| 编辑推荐: |
| 来源作者maxluo,主要讲解了怎么部署环境,如何基于Azkaban的工作流,定时调度任务,最后总结经验,更多内容请看下文。 |
|
一、Azkaban介绍 Azkaban是LinkedIn开源的任务调度框架,类似于JavaEE中的JBPM和Activiti工作流框架。
Azkaban功能和特点:
1,任务的依赖处理。
2,任务监控,失败告警。
3,任务流的可视化。
4,任务权限管理。
常见的任务调度框架有Apache Oozie、LinkedIn Azkaban、Apache Airflow、Alibaba
Zeus,由于Azkaban具有轻量可插拔、友好的WebUI、SLA告警、完善的权限控制、易于二次开发等优点,也得到了广泛应用。下图为Azkaban的架构图,主要有三部分组成:Azkaban
Webserver、Azkaban Executor、 DB。
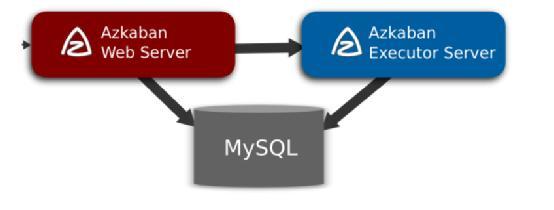
Webserver主要负责权限验证、项目管理、作业流下发等工作;
Executor主要负责作业流/作业的具体执行以及搜集执行日志等工作;
MySQL用于存储作业/作业流的执行状态信息。图中所示的是单executor场景,但是实际应用中大部分的项目使用的都是多executor场景。
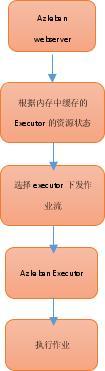
1.1 作业流执行过程
Azkaban webserver会根据搜集起来的Executor的状态选择一个合适的任务运行节点,并将任务推送给该节点,管理并运行该工作流的所有job。
1.2 部署模式 Azkaban支持三种部署模式,分别用于学习和测试,高可用部署方式。
solo-server模式 DB使用的是一个内嵌的H2,Web Server和Executor Server运行在同一个进程里。这种模式包含Azkaban的所有特性,但一般用来学习和测试。
two-server模式 DB使用的是MySQL,MySQL支持master-slave架构,Web Server和Executor
Server运行在不同的进程中。
分布式multiple-executor模式 DB使用的是MySQL,MySQL支持master-slave架构,Web Server和Executor
Server运行在不同机器上,且有多个Executor Server。
1.3 编译部署
编译环境
yum install git
yum install gcc-c++
yum install java-1.8.0-openjdk-devel |
下载源码&解压
mkdir –p /data/azkaban/install
cd /data/azkaban
wget https://github.com/azkaban/azkaban/archive/3.42.0.tar.gz
mv 3.42.0.tar.gz azkaban-3.42.0.tar.gz
tar -zxvf azkaban-3.42.0.tar.gz |
编译
cd azkaban-3.42.0
./gradlew build installDist -x test |
solo-server模式部署
下面为了部署测试简单,采用solo-server模式进行部署。
| cd /data/azkaban/install
tar -zxvf ../azkaban-3.42.0/azkaban-solo-server/build/distributions/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz
-C .
|
修改时区
cd /data/azkaban/install/azkaban-solo-server-0.1.0-SNAPSHOT
tzselect #选择Asia/Shanghai
vim ./conf/azkaban.properties
default.timezone.id=Asia/Shanghai #修改时区
|
启动
| ./bin/azkaban-solo-start.sh |
注:启动/关闭必须进到/data/azkaban/install/azkaban-solo-server-0.1.0-SNAPSHOT/目录。
登录 http://ip:port/
监听端口具体见配置./conf/azkaban.properties:jetty.port=8081
IP为服务器地址。
用户名见配置./conf/azkaban-users.xml, 具有admin角色的用户名是azkaban,密码是azkaban:
详细配置方法内容见:https://azkaban.github.io/azkaban/docs/latest/
#azkaban-plugin-configuration
二、Azkaban与数仓集群的网络互通 目前Azkaban与云产品Snova网络互通基于两个事实:1,Azkaban Executor的服务器能够访问外网或者能够访问Snova的服务端IP。2,Snova提供外网IP访问的能力。下图为网络连通示意图:

Azkaban Executor在执行运行job时,其脚本或者命令通过公网IP访问Snova。
接下来分步骤讲解如何基于Azkaban的工作流。
三、前期准备工作 3.1 Snova集群创建外网IP 在Snova集群控制台,基础配置页面,点击“申请外网地址”,等待运行成功后,会看到访问该集群的外网IP地址。
3.2 添加Snova访问地址白名单 在Snova控制台,集群详情页,配置页,新建白名单如下所示。
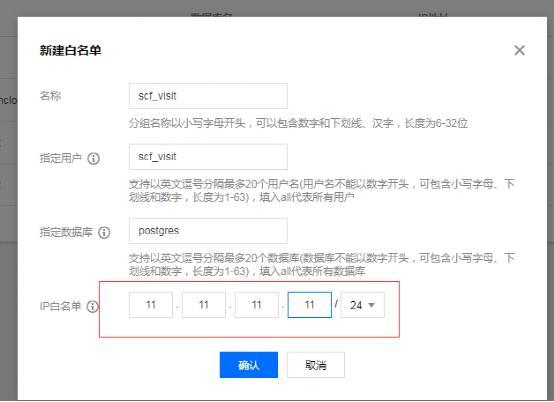
为什么要建这个访问白名单?
为了系统安全,Snova默认情况是拒绝不在白名单的地址或者用户访问数据库。
即配置IP白名单CIDR地址为xx.xx.xx.xx/xx,包括所有Azkaban Executor的所有IP或者网段。
3.3 用户授权 在3.2章节中,建议单独创建一个用户用于SCF的任务调度和计算。因此需要授权该用户访问对应数据库和表的权限。
创建用户
| CREATE USER scf_visit
WITH LOGIN PASSWORD 'scf_passwd'; |
并设置用户访问密码。
数据库表授权
| GRANT ALL on
t1 to scf_visit; |
四、定时调度任务 http://node1:8081/index
登录Azkaban,Create Project=>Upload
上一步生成的zip包 =>execute flow执行一步步操作即可。
4.1 创建工程 
4.2 创建job job1
文件名:job.job,必须以.job结尾。内容如下:
type=command
command=echo "job1"
retries=5 |
注:type类型及使用方式见https://azkaban.github.io/azkaban/docs/latest/#job-types
job2
type=command
dependencies=job1
retries=5
command=echo "job2 xx"
command.1=ls –al |
注:dependencies为该job依赖的任务文件名(不包括.job后缀)。如果依赖多个,则以逗号分隔,如job2,job5。
job3
type=command
dependencies=job2,job5
command=sleep 60 |
job5
type=command
dependencies=job2,job5
command=sleep 60 |
job6
type=command
dependencies=job3
command=sh /data/shell/admin.sh psqlx |
其中/data/shell/admin.sh ,注意作用可以封装用户功能代码,脚本内容如下,实现读取表中的数据,并进行打印:
| function psqlx()
{ result=PGPASSWORD=scf_passwd psql -h xx.xx.xx.xx
-p xx -U scf_visit -d postgres <<EOF select
* from t1; EOF echo $result } |
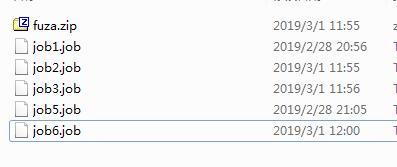
4.3上传job压缩包 压缩所有job文件到一个zip包中。注意:所有文件必须在压缩包的根目录中,没有子目录,如下:

4.4运行

查询执行过程和结果。

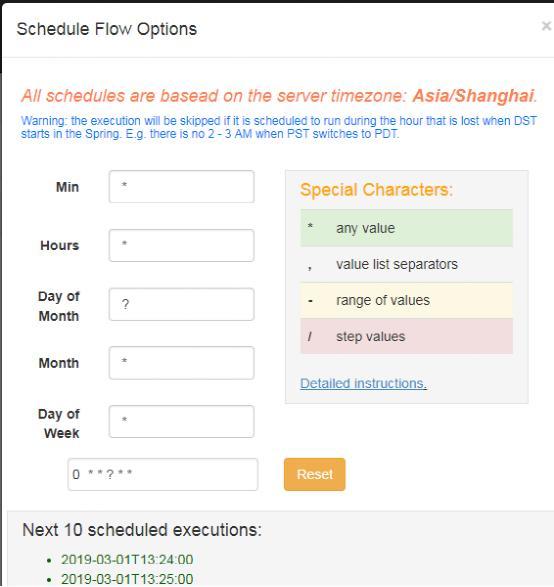
4.5设置周期调度
在调试成功完成后,可以设置周期调度计划,比如每天定时进行工作流的调度,完成运行计划。
五、实践总结 对市面上最流行的两种调度器,给出以下详细对比。知名度比较高的应该是Apache Oozie。
5.1 对比 从功能上来对比
两者均可以调度linux命令、mapreduce、spark、pig、java、hive、java程序、脚本工作流任务
两者均可以定时执行工作流任务
从工作流定义上来对比
1、Azkaban使用Properties文件定义工作流
2、Oozie使用XML文件定义工作流
从工作流传参上来对比
1、Azkaban支持直接传参,例如${input}
2、Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
从定时执行上来对比
1、Azkaban的定时执行任务是基于时间的
2、Oozie的定时执行任务基于时间和输入数据
从资源管理上来对比
1、Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
2、Oozie暂无严格的权限控制
5.2 应用场景 对于数据分析基本上可以概括为三个步骤: 一、数据导入。二、数据计算。三、数据导出。
三个类型的任务可能是多个并发运行,且任务依赖。因此Azkaban基本上能满足以上的任务调度管理和运行场景需求。
首先创建一个job1,用于用户数据导入,比如从cos导入,任务内容执行以下SQL命令。
insert into gp_table select * from cos_table;
数据的导入也可以通过其他导入工具,如DataX将其他数据库的数据周期性的导入Snova数据仓库中。因此只需把DataX部署到Azkaban
Executor机器对应目录,并进行调用即可
其次,创建job2,用户数据计算分析。该步骤可以是多个job多次运行的结果,也可以是并发运行。
最后,可以把计算结果出库到应用数据库。
insert into cos_table select * from gp_table;
5.2 不足 1,Azkaban目前Job粒度的失败重试理解相对复杂,在Projects->Executions找到对应的执行失败的Id,选择该执行实例ID,进入详情,点击重新运行,则会生成一个全新的工作流实例ID,而不是重新运行原来失败的实例ID,新的实例ID从失败的job开始运行,已经成功运行的直接跳过,不再运行。
2,job通过shell命令启动复杂的程序,shell返回成功,并不代表程序运行成功。
3,job运行管理容错性不足,当一个job提交一个运行任务后,此时重启或者executor进程挂掉,该任务将出现状态失败的情况,实际可能任务已经运行成功。
|








