| БрМЭЦМі: |
| ШчКЮдквЛИіЯЕЭГжаШкКЯOLTPаЭЫцЛњЖСаДФмСІгыOLAPаЭЗжЮіФмСІЃЌKuduЬсЙЉСЫгХауЕФЩшМЦЫМТЗЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
БОЮФжївЊДгKuduЕФЩшМЦТлЮФзХЪжЃЌНсКЯгыHBaseЕФЖдБШЗжЮіЃЌРДГѕВННвЪОKuduЕФЩшМЦдРэЃЌВПЗжЩшМЦдкзюаТЕФKuduАцБОжаПЩФмвбОЙ§ЪБЃЌЕЋзюГѕЕФЩшМЦЫМЯывРШЛжЕЕУНшМјЁЃ
1KuduЕФЩшМЦГѕжд
дкНщЩмKuduЪЧЪВУДжЎЧАЃЌЛЙЪЧЯШМђЕЅЕФЫЕвЛЯТЯжДцЯЕЭГеыЖдНсЙЙЛЏЪ§ОнДцДЂгыВщбЏЕФвЛаЉЭДЕуЮЪЬтЃЌНсЙЙЛЏЪ§ОнЕФДцДЂЃЌЭЈГЃАќКЌШчЯТСНжжЗНЪНЃК
ОВЬЌЪ§ОнЭЈГЃвдParquet/Carbon/AvroаЮЪНжБНгДцЗХдкHDFSжаЃЌЖдгкЗжЮіГЁОАЃЌетжжДцДЂЭЈГЃЪЧИќМгЪЪКЯЕФЁЃЕЋЮоТлвдФФжжЗНЪНДцдкгкHDFSжаЃЌЖМФбвджЇГжЕЅЬѕМЧТММЖБ№ЕФИќаТЃЌЫцЛњЖСШЁвВВЂВЛИпаЇЁЃ
ПЩБфЪ§ОнЕФДцДЂЭЈГЃбЁдёHBaseЛђепCassandraЃЌвђЮЊЫќУЧФмЙЛжЇГжМЧТММЖБ№ЕФИпаЇЫцЛњЖСаДЁЃЕЋетжжДцДЂШДВЂВЛЪЪКЯРыЯпЗжЮіГЁОАЃЌвђЮЊЫќУЧдкДѓХњСПЪ§ОнЛёШЁЪБЕФадФмНЯВюЃЈеыЖдHBaseЖјбдЃЌгаСНЗНУцЕФжївЊдвђЃКвЛЪЧHFileБОЩэЕФНсЙЙЖЈвхЃЌЫќЪЧАДаазщжЏЪ§ОнЕФЃЌетжжИёЪНеыЖдДѓЖрЪ§ЕФЗжЮіГЁОАЃЌЖМЛсДјРДНЯДѓЕФIOЯћКФЃЌвђЮЊПЩФмЛсЖСШЁКмЖрВЛБивЊЕФЪ§ОнЃЌЯрЖдЖјбдParquetИёЪНеыЖдЗжЮіГЁОАОЭзіСЫКмЖргХЛЏЁЃ
ЖўЪЧгЩгкHBaseБОЩэЕФLSM-TreeМмЙЙОіЖЈЕФЃЌHBaseЕФЖСШЁТЗОЖжаЃЌВЛНівЊПМТЧФкДцжаЕФЪ§ОнЃЌЭЌЪБвЊПМТЧHDFSжаЕФвЛИіЛђЖрИіHFileЃЌНЯжЎгкжБНгДгHDFSжаЖСШЁЮФМўЖјбдЃЌетжжЖСШЁТЗОЖЪЧЙ§ГЄЕФЃЉЁЃ
ПЩвдПДГіЃЌШчЩЯСНжжДцДЂЗНЪНЃЌЖМДцдкУїЯдЕФгХШБЕуЃК
жБНгДцЗХгкHDFSжаЃЌЪЪКЯРыЯпЗжЮіЃЌШДВЛРћгкМЧТММЖБ№ЕФЫцЛњЖСаДЁЃ
жБНгНЋЪ§ОнДцЗХгкHBase/CassandraжаЃЌЪЪКЯМЧТММЖБ№ЕФЫцЛњЖСаДЃЌЖдРыЯпЗжЮіШДВЛгбКУЁЃ
ЕЋдкКмЖрЪЕМЪвЕЮёГЁОАжаЃЌСНжжГЁОАЪБГЃЪЧВЂДцЕФЁЃЮвУЧЕФЭЈГЃзіЗЈгаШчЯТМИжжЃК
Ъ§ОнДцЗХгкHBaseжаЃЌЖдгкЗжЮіШЮЮёЃЌЛљгкSpark/Hive On HBaseНјааЃЌадФмНЯВюЁЃ
ЖдгкЗжЮіадФмвЊЧѓНЯИпЕФЃЌПЩвдНЋЪ§ОндкHDFS/HiveжаЖрШпгрДцЗХвЛЗнЃЌЛђепЃЌНЋHBaseжаЕФЪ§ОнЖЈЦкЕФЕМГіГЩParquet/CarbonИёЪНЕФЪ§ОнЁЃ
УїЯдетжжЗНАИЖдвЕЮёгІгУЬсГіСЫНЯИпЕФвЊЧѓЃЌЖјЧвШнвзЕМжТдкЯпЪ§ОнгыРыЯпЪ§ОнжЎМфЕФвЛжТадЮЪЬтЁЃ
KuduЕФЩшМЦЃЌОЭЪЧЪдЭМдкOLAPгыOLTPжЎМфЃЌбАЧѓвЛИізюМбЕФНсКЯЕуЃЌДгЖјдквЛИіЯЕЭГЕФвЛЗнЪ§ОнжаЃЌМШФмжЇГжOLTPаЭЪЕЪБЖСаДФмСІгжФмжЇГжOLAPаЭЗжЮіЁЃСэЭтвЛИіГѕждЃЌдкClouderaЗЂВМЕФЁЖKudu:
New Apache Hadoop Storage for Fast Analytics on Fast
DataЁЗвЛЮФжагаЬсМАЃЌKuduзїЮЊвЛИіаТЕФЗжВМЪНДцДЂЯЕЭГЦкЭћгааЇЬсЩ§CPUЕФЪЙгУТЪЃЌЖјЕЭCPUЪЙгУТЪЧЁЪЧHBase/CassandraЕШЯЕЭГЕФзюДѓЮЪЬтЁЃЯТУцЕФеТНкжаЃЌжївЊДгТлЮФЫљНвЪОЕФФкШнРДНтЖСKuduЕФЩшМЦдРэЁЃ
2 KuduЕФдРэНщЩм
KuduздЩэЕФМмЙЙЃЌВПЗжНшМјСЫBigtable/HBase/SpannerЕФЩшМЦЫМЯыЁЃТлЮФЕФзїепСаБэжаЃЌгаМИЮЛЪЧHBaseЩчЧјЕФCommitter/PBCГЩдБЃЌвђДЫЃЌдкТлЮФжавВФмКмЩюПЬЕФИаЪмЕНHBaseЖдKuduЩшМЦЕФвЛаЉгАЯьЃЌвђДЫЃЌдкБОЮФЕФЖрИіЕиЗНЖМгаЬИМАKuduгыHBaseдкЩшМЦЩЯЕФвьЭЌЁЃ
2.1 БэгыSchema
KuduЩшМЦЪЧУцЯђНсЙЙЛЏДцДЂЕФЃЌвђДЫЃЌKuduЕФБэЃЌашвЊгУЛЇдкНЈБэЪБЖЈвхЫќЕФSchemaаХЯЂЃЌетаЉSchemaаХЯЂАќКЌЃКСаЖЈвхЃЈКЌРраЭЃЉЃЌPrimary
KeyЖЈвхЃЈгУЛЇжИЖЈЕФШєИЩИіСаЕФгаађзщКЯЃЉЁЃЪ§ОнЕФЮЈвЛадЃЌвРРЕгкгУЛЇЫљЬсЙЉЕФPrimary KeyжаЕФColumnзщКЯЕФжЕЕФЮЈвЛадЁЃ
KuduЬсЙЉСЫAlterУќСюРДдіЩОСаЃЌЕЋЮЛгкPrimary KeyжаЕФСаЪЧВЛдЪаэЩОГ§ЕФЁЃ
KuduЕБЧАВЂВЛжЇГжЖўМЖЫїв§ЁЃ
2.2 API
KuduЬсЙЉСЫJava/C++СНжжгябдЕФAPIЃЈОЁЙмвВЬсЙЉСЫPython APIЃЌЕЋЩаДІгкExperimentalНзЖЮЃЉЁЃЭЈЙ§етаЉAPIЃЌПЩвдНјааШчЯТвЛаЉВйзїЃК
Insert/Update/Delete
ХњСПЪ§ОнЕМШы/ИќаТВйзї
Scan(ПЩжЇГжМђЕЅЕФFilter)
2.3 ЪТЮёгывЛжТадФЃаЭ
KuduНіНіЬсЙЉЕЅааЪТЮёЃЌвВВЛжЇГжЖрааЪТЮёЁЃетвЛЕугыHBaseЪЧЯрЫЦЕФЁЃЕЋдкЪ§ОнвЛжТадФЃаЭЩЯЃЌгыHBaseгаНЯДѓЕФЧјБ№ЁЃ
KuduЬсЙЉСЫШчЯТСНжжвЛжТадФЃаЭЃК
Snapshot Consistency
етЪЧKuduжаЕФФЌШЯвЛжТадФЃаЭЁЃдкетжжФЃаЭжаЃЌжЛБЃжЄвЛИіПЭЛЇЖЫФмЙЛПДЕНздМКЫљЬсНЛЕФаДВйзїЃЌЖјВЂВЛБЃеЯШЋОжЕФЃЈПчЖрИіПЭЛЇЖЫЕФЃЉЪТЮёПЩМћадЁЃ
External Consistency
зюдчЬсГіExternal ConsistencyЛњжЦЕФЃЌгІИУЪЧдкGoogleЕФSpannerТлЮФжаЁЃДЋЭГЙиЯЕаЭЪ§ОнПтжаЕФСННзЖЮЬсНЛЛњжЦЃЌашвЊСНЛиКЯЭЈаХЃЌетЙ§ГЬжаДјРДЕФДњМлЪЧНЯИпЕФЃЌЕЋЭЌЪБетЙ§ГЬжаЕФИДдгЕФЫјЛњжЦвВПЩФмЛсДјРДвЛаЉПЩгУадЮЪЬтЁЃвЛИіИќКУЕФЪЕЯжЗжВМЪНЪТЮё/вЛжТадЕФЫМТЗЃЌЪЧЛљгквЛИіШЋОжЗЂВМЕФTimestampЛњжЦЁЃSpannerЬсГіСЫCommit-waitЕФЛњжЦЃЌРДБЃеЯШЋОжЪТЮёЕФгаађадЃКШчЙћвЛИіЪТЮёT1ЕФЬсНЛЯШгкСэЭтвЛИіЪТЮёT2ЕФПЊЪМЃЌдђT1ЕФTimestampвЊаЁгкT2ЕФTimeStampЁЃЮвУЧжЊЕРЃЌдкЗжВМЪНЯЕЭГжаЃЌЪЧКмФбгкзіетбљЕФГаХЕЕФЁЃдкHBaseжаЃЌЮвУЧПЩвдЯыЯѓЃЌШчЙћЫљгаRegionServerжаЕФSequenceIDЗЂВМздЭЌвЛИіЪ§ОндДЃЌФЧУДЃЌHBaseЕФКмЖрЪТЮёадЮЪЬтОЭгШаЖјНтСЫЃЌШЛКѓзюДѓЕФЮЪЬтдкгкетИіШЋОжЕФSequenceIDЪ§ОндДНЋЛсЪЧећИіЯЕЭГЕФадФмЦПОБЕуЁЃЛиЕНExternal
ConsistencyЛњжЦЃЌSpannerЪЧвРРЕгкИпОЋЖШгыПЩдЄМћЮѓВюЕФБОЕиЪБжг(TrueTime API)ЪЕЯжЕФ(МДашвЊвЛИіИпПЩППКЭИпОЋЖШЕФЪБжгдДЃЌЭЌЪБЃЌетИіЪБжгЕФЮѓВюЪЧПЩдЄМћЕФЁЃИааЫШЄЕФЭЌбЇПЩвддФЖСSpannerТлЮФЃЌетРяВЛзИЪі)ЁЃKuduжаЬсЙЉСЫСэЭтвЛжжЫМТЗРДЪЕЯжExternal
Consistency,ЛљгкTimestampРЉЩЂЛњжЦЃЌМДЃЌЖрИіПЭЛЇЖЫПЩЯрЛЅЭЈаХРДИцжЊБЫДЫЫљЬсНЛЕФTimestampжЕЃЌДгЖјБЃеЯвЛИіШЋОжЕФЫГађЁЃетжжЛњжЦвВЪЧЯрЖдНЯЮЊИДдгЕФЁЃ
гыSpannerРрЫЦЃЌKuduВЛдЪаэгУЛЇздЖЈвхгУЛЇЪ§ОнЕФTimestampЃЌЕЋдкHBaseжаШДЪЧВЛЭЌЃЌгУЛЇПЩвдЗЂЦ№вЛДЮЛљгкФГЬиЖЈTimestampЕФВщбЏЁЃ
2.4 KuduЕФМмЙЙ
KuduвВВЩгУСЫMaster-SlaveаЮЪНЕФжааФНкЕуМмЙЙЃЌЙмРэНкЕуБЛГЦзїKudu MasterЃЌЪ§ОнНкЕуБЛГЦзїTablet
ServerЃЈПЩЖдБШРэНтHBaseжаЕФRegionServerНЧЩЋЃЉЁЃвЛИіБэЕФЪ§ОнЃЌБЛЗжИюГЩ1ИіЛђЖрИіTabletЃЌTabletБЛВПЪ№дкTablet
ServerРДЬсЙЉЪ§ОнЖСаДЗўЮёЁЃ?
Kudu MasterдкKuduМЏШКжаЃЌЗЂЛгШчЯТЕФвЛаЉзїгУЃК
1. гУРДДцЗХвЛаЉБэЕФSchemaаХЯЂЃЌЧвИКд№ДІРэНЈБэЕШЧыЧѓЁЃ
2. ИњзйЙмРэМЏШКжаЕФЫљгаЕФTablet ServerЃЌВЂЧвдкTablet ServerвьГЃжЎКѓаЕїЪ§ОнЕФжиВПЪ№ЁЃ
3. ДцЗХTabletЕНTablet ServerЕФВПЪ№аХЯЂЁЃ
TabletгыHBaseжаЕФRegionДѓжТЯрЫЦЃЌЕЋДцдкШчЯТвЛаЉУїЯдЕФЧјБ№ЕуЃК
TabletАќКЌСНжжЗжЧјВпТдЃЌвЛжжЪЧЛљгкHash PartitionЗНЪНЃЌдкетжжЗжЧјЗНЪНЯТгУЛЇЪ§ОнПЩНЯОљдШЕФЗжВМдкИїИіTabletжаЃЌЕЋдРДЕФЪ§ОнХХађЬиЕувбБЛДђТвЁЃСэЭтвЛжжЪЧЛљгкRange
PartitionЗНЪНЃЌЪ§ОнНЋАДеегУЛЇЪ§ОнжИЖЈЕФгаађЕФPrimary Key ColumnsЕФзщКЯStringЕФЫГађНјааЗжЧјЁЃЖјHBaseжаНіНіЬсЙЉСЫвЛжжАДгУЛЇЪ§ОнRowKeyЕФRange
PartitionЗНЪНЁЃ
вЛИіTabletПЩвдБЛВПЪ№ЕНСЫЖрИіTablet ServerжаЁЃдкHBaseзюГѕЕФМмЙЙжаЃЌвЛИіRegionжЛФмБЛВПЪ№дквЛИіRegionServerжаЃЌЫќЕФЪ§ОнЖрИББОНЛгЩHDFSРДБЃеЯЁЃДг1.0АцБОПЊЪМЃЌHBaseгаСЫRegion
ReplicaЃЈHBASE-10070ЃЉЬиадЃЌИУЬиаддЪаэНЋвЛИіRegionВПЪ№дкЖрИіRegionServerжаРДЬсЩ§ЖСШЁЕФПЩгУадЃЌЕЋЖрRegionИББОжЎМфЕФЪ§ОнШДВЛЪЧЪЕЪБЭЌВНЕФЁЃ
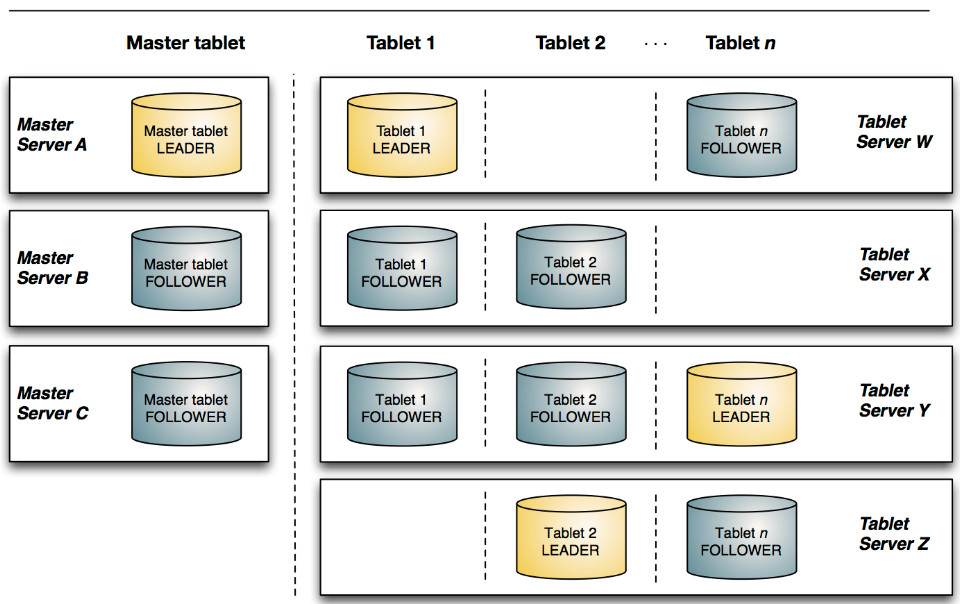
ЭМ1 KuduЕФЪ§ОнЖрИББОЛњжЦ

ЭМ2 HBaseЕФЪ§ОнЖрИББОЛњжЦ
2.5 KuduЕФЕзВуЪ§ОнФЃаЭ
KuduЕФЕзВуЪ§ОнЮФМўЕФДцДЂЃЌЮДВЩгУHDFSетбљЕФНЯИпГщЯѓВуДЮЕФЗжВМЪНЮФМўЯЕЭГЃЌЖјЪЧздааПЊЗЂСЫвЛЬзПЩЛљгкTable/Tablet/ReplicaЪгЭММЖБ№ЕФЕзВуДцДЂЯЕЭГЁЃетЬзЪЕЯжЛљгкШчЯТЕФМИИіЩшМЦФПБъЃК
ПЩЬсЙЉПьЫйЕФСаЪНВщбЏЁЃ
ПЩжЇГжПьЫйЕФЫцЛњИќаТ
ПЩЬсЙЉИќЮЊЮШЖЈЕФВщбЏадФмБЃеЯЁЃ
ЮЊСЫЪЕЯжШчЩЯФПБъЃЌKuduВЮПМСЫвЛжжРрЫЦгкFractured MirrorsЕФЛьКЯСаДцДЂМмЙЙЁЃTabletдкЕзВуБЛНјвЛВНЯИЗжГЩСЫвЛИіГЦжЎЮЊRowSetsЕФЕЅдЊЃК

ЭМ3 RowSets
MemRowSetsПЩвдЖдБШРэНтГЩHBaseжаЕФMemStore, ЖјDiskRowSetsПЩРэНтГЩHBaseжаЕФHFileЁЃMemRowSetsжаЕФЪ§ОнАДееааЪдЭМНјааДцДЂЃЌЪ§ОнНсЙЙЮЊB-TreeЁЃMemRowSetsжаЕФЪ§ОнБЛFlushЕНДХХЬжЎКѓЃЌаЮГЩDiskRowSetsЁЃ
DisRowSetsжаЕФЪ§ОнЃЌАДее32MBДѓаЁЮЊЕЅЮЛЃЌАДађЛЎЗжЮЊвЛИіИіЕФDiskRowSetЁЃ
DiskRowSetжаЕФЪ§ОнАДееColumnНјаазщжЏЃЌгыParquetРрЫЦЁЃетЪЧKuduПЩжЇГжвЛаЉЗжЮіадВщбЏЕФЛљДЁЁЃУПвЛИіColumnЕФЪ§ОнБЛДцДЂдквЛИіЯрСкЕФЪ§ОнЧјгђЃЌЖјетИіЪ§ОнЧјгђНјвЛВНБЛЯИЗжГЩвЛИіИіЕФаЁЕФPageЕЅдЊЃЌгыHBase
FileжаЕФBlockРрЫЦЃЌЖдУПвЛИіColumn PageПЩВЩгУвЛаЉEncodingЫуЗЈЃЌвдМАвЛаЉЭЈгУЕФCompressionЫуЗЈЁЃ
МШШЛПЩЖдColumn PageПЩВЩгУEncodingвдМАCompressionЫуЗЈЃЌФЧУДЃЌЖдЕЅЬѕМЧТМЕФИќИФОЭЛсБШНЯРЇФбСЫЁЃЧАУцЬсЕНСЫKuduПЩжЇГжЕЅЬѕМЧТММЖБ№ЕФИќаТ/ЩОГ§ЃЌЪЧШчКЮзіЕНЕФЃПгыHBaseРрЫЦЃЌвВЪЧЭЈЙ§діМгвЛЬѕаТЕФМЧТМРДУшЪіетДЮИќаТ/ЩОГ§ВйзїЕФЁЃвЛИіDiskRowSetАќКЌСНВПЗжЪ§ОнЃКЛљДЁЪ§Он(Base
Data)ЃЌвдМАБфИќЪ§Он(Delta Stores)ЁЃИќаТ/ЩОГ§ВйзїЫљЩњГЩЕФЪ§ОнМЧТМЃЌБЛБЃДцдкБфИќЪ§ОнВПЗжЁЃ

ЭМ4 Delta Store Design
ДгЩЯЭМЃЈдДздKuduЕФдДЙЄГЬЮФМўЃЉРДПДЃЌDeltaЪ§ОнВПЗжгІИУАќКЌREDOгыUNDOСНВПЗжЃЌетРяЕФREDOгыUNDOгыЙиЯЕаЭЪ§ОнПтжаЕФREDOгыUNDOШежОРрЫЦЃЈдкЙиЯЕаЭЪ§ОнПтжаЃЌREDOШежОМЧТМСЫИќаТКѓЕФЪ§ОнЃЌПЩвдгУРДЛжИДЩаЮДаДШыData
FileЕФвбГЩЙІЪТЮёИќаТЕФЪ§ОнЁЃ ЖјUNDOШежОгУРДМЧТМЪТЮёИќаТжЎЧАЕФЪ§ОнЃЌПЩвдгУРДдкЪТЮёЪЇАмЪБНјааЛиЙіЃЉЃЌЕЋвВДцдквЛаЉЯИНкЩЯЕФВювьЃК
REDO Delta FilesАќКЌСЫBase DataздЩЯвЛДЮБЛFlush/CompactionжЎКѓЕФБфИќжЕЁЃREDO
Delta FilesАДееTimestampЫГађХХСаЁЃ
UNDO Delta FilesАќКЌСЫBase DataздЩЯвЛДЮFlush/CompactionжЎЧАЕФБфИќжЕЁЃетбљВХПЩвдБЃеЯЛљгквЛИіОЩTimestampЕФВщбЏФмЙЛПДЕНвЛИівЛжТадЪгЭМЁЃUNDOАДееTimestampЕЙађХХСаЁЃ
2.6 Ъ§ОнЖСаДСїГЬ
аДЪ§ОнЕФСїГЬЃЌШчЯТЭМЫљЪОЃК
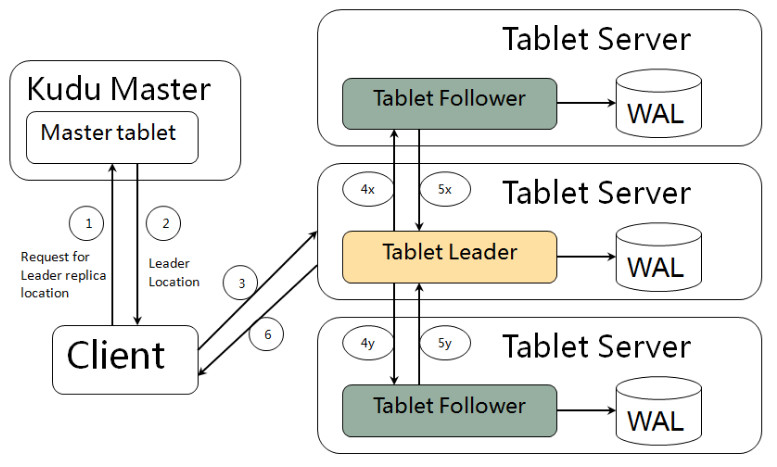
ЭМ5 Write Path
KuduВЛдЪаэгУЛЇЪ§ОнЕФPrimary KeyжиИДЃЌвђДЫЃЌдкTabletФкВПаДШыЪ§ОнжЎЧАЃЌашвЊЯШДгвбгаЕФЪ§ОнжаМьВщЕБЧАаТаДШыЕФЪ§ОнЕФPrimary
KeyЪЧЗёвбОДцдкЃЌОЁЙмдкDiskRowSetsжадіМгСЫBloomFilterРДЬсЩ§етжжХаЖЯЕФаЇТЪЃЌЕЋПЩвддЄМћЃЌKuduЕФетжжЩшМЦНЋЛсУїЯддіДѓаДШыЕФЪБбгЁЃ
Ъ§ОнвЛПЊЪМЯШДцЗХгкMemRowSetsжаЃЌД§ДѓаЁГЌГівЛЖЈЕФуажЕжЎКѓЃЌдйFlushГЩDiskRowSetsЁЃетВПЗжвбОдкЭМ4жагаЯъЯИЕФНщЩмЁЃЫцзХFlushДЮЪ§ЕФВЛЖЯдіМгЃЌЩњГЩЕФDiskRowSetsвВЛсВЛЖЯЕФдіЖрЃЌдкKuduФкВПвВДцдквЛИіCompactionСїГЬЃЌетбљПЩвдНЋвбОДцдкЕФЖрИіДцдкPrimary
KeyНЛМЏЕФDiskRowSetsжиаТХХађЖјЩњГЩвЛИіаТЕФDiskRowSetsЁЃШчЯТЭМЫљЪОЃК

ЭМ6 RowSet Compaction
ЖСЪ§ОнЕФСїГЬЃЌМШвЊПМТЧДцдкгкФкДцжаЕФMemRowSets,гжвЊЖСШЁЮЛгкДХХЬжаЕФвЛИіЛђЖрИіDiskRowSetsЃЌдкScannerЕФИпВуГщЯѓжаЃЌгІИУгыHBaseРрЫЦЁЃШчЯТжиЕуЬсвЛаЉЯИНкЕФгХЛЏЕуЃК
ЭЈЙ§ScanЕФЗЖЮЇЃЌгыУПвЛИіDiskRowSetsжаЕФPrimary Key RangeНјааЖдБШЃЌПЩвдЪзЯШЙ§ТЫЕєвЛаЉВЛБивЊВЮгыДЫДЮScanЕФDiskRowSetsЁЃ
Delta StoreВПЗжЃЌеыЖдМЧТММЖБ№ЕФИќИФЃЌМЧТМСЫBase DataжаЖдгІдЪМЪ§ОнЕФOffsetЁЃетбљЃЌдкХаЖЯвЛЬѕМЧТМЪЧЗёДцдкИќИФЕФМЧТМЪБЃЌНЋЛсИќМгЕФПьЫйЁЃ
гЩгкDiskRowSetsЕФЕзВуЮФМўЪЧАДееСазщжЏЕФЃЌЛљгквЛаЉСаЕФЬѕМўНјааЙ§ТЫВщбЏЪБЃЌПЩвдгХЯШЙ§ТЫЕєвЛаЉВЛБивЊЕФPrimary
KeysЁЃKuduВЂВЛЛсдквЛПЊЪМЖСШЁЕФЪБКђОЭНЋвЛааЪ§ОнЕФЫљгаСаЖСШЁГіРДЃЌЖјЪЧЯШЖСШЁгыЙ§ТЫЬѕМўЯрЙиЕФСаЃЌЭЈЙ§НЋетаЉСагыВщбЏЬѕМўЦЅХфжЎКѓЃЌдйРДОіЖЈЪЧЗёШЅЖСШЁЗћКЯЬѕМўЕФаажаЕФЦфЫќЕФСааХЯЂЁЃетбљПЩвдНкЪЁвЛаЉДХХЬIOЁЃетОЭЪЧKuduЫљЬсЙЉЕФLazy
MaterializationЬиадЁЃ
2.7 RaftФЃаЭ
KuduЕФЖрИББОжЎМфЕФЪ§ОнЙВЪЖавщВЩгУСЫRaftавщЃЌRaftЪЧБШPaxosИќШнвзРэНтЧвИќМђЕЅЕФвЛжжвЛжТадавщЁЃ
ЙигкRaftЕФИќЖраХЯЂЃЌЧыВЮПМЃКhttps://raft.github.io/
3 KuduгыHBaseЕФЧјБ№
етРядйзмНсвЛЯТKuduгыHBaseЕФвЛаЉДѓЕФЧјБ№ЕуЃК
KuduЕФЪ§ОнЗжЧјЗНЪНЯрЖдЖрбљЛЏЃЌЖјHBaseНЯЕЅвЛЁЃ
KuduЕФTabletздЩэОпБИЖрИББОЛњжЦЃЌЖјHBaseЕФRegionвРРЕгкЕзВуHDFSЕФЖрИББОЛњжЦЁЃ
KuduЕзВужБНгВЩгУБОЕиЮФМўЯЕЭГЃЌ ЖјHBaseвРРЕгкHDFSЁЃ
KuduЕФЕзВуЮФМўИёЪНВЩгУСЫРрЫЦгкParquetЕФСаЪНДцДЂИёЪНЃЌЖјHBaseЕФЕзВуHFileЮФМўШДЪЧАДааРДзщжЏЕФЁЃ
KuduЙигкЕзВуЕФFlushШЮЮёвдМАCompactionШЮЮёЃЌФмЙЛНсКЯУІЪБЛђепЯаЪБНјааздЖЏЕФЕїећЁЃHBaseЛЙЩаВЛОпБИетжжЕїЖШФмСІЁЃ
KuduЕФCompactionЮоMinor/MajorЕФЧјЗжЃЌЯожЦУПвЛДЮCompactionЕФIOзмСПдк128MBДѓаЁЃЌвђДЫЃЌВЂВЛДцдкГЄОУжДааЕФCompactionШЮЮёЁЃ
CompactionЪЧАДашНјааЕФЃЌР§ШчЃЌШчЙћЫљгаЕФаДШыЖМЪЧЫГађаДШыЃЌдђНЋВЛЛсДЅЗЂCompactionЁЃ
KuduЕФЩшМЦЃЌМШМцЙЫСЫЗжЮіаЭЕФВщбЏФмСІЃЌгжМцЙЫСЫЫцЛњЖСаДФмСІЃЌетбљЃЌЪЦБивВЛсИЖГівЛаЉДњМлЁЃ Р§ШчЃЌаДШыЪ§ОнЪБЙигкPrimary
KeyЮЈвЛадЕФЯожЦЃЌОЭвЊЧѓаДШыЧАвЊМьВщЖдгІЕФPrimary KeyЪЧЗёвбОДцдкЃЌетбљЪЦБиЛсдіДѓаДШыЕФЪБбгЁЃЖјЕзВуОЁЙмВЩгУСЫРрЫЦгкParquetЕФСаЪНЮФМўЩшМЦЃЌЕЋгыHBaseРрЫЦЕФШпГЄЕФЖСШЁТЗОЖЃЌвВЛсЖдЗжЮіадЕФВщбЏДјРДвЛаЉгАЯьЁЃСэЭтЃЌетжжЩшМЦдкећааЖСШЁЪБЃЌвВЛсИЖГіНЯИпЕФДњМлЁЃ
4 KuduгыЯжгаЯЕЭГЕФЖдНг
KuduЬсЙЉСЫгыШчЯТвЛаЉЯЕЭГЕФЖдНгЃК
MapReduce: ЬсЙЉеыЖдKuduгУЛЇБэЕФInputвдМАOutputШЮЮёЖдНгЁЃ
Spark: ЬсЙЉгыSpark SQLвдМАDataFramesЕФЖдНгЁЃ
Impala: KuduздЩэЮДЬсЙЉShellвдМАSQL ParserЃЌЫљвдЃЌЫќЕФSQLФмСІдДздгыImpalaЕФМЏГЩЁЃдкетаЉМЏГЩжаЃЌФмЙЛКмКУЕФИажЊKuduБэЪ§ОнЕФБОЕиадаХЯЂЃЌФмЙЛГфЗжРћгУKuduЫљЬсЙЉЕФЙ§ТЫЦїЖдВщбЏНјаагХЛЏЃЌЭЌЪБЃЌImpalaБОЩэЕФDDL/DMLгяЗЈеыЖдKuduвВзіСЫвЛаЉРЉеЙЁЃПЩвдЯыЯѓЃЌClouderaдкImpalaгыKuduЕФМЏГЩЩЯЃЌвЛЖЈЛсгаИќЖрЕФЗЂСІЕуЁЃ
5KuduЕФЪЪгУГЁОА
Todd LipconдкStrata+Hadoop World 2015ДѓЛсЩЯЫљЬсЙЉЕФжїЬтЮЊЁЖKudu:
Resolving transactional and analytic trade-offs in
HadoopЁЗЕФбнНВжаЃЌетбљзгУшЪіKuduЕФЪЪгУГЁОАЃК

6 Kudu BenchmarkЪ§ОнНтЮі
ШчЯТЪЧЖдKudu WhitePageжаЫљЬсЙЉЕФвЛаЉBenchmarkадФмВтЪдЪ§ОнЕФМђЕЅНтЮі(ЯъЯИЕФНсЙћЧыВЮПМТлЮФЕФЕк6еТНк)ЃК
1.ЛљгкTPC-HВтЪдБъзМЃКеыЖдImpala On ParquetвдМАImpala
On KuduзіСЫЖдБШВтЪдЃЌImpala On KuduЕФЦНОљадФмБШImpala On ParquetЬсЩ§СЫ31%ЁЃетЪЧгЩгкKuduЫљЬсЙЉЕФLazy
MeterializationЬиадвдМАЖдЖдCPUаЇТЪЕФЬсЩ§ЖјДјРДЕФГЩЙћЁЃ
2.Impala-KuduгыPhoenix-HBaseЕФЖдБШЃКВтЪдЪЙгУЕНСЫTPC-HжаЕФlineitemвЛБэЃЌЙВЕМШыСЫ62GBЕФCSVИёЪНЕФЪ§ОнЁЃдкЕМШыPhoenixЪБЪЙгУСЫPhoenixЫљЬсЙЉЕФCsvBulkLoadToolЙЄОпЁЃВтЪдЪБЕФвЛаЉХфжУаХЯЂШчЯТЫљЪОЃК
ЮЊPhoenixБэЛЎЗжСЫ100ИіHash PartitionsЁЃЮЊKuduДДНЈСЫ100ИіTabletsЁЃ
HBaseВЩгУФЌШЯЕФBlock CacheВпТдЃЌЮЊУПвЛИіRegionServerХфжУСЫ9.6GBЕФCacheФкДцЁЃЖјKuduХфжУСЫ1GBЕФBlock
CacheЕФНјГЬФкДцЃЌЕЋЭЌЪБЛЙвРРЕгкВйзїЯЕЭГЕФBufferЁЃ
HBaseБэжаВЩгУСЫFAST_DIFFЕФBlock EncodingЫуЗЈЃЌЮДЦєгУШЮКЮбЙЫѕЁЃ
Ъ§ОнЕМШыЕНHBaseжажЎКѓЃЌжїЖЏДЅЗЂСЫвЛДЮMajor CompactionЃЌРДШЗБЃЪ§ОнЕФБОЕиЛЏТЪЁЃ62GBдЪМЪ§ОнЕМШыЕНHBaseжажЎКѓЕФзмДѓаЁдМЮЊ570GBЃЈетЪЧгЩгкЮДЦєгУCompressionбЙЫѕЃЌЭЌЪБЃЌгЩгкЖрИіСаЖМЪЧЖРСЂДцдкЕФДјРДЕФХђеЭЕМжТЃЉЃЌЖјЕМШыЕНKuduжажЎКѓЕФДѓаЁдМЮЊ227GBЁЃШчЯТЪЧЯргІЕФЖдБШВтЪдГЁОАвдМАЖдБШНсЙћЃК

Г§СЫЛљгкKeyжЕЕФећааЪ§ОнЕФВщбЏадФмЃЌPhoenixгаУїЯдЕФгХЪЦвдЭтЃЌЦфЫќЕФЛљгкећБэЩЈУшЃЌЛђепЪЧЛљгквЛаЉСаЕФВщбЏЃЌImpala-KuduЪЧгаУїЯдЕФгХЪЦЕФЁЃ
ЛљгкScan + FilterЕФВщбЏЃЌHBaseБОЩэОЭВЛЩУГЄЁЃ
3.ЫцЛњЖСаДФмСІЕФЖдБШ
ШчЯТЪЧЖдБШВтЪдЕФвЛаЉГЁОАЃК

ШчЯТЪЧЖдБШВтЪдЕФНсЙћЃК

ЙигкМгдивдМАZipfianЗжВМФЃЪНЯТЃЌHBaseЕФгХЪЦИќМгУїЯдЃЌЕБЧАKuduвВе§дкзіЙигкZipfianЗжВМФЃЪНЯТЕФгХЛЏЃЈKUDU-749ЃЉЃЌЖјдкUniformФЃЪНЯТЃЌHBaseЕФгХЪЦЩдШѕЁЃећЬхРДПДЃЌдкЫцЛњЖСаДЩЯЃЌKuduЕФЩшМЦНЯжЎHBaseЖјбдЃЌДцдквЛаЉСгЪЦЃЌетЪЧЮЊСЫМцЙЫЗжЮіаЭВщбЏЫљИЖГіЕФвЛаЉДњМлЁЃ
|








