЯћЯЂвЛЖЈЛсБЛе§ШЗДІРэЁЃгЩгкЯћЯЂПЩФмТвађСїШыTaskЃЌЫљвдTaskашвЊЛКДцЕБЧАЪБМфДАПкЯћЯЂДІРэЕФзДЬЌЃЌжБЕНШЗШЯЪєгкИУЪБМфДАПкЕФЫљгаЯћЯЂЖМБЛДІРэЃЌВХПЩвдЪЭЗХЃЌШчЙћТвађЕФЯћЯЂбгГйКмИпЛсгАЯьЗжВМЪНЯЕЭГЕФЭЬЭТСПКЭбгГйЁЃ
Ingress TimeЁЃгаЪБЯћЯЂБОЩэВЂВЛДјгаЪБМфДСаХЯЂЃЌЕЋгУЛЇвРШЛЯЃЭћАДееЯћЯЂЖјВЛЪЧНкЕуЪБжгЛЎЗжЪБМфДАПкЃЌР§ШчБмУтЩЯУцЬсЕНЕФЕкЖўИіЮЪЬтЃЌДЫЪБПЩвддкЯћЯЂдДСїШыFlinkСїДІРэЯЕЭГЪБздЖЏЩњГЩдіСПЕФЪБМфДСИГгшЯћЯЂЃЌжЎКѓДІРэЕФСїГЬгыEvent
TimeЯрЭЌЁЃIngress TimeПЩвдПДГЩЪЧEvent TimeЕФвЛИіЬиР§ЃЌгЩгкЦфдкЯћЯЂдДДІЪБМфДСвЛЖЈЪЧгаађЕФЃЌЫљвддкСїДІРэЯЕЭГжаЃЌЯрЖдгкEvent
TimeЃЌЦфТвађЕФЯћЯЂбгГйВЛЛсКмИпЃЌвђДЫЖдFlinkЗжВМЪНЯЕЭГЕФЭЬЭТСПКЭбгГйЕФгАЯьвВЛсИќаЁЁЃ
Event TimeЪБМфДАПкЕФЪЕЯж
FlinkНшМјСЫGoogleЕФMillWheelЯюФПЃЌЭЈЙ§WaterMarkРДжЇГжЛљгкEvent TimeЕФЪБМфДАПкЁЃ
ЕБВйзїЗћЭЈЙ§ЛљгкEvent TimeЕФЪБМфДАПкРДДІРэЪ§ОнЪБЃЌЫќБиаыдкШЗЖЈЫљгаЪєгкИУЪБМфДАПкЕФЯћЯЂШЋВПСїШыДЫВйзїЗћКѓВХФмПЊЪМЪ§ОнДІРэЁЃЕЋЪЧгЩгкЯћЯЂПЩФмЪЧТвађЕФЃЌЫљвдВйзїЗћЮоЗЈжБНгШЗШЯКЮЪБЫљгаЪєгкИУЪБМфДАПкЕФЯћЯЂШЋВПСїШыДЫВйзїЗћЁЃWaterMarkАќКЌвЛИіЪБМфДСЃЌFlinkЪЙгУWaterMarkБъМЧЫљгааЁгкИУЪБМфДСЕФЯћЯЂЖМвбСїШыЃЌFlinkЕФЪ§ОндДдкШЗШЯЫљгааЁгкФГИіЪБМфДСЕФЯћЯЂЖМвбЪфГіЕНFlinkСїДІРэЯЕЭГКѓЃЌЛсЩњГЩвЛИіАќКЌИУЪБМфДСЕФWaterMarkЃЌВхШыЕНЯћЯЂСїжаЪфГіЕНFlinkСїДІРэЯЕЭГжаЃЌFlinkВйзїЗћАДееЪБМфДАПкЛКДцЫљгаСїШыЕФЯћЯЂЃЌЕБВйзїЗћДІРэЕНWaterMarkЪБЃЌЫќЖдЫљгааЁгкИУWaterMarkЪБМфДСЕФЪБМфДАПкЪ§ОнНјааДІРэВЂЗЂЫЭЕНЯТвЛИіВйзїЗћНкЕуЃЌШЛКѓвВНЋWaterMarkЗЂЫЭЕНЯТвЛИіВйзїЗћНкЕуЁЃ
ЮЊСЫБЃжЄФмЙЛДІРэЫљгаЪєгкФГИіЪБМфДАПкЕФЯћЯЂЃЌВйзїЗћБиаыЕШЕНДѓгкетИіЪБМфДАПкЕФWaterMarkжЎКѓВХФмПЊЪМЖдИУЪБМфДАПкЕФЯћЯЂНјааДІРэЃЌЯрЖдгкЛљгкOperator
TimeЕФЪБМфДАПкЃЌFlinkашвЊеМгУИќЖрФкДцЃЌЧвЛсжБНггАЯьЯћЯЂДІРэЕФбгГйЪБМфЁЃЖдДЫЃЌвЛИіПЩФмЕФгХЛЏДыЪЉЪЧЃЌЖдгкОлКЯРрЕФВйзїЗћЃЌПЩвдЬсЧАЖдВПЗжЯћЯЂНјааОлКЯВйзїЃЌЕБгаЪєгкИУЪБМфДАПкЕФаТЯћЯЂСїШыЪБЃЌЛљгкжЎЧАЕФВПЗжОлКЯНсЙћМЬајМЦЫуЃЌетбљЕФЛАЃЌжЛашЛКДцжаМфМЦЫуНсЙћМДПЩЃЌЮоашЛКДцИУЪБМфДАПкЕФЫљгаЯћЯЂЁЃ
ЖдгкЛљгкEvent TimeЪБМфДАПкЕФВйзїЗћРДЫЕЃЌСїШыWaterMarkЕФЪБМфДСгыЕБЧАНкЕуЕФЪБжгвЛжТЪЧзюМђЕЅРэЯыЕФзДПіЃЌЕЋЪЧдкЪЕМЪЛЗОГжаЪЧВЛПЩФмЕФЃЌгЩгкЯћЯЂЕФТвађвдМАЧАУцНкЕуДІРэаЇТЪЕФВЛЭЌЃЌзмЪЧЛсгаФГаЉЯћЯЂСїШыЪБМфДѓгкЦфБОЩэЕФЪБМфДСЃЌецЪЕWaterMarkЪБМфДСгыРэЯыЧщПіЯТWaterMarkЪБМфДСЕФВюБ№ГЦЮЊTime
SkewЃЌШчЭМ5ЫљЪОЃК

ЭМ5 WaterMarkЕФTime SkewЭМ
Time SkewОіЖЈСЫИУWaterMarkгыЩЯвЛИіWaterMarkжЎМфЕФЪБМфДАПкЫљгаЪ§ОнашвЊЛКДцЕФЪБМфЃЌTime
SkewЪБМфдНГЄЃЌИУЪБМфДАПкЪ§ОнЕФбгГйдНГЄЃЌеМгУФкДцЕФЪБМфвВдНГЄЃЌЭЌЪБЛсЖдСїДІРэЯЕЭГЕФЭЬЭТСПВњЩњИКУцгАЯьЁЃ
ЛљгкЪБМфДСЕФХХађ
дкСїДІРэЯЕЭГжаЃЌгЩгкСїШыЕФЯћЯЂЪЧЮоЯоЕФЃЌЫљвдЖдЯћЯЂНјааХХађЛљБОЩЯБЛШЯЮЊЪЧВЛПЩааЕФЁЃЕЋЪЧдкFlinkСїДІРэЯЕЭГжаЃЌЛљгкWaterMarkЃЌFlinkЪЕЯжСЫЛљгкЪБМфДСЕФШЋОжХХађЁЃХХађЕФЪЕЯжЫМТЗШчЯТЃКХХађВйзїЗћЛКДцЫљгаСїШыЕФЯћЯЂЃЌЕБЦфНгЪеЕНWaterMarkЪБЃЌЖдЪБМфДСаЁгкИУWaterMarkЕФЯћЯЂНјааХХађЃЌВЂЗЂЫЭЕНЯТвЛИіНкЕуЃЌдкДЫХХађВйзїЗћжаЪЭЗХЫљгаЪБМфДСаЁгкИУWaterMarkЕФЯћЯЂЃЌМЬајЛКДцСїШыЕФЯћЯЂЃЌЕШД§ЯТвЛИіWaterMarkДЅЗЂЯТвЛДЮХХађЁЃ
гЩгкWaterMarkБЃжЄСЫдкЦфжЎКѓВЛЛсГіЯжЪБМфДСБШЫќаЁЕФЯћЯЂЃЌЫљвдПЩвдБЃжЄХХађЕФе§ШЗадЁЃашвЊзЂвтЕФЪЧЃЌШчЙћХХађВйзїЗћгаЖрИіНкЕуЃЌжЛФмБЃжЄУПИіНкЕуЕФСїГіЯћЯЂЪЧгаађЕФЃЌНкЕужЎМфЕФЯћЯЂВЛФмБЃжЄгаађЃЌвЊЪЕЯжШЋОжгаађЃЌдђжЛФмгавЛИіХХађВйзїЗћНкЕуЁЃ
ЭЈЙ§жЇГжЛљгкEvent TimeЕФЯћЯЂДІРэЃЌFlinkРЉеЙСЫЦфСїДІРэЯЕЭГЕФгІгУЗЖЮЇЃЌЪЙЕУИќЖрЕФСїДІРэШЮЮёПЩвдЭЈЙ§FlinkРДжДааЁЃ
ЖЈжЦЕФФкДцЙмРэ
FlinkЯюФПЛљгкJavaМАScalaЕШJVMгябдЃЌJVMБОЩэзїЮЊвЛИіИїжжРраЭгІгУЕФжДааЦНЬЈЃЌЦфЖдJavaЖдЯѓЕФЙмРэвВЪЧЛљгкЭЈгУЕФДІРэВпТдЃЌЦфРЌЛјЛиЪеЦїЭЈЙ§ЙРЫуJavaЖдЯѓЕФЩњУќжмЦкЖдJavaЖдЯѓНјаагааЇТЪЕФЙмРэЁЃ
еыЖдВЛЭЌРраЭЕФгІгУЃЌгУЛЇПЩФмашвЊеыЖдИУРраЭгІгУЕФЬиЕуЃЌХфжУеыЖдадЕФJVMВЮЪ§ИќгааЇТЪЕФЙмРэJavaЖдЯѓЃЌДгЖјЬсИпадФмЁЃетжжJVMЕїгХЕФКкФЇЗЈашвЊгУЛЇЖдгІгУБОЩэМАJVMЕФИїВЮЪ§гаЩюШыСЫНтЃЌМЋДѓЕиЬсИпСЫЗжВМЪНМЦЫуЦНЬЈЕФЕїгХУХМїЁЃFlinkПђМмБОЩэСЫНтМЦЫуТпМУПИіВНжшЕФЪ§ОнДЋЪфЃЌЯрБШгкJVMРЌЛјЛиЪеЦїЃЌЦфСЫНтИќЖрЕФJavaЖдЯѓЩњУќжмЦкЃЌДгЖјЮЊИќгааЇТЪЕиЙмРэJavaЖдЯѓЬсЙЉСЫПЩФмЁЃ
JVMДцдкЕФЮЪЬт
JavaЖдЯѓПЊЯњ
ЯрЖдгкc/c++ЕШИќМгНгНќЕзВуЕФгябдЃЌJavaЖдЯѓЕФДцДЂУмЖШЯрЖдЦЋЕЭЃЌР§Шч[1]ЃЌЁАabcdЁБетбљМђЕЅЕФзжЗћДЎдкUTF-8БрТыжаашвЊ4ИізжНкДцДЂЃЌЕЋВЩгУСЫUTF-16БрТыДцДЂзжЗћДЎЕФJavaдђашвЊ8ИізжНкЃЌЭЌЪБJavaЖдЯѓЛЙгаheaderЕШЦфЫћЖюЭтаХЯЂЃЌвЛИі4зжНкзжЗћДЎЖдЯѓдкJavaжаашвЊ48зжНкЕФПеМфРДДцДЂЁЃЖдгкДѓВПЗжЕФДѓЪ§ОнгІгУЃЌФкДцЖМЪЧЯЁШБзЪдДЃЌИќгааЇТЪЕиФкДцДцДЂЃЌвтЮЖзХCPUЪ§ОнЗУЮЪЭЬЭТСПИќИпЃЌвдМАИќЩйДХХЬТфЕиЕФДцдкЁЃ
ЖдЯѓДцДЂНсЙЙв§ЗЂЕФcache miss
ЮЊСЫЛКНтCPUДІРэЫйЖШгыФкДцЗУЮЪЫйЖШЕФВюОр[2]ЃЌЯжДњCPUЪ§ОнЗУЮЪвЛАуЖМЛсгаЖрМЖЛКДцЁЃЕБДгФкДцМгдиЪ§ОнЕНЛКДцЪБЃЌвЛАуЪЧвдcache
lineЮЊЕЅЮЛМгдиЪ§ОнЃЌЫљвдЕБCPUЗУЮЪЕФЪ§ОнШчЙћЪЧдкФкДцжаСЌајДцДЂЕФЛАЃЌЗУЮЪЕФаЇТЪЛсЗЧГЃИпЁЃШчЙћCPUвЊЗУЮЪЕФЪ§ОнВЛдкЕБЧАЛКДцЫљгаЕФcache
lineжаЃЌдђашвЊДгФкДцжаМгдиЖдгІЕФЪ§ОнЃЌетБЛГЦЮЊвЛДЮcache missЁЃЕБcache missЗЧГЃИпЕФЪБКђЃЌCPUДѓВПЗжЕФЪБМфЖМдкЕШД§Ъ§ОнМгдиЃЌЖјВЛЪЧеце§ЕФДІРэЪ§ОнЁЃJavaЖдЯѓВЂВЛЪЧСЌајЕФДцДЂдкФкДцЩЯЃЌЭЌЪБКмЖрЕФJavaЪ§ОнНсЙЙЕФЪ§ОнОлМЏадвВВЛКУЁЃ
ДѓЪ§ОнЕФРЌЛјЛиЪе
JavaЕФРЌЛјЛиЪеЛњжЦвЛжБШУJavaПЊЗЂепгжАЎгжКоЃЌвЛЗНУцЫќУтШЅСЫПЊЗЂепздМКЛиЪезЪдДЕФВНжшЃЌЬсИпСЫПЊЗЂаЇТЪЃЌМѕЩйСЫФкДцаЙТЉЕФПЩФмЃЌСэвЛЗНУцРЌЛјЛиЪевВЪЧJavaгІгУЕФВЛЖЈЪБеЈЕЏЃЌгаЪБУыМЖЩѕжСЪЧЗжжгМЖЕФРЌЛјЛиЪеМЋДѓгАЯьСЫJavaгІгУЕФадФмКЭПЩгУадЁЃдкЪБЯТЪ§ОнжааФЃЌДѓШнСПФкДцЕУЕНСЫЙуЗКЕФгІгУЃЌЩѕжСГіЯжСЫЕЅЬЈЛњЦїХфжУTBФкДцЕФЧщПіЃЌЭЌЪБЃЌДѓЪ§ОнЗжЮіЭЈГЃЛсБщРњећИідДЪ§ОнМЏЃЌЖдЪ§ОнНјаазЊЛЛЁЂЧхЯДЁЂДІРэЕШВНжшЁЃдкетИіЙ§ГЬжаЃЌЛсВњЩњКЃСПЕФJavaЖдЯѓЃЌJVMЕФРЌЛјЛиЪежДаааЇТЪЖдадФмгаКмДѓгАЯьЁЃЭЈЙ§JVMВЮЪ§ЕїгХЬсИпРЌЛјЛиЪеаЇТЪашвЊгУЛЇЖдгІгУКЭЗжВМЪНМЦЫуПђМмвдМАJVMЕФИїВЮЪ§гаЩюШыСЫНтЃЌЖјЧвгаЪБКђетвВдЖдЖВЛЙЛЁЃ
OOMЮЪЬт
OutOfMemoryErrorЪЧЗжВМЪНМЦЫуПђМмОГЃЛсгіЕНЕФЮЪЬтЃЌЕБJVMжаЫљгаЖдЯѓДѓаЁГЌЙ§ЗжХфИјJVMЕФФкДцДѓаЁЪБЃЌОЭЛсГіЯжOutOfMemoryErrorДэЮѓЃЌJVMБРРЃЃЌЗжВМЪНПђМмЕФНЁзГадКЭадФмЖМЛсЪмЕНгАЯьЁЃЭЈЙ§JVMЙмРэФкДцЃЌЭЌЪБЪдЭМНтОіOOMЮЪЬтЕФгІгУЃЌЭЈГЃЖМашвЊМьВщJavaЖдЯѓЕФДѓаЁЃЌВЂдкФГаЉДцДЂJavaЖдЯѓЬиБ№ЖрЕФЪ§ОнНсЙЙжаЩшжУуажЕНјааПижЦЁЃЕЋЪЧJVMВЂУЛгаЬсЙЉЙйЗНМьВщJavaЖдЯѓДѓаЁЕФЙЄОпЃЌЕкШ§ЗНЕФЙЄОпРрПтПЩФмЮоЗЈзМШЗЭЈгУЕиШЗЖЈJavaЖдЯѓДѓаЁ[6]ЁЃЧжШыЪНЕФуажЕМьВщвВЛсЮЊЗжВМЪНМЦЫуПђМмЕФЪЕЯждіМгКмЖрЖюЭтгывЕЮёТпМЮоЙиЕФДњТыЁЃ
FlinkЕФДІРэВпТд
ЮЊСЫНтОівдЩЯЬсЕНЕФЮЪЬтЃЌИпадФмЗжВМЪНМЦЫуПђМмЭЈГЃашвЊвдЯТММЪѕЃК
ЖЈжЦЕФађСаЛЏЙЄОпЁЃЯдЪНФкДцЙмРэЕФЧАЬсВНжшОЭЪЧађСаЛЏЃЌНЋJavaЖдЯѓађСаЛЏГЩЖўНјжЦЪ§ОнДцДЂдкФкДцЩЯЃЈon
heapЛђЪЧoff-heapЃЉЁЃЭЈгУЕФађСаЛЏПђМмЃЌШчJavaФЌШЯЪЙгУjava.io.SerializableНЋJavaЖдЯѓМАЦфГЩдББфСПЕФЫљгадЊаХЯЂзїЮЊЦфађСаЛЏЪ§ОнЕФвЛВПЗжЃЌађСаЛЏКѓЕФЪ§ОнАќКЌСЫЫљгаЗДађСаЛЏЫљашЕФаХЯЂЁЃетдкФГаЉГЁОАжаЪЎЗжБивЊЃЌЕЋЪЧЖдгкFlinkетбљЕФЗжВМЪНМЦЫуПђМмРДЫЕЃЌетаЉдЊЪ§ОнаХЯЂПЩФмЪЧШпгрЪ§ОнЁЃЖЈжЦЕФађСаЛЏПђМмЃЌШчHadoopЕФorg.apache.hadoop.io.WritableашвЊгУЛЇЪЕЯжИУНгПкЃЌВЂздЖЈвхРрЕФађСаЛЏКЭЗДађСаЛЏЗНЗЈЁЃетжжЗНЪНаЇТЪзюИпЃЌЕЋашвЊгУЛЇЖюЭтЕФЙЄзїЃЌВЛЙЛгбКУЁЃ
ЯдЪНЕФФкДцЙмРэЁЃвЛАуЭЈгУЕФзіЗЈЪЧХњСПЩъЧыКЭЪЭЗХФкДцЃЌУПИіJVMЪЕР§гавЛИіЭГвЛЕФФкДцЙмРэЦїЃЌЫљгаФкДцЕФЩъЧыКЭЪЭЗХЖМЭЈЙ§ИУФкДцЙмРэЦїНјааЁЃетПЩвдБмУтГЃМћЕФФкДцЫщЦЌЮЪЬтЃЌЭЌЪБгЩгкЪ§ОнвдЖўНјжЦЕФЗНЪНДцДЂЃЌПЩвдДѓДѓМѕЧсРЌЛјЛиЪебЙСІЁЃ
ЛКДцгбКУЕФЪ§ОнНсЙЙКЭЫуЗЈЁЃЖдгкМЦЫуУмМЏЕФЪ§ОнНсЙЙКЭЫуЗЈЃЌжБНгВйзїађСаЛЏКѓЕФЖўНјжЦЪ§ОнЃЌЖјВЛЪЧНЋЖдЯѓЗДађСаЛЏКѓдйНјааВйзїЁЃЭЌЪБЃЌжЛНЋВйзїЯрЙиЕФЪ§ОнСЌајДцДЂЃЌПЩвдзюДѓЛЏЕФРћгУL1/L2/L3ЛКДцЃЌМѕЩйCache
missЕФИХТЪЃЌЬсЩ§CPUМЦЫуЕФЭЬЭТСПЁЃвдХХађЮЊР§ЃЌгЩгкХХађЕФжївЊВйзїЪЧЖдKeyНјааЖдБШЃЌШчЙћНЋЫљгаХХађЪ§ОнЕФKeyгыValueЗжПЊВЂЖдKeyСЌајДцДЂЃЌФЧУДЗУЮЪKeyЪБЕФCacheУќжаТЪЛсДѓДѓЬсИпЁЃ
ЖЈжЦЕФађСаЛЏЙЄОп
ЗжВМЪНМЦЫуПђМмПЩвдЪЙгУЖЈжЦађСаЛЏЙЄОпЕФЧАЬсЪЧвЊД§ДІРэЪ§ОнСїЭЈГЃЪЧЭЌвЛРраЭЃЌгЩгкЪ§ОнМЏЖдЯѓЕФРраЭЙЬЖЈЃЌДгЖјПЩвджЛБЃДцвЛЗнЖдЯѓSchemaаХЯЂЃЌНкЪЁДѓСПЕФДцДЂПеМфЁЃЭЌЪБЃЌЖдгкЙЬЖЈДѓаЁЕФРраЭЃЌвВПЩЭЈЙ§ЙЬЖЈЕФЦЋвЦЮЛжУДцШЁЁЃдкашвЊЗУЮЪФГИіЖдЯѓГЩдББфСПЪБЃЌЭЈЙ§ЖЈжЦЕФађСаЛЏЙЄОпЃЌВЂВЛашвЊЗДађСаЛЏећИіJavaЖдЯѓЃЌЖјЪЧжБНгЭЈЙ§ЦЋвЦСПЃЌДгЖјжЛашвЊЗДађСаЛЏЬиЖЈЕФЖдЯѓГЩдББфСПЁЃШчЙћЖдЯѓЕФГЩдББфСПНЯЖрЪБЃЌФмЙЛДѓДѓМѕЩйJavaЖдЯѓЕФДДНЈПЊЯњЃЌвдМАФкДцЪ§ОнЕФПНБДДѓаЁЁЃFlinkЪ§ОнМЏЖМжЇГжШЮвтJavaЛђЪЧScalaРраЭЃЌЭЈЙ§здЖЏЩњГЩЖЈжЦађСаЛЏЙЄОпЃЌМШБЃжЄСЫAPIНгПкЖдгУЛЇгбКУЃЈВЛгУЯёHadoopФЧбљЪ§ОнРраЭашвЊМЬГаЪЕЯжorg.apache.hadoop.io.WritableНгПкЃЉЃЌвВДяЕНСЫКЭHadoopРрЫЦЕФађСаЛЏаЇТЪЁЃ
FlinkЖдЪ§ОнМЏЕФРраЭаХЯЂНјааЗжЮіЃЌШЛКѓздЖЏЩњГЩЖЈжЦЕФађСаЛЏЙЄОпРрЁЃFlinkжЇГжШЮвтЕФJavaЛђЪЧScalaРраЭЃЌЭЈЙ§Java
ReflectionПђМмЗжЮіЛљгкJavaЕФFlinkГЬађUDFЃЈUser Define FunctionЃЉЕФЗЕЛиРраЭЕФРраЭаХЯЂЃЌЭЈЙ§Scala
CompilerЗжЮіЛљгкScalaЕФFlinkГЬађUDFЕФЗЕЛиРраЭЕФРраЭаХЯЂЁЃРраЭаХЯЂгЩTypeInformationРрБэЪОЃЌетИіРргажюЖрОпЬхЪЕЯжРрЃЌР§ШчЃК
BasicTypeInfoШЮвтJavaЛљБОРраЭЃЈзААќЛђЮДзААќЃЉКЭStringРраЭЁЃ
BasicArrayTypeInfoШЮвтJavaЛљБОРраЭЪ§зщЃЈзААќЛђЮДзААќЃЉКЭStringЪ§зщЁЃ
WritableTypeInfoШЮвтHadoopЕФWritableНгПкЕФЪЕЯжРрЁЃ
TupleTypeInfoШЮвтЕФFlink tupleРраЭ(жЇГжTuple1 to Tuple25)ЁЃ
Flink tuplesЪЧЙЬЖЈГЄЖШЙЬЖЈРраЭЕФJava TupleЪЕЯжЁЃ
CaseClassTypeInfoШЮвтЕФ Scala CaseClass(АќРЈ Scala tuples)ЁЃ
PojoTypeInfoШЮвтЕФPOJO (Java or Scala)ЃЌР§ШчJavaЖдЯѓЕФЫљгаГЩдББфСПЃЌвЊУДЪЧpublicаоЪЮЗћЖЈвхЃЌвЊУДгаgetter/setterЗНЗЈЁЃ
GenericTypeInfoШЮвтЮоЗЈЦЅХфжЎЧАМИжжРраЭЕФРрЁЃ
ЧА6жжРраЭЪ§ОнМЏМИКѕИВИЧСЫОјДѓВПЗжЕФFlinkГЬађЃЌеыЖдЧА6жжРраЭЪ§ОнМЏЃЌFlinkНдПЩвдздЖЏЩњГЩЖдгІЕФTypeSerializerЖЈжЦађСаЛЏЙЄОпЃЌЗЧГЃгааЇТЪЕиЖдЪ§ОнМЏНјааађСаЛЏКЭЗДађСаЛЏЁЃЖдгкЕк7жжРраЭЃЌFlinkЪЙгУKryoНјааађСаЛЏКЭЗДађСаЛЏЁЃДЫЭтЃЌЖдгкПЩБЛгУзїKeyЕФРраЭЃЌFlinkЛЙЭЌЪБздЖЏЩњГЩTypeComparatorЃЌгУРДИЈжњжБНгЖдађСаЛЏКѓЕФЖўНјжЦЪ§ОнжБНгНјааcompareЁЂhashЕШВйзїЁЃЖдгкTupleЁЂCaseClassЁЂPojoЕШзщКЯРраЭЃЌFlinkздЖЏЩњГЩЕФTypeSerializerЁЂTypeComparatorЭЌбљЪЧзщКЯЕФЃЌВЂАбЦфГЩдБЕФађСаЛЏ/ЗДађСаЛЏДњРэИјЦфГЩдБЖдгІЕФTypeSerializerЁЂTypeComparatorЃЌШчЭМ6ЫљЪОЃК

ЭМ6 FlinkзщКЯРраЭађСаЛЏ
ДЫЭтШчгаашвЊЃЌгУЛЇПЩЭЈЙ§МЏГЩTypeInformationНгПкЖЈжЦЪЕЯжздМКЕФађСаЛЏЙЄОпЁЃ
ЯдЪНЕФФкДцЙмРэ
РЌЛјЛиЪеЪЧJVMФкДцЙмРэЛиБмВЛСЫЕФЮЪЬтЃЌJDK8ЕФG1ЫуЗЈИФЩЦСЫJVMРЌЛјЛиЪеЕФаЇТЪКЭПЩгУЗЖЮЇЃЌЕЋЖдгкДѓЪ§ОнДІРэЪЕМЪЛЗОГЛЙдЖдЖВЛЙЛЁЃетвВКЭЯждкЗжВМЪНПђМмЕФЗЂеЙЧїЪЦгаЫљГхЭЛЃЌдНРДдНЖрЕФЗжВМЪНМЦЫуПђМмЯЃЭћОЁПЩФмЖрЕиНЋД§ДІРэЪ§ОнМЏЗХШыФкДцЃЌЖјЖдгкJVMРЌЛјЛиЪеРДЫЕЃЌФкДцжаJavaЖдЯѓдНЩйЁЂДцЛюЪБМфдНЖЬЃЌЦфаЇТЪдНИпЁЃЭЈЙ§JVMНјааФкДцЙмРэЕФЛАЃЌOutOfMemoryErrorвВЪЧвЛИіКмФбНтОіЕФЮЪЬтЁЃЭЌЪБЃЌдкJVMФкДцЙмРэжаЃЌJavaЖдЯѓгаЧБдкЕФЫщЦЌЛЏДцДЂЮЪЬтЃЈJavaЖдЯѓЫљгааХЯЂПЩФмдкФкДцжаСЌајДцДЂЃЉЃЌвВгаПЩФмдкЫљгаJavaЖдЯѓДѓаЁУЛгаГЌЙ§JVMЗжХфФкДцЪБЃЌГіЯжOutOfMemoryErrorЮЪЬтЁЃFlinkНЋФкДцЗжЮЊ3ИіВПЗжЃЌУПИіВПЗжЖМгаВЛЭЌгУЭОЃК
Network buffers: вЛаЉвд32KB ByteЪ§зщЮЊЕЅЮЛЕФbufferЃЌжївЊБЛЭјТчФЃПщгУгкЪ§ОнЕФЭјТчДЋЪфЁЃ
Memory Manager poolДѓСПвд32KB ByteЪ§зщЮЊЕЅЮЛЕФФкДцГиЃЌЫљгаЕФдЫааЪБЫуЗЈЃЈР§ШчSort/Shuffle/JoinЃЉЖМДгетИіФкДцГиЩъЧыФкДцЃЌВЂНЋађСаЛЏКѓЕФЪ§ОнДцДЂЦфжаЃЌНсЪјКѓЪЭЗХЛиФкДцГиЁЃ
Remaining (Free) HeapжївЊСєИјUDFжагУЛЇздМКДДНЈЕФJavaЖдЯѓЃЌгЩJVMЙмРэЁЃ
Network buffersдкFlinkжажївЊЛљгкNettyЕФЭјТчДЋЪфЃЌЮоашЖрНВЁЃRemaining
HeapгУгкUDFжагУЛЇздМКДДНЈЕФJavaЖдЯѓЃЌдкUDFжаЃЌгУЛЇЭЈГЃЪЧСїЪНЕФДІРэЪ§ОнЃЌВЂВЛашвЊКмЖрФкДцЃЌЭЌЪБFlinkвВВЛЙФРјгУЛЇдкUDFжаЛКДцКмЖрЪ§ОнЃЌвђЮЊетЛсв§Ц№ЧАУцЬсЕНЕФжюЖрЮЪЬтЁЃMemory
Manager poolЃЈвдКѓвдФкДцГиДњжИЃЉЭЈГЃЛсХфжУЮЊзюДѓЕФвЛПщФкДцЃЌНгЯТРДЛсЯъЯИНщЩмЁЃ
дкFlinkжаЃЌФкДцГигЩЖрИіMemorySegmentзщГЩЃЌУПИіMemorySegmentДњБэвЛПщСЌајЕФФкДцЃЌЕзВуДцДЂЪЧbyte[]ЃЌФЌШЯ32KBДѓаЁЁЃMemorySegmentЬсЙЉСЫИљОнЦЋвЦСПЗУЮЪЪ§ОнЕФИїжжЗНЗЈЃЌШчget/put
intЁЂlongЁЂfloatЁЂdoubleЕШЃЌMemorySegmentжЎМфЪ§ОнПНБДЕШЗНЗЈКЭjava.nio.ByteBufferРрЫЦЁЃЖдгкFlinkЕФЪ§ОнНсЙЙЃЌЭЈГЃАќРЈЖрИіЯђФкДцГиЩъЧыЕФMemeorySegmentЃЌЫљгавЊДцШыЕФЖдЯѓЭЈЙ§TypeSerializerађСаЛЏжЎКѓЃЌНЋЖўНјжЦЪ§ОнДцДЂдкMemorySegmentжаЃЌдкШЁГіЪБЭЈЙ§TypeSerializerЗДађСаЛЏЁЃЪ§ОнНсЙЙЭЈЙ§MemorySegmentЬсЙЉЕФset/getЗНЗЈЗУЮЪОпЬхЕФЖўНјжЦЪ§ОнЁЃFlinkетжжПДЦ№РДБШНЯИДдгЕФФкДцЙмРэЗНЪНДјРДЕФКУДІжївЊгаЃК
ЖўНјжЦЕФЪ§ОнДцДЂДѓДѓЬсИпСЫЪ§ОнДцДЂУмЖШЃЌНкЪЁСЫДцДЂПеМфЁЃ
ЫљгаЕФдЫааЪБЪ§ОнНсЙЙКЭЫуЗЈжЛФмЭЈЙ§ФкДцГиЩъЧыФкДцЃЌБЃжЄСЫЦфЪЙгУЕФФкДцДѓаЁЪЧЙЬЖЈЕФЃЌВЛЛсвђЮЊдЫааЪБЪ§ОнНсЙЙКЭЫуЗЈЖјЗЂЩњOOMЁЃЖдгкДѓВПЗжЕФЗжВМЪНМЦЫуПђМмРДЫЕЃЌетВПЗжгЩгквЊЛКДцДѓСПЪ§ОнзюгаПЩФмЕМжТOOMЁЃ
ФкДцГиЫфШЛеМОнСЫДѓВПЗжФкДцЃЌЕЋЦфжаЕФMemorySegmentШнСПНЯДѓЃЈФЌШЯ32KBЃЉЃЌЫљвдФкДцГижаЕФJavaЖдЯѓЦфЪЕКмЩйЃЌЖјЧввЛжББЛФкДцГив§гУЃЌЫљгадкРЌЛјЛиЪеЪБКмПьНјШыГжОУДњЃЌДѓДѓМѕЧсСЫJVMРЌЛјЛиЪеЕФбЙСІЁЃ
Remaining HeapЕФФкДцЫфШЛгЩJVMЙмРэЃЌЕЋЪЧгЩгкЦфжївЊгУРДДцДЂгУЛЇДІРэЕФСїЪНЪ§ОнЃЌЩњУќжмЦкЗЧГЃЖЬЃЌЫйЖШКмПьЕФMinor
GCОЭЛсШЋВПЛиЪеЕєЃЌвЛАуВЛЛсДЅЗЂFull GCЁЃ
FlinkЕБЧАЕФФкДцЙмРэдкзюЕзВуЪЧЛљгкbyte[]ЃЌЫљвдЪ§ОнзюжеЛЙЪЧon-heapЃЌзюНќFlinkдіМгСЫoff-heapЕФФкДцЙмРэжЇГжЁЃFlink
off-heapЕФФкДцЙмРэЯрЖдгкon-heapЕФгХЕужївЊдкгкЃК
ЦєЖЏЗжХфСЫДѓФкДц(Р§Шч100G)ЕФJVMКмКФЗбЪБМфЃЌРЌЛјЛиЪевВКмТ§ЁЃШчЙћВЩгУoff-heapЃЌЪЃЯТЕФNetwork
bufferКЭRemaining heapЖМЛсКмаЁЃЌРЌЛјЛиЪевВВЛгУПМТЧMemorySegmentжаЕФJavaЖдЯѓСЫЁЃ
ИќгааЇТЪЕФIOВйзїЁЃдкoff-heapЯТЃЌНЋMemorySegmentаДЕНДХХЬЛђЪЧЭјТчПЩвджЇГжzeor-copyММЪѕЃЌЖјon-heapЕФЛАдђжСЩйашвЊвЛДЮФкДцПНБДЁЃ
off-heapПЩгУгкДэЮѓЛжИДЃЌБШШчJVMБРРЃЃЌдкon-heapЪБЪ§ОнвВЫцжЎЖЊЪЇЃЌЕЋдкoff-heapЯТЃЌoff-heapЕФЪ§ОнПЩФмЛЙдкЁЃДЫЭтЃЌoff-heapЩЯЕФЪ§ОнЛЙПЩвдКЭЦфЫћГЬађЙВЯэЁЃ
ЛКДцгбКУЕФМЦЫу
ДХХЬIOКЭЭјТчIOжЎЧАвЛжББЛШЯЮЊЪЧHadoopЯЕЭГЕФЦПОБЃЌЕЋЪЧЫцзХSparkЁЂFlinkЕШаТвЛДњЗжВМЪНМЦЫуПђМмЕФЗЂеЙЃЌдНРДдНЖрЕФЧїЪЦЪЙЕУCPU/Memoryж№НЅГЩЮЊЦПОБЃЌетаЉЧїЪЦАќРЈЃК
ИќЯШНјЕФIOгВМўж№НЅЦеМАЁЃ10GBЭјТчКЭSSDгВХЬЕШвбОБЛдНРДдНЖрЕФЪ§ОнжааФЪЙгУЁЃ
ИќИпаЇЕФДцДЂИёЪНЁЃParquetЃЌORCЕШСаЪНДцДЂБЛдНРДдНЖрЕФHadoopЯюФПжЇГжЃЌЦфЗЧГЃИпаЇЕФбЙЫѕадФмДѓДѓМѕЩйСЫТфЕиДцДЂЕФЪ§ОнСПЁЃ
ИќИпаЇЕФжДааМЦЛЎЁЃР§ШчКмЖрSQLЯЕЭГжДааМЦЛЎгХЛЏЦїЕФFliter-Push-DownгХЛЏЛсНЋЙ§ТЫЬѕМўОЁПЩФмЕФЬсЧАЃЌЩѕжСЬсЧАЕНParquetЕФЪ§ОнЗУЮЪВуЃЌЪЙЕУдкКмЖрЪЕМЪЕФЙЄзїИКдижаВЂВЛашвЊКмЖрЕФДХХЬIOЁЃ
гЩгкCPUДІРэЫйЖШКЭФкДцЗУЮЪЫйЖШЕФВюОрЃЌЬсЩ§CPUЕФДІРэаЇТЪЕФЙиМќдкгкзюДѓЛЏЕФРћгУL1/L2/L3/MemoryЃЌМѕЩйШЮКЮВЛБивЊЕФCache
missЁЃЖЈжЦЕФађСаЛЏЙЄОпИјFlinkЬсЙЉСЫПЩФмЃЌЭЈЙ§ЖЈжЦЕФађСаЛЏЙЄОпЃЌFlinkЗУЮЪЕФЖўНјжЦЪ§ОнБОЩэЃЌвђЮЊеМгУФкДцНЯаЁЃЌДцДЂУмЖШБШНЯДѓЃЌЖјЧвЛЙПЩвддкЩшМЦЪ§ОнНсЙЙКЭЫуЗЈЪБОЁСПСЌајДцДЂЃЌМѕЩйФкДцЫщЦЌЛЏЖдCacheУќжаТЪЕФгАЯьЃЌЩѕжСИќНјвЛВНЃЌFlinkПЩвджЛЪЧНЋашвЊВйзїЕФВПЗжЪ§ОнЃЈШчХХађЪБЕФKeyЃЉСЌајДцДЂЃЌЖјНЋЦфЫћВПЗжЕФЪ§ОнДцДЂдкЦфЫћЕиЗНЃЌДгЖјзюДѓПЩФмЕиЬсЩ§CacheУќжаЕФИХТЪЁЃ
вдFlinkжаЕФХХађЮЊР§ЃЌХХађЭЈГЃЪЧЗжВМЪНМЦЫуПђМмжавЛИіЗЧГЃжиЕФВйзїЃЌFlinkЭЈЙ§ЬиЪтЩшМЦЕФХХађЫуЗЈЛёЕУСЫЗЧГЃКУЕФадФмЃЌЦфХХађЫуЗЈЕФЪЕЯжШчЯТЃК
НЋД§ХХађЕФЪ§ОнОЙ§ађСаЛЏКѓДцДЂдкСНИіВЛЭЌЕФMemorySegmentМЏжаЁЃЪ§ОнШЋВПЕФађСаЛЏжЕДцЗХгкЦфжавЛИіMemorySegmentМЏжаЁЃЪ§ОнађСаЛЏКѓЕФKeyКЭжИЯђЕквЛИіMemorySegmentМЏжажЕЕФжИеыДцЗХгкЕкЖўИіMemorySegmentМЏжаЁЃ
ЖдЕкЖўИіMemorySegmentМЏжаЕФKeyНјааХХађЃЌШчашНЛЛЛKeyЮЛжУЃЌжЛашНЛЛЛЖдгІЕФKey+PointerЕФЮЛжУЃЌЕквЛИіMemorySegmentМЏжаЕФЪ§ОнЮоашИФБфЁЃ
ЕББШНЯСНИіKeyДѓаЁЪБЃЌTypeComparatorЬсЙЉСЫжБНгЛљгкЖўНјжЦЪ§ОнЕФЖдБШЗНЗЈЃЌЮоашЗДађСаЛЏШЮКЮЪ§ОнЁЃ
ХХађЭъГЩКѓЃЌЗУЮЪЪ§ОнЪБЃЌАДееЕкЖўИіMemorySegmentМЏжаKeyЕФЫГађЗУЮЪЃЌВЂЭЈЙ§PointerжЕевЕНЪ§ОндкЕквЛИіMemorySegmentМЏжаЕФЮЛжУЃЌЭЈЙ§TypeSerializerЗДађСаЛЏГЩJavaЖдЯѓЗЕЛиЁЃ

ЭМ7 FlinkХХађЫуЗЈ
етбљЪЕЯжЕФКУДІгаЃК
ЭЈЙ§KeyКЭFull dataЗжРыДцДЂЕФЗНЪНОЁСПНЋБЛВйзїЕФЪ§ОнзюаЁЛЏЃЌЬсИпCacheУќжаЕФИХТЪЃЌДгЖјЬсИпCPUЕФЭЬЭТСПЁЃ
вЦЖЏЪ§ОнЪБЃЌжЛашвЦЖЏKey+PointerЃЌЖјЮоаывЦЖЏЪ§ОнБОЩэЃЌДѓДѓМѕЩйСЫФкДцПНБДЕФЪ§ОнСПЁЃ
TypeComparatorжБНгЛљгкЖўНјжЦЪ§ОнНјааВйзїЃЌНкЪЁСЫЗДађСаЛЏЕФЪБМфЁЃ
ЭЈЙ§ЖЈжЦЕФФкДцЙмРэЃЌFlinkЭЈЙ§ГфЗжРћгУФкДцгыCPUЛКДцЃЌДѓДѓЬсИпСЫCPUЕФжДаааЇТЪЃЌЭЌЪБгЩгкДѓВПЗжФкДцЖМгЩПђМмздМКПижЦЃЌвВКмДѓГЬЖШЬсЩ§СЫЯЕЭГЕФНЁзГадЃЌМѕЩйСЫOOMГіЯжЕФПЩФмЁЃ
змНс
FlinkЪЧвЛИігЕгажюЖрЬиЩЋЕФЯюФПЃЌАќРЈЦфЭГвЛЕФХњДІРэКЭСїДІРэжДаав§ЧцЃЌЭЈгУДѓЪ§ОнМЦЫуПђМмгыДЋЭГЪ§ОнПтЯЕЭГЕФММЪѕНсКЯЃЌвдМАСїДІРэЯЕЭГЕФжюЖрММЪѕДДаТЕШЃЌвђЮЊЦЊЗљгаЯоЃЌFlinkЛЙгавЛаЉЦфЫћКмгавтЫМЕФЬиадУЛгаЯъЯИНщЩмЃЌБШШчDataSet
APIМЖБ№ЕФжДааМЦЛЎгХЛЏЦїЃЌдЩњЕФЕќДњВйзїЗћЕШЃЌИааЫШЄЕФЖСепПЩвдЭЈЙ§FlinkЙйЭјСЫНтИќЖрFlinkЕФЯъЯИФкШнЁЃ
|








