| БрМЭЦМі: |
| БОЮФжївЊНщЩмСЫ
СїЪ§ОнФЃФтЦїЁЂЖСШЁЮФМўбнЪОЁЂЭјТчЪ§ОнбнЪОЁЂЯњЪлЪ§ОнЭГМЦбнЪОЕШЯрЙиФкШн
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1ЁЂЪЕР§бнЪО
1.1 СїЪ§ОнФЃФтЦї
1.1.1 СїЪ§ОнЫЕУї
дкЪЕР§бнЪОжаФЃФтЪЕМЪЧщПіЃЌашвЊдДдДВЛЖЯЕиНгШыСїЪ§ОнЃЌЮЊСЫдкбнЪОЙ§ГЬжаИќНгНќецЪЕЛЗОГНЋЖЈвхСїЪ§ОнФЃФтЦїЁЃИУФЃФтЦїжївЊЙІФмЃКЭЈЙ§SocketЗНЪНМрЬ§жИЖЈЕФЖЫПкКХЃЌЕБЭтВПГЬађЭЈЙ§ИУЖЫПкСЌНгВЂЧыЧѓЪ§ОнЪБЃЌФЃФтЦїНЋЖЈЪБНЋжИЖЈЕФЮФМўЪ§ОнЫцЛњЛёШЁЗЂЫЭИјЭтВПГЬађЁЃ
1.1.2 ФЃФтЦїДњТы
| import java.io.{PrintWriter}
import java.net.ServerSocket
import scala.io.Source
object StreamingSimulation {
// ЖЈвхЫцЛњЛёШЁећЪ§ЕФЗНЗЈ
def index(length: Int) = {
import java.util.Random
val rdm = new Random
rdm.nextInt(length)
}
def main(args: Array[String]) {
// ЕїгУИУФЃФтЦїашвЊШ§ИіВЮЪ§ЃЌЗжЮЊЮЊЮФМўТЗОЖЁЂЖЫПкКХКЭМфИєЪБМфЃЈЕЅЮЛЃККСУыЃЉ
if (args.length != 3) {
System.err.println("Usage: <filename>
<port> <millisecond>")
System.exit(1)
}
// ЛёШЁжИЖЈЮФМўзмЕФааЪ§
val filename = args(0)
val lines = Source.fromFile(filename).getLines.toList
val filerow = lines.length
// жИЖЈМрЬ§ФГЖЫПкЃЌЕБЭтВПГЬађЧыЧѓЪБНЈСЂСЌНг
val listener = new ServerSocket(args(1).toInt)
while (true) {
val socket = listener.accept()
new Thread() {
override def run = {
println("Got client connected from: "
+ socket.getInetAddress)
val out = new PrintWriter(socket.getOutputStream(),
true)
while (true) {
Thread.sleep(args(2).toLong)
// ЕБИУЖЫПкНгЪмЧыЧѓЪБЃЌЫцЛњЛёШЁФГааЪ§ОнЗЂЫЭИјЖдЗН
val content = lines(index(filerow))
println(content)
out.write(content + '\n')
out.flush()
}
socket.close()
}
}.start()
}
}
} |
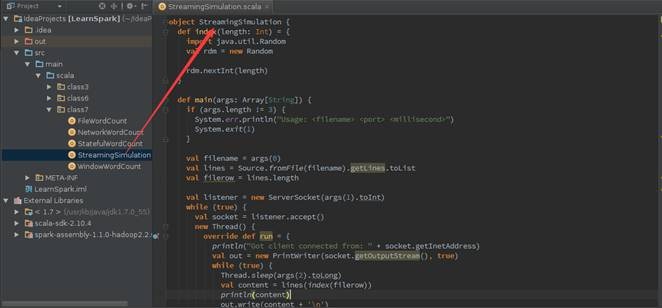
1.1.3 ЩњГЩДђАќЮФМў
ЁОзЂЁППЩвдВЮМћЕк3ПЮЁЖSparkБрГЬФЃаЭЃЈЯТЃЉ--IDEAДюНЈМАЪЕеНЁЗНјааДђАќ
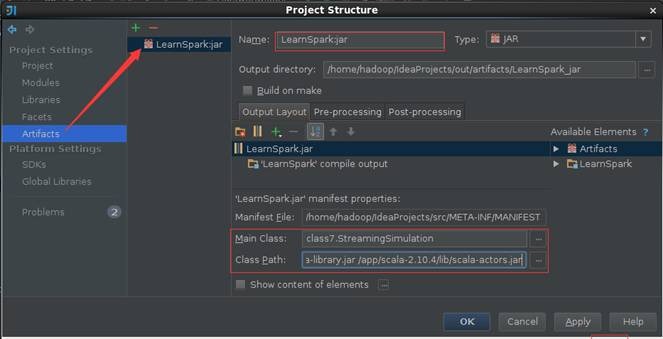
дкДђАќХфжУНчУцжаЃЌашвЊдкClass PathМгШыЃК/app/scala-
2.10.4/lib/scala-swing.jar /app/scala- 2.10.4/lib/scala-library.jar
/app/scala-2.10.4/lib/scala-actors.jar ЃЌИїИіjarАќжЎМфгУПеИёЗжПЊЃЌ
ЕуЛїВЫЕЅBuild->Build ArtifactsЃЌЕЏГібЁдёЖЏзїЃЌбЁдёBuildЛђепRebuildЖЏзїЃЌЪЙгУШчЯТУќСюИДжЦДђАќЮФМўЕНSparkИљФПТМЯТ
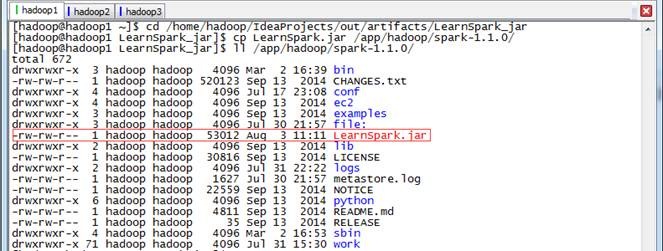
cd /home/hadoop/IdeaProjects /out/artifacts/LearnSpark_jar
cp LearnSpark.jar /app /hadoop/spark-1.1.0/
ll /app/hadoop/spark-1.1.0/
1.2 ЪЕР§1ЃКЖСШЁЮФМўбнЪО
1.2.1 бнЪОЫЕУї
дкИУЪЕР§жаSpark StreamingНЋМрПиФГФПТМжаЕФЮФМўЃЌЛёШЁдкМфИєЪБМфЖЮФкБфЛЏЕФЪ§ОнЃЌШЛКѓЭЈЙ§Spark
StreamingМЦЫуГіИФЪБМфЖЮФкЕЅДЪЭГМЦЪ§ЁЃ
1.2.2 бнЪОДњТы
import org.apache.spark.SparkConf
import org.apache.spark.streaming. {Seconds,
StreamingContext}
import org.apache.spark .streaming.StreamingContext._
object FileWordCount {
def main(args: Array[String]) {
val sparkConf = new SparkConf( ).setAppName
( "FileWordCount").setMaster ("local[2]")
// ДДНЈStreamingЕФЩЯЯТЮФЃЌАќРЈSparkЕФХфжУКЭЪБМфМфИєЃЌетРяЪБМфЮЊМфИє20Уы
val ssc = new StreamingContext( sparkConf,
Seconds(20))
// жИЖЈМрПиЕФФПТМЃЌдкетРяЮЊ/home/hadoop/temp/
val lines = ssc.textFileStream ("/home/hadoop/temp/")
// ЖджИЖЈЮФМўМаБфЛЏЕФЪ§ОнНјааЕЅДЪЭГМЦВЂЧвДђгЁ
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_
+ _)
wordCounts.print()
// ЦєЖЏStreaming
ssc.start()
ssc.awaitTermination()
}
} |
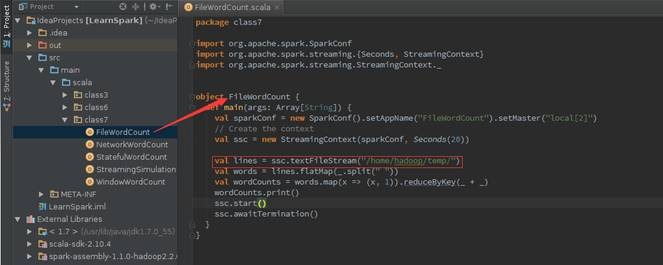
1.2.3 дЫааДњТы
ЕквЛВН ДДНЈStreamingМрПиФПТМ
ДДНЈ/home/hadoop/tempЮЊSpark StreamingМрПиЕФФПТМЃЌЭЈЙ§дкИУФПТМжаЖЈЪБЬэМгЮФМўФкШнЃЌШЛКѓгЩSpark
StreamingЭГМЦГіЕЅДЪИіЪ§
ЕкЖўВН ЪЙгУШчЯТУќСюЦєЖЏSparkМЏШК
$cd /app/hadoop/spark-1.1.0
$sbin/start-all.sh
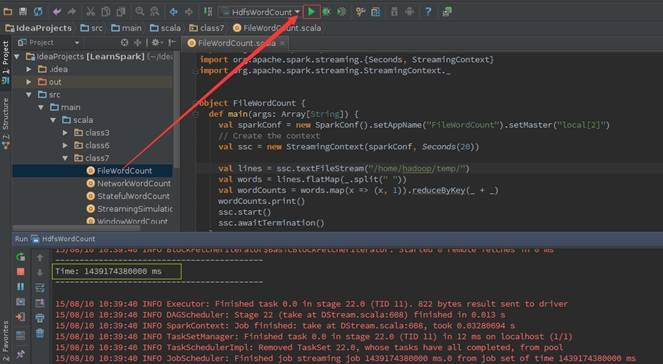
ЕкШ§ВН дкIDEAжадЫааStreamingГЬађ
дкIDEAжадЫааИУЪЕР§ЃЌгЩгкИУЪЕР§УЛгаЪфШыВЮЪ§ЙЪВЛашвЊХфжУВЮЪ§ЃЌдкдЫааШежОжаНЋЖЈЪБДђгЁЪБМфДСЁЃШчЙћдкМрПиФПТМжаМгШыЮФМўФкШнЃЌНЋЪфГіЪБМфДСЕФЭЌЪБНЋЪфГіЕЅДЪЭГМЦИіЪ§ЁЃ
1.2.4 ЬэМгЮФБОМАФкШн 
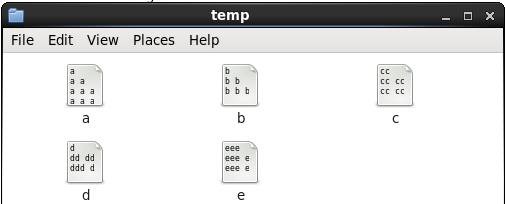
1.2.5 ВщПДНсЙћ
ЕквЛВН ВщПДIDEAжадЫааЧщПі
дкIDEAЕФдЫааШежОДАПкжаЃЌПЩвдЙлВьЕНЪфГіЪБМфДСЕФЭЌЪБНЋЪфГіЕЅДЪЭГМЦИіЪ§
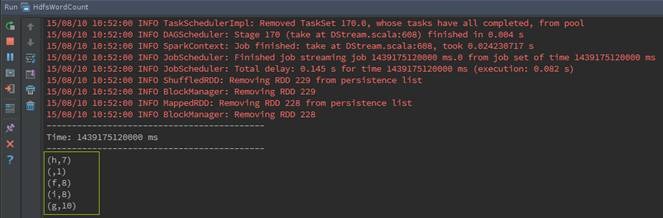
ЕкЖўВН ЭЈЙ§webUIМрПидЫааЧщПі
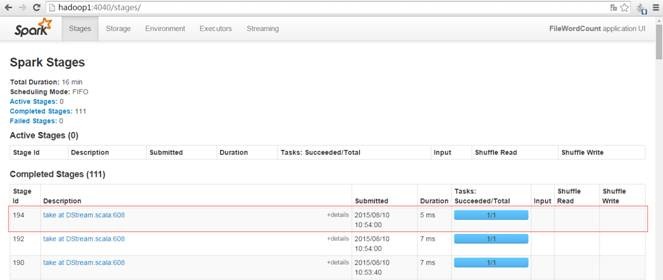
дкhttp://hadoop1:4040МрПиSpark StreamingдЫааЧщПіЃЌПЩвдЙлВьЕНУП20УыдЫаавЛДЮзївЕ
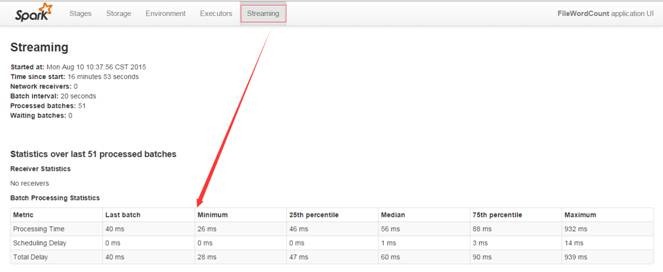
ВЂЧвгыЦфЫћдЫаазївЕЯрБШдкМрПиВЫЕЅдіМгСЫ"Streaming"ЯюФПЃЌЕуЛїПЩвдПДЕНМрПиФкШнЃК
1.3 ЪЕР§2ЃКЭјТчЪ§ОнбнЪО
1.3.1 бнЪОЫЕУї
дкИУЪЕР§жаНЋгЩ4.1СїЪ§ОнФЃФтвд1УыЕФЦЕЖШЗЂЫЭФЃФтЪ§ОнЃЌSpark StreamingЭЈЙ§SocketНгЪеСїЪ§ОнВЂУП20УыдЫаавЛДЮгУРДДІРэНгЪеЕНЪ§ОнЃЌДІРэЭъБЯКѓДђгЁИУЪБМфЖЮФкЪ§ОнГіЯжЕФЦЕЖШЃЌМДдкИїДІРэЖЮЪБМфжЎМфзДЬЌВЂЮоЙиЯЕЁЃ
1.3.2 бнЪОДњТы
import org.apache.spark. {SparkContext,
SparkConf}
import org.apache.spark.streaming. {Milliseconds,
Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.storage.StorageLevel
object NetworkWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName ("NetworkWordCount").setMaster( "local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(20))
// ЭЈЙ§SocketЛёШЁЪ§ОнЃЌИУДІашвЊЬсЙЉSocketЕФжїЛњУћКЭЖЫПкКХЃЌЪ§ОнБЃДцдкФкДцКЭгВХЬжа
val lines = ssc.socketTextStream(args(0),
args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
// ЖдЖСШыЕФЪ§ОнНјааЗжИюЁЂМЦЪ§
val words = lines.flatMap(_.split (","))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_
+ _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
} |
1.3.3 дЫааДњТы
ЕквЛВН ЦєЖЏСїЪ§ОнФЃФтЦї
ЦєЖЏ4.1ДђАќКУЕФСїЪ§ОнФЃФтЦїЃЌдкИУЪЕР§жаНЋЖЈЪБЗЂЫЭ/home/hadoop/upload/class7ФПТМЯТЕФpeople.txtЪ§ОнЮФМўЃЈИУЮФМўПЩвддкБОЯЕСаХфЬззЪдДФПТМ/data/class7жаевЕНЃЉЃЌЦфжаpeople.txtЪ§ОнФкШнШчЯТЃК

ФЃФтЦїSocketЖЫПкКХЮЊ9999ЃЌЦЕЖШЮЊ1УыЃЌ
$cd /app/hadoop/spark-1.1.0
$java -cp LearnSpark.jar class7.StreamingSimulation
/home/hadoop/upload/class7/people. txt 9999 1000

дкУЛгаГЬађСЌНгЪБЃЌИУГЬађДІгкзшШћзДЬЌ
ЕкЖўВН дкIDEAжадЫааStreamingГЬађ
дкIDEAжадЫааИУЪЕР§ЃЌИУЪЕР§ашвЊХфжУСЌНгSocketжїЛњУћКЭЖЫПкКХЃЌдкетРяХфжУВЮЪ§ЛњЦїУћЮЊhadoop1КЭЖЫПкКХЮЊ9999
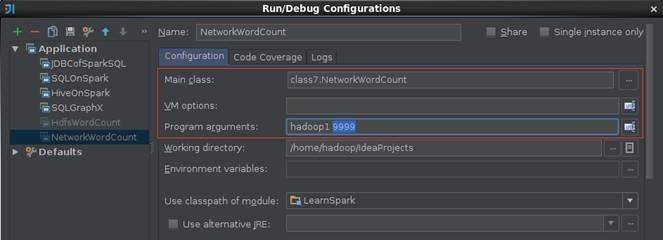
1.3.4 ВщПДНсЙћ
ЕквЛВН ЙлВьФЃФтЦїЗЂЫЭЧщПі
IDEAжаЕФSpark StreamingГЬађдЫаагыФЃФтЦїНЈСЂСЌНгЃЌЕБФЃФтЦїМьВтЕНЭтВПСЌНгЪБПЊЪМЗЂЫЭВтЪдЪ§ОнЃЌЪ§ОнЪЧЫцЛњЕФдкжИЖЈЕФЮФМўжаЛёШЁвЛааЪ§ОнВЂЗЂЫЭЃЌЪБМфМфИєЮЊ1Уы
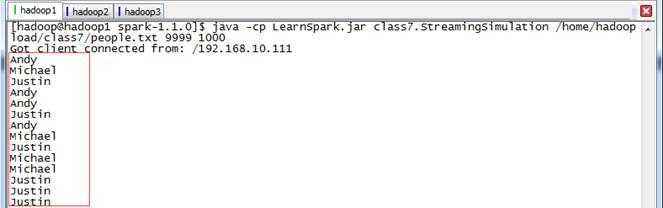
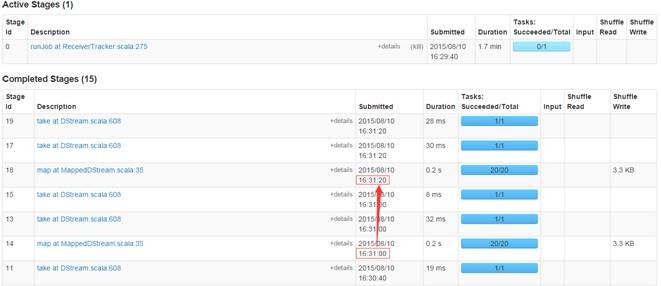
ЕкЖўВН дкМрПивГУцЙлВьжДааЧщПі
дкwebUIЩЯМрПизївЕдЫааЧщПіЃЌПЩвдЙлВьЕНУП20УыдЫаавЛДЮзївЕ
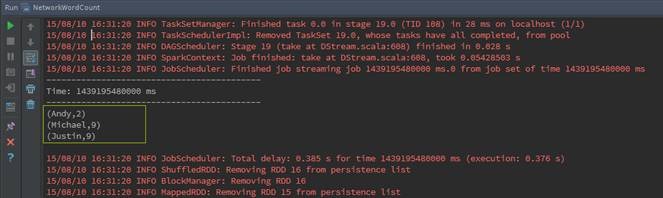
ЕкШ§ВН IDEAдЫааЧщПі
дкIDEAЕФдЫааДАПкжаЃЌПЩвдЙлВтЕНЕФЭГМЦНсЙћЃЌЭЈЙ§ЗжЮідкSpark StreamingУПЖЮЪБМфФкЕЅДЪЪ§ЮЊ20ЃЌе§КУЪЧ20УыФкУПУыЗЂЫЭзмЪ§ЁЃ
1.4 ЪЕР§3ЃКЯњЪлЪ§ОнЭГМЦбнЪО
1.4.1 бнЪОЫЕУї
дкИУЪЕР§жаНЋгЩ4.1СїЪ§ОнФЃФтЦївд1УыЕФЦЕЖШЗЂЫЭФЃФтЪ§ОнЃЈЯњЪлЪ§ОнЃЉЃЌSpark StreamingЭЈЙ§SocketНгЪеСїЪ§ОнВЂУП5УыдЫаавЛДЮгУРДДІРэНгЪеЕНЪ§ОнЃЌДІРэЭъБЯКѓДђгЁИУЪБМфЖЮФкЯњЪлЪ§ОнзмКЭЃЌашвЊзЂвтЕФЪЧИїДІРэЖЮЪБМфжЎМфзДЬЌВЂЮоЙиЯЕЁЃ
1.4.2 бнЪОДњТы
import org.apache.log4j.{Level,
Logger}
import org.apache.spark. {SparkContext, SparkConf}
import org.apache.spark.streaming. {Milliseconds,
Seconds, StreamingContext}
import org.apache.spark.streaming .StreamingContext._
import org.apache.spark.storage.StorageLevel
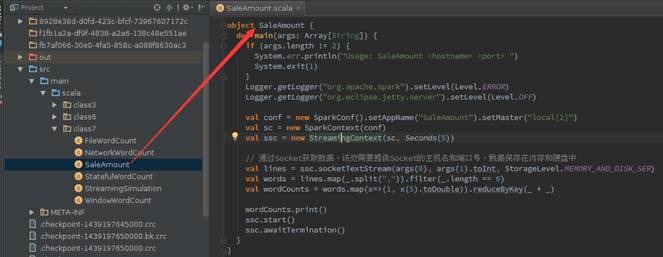
object SaleAmount {
def main(args: Array[String]) {
if (args.length != 2) {
System.err.println ("Usage: SaleAmount
<hostname> <port> ")
System.exit(1)
}
Logger.getLogger ("org.apache.spark").setLevel( Level.ERROR)
Logger.getLogger ("org.eclipse.jetty.server" ).setLevel(Level.OFF)
val conf = new SparkConf().setAppName("SaleAmount").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
// ЭЈЙ§SocketЛёШЁЪ§ОнЃЌИУДІашвЊЬсЙЉSocketЕФжїЛњУћКЭЖЫПкКХЃЌЪ§ОнБЃДцдкФкДцКЭгВХЬжа
val lines = ssc.socketTextStream(args(0),
args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.map(_.split(",")).filter(_.length
== 6)
val wordCounts = words.map(x=>(1, x(5).toDouble)).reduceByKey(_
+ _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
|
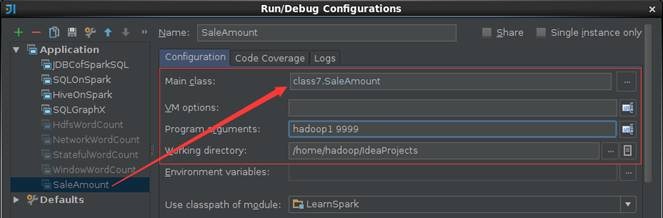
1.4.3 дЫааДњТы
ЕквЛВН ЦєЖЏСїЪ§ОнФЃФтЦї
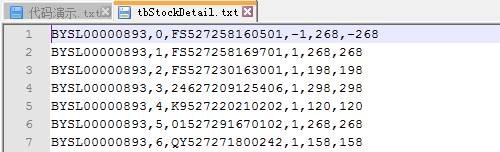
ЦєЖЏ4.1ДђАќКУЕФСїЪ§ОнФЃФтЦїЃЌдкИУЪЕР§жаНЋЖЈЪБЗЂЫЭЕкЮхПЮ/home/hadoop/upload/class5/saledataФПТМЯТЕФtbStockDetail.txtЪ§ОнЮФМўЃЈВЮМћЕкЮхПЮЁЖ5.HiveЃЈЯТЃЉ--HiveЪЕеНЁЗжа2.1.2Ъ§ОнУшЪіЃЌИУЮФМўПЩвддкБОЯЕСаХфЬззЪдДФПТМ/data/class5/saledataжаевЕНЃЉЃЌЦфжаБэtbStockDetailзжЖЮЗжБ№ЮЊЖЉЕЅКХЁЂааКХЁЂЛѕЦЗЁЂЪ§СПЁЂН№ЖюЃЌЪ§ОнФкШнШчЯТЃК
ФЃФтЦїSocketЖЫПкКХЮЊ9999ЃЌЦЕЖШЮЊ1Уы
$cd /app/hadoop/spark-1.1.0
$java -cp LearnSpark.jar class7.StreamingSimulation
/home/hadoop/upload/class5 /saledata/tbStockDetail.txt
9999 1000

дкIDEAжадЫааИУЪЕР§ЃЌИУЪЕР§ашвЊХфжУСЌНгSocketжїЛњУћКЭЖЫПкКХЃЌдкетРяХфжУВЮЪ§ЛњЦїУћЮЊhadoop1КЭЖЫПкКХЮЊ9999
1.4.4 ВщПДНсЙћ
ЕквЛВН ЙлВьФЃФтЦїЗЂЫЭЧщПі
IDEAжаЕФSpark StreamingГЬађдЫаагыФЃФтЦїНЈСЂСЌНгЃЌЕБФЃФтЦїМьВтЕНЭтВПСЌНгЪБПЊЪМЗЂЫЭЯњЪлЪ§ОнЃЌЪБМфМфИєЮЊ1Уы
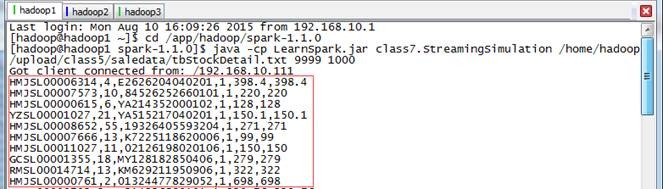
ЕкЖўВН IDEAдЫааЧщПі
дкIDEAЕФдЫааДАПкжаЃЌПЩвдЙлВьЕНУП5УыдЫаавЛДЮзївЕЃЈСНДЮдЫааМфИєЮЊ5000КСУыЃЉЃЌдЫааЭъБЯКѓДђгЁИУЪБМфЖЮФкЯњЪлЪ§ОнзмКЭЁЃ
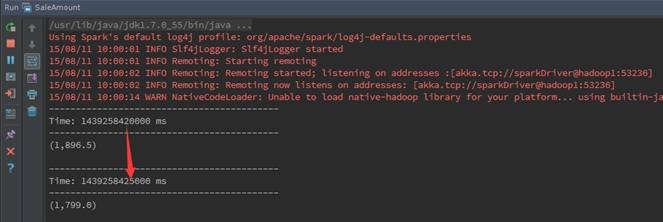
ЕкШ§ВН дкМрПивГУцЙлВьжДааЧщПі
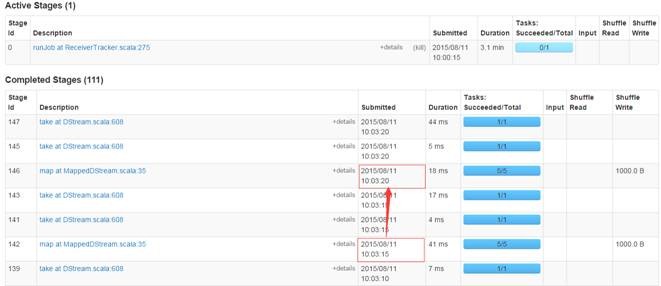
дкwebUIЩЯМрПизївЕдЫааЧщПіЃЌПЩвдЙлВьЕНУП5УыдЫаавЛДЮзївЕ
1.5 ЪЕР§4ЃКStatefulбнЪО
1.5.1 бнЪОЫЕУї
ИУЪЕР§ЮЊSpark StreamingзДЬЌВйзїЃЌФЃФтЪ§ОнгЩ4.1СїЪ§ОнФЃФтвд1УыЕФЦЕЖШЗЂЫЭЃЌSpark
StreamingЭЈЙ§SocketНгЪеСїЪ§ОнВЂУП5УыдЫаавЛДЮгУРДДІРэНгЪеЕНЪ§ОнЃЌДІРэЭъБЯКѓДђгЁГЬађЦєЖЏКѓЕЅДЪГіЯжЕФЦЕЖШЃЌЯрБШНЯЧАУц4.3ЪЕР§дкИУЪЕР§жаИїЪБМфЖЮжЎМфзДЬЌЪЧЯрЙиЕФЁЃ
1.5.2 бнЪОДњТы
import org.apache.log4j. {Level,
Logger}
import org.apache.spark. {SparkContext, SparkConf}
import org.apache.spark.streaming. {Seconds,
StreamingContext}
import org.apache.spark.streaming. StreamingContext._
object StatefulWordCount {
def main(args: Array[String]) {
if (args.length != 2) {
System.err.println ("Usage: StatefulWordCount
<filename> <port> ")
System.exit(1)
}
Logger.getLogger ("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger ("org.eclipse.jetty.server" ).setLevel(Level.OFF)
// ЖЈвхИќаТзДЬЌЗНЗЈЃЌ ВЮЪ§valuesЮЊЕБЧАХњДЮЕЅДЪЦЕЖШЃЌstateЮЊвдЭљХњДЮЕЅДЪЦЕЖШ
val updateFunc = (values: Seq[Int], state:
Option[Int]) => {
val currentCount = values.foldLeft(0)(_ +
_)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val conf = new SparkConf( ).setAppName("StatefulWordCount" ).setMaster("local[2]")
val sc = new SparkContext(conf)
// ДДНЈStreamingContextЃЌ Spark SteamingдЫааЪБМфМфИєЮЊ5Уы
val ssc = new StreamingContext(sc, Seconds(5))
// ЖЈвхcheckpointФПТМЮЊЕБЧАФПТМ
ssc.checkpoint(".")
// ЛёШЁДгSocketЗЂЫЭЙ§РДЪ§Он
val lines = ssc.socketTextStream(args(0),
args(1).toInt)
val words = lines.flatMap(_.split(","))
val wordCounts = words.map(x => (x, 1))
// ЪЙгУupdateStateByKeyРДИќаТзДЬЌЃЌЭГМЦДгдЫааПЊЪМвдРДЕЅДЪзмЕФДЮЪ§
val stateDstream = wordCounts.updateStateByKey[Int](updateFunc)
stateDstream.print()
ssc.start()
ssc.awaitTermination()
}
} |
1.5.3 дЫааДњТы
ЕквЛВН ЦєЖЏСїЪ§ОнФЃФтЦї
ЦєЖЏ4.1ДђАќКУЕФСїЪ§ОнФЃФтЦїЃЌдкИУЪЕР§жаНЋЖЈЪБЗЂЫЭ/home/hadoop/upload/class7ФПТМЯТЕФpeople.txtЪ§ОнЮФМўЃЈИУЮФМўПЩвддкБОЯЕСаХфЬззЪдДФПТМ/data/class7жаевЕНЃЉЃЌЦфжаpeople.txtЪ§ОнФкШнШчЯТЃК

ФЃФтЦїSocketЖЫПкКХЮЊ9999ЃЌЦЕЖШЮЊ1Уы
$cd /app/hadoop/spark-1.1.0
$java -cp LearnSpark.jar class7.StreamingSimulation
/home/hadoop/upload/class7/people.txt 9999 1000

дкУЛгаГЬађСЌНгЪБЃЌИУГЬађДІгкзшШћзДЬЌЃЌдкIDEAжадЫааStreamingГЬађ
дкIDEAжадЫааИУЪЕР§ЃЌИУЪЕР§ашвЊХфжУСЌНгSocketжїЛњУћКЭЖЫПкКХЃЌдкетРяХфжУВЮЪ§ЛњЦїУћЮЊhadoop1КЭЖЫПкКХЮЊ9999
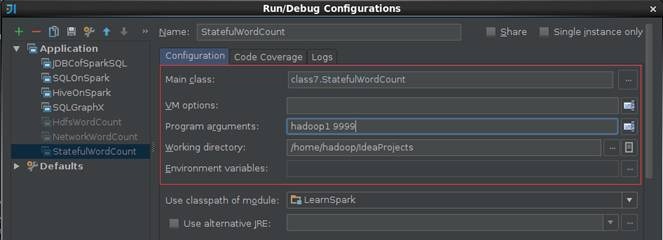
1.5.4 ВщПДНсЙћ
ЕквЛВН IDEAдЫааЧщПі
дкIDEAЕФдЫааДАПкжаЃЌПЩвдЙлВьЕНЕквЛДЮдЫааЭГМЦЕЅДЪзмЪ§ЮЊ1ЃЌЕкЖўДЮЮЊ6ЃЌЕкNДЮЮЊ5(N-1)+1ЃЌМДЭГМЦЕЅДЪЕФзмЪ§ЮЊГЬађдЫааЕЅДЪЪ§змКЭЁЃ
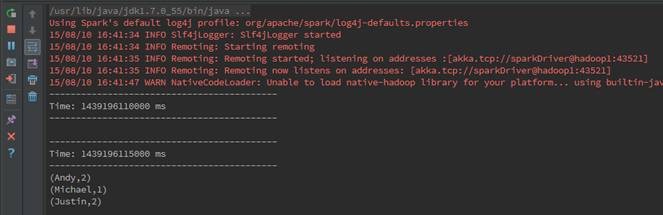
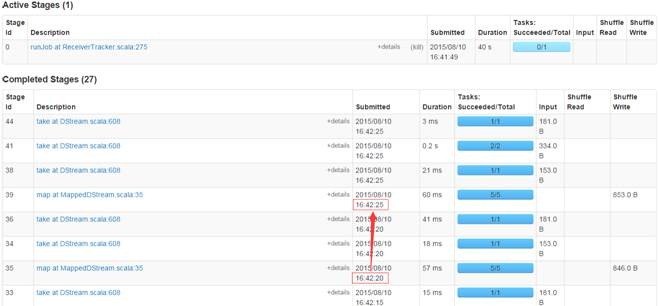
ЕкЖўВН дкМрПивГУцЙлВьжДааЧщПі
дкwebUIЩЯМрПизївЕдЫааЧщПіЃЌПЩвдЙлВьЕНУП5УыдЫаавЛДЮзївЕ
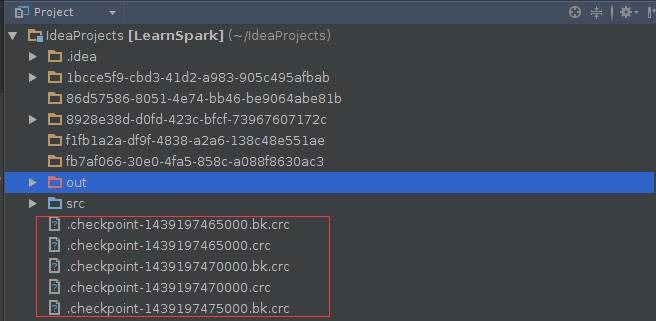
ЕкШ§ВН ВщПДCheckPointЧщПі
дкЯюФПИљФПТМЯТПЩвдПДЕНcheckpointЮФМў
1.6 ЪЕР§5ЃКWindowбнЪО
1.6.1 бнЪОЫЕУї
ИУЪЕР§ЮЊSpark StreamingДАПкВйзїЃЌФЃФтЪ§ОнгЩ4.1СїЪ§ОнФЃФтвд1УыЕФЦЕЖШЗЂЫЭЃЌSpark
StreamingЭЈЙ§SocketНгЪеСїЪ§ОнВЂУП10УыдЫаавЛДЮгУРДДІРэНгЪеЕНЪ§ОнЃЌДІРэЭъБЯКѓДђгЁГЬађЦєЖЏКѓЕЅДЪГіЯжЕФЦЕЖШЁЃЯрБШЧАУцЕФЪЕР§ЃЌSpark
StreamingДАПкЭГМЦЪЧЭЈЙ§reduceByKeyAndWindow()ЗНЗЈЪЕЯжЕФЃЌдкИУЗНЗЈжаашвЊжИЖЈДАПкЪБМфГЄЖШКЭЛЌЖЏЪБМфМфИєЁЃ
1.6.2 бнЪОДњТы
import org.apache.log4j. {Level,
Logger}
import org.apache.spark .{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object WindowWordCount {
def main(args: Array[String]) {
if (args.length != 4) {
System.err.println ("Usage: WindowWorldCount
<filename> <port> <windowDuration>
<slideDuration>")
System.exit(1)
}
Logger.getLogger ("org.apache.spark").setLevel(
Level.ERROR)
Logger.getLogger ("org.eclipse.jetty.server").setLevel(
Level.OFF)
val conf = new SparkConf().setAppName ("WindowWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
// ДДНЈStreamingContext
val ssc = new StreamingContext(sc, Seconds(5))
// ЖЈвхcheckpointФПТМЮЊЕБЧАФПТМ
ssc.checkpoint(".")
// ЭЈЙ§SocketЛёШЁЪ§ОнЃЌИУДІашвЊЬсЙЉSocketЕФжїЛњУћКЭЖЫПкКХЃЌЪ§ОнБЃДцдкФкДцКЭгВХЬжа
val lines = ssc.socketTextStream(args(0),
args(1).toInt, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(","))
// windowsВйзїЃЌЕквЛжжЗНЪНЮЊЕўМгДІРэЃЌЕкЖўжжЗНЪНЮЊдіСПДІРэ
val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow( (a:Int,b:Int)
=> (a + b), Seconds(args(2).toInt), Seconds(args(3).toInt))
//val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow(_+_,
_-_,Seconds(args(2).toInt), Seconds(args(3).toInt))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
} |
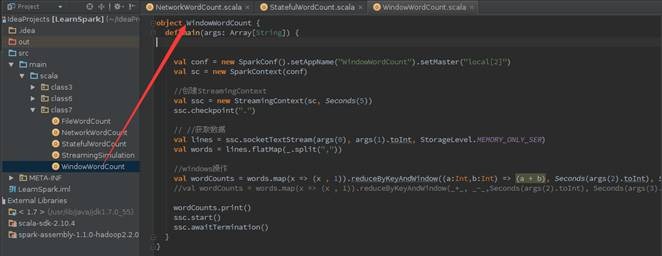
1.6.3 дЫааДњТы
ЕквЛВН ЦєЖЏСїЪ§ОнФЃФтЦї
ЦєЖЏ4.1ДђАќКУЕФСїЪ§ОнФЃФтЦїЃЌдкИУЪЕР§жаНЋЖЈЪБЗЂЫЭ/home/hadoop/upload/class7ФПТМЯТЕФpeople.txtЪ§ОнЮФМўЃЈИУЮФМўПЩвддкБОЯЕСаХфЬззЪдДФПТМ/data/class7жаевЕНЃЉЃЌЦфжаpeople.txtЪ§ОнФкШнШчЯТЃК

ФЃФтЦїSocketЖЫПкКХЮЊ9999ЃЌЦЕЖШЮЊ1Уы
$cd /app/hadoop/spark-1.1.0
$java -cp LearnSpark.jar class7.StreamingSimulation
/home/hadoop/upload/class7/people.txt 9999 1000

дкУЛгаГЬађСЌНгЪБЃЌИУГЬађДІгкзшШћзДЬЌЃЌдкIDEAжадЫааStreamingГЬађ
дкIDEAжадЫааИУЪЕР§ЃЌИУЪЕР§ашвЊХфжУСЌНгSocketжїЛњУћКЭЖЫПкКХЃЌдкетРяХфжУВЮЪ§ЛњЦїУћЮЊhadoop1ЁЂЖЫПкКХЮЊ9999ЁЂЪБМфДАПкЮЊ30УыКЭЛЌЖЏЪБМфМфИє10Уы
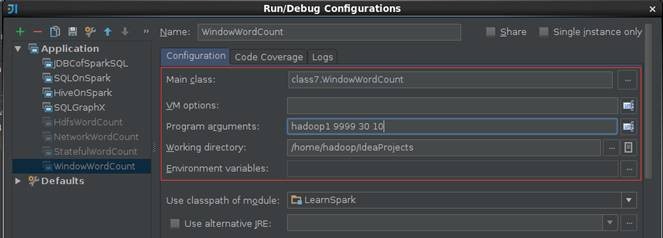
1.6.4 ВщПДНсЙћ
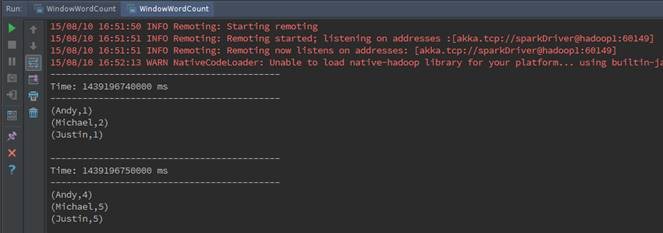
ЕквЛВН IDEAдЫааЧщПі
дкIDEAЕФдЫааДАПкжаЃЌПЩвдЙлВьЕНЕквЛДЮдЫааЭГМЦЕЅДЪзмЪ§ЮЊ4ЃЌЕкЖўДЮЮЊ14ЃЌЕкNДЮЮЊ10(N-1)+4ЃЌМДЭГМЦЕЅДЪЕФзмЪ§ЮЊГЬађдЫааЕЅДЪЪ§змКЭЁЃ
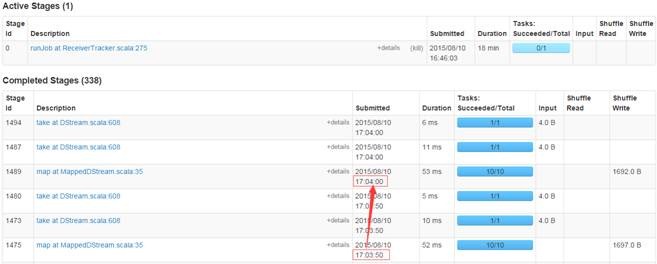
ЕкЖўВН дкМрПивГУцЙлВьжДааЧщПі
дкwebUIЩЯМрПизївЕдЫааЧщПіЃЌПЩвдЙлВьЕНУП10УыдЫаавЛДЮзївЕ
|








