| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФНщЩмСЫSparkЕФЪЪгУГЁОАЃЌSparkЕФМмЙЙЩшМЦЁЂдЫааЬиЕувдМАSparkШЮЮёЕїЖШФЃПщDAGSchedulerЁЂTaskSchedulerЕШЯрЙиФкШнЁЃ |
|
Apache SparkЪЧвЛИіЮЇШЦЫйЖШЁЂвзгУадКЭИДдгЗжЮіЙЙНЈЕФДѓЪ§ОнДІРэПђМмЃЌзюГѕдк2009ФъгЩМгжнДѓбЇВЎПЫРћЗжаЃЕФAMPLabПЊЗЂЃЌВЂгк2010ФъГЩЮЊApacheЕФПЊдДЯюФПжЎвЛЃЌгыHadoopКЭStormЕШЦфЫћДѓЪ§ОнКЭMapReduceММЪѕЯрБШЃЌSparkгаШчЯТгХЪЦЃК
1.дЫааЫйЖШПь,SparkгЕгаDAGжДаав§ЧцЃЌжЇГждкФкДцжаЖдЪ§ОнНјааЕќДњМЦЫуЁЃЙйЗНЬсЙЉЕФЪ§ОнБэУїЃЌШчЙћЪ§ОнгЩДХХЬЖСШЁЃЌЫйЖШЪЧHadoop
MapReduceЕФ10БЖвдЩЯЃЌШчЙћЪ§ОнДгФкДцжаЖСШЁЃЌЫйЖШПЩвдИпДя100ЖрБЖЁЃ
2.ЪЪгУГЁОАЙуЗК,ДѓЪ§ОнЗжЮіЭГМЦЃЌЪЕЪБЪ§ОнДІРэЃЌЭММЦЫуМАЛњЦїбЇЯА
3.взгУад,БраДМђЕЅЃЌжЇГж80жжвдЩЯЕФИпМЖЫузгЃЌжЇГжЖржжгябдЃЌЪ§ОндДЗсИЛЃЌПЩВПЪ№дкЖржжМЏШКжа
4.ШнДэадИпЁЃSparkв§НјСЫЕЏадЗжВМЪНЪ§ОнМЏRDD (Resilient Distributed
Dataset) ЕФГщЯѓЃЌЫќЪЧЗжВМдквЛзщНкЕужаЕФжЛЖСЖдЯѓМЏКЯЃЌетаЉМЏКЯЪЧЕЏадЕФЃЌШчЙћЪ§ОнМЏвЛВПЗжЖЊЪЇЃЌдђПЩвдИљОнЁАбЊЭГЁБЃЈМДГфаэЛљгкЪ§ОнбмЩњЙ§ГЬЃЉЖдЫќУЧНјаажиНЈЁЃСэЭтдкRDDМЦЫуЪБПЩвдЭЈЙ§CheckPointРДЪЕЯжШнДэЃЌЖјCheckPointгаСНжжЗНЪНЃКCheckPoint
DataЃЌКЭLogging The UpdatesЃЌгУЛЇПЩвдПижЦВЩгУФФжжЗНЪНРДЪЕЯжШнДэЁЃ
SparkЕФЪЪгУГЁОА
ФПЧАДѓЪ§ОнДІРэГЁОАгавдЯТМИИіРраЭЃК
1.ИДдгЕФХњСПДІРэЃЈBatch Data ProcessingЃЉЃЌЦЋжиЕудкгкДІРэКЃСПЪ§ОнЕФФмСІЃЌжСгкДІРэЫйЖШПЩШЬЪмЃЌЭЈГЃЕФЪБМфПЩФмЪЧдкЪ§ЪЎЗжжгЕНЪ§аЁЪБЃЛ
2.ЛљгкРњЪЗЪ§ОнЕФНЛЛЅЪНВщбЏЃЈInteractive QueryЃЉЃЌЭЈГЃЕФЪБМфдкЪ§ЪЎУыЕНЪ§ЪЎЗжжгжЎМф
3.ЛљгкЪЕЪБЪ§ОнСїЕФЪ§ОнДІРэЃЈStreaming Data ProcessingЃЉЃЌЭЈГЃдкЪ§АйКСУыЕНЪ§УыжЎМф
МмЙЙМАЩњЬЌ
ЭЈГЃЕБашвЊДІРэЕФЪ§ОнСПГЌЙ§СЫЕЅЛњГпЖШ(БШШчЮвУЧЕФМЦЫуЛњга4GBЕФФкДцЃЌЖјЮвУЧашвЊДІРэ100GBвдЩЯЕФЪ§Он)етЪБЮвУЧПЩвдбЁдёsparkМЏШКНјааМЦЫуЃЌгаЪБЮвУЧПЩФмашвЊДІРэЕФЪ§ОнСПВЂВЛДѓЃЌЕЋЪЧМЦЫуКмИДдгЃЌашвЊДѓСПЕФЪБМфЃЌетЪБЮвУЧвВПЩвдбЁдёРћгУsparkМЏШКЧПДѓЕФМЦЫузЪдДЃЌВЂааЛЏЕиМЦЫуЃЌЦфМмЙЙЪОвтЭМШчЯТЃК
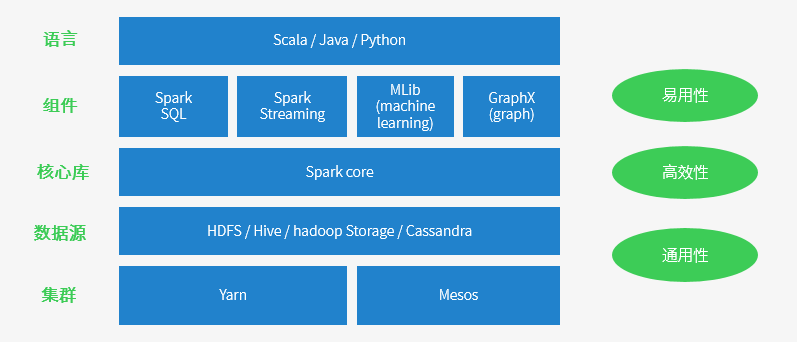
Spark CoreЃКАќКЌSparkЕФЛљБОЙІФмЃЛгШЦфЪЧЖЈвхRDDЕФAPIЁЂВйзївдМАетСНепЩЯЕФЖЏзїЁЃЦфЫћSparkЕФПтЖМЪЧЙЙНЈдкRDDКЭSpark
CoreжЎЩЯЕФЁЃ
Spark SQLЃКЬсЙЉЭЈЙ§Apache HiveЕФSQLБфЬхHiveВщбЏгябдЃЈHiveQLЃЉгыSparkНјааНЛЛЅЕФAPIЁЃУПИіЪ§ОнПтБэБЛЕБзівЛИіRDDЃЌSpark
SQLВщбЏБЛзЊЛЛЮЊSparkВйзїЁЃSparkЬсЙЉЕФsqlаЮЪНЕФЖдНгHiveЁЂJDBCЁЂHBaseЕШИїжжЪ§ОнЧўЕРЕФAPIЃЌгУJavaПЊЗЂШЫдБЕФЫМЯыРДНВОЭЪЧУцЯђНгПкЁЂНтёюКЯЃЌORMappingЁЂSpring
Cloud StreamЕШЖМЪЧРрЫЦЕФЫМЯыЁЃ
Spark StreamingЃКЛљгкSparkCoreЪЕЯжЕФПЩРЉеЙЁЂИпЭЬЭТЁЂИпПЩППадЕФЪЕЪБЪ§ОнСїДІРэЁЃжЇГжДгKafkaЁЂFlumeЕШЪ§ОндДДІРэКѓДцДЂЕНHDFSЁЂDataBaseЁЂDashboardжаЁЃЖдЪЕЪБЪ§ОнСїНјааДІРэКЭПижЦЁЃSpark
StreamingдЪаэГЬађФмЙЛЯёЦеЭЈRDDвЛбљДІРэЪЕЪБЪ§ОнЁЃ
MLlibЃКвЛИіГЃгУЛњЦїбЇЯАЫуЗЈПтЃЌЫуЗЈБЛЪЕЯжЮЊЖдRDDЕФSparkВйзїЁЃетИіПтАќКЌПЩРЉеЙЕФбЇЯАЫуЗЈЃЌБШШчЗжРрЁЂЛиЙщЕШашвЊЖдДѓСПЪ§ОнМЏНјааЕќДњЕФВйзїЁЃ
GraphXЃКПижЦЭМЁЂВЂааЭМВйзїКЭМЦЫуЕФвЛзщЫуЗЈКЭЙЄОпЕФМЏКЯЁЃGraphXРЉеЙСЫRDD APIЃЌАќКЌПижЦЭМЁЂДДНЈзгЭМЁЂЗУЮЪТЗОЖЩЯЫљгаЖЅЕуЕФВйзї
SparkЕФМмЙЙЩшМЦ
HadoopДцдкШБЯнЃК
ЛљгкДХХЬЃЌЮоТлЪЧMapReduceЛЙЪЧYARNЖМЪЧНЋЪ§ОнДгДХХЬжаМгдиГіРДЃЌОЙ§DAGЃЌШЛКѓжиаТаДЛиЕНДХХЬжаЃЌМЦЫуЙ§ГЬЕФжаМфЪ§ОнгжашвЊаДШыЕНHDFSЕФСйЪБЮФМўЃЌетаЉЖМЪЙЕУHadoopдкДѓЪ§ОндЫЫуЩЯБэЯжЬЋЁАТ§ЁБЃЌSparkгІдЫЖјЩњЁЃ
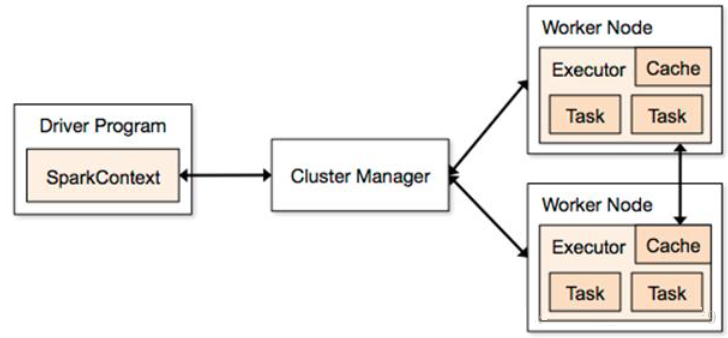
Cluster ManagerдкstandaloneФЃЪНжаМДЮЊMasterжїНкЕуЃЌПижЦећИіМЏШКЃЌМрПиworkerЁЃдкYARNФЃЪНжаЮЊзЪдДЙмРэЦїИКд№ЗжХфзЪдДЃЌгаЕуЯёYARNжаResourceManagerФЧИіНЧЩЋЃЌДѓЙмМвЮегаЫљгаЕФИЩЛюЕФзЪдДЃЌЪєгкввЗНЕФзмАќЁЃ
WorkerNodeЪЧПЩвдИЩЛюЕФНкЕуЃЌЬ§ДѓЙмМвClusterManagerВюЧВЃЌЪЧеце§газЪдДИЩЛюЕФжїЁЃДгНкЕуЃЌИКд№ПижЦМЦЫуНкЕуЃЌЦєЖЏExecutorЛђепDriverЁЃ
ExecutorЪЧдкWorkerNodeЩЯЦ№ЕФвЛИіНјГЬЃЌЯрЕБгквЛИіАќЙЄЭЗЃЌИКд№зМБИTaskЛЗОГКЭжДаа
TaskЃЌИКд№ФкДцКЭДХХЬЕФЪЙгУЁЃTaskЪЧЪЉЙЄЯюФПРяЕФУПвЛИіОпЬхЕФШЮЮёЁЃ
DriverЪЧЭГЙмTaskЕФВњЩњгыЗЂЫЭИјExecutorЕФЃЌдЫааApplication ЕФmain()КЏЪ§ЃЌЪЧМзЗНЕФЫОСюдБЁЃ
SparkContextЪЧгыClusterManagerДђНЛЕРЕФЃЌИКд№ИјЧЎЩъЧызЪдДЕФЃЌЪЧМзЗНЕФНгПкШЫЁЃ
ећИіЛЅЖЏСїГЬЪЧетбљЕФЃК
1 МзЗНРДСЫИіЯюФПЃЌДДНЈСЫSparkContextЃЌSparkContextШЅевClusterManagerЩъЧызЪдДЭЌЪБИјГіБЈМлЃЌашвЊЖрЩйCPUКЭФкДцЕШзЪдДЁЃClusterManagerШЅевWorkerNodeВЂЦєЖЏExcutorЃЌВЂНщЩмExcutorИјDriverШЯЪЖЁЃ
2 DriverИљОнЪЉЙЄЭМВ№ЗжвЛХњХњЕФTaskЃЌНЋTaskЫЭИјExecutorШЅжДааЁЃ
3 ExecutorНгЪеЕНTaskКѓзМБИTaskдЫааЪБвРРЕВЂжДааЃЌВЂНЋжДааНсЙћЗЕЛиИјDriver
4 DriverЛсИљОнЗЕЛиЛиРДЕФTaskзДЬЌВЛЖЯЕФжИЛгЯТвЛВНЙЄзїЃЌжБЕНЫљгаTaskжДааНсЪјЁЃ
дЫааСїГЬМАЬиЕу
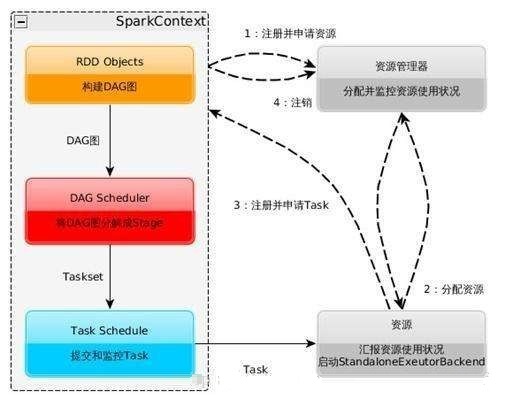
1.ЙЙНЈSpark ApplicationЕФдЫааЛЗОГЃЌЦєЖЏSparkContext
2.SparkContextЯђзЪдДЙмРэЦїЃЈПЩвдЪЧStandaloneЃЌMesosЃЌYarnЃЉЩъЧыдЫааExecutorзЪдДЃЌВЂЦєЖЏStandaloneExecutorbackendЃЌ
3.ExecutorЯђSparkContextЩъЧыTask
4.SparkContextНЋгІгУГЬађЗжЗЂИјExecutor
5.SparkContextЙЙНЈГЩDAGЭМЃЌНЋDAGЭМЗжНтГЩStageЁЂНЋTasksetЗЂЫЭИјTask
SchedulerЃЌзюКѓгЩTask SchedulerНЋTaskЗЂЫЭИјExecutorдЫаа
6.TaskдкExecutorЩЯдЫааЃЌдЫааЭъЪЭЗХЫљгазЪдД
SparkдЫааЬиЕуЃК
1.УПИіApplicationЛёШЁзЈЪєЕФexecutorНјГЬЃЌИУНјГЬдкApplicationЦкМфвЛжБзЄСєЃЌВЂвдЖрЯпГЬЗНЪНдЫааTaskЁЃетжжApplicationИєРыЛњжЦЪЧгагХЪЦЕФЃЌЮоТлЪЧДгЕїЖШНЧЖШПДЃЈУПИіDriverЕїЖШЫћздМКЕФШЮЮёЃЉЃЌЛЙЪЧДгдЫааНЧЖШПДЃЈРДздВЛЭЌApplicationЕФTaskдЫаадкВЛЭЌJVMжаЃЉЃЌЕБШЛетбљвтЮЖзХSpark
ApplicationВЛФмПчгІгУГЬађЙВЯэЪ§ОнЃЌГ§ЗЧНЋЪ§ОнаДШыЭтВПДцДЂЯЕЭГ
2.SparkгызЪдДЙмРэЦїЮоЙиЃЌжЛвЊФмЙЛЛёШЁexecutorНјГЬЃЌВЂФмБЃГжЯрЛЅЭЈаХОЭПЩвдСЫ
ЬсНЛSparkContextЕФClientгІИУППНќWorkerНкЕуЃЈдЫааExecutorЕФНкЕуЃЉЃЌзюКУЪЧдкЭЌвЛИіRackРяЃЌвђЮЊSpark
ApplicationдЫааЙ§ГЬжаSparkContextКЭExecutorжЎМфгаДѓСПЕФаХЯЂНЛЛЛ
TaskВЩгУСЫЪ§ОнБОЕиадКЭЭЦВтжДааЕФгХЛЏЛњжЦ
SparkШЮЮёЕїЖШФЃПщDAGSchedulerЁЂTaskSchedulerЃК
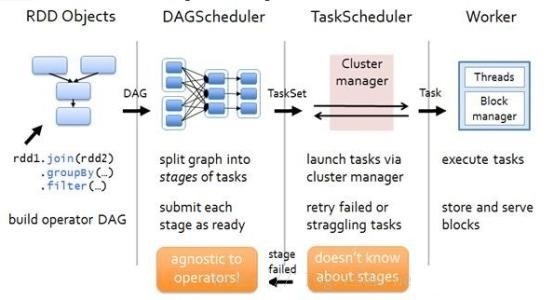
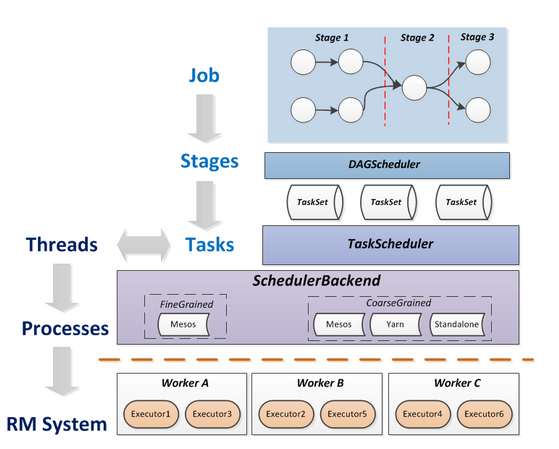
гУЛЇБрХХЕФДњТыгЩвЛИіИіЕФRDD ObjectsзщГЩЃЌDAGSchedulerИКд№ИљОнRDDЕФПэвРРЕВ№ЗжDAGЮЊвЛИіИіЕФStageЃЌТђИіStageАќКЌвЛзщТпМЭъШЋЯрЭЌЕФПЩвдВЂЗЂжДааЕФTaskЁЃTaskSchedulerИКд№НЋTaskЭЦЫЭИјДгClusterManagerФЧРяЛёШЁЕНЕФWorkerЦєЖЏЕФExecutorЁЃ
DAGSchedulerЃЈЭГвЛЛЏЕФЃЌSparkЫЕСЫЫуЃЉЃК
ЯъЯИЕФАИР§ЗжЮіЯТШчКЮНјааStageЛЎЗжЃЌЧыПДЯТЭМ
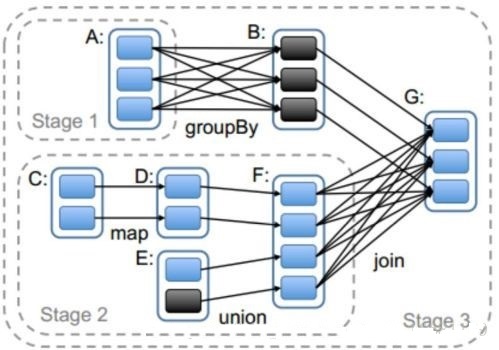
1 stageЪЧДЅЗЂactionЕФЪБКђДгКѓЭљЧАЛЎЗжЕФЃЌЫљвдБОЭМвЊДгRDD_GПЊЪМЛЎЗжЁЃ
2 RDD_GвРРЕгкRDD_BКЭRDD_FЃЌЫцЛњОіЖЈЯШХаЖЯФФвЛИівРРЕЃЌЕЋЪЧЖдгкНсЙћЮогАЯьЁЃ
3 RDD_BгыRDD_GЪєгкевРРЕЃЌЫљвдЫћУЧЪєгкЭЌвЛИіstageЃЌRDD_BгыРЯЕљRDD_AжЎМфЪЧПэвРРЕЕФЙиЯЕЃЌЫљвдЫћУЧВЛФмЛЎЗждквЛЦ№ЃЌЫљвдRDD_AздМКЪЧвЛИіstage1
4 RDD_FгыRDD_GЪЧЪєгкПэвРРЕЃЌЫћУЧВЛФмЛЎЗждквЛЦ№ЃЌЫљвдзюКѓвЛИіstageЕФЗЖЮЇвВОЭЯоЖЈСЫЃЌRDD_BКЭRDD_GзщГЩСЫStage3
5 RDD_FгыСНИіЕљRDD_DЁЂRDD_EжЎМфЪЧевРРЕЙиЯЕЃЌRDD_DгыЕљRDD_CжЎМфвВЪЧевРРЕЙиЯЕЃЌЫљвдЫћУЧЖМЪєгкЭЌвЛИіstage2
6 жДааЙ§ГЬжаstage1КЭstage2ЯрЛЅжЎМфУЛгаЧАКѓЙиЯЕЫљвдПЩвдВЂаажДааЃЌЯргІЕФУПИіstageФкВПИїИіpartitionЖдгІЕФtaskвВВЂаажДаа
7 stage3вРРЕstage1КЭstage2жДааНсЙћЕФpartitionЃЌжЛгаЕШЧАСНИіstageжДааНсЪјКѓВХПЩвдЦєЖЏstage3.
8 ЮвУЧЧАУцгаНщЩмЙ§SparkЕФTaskгаСНжжЃКShuffleMapTaskКЭResultTaskЃЌЦфжаКѓепдкDAGзюКѓвЛИіНзЖЮЭЦЫЭИјExecutorЃЌЦфгрЫљгаНзЖЮЭЦЫЭЕФЖМЪЧShuffleMapTaskЁЃдкетИіАИР§жаstage1КЭstage2жаВњЩњЕФЖМЪЧShuffleMapTaskЃЌдкstage3жаВњЩњЕФResultTaskЁЃ
9 ЫфШЛstageЕФЛЎЗжЪЧДгКѓЭљЧАМЦЫуЛЎЗжЕФЃЌЕЋЪЧвРРЕТпМХаЖЯЕШНсЪјКѓеце§ДДНЈstageЪЧДгЧАЭљКѓЕФЁЃвВОЭЪЧЫЕШчЙћДгstageЕФIDзїЮЊБъЪЖЕФЛАЃЌЯШашвЊжДааЕФstageЕФIDвЊаЁгкКѓашвЊжДааЕФIDЁЃОЭБОАИР§РДЫЕЃЌstage1КЭstage2ЕФIDвЊаЁгкstage3ЃЌжСгкstage1КЭstage2ЕФIDЫДѓЫаЁЪЧЫцЛњЕФЃЌЪЧгЩЧАУцЕк2ВНОіЖЈЕФЁЃ
ЫфШЛРэТлЩЯTaskгІИУНЛИјworkerNodeЩЯЕФexecutorРДжДааЕФЃЌЕЋЪЧгавЛжжЧщПіЯТЪЧЪЧдкDAGЛЎЗжНсЪјКѓжБНгдкБОЕижДааЕФЁЃ
1 Spark.localExecution.enabledЩшжУЮЊtrueЃЛ
2 гУЛЇЯдЪОжИЖЈдЪаэБОЕижДааЃЛ
3 ећИіDAGжЛгавЛИіstageЃЛ
4 НігавЛИіPartitionЁЃ
ЭЌЪБТњзуЩЯУц4ИіЬѕМўЯТЃЌПЩвджБНгдкSparkContextЃЈDriverЃЉНкЕуЩЯБОЕижДааЁЃ
TaskSchedulerЃЈНгПкЛЏЕФЃЌИљОнВЛЭЌЕФВПЪ№ЗНЪНStandaloneЁЂMesosЁЂYARNЁЂLocalЃЉЃК
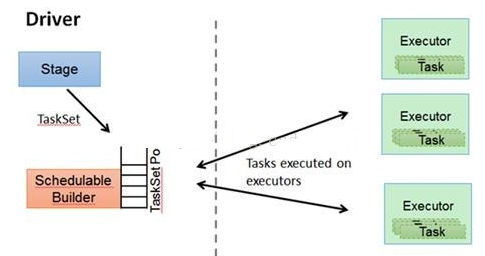
УПИіTaskSchedulerЖдгІзХвЛИіАяЪжSchedulerBackendЃЌSchedulerBackendИКд№гыClusterManagerНЛЛЅЛёЕУзЪдДЃЌШЛКѓНЋетаЉзЪдДаХЯЂДЋИјTaskSchedulerЃЌTaskSchedulerИКд№МрЖНTaskЕФжДаазДЬЌВЂНјааЯргІЕФЕїЖШЁЃетРяжївЊзіЕФЙЄзїгаЃКОЭНќддђЁЂЪЇАмжиЪдЁЂТ§ШЮЮёЭЦВтаджДаа
ШЮЮёЕїЖШЕФЪБКђФЌШЯЪЧFIFOЃЈЯШЕНЯШЕУЃЉЕФЃЌгЩjobIDКЭstageIDЕФДѓаЁРДОіЖЈЃЛвВПЩвдХфжУГЩFAIRЃЈЙЋЦНЃЉЕФЃЌжиаТШЗЖЈЕїЖШЫГађЭЦЫЭtaskИјExecutorЁЃ
ExecutorжДааЭъTaskКѓЛсЭЈЙ§ЯђDriverЗЂЫЭStatusUpdateЕФЯћЯЂРДЭЈжЊDriverШЮЮёИќаТTaskЕФзДЬЌЁЃDriverЛсНЋTaskзДЬЌЭЈжЊзЊИцИјTaskScheduleЃЌКѓепЛсжиаТЗжХфМЦЫуШЮЮёЁЃ
МйШчTaskгажДааЪЇАмЕФЃЌИљОнЪЇАмдвђКЭуажЕНјааИУTaskЕФжиЪдЛђепЗХЦњЁЃ
МйШчЫљгаTaskжДааГЩЙІЃЌШчЙћTaskЪЧResultTaskЃЌФЧУДШЮЮёНсЪјЃЛШчЙћЪЧShuffleMapTaskФЧУДЦєЖЏЯТвЛИіstageЁЃ
SparkдЫааФЃЪНЃК
LocalФЃЪНЃК
БШНЯМђЕЅЃЌжЛЪЪгУгкздМКЭцКЭВтЪдЃЌМзЗНSparkContextввЗНExecutorЕШЖМВПЪ№дквЛЦ№ЃЌЮяРэЮЛжУЩЯНЧЩЋЖЈЮЛВЛУїШЗЁЃ
MesosФЃЪНЃК
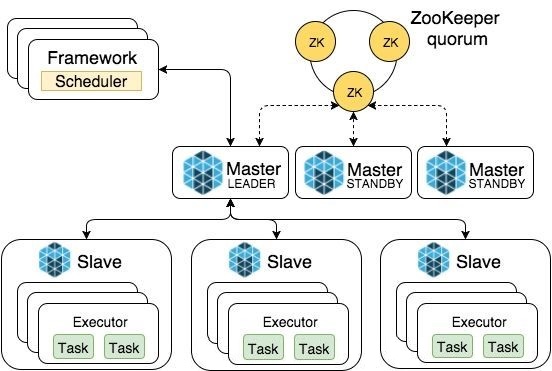
WorkerВПЗжВЩгУMaster/SlaverФЃЪНЃЌMasterЪЧећИіЯЕЭГЕФКЫаФВПМўЫљвдгУZooKeeperзіИпПЩгУадМгЙЬЃЌSlaverеце§ДДНЈExecutorжДааTaskВЂНЋздМКЕФЮяРэМЦЫузЪдДЛуБЈИјMasterЃЌMasterИКд№НЋslaversЕФзЪдДАДееВпТдЗжХфИјFrameworkЁЃ
MesosзЪдДЕїЖШЗжЮЊДжСЃЖШКЭЯИСЃЖШСНжжЗНЪНЃК
ДжСЃЖШЗНЪНЪЧЦєЖЏЪБжБНгЯђMasterЩъЧыжДааШЋВПTaskЕФзЪдДЃЌВЂЕШЫљгаМЦЫуШЮЮёНсЪјКѓВХЪЭЗХзЪдДЃЛЯИСЃЖШЗНЪНЪЧИљОнTaskашвЊЕФзЪдДВЛЭЃЕФЩъЧыКЭЙщЛЙЁЃСНИіЗНЪНИїгаРћБзЃЌДжСЃЖШЕФгХЕуЪЧЕїЖШГЩБОаЁЃЌЕЋЪЧЛсвђФОЭАаЇгІдьГЩзЪдДГЄЦкБЛАдеМЃЛЯИСЃЖШУЛгаФОЭАаЇгІЃЌЕЋЪЧЕїЖШЩЯЕФЙмРэГЩБОНЯИпЁЃ
YARNФЃЪНЃК
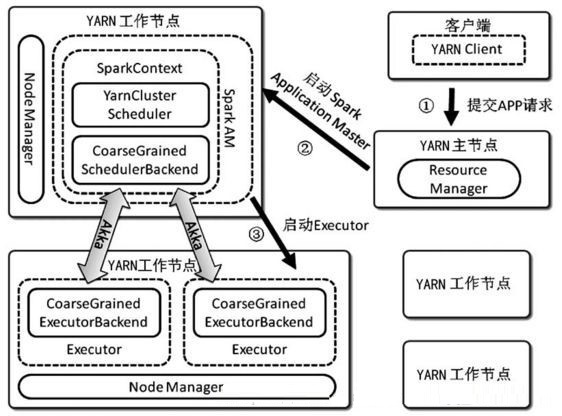
YRANФЃЪНЯТЗжЮЊClusterКЭClientСНжжФЃЪНЃЌЩЯЭМжаЕФЮЊClusterФЃЪНЁЃ
ClusterФЃЪНЯТОЭЪЧНЋSparkзїЮЊвЛИіЦеЭЈЕФYARNШЮЮёЃЌClientЖЫЭЈЙ§ResourceManagerЩъЧыЕНзЪдДЃЌДДНЈApplicationMasterЁЂTaskЕНContainerжаШЅЁЃApplicationMasterИКд№МрЖНTaskЕФжДааЧщПіЁЃ
Yarn-ClientФЃЪНжаЃЌDriverдкПЭЛЇЖЫБОЕидЫааЃЌетжжФЃЪНПЩвдЪЙЕУSpark ApplicationКЭПЭЛЇЖЫНјааНЛЛЅЃЌвђЮЊDriverдкПЭЛЇЖЫЃЌЫљвдПЩвдЭЈЙ§webUIЗУЮЪDriverЕФзДЬЌЃЌФЌШЯЪЧhttp://hadoop1:4040ЗУЮЪЃЌЖјYARNЭЈЙ§http://
hadoop1:8088ЗУЮЪ
YARN-clientЕФЙЄзїСїГЬВНжшЮЊЃК
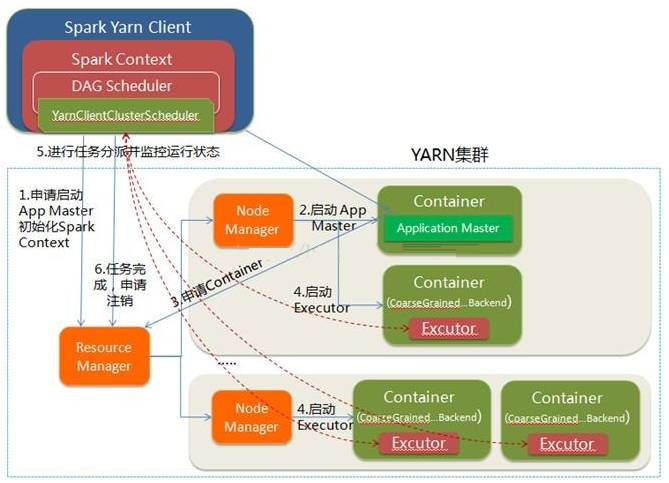
Spark ClusterФЃЪН:
дкYARN-ClusterФЃЪНжаЃЌЕБгУЛЇЯђYARNжаЬсНЛвЛИігІгУГЬађКѓЃЌYARNНЋЗжСНИіНзЖЮдЫааИУгІгУГЬађЃК
ЕквЛИіНзЖЮЪЧАбSparkЕФDriverзїЮЊвЛИіApplicationMasterдкYARNМЏШКжаЯШЦєЖЏЃЛ
ЕкЖўИіНзЖЮЪЧгЩApplicationMasterДДНЈгІгУГЬађЃЌШЛКѓЮЊЫќЯђResourceManagerЩъЧызЪдДЃЌВЂЦєЖЏExecutorРДдЫааTaskЃЌЭЌЪБМрПиЫќЕФећИідЫааЙ§ГЬЃЌжБЕНдЫааЭъГЩ
YARN-clusterЕФЙЄзїСїГЬЗжЮЊвдЯТМИИіВНжш

Spark Client КЭ Spark ClusterЕФЧјБ№:
РэНтYARN-ClientКЭYARN-ClusterЩюВуДЮЕФЧјБ№жЎЧАЯШЧхГўвЛИіИХФюЃКApplication
MasterЁЃдкYARNжаЃЌУПИіApplicationЪЕР§ЖМгавЛИіApplicationMasterНјГЬЃЌЫќЪЧApplicationЦєЖЏЕФЕквЛИіШнЦїЁЃЫќИКд№КЭResourceManagerДђНЛЕРВЂЧыЧѓзЪдДЃЌЛёШЁзЪдДжЎКѓИцЫпNodeManagerЮЊЦфЦєЖЏContainerЁЃДгЩюВуДЮЕФКЌвхНВYARN-ClusterКЭYARN-ClientФЃЪНЕФЧјБ№ЦфЪЕОЭЪЧApplicationMasterНјГЬЕФЧјБ№
YARN-ClusterФЃЪНЯТЃЌDriverдЫаадкAM(Application Master)жаЃЌЫќИКд№ЯђYARNЩъЧызЪдДЃЌВЂМрЖНзївЕЕФдЫаазДПіЁЃЕБгУЛЇЬсНЛСЫзївЕжЎКѓЃЌОЭПЩвдЙиЕєClientЃЌзївЕЛсМЬајдкYARNЩЯдЫааЃЌвђЖјYARN-ClusterФЃЪНВЛЪЪКЯдЫааНЛЛЅРраЭЕФзївЕ
YARN-ClientФЃЪНЯТЃЌApplication MasterНіНіЯђYARNЧыЧѓExecutorЃЌClientЛсКЭЧыЧѓЕФContainerЭЈаХРДЕїЖШЫћУЧЙЄзїЃЌвВОЭЪЧЫЕClientВЛФмРыПЊ
StandaloneЃЈвВНаDeployЃЉФЃЪНЃК
гыMesosФЃЪНгаЕуЯёЃЌвВЪЧMaster/SlaversЕФМмЙЙЁЃStandaloneФЃЪНЪЙгУSparkздДјЕФзЪдДЕїЖШПђМмЃЌбЁгУZooKeeperРДЪЕЯжMasterЕФHA
ПђМмНсЙЙЭМШчЯТ:
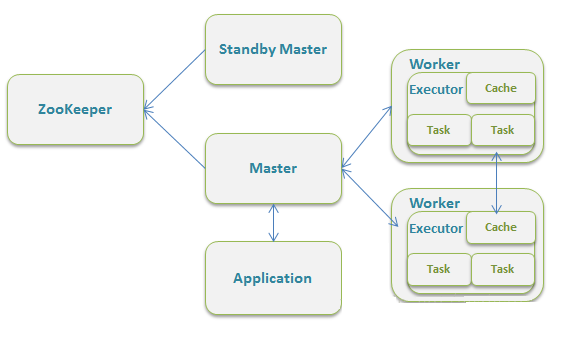
ИУФЃЪНжївЊЕФНкЕугаClientНкЕуЁЂMasterНкЕуКЭWorkerНкЕуЁЃЦфжаDriverМШПЩвддЫаадкMasterНкЕуЩЯжаЃЌвВПЩвддЫаадкБОЕиClientЖЫЁЃЕБгУspark-shellНЛЛЅЪНЙЄОпЬсНЛSparkЕФJobЪБЃЌDriverдкMasterНкЕуЩЯдЫааЃЛЕБЪЙгУspark-submitЙЄОпЬсНЛJobЛђепдкEclipsЁЂIDEAЕШПЊЗЂЦНЬЈЩЯЪЙгУЁБnew
SparkConf.setManager(ЁАspark://master:7077ЁБ)ЁБЗНЪНдЫааSparkШЮЮёЪБЃЌDriverЪЧдЫаадкБОЕиClientЖЫЩЯЕФ
дЫааЙ§ГЬШчЯТЭМ

1.SparkContextСЌНгЕНMasterЃЌЯђMasterзЂВсВЂЩъЧызЪдДЃЈCPU Core КЭMemoryЃЉ
2.MasterИљОнSparkContextЕФзЪдДЩъЧывЊЧѓКЭWorkerаФЬјжмЦкФкБЈИцЕФаХЯЂОіЖЈдкФФИіWorkerЩЯЗжХфзЪдДЃЌШЛКѓдкИУWorkerЩЯЛёШЁзЪдДЃЌШЛКѓЦєЖЏStandaloneExecutorBackendЃЛ
StandaloneExecutorBackendЯђSparkContextзЂВсЃЛ
3.SparkContextНЋApplicaitonДњТыЗЂЫЭИјStandaloneExecutorBackendЃЛВЂЧвSparkContextНтЮіApplicaitonДњТыЃЌЙЙНЈDAGЭМЃЌВЂЬсНЛИјDAG
SchedulerЗжНтГЩStageЃЈЕБХіЕНActionВйзїЪБЃЌОЭЛсДпЩњJobЃЛУПИіJobжаКЌга1ИіЛђЖрИіStageЃЌStageвЛАудкЛёШЁЭтВПЪ§ОнКЭshuffleжЎЧАВњЩњЃЉЃЌШЛКѓвдStageЃЈЛђепГЦЮЊTaskSetЃЉЬсНЛИјTask
SchedulerЃЌTask SchedulerИКд№НЋTaskЗжХфЕНЯргІЕФWorkerЃЌзюКѓЬсНЛИјStandaloneExecutorBackendжДааЃЛ
4.StandaloneExecutorBackendЛсНЈСЂExecutorЯпГЬГиЃЌПЊЪМжДааTaskЃЌВЂЯђSparkContextБЈИцЃЌжБжСTaskЭъГЩ
5.ЫљгаTaskЭъГЩКѓЃЌSparkContextЯђMasterзЂЯњЃЌЪЭЗХзЪдД
SparkЕФШнДэДІРэ
ЧызЂвтетРяЪЙгУЕФЪЧШнДэЖјВЛЪЧШнджЃЌвђЮЊетСЉВЛЪЧвЛИіИХФюЁЃ
ШнджЪЧКщЫЎЁЂЛ№джЁЂЕие№ЕШЕМжТЕФджФбадЕФЛйУ№адЕФЙЪеЯЃЌЪЧЗЧГЃаЁИХТЪЕФЪТМўЃЌашвЊзіЪ§ОнМЖБ№ЩѕжСгІгУМЖБ№ЕФвьЕиБИЗнЃЛЖјШнДэЪЧНтОігЩгкЭјТчзшШћЁЂДХХЬЫ№ЛЕЁЂФкДцвчГіЁЂЛњЦїЕєЕчЕШв§Ц№ЕФЕЅЕуЙЪеЯЛђепФЃПщЛЏЕФЙЪеЯЃЌЪЧУПЪБУППЬЖМгаПЩФмЗЂЩњЕФДѓИХТЪЪТМўЁЃ
ЫљвдЫЕШнДэКЭШнджВЛЪЧвЛИіМЖБ№ЕФЃЌЮвУЧЖдМмЙЙЭиЦЫЩдзїгХЛЏЭЈЙ§КмаЁЕФГЩБООЭПЩвдДяЕНШнДэЕФаЇЙћЃЛЕЋЪЧвЊЯыДяЕНШнджФЧНЋЪЧОоДѓЕФПЊЯњЖјЧвКмФбДцдквЛИі100%ШнджЕФЩшМЦЃЌР§ШчЕиЧђБЛеЈСЫФбЕРЛЙвЊНЋЪ§ОндкЭтЬЋПезіЖЈЦкБИЗнУД~~
ЧАУцНщЩмФЃЪНЕФЪБКђЮвУЧвЛдйЧПЕїЃЌMasterЪЧКЫаФВПМўЃЌЪЧаФдрКЭДѓФдЃЌЫљвдMasterЕФЙЪеЯЪЧЮвУЧВЛФмНгЪмЕФЃЌЫљвдашвЊЭЈЙ§ZookeeperРДзіИпПЩгУадЃЈЫфШЛвВгаfileSystemФЃЪНЕЋЪЧздДгЮвзіЙ§ЕФвЛИіВњЦЗецЕФГіЯжДХХЬЫ№ЛЕЕМжТЕЅЕуЙЪеЯШЛКѓСЌајМгАрСЫ40ЖраЁЪБКђвдКѓЮвдйвВВЛЯраХгВМўСЫЃЉЁЃвЛЕЉLeaderЕФMasterЙвЕєЃЌЦфЫќMasterЛсзджїЭЦгХГіаТЕФLeaderЁЃаТЕФLeaderЛсДгZooKeeperжаЖСШЁЫљгадЊЪ§ОнВЂЭЈжЊЕНДѓМвЃЈWorkerЁЂClientЃЉздМКЕЧЛљЩЯЮЛЁЃ
WorkerНкЕужкЖрЃЌГіЯжЙЪеЯЕФИХТЪзюИпЃЌworkersЖЈЪБЕФЯђMasterЩЯБЈаФЬјЃЌвЛЕЉГЌЪБMasterНЋЖдЫќНјаааЖФЅЩБТПЁЃMasterЛсНЋworkerЩЯЫљгаExecutorЩшжУЮЊЪЇаЇВЂЭЈжЊИјClientЃЌClientЛсЭЈжЊSchedulerBackendШчЙћгаИУworkerЩЯЕФexecutorе§дкжДааФуЕФtaskЧыжиаТЕїЖШЁЃMasterЭЈжЊЭъвдКѓЛсГЂЪдkillЕєИУЛЕЕєЕФworkerЁЃ
WorkerНкЕуЩЯдЫаазХКмЖрexecutorНјГЬЃЌШчЙћworkerаФЬјУЛЮЪЬтЕЋЪЧФГИіexecutorНјГЬГіЯпСЫЮЪЬтдѕУДАьЃПетИіИХТЪБШworkerГіЯжвьГЃЕФИХТЪИќДѓЃЁЦфЪЕworkerНкЕуГ§СЫУїзХИЩЛюЕФexecutorЃЌЛЙгаМрЖНexecutorЕФexecutorRunnerЃЌЫќЛсНЋexecutorЭЫГіЕФаХЯЂИцжЊздМКЫљдкЕФworkerЃЌworkerдкЭЈжЊздМКЕФmasterЃЌЪЃЯТЕФОЭЪЧИњЩЯУцвЛбљЕФЬзТЗСЫЁЃ
ExecutorЯъНтЃК
ExecutorИЩСЫСНМўЪТЧщЃКдЫааTaskКЭНЋНсЙћЗДРЁИјDriverЁЃЁЃ
MasterдкИјApplicationЗжХфWorkerЪБгаСНжжЗНЪНЃКОЁСПДђЩЂКЭОЁСПМЏжаЁЃ
ОЁСПДђЩЂЪЪгУгкФкДцУмМЏаЭЃЌОЁСПМЏжаЪЪгУгкCPUУмМЏаЭЁЃ
1ИіЮяРэНкЕуПЩвдВПЪ№ЖрИіWorkerЃЌЕЋЪЧвЛИіWorkerжаЖдгк1ИіApplicationжЛФмга1ИіExecutorЁЃ
ЙигкExecutorЕФФкДцЩшжУЃК
ExecutorЪЧжДааTaskЕФеце§ПрСІЃЌФкДцЩшжУЕФЙ§аЁЃЌЛсЕМжТФкДцвчГіЛђепЦЕЗБGCгАЯьаЇТЪЃЛФкДцЩшжУЙ§ДѓЛсЕМжТеМгУЙ§ЖрзЪдДЃЈФкДцзЪдДДгМлИёЩЯКЭВлЕРЪ§СПЩЯРДНВЛЙЪЧБШНЯефЙѓЕФЃЉЁЃЫљвдКЯРэЕФЩшжУExecutorФкДцЪЧSparkДІРэШЮЮёЕФЙиМќЁЃExecutorжЇГжЕФШЮЮёЕФЪ§СПШЁОігкГжгаЕФCPUЕФКЫЪ§ЃЌЫљвдвЛжжЫМТЗЪЧШчЙћМЏШКЦеБщЕФCPUКЫЪ§ЙЛЖрЕЋЪЧФкДцНєеХЃЌПЩвдВЩгУИќЖрЕФЗжЧјРДдіМгTaskЕФИіЪ§МѕЩйЕЅИіTaskжДааЖдФкДцЕФвЊЧѓЁЃ
ExecutorзюжеНЋTaskЕФжДааНсЙћЗДРЁИјDriverЃЌЛсИљОнДѓаЁВЩгУВЛЭЌЕФВпТдЃК
1 ШчЙћДѓгкMaxResultSizeЃЌФЌШЯ1GЃЌжБНгЖЊЦњЃЛ
2 ШчЙћЁАНЯДѓЁБЃЌДѓгкХфжУЕФframeSizeЃЈФЌШЯ10MЃЉЃЌвдtaksIdЮЊkeyДцШыBlockManager
3 elseЃЌШЋВПЭТИјDriverЁЃ
ShuffleЯъНтЃК
Hash Base ShuffleЃЈspark1.2вдЧАФЌШЯЃЉЃК
ЯТЭМЪЧНЋ4ИіPartitionЯДХЦГЩ3ИіPartitionЕФАИР§ЃЌМйЩшЕБЧАЪЧStageAЃЌЯТвЛИіЪЧStageB
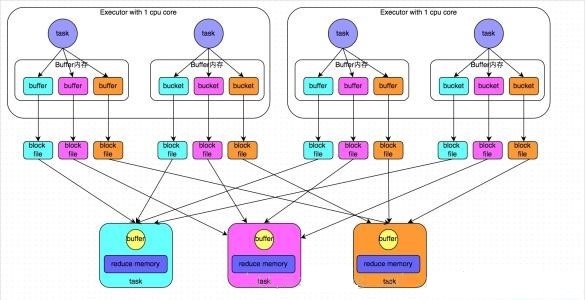
дкЯДХЦЙ§ГЬжаStageAУПИіЕБЧАЕФTaskЛсАбздМКЕФPartitionАДееstageBжаPartitionЕФвЊЧѓзіHashВњЩњstageBжаtaskЪ§СПЕФPartitionЃЈетРяЬиБ№ЧПЕїЪЧУПИіstageAЕФtaskЃЉЃЌетбљОЭЛсгаlenЃЈstageA.taskЃЉ*len(stageB.task)етУДЖрЕФаЁfileдкжаМфЙ§ГЬВњЩњЃЌШчЙћвЊЛКДцRDDНсЙћЛЙашвЊЮЌЛЄЕНФкДцЃЌЯТИіstageBашвЊmergeетаЉfileгжЩцМАЕНЭјТчЕФПЊЯњКЭРыЩЂЮФМўЕФЖСШЁЃЌЫљвдЫЕГЌЙ§вЛЖЈЙцФЃЕФШЮЮёгУHash
BaseФЃЪНЪЧЗЧГЃГдгВМўЕФЁЃ
ОЁЙмКѓРДSparkАцБОЭЦГіСЫConsolidateЖдЛљгкHashЕФФЃЪНзіСЫгХЛЏЃЌЕЋЪЧжЛФмдквЛЖЈГЬЖШЩЯМѕЩйblock
fileЕФЪ§СПЃЌУЛгаИљБОНтОіЩЯУцЕФШБЯнЁЃ
Sort Base ShuffleЃЈspark1.2ПЊЪМФЌШЯЃЉЃК
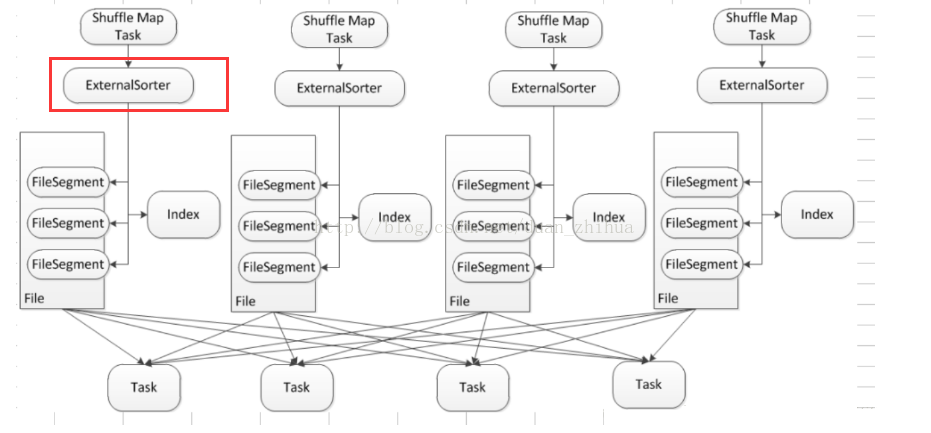
SortФЃЪНЯТStageAУПИіTaskЛсВњЩњ2ИіЮФМўЃКФкШнЮФМўКЭЫїв§ЮФМўЁЃФкШнЮФМўЪЧИљОнStageBжаPartitionЕФвЊЧѓздМКЯШsortКУВЂЩњГЩвЛИіДѓЮФМўЃЛЫїв§ЮФМўЪЧЖдФкШнЮФМўЕФИЈжњЫЕУїЃЌРяУцЮЌЛЄСЫВЛЭЌЕФзгpartitionжЎМфЕФЗжНчЃЌХфКЯStageBЕФTaskРДЬсШЁаХЯЂЁЃетбљжаМфЙ§ГЬВњЩњЮФМўЕФЪ§СПгЩlenЃЈstageA.taskЃЉ*len(stageB.task)МѕЩйЕН2*
len(stageB.task)ЃЌStageBЖдФкШнЮФМўЕФЖСШЁвВЪЧЫГађЕФЁЃSortДјРДЕФСэвЛИіКУДІЪЧЃЌвЛИіДѓЮФМўЖдБШгыЗжЩЂЕФаЁЮФМўИќЗНБубЙЫѕКЭНтбЙЃЌЭЈЙ§бЙЫѕПЩвдМѕЩйЭјТчIOЕФЯћКФЁЃЃЈPSЃКЕЋЪЧбЙЫѕКЭНтбЙЕФЙ§ГЬГдCPUЃЌЫљвдвЊКЯРэЦРЙРЃЉ
SortКЭHashФЃЪНЭЈЙ§spark.shuffle.managerРДХфжУЕФЁЃ
StorageФЃПщЃК
ДцДЂНщжЪЃКФкДцЁЂДХХЬЁЂTachyonЃЈетЛѕЪЧИіЗжВМЪНФкДцЮФМўЃЌгыRedisВЛвЛбљЃЌRedisЪЧЗжВМЪНФкДцЪ§ОнПтЃЉЃЌДцДЂМЖБ№ОЭЪЧЫќУЧЕЅЖРЛђепЯрЛЅзщКЯЃЌдйХфКЯвЛаЉШнДэЁЂађСаЛЏЕШВпТдЁЃР§ШчФкДц+ДХХЬЁЃ
ИКд№ДцДЂЕФзщМўЪЧBlockManagerЃЌдкMasterЃЈDirverЃЉЖЫКЭSlaverЃЈExecutorЃЉЖЫЖМгаBlockManagerЃЌЗжЙЄВЛЭЌЁЃSlaverЖЫЕФНЋздМКЕФBlockManagerзЂВсИјMasterЃЌИКд№еце§blockЃЛMasterЖЫЕФжЛИКд№ЙмРэКЭЕїЖШЁЃ
StorageФЃПщдЫааЪБФкДцФЌШЯеМExecutorЗжХфФкДцЕФ60%ЃЌЫљвдКЯРэЕФЗжХфExecutorФкДцКЭбЁдёКЯЪЪЕФДцДЂМЖБ№ашвЊЦНКтЯТSparkЕФадФмКЭЮШЖЈЁЃ
RDD(Resilient Distributed Datasets)ЕЏадЗжВМЪНЪ§ОнМЏ
RDDжЇГжСНжжВйзїЃКзЊЛЛЃЈtransiformationЃЉКЭЖЏзїЃЈactionЃЉ
зЊЛЛОЭЪЧНЋЯжгаЕФЪ§ОнМЏДДНЈГіаТЕФЪ§ОнМЏЃЌЯёMapЃЛЖЏзїОЭЪЧЖдЪ§ОнМЏНјааМЦЫуВЂНЋНсЙћЗЕЛиИјDriverЃЌЯёReduceЁЃ
RDDжазЊЛЛЪЧЖшадЕФЃЌжЛгаЕБЖЏзїГіЯжЪБВХЛсзіеце§дЫааЁЃетбљЩшМЦПЩвдШУSparkИќМћгааЇЕФдЫааЃЌвђЮЊЮвУЧжЛашвЊАбЖЏзївЊЕФНсЙћЫЭИјDriverОЭПЩвдСЫЖјВЛЪЧећИіОоДѓЕФжаМфЪ§ОнМЏЁЃ
ЛКДцММЪѕЃЈВЛНіЯоФкДцЃЌЛЙПЩвдЪЧДХХЬЁЂЗжВМЪНзщМўЕШЃЉЪЧSparkЙЙНЈЕќДњЪНЫуЗЈКЭПьЫйНЛЛЅЪНВщбЏЕФЙиМќЃЌЕБГжОУЛЏвЛИіRDDКѓУПИіНкЕуЖМЛсАбМЦЫуЗжЦЌНсЙћБЃДцдкЛКДцжаЃЌВЂЖдДЫЪ§ОнМЏНјааЕФЦфЫќЖЏзїЃЈactionЃЉжажигУЃЌетОЭЛсЪЙКѓајЕФЖЏзїЃЈactionЃЉБфЕУИњбИЫйЃЈОбщжЕ10БЖЃЉЁЃР§ШчRDD0ЈЄRDD1ЈЄRDD2ЃЌжДааНсЪјКѓRDD1КЭRDD2ЕФНсЙћвбОдкФкДцжаСЫЃЌДЫЪБШчЙћгжРДRDD0ЈЄRDD1ЈЄRDD3ЃЌОЭПЩвджЛМЦЫузюКѓвЛВНСЫЁЃ
RDDжЎМфЕФПэвРРЕКЭевРРЕЃК
евРРЕЃКИИRDDЕФУПИіPartitionжЛБЛзгRDDЕФвЛИіPartitionЪЙгУЁЃ
ПэвРРЕЃКИИRDDЕФУПИіPartitionЛсБЛзгRDDЕФЖрИіPartitionЪЙгУЁЃ
ПэКЭеПЩвдРэНтЮЊПубќДјЃЌПубќДјдњЕФНєЯТАыЩэЙмЕФбЯЫљвджЛгавЛИіЖљзгЃЛПубќДјАяЕФБШНЯПэЫЩЯТАыЩэЙмЕФВЛНћЛсИуГівЛЖбЫНЩњзгЃЌетбљОЭМЧзЁСЫЁЃ
ЖдгкевРРЕЕФRDDЃЌПЩвдгУвЛИіМЦЫуЕЅдЊРДДІРэИИзгpartitionЕФЃЌВЂЧветаЉPartitionЯрЛЅЖРСЂПЩвдВЂаажДааЃЛЖдгкПэвРРЕЭъШЋЯрЗДЁЃ
дкЙЪеЯЛиИДЪБевРРЕБэЯжЕФаЇТЪИќИпЃЌЖљзгЛЕСЫПЩвдЭЈЙ§жиЫуЕљРДЕУЕНЖљзгЃЌЗДе§ОЭетвЛИіЖљзгЕБЕљЕФЛжИДаЇТЪОЭЪЧ100%ЁЃЕЋЪЧЖдгкПэвРРЕаЇТЪОЭКмЕЭСЫЃЌШчЯТЭМЃК
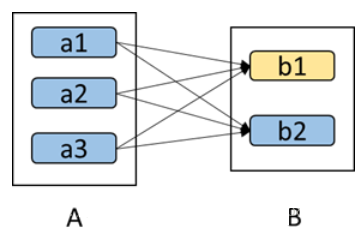
ШчЙћЖљзгb1ЛЕСЫa1ЁЂa2ЁЂa3Ш§ИіЕБЕљЕФЖМдЫЫуСЫвЛДЮЛжИДСЫb1ЃЌЕЋЪЧЦфЪЕЫќУЧЕФдЫЫуЭЌЪБвВЛсИВИЧвЛБщb2етИіЮоЙМЕФЖљзгЃЌгааЇТЪжЛга50%ЁЃ
ДњТыЪЕЯжЩЯевРРЕNarrowDependencyга2жжЃКOneToOneDependencyКЭRangeDependency
ПэвРРЕжЛга1жжShuffleDependencyЃЌЕЋЪЧФкВПВЮЪ§ShuffleManagerгаHashКЭSortСНжжЃЌКѓУцЛсЯъЯИНщЩмHashКЭSorkЕФЧјБ№ЁЃ
гаСЫвдЩЯRDDПэевРРЕКЭИИзгжЎМфЕФбЊдЕЙиЯЕЃЌЮвУЧОЭПЩвдЛцжЦDAGЃК
ЛцжЦддђОЭЪЧгЩгкПэвРРЕЕФЁАЖЯЕуЁБаЇгІЃЌИљОнПэвРРЕНЋећИіDAGЗжЮЊВЛЭЌЕФНзЖЮЃЈStageЃЉЃЌУПИіStageжЎМфгаЯШКѓЙиЯЕДгЧАЯђКѓНјааЃЌдкУПИіStageФкВПевРРЕRDDЪЧВЂаажДааЕФЁЃ
StageЕФЛЎЗжЪЧДгзюКѓвЛИіRDDДгКѓЭљЧАНјааЕФЁЃ
зЂвтЃКзЊЛЏКЭЖЏзїжЛЪЧОіЖЈЖшаджДааЕФЪБЛњЃЌПэевРРЕВХЪЧЛЎЗжStageЕФЮЈвЛБъзМЁЃReduceByKeyЪЧзЊЛЏЃЌЕЋЫќАќКЌShuffleDependencyЃЌЫљвдзЊЛЏКЭЖЏзїгыПэевРРЕУЛЙиЃЌВЛвЊЛьЯ§ЁЃ
RDDЕФМЦЫуЃК
SparkЕФTaskгаСНжжЃКShuffleMapTaskКЭResultTaskЃЌЦфжаКѓепдкDAGзюКѓвЛИіНзЖЮЭЦЫЭИјExecutorЃЌЦфгрЫљгаНзЖЮЭЦЫЭЕФЖМЪЧShuffleMapTaskЁЃ
ExecutorдкзМБИКУTaskдЫааЛЗОГКѓЛсЕїгУscheduler.Task#runЃЌscheduler.Task#runЛсЕїгУShuffleMapTaskЛђResultTaskЕФrunTaskЃЌrunTaskЛсЕїгУRDDЕФ#iteratorЃЌУПИіRDDеце§ЕФМЦЫуТпМЪЕЯждкRDDЕФcomputerЗНЗЈжаЁЃгУЛЇДДНЈSparkContextЪБЛсДДНЈSparkEnvИКд№ЙмРэЫљгадЫааЛЗОГЕФаХЯЂЃЌзюКЫаФЕФЪЧcacheManagerЁЃ
CheckPointЃК
CheckPointЪЧЖдRDDЛКДцВЛзуБЛВСаДЕШжаМфblockЖЯЖЊЪЇЕМжТжиаТМЦЫуетвЛШБЕуЕФУжВЙЃЌCheckPointЛсЦєЖЏвЛИіjobРДМЦЫуВЂНЋМЦЫуНсЙћаДШыДХХЬжаЃЌзюКѓаоИФдЪМRDDЕФвРРЕЮЊЕБЧАCheckPointЁЃЕБЛКДцУЛгаУќжаЪБЯШРДПДCheckPointжагаУЛгаМЧТМЃЌдйОіЖЈЪЧЗёжиаТМЦЫуЁЃCheckPointЪЧRDDДХХЬЛКДцЕФвЛжжБэЯжЃЌЮШЖЈадИќИпЃЌЕЋЪЧIOИќТ§ЁЃ
Sparkгыhadoop:
HadoopгаСНИіКЫаФФЃПщЃЌЗжВМЪНДцДЂФЃПщHDFSКЭЗжВМЪНМЦЫуФЃПщMapreduce
sparkБОЩэВЂУЛгаЬсЙЉЗжВМЪНЮФМўЯЕЭГЃЌвђДЫsparkЕФЗжЮіДѓЖрвРРЕгкHadoopЕФЗжВМЪНЮФМўЯЕЭГHDFS
HadoopЕФMapreduceгыsparkЖМПЩвдНјааЪ§ОнМЦЫуЃЌЖјЯрБШгкMapreduceЃЌsparkЕФЫйЖШИќПьВЂЧвЬсЙЉЕФЙІФмИќМгЗсИЛ
ЙиЯЕЭМШчЯТЃК 
|








