| БрМЭЦМі: |
БОЮФНщЩмСЫ
Hbase ЕФЪ§ОнФЃаЭдРэЃЌЗжЮіСЫ Hbase БэЩЈУш/ВщбЏВйзїЕФЪБМфИДдгЖШЃЌВЂЭЈЙ§вЛИігЮЯЗЙЋЫОПЭЛЇЪЕМЪАИР§ЕФНВНтЃЌЗжЮіСЫ
Hbase БэЩшМЦМАПЊЗЂдкЪЕМЪАИР§жаЕФдЫгУЃЌЖдБШСЫВЛЭЌЕФ Hbase ЩшМЦПМСПЖдПЭЛЇЖЫЗУЮЪФЃЪНМАМьЫїадФмЕФВювьЁЃ
БОЮФРДздibmЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1 HbaseИХЪі
ДѓЪ§ОнМА NoSQL ЕФЧАЪРНёЩњ
ДЋЭГЕФЙиЯЕаЭЪ§ОнПтДІРэЗНЪНЪЧЛљгкШЋУцЕФACIDБЃжЄЃЌзёбSQL92ЕФБъзМБэЩшМЦФЃЪНЃЈЗЖЪНЃЉКЭЪ§ОнРраЭЃЌЛљгкSQLгябдЕФDMLЪ§ОнНЛЛЅЗНЪНЁЃГЄЦквдРДетжжЛљгкЙиЯЕаЭЪ§ОнПтЕФITаХЯЂЛЏНЈЩшжаЗЂеЙСМКУЃЌЕЋЪмжЦгкЙиЯЕаЭЪ§ОнПтЬсЙЉЕФЪ§ОнФЃаЭЃЌЖдгкж№НЅГіЯжЕФЃЌЮЊдЄЯШЖЈвхФЃаЭЕФЪ§ОнМЏЃЌЙиЯЕаЭЪ§ОнПтВЛФмКмКУЕФЙЄзїЁЃдНРДдНЖрЕФвЕЮёЯЕЭГашвЊФмЙЛЪЪгІВЛЭЌжжРрЕФЪ§ОнИёЪНКЭЪ§ОндДЃЌВЛашвЊдЄЯШЗЖЪНЖЈвхЃЌОГЃЪЧЗЧНсЙЙЛЏЕФЛђепАыНсЙЙЛЏЕФЃЈШчгУЛЇЗУЮЪЭјеОЕФШежО)ЃЌеташвЊЯЕЭГДІРэБШДЋЭГЙиЯЕаЭЪ§ОнПтИпМИИіЪ§СПМЖЕФЪ§ОнЃЈЭЈГЃЪЧTBМАPBЙцФЃМЖБ№ЃЉЁЃДЋЭГЙиЯЕаЭЪ§ОнПтФмЙЛзнЯђРЉеЙЕНвЛЖЈГЬЖШЃЈШчOracleЕФRACЃЌIBMЕФpureScaleЃЉЁЃЕЋетЭЈГЃвтЮЖзХИпАКЕФШэМўаэПЩЗбгУКЭИДдгЕФгІгУТпМЁЃ
ЛљгкЯЕЭГашЧѓЗЂЩњСЫОоДѓБфЛЏЃЌЪ§ОнММЪѕЕФЯШЧ§УЧВЛЕУВЛжиаТЩшМЦЪ§ОнПтЃЌЛљгкДѓЪ§ОнЕФNoSQLЕФЪяЙтОЭетбљГіЯжСЫЃЌДѓЪ§ОнМАNoSQLЕФЪЙгУЪзЯШдкgoogleЁЂfacebookЕШЛЅСЊЭјЙЋЫОЃЌЫцКѓЪЧН№ШкЁЂЕчаХаавЕЃЌжкЖрHadoop&NoSQLЕФПЊдДДѓЪ§ОнЯюФПШчгъКѓДКЫёАуЗЂеЙЃЌБЛЛЅСЊЭјЕШЙЋЫОгУгкДІРэКЃСПКЭЗЧНсЙЙЛЏРраЭЕФЪ§ОнЁЃвЛаЉЯюФПЙизЂгкПьЫйkey-valueЕФМќжЕДцДЂЃЌвЛаЉЙизЂФкжУЪ§ОнНсЙЙЛђепЛљгкЮФЕЕЕФГщЯѓЛЏЃЌвЛаЉNoSQLЪ§ОнЙмРэММЪѕПђМмЮЊСЫадФмЖјЮўЩќЕБЧАЕФЪ§ОнГжОУЛЏЃЌВЛжЇГжбЯИёЕФACIDЃЌвЛаЉПЊдДПђМмЩѕжСЮЊСЫадФмЗХЦњаДЪ§ОнЕНгВХЬЁЁ
HbaseОЭЪЧNoSQLжазПдНЕФвЛдБЃЌHbaseЬсЙЉСЫМќжЕAPIЃЌГаХЕЧПвЛжТадЃЌЫљвдПЭЛЇЖЫФмЙЛдкаДШыКѓТэЩЯПДЕНЪ§ОнЁЃHBaseвРРЕHadoopЕзВуЗжВМЪНДцДЂЛњжЦЃЌвђДЫФмЙЛдЫаадкЖрИіНкЕузщГЩЕФМЏШКЩЯЃЌВЂЖдПЭЛЇЖЫгІгУДњТыЭИУїЃЌДгЖјЖдУПИіПЊЗЂШЫдБРДЫЕЩшМЦКЭПЊЗЂHbaseЕФДѓЪ§ОнЯюФПБфЕУМђЕЅвзааЁЃHbaseБЛЩшМЦРДДІРэTBЕНPBМЖЕФЪ§ОнЃЌВЂеыЖдИУРрКЃСПЪ§ОнКЭИпВЂЗЂЗУЮЪзіСЫгХЛЏЃЌзїЮЊHadoopЩњЬЌЯЕЭГЕФвЛВПЗжЃЌЫќвРРЕHadoopЦфЫћзщМўЬсЙЉЕФживЊЙІФмЃЌШчDataNodeЪ§ОнШпгрКЭMapReduceХњзЂДІРэЁЃ
2 HbaseМмЙЙМАПђМмМђНщ
БОЮФжаЮвУЧМђвЊНщЩмЯТHbaseЕФМмЙЙМАПђМмЃЌHbaseЪЧвЛжжзЈУХЮЊАыНсЙЙЛЏЪ§ОнКЭЫЎЦНРЉеЙадЩшМЦЕФЪ§ОнПтЁЃЫќАбЪ§ОнДцДЂдкБэжаЃЌБэАДЁАааНЁЃЌСаДиЃЌСаЯоЖЈЗћКЭЪБМфАцБОЁБЕФЫФЮЌзјБъЯЕРДзщжЏЁЃHbaseЪЧЮоФЃЪНЪ§ОнПтЃЌжЛашвЊЬсЧАЖЈвхСаДиЃЌВЂВЛашвЊжИЖЈСаЯоЖЈЗћЁЃЭЌЪБЫќвВЪЧЮоРраЭЪ§ОнПтЃЌЫљгаЪ§ОнЖМЪЧАДЖўНјжЦзжНкЗНЪНДцДЂЕФЃЌЖдHbaseЕФВйзїКЭЗУЮЪга5ИіЛљБОЗНЪНЃЌМДGetЁЂPutЁЂDeleteКЭScanвдМАIncrementЁЃHbaseЛљгкЗЧааНЁжЕВщбЏЕФЮЈвЛЭООЖЪЧЭЈЙ§ДјЙ§ТЫЦїЕФЩЈУшЁЃ
гЩгкHbaseеыЖдPBЁЂTBДцДЂМЖБ№ЃЌвкМЖааЪ§ОнЕФКЃСПБэМЧТМЕФИпВЂЗЂЃЌМЋЯоадФмВщбЏМьЫїЕФЩшМЦГѕждЃЌHbaseдкЮяРэМмЙЙЗНУцЩшМЦГЩвЛИівРППHadoopHDFSЕФШЋЗжВМЪНЕФДцДЂМЏШКЃЌВЂЛљгкHadoopЕФMapReduceЭјИёМЦЫуПђМмЃЌгУвджЇГжИпЭЬЭТСПЪ§ОнЗУЮЪЃЌжЇГжПЩгУадКЭПЩППадЃЌЦфећЬхМмЙЙШчЯТЭМЫљЪОЃК
ЭМ1.HbaseећЬхМмЙЙЭМ
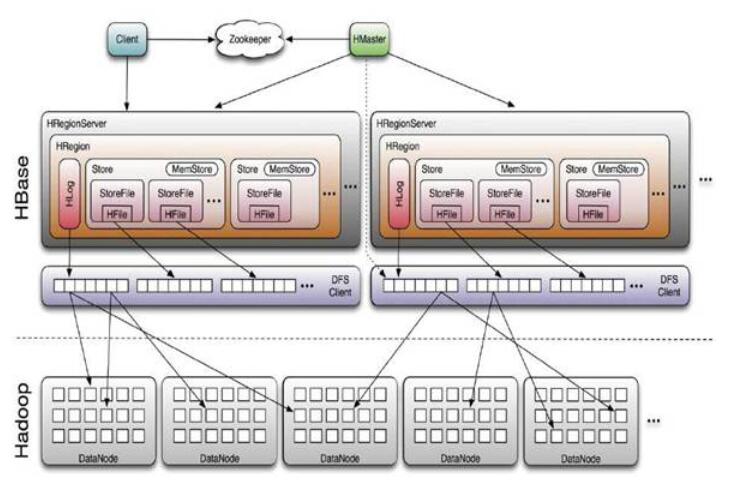
ДгЩЯЭМЮвУЧПЩвдПДГіHbaseЕФзщГЩВПМўЃЌHBaseжаЕФУПеХБэЖМЭЈЙ§ааМќАДеевЛЖЈЕФЗЖЮЇБЛЗжИюГЩЖрИізгБэЃЈHRegionЃЉЃЌФЌШЯвЛИіHRegionГЌЙ§256MОЭвЊБЛЗжИюГЩСНИіЃЌгЩHRegionServerЙмРэЃЌЙмРэФФаЉHRegionгЩHMasterЗжХфЁЃ
HRegionServerДцШЁвЛИізгБэЪБЃЌЛсДДНЈвЛИіHRegionЖдЯѓЃЌШЛКѓЖдБэЕФУПИіСазх(ColumnFamily)ДДНЈвЛИіStoreЪЕР§ЃЌУПИіStoreЖМЛсга0ИіЛђЖрИіStoreFileгыжЎЖдгІЃЌУПИіStoreFileЖМЛсЖдгІвЛИіHFileЃЌHFileОЭЪЧЪЕМЪЕФДцДЂЮФМўЁЃвђДЫЃЌвЛИіHRegionгаЖрЩйИіСазхОЭгаЖрЩйИіStoreЁЃДЫЭтЃЌУПИіHRegionЛЙгЕгавЛИіMemStoreФкДцЛКДцЪЕР§ЁЃ
HBaseДцДЂИёЪНЪЧЛљгкHadoopЕФHDFSЗжВМЪНЮФМўЯЕЭГЃЌHBaseжаЕФЫљгаЪ§ОнЮФМўЖМДцДЂдкHadoopHDFSЩЯЃЌИёЪНжївЊгаСНжжЃК
ЃЈ1ЃЉHFileЃКHBaseжаKeyValueЪ§ОнЕФДцДЂИёЪНЃЌHFileЪЧHadoopЕФЖўНјжЦИёЪНЮФМўЃЌЪЕМЪЩЯStoreFileОЭЪЧЖдHFileзіСЫЧсСПМЖАќзАЃЌМДStoreFileЕзВуОЭЪЧHFileЁЃ
ЃЈ2ЃЉHLogFileЃКHBaseжаWALЃЈWriteAheadLogЃЉЕФДцДЂИёЪНЃЌЮяРэЩЯЪЧHadoopЕФSequenceFileЁЃ
HBaseЪЧЛљгкРрЫЦGoogleЕФBigTableЕФУцЯђСаЕФЗжВМЪНДцДЂЯЕЭГЃЌЦфДцДЂЩшМЦЪЧЛљгкMemtable/SSTableЩшМЦЕФЃЌжївЊЗжЮЊСНВПЗжЃКвЛВПЗжЮЊФкДцжаЕФMemStore(Memtable)ЃЌСэЭтвЛВПЗжЮЊHDFSЩЯЕФHFile(SSTable)ЁЃЛЙгаОЭЪЧДцДЂWALЕФlogЃЌжївЊЪЕЯжРрЮЊHLogЁЃ
ЃЈ3ЃЉMemStoreЃКMemStoreМДФкДцРяЗХзХЕФБЃДцKEY/VALUEгГЩфЕФMAPЃЌЕБMemStoreЃЈФЌШЯ64MBЃЉаДТњжЎКѓЃЌЛсПЊЪМflushЕНДХХЬЃЈМДHadoopЕФHDFSЩЯЃЉЕФВйзїЁЃ
ЮЊАяжњЖСепРэНтЃЌетРяЮвУЧдйАбHFileИќdetailЕФЪ§ОнНсЙЙзіМђвЊЕФНщЩмЃЌHFileЪЧЛљгкHadoopTFileЕФЮФМўРраЭЃЌЦфНсЙЙШчЯТЭМЫљЪОЃК
ЭМ2.HFileНсЙЙЭМ
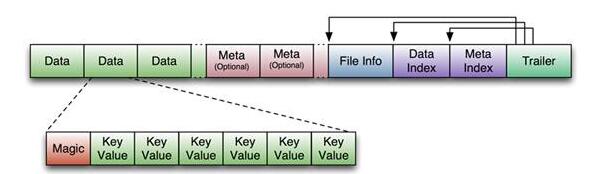
ШчЩЯЭМЫљЪОЃЌHFileЕФЮФМўГЄЖШЪЧБфГЄЕФЃЌНіFILEINFO/TrailerВПЗжЪЧЖЈГЄЃЌTrailerжагажИеыжИЯђЦфЫћЪ§ОнПщЕФЦ№ЪМЕуЁЃЖјIndexЪ§ОнПщдђМЧТМСЫУПИіDataПщКЭMetaПщЕФЦ№ЪМЕуЁЃDataПщКЭMetaПщЖМЪЧПЩгаПЩЮоЕФЃЌЕЋЖдгкДѓЖрЪ§HFileЃЌЖМгаDataПщЁЃ
HLogгУРДДцЗХHBaseЕФШежОЮФМўЃЌгыДЋЭГЙиЯЕаЭЪ§ОнПтРрЫЦЃЌЮЊБЃжЄЖСвЛжТадМАundo/redoЛиЙіЕШЪ§ОнЛжИДВйзїЃЌHbaseдкаДШыЪ§ОнЪБМДЯШНјааwrite-ahead-log(WAL)ВйзїЁЃУПИіHRegionServerЖдгІвЛИіHLogЪЕР§ЃЌHRegionдкГѕЪМЛЏЕФЪБКђHRegionServerЛсНЋИУHLogзїЮЊЙЙдьКЏЪ§ДЋШыЦфжаЃЌвдБуГѕЪМЛЏHLogЪЕР§ЁЃ
HLogFileЪЧвЛИіSequenceFileЃЌжЛФмдкЮФМўЕФФЉЮВЬэМгФкШнЁЃГ§СЫЮФМўЭЗвдЭтЃЌHLogFileгЩвЛЬѕЬѕHLog.EntryЙЙГЩЁЃEntryЪЧHLogЕФЛљБОзщГЩВПЗжЃЌвВЪЧRead/WriteЕФЛљБОЕЅЮЛЁЃ
ЖСепШчЙћЖдHBaseМмЙЙЕФЯИНкФкШнИааЫШЄЃЌПЩвдЭЈЙ§HbaseЙйЭјЃЌСЫНтHbaseећЬхМмЙЙМАЕзВуЮяРэДцДЂЛњжЦЁЃ
HbaseМьЫїЪБМфИДдгЖШ
МШШЛЪЙгУHbaseЕФФПЕФЪЧИпаЇЁЂИпПЩППЁЂИпВЂЗЂЕФЗУЮЪКЃСПЗЧНсЙЙЛЏЪ§ОнЃЌФЧУДHbaseМьЫїЪ§ОнЕФЪБМфИДдгЖШЪЧЙиЯЕЕНЛљгкHbaseЕФвЕЮёЯЕЭГПЊЗЂЩшМЦЕФжижажЎжиЃЌHbaseЕФдЫЫугаЖрПьЃЌБОЮФДгМЦЫуЛњЫуЗЈЕФЪ§бЇНЧЖШзіМђвЊЗжЮіЃЌвдБуЖСепРэНтКѓЮФЕФЯюФПЪЕР§жаHbaseвЕЮёНЈФЃМАЩшМЦФЃЪНжаЕФПМСПвђЫиЁЃ
ЮвУЧЯШвдШчЯТБфСПЖЈвхHbaseЕФЯрЙиЪ§ОнаХЯЂЃК
n=БэжаKeyValueЬѕФПЪ§СПЃЈАќРЈPutНсЙћКЭDeleteСєЯТЕФБъМЧЃЉ
b=HFileРюЪ§ОнПтЃЈHFileBlockЃЉЕФЪ§СП
e=ЦНОљвЛИіHFileРяУцKeyValueЬѕФПЕФЪ§СПЃЈШчЙћжЊЕРааЕФДѓаЁЃЌПЩвдМЦЫуЕУЕНЃЉ
c=УПааРяСаЕФЦНОљЪ§СП
ЮвУЧжЊЕРHbaseжагаСНеХЬиЪтБэЃК-ROOT-&.META.ЃЌЦфжа.META.БэМЧТМRegionЗжЧјаХЯЂЃЌЭЌЪБЃЌ.META.вВПЩвдгаЖрИіRegionЗжЧјЃЌЭЌЪБ-ROOT-БэгжМЧТМ.META.БэЕФRegionаХЯЂЃЌЕЋ-ROOT-жЛгавЛИіRegionЃЌЖј-ROOT-БэЕФЮЛжУгЩHbaseЕФМЏШКЙмПиПђМмЃЌМДZookeeperМЧТМЁЃ
Йигк-ROOT-&.META.БэЕФЯИНкетРяВЛдйРлЪіЃЌИааЫШЄЕФЖСепПЩвдВЮдФHbaseЈCROOT-МА.META.БэзЪСЯЃЌРэНтHbaseIOМАЪ§ОнМьЫїЪБађдРэЁЃ
HbaseМьЫївЛЬѕЪ§ОнЕФСїГЬШчЯТЭМЫљЪОЁЃ
ЭМ3.HbaseМьЫїЪОвтЭМ
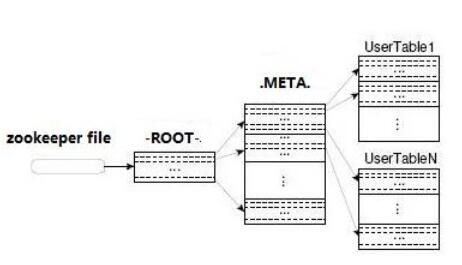
ШчЩЯЭМЮвУЧПЩвдПДГіЃЌHbaseМьЫївЛЬѕПЭЛЇЪ§ОнашвЊЕФДІРэЙ§ГЬДѓжТШчЯТЃК
(1)ШчЙћВЛжЊЕРааНЁЃЌжБНгВщевСаkey-valueжЕЃЌдђФуашвЊВщевећИіregionЧјМфЃЌЛђепећИіTableЃЌФЧбљЕФЛАЪБМфИДдгЖШЪЧO(n)ЃЌетжжЧщПіЪЧзюКФЪБЕФВйзїЃЌЭЈГЃПЭЛЇЖЫГЬађЪЧВЛФмНгЪмЕФЃЌЮвУЧжївЊЗжЮіеыЖдааНЁЩЈУшМьЫїЕФЪБМфИДдгЖШЧщПіЃЌвВОЭЪЧвдЯТ2жС4ВНжшЕФФкШнЁЃ
(2)ПЭЛЇЖЫбАеве§ШЗЕФRegionServerКЭRegionЁЃЛАЗб3ДЮЙЬЖЈдЫЫуевЕНе§ШЗЕФregionЃЌАќРЈВщевZooKeeperЃЌВщев-ROOT-БэЃЌевев.METAБэЃЌетЪЧвЛДЮO(1)дЫЫуЁЃ
(3)дкжИЖЈRegionЩЯЃЌаадкЖСЙ§ГЬжаПЩФмДцдкСНИіЕиЗНЃЌШчЙћЛЙУЛгаЫЂаДЕНгВХЬЃЌФЧОЭЪЧдкMemStoreжаЃЌШчЙћвбОЫЂаДЕНгВХЬЃЌдђдквЛИіHFileжа
МйЖЈжЛгавЛИіHFileЃЌетвЛааЪ§ОнвЊУДдкетИіHFileжаЃЌвЊУДдкMemstoreжаЁЃ
(4)ЖдгкКѓепЃЌЪБМфИДдгЖШЭЈГЃБШНЯЙЬЖЈЃЌМДO(loge)ЃЌЖдгкЧАепЃЌЗжЮіЦ№РДвЊИДдгЕУЖрЃЌдкHFileжаВщеве§ШЗЕФЪ§ОнПщЪЧвЛДЮЪБМфИДдгЖШЮЊO(logb)ЕФдЫЫуЃЌевЕНетвЛааЪ§ОнКѓЃЌдйВщевСаДиРяУцkeyvalueЖдЯѓОЭЪЧЯпадЩЈУшЙ§ГЬСЫЃЈЭЌвЛСаДиЕФСаЪ§ОнЭЈГЃЪЧдкЭЌвЛЪ§ОнПщжаЕФЃЉЃЌетбљЕФЛАЩЈУшЕФЪБМфИДдгЖШЪЧO(elb),ШчЙћСаДижаЕФСаЪ§ОнВЛдкЭЌвЛЪ§ОнПщЃЌдђашвЊЗУЮЪЖрИіСЌајЪ§ОнПщЃЌетбљЕФЪБМфИДдгЖШЮЊO(c)ЃЌвђДЫетбљЕФЪБМфИДдгЖШЪЧСНжжПЩФмадЕФзюДѓжЕЃЌвВОЭЪЧO(max(c,elb)
злЩЯЫљЪіЃЌВщевHbaseжаФГвЛааЕФЪБМфПЊЯњЮЊЃК
O(1)гУгкВщевregion
O(loge)гУРДдкregionжаЖЈЮЛKeyValueЃЌШчЙћЫќЛЙдкMemStoreжа
O(logbЃЉгУРДВщевHFileРяУце§ШЗЕФЪ§ОнПщ
O(maxЃЈcelb)гУРДВщевHFile
HbaseЩшМЦЪЕеН
гЩЩЯЮФНщЩмЕФHbaseЕФећЬхМмЙЙМАМьЫїЕФЪБМфИДдгЖШЗжЮіЮвУЧПЩвдПДГіЃЌааМќЁЂСаДиЕШЕФЩшМЦМАЪ§ОнДцДЂОіЖЈСЫHbaseзмЬхЕФадФмМАжДааВщбЏЕФаЇТЪЃЌКмЖрЪЙгУHbaseЕФЯюФПМАММЪѕШЫдБФмЪьСЗЕФЪЙгУHbaseShellЛђSDKAPIЗУЮЪHbaseЃЌНјааБэДДНЈЁЂЩОГ§ЕШDDLЃЌвдМАput/delete/scanЕШDMLВйзїЃЌЕЋВЂЩюШыЬНОПашвЊЖрЩйИіСаДиЃЌвЛИіСаДиашвЊЖрЩйСаЃЌЪВУДЪ§ОнгІИУДцШыСаУћжаЃЌвдМАЪВУДЪ§ОнгІИУДцШыЕЅдЊЕШПЊЗЂЩшМЦжаЕФЙиМќЮЪЬтЁЃ
ЛљгкHbaseЕФЯЕЭГЩшМЦгыПЊЗЂжаЃЌашвЊПМТЧЕФвђЫиВЛЭЌгкЙиЯЕаЭЪ§ОнПтЃЌHbaseФЃЪНБОЩэКмМђЕЅЃЌЕЋИГгшФуИќЖрЕїећЕФПеМфЃЌгавЛаЉФЃЪНаДадФмКмКУЃЌЕЋЖСШЁЪ§ОнЪББэЯжВЛКУЃЌЛђепе§КУЯрЗДЃЌРрЫЦДЋЭГЪ§ОнПтЛљгкЗЖЪНЕФORНЈФЃЃЌдкЪЕМЪЯюФПжаПМТЧHbaseЩшМЦФЃЪНЪЧЃЌЮвУЧашвЊДгвдЯТМИЗНУцФкШнзХЪжЃК
1. етИіБэгІИУгаЖрЩйИіСаДи
2. СаДиЪЙгУЪВУДЪ§Он
3. УПИіСаДигІгаЖрЩйИіСа
4. СаУћгІИУЪЧЪВУДЃЌОЁЙмСаУћВЛБидкНЈБэЪБЖЈвхЃЌЕЋЪЧЖСаДЪ§ОнЪБЪЧашвЊЕФ
5. ЕЅдЊгІИУДцЗХЪВУДЪ§Он
6. УПИіЕЅдЊДцДЂЪВУДЪБМфАцБО
7. ааНЁНсЙЙЪЧЪВУДЃЌгІИУАќРЈЪВУДаХЯЂ
вдЯТЮвУЧвдвЛИіЪЙгУHbaseММЪѕЕФецЪЕПЭЛЇАИР§ЮЊР§ЃЌЫЕУїHbaseЩшМЦФЃЪНдкецЪЕЯюФПжаЕФЪЕМљЃЌВЂЭЈЙ§ВЛЭЌЕФБэЩшМЦФЃЪНЃЌПЩвдПДГідкФЃЪНЪЧШчКЮгАЯьЕНБэНсЙЙКЭЖСаДБэЕФЗНЪНЗНЗЈЃЌвдМАЖдПЭЛЇЖЫМьЫїВщбЏЕФадФмЕФгАЯь
ПЭЛЇГЁОАНщЩм
ПЭЛЇМђНщЃКПЭЛЇЪЧвЛИіЛЅСЊЭјЪжЛњгЮЯЗЦНЬЈЃЌашвЊеыЖдЙуДѓЪжгЮЭцМвНјааЪжгЮВњЦЗЕФЭГМЦЗжЮіЃЌашвЊДцДЂУПИіЪжгЮЭцМвМДПЭЛЇЖдУПИіЪжгЮВњЦЗЕФЙизЂЖШЃЈгЮЯЗШШЖШЃЉЃЌЧвДцДЂЪБМфЮЌЖШЩЯЕФЙизЂЖШаХЯЂЃЌДгЖјФмеыЖдПЭЛЇЕФЯВКУНјааЭкОђВЂНјааРрЫЦОЋзМгЊЯњЕФЪжгЮЖЈЕуЭЦЫЭЃЌЙуИцгЊЯњЕШвЕЮёЃЌДгЖјРЉДѓИУЦНЬЈЕФгУЛЇСПВЂЬсЩ§гУЛЇеГзХЖШЁЃ
ИУЦНЬЈЩЯЪжгЮВњЦЗЗжРржкЖрЃЌзмЙВдк500грвдЩЯЃЌзЂВсЭцМвЃЈгУЛЇеЪКХЃЉЪ§СПдк200ЭђзѓгвЃЌдкЯпЭцМвЪ§СП5ЭђЖрЃЌУПЬьЪЙгУЪжгЮЦЕТЪЗхжЕдк10Эђ/ШЫДЮвдЩЯЃЌФъдіСП10%вдЩЯЁЃ
ИљОнвдЩЯашЧѓЃЌЪжгЮВњЦЗЖЏЬЌдіГЄЃЌЮоЗЈШЗЖЈФФаЉЪжгЮВњЦЗашвЊБЛДцДЂЃЌШЋВПДцДЂгжЛсБэГЌЙ§200СаЃЌдьГЩДѓСППеМфРЫЗбЃЌЭцМвУПЬьЪЙгУЪжгЮЕФЦЕТЪМАЗжРрВЛШЗЖЈЃЌПЭЛЇзЂВсгУЛЇГЌАйЭђЃЌАДЬьЕФЪЙгУШШЖШЪ§ОнСПГЌЙ§1000ЭђааЃЌКЃСПЪ§ОнвВЪЙЕУБэВщбЏМАвЕЮёЗжЮіашвЊЕФМЏШКЪ§СПХгДѓМАSQLгХЛЏЃЌаЇТЪЕЭЯТЃЌвђДЫДЋЭГЙиЯЕаЭЪ§ОнПтВЛЪЪКЯИУРрЪ§ОнЗжЮіКЭДІРэЕФашЧѓЃЌдкЯюФПжаЮвУЧОіЖЈВЩгУHbaseРДНјааЪ§ОнВуЕФДцДЂЕФЗжЮіЁЃ
ИпБэЩшМЦ
ШУЮвУЧЛиЕНЩЯЮФжаЩшМЦФЃЪНРДПМТЧИУПЭЛЇАИР§жаБэЕФЩшМЦЃЌЮвУЧашвЊДцДЂЭцМваХЯЂЃЌЭЈГЃЪЧЮЂаХКХЃЌQQКХМАдкИУЪжгЮЦНЬЈЩЯзЂВсЕФеЪКХЃЌЭЌЪБашвЊДцДЂИУгУЛЇЙизЂЪВУДЪжгЮВњЦЗЕФаХЯЂЃЌЖјгУЛЇУПЬьЛсЭцвЛИіЛђепЖрИіЪжгЮВњЦЗЃЌУПИіВњЦЗЭцвЛДЮЛђепЖрДЮЃЌвђДЫДцДЂЕФгІИУЪЧИУгУЛЇЖдФГвЛЪжгЮВњЦЗЕФЙизЂЖШЃЈЪЙгУДЮЪ§ЃЉЃЌИУЪЙгУДЮЪ§дкУПЬьЪЧвЛИіЖЏЬЌЕФжЕЃЌЖјгУЛЇЖдЪжгЮВњЦЗвВЪЧвЛИіЖрЖдЖрЕФkey
valueМќжЕЕФМЏКЯЁЃИУЪжгЮЦНЬЈГЇЩЬЙиаФЕФЪЧжюШчЁАXXXПЭЛЇЭцМвЙизЂYYYЪжгЮСЫУДЃПЁБЃЌЁАYYYЪжгЮБЛгУЛЇЙизЂСЫУДЃПЁБетРрЕФвЕЮёЮЌЖШЗжЮіЁЃ
МйЩшУПЬьУПИіЪжгЮЭцМвЖдУПИіВњЦЗЕФЙизЂЖШЖМДцдкИУБэжаЃЌдђвЛИіПЩФмЕФЩшМЦЗНАИЪЧУПИігУЛЇУПЬьЖдгІвЛааЃЌвЛгУЛЇID
ЕБЬьЕФЪБМфДСзїЮЊааНЁЃЌНЈСЂвЛИіБЃДцЪжгЮВњЦЗЪЙгУаХЯЂЕФСаДиЃЌУПСаДњБэИУЬьИУгУЛЇЖдИУВњЦЗЕФЪЙгУДЮЪ§ЁЃ
БОАИР§жаЮвУЧжЛЩшМЦвЛИіСаДиЃЌвЛИіЬиЖЈЕФСаДидкHDFSЩЯЛсгЩвЛИіRegionИКд№ЃЌетИіregionЯТЕФЮяРэДцДЂПЩФмгаЖрИіHFileЃЌвЛИіСаДиЪЙЕУЫљгаСадкгВХЬЩЯДцЗХдквЛЦ№ЃЌЪЙгУетИіЬиадПЩвдЪЙВЛЭЌРраЭЕФСаЪ§ОнЗХдкВЛЭЌЕФСаДиЩЯЃЌвдБуИєРыЃЌетвВЪЧHbaseБЛГЦЮЊУцЯђСаДцДЂЕФдвђЃЌдкетеХБэРяЃЌвђЮЊЫљгаЪжгЮВњЦЗВЂУЛгаУїЯдЕФЗжРрЃЌЖдБэЕФЗУЮЪФЃЪНвВВЛашЧјЗжЪжгЮВњЦЗРраЭЃЌвђДЫВЂВЛашвЊЖрИіСаДиЕФЛЎЗжЃЌФуашвЊвтЪЖЕНвЛЕуЃКвЛЕЉДДНЈСЫБэЃЌШЮКЮЖдИУБэСаДиЕФЖЏзїЭЈГЃЖМашвЊЯШШУБэofflineЁЃ
ЮвУЧПЩвдЪЙгУHbaseShellЛђепHbaseSDKapiДДНЈБэЃЌHbaseshellНХБОЪОР§ШчЯТЃК
ЧхЕЅ1.HbaseshellНХБОЪОР§
$hbase shell
Version 0.92.0, r1231986, Mon Nov 16 13:16:35
UTC 2015
$hbase(main):001:0 >create 'prodFocus' , 'degeeInfo'
0 row(s) in 0.1200 seconds
hbase(main):008:0> describe 'prodFocus'
DESCRIPTION ENABLED
'prodFocus', {NAME => 'cf', DATA_BLOCK_ENCODING
=> true
'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE
=>
'0', VERSIONS => '1', COMPRESSION => 'NONE',
MIN_VE
RSIONS => '0', TTL => '2147483647', KEEP_DELETED_CE
LLS => 'false', BLOCKSIZE => '65536', IN_MEMORY
=>
'false', BLOCKCACHE => 'true'}
1 row(s) in 0.0740 seconds |
ЯждкЕФБэШчЯТЭМЫљЪОЃЌвЛИіДцгаЪОР§Ъ§ОнЕФБэЁЃ
Бэ1.prodFocusБэЪОР§
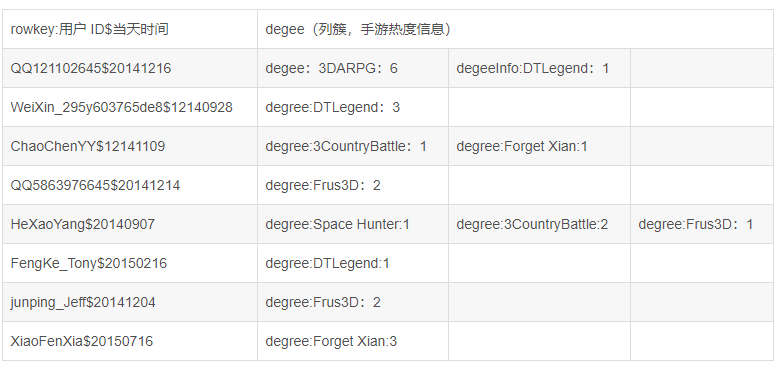
БэЩшМЦНтЪЭШчЯТЃК
rowkeyЮЊQQ121102645$20141216БэЪОеЪКХЮЊQQ121102645ЕФЪжгЮЭцМвЃЈвдQQКХСЊАюШЯжЄЕФЃЉдк2014Фъ12дТ16ШеЕБЬьЕФгЮЯЗМЧТМЃЛСаДиfocusproМЧТМИУааеЫЛЇЕБЬьЖдУПжжВњЦЗРраЭЕФЕуЛїШШЖШ(гЮЯЗДЮЪ§)ЃЌБШШчSpaceHunter:ЃК1БэЪОЭц(ЛђепЕуПЊ)SpaceHunter:(ЪБПеСдШЫ)ЕФДЮЪ§ЮЊ1ДЮ
ЯждкФуашвЊМьбщетеХБэЪЧЗёТњзуашЧѓЃЌЮЊДЫзюживЊЕФЪТЪЧЖЈвхЗУЮЪФЃЪНЃЌвВОЭЪЧгІгУЯЕЭГШчКЮЗУЮЪHbaseБэжаЕФЪ§ОнЃЌдкећИіHbaseЯЕЭГЩшМЦПЊЗЂЙ§ГЬжагІИУОЁдчетУДзіЁЃ
ЮвУЧЯждкРДПДЃЌЮвУЧЩшМЦЕФИУHbaseБэЪЧЗёФмЛиД№ПЭЛЇЙиаФЕФЮЪЬтЃКБШШчЁАеЪКХЮЊQQ121102645ЕФгУЛЇЙизЂЙ§ФФаЉЪжгЮЃПЁБЃЌбизХетИіЗНЯђНјвЛВНЫМПМЃЌгаЯрЙивЕЮёЗжЮіЕФЮЪЬтЃКЁАQQ121102645гУЛЇЪЧЗёЭцЙ§3CountryBattleЃЈШ§Йњ3ЃЉЪжгЮЃПЁБЁАФФаЉгУЛЇЙизЂСЫDTLegendЃЈЕЖЫўДЋЦц)ЃПЁБЁА3CountryBattleЃЈШ§Йњ3ЃЉЪжгЮБЛЙизЂЙ§Т№ЃПЁБ
ЛљгкЯждкЕФprodFocusБэЩшМЦЃЌвЊЛиД№ЁАеЪКХЮЊQQ121102645ЕФгУЛЇЙизЂЙ§ФФаЉЪжгЮЃПЁБетИіЗУЮЪФЃЪНЃЌПЩвддкБэЩЯжДаавЛИіМђЕЅЕФScanЩЈУшВйзїЃЌИУЕїгУЛсЗЕЛиећИіQQ121102645ЧАзКЕФећИіааЃЌУПвЛааЕФСаДиНјааСаБщРњОЭФмевЕНгУЛЇЙизЂЕФЪжгЮСаБэЁЃ
ДњТыЪОР§ШчЯТЃК
ЧхЕЅ2.ПЭЛЇЖЫВщбЏгУЛЇЙизЂЪжгЮСаБэ
static {
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set (ЁАhbase.zookeeper.quorumЁБ,ЁА192.168.2.6ЁБ);
HBASE_CONFIG.set (ЁАhbase.zookeeper.property.clientPortЁБ,ЁА2181ЁБ);
cfg = new HBaseConfiguration(HBASE_CONFIG);
}
HTablePool pool = new HTablePool();
HTableInterface prodTable = pool.getTable(ЁАprodFocusЁБ);
Scan a = new Scan();
a.addFamily(Bytes.toBytes (ЁАdegreeInfoЁБ));
a.setStartRow(Bytes.toBytes (ЁАQQ121102645ЁБ));
ResultScanner results = prodTable.getScanner(a);
List<KeyValue> list = result.list();
List<String> followGamess = new ArrayList<String>();
for(Result r:results){
KeyValue kv = iter.next();;
String game =kv.get(1];
followGames.add(user);
} |
ДњТыНтЪЭЃКЪзЯШЭЈЙ§ConfigurationЩшжУHbaseMasterжїЛњМАПЭЛЇЖЫСЌНгЖЫПкЃЌШЛКѓЪЙгУHtableInterfaceНгПкЪОЧэНгЩЯprodFocusБэЃЌвђЮЊprodFocusБэrowkeyЩшМЦЮЊгУЛЇID
$ ЕБЬьЕФЪБМфДСЃЌвђДЫЮвУЧДДНЈвдгУЛЇЁАQQ121102645ЁБЮЊМьЫїЧАзКЕФScanЩЈУшЃЌЩЈУшЗЕЛиЕФResultScannerМДЮЊИУгУЛЇЯрЙиЕФЫљгаааЪ§ОнЃЌБщРњУПааЕФЁАdegreeInfoЁБСаДижаЕФИїИіСаМДПЩЛёЕУИУгУЛЇЫљгаЙизЂЃЈЭцЙ§ЃЉЕФЪжгЮВњЦЗЁЃ
ЙигкHbaseAPIВйзїЕФДњТыетРяВЛдйЯъЪіЃЌИааЫШЄЕФЖСепПЩвдВщдФHbaseSDKЃЌЪьЯЄВйзїHBaseБэМАputЁЂscanЁЂdeleteДњТыЁЃ
ЕкЖўИіЮЪЬтЁАQQ121102645гУЛЇЪЧЗёЭцЙ§3CountryBattleЃЈШ§Йњ3ЃЉЪжгЮЁБЕФвЕЮёИњЕквЛИіРрЫЦЃЌПЭЛЇЖЫДњТыПЩвдгУScanевГіааНЁЮЊQQ121102645ЧАзКЕФЫљгаааЃЌЗЕЛиЕФresultМЏКЯПЩвдДДНЈвЛИіЪ§зщСаБэЃЌБщРњетИіСаБэМьВщ3CountryBattlesЪжгЮЪЧЗёзїЮЊСаУћДцдкЃЌМДПЩХаЖЯИУгУЛЇЪЧЗёЙизЂФГвЛЪжгЮЃЌЯргІДњТыгыЩЯЮФЮЪЬт1ЕФДњТыРрЫЦЃК
ЧхЕЅ3.ПЭЛЇЖЫХаЖЯгУЛЇЪЧЗёЙизЂФГвЛЪжгЮ
HTablePool pool
= new HTablePool();
HTableInterface prodTable = pool.getTable(ЁАprodFocusЁБ);
Scan a = new Scan();
a.addFamily(Bytes.toBytes(ЁАdegreeInfoЁБ));
a.setStartRow(Bytes.toBytes(ЁАQQ121102645ЁБ));
ResultScanner results = prodTable.getScanner(a);
List<Integer> degrees = new ArrayList<Integer>();
List<KeyValue> list = results.list();
Iterator<KeyValue> iter = list.iterator();
String gameNm =ЁА3CountryBattleЁБ;
while(iter.hasNext()){
KeyValue kv = iter.next();
if(gameNm.equals(Bytes.toString(kv.getKey()))){
return true;
}
}
prodTable.close(); |
ДњТыНтЪЭЃКЭЌбљЭЈЙ§ЩЈУшЧАзКЮЊЁАQQ121102645ЁБЕФScanжДааБэМьЫїВйзїЃЌЗЕЛиЕФList<keyValue>Ъ§зщжаУПвЛKey-valueЪЧdegreeInfoСаДижаУПвЛСаЕФМќжЕЖдЃЌМДгУЛЇЙизЂЃЈЭцЙ§ЃЉЕФЪжгЮВњЦЗаХЯЂЃЌХаЖЯЦфKeyжЕЪЧЗёАќКЌЁА3CountryBattleЁБЕФгЮЯЗУћаХЯЂМДПЩжЊЕРИУгУЛЇЪЧЗёЙизЂИУЪжгЮВњЦЗЁЃ
ПДЦ№РДетИіБэЩшМЦЪЧМђЕЅЪЕгУЕФЃЌЕЋЪЧШчЙћЮвУЧНгзХПДЕкШ§ИіКЭЕкЫФИівЕЮёЮЪЬтЁАФФаЉгУЛЇЙизЂСЫDTLegendЃЈЕЖЫўДЋЦц)ЃПЁБЁА3CountryBattleЃЈШ§Йњ3ЃЉЪжгЮБЛЙизЂЙ§Т№ЃПЁБ
ШчФуЫљПДЕНЕФЃЌЯжгаЕФБэЩшМЦЖдгкЖрИіЪжгЮВњЦЗЪЧЗХдкСаДиЕФЖрИіСазжЖЮжаЕФЃЌвђДЫЕБФГвЛгУЛЇЖдВњЦЗЕФЯВКУЧїгкЖрбљЛЏЕФЪБКђЃЈproductkey-valueМќжЕЖдЛсКмЖрЃЌвтЮЖзХФГвЛrowkeyЕФБэСаДиЛсБфГЄЃЌетБОЩэвВВЛЪЧДѓЮЪЬтЃЌЕЋЫќгАЯьЕНСЫПЭЛЇЖЫЖСШЁЕФДњТыФЃЪНЃЌЛсШУПЭЛЇЖЫгІгУДњТыБфЕУКмИДдгЁЃ
ЭЌЪБЃЌЖдгкЕкШ§КЭЕкЫФЮЪЬтЖјбдЃЌУПдіМгвЛжжЪжгЮЙизЂЕФkey-valueМќжЕЃЌПЭЛЇЖЫДњТыБиаывЊЯШЖСГіИУгУЛЇЕФrowааЃЌдйБщРњЫљгаааСаДижаЕФУПвЛИіСазжЖЮЁЃДгЩЯЮФHbaseЫїв§ЕФдРэМАФкВПМьЫїЕФЛњжЦЮвУЧжЊЕРЃЌааНЁЪЧЫљгаHbaseЫїв§ЕФОіЖЈадвђЫиЃЌШчЙћВЛжЊЕРааНЁЃЌОЭашвЊАбЩЈУшЯоЖЈдкШєИЩHFileЪ§ОнПщжаЃЌИќТщЗГЕФЪЧЃЌШчЙћЪ§ОнЛЙУЛгаДгHDFSЖСЕНЪ§ОнПщЛКДцЃЌДггВХЬЖСШЁHFileЕФПЊЯњИќДѓЃЌДгЩЯЮФHbaseМьЫїЕФЪБМфИДдгЖШЗжЮіРДПДЃЌЯждкЕФHbaseБэЩшМЦФЃЪНЯТашвЊдкRegionжаМьЫїУПвЛСаЃЌаЇТЪЪЧСаЕФИіЪ§*O(max(elb)ЃЌДгРэТлЩЯвбОЪЧзюИДдгЕФЪ§ОнМьЫїЙ§ГЬЁЃ
ЖдЙизЂИУЦНЬЈвЕЮёЕФПЭЛЇЙЋЫОНЧЖШПМТЧЃЌЕкШ§ИіЕкЫФИіЕФвЕЮёЮЪЬтИќМгЙизЂПЭЛЇЖЫЛёШЁЗжЮіНсЙћЕФЪЕЪБЗжЮіЕФадФмЃЌвђДЫДгЩшМЦФЃЪНЩЯгІИУЩшМЦИќГЄЕФааНЁЃЌИќЖЬЕФСаДизжЖЮЃЌЬсИпHbaseааНЁЕФМьЫїаЇТЪВЂЭЌЪБМѕЩйЗУЮЪПэааЕФПЊЯњЁЃ
ПэБэЩшМЦ
HbaseЩшМЦФЃЪНЕФМђЕЅКЭСщЛюдЪаэФњзіГіИїжжгХЛЏЃЌВЛашвЊзіКмЖрЕФЙЄзїОЭПЩвдДѓДѓМђЛЏПЭЛЇЖЫДњТыЃЌВЂЧвЪЙМьЫїЕФадФмЛёЕУЯджјЬсЩ§ЁЃЮвУЧЯждкРДПДПДprodFocusБэЕФСэвЛжжЩшМЦФЃЪНЃЌжЎЧАЕФБэЩшМЦЪЧвЛжжПэБэЃЈwidetableЃЉФЃЪНЃЌМДвЛааАќРЈКмЖрСаЁЃУПвЛСаДњБэФГвЛЪжгЮЕФШШЖШЁЃЭЌбљЕФаХЯЂПЩвдгУИпБэЃЈtalltableЃЉаЮЪНДцДЂЃЌаТЕФИпБэаЮЪНЩшМЦЕФВњЦЗЙизЂЖШБэНсЙЙШчБэ2ЫљЪОЁЃ
Бэ2.prodFocusV2БэЪОР§
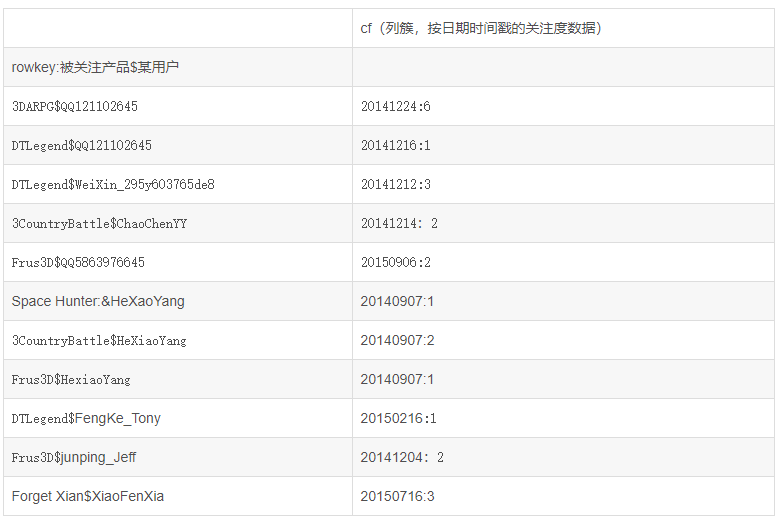
БэНтЪЭЃКНЋВњЦЗдкФГвЛЬьБЛФГгУЛЇЙизЂЕФЙиСЊЙиЯЕЩшМЦЕНrowkeyжаЃЌЖјЦфЙизЂЖШЪ§ОнжЛгУвЛИіkey-valueРДДцДЂЃЌааНЁDaqier_weixin1398765386465ДЎСЊСЫСНИіжЕЃЌВњЦЗУћКЭгУЛЇЕФеЪКХЃЌетбљдРДБэЩшМЦжаФГвЛгУЛЇдкФГЬьЕФаХЯЂБЛзЊЛЛЮЊвЛИіЁАВњЦЗ-ЙизЂЕФгУЛЇЁБЕФЙиЯЕЃЌетЪЧЕфаЭЕФИпБэЩшМЦЁЃ
HFileжаЕФkeyvalueЖдЯѓДцДЂСаДиУћзжЁЃЪЙгУЖЬЕФСаДиУћзждкМѕЩйгВХЬКЭЭјТчIOЗНУцКмгаАяжњЁЃетжжгХЛЏЗНЪНвВПЩвдгІгУЕНааНЁЃЌСаУћЃЌЩѕжСЕЅдЊЁЃНєДеЕФrowkeyДцДЂвЕЮёЪ§ОнвтЮЖгІгУГЬађМьЫїЪБЃЌIOИКдиЗНУцЛсДѓДѓНЕЕЭЁЃетжжаТЩшМЦдкЛиД№жЎЧАвЕЮёЙиаФЕФЁАФФаЉгУЛЇЙизЂСЫXXXXВњЦЗЃПЁБЛђепЁАXXXXВњЦЗБЛЙизЂЙ§Т№ЃПЁБетРрЮЪЬтЪБЃЌОЭПЩвдЛљгкааНЁЪЙгУget()жБНгЕУЕНД№АИЃЌСаДижажЛгавЛИіЕЅдЊЃЌЫљвдВЛЛсгаЕквЛжжЩшМЦжаЖрИіkeyvalueБщРњЕФЮЪЬтЃЌдкHbaseжаЗУЮЪФизЄСєдкBlockCacheРыЕУвЛИіеааЪЧзюПьЕФЖСВйзїЁЃДгIOЗНУцРДПДЃЌЩЈУшетаЉаадквЛИіПэааЩЯжДааgetУќСюШЛКѓБщРњЫљгаЕЅдЊЯрБШЃЌДгRegionServerЖСШЁЕФЪ§ОнСПЪЧЯрЭЌЕФЃЌЕЋЫїв§ЗУЮЪаЇТЪУїЯдДѓДѓЬсИпСЫ
Р§ШчвЊЗжЮіЁА3CountryBattlesЃЈШ§ЙњШКалЃЉЪжгЮЪЧЗёБЛQQ121102645гУЛЇЙизЂЃПЁБЪБЃЌПЭЛЇЖЫДњТыЪОР§ШчЯТЃК
ЧхЕЅ4.ПЭЛЇЖЫХаЖЯФГвЛЪжгЮВњЦЗЪЧЗёБЛЙизЂ
HTablePool pool
= new HTablePool();
HTableInterface prodTable = pool.getTable(ЁАprodFocusV2ЁБ);
String userNm =ЁАQQ121102645ЁБ;
String gameNm =ЁА3CountryBattlesЁБ;
Get g = new Get(Bytes.toBytes(userNm+ЁБ$ЁБ+gameNm));
g.addFamily(Bytes.toBytes(ЁАdegreeInfoЁБ));
Result r = prodTable.get(g);
if(!r.isEmpty()){
return true;
}
table.close(); |
ДњТыНтЪЭЃКгЩгкprodFocusV2ЕФrowkeyЩшМЦИФЮЊБЛЙизЂВњЦЗ$гУЛЇIdЕФИпБэФЃЪНЃЌЪжгЮВњЦЗМАгУЛЇаХЯЂжБНгДцЗХдкааНЁжаЃЌвђДЫДњТывдЪжгЮВњЦЗУћЁА3CountryBattlesЁБ
ЁА$ЁБ гУЛЇеЪКХЁАQQ121102645ЁБЕФByteЪ§ОнзїЮЊGetМќжЕЃЌдкБэЩЯжБНгжДааGetВйзїЃЌХаЖЯЗЕЛиЕФResultНсЙћМЏЪЧЗёЮЊПеМДПЩжЊЕРИУЪжгЮВњЦЗЪЧЗёБЛгУЛЇЙизЂЁЃ
ЮвУЧЪЙгУбЙСІВтЪдРДМьбщвЛЯТСНжжHbaseБэЩшМЦФЃЪНЯТЕФВЂЗЂЗУЮЪадФмЕФЖдБШЃЌдкАйЭђМЖМАЧЇЭђМЖааЪ§ОнЬѕМўЯТЃЌВЩгУПэБэКЭИпБэЕФСНжжЩшМЦФЃЪНЯТЃЌдкНјааЁБЙизЂ3CountryBattlesЪжгЮЕФгУЛЇЁБВщбЏЃЌШЁЕУresultМьЫїНсЙћЕФЯргІЪБМфШчЯТБэЫљЪОЃК
Бэ3.ИпБэvsПэБэМьЫїадФмЖдБШ
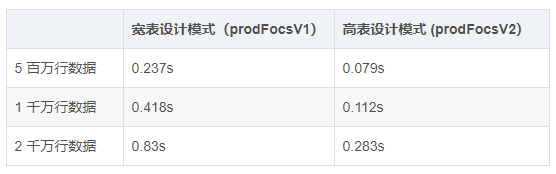
ПЩвдПДЕНдкПЭЛЇЙиаФЕФВњЦЗЙизЂЖШЮЌЖШЩЯЃЌИпБэЕФадФмБШПэБэвЊИпГі50%вдЩЯЃЌетЪЧrowkeyКЭСаДиЕФЩшМЦгАЯьЕНHbaseЫїв§МьЫїдкHbaseЩшМЦФЃЪНжаГЩЙІдЫгУЕФБэЯжЁЃеЦЮеHbaseЪ§ОнДцДЂЛњжЦМАФкВПМьЫїЙЄзїЛњжЦжЎЫљвдживЊЃЌКмДѓвЛВПЗждвђОЭдкгкдЫгУИУЛњжЦЪЧЬсЩ§адФмЕФЛњЛсЁЃ
3ЦфЫћЕїгХПМТЧ
ЕБШЛЛЙгавЛаЉЦфЫћгХЛЏММЧЩЁЃФуПЩвдЪЙгУMD5жЕзіЮЊааНЁЃЌетбљПЩвдЕУЕНЖЈГЄЕФrowkeyЁЃЪЙгУЩЂСаМќЛЙгаЦфЫћКУДІЃЌФуПЩвддкааНЁжаЪЙгУMD5ШЅЕєЁА$ЁБЗжИєЗћЃЌетЛсДјРДСНИіКУДІЃКвЛЪЧааМќЖМЪЧЭГвЛГЄЖШЕФЃЌПЩвдАяжњФуИќКУЕФдЄВтЖСаДадФмЁЃЕкЖўИіКУДІЪЧЃЌВЛдйашвЊЗжИєЗћКѓЃЌscanЕФВйзїДњТыИќШнвзЖЈвхЦ№ЪМКЭЭЃжЙМќжЕЁЃетбљЕФЛАФуЪЙгУЛљгкгУЛЇ
ЪжгЮУћЕФMD5ЩЂСажЕРДЩшЖЈScanЩЈУшНєСкЕФЦ№ЪМааЃЈstartRowКЭstopRowЃЉОЭПЩвдевЕНИУЪжгЮЪмЙизЂЕФзюаТЕФШШЖШаХЯЂЁЃ
ЪЙгУЩЂСаМќвВЛсгажњгкЪ§ОнИќОљдШЕФЗжВМдкregionЩЯЁЃШчИУАИР§жаЃЌШчЙћПЭЛЇЕФЙизЂЖШЪЧе§ГЃЕФЃЈМДУПЬьЖМгаВЛЭЌЕФПЭЛЇЭцВЛЭЌЕФгЮЯЗЃЉЃЌФЧЪ§ОнЕФЗжВМВЛЪЧЮЪЬтЃЌЕЋгаПЩФмФГаЉПЭЛЇЕФЙизЂЖШЪЧЬьЩњЧуаБЕФЃЈМДФГгУЛЇОЭЪЧЯВЛЖФГвЛСНИіВњЦЗЃЌУПЬьШШЖШЖМдкетвЛСНИіВњЦЗЩЯЃЉЃЌФЧОЭЛсЪЧвЛИіЮЪЬтЃЌФуЛсгіЕНИКдиУЛгаЗжЬЏдкећИіHbaseМЏШКЩЯЖјЪЧМЏжадкФГвЛИіШШЕуЕФregionЩЯЃЌетМИИіregionЛсГЩЮЊећЬхадФмЕФЦПОБЃЌЖјШчЙћЖдDaqier_weixin1398765386465ФЃЪНзіMD5МЦЫуВЂАбНсЙћзїЮЊааМќЃЌФуЛсдкЫљгаregionЩЯЪЕЯжвЛИіОљдШЕФЗжВМЁЃ
ЪЙгУMD5ЩЂСаprodFocusV2БэКѓЕФБэЪОР§ШчЯТЃК
Бэ4.rowkeyMD5БэЪОР§
НсЪјгя
БОЮФНщЩмСЫHadoopДѓЪ§ОнЦНЬЈЯТЕФnonsqlЕФЕфаЭЦНЬЈ-HbaseЕФећЬхМмЙЙМАЛљБОдРэЃЌЗжЮіСЫдкHbaseЮяРэФЃаЭКЭМьЫїЙЄзїЛњжЦЯТHbaseБэЕФЩшМЦФЃЪНЁЃВЂвдвЛИіЪЕМЪЪжгЮЙЋЫОЕФПЭЛЇАИР§ЃЌУшЪіСЫЩшМЦHbaseБэЪБеыЖдПЭЛЇЗУЮЪФЃЪНМАадФмашЧѓЪБЕФММЧЩЃЌЭЈЙ§ВЛЭЌЩшМЦФЃЪНЯТДњТыЪЕЯжКЭВтЪдЖдБШНјааСЫзюМбЪЕМљВЮПМАИР§ЕФЯъНтЁЃ
|








