| БрМЭЦМі: |
| РДдДзїепаьаЁЗЩ
ЃЌжївЊИјДѓМвНВНтАЂРяДѓЪ§ОнЬхЯЕЕФЧїЪЦЃЌTeslaдЫЮЌНтОіЗНАИЃЌDataOpsЪ§ОнЛЏдЫЮЌЃЌЪ§ОнМлжЕзЊЛЏЕШЁЃ |
|
БОЮФеЊвЊЃК
НщЩмTeslaШчКЮжЇГХАЂРяРыЯпМЦЫуКЭЪЕЪБМЦЫуСНДѓКЃСПДѓЪ§ОнЦНЬЈЕФБъзМЛЏШеГЃдЫЮЌдЫгЊЃЌвдМАЬНЫїШчКЮЙЙжўдЫЮЌСьгђЕФжЊЪЖЭМЦзЃЌДђдьеыЖдДѓЪ§ОнЦНЬЈКЭДѓЪ§ОнвЕЮёЕФЪ§ОнЛЏШЋЯЂЭЖгАЃЌЪЕЯжЖрЮЌЕФСЂЬхЛЏМрПиЁЂжЧФмОіВпЗжЮіЁЂздЖЏЛЏжДааЕФдЫЮЌБеЛЗЁЃTeslaЪЧУцЯђЦѓвЕМЖИДдгвЕЮёЯЕЭГЕФЪ§ОнЛЏЧ§ЖЏдЫЮЌНтОіЗНАИЃЌНтОіЗНАИАќКЌвЛИіЭГвЛдЫЮЌУХЛЇ(дЫЮЌЙЄЕЅЁЂдЫЮЌДЙжБЫбЫї)КЭЫФИідЫЮЌЛљДЁЦНЬЈ(СїГЬЦНЬЈЁЂХфжУЦНЬЈЁЂзївЕЦНЬЈЁЂЪ§ОнЦНЬЈ)ЃЌМЏШеГЃдЫЮЌЙЄЕЅЙмРэЁЂздЖЏЛЏЗЂВМБфИќЁЂЭГвЛХфжУЙмРэЁЂЭГвЛШЮЮёЕїЖШЁЂжЧФмМрПиИцОЏЙмРэЁЂвьГЃМьВтдЄВтЁЂЙЪеЯздгњЕШЁЃ
ЗжЯэДѓИйЃК
ЁЄдЫЮЌаТЧїЪЦ
ЁЄTeslaдЫЮЌНтОіЗНАИ
ЁЄDataOpsЪ§ОнЛЏдЫЮЌ
ЁЄЪ§ОнМлжЕзЊЛЏ
ЁЄAIOpsеїГЬ
ПЊЦЊНщЩмЃК
ЮвЫљдкЕФЭХЖгНаДѓЪ§ОнЛљДЁЙЄГЬММЪѕЃЌЭЈЫзЕуЫЕОЭЪЧДѓЪ§ОнSRE(ЮЊЪВУДЦ№ЛљДЁЙЄГЬММЪѕетИіУћзж? SREЮФЛЏРягаИізюКЫаФЕФЕуОЭЪЧЪЙгУШэМўЙЄГЬЕФЫМЯыРДНтОідЫЮЌЮЪЬт)ЃЌЮвУЧЭХЖгжЇГХЕФЪЧећИіАЂРяДѓЪ§ОнЩњЬЌЕФдЫЮЌдЫгЊЃЌВЂГСЕэГівЛЬзздМКЕФдЫЮЌНтОіЗНАИЬхЯЕЁЊЁЊTeslaЃЌетЬзЬхЯЕЪЧвЛИіЗжВуЬхЯЕЃЌАќКЌСЫУцЯђдЫЮЌСьгђЙІФмЕФдЫЮЌжаЬЈКЭУцЯђОпЬхДѓЪ§ОнЦНЬЈвЕЮёЕФдЫЮЌгІгУЁЃФПЧАTeslaГадиСЫАЂРяДѓЪ§ОнЦНЬЈМАвЕЮёЙВ10w+ЙцФЃНкЕуЕФШеГЃдЫЮЌЙЄзїЁЃЯраХСЫНтАЂРяЕФШЫЖМЬ§Й§етбљвЛИіДЪЁЊЁЊЁАДѓжаЬЈКЭаЁЧАЬЈЁБеНТдЃЌЭЌбљдкдЫЮЌСьгђЃЌЮвУЧвВЪЧРћгУетИіеНТдРДЙЙжўЮвУЧЕФвЕЮёЃКДѓжаЬЈЬсЙЉЭЈгУЕФдЫЮЌСьгђЙІФмЃЌЖјаЁЧАЬЈПЩвдЛљгквЕЮёГЁОАПьЫйЪдДэЁЂДДаТЁЃЪзЯШЮвУЧЯШПДЯТдЫЮЌЕФаТЧїЪЦЁЃ
вЛ.дЫЮЌаТЧїЪЦ
ИеКУетМИЬьGoogle IOДѓЛсвВе§дкейПЊЃЌЯраХдкзљЕФКмЖрЭЌбЇЖМЛсЙизЂЃЌНёФъЕФДѓЛсжагавЛИіКмЮќв§блЧђЕФЛАЬтЃЌОЭЪЧдкПЊГЁЕквЛЬьЗХГіРДЕФСНЖЮDemoЪгЦЕЃЌЪЧИіЕчЛАТМвєЪгЦЕЃЌФкШнЪЧGoogleжњЪжАяжњПЭЛЇДђЕчЛАЕНЗЂРШЛђВЭЬќШЅзідЄдМЁЃФЧУДССЕудкФФРяФи?дкећИіЕчЛАдЄдМЕФЙ§ГЬжаЃЌЗЂРШКЭВЭЬќЕФШЫЭъШЋУЛгаИажЊЕНКЭЫћУЧНЛСїЕФЪЧAIЛњЦїШЫЁЃЛЛОфЛАЫЕЃЌAIЛњЦїШЫвбОДяЕНСЫвдМйТвецЕФаЇЙћЃЌВЛНідкНЛСїЙ§ГЬжагагяЦјДЪКЭЫМПМЃЌЖјЧвЕБЛАЬтГіЯжжаЖЯЪБЃЌЛЙЛсЬсГіЗДЮЪОфЃЌФмШУЛАЬтЛиЕНЛњЦїШЫЫљвЊЕФЧщОАНјааЯТШЅЁЃ
GoogleЖдЭтаћГЦдкФГаЉЬиЖЈСьгђЃЌР§ШчдЄдМСьгђЃЌЫћУЧвбОЭЈЙ§СЫЭМСщВтЪдЁЃЭМСщВтЪдДѓМвПЩвдШЅСЫНтвЛЯТЃЌЭМСщгавЛЦЊеыЖдЮДРДЛњЦїжЧФмЕФТлЮФЃЌвЛОфЛАНтЪЭТлЮФРяЕФЭМСщВтЪдЃКЕБШЫЛњНЛЛЅЪБЃЌШЫРрЭъШЋИаОѕВЛЕНЖдЗНЪЧИіЛњЦїШЫЃЌФЧУДОЭБъжОзХНјШыСЫЛњЦїжЧФмЕФЪБДњЁЃ
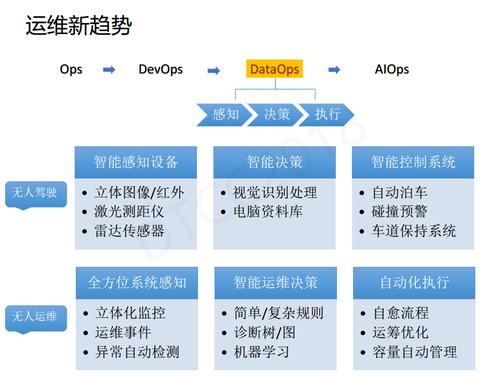
ДѓИХдкШ§ФъЧАЃЌGoogleЬсГіСЫAIеНТдЁЃЪБжСНёШеЃЌЮвУЧПДЕНGoogleдкКмЖрСьгђЖМЩјЭИСЫAIЃЌGoogleЕФAIВЂВЛЪЧзівЛИіШЋаТЕФAIВњЦЗЃЌЖјЪЧНЋAIИГФмЕНЫќЕФЖЅМтВњЦЗжаЁЃЫљвдЃЌЮвУЧБэУцПДЕНЕФЪЧдЄдМЗўЮёЃЌЕЋЦфЪЕЮЊСЫДяЕНетИіаЇЙћЪЧашвЊКмЧПДѓЕФЪ§Он+ЫуЗЈЕФжЇГХЁЃЮвУЧОГЃЬсЕНЕФABC(AIЃЌBigDataЃЌCloud)ЃЌЯывЊЪЕЯжAIЃЌЧАЬсвЛЖЈЪЧДѓЪ§ОнКЭдЦМЦЫуЃЌЖјдкдЫЮЌСьгђвВЭЌбљЪЧШчДЫЁЃетСНФъAIOpsЬиБ№Л№ЃЌЭЌбљЕиЮвУЧШЯЮЊвЊЪЕЯжAIOpsЃЌвЛЖЈЪЧЯШгадЫЮЌЕФЪ§ОнКЭМЦЫуЃЌОЭЪЧЫЕДгDevOpsЕНAIOpsжЎМфЃЌгавЛЖЮDataOpsБиОжЎТЗЁЃ
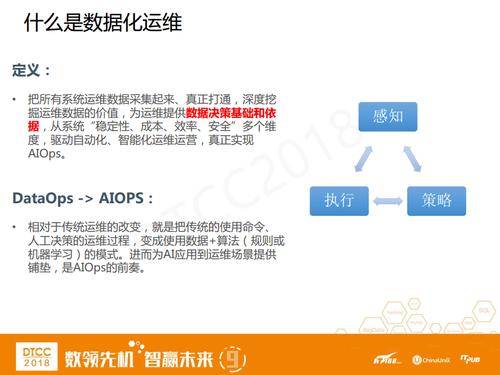
ШчКЮРэНтDataOpsФи?ЪзЯШЃЌЮвУЧвЊФУЪ§ОнРДИажЊЮвУЧЫљдЫЮЌЕФЯЕЭГЃЌМЬЖјРћгУЪ§ОнЗжЮізівЛаЉОіВпЃЌдйЭљЯТОЭЪЧШЅДЅЗЂздЖЏЛЏЕФжЧФмБеЛЗЁЃЮвУЧШЯЮЊDataOpsжазюКЫаФЕФЙ§ГЬОЭЪЧдЫЮЌИажЊЁЂОіВпКЭжДааЁЃ
ЮвУЧАбЮоШЫМнЪЛКЭЮоШЫдЫЮЌзіСЫвЛИіРрБШЁЃЮоШЫМнЪЛвВЪЧGoogleЕквЛИіЬсГіРДЕФЃЌЯждкгаКмЖрГЇЩЬЭЖЩэЦфжаЃЌШчЙћЯИПДЮоШЫМнЪЛЃЌЦфЪЕЮвУЧЗЂЯжгыЮоШЫдЫЮЌРрЫЦЁЊЁЊЮоШЫМнЪЛЪЧдкДЋЭГЦћГЕЩЯИНМгжЧФмИажЊЁЂОіВпЁЂжЧФмПижЦЯЕЭГЁЃЕЋЪЧеце§ЕФЮоШЫМнЪЛЛЙУЛгаДяЕНЃЌМДЪЙЪЧTesla(ТэЫЙПЫЕФЬиЫЙР)вВВЛР§ЭтЁЃЖјжеМЋAIOpsЯывЊДяЕНЕФЪЧвВЪЧЮоШЫдЫЮЌЕФаЇЙћЃЌМДдкDataOps
ЕФИажЊЁЂОіВпКЭжДааШ§ИіНзЖЮЖМИНМгЩЯAIжЧФмЁЃНгЯТРДЯШПДЯТећЬхЕФTeslaдЫЮЌНтОіЗНАИЁЃ
Жў.TeslaдЫЮЌНтОіЗНАИ
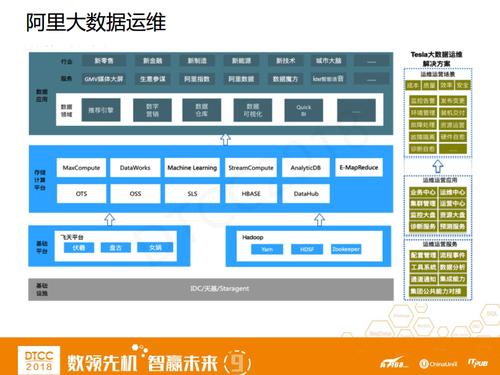
ЩЯУцетеХЭМЪЧАЂРяДѓЪ§ОнЕФЬхЯЕЃЌзѓБпзюЕзВуЪЧЛљДЁЩшЪЉЃЌАќКЌСЫЕзВувРРЕЃЌЛњЗПЁЂЬьЛљЁЂStaragent;ЦфЩЯгаСНДѓЛљДЁЦНЬЈЃЌвЛИіЪЧЗЩЬьЦНЬЈЃЌетЪЧЭъШЋздбаЕФЃЌСэвЛИіЪЧHadoopЦНЬЈЁЃетСНЬзЦНЬЈжЎЩЯЗжБ№ЖдгІЕФЪЧMaxComputeКЭStreamComputeСНДѓДцДЂМЦЫуЦНЬЈ;дйЭљЩЯЪЧЪ§ОнгІгУВуЁЃЖјгвБпЪЧTeslaДѓЪ§ОндЫЮЌНтОіЗНАИЃЌЮвУЧПЩвдПДЕНTeslaЙсДЉСЫећИіАЂРяЕФДѓЪ§ОнЬхЯЕЃЌИКд№ДгЛљДЁЩшЪЉЕНЛљДЁЦНЬЈЕНДцДЂМЦЫуЦНЬЈЕФЫљгаВњЦЗЕФдЫЮЌжЇГХЁЃ
МђЖјбджЎЃЌTeslaОЭЪЧдкЮЊАЂРяЕФДѓЪ§ОнБЃМнЛЄКНЁЃ
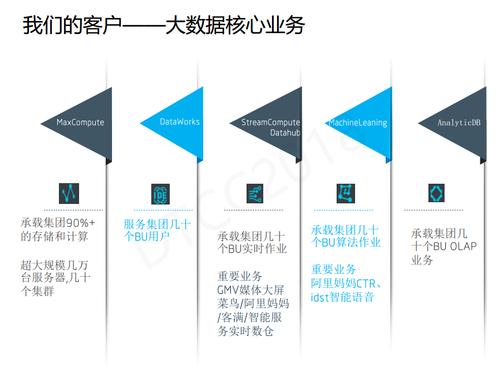
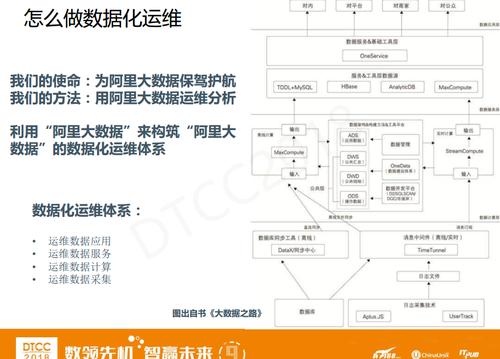
MaxComputeЪЧДѓЪ§ОнЕФКЫаФвЕЮёЃЌЖјDataWorksПЩвдРэНтЮЊЪЧвЛИіУцЯђПЊЗЂепЕФЧАЖЫЃЌЪЧMaxComputeЕФУХЛЇЁЃ
MaxComputeЛљБОЩЯГадиСЫМЏЭХ90%вдЩЯЕФМЦЫуКЭДцДЂЁЃдкАЂРяЃЌЗВЪЧКЭЪ§ОнДђНЛЕРЭЌбЇЖМЛсгУЕНDataWorksЁЃStreamComputeГадиСЫМЏЭХМИЪЎИіBUЕФЪЕЪБзївЕЁЃДѓМвПЩФмИаДЅзюЖрЕФЪЧУПФъЕФЫЋ11ДѓЦСЃЌетБГКѓЖМЪЧгЩStreamComputeЪЕЪБзївЕДЋЩЯШЅЕФЃЌПЩвдДяЕНУыМЖЁЂКСУыМЖЁЃзюКѓЪЧЮвУЧФкВПЕФЛњЦїбЇЯАPAIКЭAnalyticDBЁЃ
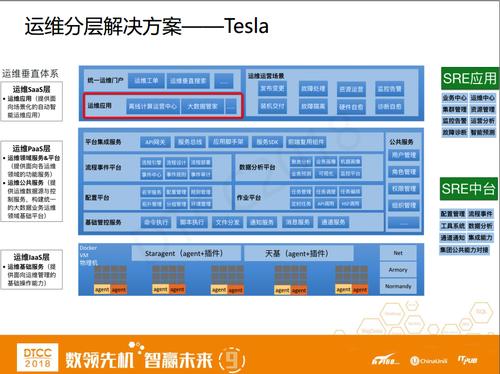
етеХЭМЪЧTeslaдЫЮЌНтОіЗНАИМмЙЙЭМЁЃећИіTeslaдЫЮЌНтОіЗНАИЪЧвЛИіЗжВуЕФЬхЯЕЃЌДгSREжаЬЈЕНSREгІгУЁЃећЬхЪЧвЛИіДЙжБЬхЯЕЃЌвВПЩвдФУSPIРДЗжЃЌжаЬЈзюЕзВуЪЧIaaSЃЌIaaSВуЪЧзюЛљДЁЕФЙЋЙВМЏЭХЕФЩшЪЉЃЌжЎЩЯЪЧКЫаФдЫЮЌPaaSВуЃЌЦфжаАќКЌЫФДѓЦНЬЈ+СНДѓРрЗўЮёЁЃ
ЫФДѓЦНЬЈгыдЫЮЌШЫШеГЃЕФЙЄзїЯрЙиЃЌЗжБ№ЪЧХфжУЦНЬЈЁЂзївЕЦНЬЈЁЂСїГЬЪТМўЦНЬЈКЭЪ§ОнЗжЮіЦНЬЈЁЃдйЭљЩЯОЭЪЧSaaSВуЃЌЬсЙЉСЫЫљгаЕФЦНЬЈКЭЗўЮёЁЃTeslaЦНЬЈжЇГХСЫАЂРяДѓЪ§ОнЕФЪЎМИИіЦНЬЈЃЌвђЮЊУПИіДѓЪ§ОнЦНЬЈвЕЮёВњЦЗЕФдЫЮЌЬиадЖМЪЧВЛвЛбљЕФЃЌПЯЖЈЮоЗЈзіЕНвЛЬздЫЮЌЯЕЭГжЇГХЫљгаЕФВњЦЗдЫЮЌдЫгЊЃЌЫљвдЮвУЧОЭВЩгУСЫЗжВуеНТдЃК
дЫЮЌПЊЗЂЭХЖгЬсЙЉЦНЬЈЃЌЖјеыЖдОпЬхВњЦЗЕФдЫЮЌгІгУгЩSREЭЌбЇРћгУЦНЬЈШЅЙЙжўЁЃЕфаЭЕФSREгІгУАќРЈГЃМћЕФМЏШКЙмРэЁЂзЪдДЙмРэЁЂМрПиИцОЏЁЂЙЪеЯЙмРэЕШЁЃдкетеХЭМРяЮвУЧПЩвдПДЕНDataOpsЬхЯждкЪ§ОнЗжЮіЦНЬЈетвЛВуЁЃ
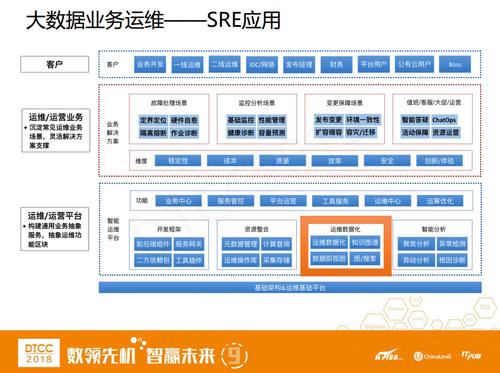
етеХЭМЪЧгІгУЮЌЖШЁЃSREгІгУетвЛВуЕФЙІФмвВЪЧЗжВуЕФЃЌзюЯТУцЪЧЦфЫљвРРЕЕФЛљДЁЦНЬЈЃЌЭљЩЯЪЧУцЯђвЕЮёЕФЙІФм(АќКЌвЕЮёжааФЁЂЗўЮёЙмПиЁЂЦНЬЈдЫгЊЁЂЙЄОпЗўЮёЁЂдЫЮЌжааФКЭдЫГягХЛЏ)ЃЌРћгУетаЉЙІФмЯђЩЯжЇГХОпЬхЕФдЫЮЌГЁОА(ЮЇШЦЮШЖЈадЁЂГЩБОЁЂжЪСПЁЂаЇТЪЁЂАВШЋвдМАЬхбщЕФЮЌЖШ)ЃЌзюжеЗўЮёКУвЕЮёЕФИїРргУЛЇЁЃ
дкдЫЮЌ/дЫгЊЦНЬЈжаГщЯѓГіСЫМИПщФкШнЃЌПЊЗЂПђМмЁЂзЪдДећКЯЁЂдЫЮЌЪ§ОнЛЏКЭжЧФмЗжЮіЁЃвђЮЊзюжеЯЕЭГЖМЪЧЯрЫЦЕФЃЌЫљвдЮвУЧЛсИјЬсЙЉЧАКѓЖЫПђМмЁЂЗўЮёЭјЙиЁЂЖўЗНвРРЕАќвдМАЙЄОпВхМўЃЌвЕЮёSREжЛашдкЛЗОГЩЯШЅЛёШЁЪ§ОнЃЌзіЪ§ОнДІРэЁЂдЊЪ§ОнЙмРэвдМАЬсЙЉЪ§ОнВщбЏЕФЗўЮёЁЃдЫЮЌЪ§ОнЛЏ(DataOps)ОЭЪЧЮвУЧЧАУцЬсЕНЕФЃЌжЧФмЗжЮіжЇГХГЃМћЕФдЫЮЌГЁОАЃЌБШШчзюЕфаЭЕФЙЪеЯДІРэЁЂМрПиЗжЮіЁЂДѓДйБЃеЯвдМАжЕАрПЭЗўЕШЃЌЫћУЧУцСйЕФПЭЛЇЪЧвЛЖбПЭЛЇЃЌетвВЪЧDataOpsдкSREгІгУЩЯЕФЬхЯжЁЃНгЯТРДЮвУЧжиЕуНтЪЭЕНЕзЪВУДЪЧDataOpsЁЃ
Ш§.DataOpsЪ§ОнЛЏдЫЮЌ

ЪВУДЪЧDataOps?ШчКЮзіDataOps?АЂРяЮхаТеНТджагавЛИіаТФмдДЃЌЮвУЧШЯЮЊЪ§ОнОЭЪЧаТФмдДЃЌЯждквбОНјШыЕНаХЯЂБЌеЈЕФЪБДњЃЌДѓМвЫЂЬдБІЬьУЈЪБЕФУПвЛДЮааЮЊЖМЛсДЅЗЂШежОЃЌетаЉШежОзюжеЖМСїЕНЮвУЧЕФЦНЬЈРяЁЃШчДЫКЃСПЕФЪ§ОнЃЌШчЙћФмгааЇЕФзщжЏЙмРэКУЃЌФЧУДОЭПЩвдДгжаЭкОђГіМлжЕЃЌЕЋШчЙћЙмРэВЛКУЃЌОЭПЩФмЛсЪЧИіДѓджФбЁЃ
ЫуЗЈ+ММЪѕЃЌдйНсКЯЪ§ОнОЭЛсВњЩњаТФмдДЃЌЖјЯждкБШНЯЭЈгУЕФЪ§ОнЬєеНЪЧЮвУЧдѕУДгааЇЕФШЅЪеМЏЁЂЧхЯДЪ§Он?ШчКЮБЃжЄЪ§ОнЕФЪЕЪБадЁЂзМШЗад?ШчКЮНЋЮоађЕФЁЂУЛгаНсЙЙЕФЪ§ОнгаађЁЂгаНсЙЙЕФЗжРрЁЂзщжЏЁЂДцДЂЙмРэЦ№РД?ШчКЮЭЈЙ§ЫуЗЈШЅДђЭЈЪ§ОнЃЌСЌНгЁЂЗжЮіЪ§ОнЃЌВЂДгжаЬсСЖГіМлжЕ?етвЛЯЕСаЕФЮЪЬтОЭЪЧDataOpsашвЊНтОіЕФЁЃ
ЪВУДЪЧЪ§ОнЛЏдЫЮЌ? ЮвУЧетбљЖЈвхЃКОЭЪЧАбЫљгаЯЕЭГЕФдЫЮЌЪ§ОнШЋВПВЩМЏЦ№РДЁЂеце§ДђЭЈЃЌЩюЖШЭкОђетаЉЪ§ОнЕФМлжЕЃЌЮЊдЫЮЌЬсЙЉЪ§ОнОіВпЛљДЁКЭвРРЕЁЃ
ДгЯЕЭГЁАЮШЖЈадЁЂГЩБОЁЂаЇТЪЁЂАВШЋЁБЖрИіЮЌЖШШЅЧ§ЖЏздЖЏЛЏЁЂжЧФмЛЏЕФдЫЮЌдЫгЊЃЌДгЖјжњСІЪЕЯжеце§ЕФAIOpsЁЃ
ЯрБШгкДЋЭГдЫЮЌЃЌDataOpsЕФИФБфПЩФмОЭЪЧАбДЋЭГЕФЪЙгУУќСюЁЂШЫЙЄОіВпЕФдЫЮЌЙ§ГЬзЊБфГЩЪ§Он+ЫуЗЈЕФФЃЪНЁЃ
DataOpsЪЧЪЕЯжAIOpsЕФвЛИіБиОжЎТЗЃЌЪЧвЛИідЫЮЌБеЛЗЁЃШчКЮзіЪ§ОнЛЏдЫЮЌФи?гвБпетеХЭМРДздЁЖДѓЪ§ОнжЎТЗЁЗетБОЪщЃЌЕБШЛетеХЭМЫЕЕФЪЧАЂРяећИіЕФЪ§ОнжаЬЈЃЌАЂРяЪ§ОнжаЬЈАбШЋЙЋЫОЫљгаКЭЪ§ОнЯрЙиЕФЖЋЮїЖМећКЯСЫЦ№РДЃЌЬсЙЉСЫвЛЬзЭГвЛЕФЪ§ОнжаЬЈЁЃЦфжаЃЌзюЯТУцЪЧЪ§ОнВЩМЏВуЃЌЭљЩЯЪЧЪ§ОнПтЭЌВНЙЄОпЃЌжаМфЪЧMaxComputeКЭStreamComputeЃЌвВОЭЪЧЪ§ОнДцДЂМЦЫуВуЃЌзюЩЯУцЪЧЪ§ОнЗўЮёВуКЭЪ§ОнгІгУВуЁЃ
Ъ§ОнжаЬЈжаЕФЗНАИЬхЯЕЪЧOneDataЃЌЫќЪЧгУРДЙцЗЖЪ§ОнжаЬЈЃЌШчКЮЮЌЛЄЁЂзщжЏЁЂЙмРэКЭЪЙгУЪ§ОнЕФЁЃOneDataжЎЩЯЪЧOneServiceЃЌгаСЫетЬззщжЏЙмРэКЭСНДѓМЦЫуЦНЬЈжЎКѓЃЌОЭПЩвдЬсЙЉИїЪНИїбљЕФЪ§ОнЗўЮёЃЌВЂдйЯђЩЯЬсЙЉЪ§ОнгІгУЁЃдкАЂРяЃЌЛљБОЩЯЫљгаЕФвЕЮёВПУХЖМЪЧАДееетИіЬзТЗРДзіЕФЁЃ
ШчКЮзіЪ§ОнЛЏдЫЮЌ?ЦфЪЕОЭЪЧРћгУетЬзДѓЪ§ОнЬхЯЕРДЙЙжўДѓЪ§ОнЕФЪ§ОнЛЏдЫгЊЬхЯЕЁЃетОфЛАПЩФмгаЕуФбвдРэНтЃЌИќжБАзвЛЕуЫЕЃЌетЬзЬхЯЕЪЧгЩЮвУЧРДдЫЮЌБЃеЯЕФЃЌЕЋЪЧЙ§ГЬжаЮвУЧвВРћгУЦфРДЙЙжўСЫдЫЮЌдЫгЊЬхЯЕЁЃвђЮЊЮвУЧЕФЪЙУќЪЧЮЊАЂРяДѓЪ§ОнБЃМнЛЄКНЃЌЖјЮвУЧЕФзіЗЈвВЪЧгУАЂРяДѓЪ§ОнРДзідЫЮЌЗжЮіЃЌЪ§ОнЛЏдЫЮЌЗжНтЯТРДОЭЪЧдЫЮЌЕФЪ§ОнВЩМЏЁЂдЫЮЌЕФЪ§ОнМЦЫуЁЂдЫЮЌЕФЪ§ОнЗўЮёвдМАдЫЮЌЕФЪ§ОнгІгУЁЃ
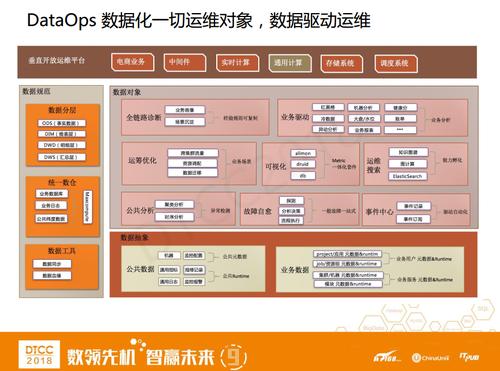
ЧАУцНВЕФЪЧЗНЗЈТлЃЌЯждкНВНВОпЬхЕФЪЕВйЁЃРћгУЪ§ОнжаЬЈЃЌЮвУЧЪзЯШзіЕФЪЧАДееOneDataЙцЗЖНЈСЂдЫЮЌЕФЪ§ОнВжПтЃЌШЛКѓАбЫљгадЫЮЌЯрЙиЕФЪ§ОнзіЗжРрГщЯѓЃЌАќКЌЙЋЙВЪ§ОнЁЂвЕЮёЪ§ОнЁЂдЊЪ§ОнЃЌruntimeЪЕЪБЪ§ОнЁЃЛљгкетаЉЪ§ОнГщЯѓЃЌЮвУЧЬсЙЉСЫДѓСПЕФдЫЮЌЗўЮёКЭЪ§ОнЗўЮёЃЌБШШчвьГЃМьВтЗжЮіЁЂЙЪеЯздгњЁЂПЩЪгЛЏСїГЬЁЂдЫЮЌЫбЫїЁЂдЫГягХЛЏЁЂШЋСДТЗеяЖЯвдМАвЕЮёЧ§ЖЏЁЃЯТУцНсКЯМИИіР§згРДОпЬхНтЪЭЯТШчКЮзіЪ§ОнЛЏдЫЮЌЁЃ
вдШЋСДТЗЗжЮіеяЖЯЮЊР§ЃЌMaxComputeЪЧвЛЬзРыЯпМЦЫуЦНЬЈПђМмЃЌУПЬьгаАйЭђМЖЕФШЮЮёдкХмЃЌетаЉШЮЮёЖМЪЧгЩПЊЗЂЭЌбЇЬсНЛЃЌЕБзївЕвђЮЊИїжждвђГіЯжВЛПЩдЄжЊЕФДэЮѓЃЌДѓМвОЭЛс@дЫЮЌжЕАрШЫдБПДПДЪЧФФРяЕФЮЪЬтЁЃКѓРДЮвУЧЗЂЯжЃЌДѓВПЗжЮЪЬтЪЧЯрЫЦЕФЃЌЫљвдОЭзмНсОбщЃЌДггУЛЇЖМдкетИіЦНЬЈЩЯЬсНЛзївЕЕНзюКѓжДааЕФУПИіНзЖЮЖМШЅДђЕуЁЂВЩМЏЗжЮіЃЌзіСЫвЛЬзШЋСДТЗзївЕеяЖЯЙЄОпЁЃ
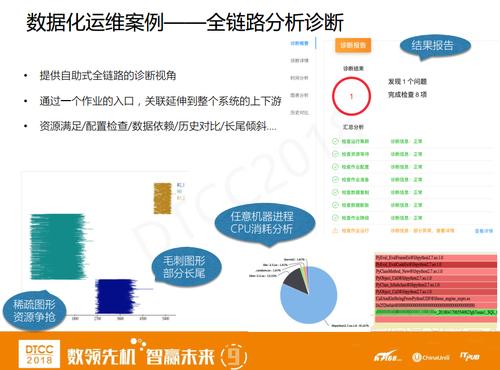
етЪЧвЛИізджњЪНЕФШЋСДТЗеяЖЯВњЦЗЃЌЬсЙЉвЛИіШыПкЃЌгУЛЇжЛвЊЪфШызївЕIDЃЌЮвУЧОЭФмбгЩьЕНећИіЩЯЯТгЮШЅВщбЏЫљгаЕФгаПЩФмЕФЮЪЬтЃЌАќРЈЫќЕФзЪдДЩъЧыЧщПіЁЂХфжУЪЧЗёе§ШЗЁЂЪ§ОнвРРЕЪЧЗёЖМвбТњзуЁЂРњЪЗЧщПіШчКЮЁЂЪЧЗёгаГЄЮВЧуаБЕШЕШЁЃ
ЩЯЭМжагаЮвУЧЙЄОпЕФвГУцНиЭМЃЌПЩвдПДЕНзѓБпЪЧгаЗжРрЕФЃЌЦфЪЕдкзіетИіШЋСДТЗЗжЮіЙЄОпЕФЪБКђЃЌЮвУЧОЭАбетИіГЁОАКЭШЅвНдКЬхМьзіСЫИіРрБШЃЌЬхМьЪБвНЩњвЊеыЖдВЁШЫЕФИїИіЛЗНкзіХаЖЯЃЌШЛКѓЪфГіВЁШЫЕФзДЬЌЃЌOKЛЙЪЧВЛOK?ШчЙћгаЮЪЬтЃЌСЂМДЬсГіРДШУВЁШЫШЅФГеяЪвЫцеяЁЃЭЌбљЕФЃЌЮвУЧвВЪЧеыЖдзївЕзіСЫЖрИіЮЌЖШЕФМьВтЃЌЖјЧвЛЙЛсНЋеяЖЯЯъЧщЁЂЪБМфЗжЮіЁЂЭМБэЗжЮівдМАРњЪЗЖдБШЕШЃЌШЋВПЖМЭИЪгИјгУЛЇЁЃзюКѓЕФНсЙћБЈИцЪЧгУЭМБэЗжЮіЕФЃЌР§ШчЯЁЪшЭМаЮзЪдДељЧРЃЌУЋДЬЭМаЮВПЗжГЄЮВЁЂШЮвтЛњЦїНјГЬCPUЯћКФЗжЮіЁЃ
ЕкЖўИіАИЧèОАЪЧгВМўздгњЃЌФПЧАЮвУЧвбОга10Эђ+ЬЈЮяРэЛњСЫЃЌУПЬьгаДѓСПЕФгВМўЙЪеЯдкЗЂЩњЃЌБШШчгВХЬЛЕСЫЃЌжїАхЛЕСЫЕШЕШЁЃШчЙћЛњЦїБШНЯЩйЃЌФЧУДЮвУЧПЩФмШЫШтЛђепжБНгЬсЕЅОЭПЩвдСЫЃЌЕЋЪЧЕБСПМЖЕНСЫвЛЖЈГЬЖШЃЌУПЬьМИЪЎЕЅЛђепЪЧЩЯАйЕЅЕФгВМўЙЪеЯЃЌетжжЗНЪНОЭВЛЪЪгУСЫЁЃ
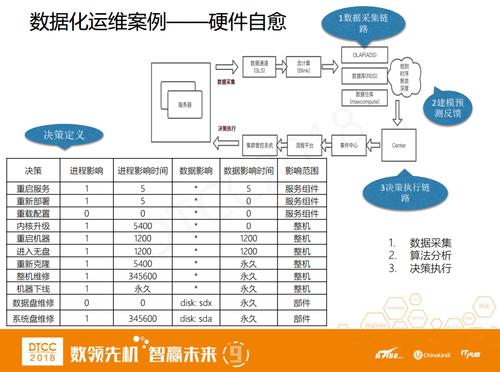
ЫљвдЮвУЧОЭРћгУетЬзЪ§ОнЛЏЕФЫМТЗзіСЫвЛИігВМўздгњЕФСїГЬЁЃЮвУЧвВЪЧДгЗўЮёЦїЩЯВЩМЏЕНЪ§ОнЃЌШЛКѓСїНјСїМЦЫуЦНЬЈBlinkдйЕНЪ§ОнВжПтЃЌзіМьВтЗжЮіВЂЕУГіОіВпЁЃОіВпДЅЗЂСїГЬЦНЬЈзівЛаЉздЖЏЛЏжДааЕФactionЃЌЕїгУМЏШКВйзїЯЕЭГШЅзіЛњЦїЮЌаоЕШЁЃ
гВМўздгњЕФБОжЪвВЪЧвЛИіШ§НзЖЮЕФБеЛЗЃЌдкетЦфжаЮвУЧЕФНЧЩЋгаКмЖрЁЃР§ШчгааЉЙЪеЯжиЦєвЛЯТЗўЮёЛђепЫЋЯђХфжУМДПЩНтОіЃЌЖјгааЉЙЪеЯашвЊЪЙгУЭђФмДѓЗЈЃЌжиЦєЛњЦїВХФмНтОіЁЃШчЙћХіЕННтОіВЛСЫЕФЮЪЬтОЭвЊНјШыЮоХЬзДЬЌЃЌШЅзівЕЮёИєРыЁЂжиаТПЫТЁЁЂећЛњЮЌаоЃЌЮЌаоЭъжЎКѓздЖЏЩЯЯпЁЃећЬзСїГЬШЋВПЪЧздЖЏСїзЊЃЌЮвУЧЪЧЮоШЫжЕЪиЕФзДЬЌЁЃ
ЫФ.Ъ§ОнМлжЕзЊЛЏ
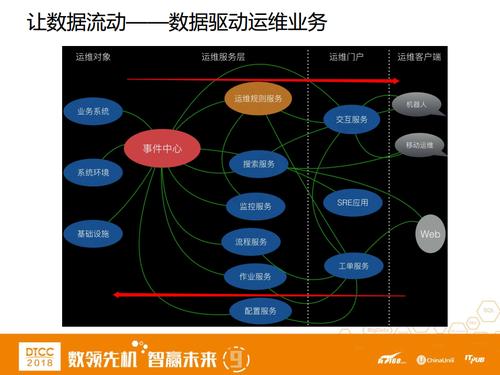
ЭЈЙ§ЧАЮФЕФЗНЗЈТлКЭСНИіАИР§ЃЌЮвУЧДѓИХНтЪЭСЫвЛЯТШчКЮзіЪ§ОнЛЏдЫЮЌЃЌНгЯТРДЃЌЮвУЧдйЭИЪгвЛЯТЪ§ОнЛЏдЫЮЌЕФБОжЪЁЊЁЊДгдЫЮЌЪ§ОнЕНжЊЪЖЕФМлжЕЬсШЁЁЃ
етРяЛсЩцМАЕНМИИіИХФюЃЌЪ§ОнЛЏдЫЮЌЕФЧАЬсЪЧЯШНЋвЛЧаЖдЯѓЪ§ОнЛЏЃЌвВОЭЪЧдЫЮЌЕФШЋгђЪ§ОнЃЌЙЙжўЭъжЎКѓЃЌЪЙгУжЊЪЖЭМЦзНЋетаЉЪ§ОнСЌНгЦ№РДЃЌжЎКѓНЋЪ§ОнЕБзіЗўЮёЬсЙЉИјШЫЃЌРћгУдЫЮЌЫбЫїШЅЬсЙЉвЛаЉПьЫйжБДяЕФЗўЮёЁЃШЛКѓШУЪ§ОнЫЕЛАЃЌЪ§ОнМДЪгЭМЃЌзюКѓЪ§ОнШчЙћФмЧхЯДЕНвЛИіОіВпЪБЁЊЁЊгаМлжЕЕФжЊЪЖЃЌФЧУДЮвУЧОЭШЯЮЊЪ§ОнПЩвдЧ§ЖЏОіВпЁЃ

ШЋгђЪ§ОнЃЌЛљБОЩЯЪЧдЫЮЌЯрЙиЕФШежОЁЂЪТМўЁЂжИБъЁЂБЈОЏЕШЃЌЬиеївВБШНЯЖрЃЌЖрЮЌЖШЁЂЖрВуДЮЁЂЪБаЇадЁЂЙиСЊадЕШЁЃетаЉЖЋЮїЕФБОжЪЦфЪЕОЭЪЧдЫЮЌЖдЯѓКЭдЫЮЌЪТМўЁЃ
гаСЫШЋгђЪ§ОнжЎКѓЃЌШчКЮАбЪ§ОнСЌНгЦ№РД?ЮвУЧОЭРћгУЪЕЬхгыЙиЯЕетСНИіИХФюРДЙЙжўдЫЮЌжЊЪЖЭМЦзЁЃЯТУцЭМЦЌЪЧвЛИіШЋЯЂЭЖгАЃЌПЩвдБШНЯаЮЯѓЕиУшЪіЮвУЧРћгУЭМЦзРДзіЕФЪТЧщЁЃЮвУЧОЭЪЧОЁПЩФмЕФРћгУЪЕЬхМАЪЕЬхжЎМфЕФЙиЯЕЃЌдйНсКЯвЛаЉЭтВПruntimeЕФЪ§ОнШЅЛЙдЕБЪБЯЕЭГЕФдЫааЧщПіЃЌШЛКѓАбЫќгГЩфЕНЯжЪЕГЁОАЩЯШЅзіОЋЯИСЃЖШЕФИажЊЁЃ

ЕБЧАЮвУЧећЬзжЊЪЖЭМЦзЕФЪ§ОнСПЃЌЪЕЬхЪ§ОнДѓИХдкАйЭђМЖЃЌЙиСЊЪ§ОндкЧЇЭђМЖЃЌЭЌЪБЮвУЧЛЙЙиСЊСЫКмЖрЭтВПruntimeЪ§ОнЁЃ
гаСЫжЊЪЖЭМЦзжЎКѓЃЌвЊИјSREЭЌбЇЪЙгУЁЃЮвУЧЬсЙЉСЫвЛЬздЫЮЌДЙжБЫбЫїЙІФмЃЌетЪЧвЛИіЙЄзїФЃЪНЕФИФБфЃЌжЎЧАдЫЮЌЭЌбЇЖМЪЧНЋКмЖрЙІФмЗжУХБ№РрЕФХХВМКУЃЌЕЋЪЧЕБЙІФмЖбЕУдНРДдНЖрЪБЃЌгУЛЇПЩФмВЛжЊЕРвЊШЅФФРяевЫћвЊЕФЖЋЮїЁЃЖјЮвУЧЬсЙЉЕФЫбЫїЙІФмЃЌЫќПЩвдЭЈЙ§ЙиМќДЪРДЫбЫїЯрЙиЕФаХЯЂЃЌР§ШчЫбЫївЛИіЛњЦїЃЌФЧУДЮвУЧОЭАбетИіЛњЦїЯрЙиЕФаХЯЂЖМЭЦИјЫћЃЌАќРЈетИіЛњЦїЕБЧААВзАЕФШэМўЁЂНјГЬзДЬЌЁЂCPUФкДцЁЂIOЧњЯпЕШЁЃ
Г§ДЫжЎЭтЃЌЮвУЧЛЙећКЯСЫАЂРяМЏЭХЕФЫљгадЫЮЌзЪдДЃЌФПЕФЪЧЮЊSREЬсЙЉвЛИіДЙжБСьгђЕФЫбЫїЗўЮёЃЌИФБфдЫЮЌЯАЙпЁЃЭЌЪБЃЌЛЙЬсЙЉСЫвЛИіЙІФмОЭЪЧЧЖШыЕНФГвЛИіеОЕуЃЌЬсЙЉеОФкЕФДЙжБЫбЫїЁЃ
Ъ§ОнМДЪгЭМЃЌЕБгаСЫДѓСПЕФЪ§ОнжЎКѓЃЌЮвУЧЛсЯЃЭћдкКмЖрЕиЗННЋетаЉЪ§ОнеЙЪОГіРДЁЃЕЋЮвУЧЗЂЯжетЦфжагаКмЖрЪТЧщЖМЪЧжиИДЙЄзїЃЌЫљвдЮвУЧОЭЛљгкдЫЮЌЕФПЩЪгЛЏећКЯСЫетЬѕСДТЗЃЌЮвУЧАбЫљгаЕФЪ§ОнЖМАДеевЊеЙЪОЕФИёЪНЙцЗЖЦ№РДЁЃетбљЕФЛАЃЌжЛашвЊЬсЙЉЪ§ОнОЭПЩвддкШЮвтЕФЕиЗНеЙЪОЃЌЯрЕБгкЪ§ОнБОЩэЪЧНсЙЙЛЏЕФЁЂПЩЪгЛЏЕФЁЃ
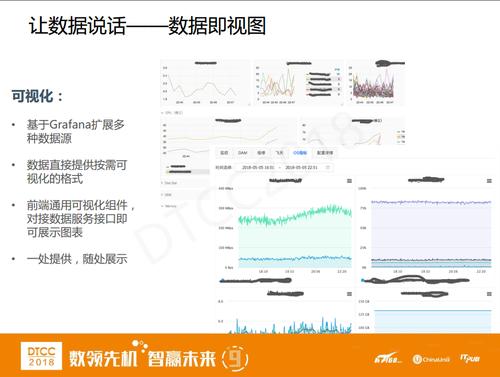
ПЩЪгЛЏЪЧЛљгкGrafanaЃЌЖдНгСЫКмЖрЕФЪ§ОндДЁЃВЛЙ§ЃЌгЩгкGrafanaЪЧangularjsаДЕФЃЌЖјЮвУЧЕФКмЖрЧАЖЫеОЕуЖМЪЧReactЃЌЫљвдЮвУЧзіСЫвЛЬзЛљгкReactЕФЧАЖЫзщМўРДЪЪХфGrafanaКѓЖЫЪ§ОндДЃЌЬсЙЉЮоЗьЕФЭМБэФмСІЁЃИљОнSREЭЌбЇЕФЗДРЁЃЌМИЗжжгжЎФкОЭПЩвдЭъГЩвЛеХПЩППЕФЭМБэПЊЗЂЁЃ
Ъ§ОнОіВпЁЃвдЧАЖМЪЧШЫШЅЬсЕЅЃЌШЛКѓгЩЙЄЕЅРДЧ§ЖЏдЫЮЌВйзїРДЖдЫљгУЕФЖдЯѓНјааЙмРэЁЃЕЋЪЧЯждкећИіЫМТЗЗЂЩњСЫФцзЊЃЌЪзЯШЮвУЧЭЈЙ§ЪТМўЁЂМрПиЕШЭИЪгдЫЮЌЖдЯѓЃЌВЂЭЈЙ§ЙцдђЁЂЫуЗЈЕШОіВпЗўЮёзіГіОіВпЃЌзюжеЭъГЩactionжДааЁЃМђЕЅРДЫЕЃЌвдЧАЪЧШЫЮЇзХЛњЦїзЊЃЌЯждкПЩФмЪЧЛњЦїЮЇзХШЫзЊЁЃ
вдChatOpsжЧФмдЫЮЌжњРэЮЊР§ЃЌетИіГЁОАЪЧФГИіЭЌбЇЯывЊжЊЕРФГвЛЬЈЛњЦїЕБЧАЪЧЪВУДЧщПіЃЌЫћдкЙЄзїШКРя@вЛЯТжњРэЃЌШЛКѓЪфШыhostnameЃЌЛњЦїШЫОЭЛсЗЕЛиетЬЈЛњЦїЕФзДЬЌЃЌЛњЦїЫљдкЕФЗжзщЁЂСЅЪєЕФМЏШКЁЂЕБЧАЯЕЭГзДЬЌЪЧВЛЪЧOKЁЂгВМўзДЬЌЪЧВЛЪЧOKЁЂАВзАЕФЗўЮёШэМўЕФзДЬЌЪЧВЛЪЧOKЁЁетЦфжаУПИізДЬЌЕФНсЙћЖМЪЧвЛИіСДНгЃЌЕуЛїжЎКѓОЭЛсЬјзЊЕНеыЖдетИіЮЪЬтЕФЯъЯИЧщПіЁЃ
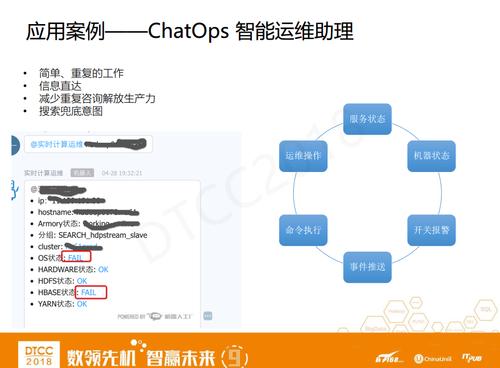
ЯждкЃЌеыЖдЗўЮёзДЬЌЁЂЛњЦїзДЬЌЃЌЮвУЧе§дкАбИќЖрЕФГЁОАЖМЭљChatOpsетЬзРэФюРДЭЦЁЃЫќЫљзіЕФОЭЪЧНЋвЛаЉМђЕЅжиИДЕФЙЄзїГСЕэЯТРДЃЌШУетаЉаХЯЂжБДягУЛЇЃЌЫѕЖЬгУЛЇгыЙІФмжЎМфЕФОрРыЁЃЭЌЪБЃЌЮвУЧЛЙгавЛИіЖЕЕзЕФвтЭМЃЌвђЮЊChatOpsБЯОЙЛЙЪЧЭЈЙ§вЛаЉвтЭМШЅЙцдђЁЂДІРэЖЋЮїЃЌЕБУЛгаЦЅХфЕНФуЕФвтЭМЕФЪБКђЃЌПЩФмОЭевВЛЕНСЫЁЃетЪБЃЌдѕУДАьФи?ЮвУЧАбЧАУцзіЕФдЫЮЌЫбЫїРДЖЕЕзЃЌШчЙћИљОнЙиМќДЪУЛгаЫбЫїЕНЃЌФЧУДЮвУЧОЭЕїгУЫбЫїНгПкРДзіЗДРЁЁЃ
Юх.AIOpsеїГЬ
ЫЕСЫетУДЖрЃЌЕНЕзЪВУДЪЧAIOps?AIOpsжаЕФAIОЙ§аоИФКѓЃЌФПЧАзюаТЕФЪЭвхЪЧArtificial
IntelligenceЁЃЮЊЪВУДЫЕЪЕЯжAIOpsБиаывЊОЙ§DataOpsНзЖЮ?вђЮЊЮвУЧШЯЮЊAIOpsЦфЪЕОЭЪЧдкДЋЭГЕФDataOpsжЎЩЯИНМгжЧФмЃЌШчЙћдкИажЊЁЂОіВпЁЂжДааУПИіНзЖЮЖМИНМгЩЯAIЕФИНМгжЕжЎКѓЃЌЮвУЧШЯЮЊетВХеце§ЪЕЯжСЫAIOpsЁЃГЃМћЕФAIЪжЖЮАќРЈЫуЗЈЁЂЩюЖШбЇЯАЁЂЩёОЭјТчЕШЕШЁЃ

AIOpsОјЖдВЛЪЧДгЮоЕНгаЃЌЫќвЛЖЈЪЧЫцзХФудкФГИіСьгђГжајЕиЙЙжўЁЂГжајЕиЛ§РлЃЌШЛКѓдкУПИіНзЖЮИНМгЩЯаТЕФAIЁЃ
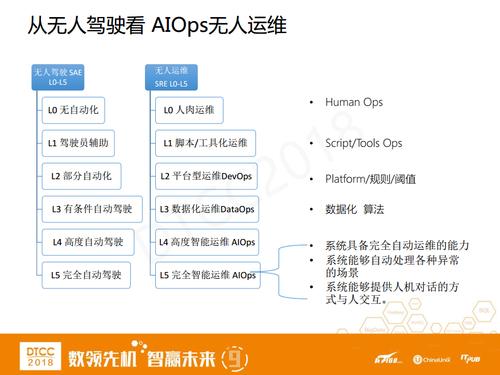
етеХЭМЪЧЮвУЧЭХЖгЭЗФдЗчБЉГіРДЕФЃЌЮвУЧЗЂЯжЮоШЫМнЪЛКЭЮоШЫдЫЮЌКмЯёЁЃSAEНЋЮоШЫМнЪЛЛЎЗжСЫСљМЖL0ЕНL5ЃЌЫћУЧШЯЮЊЕБЧАЪаУцЩЯДѓВПЗжЕФГЕЖМДІгкL2НзЖЮЃЌМДЪЕЯжСЫвЛаЉЛљДЁздЖЏЛЏЃЌБШШчABSЗРБЇЫРЯЕЭГЁЂздЖЏЖЈЫйбВКНЕШЕШЁЃL1НзЖЮПЩФмОЭЪЧЦђиЄАцЃЌВЛОпБИетаЉЙІФмЕФГЕЁЃL3ЪЧгаЬѕМўЕФздЖЏМнЪЛ(ТэЫЙПЫЕФTeslaЪЕМЪЩЯжЛЪЧL2.5)ЃЌ
L4ЪЧИпЖШЕФздЖЏМнЪЛЃЌШчЙћЫЕL3ЛЙашвЊМнЪЛдБзјдкХдБпЃЌГіЯжЮЪЬтЪБНгЙмЃЌЖјL4ЛљБОЩЯдкЬиЖЈЬѕМўЕФТЗЩЯЭъШЋЮоашМнЪЛдБНщШыЃЌГЕзгФмздЖЏХаЖЯзіГіОіВпЁЃL5ЪЧЭъШЋздЖЏМнЪЛЃЌЪЧвЛжжРэЯызДЬЌЃЌПЩФмКмФбДяЕНЁЃИљОнЮФЕЕЕФУшЪіЃЌL5НзЖЮЃЌИјЖЈГЕСОвЛИіЦ№ЪМЕиЕуКЭНсЪјЕиЕуЃЌЦфЫќОЭВЛгУШЅЙмСЫ(ПчдНЙњМвЁЂзѓЕРгвЕРЖМФмздЖЏЧаЛЛ)ЃЌЫќздМКЛсШЅХаЖЯЁЂДІРэвЛЧаЃЌЕЛЏСЫЫОЛњЕФИХФюЁЃ
РрБШЮоШЫМнЪЛЃЌЮоШЫдЫЮЌвВПЩвдЗжЮЊ6ИіНзЖЮЃЌL0ЪЧШЫШтдЫЮЌЃЌL1ЪЧНХБОЁЂЙЄОпЛЏдЫЮЌЃЌЪЧЕБЧАИїДѓЙЋЫОЖМОпБИЕФвЛИізДЬЌЃЌL2ЪЧПЊЗЂдЫЮЌвЛЬхЛЏDevOpsЃЌЫќЕФзюДѓЬиеїЪЧгавЛаЉМђЕЅЕФЙцдђЁЂуажЕЕФХаЖЯЃЌL3ЪЧЪ§ОнЛЏдЫЮЌDataOpsЃЌзюКЫаФЕФЖЋЮїОЭЪЧЪ§ОнЛЏЫуЗЈЃЌL4ЪЧИпЖШжЧФмЛЏдЫЮЌЃЌетЪБЯЕЭГвбОЭъШЋОпБИСЫздЖЏдЫЮЌЕФФмСІЃЌВЂФмЙЛЬсЙЉШЫЛњЖдЛАЕФНЛЛЅЁЃL5ЪЧ
ЭъШЋжЧФмЛЏдЫЮЌЃЌПЩФмОЭЯёЕчгАРяЕФЬьЭјЯЕЭГЭъШЋзджїЗРгљЃЌФуЯыЦЦЛЕЫќЖМВЛПЩФмЁЃзюКѓвдвЛИіАИР§РДНщЩмЯТЮвУЧдкAIOpsЩЯЕФГЂЪдЁЃ
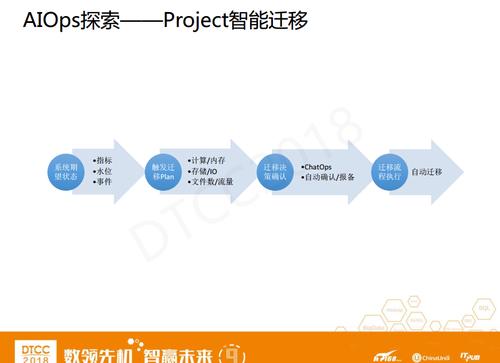
вдProjectжЧФмЧЈвЦГЁОАЮЊР§ЃЌдкМЦЫуЦНЬЈжаЃЌЫљгагУЛЇЕФзЪдДЙмРэЖМЪЧЩъЧывЛИіProjectЃЌМЦЫуЦНЬЈИљОнХфЖюзщРДЗжХфзЪдДЃЌЕБЧАХфЖюзщЕФзЪдДЪЧВЛЪЧЙЛгУЃЌгаУЛгаГЌЙ§дЄЫу?ЭЌЪБЃЌЖдгкЯЕЭГЮвУЧвВЛсгаИіЦкЭћЃЌЯЕЭГгІИУдЫаадквЛИіЪВУДбљЕФзДЬЌЃЌКЫаФжИБъгІИУЪЧЖрЩйЃЌЫЎЮЛЪЧАйЗжжЎЖрЩйЃЌе§ГЃЧщПіЯТВЛЛсДЅЗЂФФаЉЯрЙиЪТМўЁЁвЛЕЉЯЕЭГдкКѓЬЈДЅЗЂСЫЪТМўЃЌЯЕЭГЛсзіздЖЏХаЖЯЃЌжДаажЧФмЧЈвЦЕФPlanМЦЫуЁЃШчЙћЯывЊДяЕНЯЕЭГЫљЦкЭћЕФдЫаазДЬЌЃЌашвЊНЋФФаЉProjectзіЧЈвЦЃЌЧЈвЦЕНФФаЉМЏШКЃЌетЪБЮвУЧЛсЭЈЙ§ChatOpsгыШЫзівЛИіШЗШЯЕФНЛЛЅБЈБИЃЌЭЈЙ§здЖЏжЧФмЕФProjectЧЈвЦжЎКѓЃЌЯЕЭГдйДЮЛиЕНЮвУЧЦкЭћЕФзДЬЌЁЃдкећИіЙ§ГЬжаЃЌЮвУЧПЩвдзіЕНЮоШЫжЕЪиЁЃ
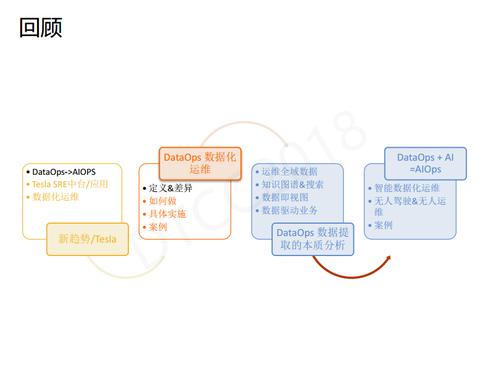
зюКѓдйећЬхЛиЙЫвЛЯТЃЌЪзЯШЃЌЮвУЧНВСЫDevOpsЕНAIOpsЕФвЛИіИХФюЃЌжиЕуНВЪіСЫЪВУДЪЧTesla;ШЛКѓЖЈвхСЫDataOpsЪ§ОнЛЏдЫЮЌЃЌВЂвдСНИіАИР§НВЪіСЫШчКЮзіDataOps;НгЯТРДЃЌЮвУЧЗжЮіСЫЪ§ОнЛЏдЫЮЌЕФБОжЪЃЌАќРЈдЫЮЌШЋгђЪ§ОнЁЂжЊЪЖЭМЦзКЭЫбЫиЁЂЪ§ОнМДЪгЭМЁЂЪ§ОнЧ§ЖЏвЕЮё;зюКѓЃЌЮвУЧНВЪіСЫAIOpsВЂВЛЪЧЮожаЩњгаЃЌЖјЪЧDataOps+AIЃЌВЂгыЮоШЫМнЪЛзіСЫРрБШЁЃзюКѓдйРДИіЙуИцЁЃ
ЮвУЧетРягаКмЖргХЪЦвВгаКмЖрЬєеНЁЃРДАЂРязюДѓЕФгХЪЦОЭЪЧетЬзДѓЪ§ОнЬхЯЕЪЕдкЬЋГЩЪьСЫЃЌвдЧАЮвзіЪ§ОнЛЏдЫЮЌЕФЯрЙиЙЄзїЖМашвЊЮвШЅДгЮоЕНгаЙЙжўЪ§ОнЛЏЬхЯЕЃЌЕЋдкАЂРяЃЌетвЛЬзДЅЪжПЩгУ;ЭЌЪБЮвУЧЫљдЫЮЌЕФЖдЯѓБОЩэОЭЪЧАЂРяДѓЪ§ОнЃЌетгжЪЧвЛИіПЩвдИњАЂРяДѓЪ§ОнЧзУмНгДЅЕФЕиЗН;ЮвУЧЕФЮшЬЈзуЙЛДѓЃЌСПМЖжСЩйдкЙњФкПЩвдГЦЕУЩЯNo.1ЃЌЭЌЪБЫљдЫЮЌЕФЖдЯѓвВКмИДдгЃЌЫљвдЮвУЧашвЊИќИпаЇИќжЧФмЕФЪжЖЮЁЃ |








