| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЖдвјааФГЯЕЭГЕФДѓБэЁЂШШБэЕФЪ§ОнЗжЮіКЭгХЛЏНЧЖШЃЌВћЪіЖдДѓЪ§ОнСПБэНјааЕФДцДЂгХЛЏЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЫцзХвЕЮёЕФбИЫйЗЂеЙЃЌХЉвЕвјааФГЯЕЭГГаЕЃЕФдЫаабЙСІдНРДдНДѓЁЃЯжНзЖЮЃЌ
ИУЯЕЭГУПЬьЕФНЛвзСПдк2300 ЭђБЪвдЩЯЃЌЗхжЕДя2950 ЭђБЪЁЃНЛвзСПЕФХЪЩ§ЕМжТСЫКѓЬЈЪ§ОнПтЪ§ОнСПЕФМЄдіЃЌДгЖјгАЯьСЫСЊЛњГЬађЯьгІЪБМфЃЌвВдіМгСЫЯЕЭГИїРрзЪдДПЊЯњКЭКѓајЪ§ОнЗжЮіЕФДІРэЪБМфЁЃЮЊБЃеЯЯЕЭГЮШЖЈдЫааЃЌЯюФПзщДгдіМгЯЕЭГзЪдДЁЂгХЛЏзЪдДХфжУЁЂгХЛЏжиЕуГЬађКЭЩ§МЖЯЕЭГЪ§ОнПтЕШЖрИіЮЌЖШЖдЯЕЭГНјааСЫзлКЯгХЛЏЁЃЯТУцБЪепДгДѓБэЁЂШШБэЕФЪ§ОнЗжЮіКЭгХЛЏНЧЖШЃЌВћЪіЖдДѓЪ§ОнСПБэНјааЕФДцДЂгХЛЏЁЃ
вЛЁЂДѓБэЪ§ОнЗжЮі
ФПЧАХЉвЕвјааФГЯЕЭГЙЄзїСїЪ§ОнСПзюДѓЧвЗУЮЪзюЦЕЗБЕФСНеХКЫаФБэЃК
(1)СїГЬЪЕР§БэЃЌгУгкДцДЂЯЕЭГЗЂЦ№ЕФЫљгаСїГЬЪЕР§ЃЌАќРЈЛљБОСїГЬЁЂЛсЧЉСїГЬЁЂВЙГфзЪСЯСїГЬКЭГЫЭСїГЬ;
(2)ШЮЮёЪЕР§БэЃЌгУгкДцДЂУПИіСїГЬЪЕР§ЕФСїзЊМЧТМЁЃ
НижС2013 Фъ4 дТ1 ШеЃЌ ЙЄзїСїСНеХДѓБэЕФЪ§ОнСПШчБэ1 ЫљЪОЁЃЦфжаШЮЮёЪЕР§БэЮЊЯЕЭГжаЪ§ОнСПзюДѓЕФвЛеХБэЃЌДяЕНСЫ1.2
вкЁЃИљОнProDBA зЅШЁЕФжДааДЮЪ§зюЖрЧвжДааЪБМфзюГЄЕФЧА30 ЬѕSQL аХЯЂжаЃЌЯдЪОСїГЬЪЕР§БэКЭШЮЮёЪЕР§БэбЙСІБШНЯДѓЁЃДѓБэжаЕФЪ§ОнАДееНсЪјЪБМфКЭзДЬЌСНИіЮЌЖШПЩвдЧјЗжЮЊШ§РрЃК
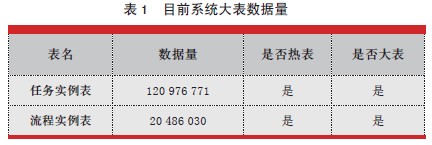
(1)е§дкдЫааЕФСїГЬЪ§ОнЃЌМДвЕЮёе§дкАьРэЙ§ГЬжаЃЌЩаЮДНсЪј;
(2)вбНсЪјСїГЬвЛФъФкЕФЪ§ОнЃЌМДвЕЮёзмЬхСїГЬвбОНсЪјЃЌЦкЯодквЛФъФк(АќКЌвЛФъ);
(3)вбОНсЪјСїГЬвЛФъвдЩЯЕФЪ§ОнЃЌМДвЕЮёзмЬхСїГЬвбОНсЪјЃЌЦкЯодквЛФъвдЩЯ(ШчБэ2 ЫљЪО)ЁЃЪТЪЕЩЯЃЌгЩгкДцдквЕЮёжЦЖШЕШЗНУцЕФЙцЖЈЃЌвбОНсЪјвЛФъвдЩЯЕФЪ§ОнЛљБОДІгкОВЬЌЮоБфЛЏЕФЧщПіЃЌВЛЛсЗЂЩњаоИФЁЂЩОГ§ЕШЪ§ОнВйзїЃЌЕЋЪЧеМОнСЫвЛЖЈЕФБэПеМфЃЌЭЌЪБвВгАЯьСЫЖдЦфЫћдЫаажаЪ§ОнЕФЗУЮЪаЇТЪЁЃЮЊНЕЕЭДѓЪ§ОнСПЖдЯЕЭГЗУЮЪЕФгАЯьЃЌашжЦЖЈЧЈвЦЙцдђЃЌНјааЪ§ОнВ№ЗжЁЃ

ЖўЁЂВ№ЗжЙцдђ
ИљОнЩЯЪіДѓЪ§ОнБэЕФЪ§ОнЗжВМЬиЕуЃЌНЈСЂШ§ЬзБэНсЙЙЃКдЫааБэЁЂРњЪЗБэКЭБИЗнБэЁЃдЫааБэНіДцДЂе§дкдЫааЕФСїГЬЪ§ОнЃЌСїГЬНсЪјКѓ(е§ГЃЭъГЩЛђепжежЙ)НЋЛљБОСїГЬвдМАЦфЫљЪєзгСїГЬЯрЙиЕФЫљгаЪ§Он(СїГЬЪЕР§ЁЂШЮЮёЪЕР§ЁЂСїГЬБфСПЁЂвьГЃЁЂЗжжЇЕШ)ЪЕЪБЧЈвЦжСРњЪЗБэЁЃШчвЕЮёашвЊНЋвбНсЪјЕФСїГЬЛжИДЃЌЯЕЭГжЇГжСїГЬДгРњЪЗБэЪЕЪБЧЈЛиЕНдЫааБэМЬајСїзЊЃЌећИіЙ§ГЬЖдгУЛЇЪЧЭъШЋЭИУїЕФЁЃ
гЩгквбЭъГЩКЭжежЙвЛФъвдЩЯЕФСїГЬЃЌашЛжИДЕФвЕЮёашЧѓКмЩй(ЯЕЭГЩЯЯпвдРДЮДЗЂЩњЙ§РрЫЦвЕЮё)ЃЌвђДЫгЩБИЗнБэДцЗХЕкШ§РрЪ§ОнЃЌаЮГЩШ§МЖДцДЂФЃЪНШчЭМ1
ЫљЪОЁЃРњЪЗБэжаЕФЪ§ОнЃЌУПФъжДаавЛДЮХњСПВ№ЗжВйзїЃЌВ№ЗжжСБИЗнБэЁЃ

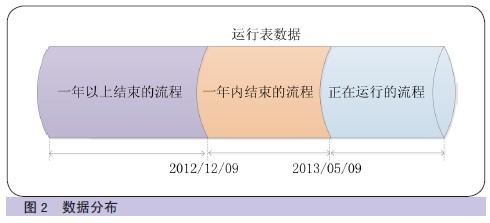
ЮЊБЃеЯЪ§ОнЦНЮШЕФЧЈвЦЃЌгІВЩШЁЗжВМЪЕЪЉЕФВпТдЁЃ2012 Фъ12 дТ8ШеЃЌСїГЬНсЪјЪ§ОнЪЕЪБЧЈвЦЕНРњЪЗБэЙІФмЯШЦкЭЖВњЃЌвђДЫФПЧАЙЄзїСїдЫааБэжаДцЗХЕФЪ§ОнАќКЌШ§жжЧщПіЃКе§дкдЫааЕФЪ§Он;2012
Фъ5 дТжС2012 Фъ12 дТНсЪјЕФСїГЬ;2012 Фъ5 дТЧАНсЪјвЛФъвдЩЯЕФСїГЬ(ШчЭМ2ЫљЪО)ЁЃ
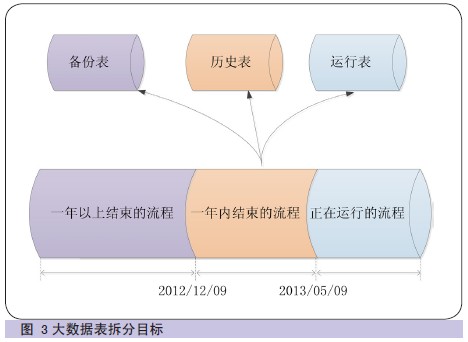
АДееЪ§ОнШ§МЖДцДЂЙцдђЃЌашвЊЖдДѓЪ§ОнБэНјааВ№ЗжЁЂАўРыМАећКЯЃЌзюжеЪЕЯждЫааБэжЛДцДЂдЫааЕФЪ§ОнЃЌНЕЕЭЯЕЭГбЙСІ(ШчЭМ3
ЫљЪО)ЁЃ
Ш§ЁЂЮЪЬтЗжЮіМАВ№ЗжВпТд
1. Ъ§ОнБэжиУќУћ
Ъ§ОнЧЈвЦЧАашвЊЖдСїГЬЪЕР§БэКЭШЮЮёБэНјааBCP Ъ§ОнБИЗнЃЌвдШЗБЃГіЯжвьГЃЧщПіЪБЃЌПЩМАЪБЛжИДЪ§ОнЁЃШЮЮёЪЕР§Бэ(1.2
вк)КЭСїГЬЪЕР§Бэ(2 ЧЇЭђ)ЃЌБИЗнЙРМЦашвЊ2~3ИіаЁЪБЁЃЪ§ОнЧЈвЦзюжевЊДяЕНдЫааБэжаНіДцЗХСїГЬе§дкдЫаажаЕФЪ§ОнЃЌвђДЫВЩШЁШчЯТВпТдЃЌНкЪЁBCP
БИЗнЪБМфЁЃ
ЪзЯШЃЌДДНЈШЮЮёЪЕР§КЭСїГЬЪЕР§жаМфБэЃЌБэНсЙЙКЭдЫааБэБЃГжЭъШЋвЛжТ;ЦфДЮЃЌНЋдЫааБэжае§дкдЫааЕФЪ§ОнЧЈвЦжСжаМфБэ;дйДЮЃЌЖдСїГЬдЫааБэКЭжаМфБэжиУќУћЃЌЪЕЯжжаМфБэзЊЛЛЮЊдЫааБэЃЌдЫааБэзЊЛЛЮЊБИЗнБэЁЃШчГіЯжЪ§ОнЧЈвЦвьГЃКЭбщжЄВЛЭЈЙ§ЕШЧщПіЃЌгЩгкБИЗнБэБЃДцСЫЧЈвЦЕБШеЕФШЋСПЪ§ОнЃЌвђДЫЃЌдйДЮжДааЪ§ОнБэжиУќУћМДПЩНтОіЮЪЬтЃЌЮоашдйЖдСНеХДѓБэНјааBCP
БИЗнЁЃЪ§ОнБэжиУќУћНХБОжДааЪБМфЃЌОВтЪддк1 ЗжжгФкМДПЩЭъГЩЃЌДѓДѓМѕЩйЧЈвЦЪБМфЁЃ
2. Ъ§ОнЭъећад
вЛБЪЭъећЕФСїГЬЃЌАќКЌвЛЬѕСїГЬЪЕР§КЭЖрЬѕШЮЮёЪЕР§ЃЌШЮЮёЪЕР§ИљОнСїГЬЪЕР§БрКХКЭзДЬЌЕШЪєадЃЌШЗЖЈЫљЪєСїГЬЁЃЧЈвЦЗНЗЈвЛЃКЮЊБЃеЯЧЈвЦЪ§ОнЭъећЃЌашвЊИљОнСїГЬЕФзДЬЌЃЌВщбЏСїГЬКЭЙиСЊШЮЮёЕФМЧТМЃЌвЛДЮадЧЈвЦСНеХБэЕФМЧТМЃЌШчЧЈвЦЪЇАмЭЌЪБЛиЙіЃЌвђДЫЃЌашвЊНјааШЮЮёЪЕР§БэКЭСїГЬЪЕР§БэЙиСЊЁЃПМТЧЕНСНеХБэЕФЪ§ОнСПЃЌДЫЗНАИНЋЛсЕМжТЧЈвЦаЇТЪКмЕЭЁЃОВтЪдЃЌЧЈвЦ5ЭђБЪСїГЬ(5
ЭђЬѕСїГЬКЭ36 ЭђЬѕШЮЮёМЧТМ) Ъ§ОндМ7ЗжжгЃЌбЛЗжДааЧЈвЦЃЌЧЈвЦЭъШЋВПСїГЬЪ§ОнашвЊдМ42 ИіаЁЪБЁЃ
ЮЊЬсИпВ№ЗжаЇТЪЃЌМѕЩйЖдЭЖВњЪБМфДАПкЕФеМгУЃЌЖдВ№ЗжЗНЗЈНјааСЫгХЛЏЁЃЧЈвЦЗНЗЈЖўЃКЪзЯШЃЌСїГЬЪЕР§БэАДееI
D КХЩ§ађХХСаЃЌШЁЧА50 ЭђЬѕМЧТМДцЗХжССйЪББэ;ЦфДЮЃЌНЋСйЪББэ(50 Эђ)КЭШЮЮёБэ(1.2 вк)НјааЙиСЊЃЌЧЈвЦСїГЬЫљЪєЕФЫљгаШЮЮё;дйДЮЃЌдйЧЈвЦ50
ЭђЬѕСїГЬМЧТМ;зюКѓЃЌЩОГ§СйЪББэЁЃбЛЗжДааВйзїЃЌУПДЮЧЈвЦЃЌвдЧАвЛДЮЧЈвЦЕФзюДѓI D КХЮЊЬѕМўЃЌ дйШЁ50
ЭђЬѕМЧТМЁЃДЫЗНЗЈЭЌбљПЩвдБЃеЯЪТЮёвЛжТадЃЌУПДЮЧЈвЦСНеХБэЕФЪ§ОнЃЌЕЋЪЧЩйСЫБэЙиСЊЕФЪ§ОнСПЁЃОВтЪдЃЌЧЈвЦ50
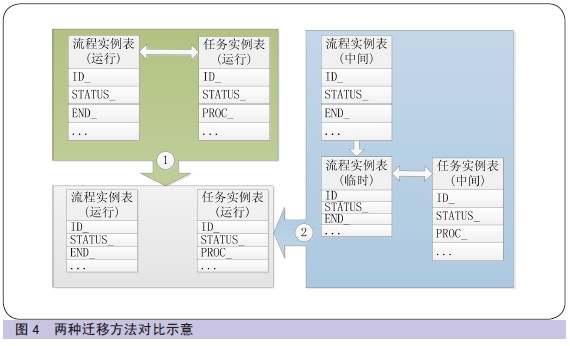
ЭђБЪСїГЬ(АќРЈСїГЬКЭШЮЮёМЧТМ)Ъ§ОндМ8 ЗжжгЃЌЧЈвЦе§дкдЫааЕФЪ§ОндЄМЦПЩдк1 ИіаЁЪБФкЭъГЩЁЃСНжжЧЈвЦЗНЗЈЖдБШЪОвтШчЭМ4ЫљЪОЁЃ
3. зддізжЖЮ
ШЮЮёЪЕР§БэКЭСїГЬЪЕР§БэЕФжїМќIDЃЌЭЌЮЊIdentity аЭзжЖЮЁЃЪ§ОнЧЈвЦЙ§ГЬжаЃЌвЊБЃГжID КХвЛжТЁЃЪзЯШЃЌНЈБэDBO
гУЛЇКЭЪ§ОнЧЈвЦВйзїгУЛЇашБЃГжвЛжТ;ЦфДЮЃЌЪ§ОнЧЈвЦНХБОжаЃЌЪЙгУSET IDENTITY_INSERT
БэУћ ON УќСюЧПжЦЙиБеЖдБэЕФзддізжЖЮЩшжУ;дйДЮЃЌ ЧЈвЦЭъГЩКѓЃЌдйЪЙгУSET IDENTITY_INSERT
БэУћ OFF УќСюдйДђПЊзддізжЖЮЩшжУЁЃ
4. ЛЎЗжЪ§ОнВ№ЗжХњДЮ
ЖдВ№ЗжВпТдКЭНХБОНјааВтЪдКЭгХЛЏКѓЃЌЭъГЩШЋВПЧЈвЦШдШЛаш5 ИіаЁЪБзѓгвЃЌвђДЫПМТЧЗжХњДЮжДааЁЃдкЪ§ОнВ№ЗжЙцдђжаЃЌЪ§ОнБЛЧјЗжЮЊШ§РрЃЌИљОнДЫЙцдђЧЈвЦЗжЮЊСНИіХњДЮЃКвЛЪЧжДааЧЈвЦе§дкдЫааЕФЪ§Он;ЖўЪЧжДааЧЈвЦвбОЭъГЩСїГЬвЛФъФкЕФЪ§ОнЁЃОЁПЩФмМѕаЁСНХњДЮжДааЕФЪБМфМфИєЁЃЕквЛХњДЮжДааЭъГЩКѓЃЌСїГЬдЫаажаЕФЪ§ОнВЛЪмгАЯьЃЌвЛФъФквбНсЪјЕФСїГЬШчашЛжИДЃЌНЋЪмЕНгАЯьЁЃПМТЧЕНвЕЮёЕФЪЕМЪАьРэЧщПіЃЌСїГЬНсЪјКѓдйДЮБЛЛжИДЕФЧщПіКмЩйЃЌвђДЫЗжСНИіХњДЮжДааЕФгАЯьУцЛ§НЯаЁЁЃ
ЫФЁЂЪ§ОнЧЈвЦЗНАИЪЕМљ
вдЧЈвЦе§дкдЫааЕФЪ§ОнЮЊР§ЃЌВћЪіЪ§ОнЧЈвЦЙ§ГЬЁЃЧЈвЦСїГЬНсЪјвЛФъФкЕФЪ§ОнЕНРњЪЗБэЕФВйзїЙ§ГЬЭЌДЫЃЌВЛдйзИЪіЁЃ
1. ВйзїВНжш
ЕквЛЃЌжДааНХБОВщбЏСїГЬЪЕР§БэКЭШЮЮёЪЕР§БэЃЌЛёШЁЪ§ОнвдБИбщжЄЁЃЭЌЪБВщбЏзюДѓСїГЬКЭШЮЮёI DКХЃЌ
вдБИдкВНжшСљжаЩшжУзддіЦ№ЪМжЕЁЃ
ЕкЖўЃЌДДНЈжаМфБэЃЌБэНсЙЙКЭдЫааБэБЃГжвЛжТЁЃ
ЕкШ§ЃЌ ЧЈвЦЮДЭъГЩСїГЬЪ§ОнЃЌУПДЮЧЈвЦ50 ЭђИіСїГЬЃЌМьВщШежОФкШнЃЌжБЕНжДаагАЯьНсЙћВЛзу50 ЭђИіЃЌжЄУїЪ§ОнЧЈвЦЭъГЩЁЃ
ЕкЫФЃЌжДааЪ§ОнбщжЄНХБОЃЌБШНЯДЫНХБОЕФжДааНсЙћКЭВНжш1 жаЕФжДааНсЙћЪЧЗёвЛжТЁЃШчВЛвЛжТЃЌКѓајВНжшВЛдйжДааЁЃ
ЕкЮхЃЌжДааНХБОЖдСїГЬдЫааБэКЭжаМфБэжиУќУћЃЌжДааЭъГЩКѓбщжЄБэНсЙЙЪЧЗёвЛжТЁЃ
ЕкСљЃЌИљОнВНжшвЛЕФВщбЏНсЙћЃЌЩшжУдЫааБэзддізжЖЮЕФЦ№ЪМжЕЁЃ
ЕкЦпЃЌПЊЦєЙЄзїСїWASЃЌгЩПЊЗЂШЫдБНјаабщжЄЁЃШчбщжЄЭЈЙ§ЃЌЙиБеЙЄзїСїWAS ;ШчбщжЄВЛЭЈЙ§ЃЌжДаагІМБЗНАИЁЃжДааЭъГЩКѓдйДЮНјаабщжЄЁЃ
ЕкАЫЃЌНјаадЫааБэЕФЫїв§ЭГМЦжЕИќаТ(ШчЭМ5 ЫљЪО)ЁЃ
2. гІМБЗНАИ
(1)вьГЃЧщПівЛЃКжДааЧЈвЦНХБОГіЯжЪБМфГЌГЄЕШвьГЃЧщПіЃЌдкМЦЛЎЪБМфДАПкФкВЛФме§ГЃжДааЭъГЩЁЃгІМБЗНАИЃКЧЈвЦНХБОЮДЖддЫааБэНјааИќаТКЭЩОГ§ЕШВйзїЃЌЪ§ОнЮДЪмгАЯьЃЌвђДЫКѓајВйзїВНжшВЛдйжДааЃЌЩОГ§жаМфБэМДПЩЁЃ
(2)вьГЃЧщПіЖўЃКЪ§ОнВ№ЗжЭъГЩЃЌПЊЦєЙЄзїСїWAS бщжЄЃЌПЊЗЂШЫдБбщжЄВЛЭЈЙ§ЁЃгІМБЗНАИЃКжДааНХБОНЋдЫааБэИќУћЮЊжаМфБэЃЌБИЗнБэИќУћЮЊдЫааБэЃЌжДааЭъГЩКѓЃЌдйДЮгЩПЊЗЂШЫдБНјаабщжЄЃЌбщжЄЭЈЙ§ЩОГ§жаМфБэЁЃ
3. Ъ§ОнСПБШНЯ
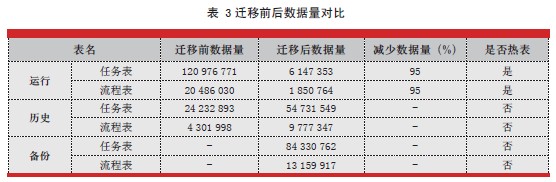
ОЙ§СНТжЧЈвЦЃЌЪ§ОнСПЖдБШШчБэ3 ЫљЪОЃЌДгжаПЩвдПДГіЗУЮЪзюЦЕЗБЕФдЫааБэЪ§ОнСПМѕЩй95%ЁЃ
4. НсТл
Ъ§ОнОЙ§В№ЗжЁЂАўРыМАећКЯКѓаЮГЩСЫШ§МЖДцДЂФЃЪНЁЃСїГЬНсЪјКѓЪ§ОнЪЕЪБзЊвЦЕНРњЪЗБэЃЌЖјдЫааБэЪ§ОндіСПБфЛЏВЛДѓЃЌвђДЫгааЇНтОіСЫгЩгкЪ§ОнСПОоДѓДјРДЕФЪ§ОнЗУЮЪЯьгІЪБМфГЄЕШЮЪЬтЃЌЬсЩ§СЫЯЕЭГадФмЁЃ
ЮхЁЂЮДРДЙцЛЎ
Ъ§ОнЧЈвЦЭъГЩКѓЃЌИљОнЪ§ОндіГЄЬиЕуЃЌУПФъЖдРњЪЗБэЪ§ОнНјаавЛДЮХњСПЧЈвЦЃЌЧЈвЦжСБИЗнБэДцДЂЃЌЖјдЫааБэЪ§ОнВЛЪмгАЯьЃЌ
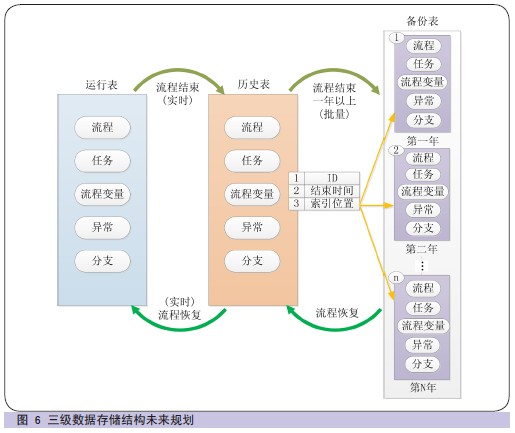
МДЯћГ§Бэ 3 ЧЈвЦЧАКѓЪ§ОнСПЖдБШСЫЖддЫаажаСїГЬЕФгАЯьЁЃгЩДЫДјРДБИЗнБэЪ§ОнвВНЋВЛЖЯдіДѓЁЃБИЗнБэЕФДцДЂВЩгУЫїв§ДцДЂЗНЪНЃЌдіМгБИЗнЪ§ОнЫїв§Бэ(
ШчЭМ6 ЫљЪО)ЁЃЮЊзіЕНЖдвЕЮёВйзїЕФЭъШЋЭИУїЃЌ ШчашЖдБИЗнБэЕФЪ§ОнЛжИДЃЌдђИљОнЫїв§ЖЈЮЛСїГЬЪ§ОнЃЌ ЫѕаЁЪ§ОнВщбЏЗЖЮЇЃЌ
зюжеНЕЕЭЯЕЭГЯьгІЪБМфЁЃБИЗнБэжаЪ§ОнвВПЩзЊвЦжСЦфЫћДцДЂЩшБИНјааБЃДцЁЃЖдБИЗнБэжаЪ§ОнВщбЏашЧѓЃЌ ЬсЙЉЕЅЖРЕФВщбЏЁЂЭГМЦМАЗжЮіЗўЮёЁЃ
|








