| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌБОЮФжївЊНщЩмСЫЭјвзШчКЮЭЈЙ§
SubmarineдЫааЩюЖШбЇЯАПђМмРДНтОіЛњЦїбЇЯАПЊЗЂКЭдЫЮЌЙ§ГЬЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
НщЩм
Hadoop ЪЧгУгкДѓаЭЦѓвЕЪ§ОнМЏЕФЗжВМЪНДІРэЕФзюСїааЕФПЊдДПђМмЃЌЫќдкБОЕиКЭдЦЖЫЛЗОГжаЖМгаКмЖрживЊгУЭОЁЃ
ЩюЖШбЇЯАЖдгкгявєЪЖБ№ЃЌЭМЯёЗжРрЃЌAI СФЬьЛњЦїШЫЃЌЛњЦїЗвыЕШСьгђЕФЦѓвЕШЮЮёЗЧГЃгагУЃЌНіОйМИР§ЁЃ ЮЊСЫбЕСЗЩюЖШбЇЯА
/ ЛњЦїбЇЯАФЃаЭЃЌПЩвдРћгУ TensorFlow / MXNet / Pytorch / Caffe
/ XGBoost ЕШПђМмЁЃ гаЪБашвЊНЋетаЉПђМмНјаазщКЯЪЙгУвдгУгкНтОіВЛЭЌЕФЮЪЬтЁЃ
ЮЊСЫЪЙЗжВМЪНЩюЖШбЇЯА / ЛњЦїбЇЯАгІгУГЬађвзгкЦєЖЏЃЌЙмРэКЭМрПиЃЌHadoop ЩчЧјЦєЖЏСЫ Submarine
ЯюФПвдМАЦфЫћИФНјЃЌР§ШчвЛСїЕФ GPU жЇГжЃЌDocker ШнЦїжЇГжЃЌШнЦї DNS жЇГжЃЌЕїЖШИФНјЕШЁЃ
етаЉИФНјЪЙЕУдк Apache Hadoop YARN ЩЯдЫааЕФЗжВМЪНЩюЖШбЇЯА / ЛњЦїбЇЯАгІгУГЬађОЭЯёдкБОЕидЫаавЛбљМђЕЅЃЌетПЩвдШУЛњЦїбЇЯАЙЄГЬЪІзЈзЂгкЫуЗЈЃЌЖјВЛЪЧЕЃаФЕзВуЛљДЁМмЙЙЁЃ
ЭЈЙ§Щ§МЖЕНзюаТЕФ HadoopЃЌгУЛЇЯждкПЩвддкЭЌвЛШКМЏЩЯдЫааЦфЫћ ETL / streaming зївЕРДдЫааЩюЖШбЇЯАЙЄзїИКдиЁЃ
етбљПЩвдЧсЫЩЗУЮЪЭЌвЛШКМЏЩЯЕФЪ§ОнЃЌДгЖјЪЕЯжИќКУЕФзЪдДРћгУТЪЁЃ

ЕфаЭЕФЩюЖШбЇЯАЙЄзїСїГЬЃКЪ§ОнДгИїИіжеЖЫЃЈЛђЦфЫћРДдДЃЉЛуОлЕНЪ§ОнКўжаЁЃ Ъ§ОнПЦбЇМвПЩвдЪЙгУБЪМЧБОНјааЪ§ОнЬНЫїЃЌДДНЈ
pipelines РДНјааЬиеїЬсШЁ / ЗжИюбЕСЗ / ВтЪдЪ§ОнМЏЁЃ ВЂПЊеЙЩюЖШбЇЯАКЭбЕСЗЙЄзїЁЃ етаЉЙ§ГЬПЩвджиИДНјааЁЃ
вђДЫЃЌдкЭЌвЛИіМЏШКЩЯдЫааЩюЖШбЇЯАзївЕПЩвдЯджјЬсИпЪ§Он / МЦЫузЪдДЙВЯэЕФаЇТЪЁЃ
ШУЮвУЧзаЯИПДПД Submarine ЯюФПЃЈЫќЪЧ Apache Hadoop ЯюФПЕФвЛВПЗжЃЉЃЌЧыПДЯТШчКЮдк
Hadoop ЩЯдЫааетаЉЩюЖШбЇЯАЙЄзїЁЃ
ЮЊЪВУДНа Submarine етИіУћзжЃП
вђЮЊЧБЭЇЪЧЮЈвЛПЩвдНЋШЫРрДјЕНИќЩюДІЕФзАжУЩшБИЁЃB-ЃЉ

ЭМЦЌгЩ NOAA АьЙЋЪвЬсЙЉКЃбѓПБЬНгыбаОПЃЌФЋЮїИчЭх 2018 ФъЁЃ
SUBMARINE ИХРР
Submarine ЯюФПгаСНИіВПЗжЃКSubmarine МЦЫув§ЧцКЭвЛЬзМЏГЩ Submarine ЕФЩњЬЌЯЕЭГШэМўКЭЙЄОпЁЃ
Submarine МЦЫув§Чц ЭЈЙ§УќСюааЯђ YARN ЬсНЛЖЈжЦЕФЩюЖШбЇЯАгІгУГЬађЃЈШч TensorflowЃЌPytorch
ЕШЃЉЁЃ етаЉгІгУГЬађгы YARN ЩЯЕФЦфЫћгІгУГЬађВЂаадЫааЃЌР§Шч Apache SparkЃЌHadoop
Map / Reduce ЕШЁЃ
зюживЊЕФЪЧЮвУЧЕФгавЛЬзМЏГЩ Submarine ЕФЩњЬЌЯЕЭГШэМўКЭЙЄОпЃЌФПЧААќРЈЃК
1.Submarine-Zeppelin integration:
дЪаэЪ§ОнПЦбЇМвдк Zeppelin ЕФ notebook жаБраДЫуЗЈКЭЕїВЮНјааПЩЪгЛЏЪфГіЃЌВЂжБНгДг
notebook ЬсНЛКЭЙмРэЛњЦїбЇЯАЕФбЕСЗЙЄзїЁЃ
2.Submarine-Azkaban integration:
дЪаэЪ§ОнПЦбЇМвДг Zeppelin ЕФ notebook жажБНгЯђ Azkaban ЬсНЛвЛзщОпгавРРЕЙиЯЕЕФШЮЮёЃЌзщГЩЙЄзїСїНјаажмЦкадЕїЖШЁЃ
3.Submarine-installer: дкФњЕФЗўЮёЦїЛЗОГжаАВзА
Submarine КЭ YARNЃЌЧсЫЩНтОі Docker ЁЂParallel network КЭ nvidia
Ч§ЖЏЕФАВзАВПЪ№ФбЬтЃЌвдБуФњИќЧсЫЩЕиГЂЪдЧПДѓЕФЙЄОпМЏЁЃ
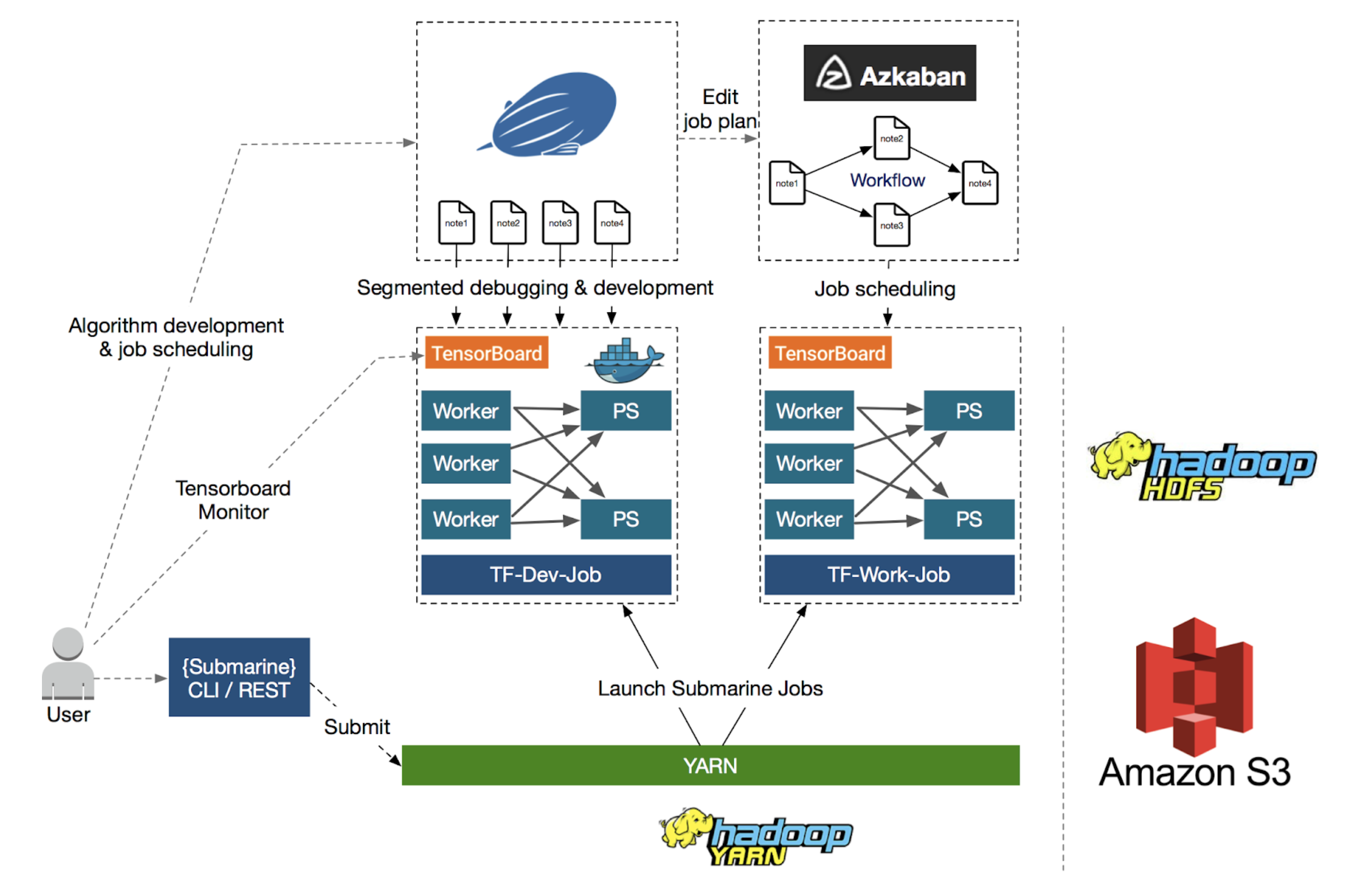
ЭМБэЫЕУїСЫ Submarine ЕФећЬхЙЙГЩЃЌЕзВПЯдЪОСЫ Submarine МЦЫув§ЧцЃЌЫќжЛЪЧ YARN
ЕФвЛИігІгУГЬађЁЃ дкМЦЫув§ЧцжЎЩЯЃЌЫќМЏГЩЕНЦфЫћЩњЬЌЯЕЭГЃЌШчБЪМЧБОЕчФдЃЈZeppelin / JupyterЃЉКЭ
AzkabanЁЃ
SUBMARINE ФмЙЛзіЪВУД?
ЭЈЙ§ЪЙгУ Submarine МЦЫув§ЧцЃЌгУЛЇжЛашЬсНЛвЛИіМђЕЅЕФ CLI УќСюМДПЩдЫааЕЅ / ЗжВМЪНЩюЖШбЇЯАбЕСЗЙЄзїЃЌВЂДг
YARN UI жаЛёШЁЭъећЕФдЫааЧщПіЁЃ ЫљгаЦфЫћИДдгадЃЌШчдЫааЗжВМЪНЕШЃЌЖМЛсгЩ YARN ИКд№ЁЃ ЮвУЧРДПДМИИіР§згЃК
ОЭЯё HELLO WORLD вЛбљЧсЫЩЦєЖЏЗжВМЪНЩюЖШбЇЯАбЕСЗ
вдЯТУќСюЦєЖЏЩюЖШбЇЯАбЕСЗЙЄзїЖСШЁ HDFS ЩЯ ЕФ cifar10
Ъ§ОнЁЃ етЯюЙЄзїЪЧЪЙгУгУЛЇжИЖЈЕФ Docker ОЕЯёЃЌгы YARN ЩЯдЫааЕФЦфЫћзївЕЙВЯэМЦЫузЪдДЃЈШч
CPU / GPU / ФкДцЃЉЁЃ
| yarn
jar hadoop-yarn-applications-submarine-<version>.jar
job run \
ЈCname tf-job-001 ЈCdocker_image <your docker
image> \
ЈCinput_path hdfs://default/dataset/cifar-10-data
\
ЈCcheckpoint_path hdfs://default/tmp/cifar-10-jobdir
\
ЈCnum_workers 2 \
ЈCworker_resources memory=8G,vcores=2,gpu=2 \
ЈCworker_launch_cmd ЁАcmd for worker ЁЁБ \
ЈCnum_ps 2 \
ЈCps_resources memory=4G,vcores=2 \
ЈCps_launch_cmd ЁАcmd for psЁБ |
ЭЈЙ§ TENSORBOARD ЗУЮЪФњЫљгаЕФбЕСЗРњЪЗШЮЮё
вдЯТУќСюЦєЖЏЩюЖШбЇЯАбЕСЗЙЄзїЖСШЁ HDFS ЩЯЕФ cifar10
Ъ§ОнЁЃ
| yarn
jar hadoop-yarn-applications-submarine-<version>.jar
job run \
ЈCname tensorboard-service-001 ЈCdocker_image
<your docker image> \
ЈCtensorboard |
дк YARN UI ЩЯЃЌгУЛЇжЛашЕЅЛїМДПЩЗУЮЪ tensorboardЃК

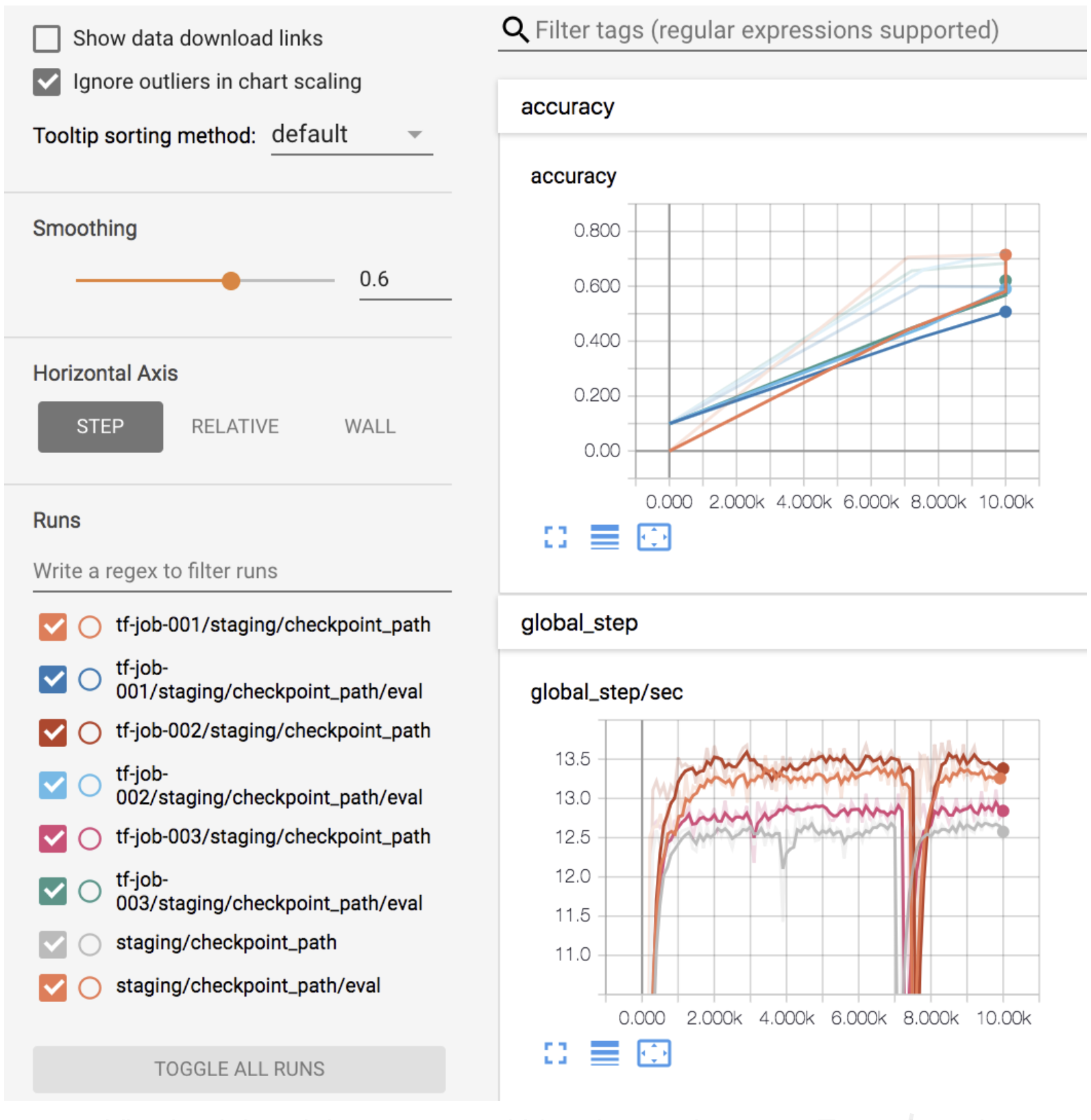
дкЭЌвЛ Tensorboard ЩЯВщПДбЕСЗзДЬЌКЭРњЪЗМЧТМЁЃ
дЦЖЫЪ§ОнПЦбЇМв NOTEBOOK
Яыдк GPU ЛњЦїЩЯгУБЪМЧБОБраДЫуЗЈТ№ЃП ЪЙгУ SubmarineЃЌФњПЩвдДг YARN зЪдДГиЛёШЁдЦЖЫ
notebookЁЃ
ЭЈЙ§дЫаавдЯТУќСюЃЌФњПЩвдЛёЕУвЛИі notebookЃЌЦфжаАќРЈ 8GB
ФкДцЃЌ2 Иі vcores КЭ 4 ИіРДзд YARN ЕФ GPUЁЃ
| yarn
jar hadoop-yarn-applications-submarine-<version>.jar
job run \
ЈCname zeppelin-noteЁЊbook-001 ЈCdocker_image <your
docker image> \
ЈCnum_workers 1 \
ЈCworker_resources memory=8G,vcores=2,gpu=4 \
ЈCworker_launch_cmd ЁА/zeppelin/bin/zeppelin.shЁБ
\
ЈCquicklink Zeppelin_Notebook=http://master-0:8080 |
ШЛКѓдк YARN UI ЩЯЃЌФњжЛашЕЅЛївЛЯТМДПЩЗУЮЪБЪМЧБОЁЃ

SUBMARINE ЩњЬЌ
Hadoop Submarine ЯюФПЕФФПБъЪЧЬсЙЉЩюЖШбЇЯАГЁОАжаЕФЪ§ОнЃЈЪ§ОнВЩМЏЃЌЪ§ОнДІРэЃЌЪ§ОнЧхРэЃЉЃЌЫуЗЈЃЈНЛЛЅЪНЃЌПЩЪгЛЏБрГЬКЭЕїгХЃЉЃЌзЪдДЕїЖШЃЌЫуЗЈФЃаЭЗЂВМКЭзївЕЕїЖШЕФШЋСїГЬЗўЮёжЇГжЁЃ
ЭЈЙ§гы Zeppelin НсКЯЃЌКмУїЯдПЩвдНтОіЪ§ОнКЭЫуЗЈЮЪЬтЁЃ Hadoop Submarine
ЛЙНЋНтОі Azkaban ЕФзївЕЕїЖШЮЪЬтЁЃ Ш§МўЬзЙЄОпМЏЃКZeppelin + Hadoop Submarine
+ Azkaban ЮЊФњЬсЙЉвЛИіСуШэМўГЩБОЕФЁЂПЊЗХЫљгадДТыЕФЫцЪБПЩгУЕФЩюЖШбЇЯАПЊЗЂЦНЬЈЁЃ
SUBMARINE МЏГЩ ZEPPELIN
Zeppelin ЪЧвЛПюЛљгкЭјТчЕФБЪМЧБОЕчФдЃЌжЇГжНЛЛЅЪНЪ§ОнЗжЮіЁЃ ФњПЩвдЪЙгУ SQLЃЌScalaЃЌPython
ЕШРДжЦзїЪ§ОнЧ§ЖЏЕФНЛЛЅЪНазїЮФЕЕЁЃ
дкЭъГЩЛњЦїбЇЯАжЎЧАЃЌФњПЩвдЪЙгУ Zeppelin жаЕФ 20 ЖржжНтЪЭЦїЃЈР§Шч SparkЃЌHiveЃЌCassandraЃЌElasticsearchЃЌKylinЃЌHBase
ЕШЃЉдк Hadoop жаЕФЪ§ОнжаЪеМЏЪ§ОнЃЌЧхРэЪ§ОнЃЌЬиеїЬсШЁЕШЁЃ ФЃЬибЕСЗЃЌЭъГЩЪ§ОндЄДІРэЙ§ГЬЁЃ
ЮвУЧЬсЙЉ Submarine НтЪЭЦїЃЌвджЇГжЛњЦїбЇЯАЙЄГЬЪІДг Zeppelin БЪМЧБОжаНјааЫуЗЈПЊЗЂЃЌВЂжБНгЯђ
YARN ЬсНЛбЕСЗШЮЮёВЂДг Zeppelin жаЛёЕУНсЙћЁЃ
ЪЙгУ ZEPPELIN SUBMARINE НтЪЭЦї
ФуПЩвддк zeppelin жаДДНЈ submarine НтЪЭЦїЁЃ
дк notebook ЕФЕквЛаажжЪфШы %submarine.python REPLЃЈRead-Eval-Print
LoopЃЌМђГЦ REPLЃЉУћГЦЃЌФуОЭПЩвдПЊЪМБраД tensorflow ЕФ python ЫуЗЈЃЌФуПЩвддквЛИі
Notebook жажСЩЯЖјЯТЗжЖЮТфЕФБраДвЛИіЛђЖрИіЫуЗЈФЃПщЃЌЗжПщБраДЫуЗЈНсКЯПЩЪгЛЏЪфГіНЋЛсАяжњФуИќШнвзбщжЄДњТыЕФе§ШЗадЁЃ

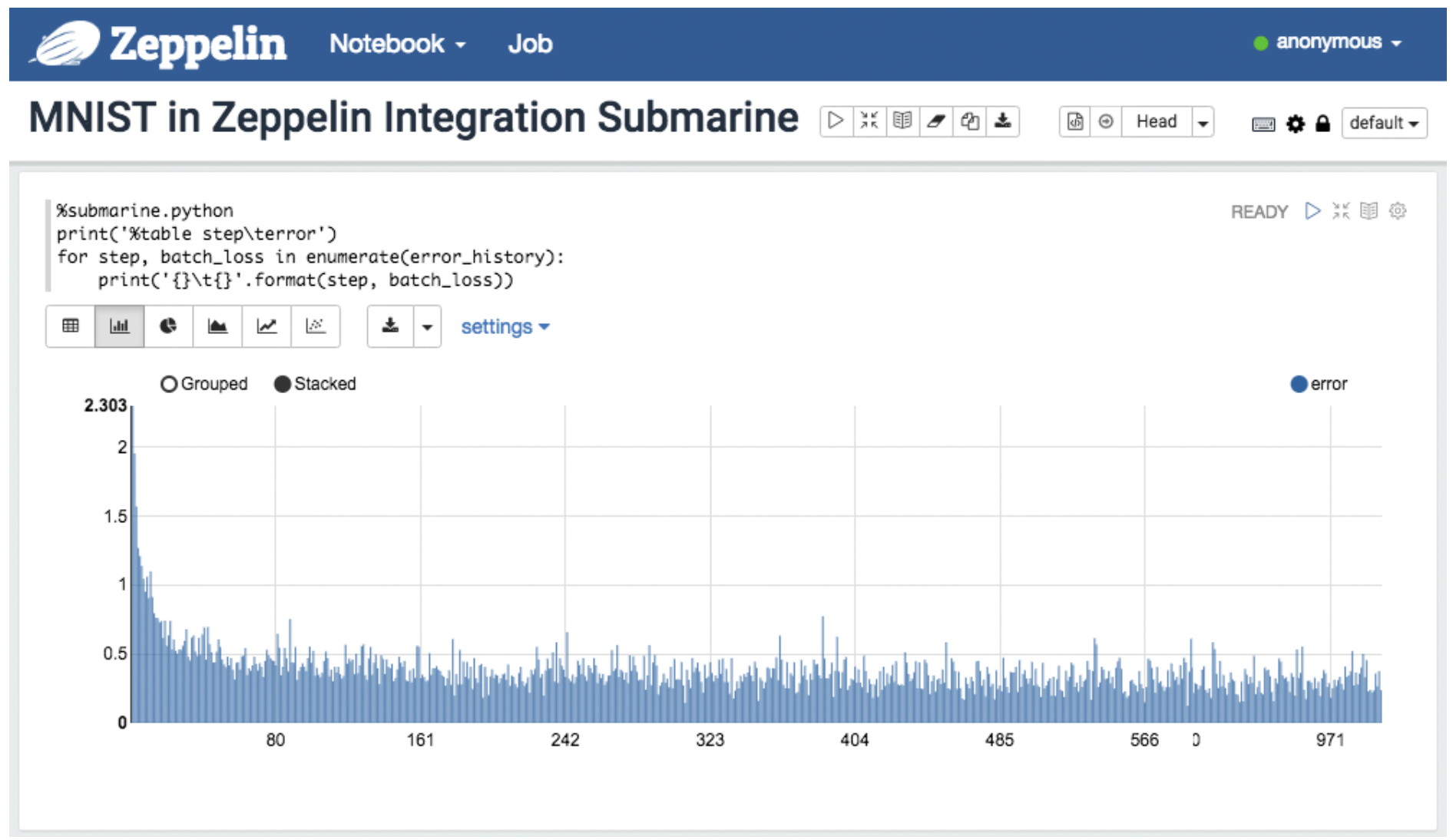
The zeppelin submarine НтЪЭЦїЛсздЖЏНЋЗжПщБраДЕФЫуЗЈФЃПщНјааКЯВЂЬсНЛЕН submarine
МЦЫув§ЧцжажДааЁЃ
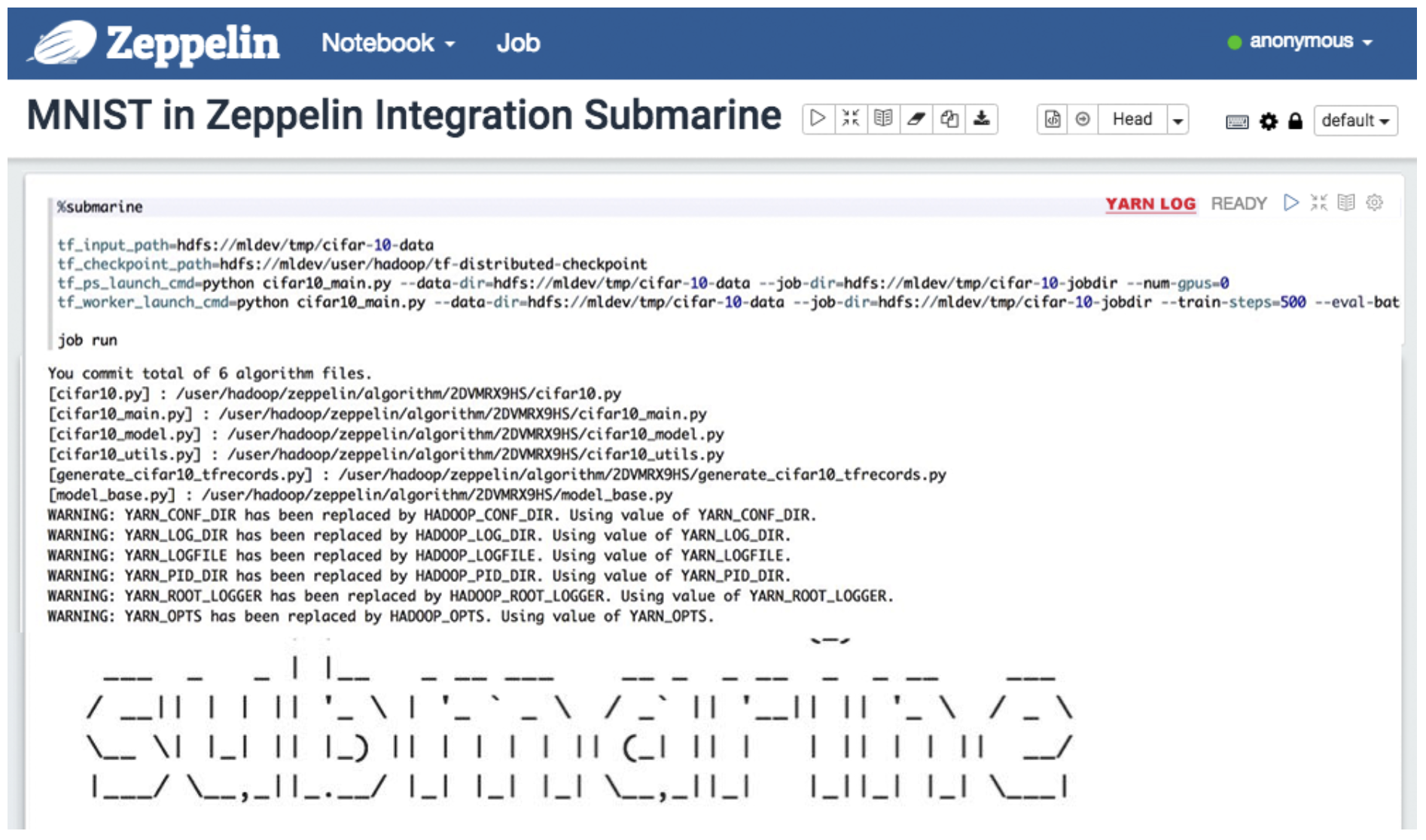
ЭЈЙ§ЕуЛї Notebook жаЕФ YARN LOG ГЌСДНгЃЌФуНЋЛсДђПЊ YARN ЕФЙмРэвГУцВщПДжДааЕФШЮЮёЁЃ

дк YARN ЙмРэвГУцжаЃЌФњПЩвдДђПЊздМКЕФШЮЮёСДНгЃЌВщПДШЮЮёЕФ docker ШнЦїЪЙгУЧщПівдМАЫљгажДааШежОЁЃ
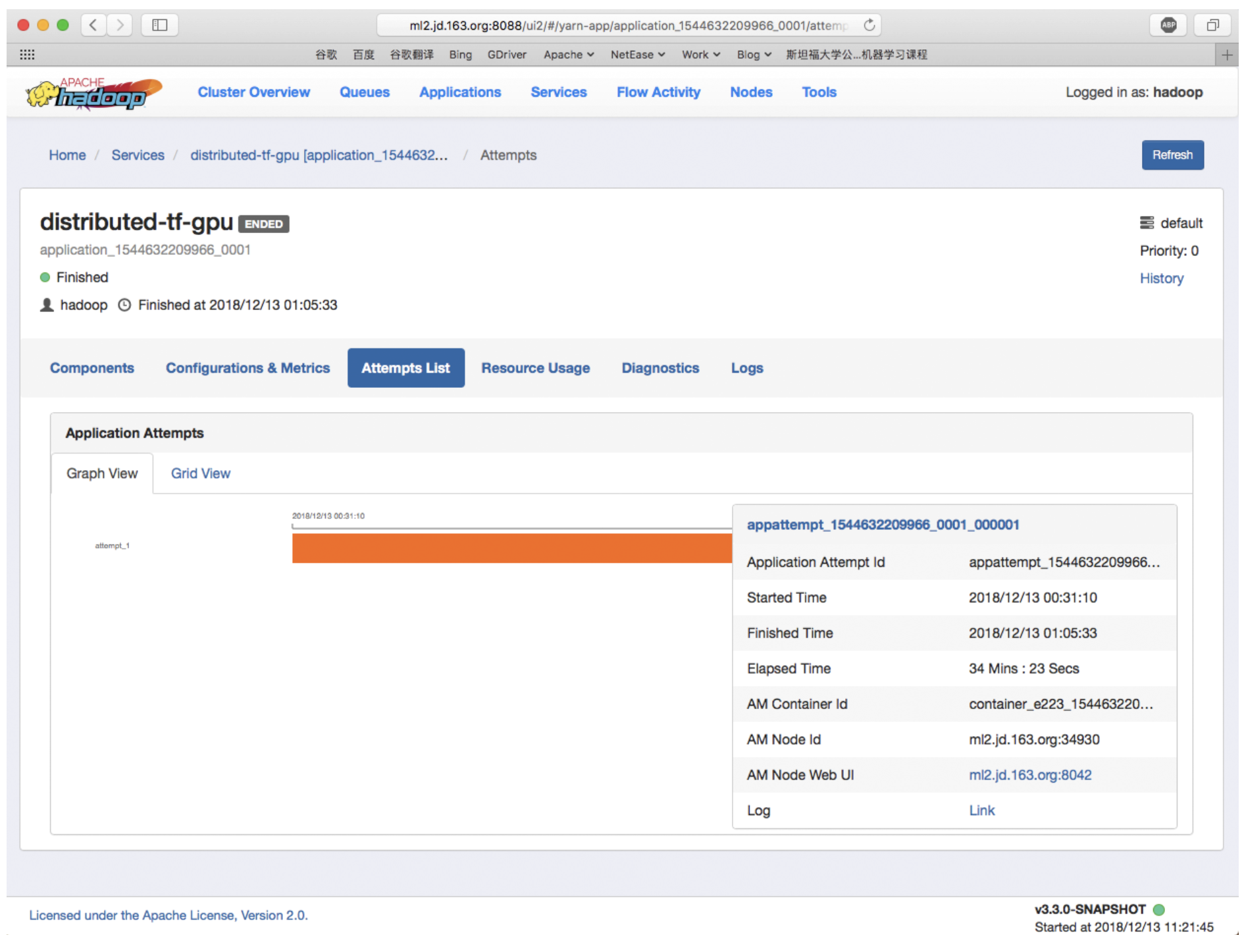
гаСЫетИіЧПДѓЕФЙЄОпЃЌЪ§ОнПЦбЇМвВЛашвЊСЫНт YARN ЕФИДдгадЛђШчКЮЪЙгУ Submarine МЦЫув§ЧцЁЃ
ЬсНЛ Submarine бЕСЗЙЄзїгыдкБЪМЧБОжадЫаа Python НХБОЭъШЋЯрЭЌЁЃ зюживЊЕФЪЧЃЌгУЛЇЮоашИќИФЦфвбгаЫуЗЈГЬађМДПЩзЊЛЛЮЊ
Submarine зївЕдЫааЁЃ
SUBMARINE МЏГЩ AZKABAN
Azkaban ЪЧвЛжжвзгкЪЙгУЕФЙЄзїСїГЬАВХХЗўЮёЃЌЭЈЙ§ Azkaban АВХХ Zeppelin БраДЕФ
Hadoop Submarine Notebook РДАВХХжИЖЈ Notebook ЩшжУФГаЉЖЮТфжЎМфЕФЙЄзїСїГЬЁЃ
ФњПЩвддк Zeppelin жаЪЙгУ Azkaban ЕФзївЕЮФМўИёЪНЃЌБраДОпгажДаавРРЕадЕФЖрИіБЪМЧБОжДааШЮЮёЁЃ
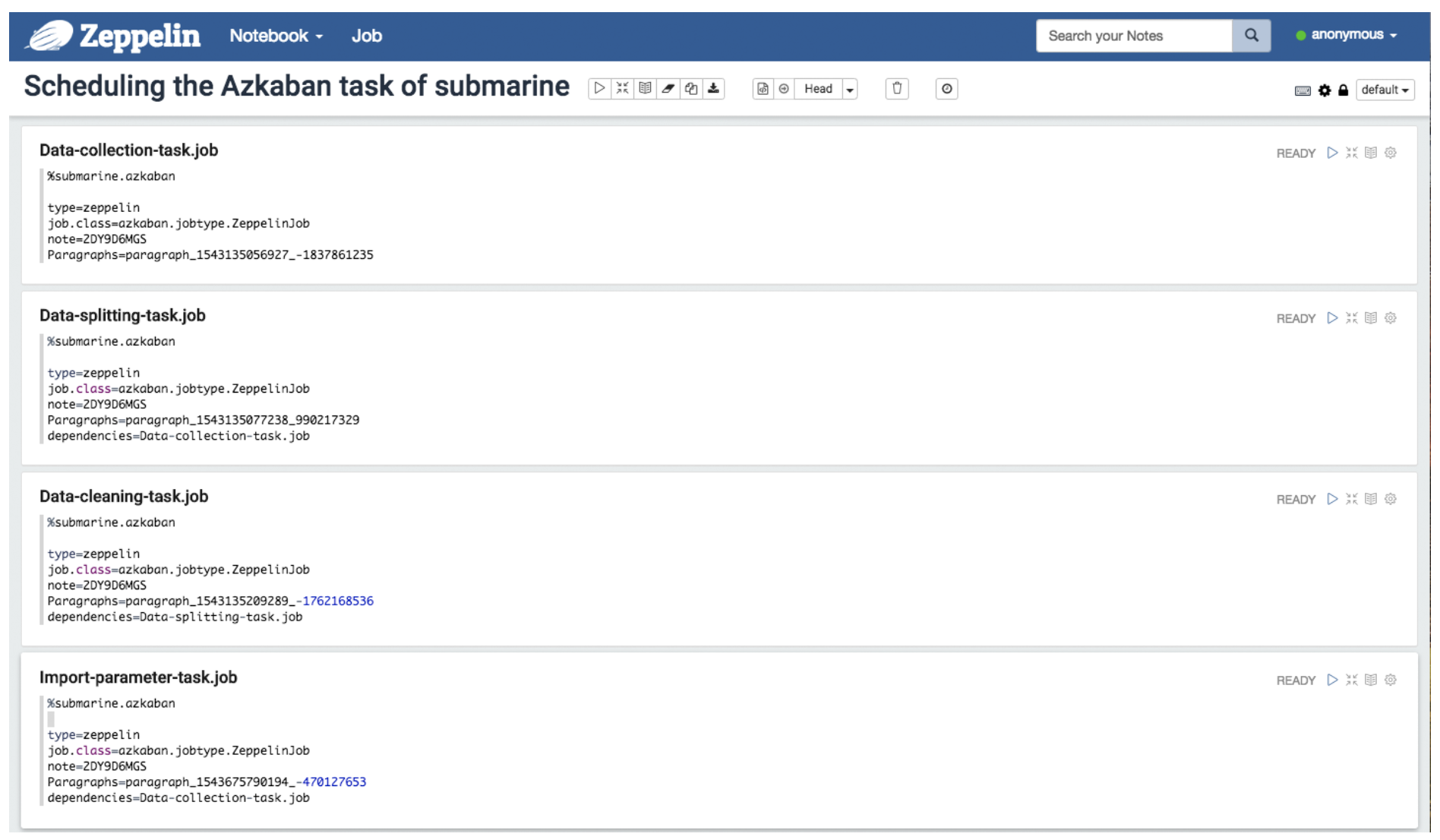
Azkaban ФмЙЛЕїЖШетаЉЭЈЙ§ zeppelin БрМКУЕФОпгавРРЕЙиЯЕЕФ notebookЁЃ
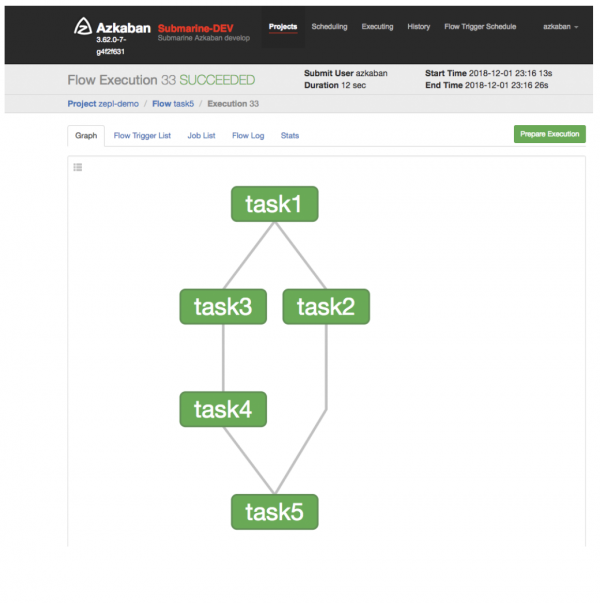
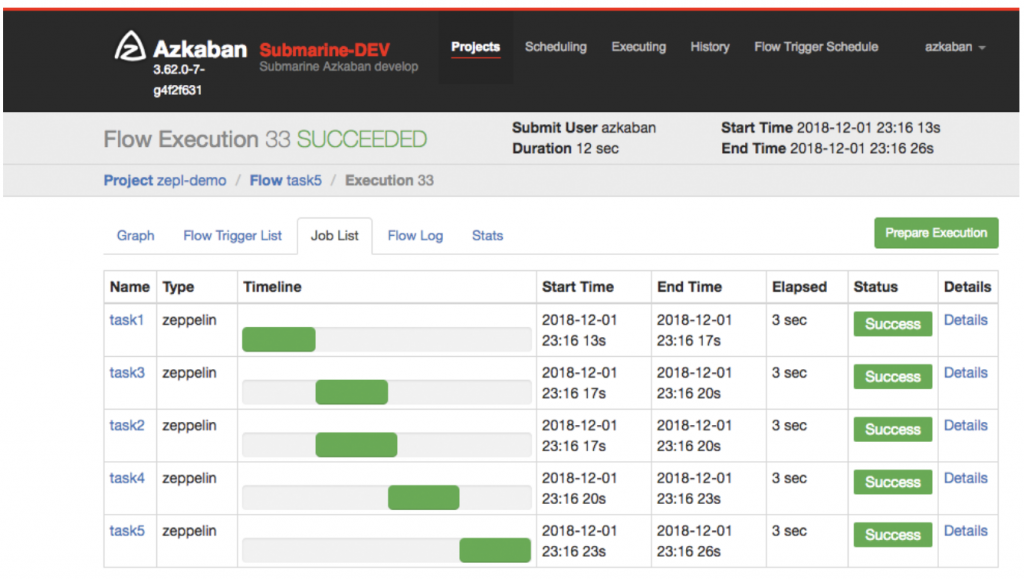
вЛЕЉжДааСЫДјга Azkaban НХБОЕФ notebookЃЌЫќНЋБЛБрвыЮЊ Azkaban жЇГжЕФЙЄзїСїВЂЬсНЛИј
Azkaban вджДааЁЃ
HADOOP SUBMARINE АВзАГЬађ
гЩгкЗжВМЪНЩюЖШбЇЯАПђМмашвЊдкЖрИі Docker ШнЦїжадЫааЃЌВЂЧвашвЊФмЙЛаЕїШнЦїжадЫааЕФИїжжЗўЮёЃЌвђДЫашвЊЮЊЗжВМЪНЛњЦїбЇЯАЭъГЩФЃаЭбЕСЗКЭФЃаЭЗЂВМЗўЮёЁЃ
етЦфжаНЋЩцМАЕНЖрИіЯЕЭГЙЄГЬЮЪЬтЃЌШч DNSЃЌDockerЃЌGPUЃЌЭјТчЃЌЯдПЈЧ§ЖЏЃЌВйзїЯЕЭГФкКЫаоИФЕШЃЌе§ШЗВПЪ№етаЉдЫааЛЗОГЪЧвЛМўЗЧГЃРЇФбКЭКФЪБЕФЪТЧщЁЃ
ЮвУЧЮЊФњЬсЙЉСЫ submarine installer ЃЌгУгкдЫааЪБЛЗОГЕФАВзАЃЌ submarine
installer ЪЧвЛИіЭъШЋгЩ Shell НХБОБраДЃЌЬсЙЉСЫМђЕЅвзгУЕФВЫЕЅЛЏВйзїЗНЪНЃЌФњжЛашвЊдквЛЬЈПЩвдСЊЭјЕФЗўЮёЦїЩЯдЫааЃЌОЭПЩвдЧсЫЩБуНнЕФАВзАКУдЫааЛЗОГЁЃ
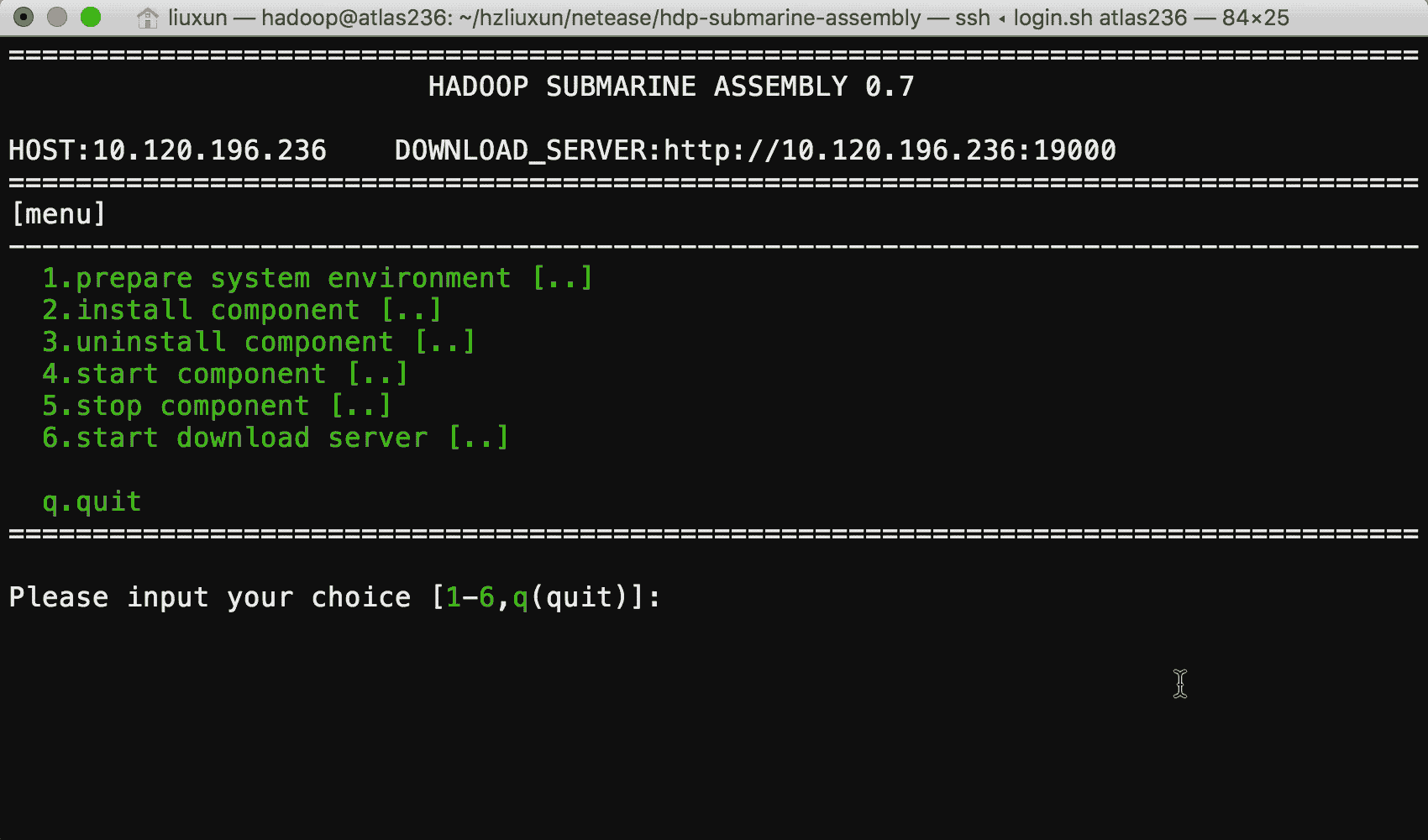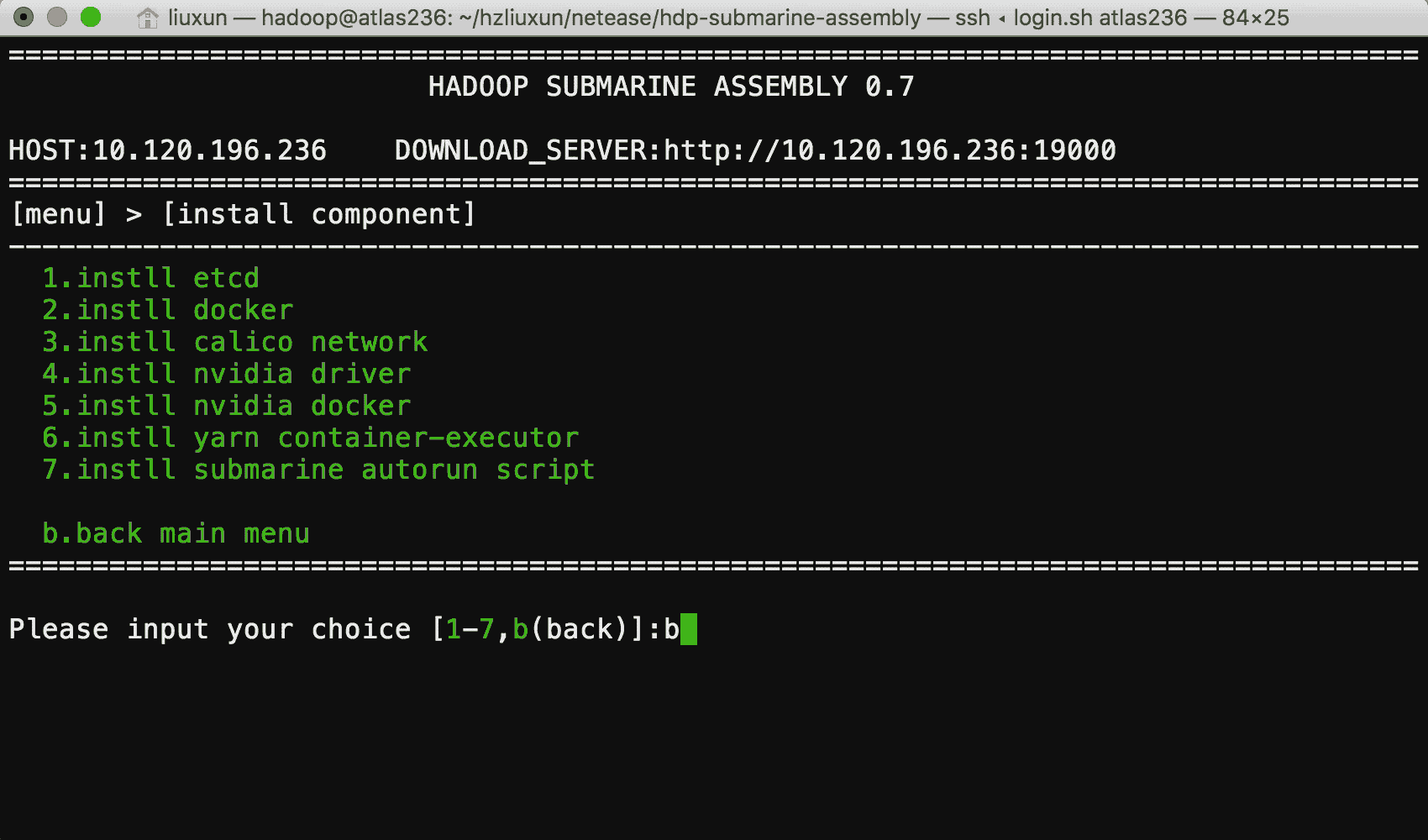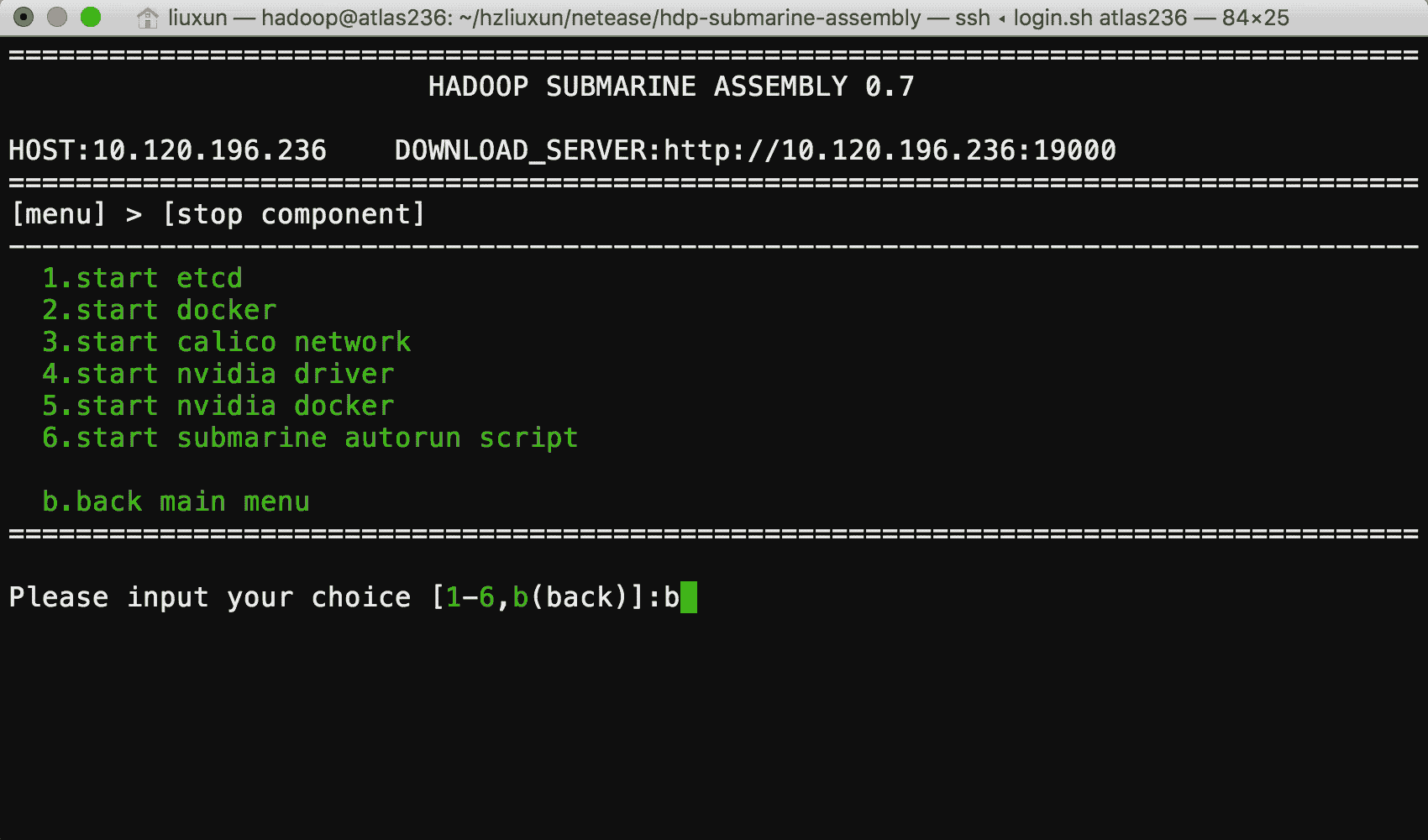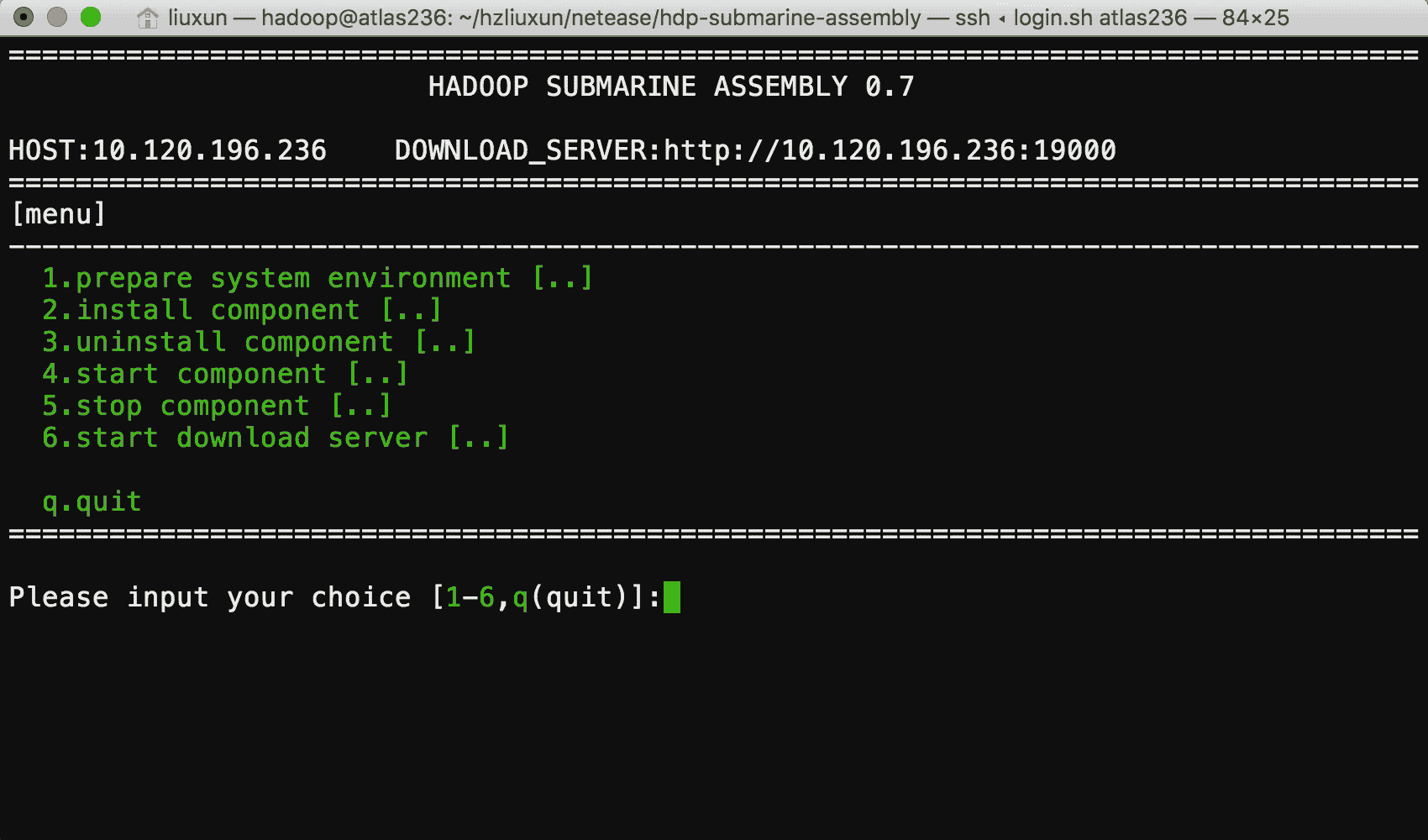
АВзАЙ§ГЬжаФуШчЙћгіМћЮЪЬтЃЌЛЙПЩвдЭЈЙ§ЮвУЧЬсЙЉЕФ АВзАЪжВс НјааНтОіЁЃ
ЯюФПзДЬЌ
Alpha АцБОЕФНтОіЗНАИвбОКЯВЂЕН Haodop жїИЩЗжжЇЁЃ 3.2.0 АцБОЕФвЛВПЗжШдДІгкЛюЖЏПЊЗЂ
/ ВтЪдНзЖЮЁЃUmbrella JIRA: YARN-8135.
Submarine ФмЙЛдЫаадк Apache Hadoop 3.1+.x release АцБОЩЯЃЌЪЕМЪЩЯФужЛашвЊАВзА
Apache Hadoop 3.1 ЕФ YARN ОЭПЩвдЪЙгУЭъећЕФ Submarine ЕФЙІФмКЭЗўЮёЃЌОЙ§ЮвУЧЕФЪЕМЪЪЙгУЃЌ
Apache Hadoop 3.1 ЕФ YARN ПЩвдЭъШЋЮоЮѓЕФжЇГж Hadoop 2.7 + вдЩЯЕФ
HDFS ЯЕЭГЁЃ
АИР§ ЈC Эјвз
ЭјвзКМбаДѓЪ§ОнЭХЖгЪЧ Submarine ЯюФПЕФжївЊЙБЯзепжЎвЛЃЌжївЊЯЃЭћЭЈЙ§ Submarine РДНтОіЛњЦїбЇЯАПЊЗЂКЭдЫЮЌЙ§ГЬжагіЕНЕФвдЯТЮЪЬтЃК
ЯжгаМЦЫуМЏШКЕФзДЬЌЃК
1.ЭјвзЭЈЙ§ЛЅСЊЭјЬсЙЉдкЯпгЮЯЗ / ЕчЩЬ / вєРж / аТЮХЕШЗўЮёЁЃ
2.YARN МЏШКжадЫаага ~ 4k ЗўЮёЦїНкЕу
3.УПЬь 100k МЦЫуШЮЮё
ЕЅЖРВПЪ№ЕФ Kubernetes МЏШКЃЈХфБИ GPUЃЉгУгкЛњЦїбЇЯАЙЄзїИКди
1.УПЬь 1000+ МЦЫубЇЯАШЮЮё
2.ЫљгаЕФ HDFS Ъ§ОнЖМЪЧЭЈЙ§ SparkЁЂHiveЁЂimpala
ЕШМЦЫув§ЧцНјааДІРэ
ДцдкЕФЮЪЬтЃК
гУЛЇЬхбщВЛМб
УЛгаМЏГЩЕФВйзїЦНЬЈЃЌШЋВПЭЈЙ§ЪжЖЏБраДЫуЗЈЃЌЬсНЛзївЕКЭМьВщдЫааНсЙћЃЌаЇТЪЕЭЃЌШнвзГіДэЁЃ
РћгУТЪЕЭ
ЮоЗЈжигУЯжгаЕФ YARN ШКМЏзЪдДЁЃ
ЮоЗЈМЏГЩЯжгаЕФДѓЪ§ОнДІРэЯЕЭГЃЈР§ШчЃКsparkЃЌhive ЕШЃЉ
ЮЌЛЄГЩБОИпЃЈашвЊЙмРэЗжРыЕФМЏШКЃЉ
ашвЊЭЌЪБдЫЮЌ Hadoop КЭ Kubernetes СНЬзВйзїЛЗОГЃЌдіМгЮЌЛЄГЩБОКЭбЇЯАГЩБОЁЃ
ЭјвзФкВП Submarine ВПЪ№ЧщПі
1.Л§МЋгы Submarine ЩчЧјКЯзїПЊЗЂЃЌвбОбщжЄ 20 Иі GPU
НкЕуМЏШКЩЯЕФ Submarine ЕФПЩППадЁЃ
2.МЦЛЎНЋРДНЋЫљгаЩюЖШбЇЯАЙЄзїзЊвЦЕН Submarine ЩЯ |








