| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдАЃЌБОЮФжївЊНщЩмСЫЖд
Flink зівЛИіМђвЊЕФЦЪЮіШЯЪЖвдМА FlinkАцБОжа ЕФНгПкжЇГжЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
1.ИХЪі
дкШчНёЪ§ОнБЌеЈЕФЪБДњЃЌЦѓвЕЕФЪ§ОнСПгыШеОудіЃЌДѓЪ§ОнВњЦЗВуГіВЛЧюЁЃНёЬьИјДѓМвЗжЯэвЛПюВњЦЗЁЊЁЊ
Apache FlinkЃЌФПЧАЃЌвбЪЧ Apache ЖЅМЖЯюФПжЎвЛЁЃФЧУДЃЌНгЯТРДЃЌБЪепЮЊДѓМвНщЩмFlink
ЕФЯрЙиФкШнЁЃ
2.ФкШн
2.1 What's Flink
Apache Flink ЪЧвЛИіУцЯђЗжВМЪНЪ§ОнСїДІРэКЭХњСПЪ§ОнДІРэЕФПЊдДМЦЫуЦНЬЈЃЌЫќФмЙЛЛљгкЭЌвЛИіFlinkдЫааЪБЃЈFlink
RuntimeЃЉЃЌЬсЙЉжЇГжСїДІРэКЭХњДІРэСНжжРраЭгІгУЕФЙІФмЁЃЯжгаЕФПЊдДМЦЫуЗНАИЃЌЛсАбСїДІРэКЭХњДІРэзїЮЊСНжжВЛЭЌЕФгІгУРраЭЃЌвђЮЊЫћУЧЫќУЧЫљЬсЙЉЕФSLAЪЧЭъШЋВЛЯрЭЌЕФЃКСїДІРэвЛАуашвЊжЇГжЕЭбгГйЁЂExactly-onceБЃжЄЃЌЖјХњДІРэашвЊжЇГжИпЭЬЭТЁЂИпаЇДІРэЃЌЫљвддкЪЕЯжЕФЪБКђЭЈГЃЪЧЗжБ№ИјГіСНЬзЪЕЯжЗНЗЈЃЌЛђепЭЈЙ§вЛИіЖРСЂЕФПЊдДПђМмРДЪЕЯжЦфжаУПвЛжжДІРэЗНАИЁЃР§ШчЃЌЪЕЯжХњДІРэЕФПЊдДЗНАИгаMapReduceЁЂTezЁЂCrunchЁЂSparkЃЌЪЕЯжСїДІРэЕФПЊдДЗНАИгаSamzaЁЂStormЁЃ
FlinkдкЪЕЯжСїДІРэКЭХњДІРэЪБЃЌгыДЋЭГЕФвЛаЉЗНАИЭъШЋВЛЭЌЃЌЫќДгСэвЛИіЪгНЧПДД§СїДІРэКЭХњДІРэЃЌНЋЖўепЭГвЛЦ№РДЃКFlinkЪЧЭъШЋжЇГжСїДІРэЃЌвВОЭЪЧЫЕзїЮЊСїДІРэПДД§ЪБЪфШыЪ§ОнСїЪЧЮоНчЕФЃЛХњДІРэБЛзїЮЊвЛжжЬиЪтЕФСїДІРэЃЌжЛЪЧЫќЕФЪфШыЪ§ОнСїБЛЖЈвхЮЊгаНчЕФЁЃЛљгкЭЌвЛИіFlinkдЫааЪБЃЈFlink
RuntimeЃЉЃЌЗжБ№ЬсЙЉСЫСїДІРэКЭХњДІРэAPIЃЌЖјетСНжжAPIвВЪЧЪЕЯжЩЯВуУцЯђСїДІРэЁЂХњДІРэРраЭгІгУПђМмЕФЛљДЁЁЃ
Flink ЪЧвЛПюаТЕФДѓЪ§ОнДІРэв§ЧцЃЌФПБъЪЧЭГвЛВЛЭЌРДдДЕФЪ§ОнДІРэЁЃетИіФПБъПДЦ№РДКЭ
Spark КЭРрЫЦЁЃетСНЬзЯЕЭГЖМдкГЂЪдНЈСЂвЛИіЭГвЛЕФЦНЬЈПЩвддЫааХњСПЃЌСїЪНЃЌНЛЛЅЪНЃЌЭМДІРэЃЌЛњЦїбЇЯАЕШгІгУЁЃЫљвдЃЌFlink
КЭ Spark ЕФФПБъВювьВЂВЛДѓЃЌЫћУЧзюжївЊЕФЧјБ№дкгкЪЕЯжЕФЯИНкЁЃ
ЯТУцИНЩЯ Flink ММЪѕеЛЕФвЛИізмРРЃЌШчЯТЭМЫљЪОЃК

2.2 Compare
СЫНт Flink ЕФзїгУКЭгХШБЕуЃЌашвЊгавЛИіВЮееЮяЃЌетРяЃЌБЪепвдЫќгы
Spark РДЖдБШВћЪіЁЃДгГщЯѓВуЃЌФкДцЙмРэЃЌгябдЪЕЯжЃЌвдМА API КЭ SQL ЕШЗНУцРДзИЪіЁЃ
2.2.1 Abstraction
НгДЅЙ§ Spark ЕФЭЌбЇЃЌгІИУБШНЯЪьЯЄЃЌдкДІРэХњДІРэШЮЮёЃЌПЩвдЪЙгУ
RDDЃЌЖјЖдгкСїДІРэЃЌПЩвдЪЙгУ StreamingЃЌШЛЦфЪРМЭЛЙЪЧ RDDЃЌЫљвдБОжЪЩЯЛЙЪЧ RDD ГщЯѓЖјРДЁЃЕЋЪЧЃЌдк
Flink жаЃЌХњДІРэгУ DataSetЃЌЖдгкСїДІРэЃЌга DataStreamsЁЃЫМЯыРрЫЦЃЌЕЋШДгаЫљВЛЭЌЃКЦфвЛЃЌDataSet
дкдЫааЪББэЯжЮЊ Runtime PlansЃЌЖјдк Spark жаЃЌRDD дкдЫааЪББэЯжЮЊ Java
ObjectsЁЃдк Flink жага Logical Plan ЃЌетКЭ Spark жаЕФ DataFrames
РрЫЦЁЃвђЖјЃЌдк Flink жаЃЌШєЪЧЪЙгУетРр API ЃЌЛсБЛгХЯШРДгХЛЏЃЈМДЃКздЖЏгХЛЏЕќДњЃЉЁЃШчЯТЭМЫљЪОЃК
ШЛЖјЃЌдк Spark жаЃЌRDD ОЭУЛгаетПщЕФЯрЙигХЛЏЃЌШчЯТЭМЫљЪОЃК

СэЭтЃЌDataSet КЭ DataStream ЪЧЯрЖдЖРСЂЕФ APIЃЌдк
Spark жаЃЌЫљгаВЛЭЌЕФ APIЃЌБШШч StreamingЃЌDataFrame ЖМЪЧЛљгк RDD
ГщЯѓЕФЁЃШЛЖјдк Flink жаЃЌDataSet КЭ DataStream ЪЧЭЌвЛИіЙЋгУв§ЧцжЎЩЯЕФСНИіЖРСЂЕФГщЯѓЁЃЫљвдЃЌВЛФмАбетСНепЕФааЮЊКЯВЂдквЛЦ№ВйзїЃЌФПЧАЙйЗНе§дкДІРэетжжЮЪЬтЃЌЯъМћЃлFLINK-2320Ѓн
2.2.2 Memory
дкжЎЧАЕФАцБОЃЈ1.5вдЧАЃЉЃЌSpark бггУ Java ЕФФкДцЙмРэРДзіЪ§ОнЛКДцЃЌетбљКмШнвзЕМжТ
OOM Лђеп GCЁЃжЎКѓЃЌSpark ПЊЪМзЊЯђСэЭтИќМггбКУКЭОЋзМЕФПижЦФкДцЃЌМДЃКTungsten ЯюФПЁЃШЛЖјЃЌЖдгк
Flink РДЫЕЃЌДгвЛПЊЪМОЭМсГжЪЙгУздМКПижЦФкДцЁЃFlink Г§АбЪ§ОнДцдкздМКЙмРэЕФФкДцжЎЭтЃЌЛЙжБНгВйзїЖўНјжЦЪ§ОнЁЃдк
Spark 1.5жЎКѓЕФАцБОПЊЪМЃЌЫљгаЕФ DataFrame ВйзїЖМЪЧжБНгзїгУгк Tungsten
ЕФЖўНјжЦЪ§ОнЩЯЁЃ
PSЃКTungsten ЯюФПНЋЪЧ Spark здЕЎЩњвдРДФкКЫМЖБ№ЕФзюДѓИФЖЏЃЌвдДѓЗљЖШЬсЩ§
Spark гІгУГЬађЕФФкДцКЭ CPU РћгУТЪЮЊФПБъЃЌжМдкзюДѓГЬЖШЩЯРћгУгВМўадФмЁЃИУЯюФПАќРЈСЫШ§ИіЗНУцЕФИФНјЃК
ФкДцЙмРэКЭЖўНјжЦДІРэЃКИќМгУїШЗЕФЙмРэФкДцЃЌЯћГ§ JVM ЖдЯѓФЃаЭКЭРЌЛјЛиЪеПЊЯњЁЃ
ЛКДцгбКУМЦЫуЃКЪЙгУЫуЗЈКЭЪ§ОнНсЙЙРДЪЕЯжФкДцЗжМЖНсЙЙЁЃ
ДњТыЩњГЩЃКЪЙгУДњТыЩњГЩРДРћгУаТаЭБрвыЦїКЭ CPUЁЃ
2.2.3 Program
Spark ЪЙгУ Scala РДЪЕЯжЕФЃЌЫќЬсЙЉСЫ JavaЃЌPython
вдМА R гябдЕФБрГЬНгПкЁЃЖјЖдгк Flink РДЫЕЃЌЫќЪЧЪЙгУ Java ЪЕЯжЕФЃЌЬсЙЉ Scala БрГЬ
APIЁЃДгБрГЬгябдЕФНЧЖШРДПДЃЌSpark ТдЯдЗсИЛвЛаЉЁЃ
2.2.4 API
Spark КЭ Flink СНепЖМЧуЯђгкЪЙгУ Scala РДЪЕЯжЖдгІЕФвЕЮёЁЃЖдБШСНепЕФ
WordCount ЪОР§ЃЌКмРрЫЦЁЃШчЯТЫљЪОЃЌЗжБ№ЮЊ RDD КЭ DataSet API ЕФЪОР§ДњТыЃК
RDD
// Spark WordCount
object WordCount {
def main(args: Array[String]) {
val env = new SparkContext("local","WordCount")
val data = List("hi","spark cluster","hi","spark")
val dataSet = env.parallelize(data)
val words = dataSet.flatMap(value => value.split("\\s+"))
val mappedWords = words.map(value => (value,1))
val sum = mappedWords.reduceByKey(_+_)
println(sum.collect())
}
} |
DataSet
// Flink WordCount
object WordCount {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment
val data = List("hello","flink
cluster","hello")
val dataSet = env.fromCollection(data)
val words = dataSet.flatMap(value => value.split("\\s+"))
val mappedWords = words.map(value => (value,1))
val grouped = mappedWords.groupBy(0)
val sum = grouped.sum(1)
println(sum.collect())
}
} |
Ждгк StreamingЃЌSpark АбЫќПДГЩИќПьЕФХњДІРэЃЌЖј Flink
АбХњДІРэПДГЩ Streaming ЕФЬиЪтР§згЃЌВювьШчЯТЃКЦфвЛЃЌдкЪЕЪБМЦЫуЮЪЬтЩЯЃЌFlink ЬсЙЉСЫЛљгкУПИіЪТМўЕФСїЪНДІРэЛњжЦЃЌЫљвдЫќПЩвдБЛШЯЮЊЪЧвЛИіеце§втвхЩЯЕФСїЪНМЦЫуЃЌРрЫЦгк
Storm ЕФМЦЫуФЃаЭЁЃЖјЖдгк Spark РДЫЕЃЌВЛЪЧЛљгкЪТМўСЃЖШЕФЃЌЖјЪЧгУаЁХњСПРДФЃФтСїЪНЃЌвВОЭЪЧЖрИіЪТМўЕФМЏКЯЁЃЫљвдЃЌSpark
БЛШЯЮЊЪЧвЛИіНгНќЪЕЪБЕФДІРэЯЕЭГЁЃЫфШЛЃЌДѓВПЗжгІгУЪЕЪБЪЧПЩвдНгЪмЕФЃЌЕЋЖдгкКмЖргІгУашвЊЛљгкЪТМўМЖБ№ЕФСїЪНМЦЫуЁЃвђЖјЃЌЛсбЁдё
Storm ЖјВЛЪЧ Spark StreamingЃЌЯждкЃЌFlink вВаэЪЧвЛИіВЛДэЕФбЁдёЁЃ
2.2.5 SQL
ФПЧАЃЌSpark SQL ЪЧЦфзщМўжаНЯЮЊЛюдОЕФвЛВПЗжЃЌЫќЬсЙЉСЫРрЫЦгк
Hive SQL РДВщбЏНсЙЙЛЏЪ§ОнЃЌAPI вРШЛКмГЩЪьЁЃЖдгк Flink РДЫЕЃЌНижСЕНФПЧА 1.0
АцБОЃЌжЛжЇГж Flink Table APIЃЌЙйЗНдк Flink 1.1 АцБОжаЛсЬэМг SQL ЕФНгПкжЇГжЁЃЃлFlink
1.1 SQL ЯъЧщМЦЛЎЃн
3.Features
Flink АќКЌвЛЯТЬиадЃК
ИпЭЬЭТ & ЕЭбгЪБ
жЇГж Event Time & ТвађЪТМў
зДЬЌМЦЫуЕФ Exactly-Once гявх
ИпЖШСщЛюЕФСїЪНДАПк
ДјЗДбЙЕФСЌајСїФЃаЭ
ШнДэад
СїДІРэКЭХњДІРэЙВгУвЛИів§Чц
ФкДцЙмРэ
ЕќДњ & діСПЕќДњ
ГЬађЕїгХ
СїДІРэгІгУ
ХњДІРэгІгУ
РрПтЩњЬЌ
ЙуЗКМЏГЩ
3.1 ИпЭЬЭТ & ЕЭбгЪБ
Flink ЕФСїДІРэв§ЧцжЛашвЊКмЩйХфжУОЭФмЪЕЯжИпЭЬЭТТЪКЭЕЭбгГйЁЃЯТЭМеЙЪОСЫвЛИіЗжВМЪНМЦЪ§ЕФШЮЮёЕФадФмЃЌАќРЈСЫСїЪ§Он
shuffle Й§ГЬЁЃ

3.2 жЇГж Event Time & ТвађЪТМў
Flink жЇГжСЫСїДІРэКЭ Event Time гявхЕФДАПкЛњжЦЁЃEvent
time ЪЙЕУМЦЫуТвађЕНДяЕФЪТМўЛђПЩФмбгГйЕНДяЕФЪТМўИќМгМђЕЅЁЃШчЯТЭМЫљЪОЃК

3.3 зДЬЌМЦЫуЕФ exactly-once гявх
СїГЬађПЩвддкМЦЫуЙ§ГЬжаЮЌЛЄздЖЈвхзДЬЌЁЃFlink ЕФ checkpointing
ЛњжЦБЃжЄСЫМДЪБдкЙЪеЯЗЂЩњЯТвВФмБЃеЯзДЬЌЕФ exactly once гявхЁЃ
3.4 ИпЖШСщЛюЕФСїЪНДАПк
Flink жЇГждкЪБМфДАПкЃЌЭГМЦДАПкЃЌsession ДАПкЃЌвдМАЪ§ОнЧ§ЖЏЕФДАПкЃЌДАПкПЩвдЭЈЙ§СщЛюЕФДЅЗЂЬѕМўРДЖЈжЦЃЌвджЇГжИДдгЕФСїМЦЫуФЃЪНЁЃ
3.5 ДјЗДбЙЕФСЌајСїФЃаЭ
Ъ§ОнСїгІгУжДааЕФЪЧВЛМфЖЯЕФЃЈГЃзЄЃЉoperatorsЁЃFlink
streaming дкдЫааЪБгазХЬьШЛЕФСїПиЃКТ§ЕФЪ§Он sink НкЕуЛсЗДбЙЃЈbackpressureЃЉПьЕФЪ§ОндДЃЈsourcesЃЉЁЃ
3.6 ШнДэад
Flink ЕФШнДэЛњжЦЪЧЛљгк Chandy-Lamport distributed
snapshots РДЪЕЯжЕФЁЃетжжЛњжЦЪЧЗЧГЃЧсСПМЖЕФЃЌдЪаэЯЕЭГгЕгаИпЭЬЭТТЪЕФЭЌЪБЛЙФмЬсЙЉЧПвЛжТадЕФБЃеЯЁЃ
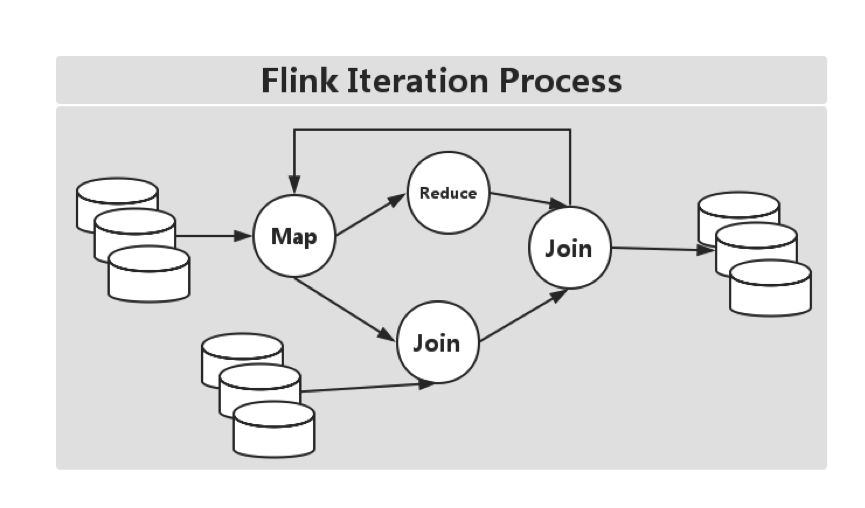
3.7 СїДІРэКЭХњДІРэЙВгУвЛИів§Чц
Flink ЮЊСїДІРэКЭХњДІРэгІгУЙЋгУвЛИіЭЈгУЕФв§ЧцЁЃХњДІРэгІгУПЩвдвдвЛжжЬиЪтЕФСїДІРэгІгУИпаЇЕидЫааЁЃШчЯТЭМЫљЪОЃК
3.8 ФкДцЙмРэ
Flink дк JVM жаЪЕЯжСЫздМКЕФФкДцЙмРэЁЃгІгУПЩвдГЌГіжїФкДцЕФДѓаЁЯожЦЃЌВЂЧвГаЪмИќЩйЕФРЌЛјЪеМЏЕФПЊЯњЁЃ
3.9 ЕќДњКЭдіСПЕќДњ
Flink ОпгаЕќДњМЦЫуЕФзЈУХжЇГжЃЈБШШчдкЛњЦїбЇЯАКЭЭММЦЫужаЃЉЁЃдіСПЕќДњПЩвдРћгУвРРЕМЦЫуРДИќПьЕиЪеСВЁЃШчЯТЭМЫљЪОЃК

3.10 ГЬађЕїгХ
ХњДІРэГЬађЛсздЖЏЕигХЛЏвЛаЉГЁОАЃЌБШШчБмУтвЛаЉАКЙѓЕФВйзїЃЈШч shuffles
КЭ sortsЃЉЃЌЛЙгаЛКДцвЛаЉжаМфЪ§ОнЁЃ
3.11 СїДІРэгІгУ
DataStream API жЇГжСЫЪ§ОнСїЩЯЕФКЏЪ§ЪНзЊЛЛЃЌПЩвдЪЙгУздЖЈвхЕФзДЬЌКЭСщЛюЕФДАПкЁЃЯТУцЪОР§еЙЪОСЫШчКЮвдЛЌЖЏДАПкЕФЗНЪНЭГМЦЮФБОЪ§ОнСїжаЕЅДЪГіЯжЕФДЮЪ§ЁЃ
case class Word(word:
String, freq: Long)
val texts: DataStream[String] = ...
val counts = text
.flatMap { line => line.split("\\W+")
}
.map { token => Word(token, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum("freq") |
3.12 ХњДІРэгІгУ
Flink ЕФ DataSet API ПЩвдЪЙФугУ Java Лђ
Scala аДГіЦЏССЕФЁЂРраЭАВШЋЕФЁЂПЩЮЌЛЄЕФДњТыЁЃЫќжЇГжЙуЗКЕФЪ§ОнРраЭЃЌВЛНіНіЪЧ key/value
ЖдЃЌвдМАЗсИЛЕФ operatorsЁЃЯТУцЪОР§еЙЪОСЫЭММЦЫужа PageRank ЫуЗЈЕФвЛИіКЫаФбЛЗЁЃ
case class Page(pageId:
Long, rank: Double)
case class Adjacency(id: Long, neighbors: Array[Long])
val result = initialRanks.iterate(30) { pages
=>
pages.join(adjacency).where("pageId").equalTo("pageId")
{
(page, adj, out : Collector[Page]) => {
out.collect(Page(page.id, 0.15 / numPages))
for (n <- adj.neighbors) {
out.collect(Page(n, 0.85*page.rank/adj.neighbors.length))
}
}
}
.groupBy("pageId").sum("rank")
} |
3.13 РрПтЩњЬЌ
Flink еЛжаЬсЙЉСЫКмЖрИпМЖ API КЭТњзуВЛЭЌГЁОАЕФРрПтЃКЛњЦїбЇЯАЁЂЭМЗжЮіЁЂЙиЯЕЪНЪ§ОнДІРэЁЃЕБЧАРрПтЛЙдк
beta зДЬЌЃЌВЂЧвдкДѓСІЗЂеЙЁЃ
3.14 ЙуЗКМЏГЩ
Flink гыПЊдДДѓЪ§ОнДІРэЩњЬЌЯЕЭГжаЕФаэЖрЯюФПЖМгаМЏГЩЁЃFlink
ПЩвддЫаадк YARN ЩЯЃЌгы HDFS аЭЌЙЄзїЃЌДг Kafka жаЖСШЁСїЪ§ОнЃЌПЩвджДаа Hadoop
ГЬађДњТыЃЌПЩвдСЌНгЖржжЪ§ОнДцДЂЯЕЭГЁЃШчЯТЭМЫљЪОЃК

4.змНс
вдЩЯЃЌБуЪЧЖд Flink зівЛИіМђвЊЕФЦЪЮіШЯЪЖЃЌжСгкШчКЮЪЙгУ FlinkЃЌвдМАЦфБрвыЃЌАВзАЃЌВПЪ№ЃЌдЫааЕШСїГЬЃЌНЯЮЊМђЕЅЃЌетРяОЭВЛЖрзізИЪіСЫЃЌДѓМвПЩвддк
Flink ЕФЙйЭјЃЌдФЖСЦф QuickStart МДПЩЃЌЃлЗУЮЪЕижЗЃнЁЃ
5.НсЪјгя
етЦЊВЉПЭОЭКЭДѓМвЗжЯэЕНетРяЃЌШчЙћДѓМвдкбаОПбЇЯАЕФЙ§ГЬЕБжагаЪВУДЮЪЬтЃЌПЩвдМгШКНјааЬжТлЛђЗЂЫЭгЪМўИјЮвЃЌЮвЛсОЁЮвЫљФмЮЊФњНтД№ЃЌгыО§ЙВУуЃЁ
|








