| БрМЭЦМі: |
| БОЮФРДздcsdnЃЌЭЈЙ§БОЮФЕФбЇЯАФуНЋRDDРэНтЮЊвЛИіДѓЕФМЏКЯЃЌНЋЫљгаЪ§ОнЖММгдиЕНФкДцжаЃЌЗНБуНјааЖрДЮжигУЁЃ |
|
1. RDDИХЪі
1.1 ЪВУДЪЧRDD
(1)RDDЃЈResilient Distributed DatasetЃЉЕЏадЗжВМЪНЪ§ОнМЏЃЌЫќЪЧSparkЕФЛљБОЪ§ОнГщЯѓЃЌЫќДњБэвЛИіВЛПЩБфЁЂПЩЗжЧјЁЂРяУцЕФдЊЫиПЩВЂааМЦЫуЕФМЏКЯЁЃ
(2) ОпгаЪ§ОнСїФЃаЭЕФЬиЕуЃКздЖЏШнДэЁЂЮЛжУИажЊадЕїЖШЁЂПЩЩьЫѕадЁЃ
(3) ВщбЏЫйЖШПьЃКдкжДааЖрИіВщбЏЪБЃЌПЩвдЯдЪОЕФНЋЙЄзїМЏЛКДцЕНФкДцжаЃЌКѓајЕФВщбЏФмЙЛжигУЛКДцЕФЙЄзїМЏЁЃ
1.2 RDDЕФЪєад
ДђПЊSparkдДДњТыЃЌдДТыЕФзЂЪЭжаЖдRDDЕФУшЪіШчЯТЭМЁЃ
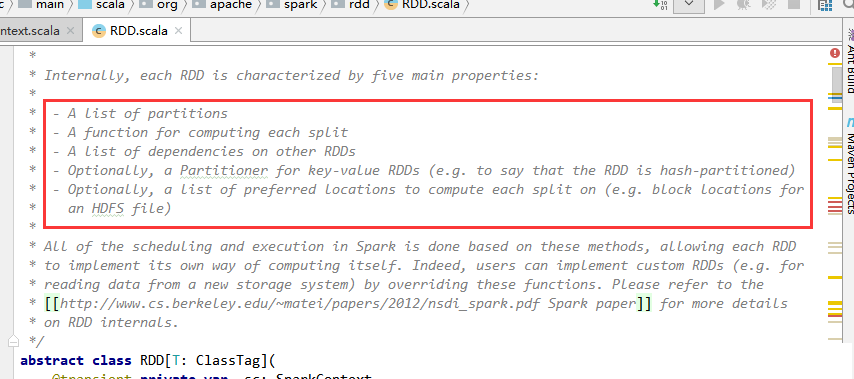
(1) A list of partitions
вЛЯЕСаЕФЗжЧј
(2) A function for computing each split
УПИіКЏЪ§зїгУгкУПвЛИіЗжЧј
(3) A list of dependencies on other RDDs
RDDгыRDDжЎМфгавРРЕЙиЯЕЃЈПэвРРЕЁЂевРРЕЃЉ
(4) Optionally, a Partitioner for key-value RDDs(e.g.
to say that the RDD is hash-partitioned)
ШчЙћRDDЪЧkey-valueаЮЪНЕФЃЌЛсгавЛИіЗжЧјЦї(Partioner)зїгУдкетИіRDDЃЌЗжЧјЦїЛсОіЖЈИУRDDЕФЪ§ОнЗХдкФФИізгRDDЕФЗжЧјЩЯ
(5) Optionally, a list of preferred locations
to compute each splite on (e.g. block locations for
an HDFS file)
дкМЦЫуУПвЛИіЗжЧјЪБЃЌЛсгавЛИігХЯШЕФЮЛжУЃЌвЛИіСаБэДцДЂУПИіPartitionЕФгХЯШЮЛжУ
2. RDDБрГЬAPI
2.1 RDDЕФЫузггаСНжжРраЭЃЌ
(1) TransformationЃК ВЛЛсТэЩЯМЦЫуНсЙћЃЌжЛЛсМЧзЁУПИігІгУЕНЛљДЁЪ§ОнМЏЩЯЕФзЊЛЛВйзїЃЌжЛгаЗЂЩњвЛИіашвЊЗЕЛиНсЙћИјDriverЕФЖЏзїЪБЃЌВХЛсеце§ДЅЗЂМЦЫуЁЃМДЃКRDDжаЫљгаЕФзЊЛЛВйзїЖМЪЧбгГйМгдиЕФЃЌФмШУSparkИќгааЇТЪЕФдЫааЁЃ
(2) ActionЃКЛсСЂМДДЅЗЂдЫЫу
2.2 ГЃгУЕФЫузг
ЖдЫузгЕФИќЯъЯИЪЙгУНтЪЭЧыВЮПМЮвЕФСэвЛЦЊВЉЮФЃК
ВЉЮФЕижЗЃКhttps://blog.csdn.net/xin93/article/details/80546765
2.2.1Transformation


2.2.2 ГЃгУЕФActionЫузг

3. RDDЕФвРРЕЙиЯЕ
3.1 евРРЕ
УПИіИИRDDЕФPartitionзюЖрБЛзгRDDЕФвЛИіPartitionЪЙгУЃЌМДЃКЖРЩњзгХЎ
3.2ПэвРРЕ
ПэвРРЕЪЧSparkЛЎЗжStageЕФвРОнЁЃУПИіИИRDDЕФPartitionБЛзгRDDЕФЖрИіPartitionЪЙгУЃЌМДЃКгаЖрИізгХЎ
ЙигкSparkдДТыжаЪЧШчКЮЧаЗжStageЕФЃЌЧыВЮПМЮвЕФСэвЛЦЊВЉЮФЃК
ВЉЮФЕижЗЃКhttps://blog.csdn.net/xin93/article/details/80674497

3. RDDЕФЛКДц
RDDЬсЙЉСНжжЗНЗЈНјааЛКДц persist( ) КЭ cache( )ЃЌетСНжжЗНЗЈВЛЛсСЂМДНјааЛКДцЃЌЖјЪЧдкКѓУцДЅЗЂСЫactionМЦЫуЪБВХЛсНЋRDDеце§ЛКДцдкМЦЫуНкЕуЕФФкДцжаЙЉКѓУцЪЙгУЁЃ
ЭЈЙ§ВщПДSparkдДДњТыЃЌЯъЯИШчЯТЭМЃК

ПЩвдПДЕНЃЌcache( )ЗНЗЈЪЕМЪЩЯвВЪЧЕїгУpersist( )ЗНЗЈЪЕЯжЕФЛКДцЙІФмЁЃЖјФЌШЯЕФДцДЂМЖБ№ЪЧStorageLevel.MEMORY_ONLYЃЌвВОЭЪЧжЛдкФкДцжаДцДЂвЛЗнЁЃ
дкдДТыжаЛЙЬсЙЉСЫШчЯТжжРрЕФЛКДцЗНЪНПЩЙЉгУЛЇЪЙгУЁЃ

|








