| БрМЭЦМі: |
| БОЮФРДздгкИіШЫВЉПЭЃЌБОЮФжївЊЯъЯИНщЩмСЫвЛИіHadoopЕФMasterНкЕуЕФАВзАХфжУЙ§ГЬЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
вЛЁЂHadoopЕФЗЂеЙРњЪЗ

ЫЕЕНHadoopЕФЦ№дДЃЌВЛЕУВЛЫЕЕНвЛИіДЋЦцЕФITЙЋЫОЁЊШЋЧђITММЪѕЕФв§СьепGoogleЁЃGoogleЃЈздГЦЃЉЮЊдЦМЦЫуИХФюЕФЬсГіепЃЌдкздЩэЖрФъЕФЫбЫїв§ЧцвЕЮёжаЙЙНЈСЫЭЛЦЦадЕФGFSЃЈGoogle
File SystemЃЉЃЌДгДЫЮФМўЯЕЭГНјШыЗжВМЪНЪБДњЁЃГ§ДЫжЎЭтЃЌGoogleдкGFSЩЯШчКЮПьЫйЗжЮіКЭДІРэЪ§ОнЗНУцПЊДДСЫMapReduceВЂааМЦЫуПђМмЃЌШУвдЭљЕФИпЖЫЗўЮёЦїМЦЫуБфЮЊСЎМлЕФx86МЏШКМЦЫуЃЌвВШУаэЖрЛЅСЊЭјЙЋЫОФмЙЛДгIOEЃЈIBMаЁаЭЛњЁЂOracleЪ§ОнПтвдМАEMCДцДЂЃЉжаНтЭбГіРДЃЌР§ШчЃКЬдБІдчОЭПЊЪМСЫШЅIOEЛЏЕФЕРТЗЁЃШЛЖјЃЌGoogleжЎЫљвдЮАДѓОЭдкгкЖРЯэММЪѕВЛШчЙВЯэММЪѕЃЌдк2002-2004ФъМфвдШ§ДѓТлЮФЕФЗЂВМЯђЪРНчЭЦЫЭСЫЦфдЦМЦЫуЕФКЫаФзщГЩВПЗжGFSЁЂMapReduceвдМАBigTableЁЃGoogleЫфШЛУЛгаНЋЦфКЫаФММЪѕПЊдДЃЌЕЋЪЧетШ§ЦЊТлЮФвбОЯђПЊдДЩчЧјЕФДѓХЃУЧжИУїСЫЗНЯђЃЌвЛЮЛДѓХЃЃКDoug
CuttingЪЙгУJavaгябдЖдGoogleЕФдЦМЦЫуКЫаФММЪѕЃЈжївЊЪЧGFSКЭMapReduceЃЉзіСЫПЊдДЕФЪЕЯжЁЃКѓРДЃЌApacheЛљН№ЛсећКЯDoug
CuttingвдМАЦфЫћITЙЋЫОЃЈШчFacebookЕШЃЉЕФЙБЯзГЩЙћЃЌПЊЗЂВЂЭЦГіСЫHadoopЩњЬЌЯЕЭГЁЃHadoopЪЧвЛИіДюНЈдкСЎМлPCЩЯЕФЗжВМЪНМЏШКЯЕЭГМмЙЙЃЌЫќОпгаИпПЩгУадЁЂИпШнДэадКЭИпПЩРЉеЙадЕШгХЕуЁЃгЩгкЫќЬсЙЉСЫвЛИіПЊЗХЪНЕФЦНЬЈЃЌгУЛЇПЩвддкЭъШЋВЛСЫНтЕзВуЪЕЯжЯИНкЕФЧщаЮЯТЃЌПЊЗЂЪЪКЯздЩэгІгУЕФЗжВМЪНГЬађЁЃ
ЖўЁЂHadoopЕФећЬхПђМм HadoopгЩHDFSЁЂMapReduceЁЂHBaseЁЂHiveКЭZooKeeperЕШГЩдБзщГЩЃЌЦфжазюЛљДЁзюживЊЕФСНжжзщГЩдЊЫиЮЊЕзВугУгкДцДЂМЏШКжаЫљгаДцДЂНкЕуЮФМўЕФЮФМўЯЕЭГHDFSЃЈHadoop
Distributed File SystemЃЉКЭЩЯВугУРДжДааMapReduceГЬађЕФMapReduceв§ЧцЁЃ

PigЪЧвЛИіЛљгкHadoopЕФДѓЙцФЃЪ§ОнЗжЮіЦНЬЈЃЌPigЮЊИДдгЕФКЃСПЪ§ОнВЂааМЦЫуЬсЙЉСЫвЛИіМђвзЕФВйзїКЭБрГЬНгПк ChukwaЪЧЛљгкHadoopЕФМЏШКМрПиЯЕЭГЃЌгЩyahooЙБЯз hiveЪЧЛљгкHadoopЕФвЛИіЙЄОпЃЌЬсЙЉЭъећЕФsqlВщбЏЙІФмЃЌПЩвдНЋsqlгяОфзЊЛЛЮЊMapReduceШЮЮёНјаадЫаа ZooKeeperЃКИпаЇЕФЃЌПЩРЉеЙЕФаЕїЯЕЭГ,ДцДЂКЭаЕїЙиМќЙВЯэзДЬЌ HBaseЪЧвЛИіПЊдДЕФЃЌЛљгкСаДцДЂФЃаЭЕФЗжВМЪНЪ§ОнПт HDFSЪЧвЛИіЗжВМЪНЮФМўЯЕЭГЁЃгазХИпШнДэадЕФЬиЕуЃЌВЂЧвЩшМЦгУРДВПЪ№дкЕЭСЎЕФгВМўЩЯЃЌЪЪКЯФЧаЉгазХГЌДѓЪ§ОнМЏЕФгІгУГЬађ MapReduceЪЧвЛжжБрГЬФЃаЭЃЌгУгкДѓЙцФЃЪ§ОнМЏЃЈДѓгк1TBЃЉЕФВЂаадЫЫу
ЯТЭМЪЧвЛИіЕфаЭЕФHadoopЪдбщМЏШКЕФВПЪ№НсЙЙЁЃ

HadoopИїзщМўжЎМфЪЧШчКЮвРРЕЙВДцЕФФиЃПЯТЭМЮЊФуеЙЪОЃК

Ш§ЁЂHadoopЕФКЫаФЩшМЦ

3.1 HDFS HDFSЪЧвЛИіИпЖШШнДэадЕФЗжВМЪНЮФМўЯЕЭГЃЌПЩвдБЛЙуЗКЕФВПЪ№гкСЎМлЕФPCжЎЩЯЁЃЫќвдСїЪНЗУЮЪФЃЪНЗУЮЪгІгУГЬађЕФЪ§ОнЃЌетДѓДѓЬсИпСЫећИіЯЕЭГЕФЪ§ОнЭЬЭТСПЃЌвђЖјЗЧГЃЪЪКЯгУгкОпгаГЌДѓЪ§ОнМЏЕФгІгУГЬађжаЁЃ
HDFSЕФМмЙЙШчЯТЭМЫљЪОЁЃHDFSМмЙЙВЩгУжїДгМмЙЙЃЈmaster/slaveЃЉЁЃвЛИіЕфаЭЕФHDFSМЏШКАќКЌвЛИіNameNodeНкЕуКЭЖрИіDataNodeНкЕуЁЃNameNodeНкЕуИКд№ећИіHDFSЮФМўЯЕЭГжаЕФЮФМўЕФдЊЪ§ОнБЃЙмКЭЙмРэЃЌМЏШКжаЭЈГЃжЛгавЛЬЈЛњЦїЩЯдЫааNameNodeЪЕР§ЃЌDataNodeНкЕуБЃДцЮФМўжаЕФЪ§ОнЃЌМЏШКжаЕФЛњЦїЗжБ№дЫаавЛИіDataNodeЪЕР§ЁЃдкHDFSжаЃЌNameNodeНкЕуБЛГЦЮЊУћГЦНкЕуЃЌDataNodeНкЕуБЛГЦЮЊЪ§ОнНкЕуЁЃDataNodeНкЕуЭЈЙ§аФЬјЛњжЦгыNameNodeНкЕуНјааЖЈЪБЕФЭЈаХЁЃ
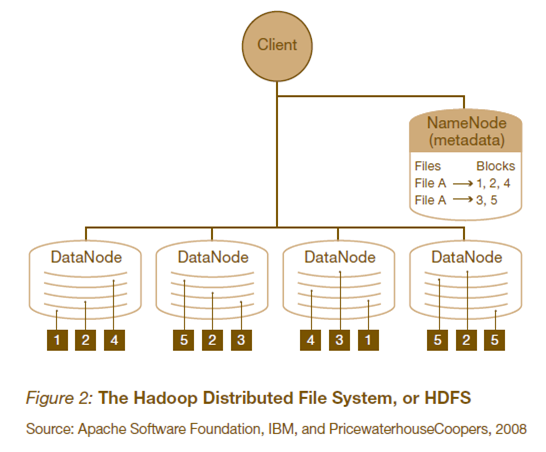
NameNode
ПЩвдПДзїЪЧЗжВМЪНЮФМўЯЕЭГжаЕФЙмРэепЃЌДцДЂЮФМўЯЕЭГЕФmeta-dataЃЌжївЊИКд№ЙмРэЮФМўЯЕЭГЕФУќУћПеМфЃЌМЏШКХфжУаХЯЂЃЌДцДЂПщЕФИДжЦЁЃ
DataNode
ЪЧЮФМўДцДЂЕФЛљБОЕЅдЊЁЃЫќДцДЂЮФМўПщдкБОЕиЮФМўЯЕЭГжаЃЌБЃДцСЫЮФМўПщЕФmeta-dataЃЌЭЌЪБжмЦкадЕФЗЂЫЭЫљгаДцдкЕФЮФМўПщЕФБЈИцИјNameNodeЁЃ
Client
ОЭЪЧашвЊЛёШЁЗжВМЪНЮФМўЯЕЭГЮФМўЕФгІгУГЬађЁЃ
ЯТУцРДПДПДдкHDFSЩЯШчКЮНјааЮФМўЕФЖС/аДВйзїЃК

ЮФМўаДШыЃК
1. ClientЯђNameNodeЗЂЦ№ЮФМўаДШыЕФЧыЧѓ
2. NameNodeИљОнЮФМўДѓаЁКЭЮФМўПщХфжУЧщПіЃЌЗЕЛиИјClientЫќЫљЙмРэВПЗжDataNodeЕФаХЯЂЁЃ
3. ClientНЋЮФМўЛЎЗжЮЊЖрИіЮФМўПщЃЌИљОнDataNodeЕФЕижЗаХЯЂЃЌАДЫГађаДШыЕНУПвЛИіDataNodeПщжаЁЃ

ЮФМўЖСШЁЃК
1. ClientЯђNameNodeЗЂЦ№ЮФМўЖСШЁЕФЧыЧѓ
2. NameNodeЗЕЛиЮФМўДцДЂЕФDataNodeЕФаХЯЂЁЃ
3. ClientЖСШЁЮФМўаХЯЂЁЃ
3.2 MapReduce MapReduceЪЧвЛжжБрГЬФЃаЭЃЌгУгкДѓЙцФЃЪ§ОнМЏЕФВЂаадЫЫуЁЃMapЃЈгГЩфЃЉКЭReduceЃЈЛЏМђЃЉЃЌВЩгУЗжЖјжЮжЎЫМЯыЃЌЯШАбШЮЮёЗжЗЂЕНМЏШКЖрИіНкЕуЩЯЃЌВЂааМЦЫуЃЌШЛКѓдйАбМЦЫуНсЙћКЯВЂЃЌДгЖјЕУЕНзюжеМЦЫуНсЙћЁЃЖрНкЕуМЦЫуЃЌЫљЩцМАЕФШЮЮёЕїЖШЁЂИКдиОљКтЁЂШнДэДІРэЕШЃЌЖМгЩMapReduceПђМмЭъГЩЃЌВЛашвЊБрГЬШЫдБЙиаФетаЉФкШнЁЃ
ЯТЭМЪЧвЛИіMapReduceЕФДІРэЙ§ГЬЃК

гУЛЇЬсНЛШЮЮёИјJobTracerЃЌJobTracerАбЖдгІЕФгУЛЇГЬађжаЕФMapВйзїКЭReduceВйзїгГЩфжСTaskTracerНкЕужаЃЛЪфШыФЃПщИКд№АбЪфШыЪ§ОнЗжГЩаЁЪ§ОнПщЃЌШЛКѓАбЫќУЧДЋИјMapНкЕуЃЛMapНкЕуЕУЕНУПвЛИіkey/valueЖдЃЌДІРэКѓВњЩњвЛИіЛђЖрИіkey/valueЖдЃЌШЛКѓаДШыЮФМўЃЛReduceНкЕуЛёШЁСйЪБЮФМўжаЕФЪ§ОнЃЌЖдДјгаЯрЭЌkeyЕФЪ§ОнНјааЕќДњМЦЫуЃЌШЛКѓАбжеНсЙћаДШыЮФМўЁЃ
ШчЙћетбљНтЪЭЛЙЪЧЬЋГщЯѓЃЌПЩвдЭЈЙ§ЯТУцвЛИіОпЬхЕФДІРэЙ§ГЬРДРэНтЃКЃЈWordCountЪЕР§ЃЉЁЁ

ЁЁHadoopЕФКЫаФЪЧMapReduceЃЌЖјMapReduceЕФКЫаФгждкгкmapКЭreduceКЏЪ§ЁЃЫќУЧЪЧНЛИјгУЛЇЪЕЯжЕФЃЌетСНИіКЏЪ§ЖЈвхСЫШЮЮёБОЩэЁЃ
mapКЏЪ§ЃКНгЪмвЛИіМќжЕЖдЃЈkey-value pairЃЉЃЈР§ШчЩЯЭМжаЕФSplittingНсЙћЃЉЃЌВњЩњвЛзщжаМфМќжЕЖдЃЈР§ШчЩЯЭМжаMappingКѓЕФНсЙћЃЉЁЃMap/ReduceПђМмЛсНЋmapКЏЪ§ВњЩњЕФжаМфМќжЕЖдРяМќЯрЭЌЕФжЕДЋЕнИјвЛИіreduceКЏЪ§ЁЃ reduceКЏЪ§ЃКНгЪмвЛИіМќЃЌвдМАЯрЙиЕФвЛзщжЕЃЈР§ШчЩЯЭМжаShufflingКѓЕФНсЙћЃЉЃЌНЋетзщжЕНјааКЯВЂВњЩњвЛзщЙцФЃИќаЁЕФжЕЃЈЭЈГЃжЛгавЛИіЛђСуИіжЕЃЉЃЈР§ШчЩЯЭМжаReduceКѓЕФНсЙћЃЉ ЕЋЪЧЃЌMap/ReduceВЂВЛЪЧЭђФмЕФЃЌЪЪгУгкMap/ReduceМЦЫугаЯШЬсЬѕМўЃК
ЂйД§ДІРэЕФЪ§ОнМЏПЩвдЗжНтГЩаэЖраЁЕФЪ§ОнМЏЃЛ
ЂкЖјЧвУПвЛИіаЁЪ§ОнМЏЖМПЩвдЭъШЋВЂааЕиНјааДІРэЃЛ
ШєВЛТњзувдЩЯСНЬѕжаЕФШЮвтвЛЬѕЃЌдђВЛЪЪКЯЪЙгУMap/ReduceФЃЪНЃЛ
ЫФЁЂHadoopЕФАВзАХфжУ HadoopЙВгаШ§жжВПЪ№ЗНЪНЃКБОЕиФЃЪНЃЌЮБЗжВМФЃЪНМАМЏШКФЃЪНЃЛБОДЮАВзАХфжУвдЮБЗжВМФЃЪНЮЊжїЃЌМДдквЛЬЈЗўЮёЦїЩЯдЫааHadoopЃЈШчЙћЪЧЗжВМЪНФЃЪНЃЌдђЪзЯШвЊХфжУMasterжїНкЕуЃЌЦфДЮХфжУSlaveДгНкЕуЃЉЁЃвдЯТЫЕУїШчЮоЬиЪтЫЕУїЃЌФЌШЯЪЙгУrootгУЛЇЕЧТМжїНкЕуЃЌНјаавдЯТЕФвЛЯЕСаХфжУЁЃ
АВзАХфжУЧАЧыЯШзМБИКУвдЯТШэМўЃК
vmware workstation 8.0ЛђвдЩЯАцБО redhat server 6.xАцБОЛђcentos 6.xАцБО jdk-6u24-linux-xxx.bin hadoop-1.1.2.tar.gz 4.1 ЩшжУОВЬЌIPЕижЗ
УќСюФЃЪНЯТПЩвджДааsetupУќСюНјШыЩшжУНчУцХфжУОВЬЌIPЕижЗЃЛx-windowНчУцЯТПЩвдгвЛїЭјТчЭМБъХфжУЃЛ
ХфжУЭъГЩКѓжДааservice network restartжиаТЦєЖЏЭјТчЗўЮёЃЛЁЁЁЁ
бщжЄЃКжДааУќСюifconfig
4.2 аоИФжїЛњУћ
<1>аоИФЕБЧАЛсЛАжаЕФжїЛњУћЃЈетРяЮвЕФжїЛњУћЩшЮЊhadoop-masterЃЉЃЌжДааУќСюhostname
hadoop-master
<2>аоИФХфжУЮФМўжаЕФжїЛњУћЃЌжДааУќСюvi /etc/sysconfig/network
бщжЄЃКжиЦєЯЕЭГreboot
4.3 DNSАѓЖЈ
жДааУќСюvi /etc/hosts,діМгвЛааФкШнЃЌШчЯТЃЈетРяЮвЕФMasterНкЕуIPЩшжУЕФЮЊ192.168.80.100ЃЉЃК
192.168.80.100 hadoop-master
БЃДцКѓЭЫГі
бщжЄЃКping hadoop-master
4.4 ЙиБеЗРЛ№ЧНМАЦфздЖЏдЫаа
<1>жДааЙиБеЗРЛ№ЧНУќСюЃКservice iptables stop
бщжЄЃКservice iptables stauts
<2>жДааЙиБеЗРЛ№ЧНздЖЏдЫааУќСюЃКchkconfig iptables off
бщжЄЃКchkconfig --list | grep iptables
4.5 SSHЃЈSecure ShellЃЉЕФУтУмТыЕЧТМ
<1>жДааВњЩњУмдПУќСюЃКssh-keygen ЈCt rsaЃЌЮЛгкгУЛЇФПТМЯТЕФ.sshЮФМўжаЃЈ.sshЮЊвўВиЮФМўЃЌПЩвдЭЈЙ§ls
ЈCaВщПДЃЉ
<2>жДааВњЩњУќСюЃКcp id_rsa.pub authorized_keys
бщжЄЃКssh localhost
4.6 ИДжЦJDKКЭHadoop-1.1.2.tar.gzжСLinuxжа
<1>ЪЙгУWinScpЛђCuteFTPЕШЙЄОпНЋjdkКЭhadoop.tar.gzИДжЦЕНLinuxжаЃЈМйЩшИДжЦЕНСЫDownloadsЮФМўМажаЃЉЃЛ
<2>жДааУќСюЃКrm ЈCrf /usr/local/* ЩОГ§ИУЮФМўМаЯТЫљгаЮФМў
<3>жДааУќСюЃКcp /root/Downloads/* /usr/local/
НЋЦфИДжЦЕН/usr/local/ЮФМўМажа
4.7 АВзАJDK
<1>дк/usr/localЯТНтбЙjdkАВзАЮФМўЃК./jdk-6u24-linux-i586.binЃЈШчЙћБЈШЈЯоВЛзуЕФЬсЪОЃЌЧыЯШЮЊЕБЧАгУЛЇЖдДЫjdkдіМгжДааШЈЯоЃКchmod
u+x jdk-6u24-linux-i586.binЃЉ
<2>жиУќУћНтбЙКѓЕФjdkЮФМўМаЃКmv jdk1.6.0_24 jdkЃЈДЫВНДеЗЧБивЊЃЌжЛЪЧНЈвщЃЉ
<3>ХфжУLinuxЛЗОГБфСПЃКvi /etc/profileЃЌдкЦфжадіМгМИааЃК
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
<4>ЩњаЇЛЗОГБфСПХфжУЃКsource /etc/profile
бщжЄЃКjava ЈCversion
4.8 АВзАHadoop
<1>дк/usr/localЯТНтбЙhadoopАВзАЮФМў:tar ЈCzvxf hadoop-1.1.2.tar.gz
<2>НтбЙКѓжиУќУћhadoop-1.1.2ЮФМўМаЃКmv hadoop-1.1.2
hadoopЃЈДЫВНДеЗЧБивЊЃЌжЛЪЧНЈвщЃЉ
<3>ХфжУHadoopЯрЙиЛЗОГБфСПЃКvi /etc/profileЃЌдкЦфжадіМгвЛааЃК
export HADOOP_HOME=/usr/local/hadoop
ШЛКѓаоИФвЛааЃК
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME:$PATH
<4>ЩњаЇЛЗОГБфСПЃКsource /etc/profile
<5>аоИФHadoopЕФХфжУЮФМўЃЌЫќУЧЮЛгк$HADOOP_HOME/confФПТМЯТЁЃ
ЗжБ№аоИФЫФИіХфжУЮФМўЃКhadoop-env.shЁЂcore-site.xmlЁЂhdfs-site.xmlЁЂmapred-site.xmlЃЛ
ОпЬхЯТаоИФФкШнШчЯТЃКЃЈгЩгкаоИФФкШнНЯЖрЃЌНЈвщЪЙгУWinScpНјШыЯрЙиФПТМЯТНјааБрМКЭБЃДцЃЌПЩвдНкЪЁНЯЖрЪБМфКЭОЋСІЃЉ
5.1ЁОhadoop-env.shЁП аоИФЕкОХааЃК
export JAVA_HOME=/usr/local/jdk/
ШчЙћащФтЛњФкДцЕЭгк1GЃЌЛЙашвЊаоИФHADOOP_HEAPSIZEЃЈФЌШЯЮЊ1000ЃЉЕФжЕЃК
export HADOOP_HEAPSIZE=100
5.2ЁОcore-site.xmlЁП дкconfigurationжадіМгвдЯТФкШнЃЈЦфжаЕФhadoop-masterЮЊФуХфжУЕФжїЛњУћЃЉЃК
| <property>
ЁЁЁЁ<name>fs.default.name</name>
ЁЁЁЁ<value>hdfs://hadoop-master:9000</value>
ЁЁЁЁ<description>change your own hostname</description>
ЁЁЁЁ</property>
ЁЁЁЁ<property>
ЁЁЁЁ<name>hadoop.tmp.dir</name>
ЁЁЁЁ<value>/usr/local/hadoop/tmp</value>
ЁЁЁЁ</property> |
5.3 ЁОhdfs-site.xmlЁП дкconfigurationжадіМгвдЯТФкШнЃК
| <property>
ЁЁЁЁ<name>dfs.replication</name>
ЁЁЁЁ<value>1</value>
ЁЁЁЁ </property>
ЁЁЁЁ <property>
ЁЁЁЁ<name>dfs.permissions</name>
ЁЁЁЁ<value>false</value>
ЁЁЁЁ </property> |
5.4 ЁОmapred-site.xmlЁП дкconfigurationжадіМгвдЯТФкШнЃЈЦфжаЕФhadoop-masterЮЊФуХфжУЕФжїЛњУћЃЉЃК
| <property>
ЁЁЁЁ<name>mapred.job.tracker</name>
ЁЁЁЁ<value>hadoop-master:9001</value>
ЁЁЁЁ<description>change your own hostname</description>
ЁЁЁЁ</property> |
<6>жДааУќСюЖдHadoopНјааГѕЪМИёЪНЛЏЃКhadoop
namenode ЈCformat

<7>жДааУќСюЦєЖЏHadoopЃКstart-all.shЃЈвЛДЮадЦєЖЏЫљгаНјГЬЃЉ

ЕкЖўжжЗНЪНЃКЭЈЙ§жДааШчЯТЗНЪНУќСюЕЅЖРЦєЖЏHDFSКЭMapReduceЃКstart-dfs.shКЭstart-mapred.shЦєЖЏЃЌstop-dfs.shКЭstop-mapred.shЙиБеЃЛ
ЕкШ§жжЗНЪНЃКЭЈЙ§жДааШчЯТЗНЪНУќСюЗжБ№ЦєЖЏИїИіНјГЬЃК
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start jobtracker
hadoop-daemon.sh start tasktracker
етжжЗНЪНЕФжДааУќСюЪЧhadoop-daemon.sh start [НјГЬУћГЦ]ЃЌетжжЦєЖЏЗНЪНЪЪКЯгкЕЅЖРдіМгЁЂЩОГ§НкЕуЕФЧщПіЃЌдкАВзАМЏШКЛЗОГЕФЪБКђЛсПДЕНЁЃ
бщжЄЃК
Ђй жДааjpsУќСюВщПДjavaНјГЬаХЯЂЃЌШчЙћЪЧstart-all.shдђвЛЙВЯдЪО5ИіjavaНјГЬЁЃ
ЂкдкфЏРРЦїжафЏРРHadoopЃЌЪфШыURLЃКhadoop-master:50070КЭhadoop-master:50030ЁЃШчЙћЯыдкЫожїЛњWindowsжафЏРРЃЌПЩвджБНгЭЈЙ§ipЕижЗМгЖЫПкКХЗУЮЪЃЌвВПЩвдХфжУCХЬжаSystem32/drivers/etc/жаЕФhostsЮФМўЃЌдіМгDNSжїЛњУћгГЩфЃЌР§ШчЃК192.168.80.100
hadoop-masterЁЃ
ЗУЮЪаЇЙћШчЯТЭМЃК

<8>NameNodeНјГЬУЛгаЦєЖЏГЩЙІЃППЩвдДгвдЯТМИИіЗНУцМьВщЃК
УЛгаЖдNameNodeНјааИёЪНЛЏВйзїЃКhadoop namenode ЈCformatЃЈPSЃКЖрДЮИёЪНЛЏвВЛсГіДэЃЌБЃЯеВйзїЪЧЯШЩОГ§/usr/local/hadoop/tmpЮФМўМадйжиаТИёЪНЛЏЃЉ
HadoopХфжУЮФМўжЛИДжЦУЛаоИФЃК аоИФЫФИіХфжУЮФМўашвЊИФЕФВЮЪ§
DNSУЛгаЩшжУIPКЭhostnameЕФАѓЖЈЃКvi /etc/hosts
SSHЕФУтУмТыЕЧТМУЛгаХфжУГЩЙІЃКжиаТЩњГЩrsaУмдП
<9>HadoopЦєЖЏЙ§ГЬжаГіЯжвдЯТОЏИцЃП

ПЩвдЭЈЙ§вдЯТВНДеШЅГ§ИУОЏИцаХЯЂЃК
ЂйЪзЯШжДааУќСюВщПДshellНХБОЃКvi start-all.shЃЈдкbinФПТМЯТжДааЃЉЃЌПЩвдПДЕНШчЯТЭМЫљЪОЕФНХБО

ЫфШЛЮвУЧПДВЛЖЎshellНХБОЕФгяЗЈЃЌЕЋЪЧПЩвдВТЕНПЩФмКЭЮФМўhadoop-config.shгаЙиЃЌЮвУЧдйПДвЛЯТетИіЮФМўЕФдДТыЁЃжДааУќСюЃКvi
hadoop-config.shЃЈдкbinФПТМЯТжДааЃЉЃЌгЩгкИУЮФМўЬиДѓЃЌЮвУЧжЛНиШЁзюКѓвЛВПЗжЃЌМћЯТЭМЁЃ
ДгЭМжаЕФКьЩЋПђПђжаПЩвдПДЕНЃЌНХБОХаЖЯЛЗОГБфСПHADOOP_HOMEКЭHADOOP_HOME_WARN_SUPPRESSЕФжЕЃЌШчЙћЧАепЮЊПеЃЌКѓепВЛЮЊПеЃЌдђЯдЪООЏИцаХЯЂЁАWarningЁБЁЃ
ЮвУЧдкЧАУцЕФАВзАЙ§ГЬжавбОХфжУСЫHADOOP_HOMEетИіЛЗОГБфСПЃЌвђДЫЃЌжЛашвЊИјHADOOP_HOME_WARN_SUPPRESSХфжУвЛИіжЕОЭПЩвдСЫЁЃЫљвдЃЌжДааУќСюЃКvi
/etc/profileЃЌдіМгвЛааФкШнЃЈжЕЫцБуЩшжУвЛИіМДПЩЃЌетРяЩшЮЊ0ЃЉЃК
export HADOOP_HOME_WARN_SUPPRESS=0
БЃДцЭЫГіКѓжДаажиаТЩњаЇУќСюЃКsource /etc/profileЃЌЩњаЇКѓжиаТЦєЖЏhadoopНјГЬдђВЛЛсЬсЪООЏИцаХЯЂСЫЁЃ
жСДЫЃЌвЛИіHadoopЕФMasterНкЕуЕФАВзАХфжУНсЪјЃЌНгЯТРДЮвУЧвЊНјааДгНкЕуЕФХфжУЁЃ
|








