| БрМЭЦМі: |
БОЮФНЋжївЊНщЩмШчКЮРћгУLambdaМмЙЙРДИњзйЪ§ОнЪЕЪБИќаТЕФЯюФПЪЕЯжЃЌвдвЛИіаТЮХЗўЮёЙІФмЮЊР§ЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДзд СЖЪ§ГЩН№ЧАбиЭЦМіЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЕБЧАЙЩЦБЪаГЁЕФНЛвзепПЩвдСЫНтЗсИЛЕФЙЩЦБНЛвзаХЯЂЁЃДгН№ШкаТЮХЕНДЋЭГЕФБЈжНКЭдгжОдйЕНВЉПЭКЭЩчНЛУНЬхЃЌЛуОлзХКЃСПЕФЪ§ОнЃЌдЖБШЙЩЦБНЛвзепЯыЙизЂЕФЙЩЦБаХЯЂвЊДѓЕУЖрЃЌетОЭашвЊЮЊЙЩЦБНЛвзепЬсЙЉаХЯЂЕФгааЇЙ§ТЫЁЃетРяНЋПЊЗЂвЛИіаТЮХЗўЮёЙІФмИјЙЩЦБжЄШЏЭЖзЪНЛвзепЪЙгУЃЌВЂЮЊЙЩЦБНЛвзепЬсЙЉИіадЛЏаТЮХЁЃ
етИіаТЮХЗўЮёОЭНа"здЖЏЛёШЁН№ШкаТЮХ"ЃЌЪфШыИїИіЪ§ОндДЕФН№ШкаТЮХЃЌвВЭЌЪБЪфШыгУЛЇЪЕЪБЙЩЦБНЛвзаХЯЂЁЃВЛЙмКЮЪБЃЌдкЙЩЦБНЛвзепЫљгЕгазЪВњжЄШЏжаеМБШНЯДѓЕФЙЋЫОЃЌЫќУЧЕФаТЮХвЛЕНДяЃЌНЋЛсЯдЪОЕНЙЩЦБНЛвзепЕФвЧБэАхЩЯЁЃЫцзХДѓСПЙЩЦБНЛвзепНјааНЛвзЃЌЯргІЕФНЛвзаХЯЂЛсЗЂЫЭЙ§РДЃЌЫљвдЯЃЭћгЕгавЛИіДѓЪ§ОнЯЕЭГРДДцДЂЫљгаНЛвзепЕФРњЪЗНЛвзаХЯЂзїЮЊецЪЕЪ§ОндДЃЌШЛЖјЃЌДІРэКЃСПЪ§ОнЛсЗЧГЃТ§вджСгкВЛФмНјааЪЕЪБЕФЪ§ОнИќаТЁЃЮЊСЫДяЕНЪЕЪБИњзйКЭЮЌГжЪ§ОнНсЙћЮЊзюаТетСНИівЊЧѓЃЌПЩвдВЩгУLambdaМмЙЙРДЪЕЯжЁЃ
LambdaМмЙЙгХЪЦ
дкДЋЭГSQLЯЕЭГЃЌИќаТвЛИіБэжЛЪЧЖдвбДцдкзжЖЮЕФжЕНјааИќИФЃЌетдкЩйСПЕФЗўЮёЦїЩЯЕФЪ§ОнПтЙЄзїЕФКмКУЃЌПЩвдЫЎЦНРЉеЙЕНДгПтЛђепБИЗнПтЁЃЕЋЪЧЕБЪ§ОнПтРЉеЙЕНДѓСПЪ§ОнЗўЮёЦїЩЯЪБЃЌгВМўБРРЃЕШЧщПіЯТЛжИДЪ§ОнЕНЪЇАмЕуОЭБШНЯРЇФбКЭКФЪБЃЌЖјЧвгЩгкРњЪЗВЛдкЪ§ОнПтжаЃЌНіНіДцдкlogШежОЃЌЪ§ОнБРРЃНЋЕМжТвЛаЉВЛПЩМћЕФЪ§ОнДэЮѓЃЌМДдрЪ§ОнЁЃ
ЖјЯрЖдгІЕиЃЌвЛИіЗжВМЪНЁЂЖрИББОЯћЯЂЖгСаЕФДѓЪ§ОнЯЕЭГПЩвдБЃжЄЪ§ОнвЛЕЉНјШыЯЕЭГОЭВЛЛсЖЊЪЇЃЌМДЪЙдкгВМўЛђепЭјТчЪЇАмЕФЧщПіЯТЁЃДцДЂИќаТЕФЫљгаРњЪЗПЩвджиНЈецЪЕЕФЪ§ОндДЃЌВЂФмБЃжЄУПДЮХњДІРэжЎКѓНсЙће§ШЗЃЌШЛЖјЃЌЮЊСЫдкЪЕЪБЪ§ОнИќаТКѓЕУЕНзюаТЭъећЕФЪ§ОнМЏЃЌашвЊжиаТДІРэећИіРњЪЗЪ§ОнМЏЃЌНЋЛсКФЗбЬЋГЄЕФЪБМфЁЃЮЊСЫНтОіетИіЮЪЬтЃЌПЩвддкLambdaМмЙЙжадіМгвЛИіЪЕЪБзщМўЃЌДЫзщМўжЛДцДЂЪ§ОнИќаТЕФЕБЧАжЕЃЌПЩвдБЃжЄПьЫйЪЕЪБЕУЕННсЙћЃЌЙЄзїЙ§ГЬРрЫЦгкДЋЭГЕФSQLЯЕЭГЁЃЪЕЪБДІРэВуЕФдрЪ§ОнНЋЛсБЛКѓајХњДІРэИВИЧЕєЃЌетИіИпПЩгУЁЂзюжевЛжТадЕФЯЕЭГПЩвдЪЕЯжзМШЗЕФНсЙћЁЃЕБЧАжЕЕФШЮКЮДэЮѓЃЌЪЕЪБДІРэВуЕФБЈИцЃЌгВМўЛђепЭјТчДэЮѓЃЌЪ§ОнБРРЃЃЌЛђепШэМўBugЕШНЋЛсдкЯТвЛДЮХњДІРэЪБздЖЏаоИДЁЃ
здЖЏЛёШЁН№ШкаТЮХЯюФПЕФЪ§ОнЙмЕР
ећИіЪ§ОнЙмЕРСїЖЏШчЭМ1ЃК
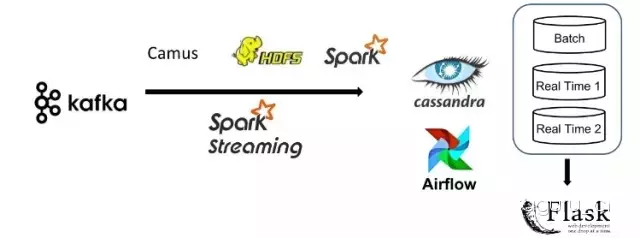
ЭМ1
ЪфШыЪ§ОнИёЪНЮЊJSONЃЌжївЊРДздзлКЯНЛвзаХЯЂКЭTwitterаТЮХЁЃJSONИёЪНЕФЯћЯЂЛсpushЕНKafkaЃЌВЂБЛХњДІРэВуЃЈbatch
layerЃЉКЭЪЕЪБДІРэВуЃЈreal-time layerЃЉЯћЗбЁЃЪЙгУKafkaзїЮЊЪ§ОнЙмЕРЕФЪфШыЦ№ЕуЃЌЪЧвђЮЊKafkaПЩвдБЃжЄМДЪЙдкгВМўЛђепЭјТчЪЇАмЕФЧщПіЯТЃЌЯћЯЂвВЛсБЛДЋЪфЕНећИіЯЕЭГЁЃ
дкХњДІРэВуЃЌCamusЃЈLinkinПЊдДЕФЯюФПЃЌЯжвбИќУћЮЊGobblinЃЉЯћЗбЫљгаKafkaЙ§РДЕФЯћЯЂВЂБЃДцЕНHDFSЩЯЃЌШЛКѓSparkДІРэЫљгаЕФНЛвзРњЪЗМЦЫуУПИіЙЩЦБНЛвзепГжгаЕФЙЩЦБзМШЗЪ§СПЃЌЖдгІЕФНсЙћЛсаДШыCassandraЪ§ОнПтЁЃ
дкСїЪНДІРэВуЃЌSpark StreamingЪЕЪБЯћЗбKafkaЯћЯЂЃЌЕЋВЂВЛЯёStormФЧбљЭъШЋЪЕЪБЃЌSpark
StreamingПЩвдДяЕН500msЕФmicro-batchЪ§ОнСїДІРэЁЃSpark StreamingПЩвджигУХњДІРэВуЕФSparkДњТыЃЌВЂЧвmicro-batchЪ§ОнСїДІРэПЩвдЕУЕНзуЙЛаЁЕФбгГйЁЃ
ХњДІРэВуКЭЪЕЪБДІРэВуЕФНсЙћЖМЛсаДШыЕНCassandraЪ§ОнПтЃЌВЂЭЈЙ§FlaskЬсЙЉвЛИіwebНгПкЗўЮёЁЃЫцзХКЃСПНЛвзЪ§ОнаДШыЯЕЭГЃЌCassandraЪ§ОнПтЕФПьЫйаДШыФмСІЛљБОПЩвдТњзуЁЃ
ШчКЮЕїЖШЪЕЪБДІРэВуКЭХњДІРэВуЕФНсЙћ
ЕБзюаТЕФЯћЯЂНјШыДѓЪ§ОнЯЕЭГЃЌwebНгПкЬсЙЉЕФНсЙћЗўЮёзмФмБЃГжзюаТЃЌзлКЯХњДІРэВуКЭЪЕЪБВуЕФДІРэНсЙћЁЃгУвЛИіР§згРДеЙЪОШчКЮМђЕЅЕФЪЙгУХњДІРэНсЙћКЭЪЕЪБДІРэНсЙћЁЃ
ДгЯТЭМ2ПДЕНЃЌгаШ§ИіЪ§ОнПтБэЃКвЛИіДцДЂХњДІРэНсЙћЃЈЭМ2жаBatchБэЃЉЃЛвЛИіДцДЂздЩЯДЮХњДІРэЭъГЩЪБМфЕуЕНЕБЧАЪБМфЕФЪЕЪБНЛвзЪ§ОнЃЌМДдіСПЪ§ОнЃЈЭМ2жаReal
Time 2БэЃЉЃЛСэЭтвЛИіДцДЂзюаТЪ§ОнЃЌМДзДЬЌБэЃЈЭМ2жаИпССЕФReal Time 1БэЃЉЁЃ
ШЮКЮШэМўЁЂгВМўЛђепЭјТчЮЪЬтв§Ц№ХњДІРэНсЙћвьГЃЃЌЖМЭЈЙ§ЕЅЖРвЛИіЪ§ОнПтБэМЧТМЪ§ОндіСПЃЌВЂдкХњДІРэГЩЙІКѓИќаТЮЊЖдгІЕФХњДІРэНсЙћЪ§РДБЃжЄзюжеЪ§ОнвЛжТадЁЃ
дкетИіР§згжаЃЌМйЩшЕквЛТжХњДІРэЦ№ЪМЪБМфЕуЮЊt0ЃЌвЛИіНЛвзепзіСЫвЛБЪНЛвзКѓЛёЕУСЫ3MЙЋЫОЕФ5000ЙЩЙЩЦБЁЃ

ЭМ2
дкt0ЪБМфЕуЃЌХњДІРэПЊЪМЃЌДІРэЭъжЎКѓзюаТНсЙћДцДЂдкReal Time 1БэЃЌЕБЧАжЕЮЊ5000ЙЩЁЃ

ЭМ3
дкХњДІРэЙ§ГЬжаЃЌНЛвзепТєЕє3MЙЋЫО1000ЙЩЙЩЦБЃЌReal Time 1БэИќаТЪ§ОнжЕЮЊ4000ЙЩЃЌЭЌЪБReal
Time 2БэДцДЂДгt0ЕНЕБЧАЕФдіСП-1000ЙЩЃЌШчЭМ4ЫљЪОЁЃ
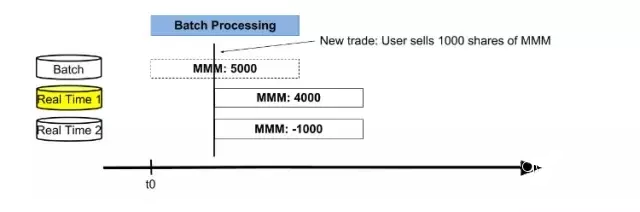
ЭМ4
ЕБХњДІРэНсЪјЃЌШ§ИіБэЕФжЕЗжБ№ЮЊ5000ЃЌ4000ЃЌ-1000ЁЃетЪБЃЌНЛЛЛactiveЪ§ОнПтБэЮЊReal
Time 2БэЃЌНјааКЯВЂХњДІРэНсЙћКЭЪЕЪБНсЙћЛёЕУзюаТНсЙћжЕЁЃШЛКѓжижУReal Time 1БэЮЊ0ЃЌКѓајгУРДДцДЂДгt1ЪБМфЕуПЊЪМЕФдіСПЪ§ОнЁЃНгЯТРДаТЕФвЛТжвдДцДЂзюаТЪ§ОнЕФReal
Time 2БэЮЊЦ№ЕуЃЌбЛЗЧАУцЕФЙ§ГЬЁЃ
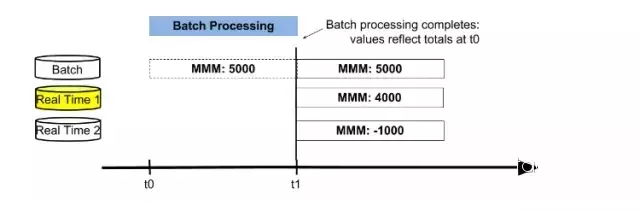
ЭМ5
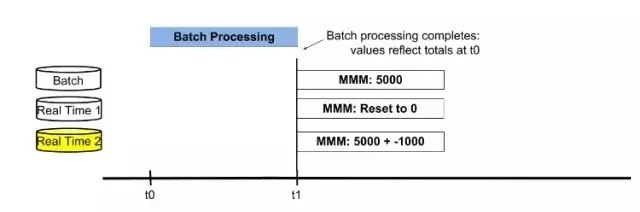
ЭМ6

ЭМ7
вдЩЯУПВНДІРэЙ§ГЬЭъШЋГЩЙІВЂаДШыЪ§ОнПтЃЌПЩвдБЃжЄеЙЪОИјНЛвзепЕФЪ§ОнзМШЗадЁЃЪ§ОнМЏ
ДІРэЪБМфШЁОігкЪ§ОнМЏДѓаЁЃЌДІРэШЮЮёЕФМЦЛЎАДађДІРэЖјВЛЪЧАДздШЛЬьЪБМфЁЃдквЛИіЯЕЭГжаашвЊЙЄзїСїжЇГжИДдгДІРэЁЂЖрШЮЮёвРРЕКЭзЪдДЙВЯэЁЃетРяВЩгУAirbnbЕФЯюФПAirflowЃЌПЩвдЕїЖШГЬађКЭМрПиЙЄзїСїЁЃAirflowАбtaskКЭЩЯгЮИїжжвРРЕЙЙНЈГЩвЛИігаЯђЮоЛЗЭМЃЈDAGЃЉЃЌЛљгкPythonЪЕЯжЃЌПЩвдАбЖрИіШЮЮёаДГЩBashНХБОЃЌBashУќСюФмжБНгЕїгУШЮКЮФЃПщЃЌВЂЧвBashНХБОПЩвдБЛAirflowЪЙгУЃЌетбљЪЙЕУAirflowвзВйзїЁЃAirflowБрГЬНгПкБШЛљгкXMLХфжУЕФЕїЖШЯЕЭГOozieМђЕЅЃЛAirflowЕФBashНХБОБрТыСПБШLuigiвЊЩйКмЖрЃЌLuigiЕФУПИіjobЖМЪЧвЛИіpythonЙЄГЬЁЃУПВНКЯВЂЪЕЪБКЭХњСПЪ§ОнЕФjobдЫааЖМЪЧЧАвЛВНГЩЙІЭъГЩЭЫГіКѓЁЃ
зюКѓМђЕЅзмНсвЛЯТЃЌLambdaМмЙЙЩцМАХњСПДІРэВуКЭЪЕЪБДІРэВуДІРэРњЪЗЪ§ОнвдМАЪЕЪБИќаТЕФЪ§ОнЁЃ ЮЊСЫLambdaМмЙЙЕФЪЕЯжЧаЪЕПЩааЃЌЪ§ОнДІРэвЊЩшМЦГЩХњДІРэВуКЭЪЕЪБДІРэВуНсКЯЁЃБОЯюФПжаЃЌгавЛИіЁАБИгУЁБЪ§ОнПтБэзЈУХгУРДДцДЂЪфШыЕФзмЪ§ЃЌЖјВЛДгХњДІРэВуЖСШЁЪ§ОнЃЌВЂдЪаэЖдХњДІРэВуКЭЪЕЪБДІРэВуЕФНсЙћНјааМђЕЅЕФОлКЯЁЃвдЩЯОЭЪЧгУLambdaМмЙЙЪЕЯжЕФвЛИіИпПЩгУЁЂИпЪ§ОнзюжевЛжТадЕФЯЕЭГЁЃ
|








