| БрМЭЦМі: |
| БОЮФРДздгк51ctoЃЌБОЮФжївЊНщЩмШчКЮЪЙгУSpark
MLАќЕФAPIвдМАЛњЦїбЇЯАСїЫЎЯпФЃПщЕШЯрЙиФкШнЁЃ |
|

дкетЦЊЮФеТжаЃЌЮвУЧSparkЕФЦфЫќЛњЦїбЇЯАAPIЃЌУћЮЊSpark MLЃЌШчЙћвЊгУЪ§ОнСїЫЎЯпРДПЊЗЂДѓЪ§ОнгІгУГЬађЕФЛАЃЌетИіЪЧЭЦМіЕФНтОіЗНАИЁЃЙиМќЕуЃК
СЫНтЛњЦїбЇЯАЪ§ОнСїЫЎЯпгаЙиФкШнЁЃ
дѕУДгУApache SparkЛњЦїбЇЯААќРДЪЕЯжЛњЦїбЇЯАЪ§ОнСїЫЎЯпЁЃ
Ъ§ОнМлжЕСДДІРэЕФВНжшЁЃ
SparkЛњЦїбЇЯАСїЫЎЯпФЃПщКЭAPIЁЃ
ЮФзжЗжРрКЭЙуИцМьВтгУР§ЁЃ
Spark ML(spark.ml)АќЬсЙЉСЫЙЙНЈдкDataFrameжЎЩЯЕФЛњЦїбЇЯАAPIЃЌЫќвбОГЩСЫSpark
SQLПтЕФКЫаФВПЗжЁЃетИіАќПЩвдгУгкПЊЗЂКЭЙмРэЛњЦїбЇЯАСїЫЎЯпЁЃЫќвВПЩвдЬсЙЉЬиеїГщШЁЦїЁЂзЊЛЛЦїЁЂбЁдёЦїЃЌВЂжЇГжЗжРрЁЂЛуОлКЭЗжДиЕШЛњЦїбЇЯАММЪѕЁЃетаЉШЋЖМЖдПЊЗЂЛњЦїбЇЯАНтОіЗНАИжСЙиживЊЁЃ
дкетРяЮвУЧПДПДШчКЮЪЙгУApache SparkРДзіЬНЫїЪНЪ§ОнЗжЮі(Exploratory Data
Analysis)ЁЂПЊЗЂЛњЦїбЇЯАСїЫЎЯпЃЌВЂЪЙгУSpark MLАќжаЬсЙЉЕФAPIКЭЫуЗЈЁЃ
вђЮЊжЇГжЙЙНЈЛњЦїбЇЯАЪ§ОнСїЫЎЯпЃЌApache SparkПђМмЯждквбОГЩСЫвЛИіЗЧГЃВЛДэЕФбЁдёЃЌПЩвдгУгкЙЙНЈвЛИіШЋУцЕФгУР§ЃЌАќРЈETLЁЂжИСПЗжЮіЁЂЪЕЪБСїЗжЮіЁЂЛњЦїбЇЯАЁЂЭМДІРэКЭПЩЪгЛЏЕШЁЃ
ЛњЦїбЇЯАЪ§ОнСїЫЎЯп
ЛњЦїбЇЯАСїЫЎЯпПЩвдгУгкДДНЈЁЂЕїНкКЭМьбщЛњЦїбЇЯАЙЄзїСїГЬађЕШЁЃЛњЦїбЇЯАСїЫЎЯпПЩвдАяжњЮвУЧИќМгзЈзЂгкЯюФПжаЕФДѓЪ§ОнашЧѓКЭЛњЦїбЇЯАШЮЮёЕШЃЌЖјВЛЪЧАбЪБМфКЭОЋСІЛЈдкЛљДЁЩшЪЉКЭЗжВМЪНМЦЫуСьгђЩЯЁЃЫќвВПЩвддкДІРэЛњЦїбЇЯАЮЪЬтЪБАяжњЮвУЧЃЌдкЬНЫїНзЖЮЮвУЧвЊПЊЗЂЕќДњЪНЙІФмКЭзщКЯФЃаЭЁЃ
ЛњЦїбЇЯАЙЄзїСїЭЈГЃашвЊАќРЈвЛЯЕСаЕФДІРэКЭбЇЯАНзЖЮЁЃЛњЦїбЇЯАЪ§ОнСїЫЎЯпГЃБЛУшЪіЮЊвЛжжНзЖЮЕФађСаЃЌУПИіНзЖЮЛђепЪЧвЛИізЊЛЛЦїФЃПщЃЌЛђепЪЧИіЙРМЦЦїФЃПщЁЃетаЉНзЖЮЛсАДЫГађжДааЃЌЪфШыЪ§ОндкСїЫЎЯпжаСїОУПИіНзЖЮЪБЛсБЛДІРэКЭзЊЛЛЁЃ
ЛњЦїбЇЯАПЊЗЂПђМмвЊжЇГжЗжВМЪНМЦЫуЃЌВЂзїЮЊзщзАСїЫЎЯпФЃПщЕФЙЄОпЁЃЛЙгавЛаЉЦфЫќЕФЙЙНЈЪ§ОнСїЫЎЯпЕФашЧѓЃЌАќРЈШнДэЁЂзЪдДЙмРэЁЂПЩРЉеЙадКЭПЩЮЌЛЄадЕШЁЃ
дкецЪЕЯюФПжаЃЌЛњЦїбЇЯАЙЄзїСїНтОіЗНАИвВАќРЈФЃаЭЕМШыЕМГіЙЄОпЁЂНЛВцбщжЄРДбЁдёВЮЪ§ЁЂЮЊЖрИіЪ§ОндДЛ§РлЪ§ОнЕШЁЃЫќУЧвВЬсЙЉСЫвЛаЉЯёЙІФмГщШЁЁЂбЁдёКЭЭГМЦЕШЕФЪ§ОнЙЄОпЁЃетаЉПђМмжЇГжЛњЦїбЇЯАСїЫЎЯпГжОУЛЏРДБЃДцКЭЕМШыЛњЦїбЇЯАФЃаЭКЭСїЫЎЯпЃЌвдБИНЋРДЪЙгУЁЃ
ЛњЦїбЇЯАЙЄзїСїЕФИХФюКЭЙЄзїСїДІРэЦїЕФзщКЯвбОдкЖржжВЛЭЌЯЕЭГжадНРДдНЪмЛЖгЁЃЯѓscikit-learnКЭGraphLabЕШДѓЪ§ОнДІРэПђМмвВЪЙгУСїЫЎЯпЕФИХФюРДЙЙНЈЯЕЭГЁЃ
вЛИіЕфаЭЕФЪ§ОнМлжЕСДСїГЬАќРЈШчЯТВНжшЃК
ЗЂЯж
зЂШы
ДІРэ
БЃДц
ећКЯ
ЗжЮі
еЙЪО
ЛњЦїбЇЯАЪ§ОнСїЫЎЯпЫљгУЕФЗНЗЈЖМЪЧРрЫЦЕФЁЃЯТЭМеЙЪОСЫдкЛњЦїбЇЯАСїЫЎЯпДІРэжаЩцМАЕНЕФВЛЭЌВНжшЁЃ

БэвЛЃКЛњЦїбЇЯАСїЫЎЯпДІРэВНжш
етаЉВНжшвВПЩвдгУЯТУцЕФЭМвЛБэЪОЁЃ
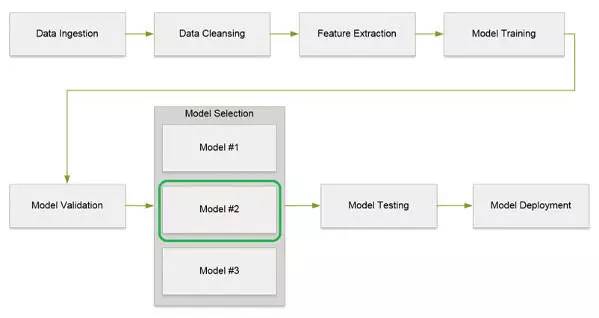
ЭМвЛЃКЛњЦїбЇЯАЪ§ОнСїЫЎЯпДІРэСїЭМ
НгЯТРДШУЮвУЧвЛЦ№ПДПДУПИіВНжшЕФЯИНкЁЃ
Ъ§ОнзЂШыЃКЮвУЧЪеМЏЦ№РДЙЉИјЛњЦїбЇЯАСїЫЎЯпгІгУГЬађЕФЪ§ОнПЩвдРДздгкЖржжЪ§ОндДЃЌЪ§ОнЙцФЃвВЪЧДгМИАйGBЕНМИTBЖМПЩвдЁЃЖјЧвЃЌДѓЪ§ОнгІгУГЬађЛЙгавЛИіЬиеїЃЌОЭЪЧзЂШыВЛЭЌИёЪНЕФЪ§ОнЁЃ
Ъ§ОнЧхЯДЃКЪ§ОнЧхЯДетвЛВНдкећИіЪ§ОнЗжЮіСїЫЎЯпжаЪЧЕквЛВНЃЌвВЪЧжСЙиживЊЕФвЛВНЃЌвВПЩвдНазіЪ§ОнЧхРэЛђЪ§ОнзЊЛЛЃЌетвЛВНжївЊЪЧвЊАбЪфШыЪ§ОнБфГЩНсЙЙЛЏЕФЃЌвдЗНБуКѓајЕФЪ§ОнДІРэКЭдЄВтадЗжЮіЁЃвРНјШыЕНЯЕЭГжаЕФЪ§ОнжЪСПВЛЭЌЃЌзмДІРэЪБМфЕФ60%-70%ЛсБЛЛЈдкЪ§ОнЧхЯДЩЯЃЌАбЪ§ОнзЊГЩКЯЪЪЕФИёЪНЃЌетбљВХФмАбЛњЦїбЇЯАФЃаЭгІгУЕНЪ§ОнЩЯЁЃ
Ъ§ОнзмЛсгаИїжжИїбљЕФжЪСПЮЪЬтЃЌБШШчЪ§ОнВЛЭъећЃЌЛђепЪ§ОнЯюВЛе§ШЗЛђВЛКЯЗЈЕШЁЃЪ§ОнЧхЯДЙ§ГЬЭЈГЃЛсЪЙгУИїжжВЛЭЌЕФЗНЗЈЃЌАќРЈЖЈжЦзЊЛЛЦїЕШЃЌгУСїЫЎЯпжаЕФЖЈжЦЕФзЊЛЛЦїШЅжДааЪ§ОнЧхЯДЖЏзїЁЃ
ЯЁЪшЛђДжСЃЪ§ОнЪЧЪ§ОнЗжЮіжаЕФСэвЛИіЬєеНЁЃдкетЗНУцзмЛсЗЂЩњаэЖрМЋЖЫАИР§ЃЌЫљвдЮвУЧвЊгУЩЯУцНВЕНЕФЪ§ОнЧхЯДММЪѕРДБЃжЄЪфШыЕНЪ§ОнСїЫЎЯпжаЕФЪ§ОнБиаыЪЧИпжЪСПЕФЁЃ
АщЫцзХЮвУЧЖдЮЪЬтЕФЩюШыРэНтЃЌУПвЛДЮЕФСЌајГЂЪдКЭВЛЖЯЕиИќаТФЃаЭЃЌЪ§ОнЧхЯДвВЭЈГЃЪЧИіЕќДњЕФЙ§ГЬЁЃЯѓTrifactaЁЂOpenRefineЛђActiveCleanЕШЪ§ОнзЊЛЛЙЄОпЖМПЩвдгУРДЭъГЩЪ§ОнЧхЯДШЮЮёЁЃ
ЬиеїГщШЁЃКдкЬиеїГщШЁ(гаЪБКђвВНаЬиеїЙЄГЬ)етвЛВНЃЌЮвУЧЛсгУЬиеїЙўЯЃ(Hashing Term Frequency)КЭWord2VecЕШММЪѕРДДгдЪМЪ§ОнжаГщШЁОпЬхЕФЙІФмЁЃетвЛВНЕФЪфГіНсЙћГЃГЃвВАќРЈвЛИіЛуБрФЃПщЃЌЛсвЛЦ№ДЋШыЯТвЛИіВНжшНјааДІРэЁЃ
ФЃаЭбЕСЗЃКЛњЦїбЇЯАФЃаЭбЕСЗАќРЈЬсЙЉвЛИіЫуЗЈЃЌВЂЬсЙЉвЛаЉбЕСЗЪ§ОнШУФЃаЭПЩвдбЇЯАЁЃбЇЯАЫуЗЈЛсДгбЕСЗЪ§ОнжаЗЂЯжФЃЪНЃЌВЂЩњГЩЪфГіФЃаЭЁЃ
ФЃаЭбщжЄЃКетвЛВНАќЦРЙРКЭЕїећЛњЦїбЇЯАФЃаЭЃЌвдКтСПгУЫќРДзідЄВтЕФгааЇадЁЃШчетЦЊЮФеТЫљЫЕЃЌЖдгкЖўНјжЦЗжРрФЃаЭЦРЙРжИБъПЩвдгУНгЪеепВйзїЬиеї(Receiver
Operating CharacteristicЃЌROC)ЧњЯпЁЃROCЧњЯпПЩвдБэЯжвЛИіЖўНјжЦЗжРрЦїЯЕЭГЕФадФмЁЃДДНЈЫќЕФЗНЗЈЪЧдкВЛЭЌЕФуажЕЩшжУЯТУшЛцецбєадТЪ(True
Positive RateЃЌTPR)КЭМйбєадТЪ(False Positive RateЃЌFPR)жЎМфЕФЖдгІЙиЯЕЁЃ
ФЃаЭбЁдёЃКФЃаЭбЁдёжИШУзЊЛЛЦїКЭЙРМЦЦїгУЪ§ОнШЅбЁдёВЮЪ§ЁЃетдкЛњЦїбЇЯАСїЫЎЯпДІРэЙ§ГЬжавВЪЧЙиМќЕФвЛВНЁЃParamGridBuilderКЭCrossValidatorЕШРрЖМЬсЙЉСЫAPIРДбЁдёЛњЦїбЇЯАФЃаЭЁЃ
ФЃаЭВПЪ№ЃКвЛЕЉбЁКУСЫе§ШЗЕФФЃаЭЃЌЮвУЧОЭПЩвдПЊЪМВПЪ№ЃЌЪфШыаТЪ§ОнВЂЕУЕНдЄВтадЕФЗжЮіНсЙћЁЃЮвУЧвВПЩвдАбЛњЦїбЇЯАФЃаЭВПЪ№ГЩЭјвГЗўЮёЁЃ
SparkЛњЦїбЇЯА
ЛњЦїбЇЯАСїЫЎЯпAPIЪЧдкApache SparkПђМм1.2Ацжав§ШыЕФЁЃЫќИјПЊЗЂепУЧЬсЙЉСЫAPIРДДДНЈВЂжДааИДдгЕФЛњЦїбЇЯАЙЄзїСїЁЃСїЫЎЯпAPIЕФФПБъЪЧЭЈЙ§ЮЊВЛЭЌЛњЦїбЇЯАИХФюЬсЙЉБъзМЛЏЕФAPIЃЌРДШУгУЛЇПЩвдПьЫйВЂЧсЫЩЕизщНЈВЂХфжУПЩааЕФЗжВМЪНЛњЦїбЇЯАСїЫЎЯпЁЃСїЫЎЯпAPIАќКЌдкorg.apache.spark.mlАќжаЁЃ
Spark MLвВгажњгкАбЖржжЛњЦїбЇЯАЫуЗЈзщКЯЕНвЛЬѕСїЫЎЯпжаЁЃ
SparkЛњЦїбЇЯАAPIБЛЗжГЩСЫСНИіАќЃЌЗжБ№ЪЧspark.mllibКЭspark.mlЁЃЦфжаspark.mlАќАќРЈСЫЛљгкRDDЙЙНЈЕФдЪМAPIЁЃЖјspark.mlАќдђЬсЙЉСЫЙЙНЈгкDataFrameжЎЩЯЕФИпМЖAPIЃЌгУгкЙЙНЈЛњЦїбЇЯАСїЫЎЯпЁЃ
ЛљгкRDDЕФMLlibПтAPIЯждкДІгкЮЌЛЄФЃЪНЁЃ
ШчЯТУцЭМЖўЫљЪОЃЌSpark MLЪЧApache SparkЩњЬЌЯЕЭГжаЕФвЛИіЗЧГЃживЊЕФДѓЪ§ОнЗжЮіПтЁЃ
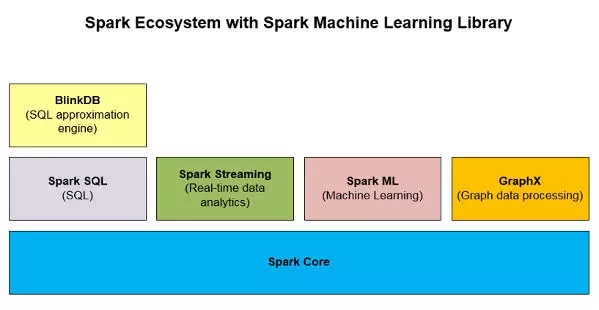
ЭМЖўЃКАќРЈСЫSpark MLЕФSparkЩњЬЌЯЕЭГ
ЛњЦїбЇЯАСїЫЎЯпФЃПщ
ЛњЦїбЇЯАЪ§ОнСїЫЎЯпАќРЈСЫЭъГЩЪ§ОнЗжЮіШЮЮёЫљашвЊЕФЖрИіФЃПщЁЃЪ§ОнСїЫЎЯпЕФЙиМќФЃПщБЛСадкСЫЯТУцЃК
Ъ§ОнМЏ
СїЫЎЯп
СїЫЎЯпЕФНзЖЮ
зЊЛЛЦї
ЙРМЦЦї
ЦРЙРЦї
ВЮЪ§(КЭВЮЪ§ЕиЭМ)
НгЯТРДЮвУЧМђЕЅПДПДетаЉФЃПщПЩвддѕУДЖдгІЕНећЬхЕФВНжшжаЁЃ
Ъ§ОнМЏЃКдкЛњЦїбЇЯАСїЫЎЯпжаЪЧЪЙгУDataFrameРДБэЯжЪ§ОнМЏЕФЁЃЫќвВдЪаэАДгаУћзжЕФзжЖЮБЃДцНсЙЙЛЏЪ§ОнЁЃетаЉзжЖЮПЩвдгУгкБЃДцЮФзжЁЂЙІФмЯђСПЁЂецЪЕБъЧЉКЭдЄВтЁЃ
СїЫЎЯпЃКЛњЦїбЇЯАЙЄзїСїБЛНЈФЃЮЊСїЫЎЯпЃЌетАќРЈСЫвЛЯЕСаЕФНзЖЮЁЃУПИіНзЖЮЖМЖдЪфШыЪ§ОнНјааДІРэЃЌЮЊЯТвЛИіНзЖЮВњЩњЪфГіЪ§ОнЁЃвЛИіСїЫЎЯпАбЖрИізЊЛЛЦїКЭЙРМЦЦїДЎСЌЦ№РДЃЌУшЪівЛИіЛњЦїбЇЯАЙЄзїСїЁЃ
СїЫЎЯпЕФНзЖЮЃКЮвУЧЖЈвхСНжжНзЖЮЃЌзЊЛЛЦїКЭЙРМЦЦїЁЃ
зЊЛЛЦїЃКЫуЗЈПЩвдАбвЛИіDataFrameзЊЛЛГЩСэвЛИіDataFrameЁЃБШШчЃЌЛњЦїбЇЯАФЃаЭОЭЪЧвЛИізЊЛЛЦїЃЌгУгкАбвЛИігаЬиеїЕФDataFrameзЊЛЛГЩвЛИігадЄВтаХЯЂЕФDataFrameЁЃ
зЊЛЛЦїЛсАбвЛИіDataFrameзЊГЩСэвЛИіDataFrameЃЌЭЌЪБЮЊЫќМгШыаТЕФЬиеїЁЃБШШчдкSpark
MLАќжаЃЌOneHotEncoderОЭЛсАбвЛИігаБъЧЉЫїв§ЕФзжЖЮзЊЛЛГЩвЛИігаЯђСПЬиеїЕФзжЖЮЁЃУПИізЊЛЛЦїЖМгавЛИіtransform()КЏЪ§ЃЌБЛЕїгУЪБОЭЛсАбвЛИіDataFrameзЊЛЛГЩСэвЛИіЁЃ
ЙРМЦЦїЃКЙРМЦЦїОЭЪЧвЛжжЛњЦїбЇЯАЫуЗЈЃЌЛсДгФуЬсЙЉЕФЪ§ОнжаНјаабЇЯАЁЃЙРМЦЦїЕФЪфШыЪЧвЛИіDataFrameЃЌЪфГіОЭЪЧвЛИізЊЛЛЦїЁЃЙРМЦЦїгУгкбЕСЗФЃаЭЃЌЫќЩњГЩзЊЛЛЦїЁЃБШШчЃЌТпМЛиЙщЙРМЦЦїОЭЛсВњЩњТпМЛиЙщзЊЛЛЦїЁЃСэвЛИіР§згЪЧАбK-MeansзіЮЊЙРМЦЦїЃЌЫќНгЪмбЕСЗЪ§ОнЃЌЩњГЩK-MeansФЃаЭЃЌОЭЪЧвЛИізЊЛЛЦїЁЃ
ВЮЪ§ЃКЛњЦїбЇЯАФЃПщЛсЪЙгУЭЈгУЕФAPIРДУшЪіВЮЪ§ЁЃВЮЪ§ЕФР§згжЎвЛОЭЪЧФЃаЭвЊЪЙгУЕФзюДѓЕќДњДЮЪ§ЁЃ
ЯТЭМеЙЪОЕФЪЧвЛИігУзїЮФзжЗжРрЕФЪ§ОнСїЫЎЯпЕФИїИіФЃПщЁЃ

ЭМШ§ЃКЪЙгУSpark MLЕФЪ§ОнСїЫЎЯп
гУР§
ЛњЦїбЇЯАСїЫЎЯпЕФгУР§жЎвЛОЭЪЧЮФзжЗжРрЁЃетжжгУР§ЭЈГЃАќРЈШчЯТВНжшЃК
ЧхЯДЮФзжЪ§Он
НЋЪ§ОнзЊЛЏГЩЬиеїЯђСПЃЌВЂЧв
бЕСЗЗжРрФЃаЭ
дкЮФзжЗжРржаЃЌдкНјааЗжРрФЃаЭ(РрЫЦSVM)ЕФбЕСЗжЎЧАЃЌЛсНјааn-gramГщЯѓКЭTF-IDFЬиеїШЈжиЕШЪ§ОндЄДІРэЁЃ
СэвЛИіЛњЦїбЇЯАСїЫЎЯпгУР§ОЭЪЧдкетЦЊЮФеТжаУшЪіЕФЭМЯёЗжРрЁЃ
ЛЙгаКмЖржжЦфЫќЛњЦїбЇЯАгУР§ЃЌАќРЈЦлеЉМьВт(ЪЙгУЗжРрФЃаЭЃЌетвВЪЧМрЖНЪНбЇЯАЕФвЛВПЗж)ЃЌгУЛЇЗжЧј(ОлДиФЃаЭЃЌетвВЪЧЗЧМрЖНЪНбЇЯАЕФвЛВПЗж)ЁЃ
TF-IDF
ДЪЦЕ-ФцЯђЮФЕЕЦЕТЪ(Term Frequency - Inverse Document FrequencyЃЌTF-IDF)ЪЧвЛжждкИјЖЈбљБОМЏКЯФкЦРЙРвЛИіДЪЕФживЊГЬЖШЕФОВЬЌЦРЙРЗНЗЈЁЃетЪЧвЛжжаХЯЂЛёШЁЫуЗЈЃЌгУгкдквЛИіЮФЕЕМЏКЯФкИјвЛИіДЪЕФживЊадДђЗжЁЃ
TFЃКШчЙћвЛИіДЪдквЛЗнЮФЕЕжаЗДИДГіЯжЃЌФЧетИіДЪОЭБШНЯживЊЁЃОпЬхМЦЫуЗНЗЈЮЊЃК
TF = (# of times word X appears in a document) /
(Total # of
words in the document)
IDFЃКЕЋШчЙћвЛИіДЪдкЖрЗнЮФЕЕжаЖМЦЕЗБГіЯж(БШШчtheЃЌandЃЌofЕШ)ЃЌФЧОЭЫЕУїетИіДЪУЛгаЪВУДЪЕМЪвтвхЃЌвђДЫОЭвЊНЕЕЭЫќЕФЦРЗжЁЃ
ЪОР§ГЬађ
ЯТУцЮвУЧПДИіЪОР§ГЬађЃЌСЫНтвЛЯТSpark MLАќПЩвддѕбљгУдкДѓЪ§ОнДІРэЯЕЭГжаЁЃЮвУЧЛсПЊЗЂвЛИіЮФЕЕЗжРрГЬађЃЌгУгкЧјБ№ГЬађЪфШыЪ§ОнжаЕФЙуИцФкШнЁЃВтЪдгУЕФЪфШыЪ§ОнМЏАќРЈЮФЕЕЁЂЕчзггЪМўЛђЦфЫќШЮКЮДгЭтВПЯЕЭГжаЪеЕНЕФПЩФмАќКЌЙуИцЕФФкШнЁЃ
ЮвУЧНЋЪЙгУдкStrata Hadoop World ConferenceбаЬжЛсЩЯЬжТлЕФЁАгУSparkЙЙНЈЛњЦїбЇЯАгІгУЁБЕФЙуИцМьВтЪОР§РДЙЙНЈЮвУЧЕФЪОР§ГЬађЁЃ
гУР§
етИігУР§ЛсЖдЗЂЫЭЕНЮвУЧЕФЯЕЭГжаЕФИїжжВЛЭЌЯћЯЂНјааЗжЮіЁЃгааЉЯћЯЂРяУцЪЧКЌгаЙуИцаХЯЂЕФЃЌЕЋгааЉЯћЯЂРяУцУЛгаЁЃЮвУЧЕФФПБъОЭЪЧвЊгУSpark
ML APIевГіФЧаЉАќКЌСЫЙуИцЕФЯћЯЂЁЃ
ЫуЗЈ
ЮвУЧНЋЪЙгУЛњЦїбЇЯАжаЕФТпМЛиЙщЫуЗЈЁЃТпМЛиЙщЪЧвЛжжЛиЙщЗжЮіФЃаЭЃЌПЩвдЛљгквЛИіЛђЖрИіЖРСЂБфСПРДдЄВтЕУЕНЪЧЛђЗЧЕФПЩФмНсЙћЁЃ
ЯъЯИЕФНтОіЗНАИ
НгЯТРДдлУЧПДПДетИіSpark MLЪОР§ГЬађЕФЯИНкЃЌвдМАдЫааВНжшЁЃ
Ъ§ОнзЂШыЃКЮвУЧЛсАбАќКЌЙуИцЕФЪ§Он(ЮФБОЮФМў)КЭВЛАќКЌЙуИцЕФЪ§ОнЖМЕМШыЁЃ
Ъ§ОнЧхЯДЃКдкЪОР§ГЬађжаЃЌЮвУЧВЛзіШЮКЮЬиБ№ЕФЪ§ОнЧхЯДВйзїЁЃЮвУЧжЛЪЧАбЫљгаЕФЪ§ОнЖМЛуОлЕНвЛИіDataFrameЖдЯѓжаЁЃ
ЮвУЧЫцЛњЕиДгбЕСЗЪ§ОнКЭВтЪдЪ§ОнжабЁдёвЛаЉЪ§ОнЃЌДДНЈвЛИіЪ§зщЖдЯѓЁЃдкетИіР§згжаЮвУЧЕФбЁдёЪЧ70%ЕФбЕСЗЪ§ОнЃЌКЭ30%ЕФВтЪдЪ§ОнЁЃ
дкКѓајЕФСїЫЎЯпВйзїжаЮвУЧЗжБ№гУетСНИіЪ§ОнЖдЯѓРДбЕСЗФЃаЭКЭзідЄВтЁЃ
ЮвУЧЕФЛњЦїбЇЯАЪ§ОнСїЫЎЯпАќРЈЫФВНЃК
Tokenizer
HashingTF
IDF
LR
ДДНЈвЛИіСїЫЎЯпЖдЯѓЃЌВЂЧвдкСїЫЎЯпжаЩшжУЩЯУцЕФИїИіНзЖЮЁЃШЛКѓЮвУЧОЭПЩвдАДееР§згЃЌЛљгкбЕСЗЪ§ОнРДДДНЈвЛИіТпМЛиЙщФЃаЭЁЃ
ЯждкЃЌЮвУЧдйЪЙгУВтЪдЪ§Он(аТЪ§ОнМЏ)РДгУФЃаЭзідЄВтЁЃ
ЯТУцЭМЫФжаеЙЪОСЫР§згГЬађЕФМмЙЙЭМЁЃ
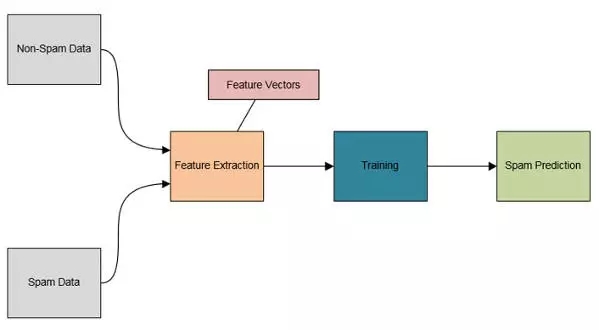
ЭМ4ЃКЪ§ОнЗжРрГЬађМмЙЙЭМ
ММЪѕ
дкЪЕЯжЛњЦїбЇЯАСїЫЎЯпНтОіЗНАИЪБЮвУЧгУЕНСЫЯТУцЕФММЪѕЁЃ
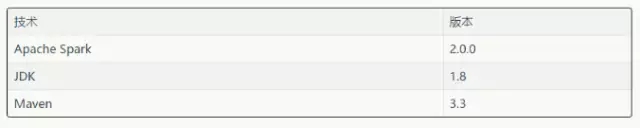
БэЖўЃКдкЛњЦїбЇЯАР§згжагУЕНЕФММЪѕКЭЙЄОп
Spark MLГЬађ
ИљОнбаЬжЛсЩЯЕФР§згЖјаДГЩЕФЛњЦїбЇЯАДњТыЪЧгУScalaБрГЬгябдаДЕФЃЌЮвУЧПЩвджБНгЪЙгУSpark ShellПижЦЬЈРДдЫааетИіГЬађЁЃ
ЙуИцМьВтScalaДњТыЦЌЖЮЃК
ЕквЛВНЃКДДНЈвЛИіЖЈжЦЕФРрЃЌгУРДДцДЂЙуИцФкШнЕФЯИНкЁЃ
case class SpamDocument(file:
String, text: String, label:
Double) |
ЕкЖўВНЃКГѕЪМЛЏSQLContextЃЌВЂЭЈЙ§вўЪНзЊЛЛЗНЗЈРДАбScalaЖдЯѓзЊЛЛГЩDataFrameЁЃШЛКѓДгДцЗХзХЪфШыЮФМўЕФжИЖЈФПТМЕМШыЪ§ОнМЏЃЌНсЙћЛсЗЕЛиRDDЖдЯѓЁЃШЛКѓгЩетСНИіЪ§ОнМЏЕФRDDЖдЯѓДДНЈDataFrameЖдЯѓЁЃ
val sqlContext
= new SQLContext(sc)
import sqlContext.implicits._
//
// Load the data files with spam
//
val rddSData = sc.wholeTextFiles("SPAM_DATA_FILE_DIR",
1)
val dfSData = rddSData.map(d => SpamDocument(d._1,
d._2,1)).toDF()
dfSData.show()
//
// Load the data files with no spam
//
val rddNSData = sc.wholeTextFiles("NO_SPAM_DATA_FILE_DIR",
1)
val dfNSData = rddNSData.map(d => SpamDocument(d._1,d._2,
0)).toDF()
dfNSData.show() |
ЕкШ§ВНЃКЯждкЃЌАбЪ§ОнМЏЛуОлЦ№РДЃЌШЛКѓИљОн70%КЭ30%ЕФБШР§РДАбећЗнЪ§ОнВ№ЗжГЩбЕСЗЪ§ОнКЭВтЪдЪ§ОнЁЃ
//
// Aggregate both data frames
//
val dfAllData = dfSData.unionAll(dfNSData)
dfAllData.show()
//
// Split the data into 70% training data and 30%
test data
//
val Array(trainingData, testData) =
dfAllData.randomSplit(Array(0.7, 0.3)) |
ЕкЫФВНЃКЯждкПЩвдХфжУЛњЦїбЇЯАЪ§ОнСїЫЎЯпСЫЃЌвЊДДНЈЮвУЧдкЮФеТЧАУцВПЗжЬжТлЕНЕФМИИіВПЗжЃКTokenizerЁЂHashingTFКЭIDFЁЃШЛКѓдйгУбЕСЗЪ§ОнДДНЈЛиЙщФЃаЭЃЌдкетИіР§згжаЪЧТпМЛиЙщЁЃ
//
// Configure the ML data pipeline
//
//
// Create the Tokenizer step
//
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
//
// Create the TF and IDF steps
//
val hashingTF = new HashingTF()
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("rawFeatures")
val idf = new
IDF().setInputCol("rawFeatures").setOutputCol
("features")
//
// Create the Logistic Regression step
//
val lr = new LogisticRegression()
.setMaxIter(5)
lr.setLabelCol("label")
lr.setFeaturesCol("features")
//
// Create the pipeline
//
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, idf, lr))
val lrModel = pipeline.fit(trainingData)
println(lrModel.toString()) |
ЕкЮхВНЃКзюКѓЃЌЮвУЧЕїгУТпМЛиЙщФЃаЭжаЕФзЊЛЛЗНЗЈРДгУВтЪдЪ§ОнзідЄВтЁЃ
//
// Make predictions.
//
val predictions = lrModel.transform(testData)
//
// Display prediction results
//
predictions.select("file", "text",
"label", "features", "prediction").show(300)
|
НсТл
SparkЛњЦїбЇЯАПтЪЧApache SparkПђМмжазюживЊЕФПтжЎвЛЁЃЫќгУгкЪЕЯжЪ§ОнСїЫЎЯпЁЃдкетЦЊЮФеТжаЃЌЮвУЧСЫНтСЫШчКЮЪЙгУSpark
MLАќЕФAPIвдМАгУЫќРДЪЕЯжвЛИіЮФБОЗжРргУР§ЁЃ
НгЯТРДЕФФкШн
ЭМЪ§ОнФЃаЭЪЧЙигкдкЪ§ОнФЃаЭжаВЛЭЌЕФЪЕЬхжЎМфЕФСЌНгКЭЙиЯЕЕФЁЃЭМЪ§ОнДІРэММЪѕзюНќЪмЕНСЫКмЖрЙизЂЃЌвђЮЊПЩвдгУЫќРДНтОіаэЖрЮЪЬтЃЌАќРЈЦлеЉМьВтКЭПЊЗЂЭЦМів§ЧцЕШЁЃ
SparkПђМмЬсЙЉСЫвЛИіПтЃЌзЈУХгУгкЭМЪ§ОнЗжЮіЁЃЮвУЧдкетИіЯЕСаЕФЮФеТжаЃЌНгЯТРДЛсСЫНтетИіУћЮЊSpark
GraphXЕФПтЁЃЮвУЧЛсгУSpark GraphXРДПЊЗЂвЛИіЪОР§ГЬађЃЌгУгкЭМЪ§ОнДІРэКЭЗжЮіЁЃ |








