| 编辑推荐: |
本文主要介绍了yarn核心思想、工作机制概述、组件简介、YARN的资源模型、组件功能等相关内容。
本文来自开源中国,由火龙果软件Anna编辑、推荐。 |
|
1、yarn产生背景
mapReduce存在问题:
JobTracker单点故障
JobTracker承受的访问压力大,影响系统扩展
不支持MapReduce之外的计算框架,比如Storm,spark,flink
2、yarn的核心思想
是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。
它由下面几大构成组件:
ResourceManager:负责为集群中的所有应用程序分配资源
每个节点代理 的NodeManager
每个应用对应一个ApplicationMaster
一个ApplicationMaster拥有多个Container,Containner在NodeManager上运行
运行在独立节点上的RM和NM一起组成了YARN的核心且构成了这个平台。AM和相应的Container一起组成了一个Yarn的应用程序。从YARN的角度来看,所有用户通过提交应用程序,然后利用该平台提供的资源来进行交互。从最终用户的角度看,他们可能是直接在YARN平台上通过运用应用程序和YARN进行交互。
3、工作机制概述

Client向RM提交应用程序,应用程序提交到RM后,AM注册到RM上,RM计算所需资源并向RM提出申请,RM返给AM资源信息,AM向NM发起启动container的请求,container启动后,NM将启动成功和启动失败的container列表发送给AM,由AM重新向RM申请资源,期间AM和NM定期的向RM发送心跳。
4、组件简介
4.1、ResourceManager(RM)
RM作为一个独立的守护进程运行在专有机器上,RM拥有集群上所有资源的信息,是集群所有资源的仲裁者,只负责给应用进行资源的划分和资源的收回。这里的资源主要指:内存,带宽,内核数等。
4.2、ApplicationMaster(AM)
ApplicationMaster管理一个在YARN内运行的应用程序的每个实例,每个应用程序对应唯一一个AM。
负责管理作业的生命周期,包括动态的增加和减少资源使用,管理作业执行流程,处理故障和计算偏差,以及执行其本地优化。
4.3、NodeManager(NM)
管理集群中独立的计算节点。
NM是每个节点上的资源和任务管理器。一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container运行状态;另一方面,它接收并处理来自AM的
Container 启动/停止等各种请求。
4.4、Container
Container是YARN中的资源抽象,是单个节点上内存,CPU,磁盘,网络等物理资源的集合。一个节点可以有一个或者多个container,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。其中AM可以看做是一种特殊的Container。
container由NM监控,RM调度。
5、YARN的资源模型
在早期的 Hadoop版本中,集群中的每个节点被静态的分配好预先定义的Map槽位和Reduce槽位数,槽位不能在Map和
Reduce之间共享。槽位的这种静态分配不是最优的,因为对槽位的需求会在MapReduce应用程序的生命周期中变化。通常情况下,在作业刚启动时,有Map槽位的需求,相对的,在作业快结束时,主要是
Reduce槽位的需求。
YARN的资源分配模型通过提供了更大的灵活性,解决了静态分配的低效率问题。如先前所述,使用 Container的方式来请求资源,每个
Container都有一些非静态属性,YARN目前已经支持内存和CPU的动态属性,还可以支持如带宽和GPU等。在未来的资源管理模型中,每个属性定义一个最小和最大值,
ApplicationManager可以请求最小值整数倍的资源container。在应用运行的过程中,AM可以对资源进行增加或者回收,达到动态调整资源的目的。

5.1、客户端资源请求
第一步:客户发送一个即将要提交程序的请求
第二步:RM在应答中给出一个ApplicationID,以及有助于客户端请求资源的就请你容量信息
5.2、Container分配
接下来,客户端在第3步中使用“ Application Submission Context”发出响应,
Application
Submission上下文中包含了 ApplicationID、用户名、队列以及其他启动 Application
Master所
需求(内存CPU)、作业文件、安全令牌以及在节点上启动 Application Master 需要的其他信息。应用程序被提交之后,客户端也可以向
ResourceManager请求杀死这个应用程序,或者提供该应用程序的状态报告
当ResourceManager收到来自客户端的应用程序提交上下文,它就会为ApplicationMaster调度一个可用
Container,这个 Container通常称为“ Container0”",因为它是ApplicationMaster,必须请求其他的
Container。如果没有适用的 Container,这个请求必须等待。如果找到了合适的 Container,
ResourceManager就会联系相应的 NodeManager并启动 ApplicationMaster(图第4步)。作为此步骤的一部分,将建立
ApplicationMaster的RPC端口和用于跟踪的URL,用来监控应用程序的状态。
在注册请求的响应中, ResourceManager会发送关于集群的最小和最大容量信息(第5步)。在这一点上,
ApplicationMaster须决定如何使用当前可用的资源。与一些客户端请求硬限制的资源调度系统不同,YARN允许应用程序适应当前的集群环境(如果可能的话)。基于来自
ResourceManager的可用资源报告, ApplicationMaster会请求一定量的Container(图第6步)。该请求可以非常具体,包括最小资源整数倍的
Container(例如,额外的内存)。 ResourceManager会基于调度策略,尽可能最优的Application
Master分配Container资源,作为资源请求的应答发给 Application Master(图第7步)。
随着作业的执行, ApplicationMaster将心跳和进度信息通过心跳发给 ResourceManager。在这些心跳中,
ApplicationMaster还可以请求和释放 Container,当作业结束时, Application
Master向 ResourceManager发出一个 Finish消息,然后退出。
5.3、ApplicationMaster与Container管理器的通信

在这一点上, ResourceManager已经将分配 NodeManager的控制权移交给ApplicationMaster
,AM将独立联系其指定的节点管理器并提供 Container launch Context(CLC),CLC包括环境变量、远程存储依赖文件、安全令牌以及启动实际进程所需的命令。当
Container启动时,所有的数据文件,可执行文件以及必要的依赖文件都被拷贝到节点的本地存储上了。依赖文件可以被运行中的应用程序的
Container之间共享。一旦所有的 Container都被启动, ApplicationMaster就可以检查它们的状态,
RM不参与应用程序的执行,只处理调度和监控其他资源。 RM可以命令NM杀死Container,在AM通知RM自己完成了,或者ResourceManager需要为另一个应用程序抢占资源,或者
Container超出资源限制时都可能发生杀死 Container事件。当 Container被杀死后,
NodeManager会清理它的本地工作目录。作业结束后, ApplicationMaster通知
ResourceManager该作业成功完成,然后ResourceManager通知 NodeManager聚集日志并且清理
Container专用的文件。如果 Container还没有退出NodeManager也可以接受指令去杀死剩余的
Container(包括 ApplicationMaster)。
5.4、管理应用程序的依赖文件
在YARN中,应用程序通过运行 Container来执行它们的工作,这些 Container对应于运行在底层操作系统上的进程。
Container上有执行程序依赖的文件,这些文件在启动时或者应用程序的执行过程中可能需要一次或者多次。例如,要在
Container中启动一个简单的Java进程,我们需要一组类文件或更多依赖的JAR文件。YARN没有强迫每个应用程序每次都远程访问(大部分是读)这些文件或者让它们自己管理这些文件,而是为应用程序提供了本地化这些文件的能力。
当启动一个 Container时, Application Master可以指定该 Container需要的所有文件,因此,这些文件都应该被本地化。一且指定了这些文件,YARN就会负责本地化,并且隐藏所有安全拷贝、管理以及后续的删除等引入的复杂性。
6、组件功能
6.1、ResourceManager
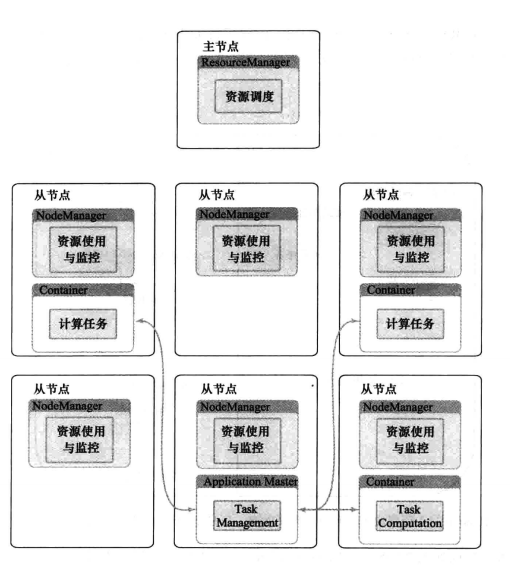
如前所述,RM是Master,仲裁集群中所有的可用资源,从而帮助管理运行在yarn平台上的分布式应用程序,他和厦门的组件一起工作:
每个节点的NM。从RM中获取指令,管理单个节点上的可用资源,并接收AM的资源请求。
每个应用程序的AM,职责是向RM申请资源并且和NM一起工作、启动、监控和停止Container。
6.2、NodeManager
NM是yarn在每个计算节点上的代理,他根据yarn应用程序的要求,使用每个节点上的物理资源来运行Container。NM本质上是YARN的工作守护进程。主要职责是:
保持与RM的同步
跟踪节点的健康状态
管理Container的生命周期,监控每个Container的资源使用情况(如内存,CPU等)
管理分布式缓存(对container所需的JAR,库等文件的本地文件系统缓存)
管理各个Container的日志
不同的YARN应用可能需要的辅助服务
其中Container的管理是NodeManager的核心功能。NodeManager接受来自ApplicationMaster对Container启动或者停止请求,对Container令牌进行鉴权(一种确保应用程序可以适当使用ResourceManager给定资源的安全机制),管理
Container执行依赖的库,监控 Container的执行过程。管理员通过配置文件( yarn-default.
xml或yarm- site.xml)来配置每个 NodeManager的资源,包括节点上的内存、CPU及其他可用资源。在向
ResourceManager成功注册之后, NodeManager通过周期性的心跳汇报自己的状态并接收
ResourceManager可能发来的指令。
在YARN中,包括 ApplicationMaster在内的所有 Container都通过 Container
launch
Context(CLC)来描述。CLC包括环境变量,依赖的库(可能存在远程存储中),下载库文件以及
Container自身运行需要的安全令牌,用于 NodeManager辅助服务的 Container专用的载荷,以及启动进程所需的命令。在验证启动
Container请求的有效性后, NodeManager会为Container配置环境,从而使管理员指定的设置生效。
在真正拉起一个 Container之前, NodeManager会将所有需要的库文件下载到本地,包括数据文件,可执行文件、
tarball、JAR文件,shel脚本等。这些下载好的库文件可以通过本地应用级别缓存被同一应用的多个
Container共享,通过本地用户级别缓存被相同用户启动的多个 Container共享,甚至通过公用缓存的方式被多个用户共享,其共享方式是通过CLC来指定的。
NodeManager最终会回收不再被任何 Container使用的库文件NodeManager也可能按照
ResourceManager的指令去杀死 Container。 Container可能在以下情况下被杀死:
ResourceManager发送应用程序已经完成的信号
调度器作出要为其他应用程序或者用户抢占该 Container的决策
NodeMananger监控到这个 Container超出了 ContainerToken中指定的资源限制
Container退出时, Node Manager就会清理掉它的本地工作目录。当应用程序完成时,其对应的
Container所有的资源都会被清理掉。
除了 Container的启动和停止,完成 Container的清理,以及对本地资源的管理Node
Manager还为运行在本节点上的 Container提供了其他本地服务,例如:当应用程序 束时,日志聚集服务可以将应用程序的
Container生成的日志以及对 stdout和 stderr重定向的文件上传到一个文件系统如 ResourceManager那一节所述,当有
NodeManager失败时(这可能由很多原因引), ResourceManager通过超时机制监控到这种失败,并将该失败报告给所有运行中的应用程序。如果引发超时的故障或原因是瞬时的,
NodeManager会与 ResourceManager重新同步,清理它的本地状态,然后继续服务。同样的,当一个新的
NodeManager加入到集群 ResourceManager会将这个用于运行 Container的新资源通知所有的
ApplicationMastser.
6.3、ApplicationMaster
每个应用程序AM都是一个引导进程,一但应用程序的提交通过了,且自身加载完成,应用程序在RM中的代表将申请一个Container来启动此引导程序,如果RM分配了Container,AM的启动器将直接与NM进行通讯,以设置并启动该container,AM的生命周期就开始了。与hadoop1中的架构相比,本质上AM是一个应用程序的JobTracker。

这个过程以应用程序提交一个请求到 ResourceManager开始。接着, ApplicationMaster启动,向
ResourceManager注册。 ApplicationMaster向 ResourceManager请求
Container执行实际的工作。将分配的 Container告知 NodeManager以便 ApplicationMaster使用。计算过程在
Container 中进行,这些 Container将与 Application Master(不是
ResourceManager)保持通信,并告知任务过程。当应用程序完成后, Container被停止,
ApplicationMaster从 ResourceManager中注销
一旦成功启动, Application Master将负责以下任务:
初始化向 ResourceManager报告自己活跃信息的进程
计算应用程序的资源需求
将需求转换成YARN调度器可以理解的 ReqsourceReques
与调度器协商申请资源
与 NodeManager合作使用分配的 Container
跟踪正在运行的 Container的状态,监控它们的进程
对 Container或节点失败的情况进行处理,在必要的情况下重新申请资源
6.4、Container

Application Master从 ResourceManager获得 Container后,它就可以进行
Container的实际启动工作。启动 Container前,它首先根据需要构造 ContainerLaunchContext对象,该对象包括分配资源的大小、安全令牌(如果已启用)、启动
Container的执行命令、进程环境、必要的二进制文件/AR包/共享对象等。它可以通过与 NodeManager通信,逐一启动Container,也可以批量运行单个节点上的所有Container,向
NodeManager在单个调用里提供一系列Start ContainerRequest来启动它们。
NodeManager通过 Start ContainerResponse回应:该回应包含成功启动的
Container列表、每个失败的 Start ontainerRequest对应的 Container
ID到异常的映射(记录了每个 Container的异常)、 allServices Data映射(从附加服务的名字到它们相应的元数据)。
ApplicationMaster能获取已经提交但未启动的 Container以及已经启动的 Container的更新状态。
ApplicationMaster可以向 Node Manager发送 Stop ContainersRequest请求,停止在该节点上运行的一系列
Container,该请求包含待停止的 Container ID。 NodeManager通过Stop
ContainersResponse回应,它包含成功停止的 Container的列表以及每个失败的请求中Container
id到异常的映射(异常信息表示了每个特定 Container的错误)。当 ApplicationMaster退出时,
ResourceManager将根据它提交的上下文杀死所有正在运行而没有被 ApplicatMaster显示终止的
Container
如上文所述,当 Container结束时, ResourceManager将以事件的形式通知 Application
Master
ResourceManager并不解释(也不关心) Container的状态,只有 ApplicationMaster才能决定ResourceManager报告的
Container的退出状态成功或失败的含义。
处理 Container失败是应用程序/框架的责任。YARN只负责为应用程序/框架提供信息。
ResourceManager收集所有已完成的 Container的信息,把它们作为 API allocate的回应信息部分返回给相应的
Application. ApplicationMaster负责查看如下信息: Container的状态、退出码和诊断信息,并恰当地处理它。例如,当
MapReduce Application Master知道Container失败时,它向 ResouceManager请求新的
Container,重新运行Map或 Reduce任务直到达到为单个任务配置的最大的尝试次数。
Application Master需要在由于它自身原因重启后恢复应用程序。当 Application
Master失败时, ResourceManager简单地通过重新启动一个新的 ApplicationMaster(更确切地说是运行
ApplicationMaster的 Container)来重启应用程序(新的 ApplicationMaster将启动新的Application
Attempt,恢复应用程序的先前的状态是新 Application.的责任。这个目标可以通过以下方法实现:前
ApplicationAttempt将当前状态持久化到外部存储供后面的ApplicationAttempt使用显然
ApplicationMaster也可以从头开始运行应用程序,而不是恢复其过去的状态。例如,如本书所述不
Hadoop MapReduce框架的 Application Master会恢复已完成的任务,但会杀死正在运行的任务以及在
Application Master恢复时完成的任务,然后重新运行它们。
|








