| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЪВУДЪЧЪ§ОнКў,Ъ§ОнКўгыДЋЭГЪ§ОнВжПтЕФЧјБ№ЃЌЕфаЭЕФЪ§ОнКўНтОіЗНАИЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
Ъ§ОнКўЪЧЪ§ОнВжПтЕФВЙГф,ЪЧЮЊСЫНтОіЪ§ОнВжПтТўГЄЕФПЊЗЂжмЦкЃЌИпАКЕФПЊЗЂЁЂЮЌЛЄГЩБОЃЌЯИНкЪ§ОнЖЊЪЇЕШЮЪЬтГіЯжЕФЁЃ
Ъ§ОнКўДѓЖрЪЧЯрЖдгкДЋЭГЛљгкRDBMSЕФЪ§ОнВжПтЃЌЖјДг2011ФъЧАКѓЃЌвВОЭЪЧЪ§ОнКўИХФюГіЯжЕФЪБКђЃЌКмЖрЪ§ОнВжПтж№НЅЧЈвЦЕНвдHadoopЮЊЛљДЁЕФММЪѕеЛЩЯЃЌЖјЧвГ§СЫНсЙЙЛЏЪ§ОнЃЌАыНсЙЙЛЏЁЂЗЧНсЙЙЪ§ОнвВж№НЅЕФДцДЂЕНЪ§ОнВжПтжаЃЌВЂЬсЙЉДЫРрЗўЮёЁЃетбљЕФЪ§ОнВжПтЃЌвбООпгаСЫЪ§ОнКўЕФВПЗжЙІФмЁЃ
Ъ§ОнКўе§дкГЩЮЊвЛжждНРДдНСїааЕФДѓЪ§ОнНтОіЗНАИЃЌЖјЪ§ОнКўетИіДЪвбОБЛДѓЪ§ОнЙЉгІЩЬИГгшСЫЬЋЖрВЛЭЌЕФКЌвхЃЌШчЙћгаЪВУДЙЄзїЪЧДЋЭГЪ§ОнВжПтзіВЛСЫЕФЃЌФЧОЭАбЫќШћНјЪ§ОнКўЃЌвджСгкЪ§ОнКўвбОБфГЩСЫвЛИіЖЈвхФЃК§ЕФИХФюЁЃЪ§ОнКўЪЧВЛЪЧОЭЪЧДЋЫЕжаЕФвјЕЏЃЌПЩвдНтОіЫљгаЪ§ОнВжПтВЛФмНтОіЕФЮЪЬтФиЁЃБОЮФНЋНВЪіЃЌЙигкЪ§ОнКўЕФЖЈвхЃЌгыЪ§ОнВжПтЕФЧјБ№ЃЌвдМАЯжЪЕжаЕФЪ§ОнКўНтОіЗНАИКЭЮДРДЛсдѕбљЗЂеЙЁЃ
ЪВУДЪЧЪ§ОнКў
ЮЌЛљАйПЦЖдЪ§ОнКўЕФЖЈвхЪЧЃЌЪ§ОнКўЪЧвЛжждкЯЕЭГЛђДцДЂПтжавдздШЛИёЪНДцДЂЪ§ОнЕФЗНЗЈЃЌЫќгажњгквдИїжжФЃЪНКЭНсЙЙаЮЪНХфжУЪ§ОнЃЌЭЈГЃЪЧЖдЯѓПщЛђЮФМўЁЃЪ§ОнКўЕФжївЊЫМЯыЪЧЖдЦѓвЕжаЕФЫљгаЪ§ОнНјааЭГвЛДцДЂЃЌДгдЪМЪ§ОнЃЈдДЯЕЭГЪ§ОнЕФОЋШЗИББОЃЉзЊЛЛЮЊгУгкБЈИцЁЂПЩЪгЛЏЁЂЗжЮіКЭЛњЦїбЇЯАЕШИїжжШЮЮёЕФФПБъЪ§ОнЁЃЪ§ОнКўжаЕФЪ§ОнАќРЈНсЙЙЛЏЪ§ОнЃЈЙиЯЕЪ§ОнПтЪ§ОнЃЉЃЌАыНсЙЙЛЏЪ§ОнЃЈCSVЁЂXMLЁЂJSONЕШЃЉЃЌЗЧНсЙЙЛЏЪ§ОнЃЈЕчзггЪМўЃЌЮФЕЕЃЌPDFЃЉКЭЖўНјжЦЪ§ОнЃЈЭМЯёЁЂвєЦЕЁЂЪгЦЕЃЉЃЌДгЖјаЮГЩвЛИіШнФЩЫљгааЮЪНЪ§ОнЕФМЏжаЪНЪ§ОнДцДЂЁЃ
ПЩМћЃЌЦѓвЕЪЙгУЪ§ОнКўМмЙЙЃЌКЫаФГіЗЂЕуОЭЪЧАбВЛЭЌНсЙЙЕФЪ§ОнЭГвЛДцДЂЃЌЪЙВЛЭЌЪ§ОнгавЛжТЕФДцДЂЗНЪНЃЌдкЪЙгУЪБЗНБуСЌНгЃЌеце§НтОіЪ§ОнМЏГЩЮЪЬтЁЃвђДЫЃЌЪ§ОнКўМмЙЙзюжївЊЕФЬиЕуЃЌвЛЪЧжЇГжвьЙЙЪ§ОнОлКЯЃЌЖўЪЧЮоашдЄЖЈвхЪ§ОнФЃаЭМДПЩНјааЪ§ОнЗжЮіЁЃ
Ъ§ОнКўДгБОжЪЩЯРДНВЃЌЪЧвЛжжЦѓвЕЪ§ОнМмЙЙЗНЗЈЃЌЮяРэЪЕЯжЩЯдђЪЧвЛИіЪ§ОнДцДЂЦНЬЈЃЌгУРДМЏжаЛЏДцДЂЦѓвЕФкКЃСПЕФЁЂЖрРДдДЃЌЖржжРрЕФЪ§ОнЃЌВЂжЇГжЖдЪ§ОнНјааПьЫйМгЙЄКЭЗжЮіЁЃДгЪЕЯжЗНЪНРДПДЃЌФПЧАHadoopЪЧзюГЃгУЕФВПЪ№Ъ§ОнКўЕФММЪѕЃЌЕЋВЂВЛвтЮЖзХЪ§ОнКўОЭЪЧжИHadoopМЏШКЁЃЮЊСЫгІЖдВЛЭЌвЕЮёашЧѓЕФЬиЕуЃЌMPPЪ§ОнПт+HadoopМЏШК+ДЋЭГЪ§ОнВжПтетжжЁАЛьДюЁБМмЙЙЕФЪ§ОнКўвВдНРДдНЖрГіЯждкЦѓвЕаХЯЂЛЏНЈЩшЙцЛЎжаЁЃ

Data LakeЪЧвЛИіДцДЂПтЃЌПЩвдДцДЂДѓСПНсЙЙЛЏЃЌАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃЫќЪЧвддЩњИёЪНДцДЂУПжжРраЭЪ§ОнЕФЕиЗНЃЌЖдеЪЛЇДѓаЁЛђЮФМўУЛгаЙЬЖЈЯожЦЁЃЫќЬсЙЉИпЪ§ОнСПвдЬсИпЗжЮіадФмКЭБОЛњМЏГЩЁЃ
Data LakeОЭЯёвЛИіДѓаЭШнЦїЃЌгыеце§ЕФКўВДКЭКгСїЗЧГЃЯрЫЦЁЃОЭЯёдкКўжаФугаЖрИіжЇСїНјРДвЛбљЃЌЪ§ОнКўгаНсЙЙЛЏЪ§ОнЃЌЗЧНсЙЙЛЏЪ§ОнЃЌЛњЦїЕНЛњЦїЃЌЪЕЪБСїЖЏЕФШежОЁЃ
Data LakeЪЙЪ§ОнУёжїЛЏЃЌЪЧвЛжжОМУгааЇЕФЗНЪНРДДцДЂзщжЏЕФЫљгаЪ§ОнвдЙЉвдКѓДІРэЁЃбаОПЗжЮіЪІПЩвдзЈзЂгкдкЪ§ОнжаевЕНвтвхФЃЪНЖјВЛЪЧЪ§ОнБОЩэЁЃгыЪ§ОнДцДЂдкЮФМўКЭЮФМўМажаЕФЗжВуЪ§ОнВжПтВЛЭЌЃЌDataКўОпгаБтЦНЕФМмЙЙЁЃData
LakeжаЕФУПИіЪ§ОндЊЫиЖМБЛИГгшЮЈвЛБъЪЖЗћЃЌВЂБъМЧгавЛзщдЊЪ§ОнаХЯЂЁЃ
Ъ§ОнКўгыДЋЭГЪ§ОнВжПтЕФЧјБ№
Ъ§ОнВжПтЪЧвЛИігХЛЏЕФЪ§ОнПтЃЌгУгкЗжЮіРДздЪТЮёЯЕЭГКЭвЕЮёЯпгІгУГЬађЕФЙиЯЕЪ§ОнЁЃЪТЯШЖЈвхЪ§ОнНсЙЙКЭ Schema
вдгХЛЏПьЫй SQL ВщбЏЃЌЦфжаНсЙћЭЈГЃгУгкВйзїБЈИцКЭЗжЮіЁЃЪ§ОнОЙ§СЫЧхРэЁЂЗсИЛКЭзЊЛЛЃЌвђДЫПЩвдГфЕБгУЛЇПЩаХШЮЕФЁАЕЅвЛаХЯЂдДЁБЁЃ
Ъ§ОнКўгаЫљВЛЭЌЃЌвђЮЊЫќДцДЂРДздвЕЮёЯпгІгУГЬађЕФЙиЯЕЪ§ОнЃЌвдМАРДздвЦЖЏгІгУГЬађЁЂIoT ЩшБИКЭЩчНЛУНЬхЕФЗЧЙиЯЕЪ§ОнЁЃВЖЛёЪ§ОнЪБЃЌЮДЖЈвхЪ§ОнНсЙЙЛђ
SchemaЁЃетвтЮЖзХФњПЩвдДцДЂЫљгаЪ§ОнЃЌЖјВЛашвЊОЋаФЩшМЦвВЮоашжЊЕРНЋРДФњПЩФмашвЊФФаЉЮЪЬтЕФД№АИЁЃФњПЩвдЖдЪ§ОнЪЙгУВЛЭЌРраЭЕФЗжЮіЃЈШч
SQL ВщбЏЁЂДѓЪ§ОнЗжЮіЁЂШЋЮФЫбЫїЁЂЪЕЪБЗжЮіКЭЛњЦїбЇЯАЃЉРДЛёЕУМћНтЁЃ
Ъ§ОнКўгыЪ§ОнВжПтетСНИіИХФюКмШнвзБЛЛьЯ§ЃЌЫќУЧЕФЧјБ№жївЊгаШ§ИіЗНУцЃК
вЛЪЧДцДЂЪ§ОнРраЭВЛЭЌЁЃЪ§ОнВжПтжаДцДЂЕФжївЊЪЧНсЙЙЛЏЪ§ОнЃЌЖдгкМгдиЕНЪ§ОнВжПтжаЕФЪ§ОнЃЌЪзЯШашвЊЖЈвхЪ§ОнДцДЂФЃаЭЁЃЖјЪ§ОнКўвдЦфдЩњИёЪНБЃДцДѓСПдЪМЪ§ОнЃЌАќРЈНсЙЙЛЏЕФЁЂАыНсЙЙЛЏЕФКЭЗЧНсЙЙЛЏЕФЪ§ОнЃЌВЂЧвдкЪЙгУЪ§ОнжЎЧАЃЌВЛЖдЪ§ОнНсЙЙНјааЖЈвхЁЃ
ЖўЪЧЪ§ОнДІРэФЃЪНВЛЭЌЁЃЪ§ОнВжПтЪЧИпЖШНсЙЙЛЏЕФМмЙЙЃЌЪ§ОндкЧхЯДзЊЛЛжЎКѓВХЛсМгдиЕНЪ§ОнВжПтЃЌгУЛЇЛёЕУЕФЪЧДІРэКѓЪ§ОнЁЃЖјдкЪ§ОнКўжаЃЌЪ§ОнжБНгМгдиЕНЪ§ОнКўжаЃЌШЛКѓИљОнЗжЮіЕФашвЊдйДІРэЪ§ОнЁЃ
Ш§ЪЧЗўЮёЖдЯѓВЛЭЌЁЃДггУЛЇВювьЩЯРДПДЃЌЪ§ОнВжПтЪЪКЯЦѓвЕжаДѓЪ§ОнВњЦЗПЊЗЂШЫдБКЭвЕЮёгУЛЇЁЃЖјЪ§ОнКўзюЪЪКЯЪ§ОнЗжЮіЪІЛђЪ§ОнПЦбЇМвЃЌЫћУЧжБНгЛљгкЪ§ОнЩГЯфзіздгЩЬНЫїКЭЗжЮіЃЌетаЉШЫвЊЧѓгаММЪѕБГОАЃЌЛсаДДњТыЛђЪьЯЄSQLЁЃ
ЭЈЙ§вдЩЯЖдБШЃЌПЩМћЪ§ОнКўВЛЪЧМђЕЅЕФЪ§ОнВжПтЩ§МЖАцЃЌСНепгаИїздЕФДцдкБивЊЁЃгыДЫЭЌЪБЃЌЛЙгавЛжжЪ§ОнегдѓЕФЬсЗЈЃЌетЪЧжИвЛжжЩшМЦВЛСМЁЂЮДГфЗжЙщЕЕЛђЮДгааЇЮЌЛЄЕФЪ§ОнКўЃЌгУЛЇЮоЗЈгааЇЕиЗжЮіКЭРћгУЦфжаДцДЂЕФЪ§ОнЁЃ
ИќЮЊЯъЯИЕФЧјБ№ЃК

ЮЊКЮбЁдёData LakeвдМАЪ§ОнКўЕФИХФюКЭМмЙЙ
ЙЙНЈЪ§ОнКўЕФжївЊФПБъЪЧЯђЪ§ОнПЦбЇМвЬсЙЉЮДОЖЈвхЕФЪ§ОнЪгЭМЁЃ
ЪЙгУData LakeЕФдвђжївЊгаЃК
ЫцзХДцДЂв§ЧцЕФГіЯжЃЌHadoopШУДцДЂВЛЭЌЕФаХЯЂБфЕУИќМгШнвзЁЃашвЊЪЙгУData LakeНЋЪ§ОнНЈФЃЕНЦѓвЕЗЖЮЇЕФФЃЪНжаЁЃ
ЫцзХЪ§ОнСПЃЌЪ§ОнжЪСПКЭдЊЪ§ОнЕФдіМгЃЌЗжЮіжЪСПвВЛсЬсИпЁЃ
Data LakeЬсЙЉвЕЮёУєНнад
ЛњЦїбЇЯАКЭШЫЙЄжЧФмПЩгУгкНјаагаРћПЩЭМЕФдЄВтЁЃ
ЫќЮЊЪЕЪЉзщжЏЬсЙЉСЫОКељгХЪЦЁЃ
УЛгаЪ§ОнЙТЕКНсЙЙЁЃData LakeЬсЙЉ360ЖШЕФПЭЛЇЪгЭМЃЌЪЙЗжЮіИќМгНЁзГЁЃ
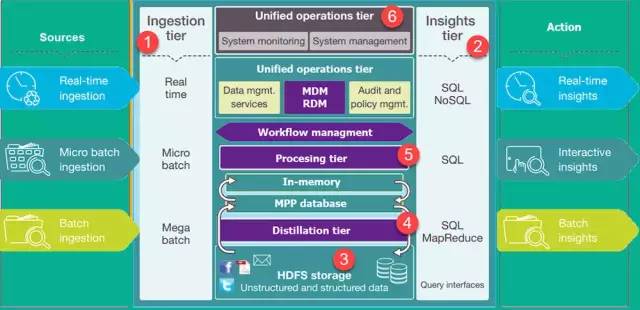
Ъ§ОнКўМмЙЙ
ЯТЭМЯдЪОСЫBusiness Data LakeЕФЬхЯЕНсЙЙЁЃНЯЕЭМЖБ№БэЪОДѓВПЗжДІгкОВжЙзДЬЌЕФЪ§ОнЃЌЖјНЯИпМЖБ№БэЪОЪЕЪБНЛвзЪ§ОнЁЃДЫЪ§ОнСїОЯЕЭГЃЌУЛгабгГйЛђбгГйКмаЁЁЃвдЯТЪЧData
Lake ArchitectureЕФживЊВуДЮЃК
1 ЩуШЁВу ЃКзѓВрЕФВуУшЪіСЫЪ§ОндДЁЃЪ§ОнПЩвдХњСПЛђЪЕЪБМгдиЕНЪ§ОнКўжа
2 ЖДВьВуЃКгвВрЕФВуДњБэбаОПЗНУцЃЌЪЙгУЯЕЭГЕФМћНтЁЃSQLЃЌNoSQLВщбЏЩѕжСexcelЖМПЩгУгкЪ§ОнЗжЮіЁЃ
3 HDFSЪЧНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЕФОМУИпаЇЕФНтОіЗНАИЁЃЫќЪЧЯЕЭГжаОВжЙЕФЫљгаЪ§ОнЕФзХТНЧјЁЃ
4 еєСѓВуДгДцДЂТжЬЅжаЛёШЁЪ§ОнВЂНЋЦфзЊЛЛЮЊНсЙЙЛЏЪ§ОнвдБугкЗжЮіЁЃ
5 ДІРэВудЫааЗжЮіЫуЗЈКЭгУЛЇВщбЏЃЌОпгаВЛЭЌЕФЪЕЪБЃЌНЛЛЅЃЌХњДІРэвдЩњГЩНсЙЙЛЏЪ§ОнЃЌвдБугкЗжЮіЁЃ
6 ЭГвЛВйзїВуЙмРэЯЕЭГЙмРэКЭМрЪгЁЃЫќАќРЈЩѓМЦКЭЪьСЗЙмРэЃЌЪ§ОнЙмРэЃЌЙЄзїСїГЬЙмРэЁЃ
Ъ§ОнКўЕФЙиМќИХФю

вдЯТЪЧData LakeЕФКЫаФИХФюЃЌШЫУЧашвЊСЫНтетаЉИХФюВХФмЭъШЋРэНтData LakeЕФМмЙЙЃК
1.Ъ§ОнЩуШЁ
Ъ§ОнЬсШЁдЪаэСЌНгЦїДгВЛЭЌЕФЪ§ОндДЛёШЁЪ§ОнВЂМгдиЕНDataКўжаЁЃ
Ъ§ОнЬсШЁжЇГжЃКЫљгаРраЭЕФНсЙЙЛЏЃЌАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃХњСПЃЌЪЕЪБЃЌвЛДЮадИКдиЕШЖрДЮЩуШЁЃЛаэЖрРраЭЕФЪ§ОндДЃЌШчЪ§ОнПтЃЌWebЗўЮёЦїЃЌЕчзггЪМўЃЌЮяСЊЭјКЭFTPЁЃ
2.Ъ§ОнДцДЂ
Ъ§ОнДцДЂгІИУЪЧПЩРЉеЙЕФЃЌЬсЙЉОМУИпаЇЕФДцДЂВЂдЪаэПьЫйЗУЮЪЪ§ОнЬНЫїЁЃЫќгІИУжЇГжИїжжЪ§ОнИёЪНЁЃ
3.Ъ§ОнжЮРэ
Ъ§ОнжЮРэЪЧЙмРэзщжЏжаЪЙгУЕФЪ§ОнЕФПЩгУадЃЌПЩгУадЃЌАВШЋадКЭЭъећадЕФЙ§ГЬЁЃ
4.АВШЋ
ашвЊдкData LakeЕФУПИіВужаЪЕЯжАВШЋадЁЃЫќЪМгкДцДЂЃЌЗЂОђКЭЯћКФЁЃЛљБОашЧѓЪЧЭЃжЙЮДЪкШЈгУЛЇЕФЗУЮЪЁЃЫќгІИУжЇГжВЛЭЌЕФЙЄОпРДЗУЮЪЪ§ОнЃЌвзгкЕМКНGUIКЭвЧБэАхЁЃ
ЩэЗнбщжЄЃЌЛсМЦЃЌЪкШЈКЭЪ§ОнБЃЛЄЪЧЪ§ОнКўАВШЋЕФвЛаЉживЊЬиадЁЃ
5.Ъ§ОнжЪСПЃК
Ъ§ОнжЪСПЪЧData LakeМмЙЙЕФживЊзщГЩВПЗжЁЃЪ§ОнгУгкШЗЖЈЩЬвЕМлжЕЁЃДгСгжЪЪ§ОнжаЬсШЁЖДВьСІНЋЕМжТжЪСПВюЕФЖДВьСІЁЃ
6.Ъ§ОнЗЂЯж
Ъ§ОнЗЂЯжЪЧФњПЊЪМзМБИЪ§ОнЛђЗжЮіжЎЧАЕФСэвЛИіживЊНзЖЮЁЃдкетИіНзЖЮЃЌБъМЧММЪѕгУгкБэДяЪ§ОнРэНтЃЌЭЈЙ§зщжЏКЭНтЪЭЪ§ОнКўжаЩуШЁЕФЪ§ОнЁЃ
7.Ъ§ОнЩѓМЦ
СНИіжївЊЕФЪ§ОнЩѓМЦШЮЮёЪЧИњзйЖдЙиМќЪ§ОнМЏЕФИќИФЃКИњзйживЊЪ§ОнМЏдЊЫиЕФИќИФЃЛВЖЛёШчКЮ/КЮЪБ/вдМАИќИФетаЉдЊЫиЕФШЫдБЁЃ
Ъ§ОнЩѓМЦгажњгкЦРЙРЗчЯеКЭКЯЙцадЁЃ
8.Ъ§ОнбиЯЎ
ИУзщМўДІРэЪ§ОнЕФРДдДЁЃЫќжївЊЩцМАЫцзХЪБМфЭЦвЦЫќЕФЭЦЖЏепвдМАЫќЗЂЩњСЫЪВУДЁЃЫќМђЛЏСЫДгЪМЗЂЕиЕНФПЕФЕиЕФЪ§ОнЗжЮіЙ§ГЬжаЕФДэЮѓИќе§ЁЃ
9.Ъ§ОнЬНЫї
етЪЧЪ§ОнЗжЮіЕФПЊЪМНзЖЮЁЃдкПЊЪМЪ§ОнЬНЫїжЎЧАЃЌШЗЖЈе§ШЗЕФЪ§ОнМЏЪЧжСЙиживЊЕФЁЃ
ЫљгаИјЖЈЕФзщМўашвЊаЭЌЙЄзїЃЌдкData LakeЙЙНЈжаЗЂЛгживЊзїгУЃЌЧсЫЩбнЛЏКЭЬНЫїЛЗОГЁЃ
Data LakeЕФГЩЪьНзЖЮ
Ъ§ОнКўГЩЪьНзЖЮЕФЖЈвхВЛЭЌгкНЬПЦЪщЁЃЫфШЛжЂНсШдШЛЪЧвЛбљЕФЁЃГЩЪьКѓЃЌНзЖЮЖЈвхЪЧДгЭтааЕФНЧЖШГіЗЂЕФЁЃ

ЕквЛНзЖЮЃКДѓЙцФЃДІРэКЭЩуШЁЪ§Он
Ъ§ОнГЩЪьЖШЕФЕквЛНзЖЮЩцМАЬсИпзЊЛЛКЭЗжЮіЪ§ОнЕФФмСІЁЃдкетРяЃЌЦѓвЕЫљгаепашвЊИљОнЫћУЧЕФММФмзщевЕНЙЄОпЃЌвдЛёШЁИќЖрЪ§ОнВЂЙЙНЈЗжЮігІгУГЬађЁЃ
ЕкЖўНзЖЮЃКНЈСЂЗжЮіФмСІ
етЪЧЕкЖўНзЖЮЃЌЩцМАЬсИпзЊЛЛКЭЗжЮіЪ§ОнЕФФмСІЁЃ?
дкетИіНзЖЮЃЌЙЋЫОЪЙгУзюЪЪКЯЫћУЧММФмЕФЙЄОпЁЃЫћУЧПЊЪМЛёШЁИќЖрЪ§ОнКЭЙЙНЈгІгУГЬађЁЃдкетРяЃЌЦѓвЕЪ§ОнВжПтКЭЪ§ОнКўЕФЙІФмвЛЦ№ЪЙгУЁЃ
ЕкШ§НзЖЮЃКEDWКЭData Lakeазї
етвЛВНЩцМАНЋЪ§ОнКЭЗжЮіНЛИјОЁПЩФмЖрЕФШЫЁЃдкДЫНзЖЮЃЌЪ§ОнКўКЭЦѓвЕЪ§ОнВжПтПЊЪМдкСЊКЯжаЙЄзїЁЃСНепЖМдкЗжЮіжаЗЂЛгзїгУЁЃ
ЕкЫФНзЖЮЃКЪ§ОнКўЕФЦѓвЕФмСІ
дкЪ§ОнКўЕФГЩЪьНзЖЮЃЌЦѓвЕЙІФмБЛЬэМгЕНData LakeжаЁЃВЩгУаХЯЂжЮРэЃЌаХЯЂЩњУќжмЦкЙмРэЙІФмКЭдЊЪ§ОнЙмРэЁЃЕЋЪЧЃЌКмЩйгазщжЏПЩвдДяЕНетжжГЩЪьЫЎЦНЃЌЕЋетжжЧщПіНЋдкЮДРДдіМгЁЃ
ЕфаЭЕФЪ§ОнКўНтОіЗНАИ
Ъ§ОнКўЕФИХФюЕЎЩњжЎКѓЃЌвЛаЉДѓЪ§ОнГЇЩЬвВЬсГіСЫздМКЖдЪ§ОнКўЕФРэНтЃЌВЂвРЭаздЩэКЫаФВњЦЗЛђПЊдДШэМўЃЌЗЂВМСЫВржигкВЛЭЌгІгУГЁОАЯТЕФЪ§ОнКўНтОіЗНАИЁЃ
ЛЊЮЊЪ§ОнКўЬНЫїЗўЮё(DLI)НтОіЗНАИЛљгкApache SparkЩњЬЌЃЌЬсЙЉЭъШЋЭаЙмЕФДѓЪ§ОнДІРэЗжЮіЗўЮёЁЃгУЛЇЪЙгУБъзМSQLЛђSparkГЬађОЭФмЭъГЩвьЙЙЪ§ОндДЕФСЊАюЗжЮіЃЌжЇГжЖржжЪ§ОнИёЪНЃЈCSVЁЂJSONЁЂParquetЁЂORCЁЂCarbonDataЕШЃЉКЭдЦЩЯЖржжЪ§ОндДЃЈOBSЁЂDWSЁЂCloudTableЁЂRDSЕШЃЉЁЃдкЖдAIФмСІЕФжЇГжЩЯЃЌЪЕЯжСЫНЋЖдЭМЦЌЁЂЪгЦЕЁЂгябдЕФДІРэЗжЮіФмСІЧЖШыдкSQLРяЃЌДцДЂКЭМЦЫузЪдДздЖЏЪЕЯжЕЏадРЉШнЁЃФПЧАЕФгІгУГЁОАжївЊАќРЈКЃСПШежОЗжЮіЁЂвьЙЙЪ§ОндДСЊАюЗжЮіКЭДѓЪ§ОнETLДІРэЁЃ
AWSЪ§ОнКўЗНАИжївЊЪЧЛљгкAWSдЦЗўЮёЃЌИУЗНАИЬсГідк AWS дЦЩЯВПЪ№ИпПЩгУЕФЪ§ОнКўМмЙЙЃЌВЂЬсЙЉгУЛЇгбКУЕФЪ§ОнМЏЫбЫїКЭЧыЧѓПижЦЬЈЃЌAWSЪ§ОнКўЗНАИжївЊНшжњСЫAmazon
S3ЁЂAWS GlueЕШAWS ЗўЮёРДЬсЙЉжюШчЪ§ОнЬсНЛЁЂНгЪеДІРэЁЂЪ§ОнМЏЙмРэЁЂЪ§ОнзЊЛЛКЭЗжЮіЁЂЙЙНЈКЭВПЪ№ЛњЦїбЇЯАЙЄОпЁЂЫбЫїЁЂЗЂВММАПЩЪгЛЏЕШЙІФмЁЃНЈСЂвдЩЯЛљДЁКѓЃЌдйгЩгУЛЇбЁдёЦфЫќДѓЪ§ОнЙЄОпРДРЉГфЪ§ОнКўЁЃ
Dell EMC Ъ§ОнКўЗНАИдђЪЧЛљгкЦфДцДЂММЪѕЃЌЫќНЋЪ§ОнКўЖЈвхЮЊвЛИіЯжДњЛЏЕФЪ§ОнВжПтЃЌЪЧПЩећКЯЪ§ОнЕФКсЯђРЉеЙДцДЂЗНАИЁЃИУЗНАИАќРЈСЫEMCаХЯЂЛљДЁЩшЪЉЁЂPivotalКЭVMwareЕФДцДЂМАДѓЪ§ОнЗжЮіММЪѕЃЌРДЪЕЯжЪ§ОнЕФДцДЂЁЂЗжЮіЁЂгІгУШ§ЯюКЫаФашЧѓЃЌжЇГжВЛЭЌЕФЪ§ОнДцДЂММЪѕЃЈData
DomainЁЂIsilonЁЂECSЃЉКЭЪ§ОнвЦЖЏММЪѕЃЈDistCpЁЂsnapshotЁЂNDMPЃЉЁЃОнГЦвбГЩЙІгІгУгквНСЦЗўЮёСьгђЃЌгУРДИФНјдЄВтадЛЄРэЙЄзївдМАЗЂЯжЪ§ОнЧїЪЦЁЃ
ЕЋзмЬхРДбдЃЌвЕНчЬсГіЪ§ОнКўНтОіЗНАИЕФЙЉгІЩЬВЂВЛЖрЃЌДѓЖрЪ§ЦѓвЕжЛЪЧдкзіетЗНУцЕФбаОПКЭЬНЫїЃЌЪ§ОнКўНтОіЗНАИжаЬсГЋЕФзджњЗжЮіЁЂЪ§ОнЩГЯфдкЪЕМЪжагІгУГЬЖШвВВЂВЛИпЁЃ
Ъ§ОнКўЕФЮДРД
Ъ§ОнКўЯрЖдгквдЭљЕФЙиЯЕаЭЪ§ОнПтЁЂДЋЭГЪНЪ§ОнВжПтЃЌИќЖрЬхЯжЕФЪЧвЛжжЪ§ОнДцДЂММЪѕЩЯЕФШкКЯЁЃЪ§ОнКўЕФЬсГіЃЌИФБфСЫгУЛЇЪЙгУЪ§ОнЕФЗНЪНЃЌЭЌЪБЃЌЪ§ОнКўвВећКЯСЫИїжжРраЭЪ§ОнЕФЗжЮіКЭДцДЂЃЌгУЛЇВЛБиЮЊВЛЭЌЕФЪ§ОнЙЙНЈВЛЭЌЪ§ОнДцДЂПтЁЃ
ЕЋЪЧЃЌЯжНзЖЮЪ§ОнКўИќЖрЪЧзїЮЊЪ§ОнВжПтЕФВЙГфЃЌЫќЕФгУЛЇвЛАужЛЯогкзЈвЕЪ§ОнПЦбЇМвЛђЗжЮіЪІЁЃЪ§ОнКўИХФюКЭММЪѕЛЙдкВЛЖЯбнЛЏЃЌВЛЭЌЕФНтОіЗНАИЙЉгІЩЬвВдкЬэМгаТЕФЬиадКЭЙІФмЃЌАќРЈМмЙЙБъзМЛЏКЭЛЅВйзїадЁЂЪ§ОнжЮРэвЊЧѓЁЂЪ§ОнАВШЋадЕШЁЃ
ЮДРДЃЌЪ§ОнКўПЩФмЛсНјвЛВНЗЂеЙЃЌзїЮЊвЛжждЦЗўЮёЫцЪБАДашТњзуЖдВЛЭЌЪ§ОнЕФЗжЮіЁЂДІРэКЭДцДЂашЧѓЃЌЪ§ОнКўЕФРЉеЙадЃЌПЩвдЮЊгУЛЇЬсЙЉИќЖрЕФЪЕЪБЗжЮіЃЌЛљгкЦѓвЕДѓЪ§ОнЕФЪ§ОнКўе§дкЯђжЇГжИќЖрРраЭЕФЪЕЪБжЧФмЛЏЗўЮёЗЂеЙЃЌ?НЋЛсЮЊЦѓвЕЯжгаЕФЪ§ОнЧ§ЖЏаЭОіВпжЦЖЈФЃЪНДјРДМЋДѓИФБфЁЃ
НсЪјгя
ДгРэТлЩЯНВЃЌЪ§ОнКўЪЧвЛжжДцДЂДѓСПИДдгИёЪНЪ§ОнЃЌБмУтЦѓвЕЪ§ОнЙТЕКЛЏЕФЪ§ОнМмЙЙЗНАИЃЌЫќвЛЗНУцНЕЕЭЪ§ОнМЏГЩГЩБОЃЌСэвЛЗНУцЮЊгУЛЇЬсЙЉИќСщЛюЕФЪ§ОнЗУЮЪжЇГжЁЃЕЋЭЌЪБЃЌИїРрЪ§ОнКўНтОіЗНАИФПЧАдкММЪѕЪЕЯжЩЯЛЙВЛЙЛГЩЪьЃЌШдДІдкбнЛЏЙ§ГЬжаЃЌЦфЗУЮЪПижЦЁЂЪ§ОнАВШЋЁЂЪ§ОнжЪСПЁЂдЊЪ§ОнЙмРэЕШЬиадШдашвЊЭъЩЦЁЃ
дкДѓЪ§Он+AIЪБДњРяЃЌДгЪ§ОнВжПтЕНЪ§ОнКўЃЌВЛНіНіЪЧЪ§ОнДцДЂМмЙЙЕФБфИяЃЌИќЪЧДѓЪ§ОнЫМЮЌЗНЪНЕФЩ§МЖЁЃЫцзХЛљгкЩюЖШбЇЯАММЪѕЕФAIгІгУашЧѓЙуЗКГіЯжЃЌашвЊЬсЙЉвЛИіЪ§ОнЦНЬЈЃЌжЇГжЖддЪМЪ§ОнЕФЧсЫЩЗУЮЪЃЌПЊеЙЫуЗЈФЃаЭбЕСЗКЭбщжЄЃЌЪ§ОнКўНтОіЗНАИНЋПЩФмГЩЮЊНтОіAIгІгУашЧѓзюКУЕФбЁдёЁЃ
|








