| БрМЭЦМі: |
БОЮФЪзЯШНщЩмСЫCDHКЭImpalaЕФИХФюЃЌImpala
ВйзїУќСюЃЌЦфДЮЖдЪ§ОнПтВйзїКЭDMLЪ§ОнВйзїНјааСЫВћЪіЃЌзюКѓНјааЪОР§ВщбЏЃЌДцДЂЁЂбЙЫѕКЭгХЛЏЁЃ
БОЮФРДздCSDNЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂCDHЕФНщЩм
ClouderaАцБОЃЈClouderaЁЏs Distribution Including Apache
HadoopЃЌМђГЦCDHЃЉЃЌЛљгкWebЕФгУЛЇНчУц,жЇГжДѓЖрЪ§HadoopзщМўЃЌАќРЈHDFSЁЂMapReduceЁЂHiveЁЂPigЁЂ
HBaseЁЂZookeeperЁЂSqoopЃЌМђЛЏСЫДѓЪ§ОнЦНЬЈЕФАВзАЁЂЪЙгУФбЖШЁЃ
Cloudera ManagerЕФЙІФмЃК
ЙмРэЃКЖдМЏШКНјааЙмРэЃЌШчЬэМгЁЂЩОГ§НкЕуЕШВйзїЁЃ
МрПиЃКМрПиМЏШКЕФНЁПЕЧщПіЃЌЖдЩшжУЕФИїжжжИБъКЭЯЕЭГдЫааЧщПіНјааШЋУцМрПиЁЃ
еяЖЯЃКЖдМЏШКГіЯжЕФЮЪЬтНјааеяЖЯЃЌЖдГіЯжЕФЮЪЬтИјГіНЈвщНтОіЗНАИЁЃ
МЏГЩЃКЖрзщМўНјааећКЯЁЃ
Cloudera ManagerЕФМмЙЙЃК
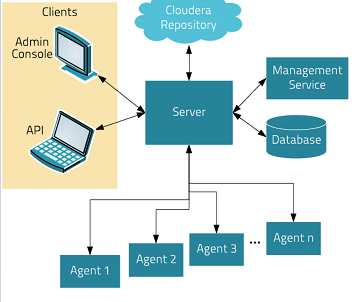
ServerЃКИКд№ШэМўАВзАЁЂХфжУЃЌЦєЖЏКЭЭЃжЙЗўЮёЃЌЙмРэЗўЮёдЫааЕФШКМЏЁЃ
AgentЃКАВзАдкУПЬЈжїЛњЩЯЁЃИКд№ЦєЖЏКЭЭЃжЙЕФЙ§ГЬЃЌХфжУЃЌМрПижїЛњЁЃ
Management ServiceЃКгЩвЛзщжДааИїжжМрПиЃЌОЏБЈКЭБЈИцЙІФмНЧЩЋЕФЗўЮёЁЃ
DatabaseЃКДцДЂХфжУКЭМрЪгаХЯЂЁЃ
Cloudera RepositoryЃКШэМўгЩClouderaЙмРэЗжВМДцДЂПтЁЃЃЈРрЫЦMavenЕФжааФВжПтЃЉ
ClientsЃКЪЧгУгкгыЗўЮёЦїНјааНЛЛЅЕФНгПкЃЈAPIКЭAdmin ConsoleЃЉ
МЏШКЬэМгЗўЮёЃК

ВщПДжїЛњзДПіЃК
ЫфШЛзДЬЌШЋКьЃЌЕЋЪЧФкДцЁЂCPUЕФзДЬЌЖМНЯКУЃЌВЂВЛгАЯьЗўЮёЕФЪЙгУЁЃ
ЖўЁЂImpalaИХФю
2.1 ЪВУДЪЧImpala
ClouderaЙЋЫОЭЦГіЃЌЬсЙЉЖдHDFSЁЂHBaseЪ§ОнЕФИпадФмЁЂЕЭбгГйЕФНЛЛЅЪНSQLВщбЏЙІФмЁЃЛљгкHiveЃЌЪЙгУФкДцМЦЫуЃЌМцЙЫЪ§ОнВжПтЁЂОпгаЪЕЪБЁЂХњДІРэЁЂЖрВЂЗЂЕШгХЕуЁЃЪЧCDHЦНЬЈЪзбЁЕФPBМЖДѓЪ§ОнЪЕЪБВщбЏЗжЮів§ЧцЁЃ

2.2 ImpalaЕФгХШБЕу
гХЕуЃК
ЛљгкФкДцдЫЫуЃЌВЛашвЊАбжаМфНсЙћаДШыДХХЬЃЌЪЁЕєСЫДѓСПЕФI/OПЊЯњ
ЮоашзЊЛЛЮЊMapReduceЃЌжБНгЗУЮЪДцДЂдкHDFSЃЌHBaseжаЕФЪ§ОнНјаазївЕЕїЖШЃЌЫйЖШПь
ЪЙгУСЫжЇГжData localityЕФI/OЕїЖШЛњжЦЃЌОЁПЩФмЕиНЋЪ§ОнКЭМЦЫуЗжХфдкЭЌвЛЬЈЛњЦїЩЯНјааЃЌМѕЩйСЫЭјТчПЊЯњ
жЇГжИїжжЮФМўИёЪНЃЌШчTEXTFILE ЁЂSEQUENCEFILEЁЂRCFileЁЂParquet
ПЩвдЗУЮЪHiveЕФmetastoreЃЌЖдHiveЪ§ОнжБНгзіЪ§ОнЗжЮі
ШБЕуЃК
ЖдФкДцЕФвРРЕДѓЃЌЧвЭъШЋвРРЕгкHive
ЪЕМљжаЃЌЗжЧјГЌЙ§1ЭђЃЌадФмбЯжиЯТНЕ
жЛФмЖСШЁЮФБОЮФМўЃЌЖјВЛФмжБНгЖСШЁздЖЈвхЖўНјжЦЮФМў
УПЕБаТЕФМЧТМ/ЮФМўБЛЬэМгЕНHDFSжаЕФЪ§ОнФПТМЪБЃЌИУБэашвЊБЛЫЂаТ
2.3 ImpalaЕФМмЙЙ
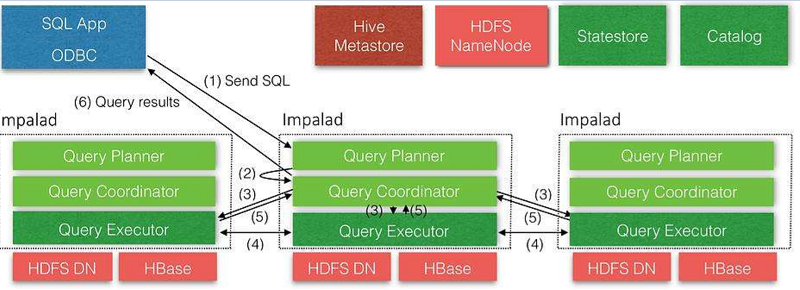
ДгЩЯЭМПЩвдПДГіЃЌImpalaздЩэАќКЌШ§ИіФЃПщЃКImpaladЁЂStatestoreКЭCatalogЃЌГ§ДЫжЎЭтЫќЛЙвРРЕHive
MetastoreКЭHDFSЁЃ
ImpaladЃКНгЪеclientЕФЧыЧѓЁЂQueryжДааВЂЗЕЛиИјжааФаЕїНкЕуЃЛзгНкЕуЩЯЕФЪиЛЄНјГЬЃЌИКд№ЯђStatestoreБЃГжЭЈаХЃЌЛуБЈЙЄзїЁЃ
CatalogЃКЗжЗЂБэЕФдЊЪ§ОнаХЯЂЕНИїИіimpaladжаЃЌНгЪеРДздStatestoreЕФЫљгаЧыЧѓЁЃ
StatestoreЃКИКд№ЪеМЏЗжВМдкМЏШКжаИїИіimpaladНјГЬЕФзЪдДаХЯЂЁЂИїНкЕуНЁПЕзДПіЃЌЭЌВННкЕуаХЯЂЃЛИКд№queryЕФаЕїЕїЖШЁЃ
2.4 ImpalaЕФЪ§ОнРраЭ
зЂвтЃКImpalaЫфШЛжЇГжArrayЃЌMapЃЌStructИДдгЪ§ОнРраЭЃЌЕЋЪЧжЇГжВЂВЛЭъШЋЃЌвЛАуДІРэЗНЗЈЃЌНЋИДдгРраЭзЊЛЏЮЊЛљБОРраЭЃЌЭЈЙ§HiveДДНЈБэЁЃ
Ш§ЁЂImpala ВйзїУќСю
3.1 ImpalaЕФЭтВПshell
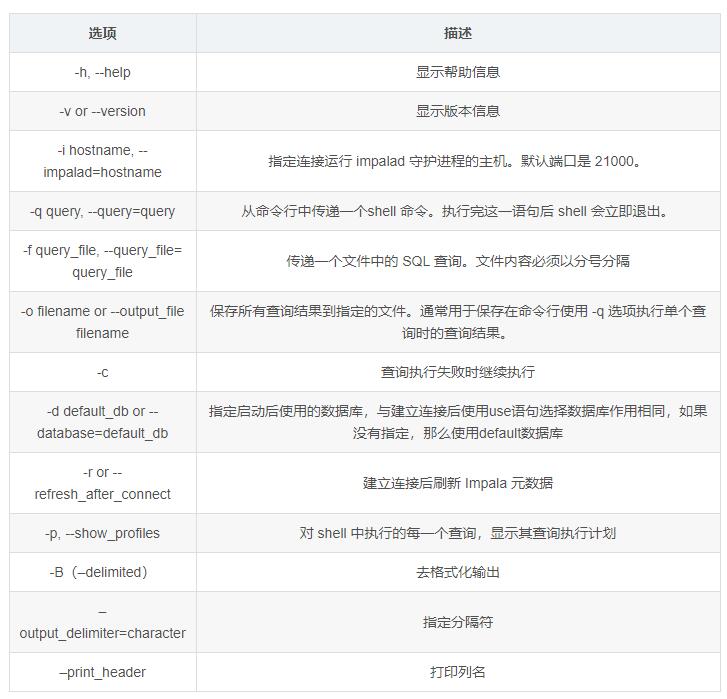
ЂйСЌНгжИЖЈhadoop101ЕФimpalaжїЛњ
| [root@hadoop100
datas]# impala-shell -i hadoop101 |
ЂкЪЙгУ-qВщбЏБэжаЪ§ОнЃЌВЂНЋЪ§ОнаДШыЮФМўжа
| [root@hadoop100
datas]# impala-shell -q 'select * from student'
-o output.txt |
ЂлВщбЏжДааЪЇАмЪБМЬајжДаа
[root@hadoop100
datas]# vim impala.sql
select * from student;
select * from stu;
select * from student;
[root@hadoop100 datas]# impala-shell -f impala.sql;
[root@hadoop100 datas]# impala-shell -c -f impala.sql; |
ЂмдкHiveжаДДНЈБэКѓЃЌЪЙгУ-rЫЂаТдЊЪ§Он
hive> create
table stu(id int, name string);
[hadoop100:21000] > show tables;
Query: show tables
+---------+
| name |
+---------+
| student |
+---------+
[root@hadoop100 ~]$ impala-shell -r
[hadoop100:21000] > show tables;
Query: show tables
+---------+
| name |
+---------+
| stu |
| student |
+---------+ |
ЂнЯдЪОВщбЏжДааМЦЛЎ
[root@hadoop100
datas]# impala-shell -p
[hadoop100:21000] > select * from student; |
ЂоШЅИёЪНЛЏЪфГі
[root@hadoop100
~]# impala-shell -q 'select * from student' \
-B --output_delimiter="\t" -o output.txt |
3.2 ImpalaЕФФкВПshell
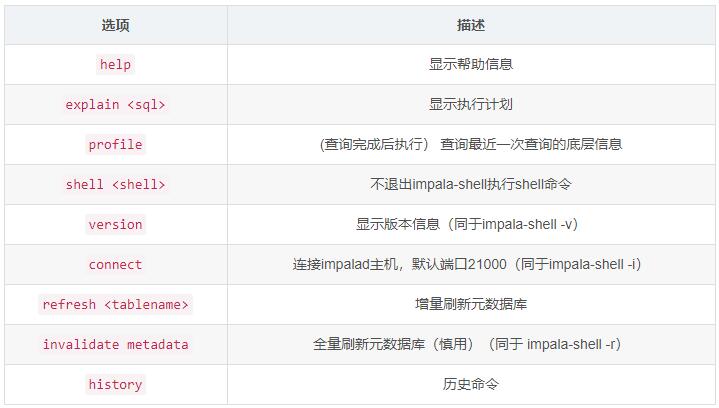
ЂйВщПДжДааМЦЛЎ
| [hadoop100:21000]
> explain select * from student; |
ЂкВщбЏзюНќвЛДЮВщбЏЕФЕзВуаХЯЂ
[hadoop100:21000]
> select count(*) from student;
[hadoop100:21000] > profile; |
ЂлВщПДHDFSМАLinuxЮФМўЯЕЭГ
[hadoop100:21000]
> shell hadoop fs -ls /;
[hadoop100:21000] > shell ls -al ./; |
ЂмЫЂаТжИЖЈБэЕФдЊЪ§Он
hive> load
data local inpath '/opt/module/datas/student.txt'
into table student;
[hadoop100:21000] > select * from student;
[hadoop100:21000] > refresh student;
[hadoop100:21000] > select * from student; |
ЂнВщПДРњЪЗУќСю
| [hadoop100:21000]
> history; |
ЫФЁЂDDLЪ§ОнЖЈвх
4.1 Ъ§ОнПтВйзї
ДДНЈЪ§ОнПтЃК
CREATE DATABASE
[IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]; |
ЯдЪОЪ§ОнПтЃК
[hadoop100:21000]
> show databases like 'hive*';
Query: show databases like 'hive*'
+---------+---------+
| name | comment |
+---------+---------+
| hive_db | |
+---------+---------+
[hadoop100:21000] > desc database hive_db;
Query: describe database hive_db
+---------+----------+---------+
| name | location | comment |
+---------+----------+---------+
| hive_db | | |
+---------+----------+---------+ |
ЩОГ§Ъ§ОнПтЃК
[hadoop103:21000]
> drop database hive_db;
[hadoop103:21000] > drop database hive_db cascade; |
МгcascadeЩОГ§ЗЧПеЪ§ОнПтЃЛ
ImpalaВЛжЇГжalter databaseгяЗЈЃЛ
ЕБЪ§ОнПтБЛuseгяОфбЁжаЪБЃЌЮоЗЈЩОГ§ЁЃ
4.2 БэВйзї
ДДНЈБэЃК
[hadoop100:21000]
> create external table stu_external(id int,
name string)
> row format delimited fields terminated by
'\t' ; |
ДДНЈЗжЧјБэ:
[hadoop100:21000]
> create table stu_par(id int, name string)
> partitioned by (month string)
> row format delimited fields terminated by
'\t'; |
ЯђЗжЧјБэжаЕМШыЪ§ОнЃК
[hadoop100:21000]
> alter table stu_par add partition (month='201810');
[hadoop100:21000] > load data inpath '/student.txt'
into table stu_par \
partition(month='201810'); |
зЂвтЃКШчЙћЗжЧјУЛгаЃЌload dataЕМШыЪ§ОнЪБЃЌВЛФмздЖЏДДНЈЗжЧјЁЃ
ВщбЏЗжЧјБэжаЕФЪ§ОнЃК
| [hadoop100:21000]
> select * from stu_par where month = '201810'; |
діМгЖрИіЗжЧјЃК
[hadoop103:21000]
> alter table stu_par add partition (month='201812')
\
partition (month='201813'); |
ЩОГ§ЗжЧјЃК
| [hadoop103:21000]
> alter table stu_par drop partition (month='201812'); |
ВщПДЗжЧјЃК
| [hadoop103:21000]
> show partitions stu_par; |
ЮхЁЂDMLЪ§ОнВйзї
Ъ§ОнЕМШыЃЈЛљБОЭЌhiveРрЫЦЃЉ
зЂвтЃКImpalaВЛжЇГжload data local inpathЁЃЌжЇГжДгHDFSжаЕМШы
Ъ§ОнЕФЕМГі
ImpalaВЛжЇГжinsert overwriteЁгяЗЈЕМГіЪ§Он
ImpalaЪ§ОнЕМГівЛАуЪЙгУimpala -o
[root@hadoop100
~]# impala-shell -q 'select * from student' \
-B --output_delimiter="\t" -o output.txt |
ImpalaВЛжЇГжexportКЭimportУќСю
СљЁЂВщбЏ
ЛљБОЕФгяЗЈИњHiveЕФВщбЏгяОфДѓЬхвЛбљ
ImpalaВЛжЇГжCLUSTER BYЃЌ DISTRIBUTE BYЃЌ SORT BY
ImpalaжаВЛжЇГжЗжЭАБэ
ImpalaВЛжЇГжCOLLECT_SET(col)КЭexplodeЃЈcolЃЉКЏЪ§
ImpalaжЇГжПЊДАКЏЪ§
[hadoop100:21000]
> select name,orderdate,cost,sum(cost) over(partition
by \
month(orderdate)) from business; |
ЦпЁЂДцДЂКЭбЙЫѕ
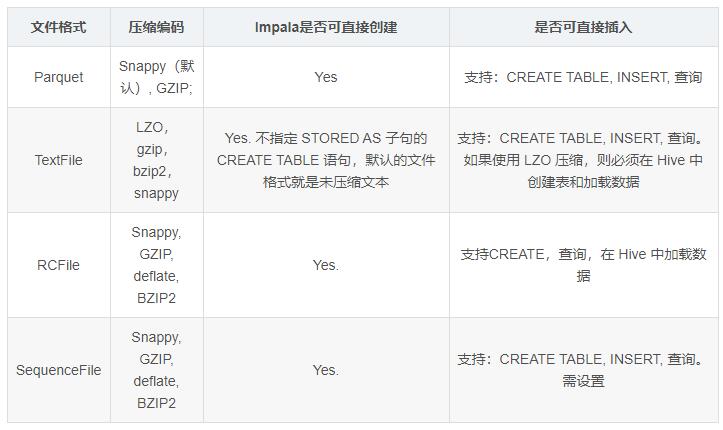
зЂЃКImpalaВЛжЇГжORCИёЪН
ДДНЈParquetИёЪНЕФБэВЂВхШыЪ§ОнНјааВщбЏ
[hadoop100:21000]
> create table student2(id int, name string)
> row format delimited
> fields terminated
by '\t'
> stored as PARQUET;
[hadoop100:21000] > insert into table student2
values(1001,'zhangsan');
[hadoop100:21000] > select * from student2; |
ДДНЈSequenceFileИёЪНЕФБэЃЌВхШыЪ§ОнЪББЈДэ
[hadoop100:21000]
> create table student3(id int, name string)
> row format delimited
> fields terminated
by '\t'
> stored as sequenceFile;
[hadoop100:21000] > insert into table student3
values(1001,'zhangsan');
Query: insert into table student3 values(1001,'zhangsan')
Query submitted at: 2018-10-25 20:59:31 (Coordinator:
http://hadoop104:25000)
Query progress can be monitored at: http://hadoop104:25000/query_plan?query_id=da4c59eb23481bdc:26f012ca00000000
WARNINGS: Writing to table format SEQUENCE_FILE
is not supported. Use query option ALLOW_UNSUPPORTED_FORMATS
to override.
[hadoop100:21000] > set ALLOW_UNSUPPORTED_FORMATS=true;
[hadoop100:21000] > insert into table student3
values(1001,'zhangsan'); |
АЫЁЂгХЛЏ
ОЁСПНЋStateStoreКЭCatalogЕЅЖРВПЪ№ЕНЭЌвЛИіНкЕуЃЌБЃжЄЫќУЧе§ГЃЭЈаХЃЛ
ЭЈЙ§ЖдImpala DaemonФкДцЯожЦЃЈФЌШЯ256MЃЉМАStateStoreЙЄзїЯпГЬЪ§ЃЌРДЬсИпImpalaЕФжДаааЇТЪЃЛ
SQLгХЛЏЃЌЪЙгУжЎЧАЕїгУжДааМЦЛЎЃЛ
бЁдёКЯЪЪЕФЮФМўИёЪННјааДцДЂЃЌЬсИпВщбЏаЇТЪЃЛ
БмУтВњЩњКмЖраЁЮФМўЃЈШчЙћгаЦфЫћГЬађВњЩњЕФаЁЮФМўЃЌПЩвдЪЙгУжаМфБэЃЌНЋаЁЮФМўЪ§ОнДцЗХЕНжаМфБэЁЃШЛКѓЭЈЙ§insertЁselectЁЗНЪНжаМфБэЕФЪ§ОнВхШыЕНзюжеБэжаЃЉЃЛ
ЪЙгУКЯЪЪЕФЗжЧјММЪѕЃЛ
ЪЙгУcompute statsНјааБэаХЯЂЫбМЏЃЌЕБвЛИіФкШнБэЛђЗжЧјУїЯдБфЛЏЃЌжиаТМЦЫуЭГМЦЯрЙиЪ§ОнБэЛђЗжЧјЁЃвђЮЊааКЭВЛЭЌжЕЕФЪ§СПВювьПЩФмЕМжТimpalaбЁдёВЛЭЌЕФСЌНгЫГађЪБНјааВщбЏЁЃ
| [hadoop100:21000]
> show table stats student; |
ЪЙгУprofileЪфГіЕзВуаХЯЂМЦЛЎЃЌдкзіЯргІЛЗОГгХЛЏЃЛ
ЭјТчioЕФгХЛЏЃКЂй БмУтАбећИіЪ§ОнЗЂЫЭЕНПЭЛЇЖЫ Ђк ОЁПЩФмЕФзіЬѕМўЙ§ТЫ Ђл ЪЙгУlimitзжОф Ђм
ЪфГіЮФМўЪБЃЌБмУтЪЙгУУРЛЏЪфГі Ђн ОЁСПЩйгУШЋСПдЊЪ§ОнЕФЫЂаТ
|








