| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫprestoМмЙЙ,
ЕЭбгГйдРэ ,ДцДЂВхМў ,жДааЙ§ГЬ ,в§ЧцЖдБШЕШЯрЙиФкШнЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Presto ЪЧ Facebook ЭЦГіЕФвЛИіЛљгкJavaПЊЗЂЕФДѓЪ§ОнЗжВМЪН
SQL ВщбЏв§ЧцЃЌПЩЖдДгЪ§ G ЕНЪ§ P ЕФДѓЪ§ОнНјааНЛЛЅЪНЕФВщбЏЃЌВщбЏЕФЫйЖШДяЕНЩЬвЕЪ§ОнВжПтЕФМЖБ№ЃЌОнГЦИУв§ЧцЕФадФмЪЧ
Hive ЕФ 10 БЖвдЩЯЁЃPresto ПЩвдВщбЏАќРЈ HiveЁЂCassandra ЩѕжСЪЧвЛаЉЩЬвЕЕФЪ§ОнДцДЂВњЦЗЃЌЕЅИі
Presto ВщбЏПЩКЯВЂРДздЖрИіЪ§ОндДЕФЪ§ОнНјааЭГвЛЗжЮіЁЃPresto ЕФФПБъЪЧдкПЩЦкЭћЕФЯьгІЪБМфФкЗЕЛиВщбЏНсЙћЃЌFacebook
дкФкВПЖрИіЪ§ОнДцДЂжаЪЙгУ Presto НЛЛЅЪНВщбЏЃЌАќРЈ 300PB ЕФЪ§ОнВжПтЃЌГЌЙ§ 1000 Иі
Facebook дБЙЄУПЬьдкЪЙгУ Presto дЫааГЌЙ§ 3 ЭђИіВщбЏЃЌУПЬьЩЈУшГЌЙ§ 1PB ЕФЪ§ОнЁЃ
PrestoМмЙЙ
PrestoВщбЏв§ЧцЪЧвЛИіMaster-SlaveЕФМмЙЙЃЌгЩЯТУцШ§ВПЗжзщГЩ:
вЛИіCoordinatorНкЕу
вЛИіDiscovery ServerНкЕу
ЖрИіWorkerНкЕу
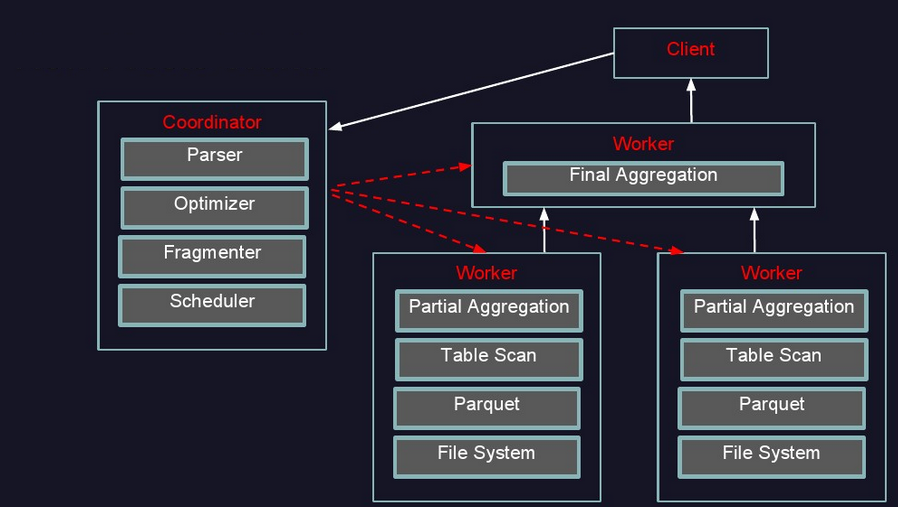
Coordinator: ИКд№НтЮіSQLгяОфЃЌЩњГЩжДааМЦЛЎЃЌЗжЗЂжДааШЮЮёИјWorkerНкЕужДаа
Discovery Server: ЭЈГЃФкЧЖгкCoordinatorНкЕужа
WorkerНкЕу: ИКд№ЪЕМЪжДааВщбЏШЮЮё,ИКд№гыHDFSНЛЛЅЖСШЁЪ§Он
WorkerНкЕуЦєЖЏКѓЯђDiscovery ServerЗўЮёзЂВсЃЌCoordinatorДгDiscovery
ServerЛёЕУПЩвде§ГЃЙЄзїЕФWorkerНкЕуЁЃШчЙћХфжУСЫHive ConnectorЃЌашвЊХфжУвЛИіHive
MetaStoreЗўЮёЮЊPrestoЬсЙЉHiveдЊаХЯЂ
ИќаЮЯѓМмЙЙЭМШчЯТЃК
PrestoЕЭбгГйдРэ
ЭъШЋЛљгкФкДцЕФВЂааМЦЫу
СїЫЎЯпЪНМЦЫузївЕ
БОЕиЛЏМЦЫу
ЖЏЬЌБрвыжДааМЦЛЎ
GCПижЦ
PrestoДцДЂВхМў
PrestoЩшМЦСЫвЛИіМђЕЅЕФЪ§ОнДцДЂЕФГщЯѓВуЃЌ РДТњзудкВЛЭЌЪ§ОнДцДЂЯЕЭГжЎЩЯЖМПЩвдЪЙгУSQLНјааВщбЏЁЃ
ДцДЂВхМўЃЈСЌНгЦї,connectorЃЉжЛашвЊЬсЙЉЪЕЯжвдЯТВйзїЕФНгПкЃЌ АќРЈЖддЊЪ§ОнЃЈmetadataЃЉЕФЬсШЁЃЌЛёЕУЪ§ОнДцДЂЕФЮЛжУЃЌЛёШЁЪ§ОнБОЩэЕФВйзїЕШЁЃ
Г§СЫЮвУЧжївЊЪЙгУЕФHive/HDFSКѓЬЈЯЕЭГжЎЭтЃЌ ЮвУЧвВПЊЗЂСЫвЛаЉСЌНгЦфЫћЯЕЭГЕФPresto СЌНгЦїЃЌАќРЈHBaseЃЌScribeКЭЖЈжЦПЊЗЂЕФЯЕЭГ
ВхМўНсЙЙЭМШчЯТЃК
prestoжДааЙ§ГЬ
жДааЙ§ГЬЪОвтЭМЃК
ЬсНЛВщбЏЃКгУЛЇЪЙгУPresto CliЬсНЛвЛИіВщбЏгяОфКѓЃЌCliЪЙгУHTTPавщгыCoordinatorЭЈаХЃЌCoordinatorЪеЕНВщбЏЧыЧѓКѓЕїгУSqlParserНтЮіSQLгяОфЕУЕНStatementЖдЯѓЃЌВЂНЋStatementЗтзАГЩвЛИіQueryStarterЖдЯѓЗХШыЯпГЬГижаЕШД§жДааЃЌШчЯТЭМ:ЪОР§SQLШчЯТ

select c1.rank, count(*) from dim.city c1 join dim.city
c2 on c1.id = c2.id where c1.id > 10 group by c1.rank
limit 10;
ТпМжДааЙ§ГЬЪОвтЭМШчЯТЃК
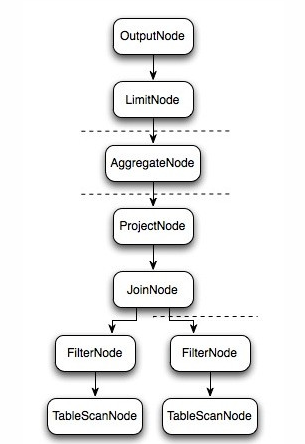
ЩЯЭМТпМжДааМЦЛЎЭМжаЕФащЯпОЭЪЧPrestoЖдТпМжДааМЦЛЎЕФЧаЗжЕуЃЌТпММЦЛЎPlanЩњГЩЕФSubPlanЗжЮЊЫФИіВПЗжЃЌУПвЛИіSubPlanЖМЛсЬсНЛЕНвЛИіЛђепЖрИіWorkerНкЕуЩЯжДаа
SubPlanгаМИИіживЊЕФЪєадplanDistributionЁЂoutputPartitioningЁЂpartitionByЪєадећИіжДааЙ§ГЬЕФСїГЬЭМШчЯТЃК
PlanDistributionЃКБэЪОвЛИіВщбЏНзЖЮЕФЗжЗЂЗНЪНЃЌЩЯЭМжаЕФ4ИіSubPlanЙВга3жжВЛЭЌЕФPlanDistributionЗНЪН
SourceЃКБэЪОетИіSubPlanЪЧЪ§ОндДЃЌSourceРраЭЕФШЮЮёЛсАДееЪ§ОндДДѓаЁШЗЖЈЗжХфЖрЩйИіНкЕуНјаажДаа
FixedЃК БэЪОетИіSubPlanЛсЗжХфЙЬЖЈЕФНкЕуЪ§НјаажДааЃЈConfigХфжУжаЕФquery.initial-hash-partitionsВЮЪ§ХфжУЃЌФЌШЯЪЧ8ЃЉ
NoneЃК БэЪОетИіSubPlanжЛЗжХфЕНвЛИіНкЕуНјаажДаа
OutputPartitioningЃКБэЪОетИіSubPlanЕФЪфГіЪЧЗёАДееpartitionByЕФkeyжЕЖдЪ§ОнНјааShuffleЃЈЯДХЦЃЉЃЌ
жЛгаСНИіжЕHASHКЭNONE
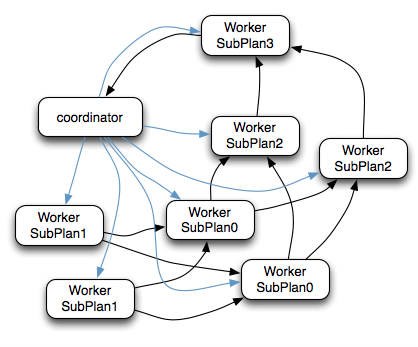
дкЩЯЭМЕФжДааМЦЛЎжаЃЌSubPlan1КЭSubPlan0 PlanDistribution=SourceЃЌетСНИіSubPlanЖМЪЧЬсЙЉЪ§ОндДЕФНкЕуЃЌSubPlan1ЫљгаНкЕуЕФЖСШЁЪ§ОнЖМЛсЗЂЯђSubPlan0ЕФУПвЛИіНкЕуЃЛSubPlan2ЗжХф8ИіНкЕужДаазюжеЕФОлКЯВйзїЃЛSubPlan3жЛИКд№ЪфГізюКѓМЦЫуЭъГЩЕФЪ§ОнЃЌШчЯТЭМЃК

SubPlan1КЭSubPlan0 зїЮЊSourceНкЕуЃЌЫќУЧЖСШЁHDFSЮФМўЪ§ОнЕФЗНЪНОЭЪЧЕїгУЕФHDFS
InputSplit APIЃЌШЛКѓУПИіInputSplitЗжХфвЛИіWorkerНкЕуШЅжДааЃЌУПИіWorkerНкЕуЗжХфЕФInputSplitЪ§ФПЩЯЯоЪЧВЮЪ§ПЩХфжУЕФЃЌConfigжаЕФquery.max-pending-splits-per-nodeВЮЪ§ХфжУЃЌФЌШЯЪЧ100
SubPlan1ЕФУПИіНкЕуЖСШЁвЛИіSplitЕФЪ§ОнВЂЙ§ТЫКѓНЋЪ§ОнЗжЗЂИјУПИіSubPlan0НкЕуНјааJoinВйзїКЭPartial
AggrВйзї
SubPlan0ЕФУПИіНкЕуМЦЫуЭъГЩКѓАДGroupBy KeyЕФHashжЕНЋЪ§ОнЗжЗЂЕНВЛЭЌЕФSubPlan2НкЕу
ЫљгаSubPlan2НкЕуМЦЫуЭъГЩКѓНЋЪ§ОнЗжЗЂЕНSubPlan3НкЕу
SubPlan3НкЕуМЦЫуЭъГЩКѓЭЈжЊCoordinatorНсЪјВщбЏЃЌВЂНЋЪ§ОнЗЂЫЭИјCoordinator
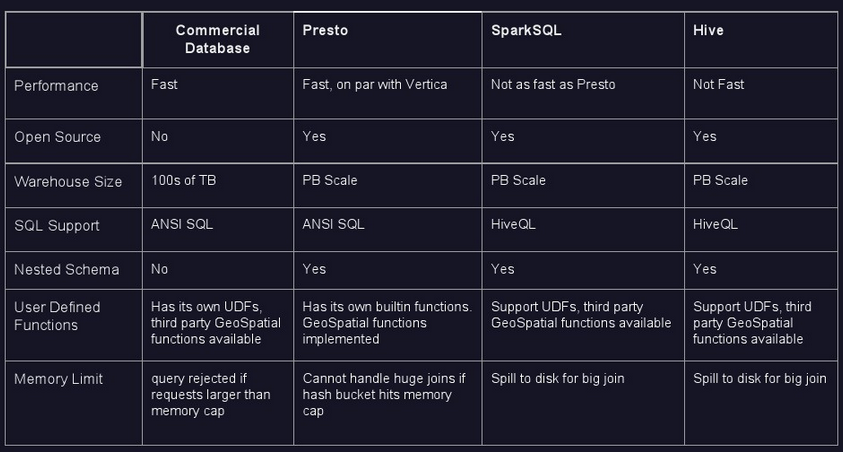
prestoв§ЧцЖдБШ
гыhiveЁЂSparkSQLЖдБШНсЙћЭМ
|








