| БрМЭЦМі: |
БОЮФНВЪіДЋЭГЯЕЭГЕФЮЪЬтЃЌLambdaМмЙЙЕФБГОАЃЌДѓЪ§ОнЯЕЭГЕФЙиМќЬиадЃЌЪ§ОнЯЕЭГЕФБОжЪЕШ
ЯЃЭћЖдФњгаЫљАяжњ
БОЮФРДздгкЮЂаХКХАЂРядЦдЦЦмКХЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
ДЋЭГЯЕЭГЕФЮЪЬт
ЁАЮвУЧе§дкДгITЪБДњзпЯђDTЪБДњ(Ъ§ОнЪБДњ)ЁЃITКЭDTжЎМфЃЌВЛНіНіЪЧММЪѕЕФБфИяЃЌИќЪЧЫМЯывтЪЖЕФБфИяЃЌITжївЊЪЧЮЊздЮвЗўЮёЃЌгУРДИќКУЕиздЮвПижЦКЭЙмРэЃЌDTдђЪЧМЄЛюЩњВњСІЃЌШУБ№ШЫЛюЕУБШФуКУЁБЁЊЁЊАЂРяАЭАЭЖЪТОжжїЯЏТэдЦЁЃ
Ъ§ОнСПДгMЕФМЖБ№ЕНGЕФМЖБ№ЕНЯждкTЕФМЖЁЂPЕФМЖБ№ЁЃЪ§ОнСПЕФБфЛЏЃЌЪ§ОнЙмРэЯЕЭГЃЈDBMSЃЉКЭЪ§ВжЯЕЭГЃЈDWЃЉвВдкЧФШЛЕФБфЛЏзХЁЃ
ДЋЭГгІгУЕФЪ§ОнЯЕЭГМмЙЙЩшМЦЪБЃЌгІгУжБНгЗУЮЪЪ§ОнПтЯЕЭГЁЃЕБгУЛЇЗУЮЪСПдіМгЪБЃЌЪ§ОнПтЮоЗЈжЇГХШевцдіГЄЕФгУЛЇЧыЧѓЕФИКдиЪБЃЌДгЖјЕМжТЪ§ОнПтЗўЮёЦїЮоЗЈМАЪБЯьгІгУЛЇЧыЧѓЃЌГіЯжГЌЪБЕФДэЮѓЁЃГіЯжетжжЧщПівдКѓЃЌдкЯЕЭГМмЙЙЩЯОЭВЩгУЭМЃЈAЃЉЕФМмЙЙЃЌдкЪ§ОнПтКЭгІгУжаМфЙ§вЛВуЛКГхИєРыЃЌЛКНтЪ§ОнПтЕФЖСаДбЙСІЁЃШЛЖјЃЌЕБгУЛЇЗУЮЪСПГжајдіМгЪБЃЌОЭашвЊПМТЧЖСаДЗжРыММЪѕЃЈMasterЃSlaveЃЉМмЙЙШчЭМЃЈBЃЉЃЌЗжПтЗжБэММЪѕЁЃЯждкЃЌМмЙЙБфЕУдНРДдНИДдгСЫЃЌдіМгЖгСаЁЂЗжЧјЁЂИДжЦЕШДІРэТпМЁЃгІгУГЬађашвЊСЫНтЪ§ОнПтЕФschemaЃЌВХФмЗУЮЪЕНе§ШЗЕФЪ§ОнЁЃ
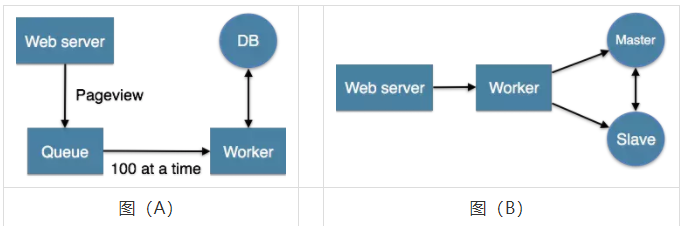
LambdaМмЙЙЕФБГОА
ДѓЪ§ОнДІРэММЪѕашвЊНтОіетжжПЩЩьЫѕадгыИДдгадЁЃ
ЪзЯШвЊШЯЪЖЕНетжжЗжВМЪНЕФБОжЪЃЌвЊКмКУЕиДІРэЗжЧјгыИДжЦЃЌВЛЛсЕМжТДэЮѓЗжЧјв§Ц№ВщбЏЪЇАмЃЌЖјЪЧвЊНЋетаЉТпМФкЛЏЕНЪ§ОнПтжаЁЃЕБашвЊРЉеЙЯЕЭГЪБЃЌПЩвдЗЧГЃЗНБуЕидіМгНкЕуЃЌЯЕЭГвВФмЙЛеыЖдаТНкЕуНјааrebalanceЁЃ
ЦфДЮЪЧвЊШУЪ§ОнГЩЮЊВЛПЩБфЕФЁЃдЪМЪ§ОнгРдЖЖМВЛФмБЛаоИФЃЌетбљМДЪЙЗИСЫДэЮѓЃЌаДСЫДэЮѓЪ§ОнЃЌдРДКУЕФЪ§ОнВЂВЛЛсЪмЕНЦЦЛЕЁЃ
StormЕФзїепNathan MarzЬсГіЕФвЛИіЪЕЪБДѓЪ§ОнДІРэПђМмЃЈLambdaМмЙЙЃЉОЭТњзувдЩЯСНЕуЁЃMarzдкTwitterЙЄзїЦкМфПЊЗЂСЫжјУћЕФЪЕЪБДѓЪ§ОнДІРэПђМмStormЃЌLambdaМмЙЙЪЧЦфИљОнЖрФъНјааЗжВМЪНДѓЪ§ОнЯЕЭГЕФОбщзмНсЬсСЖЖјГЩЁЃ
LambdaМмЙЙЕФФПБъЪЧЩшМЦГівЛИіФмТњзуЪЕЪБДѓЪ§ОнЯЕЭГЙиМќЬиадЕФМмЙЙЃЌАќРЈгаЃКИпШнДэЁЂЕЭбгЪБКЭПЩРЉеЙЕШЁЃLambdaМмЙЙећКЯРыЯпМЦЫуКЭЪЕЪБМЦЫуЃЌШкКЯВЛПЩБфадЃЈImmunabilityЃЉЃЌЖСаДЗжРыКЭИДдгадИєРыЕШвЛЯЕСаМмЙЙддђЃЌПЩМЏГЩHadoopЃЌKafkaЃЌStormЃЌSparkЃЌHbaseЕШИїРрДѓЪ§ОнзщМўЁЃ
ДѓЪ§ОнЯЕЭГЕФЙиМќЬиад
MarzНщЩмBig Data SystemаэОпБИЕФЪєадЃК
aЁЂRobust and fault-tolerantЃЈШнДэадКЭТГАєадЃЉЃКЖдДѓЙцФЃЗжВМЪНЯЕЭГРДЫЕЃЌЛњЦїЪЧВЛПЩППЕФЃЌПЩФмЛсЕБЛњЃЌЕЋЪЧЯЕЭГашвЊЪЧНЁзГЁЂааЮЊе§ШЗЕФЃЌМДЪЙЪЧгіЕНЛњЦїДэЮѓЁЃГ§СЫЛњЦїДэЮѓЃЌШЫИќПЩФмЛсЗИДэЮѓЁЃдкШэМўПЊЗЂжаФбУтЛсгавЛаЉBugЃЌЯЕЭГБиаыЖдгаBugЕФГЬађаДШыЕФДэЮѓЪ§ОнгазуЙЛЕФЪЪгІФмСІЃЌЫљвдБШЛњЦїШнДэадИќМгживЊЕФШнДэадЪЧШЫЮЊВйзїШнДэадЁЃЖдгкДѓЙцФЃЕФЗжВМЪНЯЕЭГРДЫЕЃЌШЫКЭЛњЦїЕФДэЮѓУПЬьЖМПЩФмЛсЗЂЩњЃЌШчКЮгІЖдШЫКЭЛњЦїЕФДэЮѓЃЌШУЯЕЭГФмЙЛДгДэЮѓжаПьЫйЛжИДгШЦфживЊЁЃ
bЁЂLow latency reads and updatesЃЈЕЭбгЪБЃЉЃККмЖргІгУЖдгкЖСКЭаДВйзїЕФбгЪБвЊЧѓЗЧГЃИпЃЌвЊЧѓЖдИќаТКЭВщбЏЕФЯьгІЪЧЕЭбгЪБЕФЁЃ
cЁЂScalableЃЈКсЯђРЉШнЃЉЃКЕБЪ§ОнСП/ИКдидіДѓЪБЃЌПЩРЉеЙадЕФЯЕЭГЭЈЙ§діМгИќЖрЕФЛњЦїзЪдДРДЮЌГжадФмЁЃвВОЭЪЧГЃЫЕЕФЯЕЭГашвЊЯпадПЩРЉеЙЃЌЭЈГЃВЩгУscale outЃЈЭЈЙ§діМгЛњЦїЕФИіЪ§ЃЉЖјВЛЪЧscale upЃЈЭЈЙ§діЧПЛњЦїЕФадФмЃЉЁЃ
dЁЂGeneralЃЈЭЈгУадЃЉЃКЯЕЭГашвЊФмЙЛЪЪгІЙуЗКЕФгІгУЃЌАќРЈН№ШкСьгђЁЂЩчНЛЭјТчЁЂЕчзгЩЬЮёЪ§ОнЗжЮіЕШЁЃ
eЁЂExtensibleЃЈПЩРЉеЙЃЉЃКашвЊдіМгаТЙІФмЁЂаТЬиадЪБЃЌПЩРЉеЙЕФЯЕЭГФмвдзюаЁЕФПЊЗЂДњМлРДдіМгаТЙІФмЁЃ
fЁЂAllows ad hoc queriesЃЈЗНБуВщбЏЃЉЃКЪ§ОнжадЬКЌгаМлжЕЃЌашвЊФмЙЛЗНБуЁЂПьЫйЕФВщбЏГіЫљашвЊЕФЪ§ОнЁЃ
dЁЂMinimal maintenanceЃЈвзгкЮЌЛЄЃЉЃКЯЕЭГвЊЯызіЕНвзгкЮЌЛЄЃЌЦфЙиМќЪЧПижЦЦфИДдгадЃЌдНЪЧИДдгЕФЯЕЭГдНШнвзГіДэЁЂдНФбЮЌЛЄЁЃ
hЁЂDebuggableЃЈвзЕїЪдЃЉЃКЕБГіЮЪЬтЪБЃЌЯЕЭГашвЊгазуЙЛЕФаХЯЂРДЕїЪдДэЮѓЃЌевЕНЮЪЬтЕФИљдДЁЃЦфЙиМќЪЧФмЙЛзЗИљЫндДЕНУПИіЪ§ОнЩњГЩЕуЁЃ
Ъ§ОнЯЕЭГЕФБОжЪ
MarzШЯЮЊЃКЪ§ОнЯЕЭГЭЈЙ§ВщбЏЙ§ШЅЕФЃЈВПЗжЁЂШЋВПЃЉЪ§ОнШЅЛиД№ЮЪЬтЁЃШчЃКЫћЪЧвЛИіЪВУДбљЕФШЫЃПЫћгаЖрЩйХѓгбЃПетИіеЫКХЪЧЗёЪежЇЦНКтЃПЁЃвђДЫЃЌData SystemЕФЭЈгУЖЈвхЮЊЃК
Query ЃН FunctionЃЈall dataЃЉЁЃ
ЖдЭЈгУЕФБэДяЪННјааЗжНтЕУЕНЃК
Ъ§ОнЯЕЭГ ЃН Ъ§Он ЃЋ ВщбЏ
ДгЖјПЩвдДгЪ§ОнКЭВщбЏСНИіЗНУцШЯЪЖДѓЪ§ОнЯЕЭГЕФБОжЪЁЃ
Ъ§ОнБОБОжЪЃКWhenКЭWhat
Ъ§ОнЪЧвЛИіВЛПЩЗжИюЕФЕЅдЊЃЌЪ§ОнгаСНИіЙиМќЕФЬиадЃКWhen КЭ WhatЁЃ
WhenЪЧжЛЪ§ОнЪЧгыЪБМфЯрЙиЕФЃЌвВОЭЪЧЪ§ОнЪЧдкФГИіЪБМфВњЩњЕФЁЃетИіЗЧГЃживЊЃЌдкОпгаЪТЮёЬиадЕФЪ§ОнПтжаЃЌВйзїЕФЯШКѓЫГађЖдНсЙћжСЙиживЊЁЃР§ШчЪ§ОнПтЕФBinlogШежОЁЃвђДЫЃЌЪ§ОнЕФЪБМфаджЪОіЖЈСЫЪ§ОнЕФШЋОжЗЂЩњЯШКѓЃЌвВОЭОіЖЈСЫЪ§ОнЕФНсЙћЁЃ
WhatЪЧжЛЪ§ОнЕФБОЩэЁЃгЩгкЪ§ОнИњФГИіЪБМфЕуЯрЙиЃЌЫљвдЪ§ОнЕФБОЩэЪЧВЛПЩБфЕФ(immutable)ЃЌЙ§ЭљЕФЪ§ОнвбОГЩЮЊЪТЪЕЃЈFactЃЉЃЌФуВЛПЩФмЛиЕНЙ§ШЅЕФФГИіЪБМфЕуШЅИФБфЪ§ОнЪТЪЕЁЃетвВОЭвтЮЖзХЖдЪ§ОнЕФВйзїЦфЪЕжЛгаСНжжЃКЖСШЁвбДцдкЕФЪ§ОнКЭЬэМгИќЖрЕФаТЪ§ОнЁЃВЩгУЪ§ОнПтЕФМЧЗЈЃЌCRUDОЭБфГЩСЫCRЃЌUpdateКЭDeleteБОжЪЩЯЦфЪЕЪЧаТВњЩњЕФЪ§ОнаХЯЂЃЌгУCРДМЧТМЁЃ
Ъ§ОнЕФДцДЂ
Store Everything Rawly and Immutably
ИљОнЩЯЪіЖдЪ§ОнЬиадЕФЗжЮіЃЌlambdaМмЙЙжаЖдЪ§ОнЕФДцДЂВЩгУЕФЗНЪНЪЧЃКЪ§ОнВЛПЩБфЃЌДцДЂЫљгаЪ§ОнЁЃ
ВЩгУетСНжжЗНЪНДцДЂЕФКУДІЃК
aЁЂМђЕЅЁЃВЩгУВЛПЩБфЕФЪ§ОнФЃаЭЃЌДцДЂЪ§ОнЪБжЛашвЊМђЕЅЕФЭљжїЪ§ОнМЏКѓзЗМгЪ§ОнМДПЩЁЃЯрБШгкВЩгУПЩБфЕФЪ§ОнФЃаЭЃЌЮЊСЫUpdateВйзїЃЌЪ§ОнЭЈГЃашвЊБЛЫїв§ЃЌДгЖјФмПьЫйевЕНвЊИќаТЕФЪ§ОнШЅзіИќаТВйзїЁЃ
bЁЂгІЖдШЫЮЊКЭЛњЦїЕФДэЮѓЁЃШЫКЭЛњЦїУПЬьЖМПЩФмЛсГіДэЃЌШчКЮгІЖдШЫКЭЛњЦїЕФДэЮѓЃЌШУЪ§ОнЯЕЭГПьЫйЛжИДМЋЦфживЊЁЃВЛПЩБфКЭПЩжиИДМЦЫуЪЧгІЖдШЯЮЊКЭЛњЦїДэЮѓЕФГЃгУЗНЗЈЁЃВЩгУПЩБфЪ§ОнФЃаЭЃЌв§ЗЂДэЮѓЕФЪ§ОнгаПЩФмБЛИВИЧЖјЖЊЪЇЁЃ
ЯрБШгкВЩгУВЛПЩБфЕФЪ§ОнФЃаЭЃЌвђЮЊЫљгаЕФЪ§ОнЖМдкЃЌв§ЗЂДэЮѓЕФЪ§ОнвВдкЁЃ
аоИДЕФЗНЗЈОЭПЩвдМђЕЅЕФЪЧБщРњЪ§ОнМЏЩЯДцДЂЕФЫљгаЕФЪ§ОнЃЌЖЊЦњДэЮѓЕФЪ§ОнЃЌжиаТМЦЫуЕУЕНViewsЁЃжиаТМЦЫуЕФЙиМќЕудкгкРћгУЪ§ОнЕФЪБМфЬиадОіЖЈЕФШЋОжДЮађЃЌвРДЮЫГађжиаТжДааЃЌБиШЛФмЕУЕНе§ШЗЕФНсЙћЁЃ
ЕБЧАвЕНчгаКмЖрВЩгУВЛПЩБфЪ§ОнФЃаЭРДДцДЂЫљгаЪ§ОнЕФР§згЁЃБШШчЗжВМЪНЪ§ОнПтDatomicЃЌЛљгкВЛПЩБфЪ§ОнФЃаЭРДДцДЂЪ§ОнЃЌДгЖјМђЛЏСЫЩшМЦЁЃЗжВМЪНЯћЯЂжаМфМўKafkaЃЌЛљгкLogШежОЃЌвдзЗМгappend-onlyЕФЗНЪНРДДцДЂЯћЯЂЁЃ
LambdaМмЙЙ
LambdaМмЙЙЕФжївЊЫМЯыЪЧНЋДѓЪ§ОнЯЕЭГМмЙЙЮЊЖрВуИіВуДЮЃЌЗжБ№ЮЊХњДІРэВуЃЈbatch layerЃЉЁЂЪЕЪБДІРэВуЃЈspeed layerЃЉЁЂЗўЮёВуЃЈserving layerЃЉШчЭМЃЈCЃЉЁЃ
РэЯызДЬЌЯТЃЌШЮКЮЪ§ОнЗУЮЪЖМПЩвдДгБэДяЪНQuery = function(all data)ПЊЪМЃЌЕЋЪЧЃЌШєЪ§ОнДяЕНЯрЕБДѓЕФвЛИіМЖБ№ЃЈР§ШчPBЃЉЃЌЧвЛЙашвЊжЇГжЪЕЪБВщбЏЪБЃЌОЭашвЊКФЗбЗЧГЃХгДѓЕФзЪдДЁЃвЛИіНтОіЗНЪНЪЧдЄдЫЫуВщбЏКЏЪ§ЃЈprecomputed query funcitonЃЉЁЃЪщжаНЋетжждЄдЫЫуВщбЏКЏЪ§ГЦжЎЮЊBatch ViewЃЈAЃЉЃЌетбљЕБашвЊжДааВщбЏЪБЃЌПЩвдДгBatch ViewжаЖСШЁНсЙћЁЃетбљвЛИідЄЯШдЫЫуКУЕФViewЪЧПЩвдНЈСЂЫїв§ЕФЃЌвђЖјПЩвджЇГжЫцЛњЖСШЁЃЈBЃЉЁЃгкЪЧЯЕЭГОЭБфГЩЃК
ЃЈAЃЉbatch view = function(all data)ЃЛ
ЃЈBЃЉquery = function(batch view)ЁЃ

Batch Layer
дкLambdaМмЙЙжаЃЌЪЕЯжЃЈAЃЉbatch view = function(all data)ЕФВПЗжГЦжЎЮЊBatch LayerЁЃЫћГаЕЃСНИіжАд№ЃК
aЁЂДцДЂMaster DatasetЃЌетЪЧвЛИіВЛБфЕФГжајдіГЄЕФЪ§ОнМЏ
bЁЂеыЖдетИіMaster DatasetНјаадЄдЫЫу
дкШЋЬхЪ§ОнМЏЩЯдкЯпдЫааВщбЏКЏЪ§ЕУЕННсЙћЕФДњМлЬЋДѓЃЌЭЌЪБДІРэВщбЏЪБМфЙ§ГЄЃЌЕМжТгУЛЇЬхбщВЛКУЁЃШчЙћЮвУЧдЄЯШдкЪ§ОнМЏЩЯМЦЫуВЂБЃДцдЄМЦЫуЕФНсЙћЃЌВщбЏЕФЪБКђжБНгЗЕЛидЄМЦЫуЕФНсЙћЃЌЖјЮоашжиаТНјааИДжЦКФЪБЕФМЦЫуЁЃЯдШЛЃЌbatch view ЪЧвЛИіХњДІРэЙ§ГЬЃЌШчВЩгУHadoopЛђsparkжЇГжЕФmapЃreduceЗНЪНЁЃВЩгУетжжЗНЪНМЦЫуЕУЕНЕФУПИіviewЖМжЇГждйДЮМЦЫуЃЌЧвУПДЮМЦЫуЕФНсЙћЖМЯрЭЌЁЃ

ЖдViewЕФРэНтЃК
ViewЪЧвЛИіКЭвЕЮёЙиСЊадБШНЯДѓЕФИХФюЃЌViewЕФДДНЈашвЊДгвЕЮёздЩэЕФашЧѓГіЗЂЁЃвЛИіЭЈгУЕФЪ§ОнПтВщбЏЯЕЭГЃЌВщбЏЖдгІЕФКЏЪ§ЧЇБфЭђЛЏЃЌВЛПЩФмЧюОйЁЃЕЋЪЧШчЙћДгвЕЮёздЩэЕФашЧѓГіЗЂЃЌПЩвдЗЂЯжвЕЮёЫљашвЊЕФВщбЏГЃГЃЪЧгаЯоЕФЁЃ
Batch LayerашвЊзіЕФвЛМўживЊЕФЙЄзїОЭЪЧИљОнвЕЮёЕФашЧѓЃЌПМВьПЩФмашвЊЕФИїжжВщбЏЃЌИљОнВщбЏЖЈвхЦфдкЪ§ОнМЏЩЯЖдгІЕФViewsЁЃ
Batch LayerЕФImmutable dataФЃаЭКЭViews
ШчЭМЃЈEЃЉзјЯЏЃЈagentidЃН50023ЃЉЕФШЫЃЌдк10:00:06ЗжЕФЪБКђЃЌзДЬЌЪЧcallingЃЌдк10:00:10ЕФЪБКђзДЬЌЮЊwaitingЁЃдкДЋЭГЕФЪ§ОнПтЩшМЦжаЃЌжБНгКѓУцЕФМЭТМИВИЧЧАУцЕФМЭТМЃЌЖјдкImmutable Ъ§ОнФЃаЭжаЃЌВЛЛсЖддгаЪ§ОнНјааИќИФЃЌЖјЪЧВЩгУВхШыаоИФМЭТМЕФаЮЪНИќИФРњЪЗМЭТМЁЃ

ЭМЃЈEЃЉ
ЩЯЮФЫљЬсМАЕФViewЪЧЭМЃЈEЃЉжадЄЯШМЦЫуЕУЕНЕФЯрЙиЪгЭМЃЌР§ШчЃК2016-06-21ЕБЬьЫљгаЩЯЯпЕФagentЪ§ЃЌУПЬѕШШЯпЁЂЙЋЫОЯТЩЯЯпЕФAgentЪ§ЁЃИљОнвЕЮёашвЊЃЌдЄЯШМЦЫуГіНсЙћЁЃДЫЙ§ГЬЯрЕБгкДЋЭГЪ§ВжНЈФЃЕФгІгУВуЃЌгІгУВувВЪЧИљОнвЕЮёГЁОАЃЌдЄЯШМгЙЄГіЕФviewЁЃ
Speed Layer
Batch LayerФмЙЛКмКУЕФДІРэРыЯпЪ§ОнЃЌЕЋЪЧдкКмЖрГЁОАЪ§ОнВЛЖЯВњЩњЃЌВЂЧввЕЮёГЁОАашвЊЪЕЪБВщбЏЁЃSpeed LayerОЭЪЧЩшМЦгУРДДІРэдіСПЪЕЪБЪ§ОнЁЃ
Speed LayerКЭBatch LayerБШНЯРрЫЦЃЌЖдЪ§ОнНјааМЦЫуВЂЩњГЩRealtime ViewЃЌЦфжївЊЕФЧјБ№дкгкЃК
aЁЂSpeed LayerДІРэЕФЪ§ОнЪЧзюНќЕФдіСПЪ§ОнСїЃЌBatch LayerДІРэЕФЪЧШЋЬхЪ§ОнМЏЁЃ
bЁЂSpeed LayerЮЊСЫаЇТЪЃЌНгЪеЕНаТЪ§ОнМАЪБИќаТRealtime ViewЃЌЖјBatch LayerИљОнШЋЬхРыЯпЪ§ОнжБНгЕУЕНBatch ViewЁЃSpeed LayerЪЧвЛжждіСПМЦЫуЃЌЖјЗЧжиаТМЦЫуЃЈrecomputationЃЉЁЃ
cЁЂSpeed LayerвђЮЊВЩгУдіСПМЦЫуЃЌЫљвдбгГйаЁЃЌЖјBatch LayerЪЧШЋЪ§ОнМЏЕФМЦЫуЃЌКФЪББШНЯГЄЁЃ
злЩЯЫљЫпЃЌSpeed LayerЪЧBatch LayerдкЪЕЪБадЩЯЕФвЛИіВЙГфЁЃШчЭМЃЈFЃЉ

ЭМЃЈFЃЉ
Speed LayerПЩзмНсЮЊвдЃЈCЃЉ
Realtime View ЃН functionЃЈRealtime ViewЃЌ new dataЃЉЃЛ
Lambda ArchitectureНЋЪ§ОнДІРэЗжНтЮЊBatch Layer КЭSpeed LayerгаШчЯТгХЕуЃК
aЁЂШнДэадЃКSpeed LayerжаДІРэЕФЪ§ОнВЛЖЯаДШыBatch LayerЃЌЕБBatch LayerжажиаТМЦЫуЪ§ОнМЏАќКЌSpeed LayerДІРэЕФЪ§ОнМЏКѓЃЌЕБЧАЕФRealtime ViewОЭПЩвдЖЊЦњЃЌетОЭвтЮЖзХSpeed LayerДІРэжав§ШыЕФДэЮѓЃЌдкBatch LayerжиаТМЦЫуЪБЖМПЩвдЕУЕНаожЄЁЃетЕувВПЩвдПДГЩЪБCAPРэТлжаЕФзюжевЛжТадЃЈEventual ConsistencyЃЉЕФЬхЯжЁЃ
bЁЂИДдгадИєРыЁЃBatch LayerДІРэЕФЪЧРыЯпЪ§ОнЃЌПЩвдКмКУЕФеЦПиЁЃSpeed LayerВЩгУдіСПЫуЗЈДІРэЪЕЪБЪ§ОнЃЌИДдгадБШBatch LayerвЊИпКмЖрЁЃЭЈЙ§ЗжПЊBatch LayerКЭSpeed LayerЃЌАбИДдгадИєРыЕНSpeed LayerЃЌПЩвдКмКУЕФЬсИпећИіЯЕЭГЕФТГАєадКЭПЩППадЁЃ
Serving Layer
Batch LayerЭЈЙ§ЖдMaster DatasetжДааВщбЏЛёЕУBatch ViewЃЌSpeed LayerЭЈЙ§діСПМЦЫуЬсЙЉRealtime ViewЁЃLambdaМмЙЙЕФServingLayerгУгкЯьгІгУЛЇЕФВщбЏЧыЧѓЃЌКЯВЂBatch ViewКЭRealtime ViewжаЕФНсЙћЪ§ОнМЏЕНзюжеЕФЪ§ОнМЏЃЌШчЭМЃЈGЃЉЁЃвђДЫЃЌServing LayerЕФжАд№АќКЌЃК
aЁЂЖдbatch ViewКЭRealTime ViewЕФЫцЛњЗУЮЪ
bЁЂИќаТBatch VeiwКЭRealTime ViewЃЌВЂИКд№НсКЯСНепЕФЪ§ОнЃЌЖдгУЛЇЬсЙЉЭГвЛЕФНгПк

ЭМЃЈGЃЉ
злЩЯЫљЫпЃЌServing LayerВЩгУШчЯТЕШЪНЃЈDЃЉБэЪОЃК
Query ЃН functionЃЈBatch ViewsЃЌ Realtime ViewЃЉЁЃ
Lambda МмЙЙзщМўбЁаЭ
ЯТЭМИјГіСЫLambdaМмЙЙжаИїзщМўдкДѓЪ§ОнЩњЬЌЯЕЭГжаКЭАЂРяМЏЭХЕФГЃгУзщМўЁЃ
Ъ§ОнСїДцДЂбЁгУВЛПЩБфШежОЕФЗжВМЪНЯЕЭГKafaЁЂTTЁЂMetaqЃЛBatch LayerЪ§ОнМЏЕФДцДЂбЁгУHadoopЕФHDFSЛђепАЂРядЦЕФODPSЃЛBatch ViewЕФМгЙЄВЩгУMapReduceЃЛBatch ViewЪ§ОнЕФДцДЂВЩгУMysqlЃЈВщбЏЩйСПЕФзюНќНсЙћЪ§ОнЃЉЁЂHbaseЃЈВщбЏДѓСПЕФРњЪЗНсЙћЪ§ОнЃЉЁЃSpeed LayerВЩгУдіСПЪ§ОнДІРэStormЁЂFlinkЃЛRealtime ViewдіСПНсЙћЪ§ОнМЏВЩгУФкДцЪ§ОнПтRedisЁЃ

ЭМЃЈHЃЉ
LambdaЪЧвЛИіЭЈгУПђМмЃЌИїФЃПщбЁаЭВЛвЊОжЯогкЩЯУцИјГіЕФзщМўЃЌЬиБ№ЪЧviewЕФбЁаЭЁЃвђЮЊViewЪЧКЭИївЕЮёЙиСЊЗЧГЃДѓЕФИХФюЃЌViewбЁдёзщМўЪБвЊИљОнвЕЮёЕФашЧѓЃЌбЁдёзюКЯЪЪЕФзщМўЁЃ
LambdaМмЙЙЕФЦРЙР
гХЕуЃК
aЁЂЪ§ОнЕФВЛПЩБфадЁЃРяУцИјГіЕФЪ§ОнДЋЪфФЃаЭЪЧдкГѕЪМЛЏНзЖЮЖдЪ§ОнНјааЪЕР§ЛЏЃЌетбљЕФзіЗЈЪЧФмЛёвцСМЖрЕФЁЃФмЙЛЪЙЕУДѓСПЕФMapReduceЙЄзїБфЕУгаМЃПЩбЃЌДгЖјБугкдкВЛЭЌНзЖЮНјааЖРСЂЕїЪдЁЃ
bЁЂЧПЕїСЫЪ§ОнЕФжиаТМЦЫуЮЪЬтЁЃдкСїДІРэжажиаТМЦЫуЪЧИіжївЊЬєеНЃЌЕЋЪЧОГЃБЛКіЪгЁЃБШЗНЫЕЃЌФГЙЄзїСїЕФЪ§ОнЪфГіЪЧгЩЪфШыОіЖЈЕФЃЌФЧУДвЛЕЉДњТыЗЂЩњИФЖЏЃЌЮвУЧНЋВЛЕУВЛжиаТМЦЫуРДМьЪгБфИќЕФаЇЖШЁЃЪВУДЧщПіЯТДњТыЛсИФЖЏФиЃПР§ШчашЧѓЗЂЩњБфИќЃЌМЦЫузжЖЮашвЊЕїећЛђепГЬађЗЂГіДэЮѓЃЌашвЊНјааЕїЪдЁЃ
ШБЕуЃК
aЁЂJay KrepsШЯЮЊLambdaАќКЌЙЬгаЕФПЊЗЂКЭдЫЮЌЕФИДдгадЁЃLambdaашвЊНЋЫљгаЕФЫуЗЈЪЕЯжСНДЮЃЌвЛДЮЪЧЮЊХњДІРэЯЕЭГЃЌСэвЛДЮЪЧЮЊЪЕЪБЯЕЭГЃЌЛЙвЊЧѓВщбЏЕУЕНЕФЪЧСНИіЯЕЭГНсЙћЕФКЯВЂЁЃ
гЩгкДцдквдЩЯШБЕуЃЌLinkedinЕФJay krepsЬсГіСЫKappaМмЙЙШчЭМЃЈIЃЉЃК

ЭМЃЈIЃЉ
1ЁЂЪЙгУKafkaЛђЦфЫќЯЕЭГРДЖдашвЊжиаТМЦЫуЕФЪ§ОнНјааШежОМЧТМЃЌвдМАЬсЙЉИјЖрИіЖЉдФепЪЙгУЁЃР§ШчашвЊжиаТМЦЫу30ЬьФкЕФЪ§ОнЃЌЮвУЧПЩвддкKafkaжаЩшжУ30ЬьЕФЪ§ОнБЃСєжЕЁЃ
2ЁЂЕБашвЊНјаажиаТМЦЫуЪБЃЌЦєЖЏСїДІРэзївЕЕФЕкЖўИіЪЕР§ЖджЎЧАЛёЕУЕФЪ§ОнНјааДІРэЃЌжЎКѓжБНгАбНсЙћЪ§ОнЗХШыаТЕФЪ§ОнЪфГіБэжаЁЃ
3ЁЂЕБзївЕЭъГЩЪБЃЌШУгІгУГЬађжБНгЖСШЁаТЕФЪ§ОнМЧТМБэЁЃ
4ЁЂЭЃжЙРњЪЗзївЕЃЌЩОГ§ОЩЕФЪ§ОнЪфГіБэЁЃ
KappaМмЙЙднЪБЮДзіЩюШыСЫНтЃЌдкДЫВЛзіЦРМлЁЃЮвИіШЫОѕЕУЃЌВЛЭЌЕФЪ§ОнМмЙЙгаИїздЕФгХШБЕуЃЌЮвУЧЪЙгУЕФЪБКђжЛФмИљОнгІгУГЁОАЃЌбЁдёИќКЯЪЪЕФМмЙЙЃЌВХФмбяГЄБмЖЬЁЃ
|








