| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЛљгкELKЙЙНЈвЛИідЦЪБДњЪеМЏВЂЗжЮіlogЕФНтОіЗНАИЕФЯрЙиФкШнЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ
БОЮФРДздЮЂаХЙЋжкКХithellasЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂИХЪі
ЫцзХЯждкИїжжШэМўЯЕЭГЕФИДдгЖШдНРДдНИпЃЌЬиБ№ЪЧВПЪ№ЕНдЦЩЯжЎКѓЃЌдйЯыЕЧТМИїИіНкЕуЩЯВщПДИїИіФЃПщЕФlogЃЌЛљБОЪЧВЛПЩааСЫЁЃвђЮЊВЛНіаЇТЪЕЭЯТЃЌЖјЧвгаЪБгЩгкАВШЋадЃЌВЛПЩФмШУЙЄГЬЪІжБНгЗУЮЪИїИіЮяРэНкЕуЁЃЖјЧвЯждкДѓЙцФЃЕФШэМўЯЕЭГЛљБОЖМВЩгУМЏШКЕФВПЪ№ЗНЪНЃЌвтЮЖзХЖдУПИіserviceЃЌЛсЦєЖЏЖрИіЭъШЋвЛбљЕФPODЖдЭтЬсЙЉЗўЮёЃЌУПИіcontainerЖМЛсВњЩњздМКЕФlogЃЌНіДгВњЩњЕФlogРДПДЃЌФуИљБОВЛжЊЕРЪЧФФИіPODВњЩњЕФЃЌетбљЖдВщПДЗжВМЪНЕФШежОИќМгРЇФбЁЃ
ЫљвддкдЦЪБДњЃЌашвЊвЛИіЪеМЏВЂЗжЮіlogЕФНтОіЗНАИЁЃЪзЯШашвЊНЋЗжВМдкИїИіНЧТфЕФlogЪеМЏЕНвЛИіМЏжаЕФЕиЗНЃЌЗНБуВщПДЁЃЪеМЏСЫжЎКѓЃЌЛЙПЩвдНјааИїжжЭГМЦЗжЮіЃЌЩѕжСгУСїааЕФДѓЪ§ОнЛђmaching
learningЕФЗНЗЈНјааЗжЮіЁЃЕБШЛЃЌЖдгкДЋЭГЕФШэМўВПЪ№ЗНЪНЃЌвВашвЊетбљЕФlogЕФНтОіЗНАИЃЌВЛЙ§БОЮФжївЊДгдЦЕФНЧЖШРДНщЩмЁЃ
ELKОЭЪЧетбљЕФНтОіЗНАИЃЌЖјЧвЛљБООЭЪЧЪТЪЕЩЯЕФБъзМЁЃELKЪЧШ§ИіПЊдДЯюФПЕФЪззжФИЫѕаДЃЌШчЯТЃК
E: Elasticsearch
L: LogStash
K: Kibana
LogStashЕФжївЊзїгУЪЧЪеМЏЗжВМдкИїДІЕФlogВЂНјааДІРэЃЛElasticsearchдђЪЧвЛИіМЏжаДцДЂlogЕФЕиЗНЃЌИќживЊЕФЪЧЫќЪЧвЛИіШЋЮФМьЫївдМАЗжЮіЕФв§ЧцЃЌЫќФмШУгУЛЇвдНќКѕЪЕЪБЕФЗНЪНРДВщПДЁЂЗжЮіКЃСПЕФЪ§ОнЁЃKibanaдђЪЧЮЊElasticsearchПЊЗЂЕФЧАЖЫGUIЃЌШУгУЛЇПЩвдКмЗНБуЕФвдЭМаЮЛЏЕФНгПкВщбЏElasticsearchжаДцДЂЕФЪ§ОнЃЌЭЌЪБвВЬсЙЉСЫИїжжЗжЮіЕФФЃПщЃЌБШШчЙЙНЈdashboardЕФЙІФмЁЃ
ЮвИіШЫШЯЮЊНЋELKжаЕФLРэНтГЩLogging AgentИќКЯЪЪЁЃElasticsearchКЭKibanaЛљБООЭЪЧДцДЂЁЂМьЫїКЭЗжЮіlogЕФБъзМЗНАИЃЌЖјLogStashдђВЂВЛЪЧЮЈвЛЕФЪеМЏlogЕФЗНАИЃЌFluentdКЭFilebeatsвВФмгУгкЪеМЏlogЁЃЫљвдЯждкЭјЩЯгаELKЃЌEFKжЎРрЕФЫѕаДЁЃ
вЛАуВЩгУЕФМмЙЙШчЯТЭМЫљЪОЁЃЭЈГЃвЛИіаЁаЭЕФclusterгаШ§ИіНкЕуЃЌдкетШ§ИіНкЕуЩЯПЩФмЛсдЫааМИЪЎИіЩѕжСЩЯАйИіШнЦїЁЃЖјЮвУЧжЛашвЊдкУПИіНкЕуЩЯЦєЖЏвЛИіlogging
agentЕФЪЕР§ЃЈдкkubernetesжаОЭЪЧDaemonSetЕФИХФюЃЉМДПЩЁЃ

ЖўЁЂFilebeatsЁЂLogStashЁЂFluentdШ§епЕФЧјБ№КЭСЊЯЕ
етРягаБивЊЖдFilebeatsЁЂLogStashКЭFluentdШ§епжЎМфЕФСЊЯЕКЭЧјБ№зівЛИіМђвЊЕФЫЕУїЁЃFilebeatsЪЧвЛИіЧсСПМЖЕФЪеМЏБОЕиlogЪ§ОнЕФЗНАИЃЌЙйЗНЖдFilebeatsЕФЫЕУїШчЯТЁЃПЩвдПДГіFilebeatsЙІФмБШНЯЕЅвЛЃЌЫќНіНіжЛФмЪеМЏБОЕиЕФlogЃЌЕЋВЂВЛФмЖдЪеМЏЕНЕФLogзіЪВУДДІРэЃЌЫљвдЭЈГЃFilebeatsЭЈГЃашвЊНЋЪеМЏЕНЕФlogЗЂЫЭЕНLogstashзіНјвЛВНЕФДІРэЁЃ
Filebeat is a log data shipper for local files. Installed
as an agent on your servers, Filebeat monitors the
log directories or specific log files, tails the files,
and forwards them either to Elasticsearch or Logstash
for indexing
LogStashКЭFluentdЖМОпгаЪеМЏВЂДІРэlogЕФФмСІЃЌЭјЩЯгаКмЖрЙигкЖўепЕФЖдБШЃЌЬсЙЉвЛИіаДЕУБШНЯКУЕФЮФеТСДНгШчЯТЁЃЙІФмЩЯЖўепЦьЙФЯрЕБЃЌЕЋLogStashЯћКФИќЖрЕФmemoryЃЌЖдДЫLogStashЕФНтОіЗНАИЪЧЪЙгУFilebeatsДгИїИівЖзгНкЕуЩЯЪеМЏlogЃЌЕБШЛFluentdвВгаЖдгІЕФFluent
BitЁЃ
https://logz.io/blog/fluentd-logstash/
СэЭтвЛИіживЊЕФЧјБ№ЪЧFluentdГщЯѓадзіЕУИќКУЃЌЖдгУЛЇЦСБЮСЫЕзВуЯИНкЕФЗБЫіЁЃзїепЕФдЛАШчЯТЃК
FluentdЁЏs approach is more declarative whereas LogstashЁЏs
method is procedural. For programmers trained in procedural
programming, LogstashЁЏs configuration can be easier
to get started. On the other hand, FluentdЁЏs tag-based
routing allows complex routing to be expressed cleanly.
ЫфШЛзїепЫЕЪЧвЊжаСЂЕФЖдЖўепЃЈLogStashКЭFluentdЃЉНјааЖдБШЃЌЕЋЪЕМЪЩЯЦЋЯђадКмУїЯдСЫЃКЃЉЁЃБОЮФвВжївЊЛљгкFluentdНјааНщЩмЃЌВЛЙ§змЬхЫМТЗЖМЪЧЯрЭЈЕФЁЃ
ЖюЭтЫЕвЛЕуЃЌFilebeatsЁЂLogStashЁЂElasticsearchКЭKibanaЪЧЪєгкЭЌвЛМвЙЋЫОЕФПЊдДЯюФПЃЌЙйЗНЮФЕЕШчЯТЃК
https://www.elastic.co/guide/index.html
FluentdдђЪЧСэвЛМвЙЋЫОЕФПЊдДЯюФПЃЌЙйЗНЮФЕЕШчЯТЃК
https://docs.fluentd.org/v1.0/articles/quickstart
Ш§ЁЂlogging agent (Fluentd)
ЧАУцвбОЫЕЙ§ЃЌжЛвЊдкУПИіЮяРэНкЕуЩЯЦєЖЏвЛИіlogging agentЕФЪЕР§МДПЩЃЈБОЮФвдfluentdЮЊР§ЃЉЁЃЕЋЪЧдкУПИіНкЕуЩЯЃЌЭљЭљдЫаазХМИЪЎИіЩѕжСЩЯАйИіШнЦїЃЌЖјЧвЬсЙЉВЛЭЌЕФЗўЮёЃЌУПИіНкЕуЩЯЕФlogging
agentЛсЪеМЏЕНЕБЧАНкЕуЩЯЫљгаШнЦїЕФlogЁЃЖјгаЪБЮвУЧжЛЙиаФЦфжавЛВПЗжШнЦїВњЩњЕФlogЃЌгаЪБвВашвЊЖдЪеМЏЕФlogзівЛаЉМђЕЅЕФДІРэЃЌетЪБОЭашвЊЖдfluentdХфжУвЛаЉfilterЁЃШчЙћВЛашвЊзіШЮКЮЙ§ТЫЛђЦфЫќДІРэЃЌФЧfilebeatОЭФмТњзуашЧѓСЫЁЃ
FluentdвдpipelineЕФЗНЪНРДДІРэЪеМЏЕНЕФУПвЛЬѕlogЯћЯЂЃЌгЩИїжжpluginРДДІРэlogЁЃЕфаЭЕФДІРэТпМШчЯТЭМЫљЪОЃК
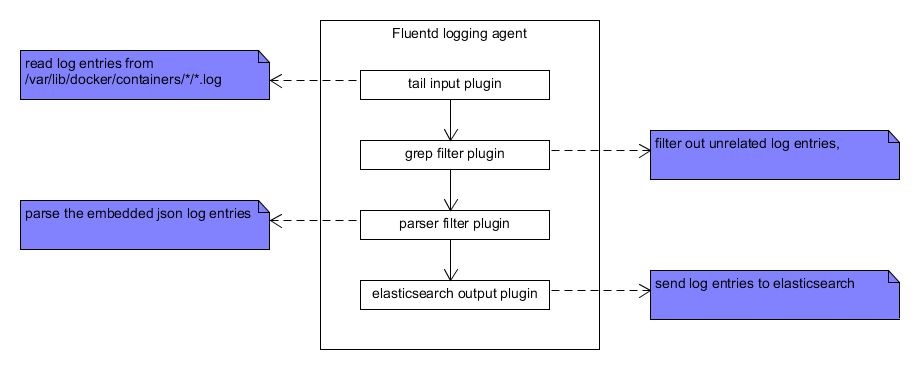
ЪзЯШЪЧinput pluginЪеМЏlogЃЌfluentdМШПЩвджБНгЖСШЁlogЮФМўжаЕФФкШнЃЌвВПЩвдНгЪмsocketДЋЙ§РДЕФlogЯћЯЂЁЃЙигкinput
pluginЕФОпЬхаХЯЂЃЌПЩвдВЮПМЯТУцЕФСДНгЃК
https://docs.fluentd.org/v1.0/articles/input-plugin-overview
Р§ШчЯТУцЕФР§згЪЧДг/var/lig/docker/container/*/*.logжаЖСШЁlogЯћЯЂЃЌжСгкЮЊЪВУДвЊДгетИіФПТМЖСШЁlogЃЌКѓУцЛсНтЪЭЁЃ
<source>
@type tail
path /var/lib/docker/containers/*/*.log
tag fluentd
<parse>
@type json
time_key time
keep_time_key true
</parse>
refresh_interval 5
</source> |
grep filterзїгУЪЧЙ§ТЫЕєЮвУЧВЛИааЫШЄЕФlogЯћЯЂЁЃетИіКмКУРэНтЃЌОЭКЭЮвУЧЦНЪБгУgrepУќСюЫбЫїЮФМўФкШнвЛбљЁЃЙигкgrep
filterЃЌВЮПМЯТУцЕФСДНгЃК
https://docs.fluentd.org/v1.0/articles/filter_grep
Р§ШчЯТУцЕФР§згОЭЪЧжЛгаЦЅХфФЃЪН"myproject.*hello"ЕФlogЯћЯЂВХЛсБЃСєЯТРДЃЌНјШыpipelineЕФЯТвЛИіЛЗНкМЬајДІРэЁЃ
<filter **>
@type grep
<regexp>
key log
pattern myproject.*hello
</regexp>
</filter> |
parser pluginдђЪЧИцЫпfluentdАДееЬиЖЈЕФИёЪННтЮіlogЯћЯЂЃЌОпЬхПЩВЮПМЯТУцЕФСДНгЃК
https://docs.fluentd.org/v1.0/articles/parser-plugin-overview
Р§ШчЯТУцЕФР§згОЭЪЧШУfluentdАДееjsonИёЪННтЮіФГИіfieldЕФФкШнЁЃетРяЯТЮФЛсНјвЛВННтЪЭЁЃ
<filter **>
@type parser
format json
key_name log
reserve_data true
hash_value_field log
</filter> |
зюКѓОЭЪЧЭЈЙ§output pluginНЋlogЪ§ОнЗЂЫЭГіШЅЃЌОпЬхВЮПМЃК
https://docs.fluentd.org/v1.0/articles/output-plugin-overview
ЯТУцЕФР§згОЭНЋДІРэжЎКѓЕФlogЗЂЫЭЕНelasticsearchЃЌ
<match fluentd>
@type elasticsearch
host elasticsearch
port 9200
flush_interval 10s
</match> |
ЫФЁЂDocker logging driver
ЬжТлloggingЃЌОЭЮоЗЈБмПЊDocker logging driverетИіЛАЬтЁЃЯждкВПЪ№дкдЦЩЯИїжжгІгУЖМЪЧдЫаадкШнЦїжаЕФЃЌЕБЮвУЧЕФгІгУНЋlogЯћЯЂЪфГіЕНstdoutЛђепstderrЕФЪБКђЃЌDocker
engineЪЧАДееХфжУЕФlogging driverРДНЋlogЯћЯЂЪфГіЕНЬиЖЈЕФФПЕФЕиЁЃDockerжЇГжЕФlogging
driverгаКмЖрЃЌФЌШЯЪЙгУЕФlogging driverЪЧjson-fileЃЌвВОЭЪЧЫЕНЋИїИігІгУЪфГіЕНstdoutЛђstderrЕФlogФЌШЯАДееjsonИёЪНЪфГіЕНЯТУцЕФЮФМўжаЃК
| /var/lib/docker/containers/${container_id}/*.log |
етОЭЪЧЮЊЪВУДЮЊfluentdХфжУЕФinput pluginвЊДг/var/lib/docker/containers/*/*.logЖСШЁlogЕФдвђЁЃ
СэЭтЃЌjson-fileЛсНЋгІгУГЬађВњЩњЕФУПЬѕlogЯћЯЂЃЌЗтзАЕНfield
"log"жаЁЃР§ШчМйЩшФГИіAPPЪфГіЯТУцЕФlogЕНstdoutЃЌ
| {"level":"info",
"msg":"hello world"} |
ЕФ
ФЧУДjson-fileЛсВњЩњЯТУцЕФlogЃЌ
| {"log":
"{\"level\":\"info\",
\"msg\":\"hello world\"}",
"stream":"stdout","time":"2018-01-27T02:38:16.382229755Z"} |
етОЭЪЧЮЊЪВУДЩЯУцвЊЮЊfluentdХфжУвЛИіparserЕФдвђЁЃ
ПЩвдБрМ/etc/docker/daemon.jsonРДаоИФФЌШЯЕФlogging
driverЃЌ
$cat /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size":
"10m"
}
} |
ПЩвдВЮПМЯТУцЕФСДНгЃЌРДСЫНтИќЖрЕФЙигкdocker logging driverЕФФкШнЃЌ
https://docs.docker.com/config /containers/logging/configure/
ЮхЁЂШчКЮжЇГжmulti-tenant
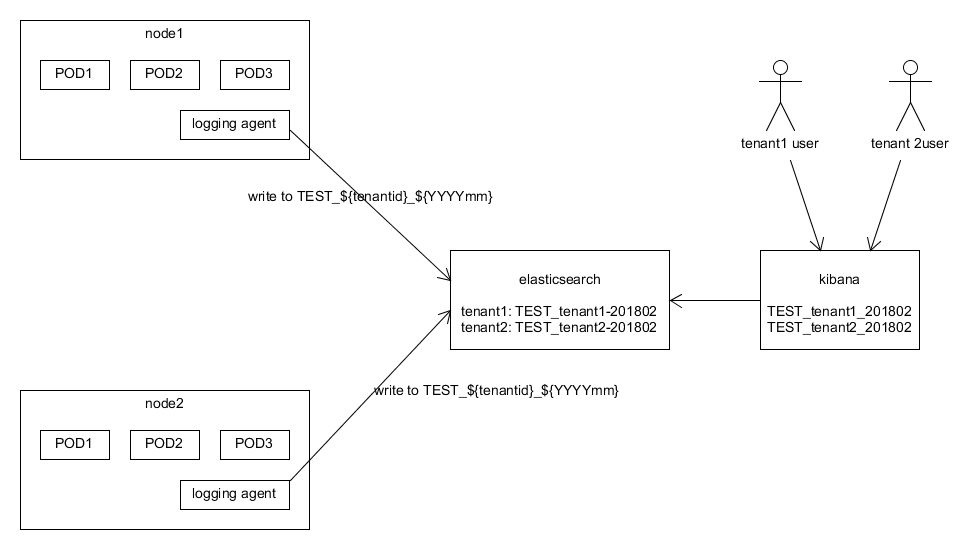
ВПЪ№дкclusterжаЕФгІгУвЛАуЖМЛсЖрИізтЛЇЬсЙЉЗўЮёЃЌФЧУДШчКЮЧјЗжВЛЭЌзтЛЇЕФЪ§ОнОЭЪЧВЛЕУВЛУцЖдЕФАВШЋЮЪЬтЁЃвВОЭЪЧЫЕУПИізтЛЇжЛФмПДЕНздМКЕФЪ§ОнЃЈздШЛАќКЌБОЮФЬжТлЕФlogЪ§ОнЃЉЁЃElasticsearchЖдетИіЮЪЬтЕФНЈвщЕФНтОіЗНАИОЭЪЧЮЊВЛЭЌЕФзтЛЇНЈСЂВЛЭЌЕФIndexЁЃ
IndexОЭЪЧвЛзщОпгаЯрЭЌЬиадЕФЮФЕЕЕФМЏКЯЁЃЙигкElasticsearchЕФЛљБОИХФюЃЌЧыВЮПМЯТУцЕФСДНгЃК
https://www.elastic.co/guide/en /elasticsearch/reference/current/_basic_concepts.html
ЪзЯШашвЊИФаДЩЯУцЮЊfluentdХфжУЕФoutput pluginЃЌЪЙfluentdПЩвджЧФмЕиНЋВЛЭЌtenantЕФlogЯћЯЂЗЂЫЭЕНelasticsearchжаВЛЭЌЕФindexЁЃЮвУЧжЛвЊдкУПЬѕlogЯћЯЂжаМгШыtenantidЕФжЕЃЌoutput
pluginНтЮіГіИУжЕКѓЃЌОЭПЩвдКмШнвзЕФЗжБ№ВЛЭЌtenantЕФЪ§ОнЁЃЁЁ
KibanaздДгАцБО6.0жЎКѓЃЌKibanaЭЈЙ§X-PackЬсЙЉСЫЛљгкНЧЩЋЕФЗУЮЪПижЦЃЈRole-based
Access ControlЃЉЃЌОЭЪЧПЩвдИјВЛЭЌЕФгУЛЇЗжХфВЛЭЌЕФНЧЩЋЃЌЖјеыЖдВЛЭЌЕФНЧЩЋИГгшЗУЮЪВЛЭЌIndexЕФШЈЯоЁЃетбљОЭПижЦСЫУПИізтЛЇЕЧТМКѓжЛФмЗУЮЪЪєгкздМКЕФIndexжаЕФЪ§ОнЁЃ
НЋБОЮФПЊЪМЕФМмЙЙЭМеыЖдmulti-tenantПЩвдзіШчЯТаоИФЃЌ
СљЁЂЪ§ОнЗжЮі
ЖдгкЪеМЏЩЯРДЕФlogЪ§ОнЃЌПЩвдДгЯТУцШ§ИіЗНУцНјааЗжЮіЃК
ЃБЁЂKibanaЬсЙЉСЫвЛИіНЛЛЅЪНЕФВщбЏНгПкЃЌПЩвдНќКѕЪЕЪБЕФВщбЏЮвУЧИааЫШЄЕФlogЪ§ОнЁЃ
ЃВЁЂНшжњKibanaЕФvisualizationКЭdashboardПЩвдКмЗНБуЕиЖдlogЪ§ОнНјааПЩЪгЛЏеЙЯжЁЃ
ЃГЁЂРћгУX-PackЬсЙЉЕФMaching learningНјааДѓЪ§ОнЗжЮіЁЃ
етРяднЪБВЛЩюШыеЙПЊЬжТлЃЌНЋРДПЩФмЛсЗжЯэИќЖрЯрЙиЕФаФЕУКЭЬхЛсЁЃ |






