| 编辑推荐: |
| 本文来自itpub
,文章主要介绍了腾讯内部基于Flink打造的一站式实时计算平台Oceanus的相关内容,希望能对您有所帮助。 |
|
一、背景介绍
TEG实时计算团队作为腾讯内部最大的实时数据服务部门,为业务部门提供高效、稳定和易用的实时数据服务。其每秒接入的数据峰值达到了2.1亿条,每天接入的数据量达到了17万亿条,每天的数据增长量达到了3PB,每天需要进行的实时计算量达到了20万亿次。

近年来大数据技术的发展,特别是HDFS和HBase这些大数据存储系统以及Hadoop和Spark这些大数据计算系统,已经使人们能较好地处理数据规模的问题。但是人们对于数据内在价值的追求是无止境的。一方面,人们开发了越来越多复杂的数据挖掘算法来发现数据更深层次的关系信息;而另一方面,由于数据价值往往随着时间的流逝而消失,人们对数据分析时效性的要求也越来越高。越来越多的业务开始使用实时计算来及时获取数据反馈。
之前实时计算团队基于Apache Storm构建了早期的实时计算平台。但在长期的维护过程中,Apache
Storm一些设计和实现上的缺陷逐渐暴露出来。Apache Flink出现之后,其在计算接口、计算性能和可靠性上的优异表现,使我们决定使用Apache
Flink作为新一代实时计算平台的计算引擎。

相比于Storm和其他一些流计算框架,Flink有着更先进的计算框架,具有以下几点优势:
1)首先,Flink提供了更友好的编程接口。Storm提供的API偏底层且过于简单,用户需要大量的开发工作来完成业务需求。另外,用户在开发Storm程序时的学习成本也较高,需要熟悉框架原理和在分布式环境下的执行细节。Flink除了提供Table
API和SQL这些高级的声明式编程语言之外,还对window这些流计算中常见的算子进行了封装,帮助用户处理流计算中数据乱序到达等问题,极大的降低了流计算应用的开发成本并减少了不必要的重复开发。
2)Flink提供了有效的状态管理支持。大部分的计算程序都是有状态的,即计算结果不仅仅决定于输入,还依赖于计算程序当前的状态。但Storm对程序状态的支持十分有限。一般情况下,用户常常需要将状态数据保存在MySQL和HBase这样的外部存储中,自己负责这些状态数据的访问。这些对外部存储的访问常常成为Storm程序的性能瓶颈。大多数情况下,用户只能设计复杂的本地cache来提升性能。Spark
Streaming直到最近才提供了有限的状态管理支持,但受限于其实现机制需要一定的远程访问和数据迁移工作,因此状态数据的访问效率并不高。Flink则对计算程序的状态存储提供了有效支持。用户可以通过提供的接口方便地存储和访问程序状态。由于这些状态数据存放在本地,因此用户可以得到较高的访问性能。在发生故障时,Flink的状态管理会配合容错机制进行状态数据的重建,保证用户程序的正确性。而当用户需要修改程序并发度时,Flink也可以自动地将状态数据分发到新的计算节点上。
3)Flink提供了丰富的容错语义。由于Storm缺少对程序状态的有效支持,其对容错的支持也较弱,很难保证在发生故障的情况下,每条输入数据恰好被处理一次。而Flink则依靠分布式系统中经典的Chandy-Lamport算法,能够对用户程序的输入和状态生成满足一致性的程序快照。在发生异常的情况下通过快照回滚,Flink可以保证EXACTLY-ONCE的容错语义。而利用异步checkpoint和增量checkpoint技术,Flink能够在以较低的成本对用户程序进行快照。在开启快照时,用户程序的性能几乎不受影响。
4)Flink拥有出色的执行性能。Flink基于事件触发的执行模式对数据流进行处理,相比于Spark
Streaming采取mini batch的执行模式,能够大量减少程序执行时的调度开销。此外,Flink对网络层进行了大量优化,通过细粒度封锁和高效内存访问提高数据传输性能,并通过反压机制和流量控制有效降低流量拥塞导致的性能下降。加上Flink能够避免状态数据的远程访问,Flink在实践中表现出比其他流计算系统更出色的执行性能,具有更低的处理延迟和更高的吞吐能力。
二、平台介绍
尽管Flink作为计算引擎有着较为出色的表现,但在业务迁移过程中,我们仍然遇到了一些问题。一个流计算任务从开发到上线要经历包括开发、测试、部署和运维在内的多个阶段。用户首先在开发阶段使用IDE开发程序,并进行编译和打包。之后用户将打包好的程序部署到测试环境中,生产测试数据进行测试。测试通过之后,用户需要将其部署到现网环境中,并设定需要的运维指标进行监控。在这些阶段中,用户需要在不同环境和不同工具打交道,整体的开发和运维效率较低。

为了提高用户流计算任务持续集成和持续发布的效率,实时计算团队围绕Flink打造了Oceanus,一个集开发、测试、部署和运维于一体的一站式可视化实时计算平台。Oceanus集成了应用管理、计算引擎和资源管理等功能,同时通过日志、监控、运维等周边服务打通了应用的整个生命周期。

目前,Oceanus已经覆盖了所有业务BG,为多个业务提供实时计算服务。实时计算团队还将腾讯内部负责数据接入、处理和管理工作的TDBank作业都从JStorm迁移到了Oceanus平台上。另外,原先基于SQL
on Storm的EasyCount平台上的大部分业务也都已迁移到Oceanus。
2.1 多样化的应用构建方式
Oceanus提供了多种形式的应用构建方式来满足不同用户的需求。一般用户可以使用画布方便的构建他们的实时计算应用。Oceanus在web页面上提供了常见的流计算算子,用户可以将算子拖拽到画布上,并将这些算子连接起来之后就构建好了一个流计算应用。这种构建方式十分简单,不需要用户了解底层实现的细节,也不需要掌握SQL等语言的语法,使得用户能够专注于业务逻辑和数据流向。

对于具有一定数据分析背景的用户,Oceanus提供了Flink SQL接口。Flink SQL尽量遵循SQL标准来描述流数据的计算语义,因此对以前经常使用数据仓库进行离线数据分析的用户能够很快的迁移到Flink
SQL上,并用Flink SQL对实时数据流进行分析。为了进一步降低用户的开发成本,Oceanus还在平台上提供了很多常见的SQL函数。为了打造便捷流畅的使用体验,Oceanus还为Flink
SQL的开发提供了一系列的辅助功能:
1)语法高亮和自动补齐
2)表名和字段名的快捷输入、模糊匹配
3)常见函数的模糊匹配
4)一键检查代码有效性
5)一键代码格式化
......
考虑到不管是画布还是SQL,它们的表达能力都比较有限,在开发一些具有复杂逻辑的应用时较为困难,并且也不能进行一些底层细节的优化,Oceanus允许用户继续使用Flink提供的DataStream接口开发实时计算程序。在这种方式下,用户只需要将他们的实时计算程序打包好上传到Oceanus即可。
2.2 外部数据管理
为了方便用户管理Flink作业读取和写入,Oceanus提供了对外部数据管理的功能。在开发应用之前,用户可以通过Oceanus声明应用所需要使用的数据源名称,存储类型(如Hippo,Tube,MySQL或HBase等),以及每个数据字段的名称和类型。外部数据管理使用户可以在Oceanus上既可以完成外部数据的创建和访问,并在开发程序时提供必要的字段和格式信息,提高了用户开发实时计算应用的效率。此外,外部数据管理也允许用户更好地维护外部数据的血缘关系和生产逻辑,在数据发生异常时能够根据生产链路追溯并定位问题。

2.2 实时可视化的计算结果
对于运行中的应用,Oceanus提供了实时查看计算结果的功能。目前Oceanus提供了两种不同的实时可视化方式。首先,用户可以通过Oceanus提供的结果抽样功能获取到当前计算结果的实时采样,利用对比结果来对实时计算应用的正确性进行验证。此外,Oceanus还打通了专业报表平台
– 小马报表(http://xiaoma.qq.com)。用户可以将计算结果接入到小马报表中来搭建业务的Dashboard,将业务数据进行实时可视化。

2.3 自助调试,快速验证业务逻辑
在完成实时计算应用的开发中,Oceanus为用户程序提供了一系列的工具进行应用逻辑的验证。用户既可以使用Oceanus提供的一键生成功能产生测试数据,也可以自己向Oceanus上传自己的的测试数据,通过对比预期结果和实际结果来验证应用逻辑的正确性。在后续工作中,Oceanus还将提供从现网数据抽样生成测试数据的功能。这样,用户就可以更好通过更真实的测试数据来发现应用逻辑的问题。
2.4 快速方便的资源管理和作业部署
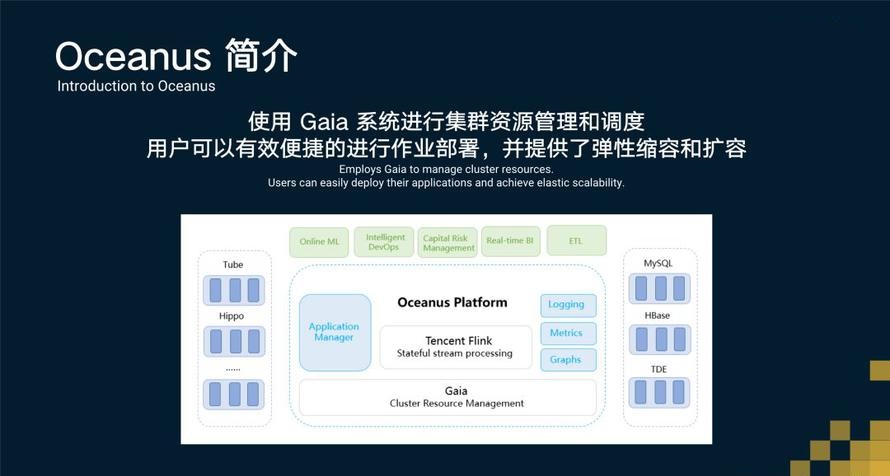
用户在完成作业的开发和测试之后,可以通过Oceanus快速的在集群上进行部署。Oceanus依托腾讯内部的资源调度系统Gaia来进行资源管理和作业部署。Oceanus在作业管理页面上提供了作业资源的配置页面,用户可以通过这个配置页面来对作业所需要的CPU和内存资源进行配置,并指定作业需要部署的集群。当用户完成配置之后,Oceanus会向Gaia申请对应的资源并将作业提交到Gaia上运行。基于Flink提供的checkpoint功能,Oceanus允许用户对作业并发度进行实时修改,实现动态的扩容和缩容。
2.5 丰富的运维监控指标
Oceanus对Flink作业运行时的多个运行指标进行采集,包括Task Manager的内存,I/O和GC等。这些采集的指标被写入了消息队列Tube中,并利用时序数据库OpenTSDB进行聚合。通过这些丰富的运行指标,用户能够很好的了解应用运行的情况,并在出现异常时能协助用户及时的定位问题。运维人员则可以通过这些采集到的指标,设置报警策略并实现精细化的运营。

三、功能改进
为了能够提供更好的实时计算服务,实时计算团队对Flink内核也进行了大量的改进,提高其可用性和可靠性。
为了方便用户开发画布和SQL程序,实时计算团队实现了超过30个的Table API和SQL函数。用户可以利用这些内置函数极大地提高实时计算应用的开发效率。此外,实时计算团队也对数据流和外部维表的join进行了大量优化。另外还提供了AsyncIO算子的超时处理。实时计算团队还实现了增强窗口来对延迟到达的数据进行更好的处理,避免这些延迟数据的丢失对计算结果正确性的影响。

实时计算团队也对Flink的稳定性做了大量的工作。例如通过改进Job Master的容错机制,实时计算团队可以实现Master在发生故障时不影响作业的正常执行。
在对Flink持续进行改进的同时,实时计算团队也和Flink社区建立了密切合作,将这些改进回馈给Flink,为Flink的发展做出了大量贡献。目前实时计算团队已经拥有了1名committer以及3名活跃contributor。在刚刚发布的Flink
1.7版本中,实时计算团队成员贡献了超过30个pull request。

在后面的工作中,Oceanus将继续在实时计算的可用性和稳定性上努力,为用户提供更好的实时计算服务。我们将继续完善我们的运维监控指标,使我们的监控系统更加智能化,方便用户对运行作业的监控和对异常情况的定位。同时,我们还将优化现有的弹性伸缩机制,使用户能根据业务负载实现快速的扩容和缩容。最后,我们会改进Flink现有的状态管理系统,减少Flink由于负载倾斜导致的性能下降。
|








