| БрМЭЦМі: |
БОЮФжївЊНщЩмЙЙНЈвЛИіПЩЪгЛЏЗжЮіЭМЕФ
Spark гІгУЃЌЛЭМВЂЛцжЦЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкSparkММЪѕШеБЈЃЌгЩЛ№СњЙћШэМўчїчїБрМЁЂЭЦМіЁЃ
|
|
Spark КЭ GraphX ЖдВЂВЛЬсЙЉЖдЪ§ОнПЩЪгЛЏЕФжЇГж, ЫќУЧЫљЙизЂЕФЪЧЪ§ОнДІРэ. ЕЋЪЧ, вЛЭМЪЄЧЇбд, гШЦфЪЧдкЪ§ОнЗжЮіЪБ. НгЯТРД, ЮвУЧЙЙНЈвЛИіПЩЪгЛЏЗжЮіЭМЕФ Spark гІгУ. ашвЊгУЕНЕФЕкШ§ЗНПтга:
GraphStream: гУгкЛГіЭјТчЭМ
BreezeViz: гУЛЇЛцжЦЭМЕФНсЙЙЛЏаХЯЂ, БШШчЖШЕФЗжВМ.
етаЉЕкШ§ЗНПтОЁЙмВЂВЛЭъУР, ЖјЧвгааЉЯожЦ, ЕЋЪЧЯрЖдЮШЖЈКЭвзгкЪЙгУ.
АВзА GraphStream КЭ BreezeViz
вђЮЊЮвУЧжЛашвЊЛцжЦОВЬЌЭјТч, ЫљвдЯТди core КЭ UI СНИі JAR ОЭПЩвдСЫ.
gs-core-1.2.jar
gs-ui-1.2.jar
breeze вВашвЊСНИі JAR:
breeze_2.10-0.9.jar
breeze-viz_2.10-0.9.jar
гЩгк BreezeViz ЪЧвЛИі Scala Пт, ЫќвРРЕСЫСэвЛИіНазі JfreeChart ЕФ Java Пт, ЫљвдвВашвЊАВзА:
jcommon-1.0.16.jar
jfreechart-1.0.13.jar
ПЩвдЕН maven ВжПтШЅЯТди, ЯТдиЭъГЩКѓЗХЕНЯюФПИљФПТМЯТ lib ЮФМўМаЯТМДПЩ. гУ sbt РДЙмРэвРРЕБШНЯЗНБу, ЫљвдЮвЪЙгУ sbt РДАВзАетаЉвРРЕ:
| // Graph
Visualization
// https://mvnrepository.com/artifact/org.
graphstream/gs-core
libraryDependencies += "org.graphstream"
% "gs-core" % "1.2"
// https://mvnrepository.com/artifact/org.
graphstream/gs-ui
libraryDependencies += "org.graphstream"
% "gs-ui" % "1.2"
// https://mvnrepository.com/artifact/org.
scalanlp/breeze_2.10
libraryDependencies += "org.scalanlp"
% "breeze_2.11" % "0.12"
// https://mvnrepository.com/artifact/org.scalanlp
/breeze-viz_2.11
libraryDependencies += "org.scalanlp"
% "breeze-viz_2.11" % "0.12"
// https://mvnrepository.com/artifact/org.jfree/jcommon
libraryDependencies += "org.jfree"
% "jcommon" % "1.0.24"
// https://mvnrepository.com/artifact/org.jfree
/jfreechart
libraryDependencies += "org.jfree"
% "jfreechart" % "1.0.19" |
ЛЭМ
ЕМШы
дкЕМШыЛЗНкашвЊзЂвтЕФЪЧ, ШчЙћЪЧгы GraphX ЕФ Graph вЛЭЌЪЙгУ, дкЕМШыЪБНЋ graphstream ЕФ Graph жиУќУћЮЊ GraphStream, ЗёдђЖМНа Graph ЛсгаУќУћПеМфЩЯЕФГхЭЛ. ЕБШЛ, ШчЙћжЛЪЙгУвЛИіОЭЮоЫљЮНСЫ.
| import org.graphstream.graph.
{Graph => GraphStream} |
ЛцжЦ
ЪзЯШЪЧЪЙгУ GraphX МгдивЛИіЭМ, ШЛКѓНЋетИіЭМЕФаХЯЂЕМШы graphstream ЕФЭМжаНјааПЩЪгЛЏ. ОпЬхЪЧ:
ДДНЈвЛИі SingleGraph ЖдЯѓ, ЫќРДзд graphstream:
val graph: SingleGraph
= new SingleGraph
("visualizationDemo") |
ЮвУЧПЩвдЕїгУ SingleGraph ЕФ addNode КЭ addEdge ЗНЗЈРДЬэМгНкЕуКЭБп, вВПЩвдЕїгУ addAttribute ЗНЗЈРДИјЭМ, ЛђЪЧЕЅЖРЕФБпКЭЖЅЕуРДЩшжУПЩЪгЛЏЪєад. graphsteam API ЗЧГЃКУЕФвЛЕуЪЧ, ЫќНЋЭМЕФНсЙЙКЭПЩЪгЛЏгУвЛИіРр CSS ЕФбљЪНЮФМўЭъШЋЗжРыСЫПЊРД, ЮвУЧПЩвдЭЈЙ§етИібљЪНЮФМўРДПижЦПЩЪгЛЏЕФЗНЪН. БШШч, ЮвУЧаТНЈвЛИі stylesheet ЮФМўВЂЗХЕНгУЛЇФПТМЯТЕФ style ЮФМўЯТУц:
| node {
fill-color: #a1d99b;
size: 20px;
text-size: 12;
text-alignment: at-right;
text-padding: 2;
text-background-color: #fff7bc;
}
edge {
shape: cubic-curve;
fill-color: #dd1c77;
z-index: 0;
text-background-mode: rounded-box;
text-background-color: #fff7bc;
text-alignment: above;
text-padding: 2;
} |
ЩЯУцЕФбљЪНЮФМўЖЈвхСЫНкЕугыБпЕФбљЪН, ИќЖрФкШнПЩМћЦф ЙйЗНЮФЕЕЃЈ http://graphstream-project.org/doc/Tutorials/Graph-Visualisation/ЃЉ.
зМБИКУбљЪНЮФМўвдКѓ, ОЭПЩвдЪЙгУЫќ:
| // Set up
the visual attributes for graph visualization
graph.addAttribute("ui.stylesheet",
"url(file:/home/xlc/style/stylesheet)")
graph.addAttribute("ui.quality")
graph.addAttribute("ui.antialias") |
ui.quality КЭ ui.antialias ЪєадЪЧИцЫпфжШОв§ЧцдкфжШОЪБвджЪСПЮЊЯШЖјЗЧЫйЖШ. ШчЙћВЛЩшжУбљЪНЮФМў, ЖЅЕугыБпФЌШЯфжШОГіРДЕФаЇЙћЪЧКкЩЋ.
МгШыНкЕуКЭБп. НЋ GraphX ЫљЙЙНЈЭМЕФ VertexRDD КЭ EdgeRDD РяУцЕФФкШнМгШыЕН GraphStream ЕФЭМЖдЯѓжа:
// Given the
egoNetwork, load the graphX vertices
into GraphStream
for ((id,_) <- egoNetwork.vertices.collect())
{
val node = graph.addNode(id.toString).asInstanceOf
[SingleNode]
}
// Load the graphX edges into GraphStream edges
for (Edge(x,y,_) <- egoNetwork.edges.collect())
{
val edge = graph.addEdge
(x.toString ++ y.toString, x. toString, y.toString,true)
.asInstanceOf[AbstractEdge]
} |
МгШыЖЅЕуЪБ, жЛашвЊНЋЖЅЕуЕФ vertex ID зЊЛЛГЩзжЗћДЎДЋШыМДПЩ.
ЖдгкБп, ЩдЯдТщЗГ. addEdge ЕФ API ЮФЕЕдк етРя, ЮвУЧашвЊДЋШы 4 ИіВЮЪ§. ЕквЛИіВЮЪ§ЪЧУПЬѕБпЕФзжЗћДЎБъЪЖЗћ, гЩгкдк GraphX дгаЕФЭМжаВЂВЛДцдк, ЫљвдЮвУЧашвЊздМКДДНЈ. зюМђЕЅЕФЗНЪНЪЧНЋетЬѕБпЕФСНИіЖЫЕуЕФ vertex ID СЌНгЦ№РД.
зЂвт, дкЩЯУцЕФДњТыжа, ЮЊСЫБмУтЮвУЧЕФ scala ДњТыгы Java Пт GraphStream ЛЅгУЩЯЕФвЛаЉЮЪЬт, ВЩгУСЫаЁЕФММЧЩ. дк GraphStream ЕФ org.graphstream.graph.implementations.AbstractGraph API oЮФЕЕжа, addNode КЭ addEdge ЗжБ№ЗЕЛиЖЅЕуКЭБп. ЕЋЪЧгЩгк GraphStream ЪЧвЛИіЕкШ§ЗНЕФ Java Пт, ЮвУЧБиаыЧПжЦЪЙгУ asInstanceOf[T], Цфжа [T] ЮЊ SingleNode КЭ AbstractEdge, зїЮЊ addNode КЭ
addEdge ЕФЗЕЛиРраЭ. ШчЙћЮвУЧТЉЕєСЫетаЉЯдЪНЕФРраЭзЊЛЛ, ПЩФмЛсЕУЕНвЛИіЦцЙжЕФвьГЃ:
java.lang.ClassCastException:
org.graphstream.graph.implementations. SingleNode
cannot
be cast to scala.runtime.Nothing$ |
ЯдЪОЭМЯё
ЭъећЪОР§:
| object Visualization
{
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("GraphStreamDemo")
.set("spark.master", "local[*]")
val sc = new SparkContext(sparkConf)
val graph: SingleGraph = new SingleGraph ("graphDemo")
val vertices: RDD[(VertexId, String)] = sc.
parallelize(List(
(1L, "A"),
(2L, "B"),
(3L, "C"),
(4L, "D"),
(5L, "E"),
(6L, "F"),
(7L, "G")))
val edges: RDD[Edge[String]]=sc.parallelize(List(
Edge(1L, 2L, "1-2"),
Edge(1L, 3L, "1-3"),
Edge(2L, 4L, "2-4"),
Edge(3L, 5L, "3-5"),
Edge(3L, 6L, "3-6"),
Edge(5L, 7L, "5-7"),
Edge(6L, 7L, "6-7")))
val srcGraph = Graph(vertices, edges)
graph.setAttribute("ui.stylesheet",
"
url(file:/home/hadoop/style/stylesheet)")
graph.setAttribute("ui.quality")
graph.setAttribute("ui.antialias")
// load the graphx vertices into GraphStream
for ((id, _) <- srcGraph.vertices.collect()){
val node = graph.addNode(id.toString). as
InstanceOf [SingleNode]
}
// load the graphx edges into GraphStream edges
for (Edge(x, y, _) <- srcGraph.edges.collect()){
val edge = graph.addEdge
(x.toString ++ y.to String,
x.toString,
y.toString, true). asInstanceOf[AbstractEdge]
}
graph.display()
}
} |
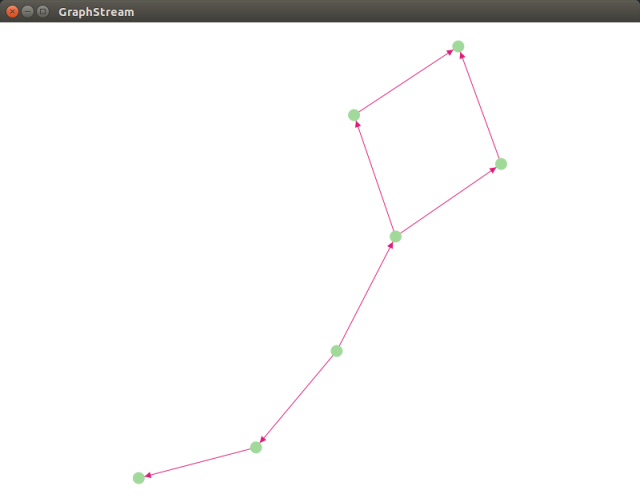
жСДЫ, вЛИіМђЕЅЕФЪОР§ЭъГЩ. ИќЖрЪЕгУЕФФкШнПЩздаабаОП.
ФПЧА, ШчЙћВЛЯћКФДѓСПЕФМЦЫузЪдД, ЖдгкДѓЙцФЃЕФЭјТчЭМЛцжЦШдШЛШБЗІвЛИігаСІЕФЙЄОп. РрЫЦЕФЙЄОпга:
snap: Лљгк GraphViz в§Чц.
Gephi: ЫќЪЧНЛЛЅЪНЕФПЩЪгЛЏЙЄОп, ОЁЙмЫќгааДЖрМЖВМОжКЭФкжУ 3D фжШОв§ЧцетбљЕФЬиЩЋ, ЕЋЪЧШдШЛгааЉИп CPU КЭФкДцЕФашЧѓ.
СэЭт, zeepelin вВПЩгы Spark МЏГЩ, ПЩздааСЫНт.
ЭМЕФЗжВМЪНЛђепВЂааДІРэЦфЪЕЪЧАбЭМВ№ЗжГЩКмЖрЕФзгЭМЃЌШЛКѓЗжБ№ЖдетаЉзгЭМНјааМЦЫуЃЌМЦЫуЕФЪБКђПЩвдЗжБ№ЕќДњНјааЗжНзЖЮЕФМЦЫуЃЌМДЖдЭМНјааВЂааМЦЫуЁЃЯТУцЮвУЧПДвЛЯТЭММЦЫуЕФМђЕЅЪОР§ЃК
|








