| БрМЭЦМі: |
БОЮФЮвУЧЯъЯИНВЪі
Pravega ЖЏЬЌЕЏадЩьЫѕЬиадЕФЪЕЯжКЭгІгУЪЕР§ЁЃ
БОЮФРДздinfoQЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
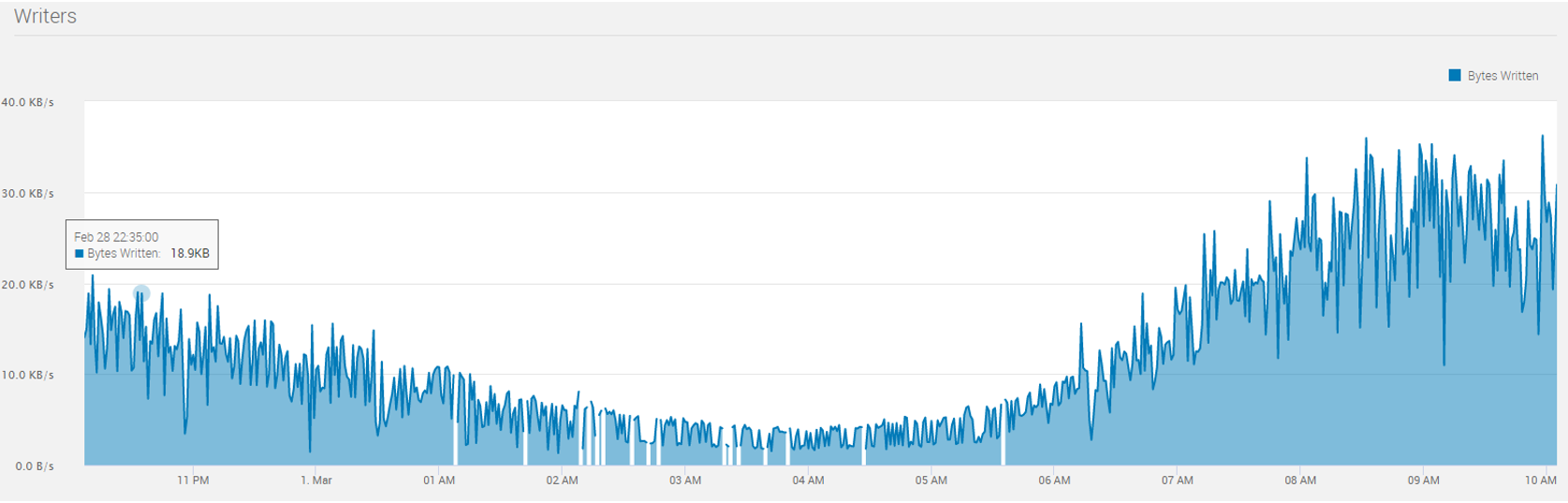
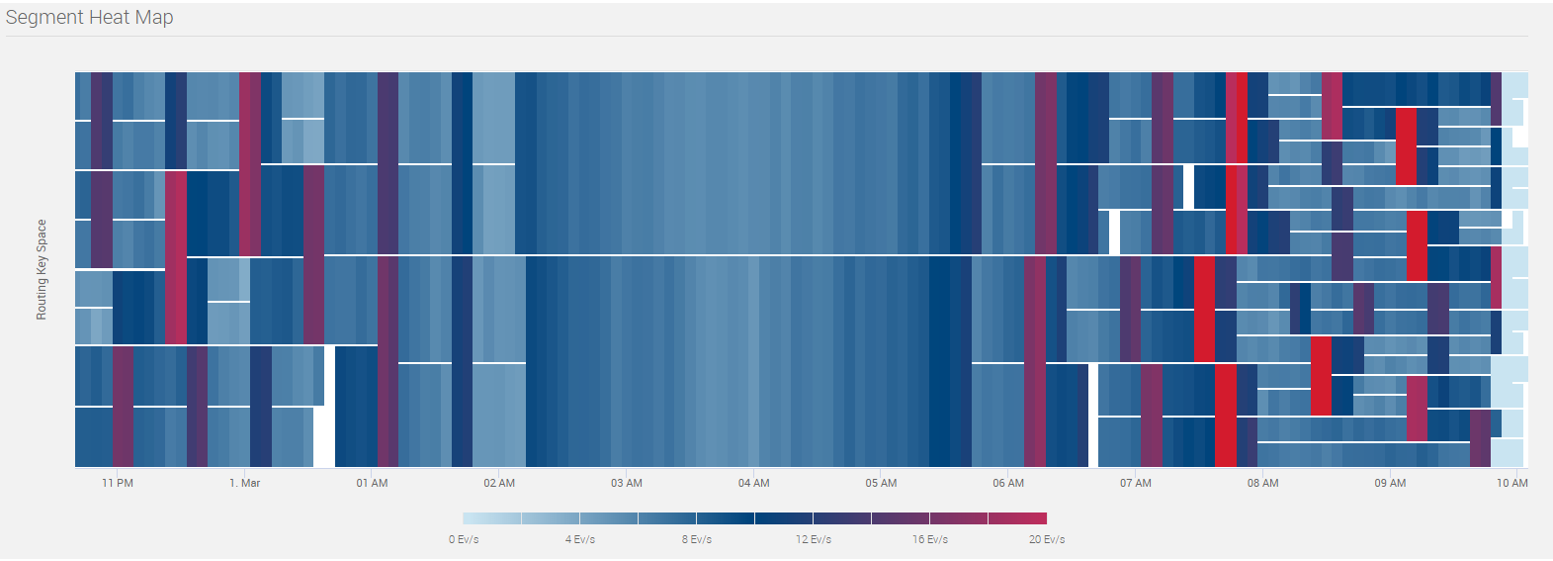
дкЕБЯТжкЖрЛЅСЊЭјгІгУГЁОАЯТЃЌЪЕЪБЪ§ОнВњЩњЕФЫйТЪИљОнЪБМфЕФБфЛЏЛсгазХЗЬьИВЕиЕФБфЛЏЁЃЮвУЧМШПЩФмУцЖджюШчЭтТєЖЉЕЅЁЂзЁЗПГЩНЛСПЁЂЫЋЪЎвЛЖЉЕЅетаЉГЁОАЃЌЦфЪ§ОнСПгажмЦкадЧвдкОжВПЕФЪБМфФкЛсгаПЩдЄжЊЕФЭЛЗЂЕФЪ§ОнЗхжЕЃЛвВПЩФмУцЖдЮЂВЉШШЫбЁЂТЗПіЪТЙЪаХЯЂетвЛРрЮоЗЈдЄжЊЕФЭЛЗЂЕФЪ§ОнСПМЄдіЁЃ
вдЩЯЬиадЭЈЫзРДНВЃЌОЭЪЧСїСПЪ§ОнЕНДяСПгаЗхгаЙШЃЌЧвПЩФмВЛПЩдЄжЊЁЃе§вђШчДЫЃЌPravega зїЮЊвЛПюСїДцДЂЕФВњЦЗЃЌБиаыФмЙЛгІЖдЫВЪБЕФЪ§ОнКщЗхЃЌзіЕНЁАЯїЗхЬюЙШЁБЃЌШУЯЕЭГздЖЏЕиАщЫцЪ§ОнЕНДяЫйТЪЕФБфЛЏЖјЩьЫѕЃЌМШФмЙЛдкЪ§ОнЗхжЕЪБНјааРЉШнЬсЩ§ЫВЪБДІРэФмСІЃЌгжФмЙЛдкЪ§ОнЙШжЕЪБНјааЫѕШнНкЪЁдЫааГЩБОЃЌЖјЖСаДПЭЛЇЖЫЮоашЖюЭтНјааЕїећЁЃ
етвЛЬиадЖдгкУцЯђЦѓвЕПЊЗЂВњЦЗгШЦфживЊЃЌDevops ПЊЯњдкЦѓвЕжаЖМЛсБЛЙщШыВњЦЗ
TCO(Total Cost of Ownership) , ЫљвдВњЦЗздЩэЕФЖЏЬЌздЪЪгІФмСІНЋЛсЪЧБиБИЬѕМўЃЌетвВЪЧЛигІЮвУЧдкЯЕСаЮФеТЕкЖўЦЊжаЬсЕНЕФШ§ДѓЬєеНзюКѓвЛЬѕЁЃ
ЖЏЬЌЩьЫѕад
ЖдгкЗжВМЪНЯћЯЂЯЕЭГРДЫЕЃЌвЛИіЩшМЦСМКУЕФЃЌПЩРЉеЙЕФЗжЧјЛњжЦБиВЛПЩЩйЁЃЗжЧјЛњжЦЪЙЕУЖСаДЕФВЂааЛЏГЩЮЊПЩФмЃЌЖјвЛИіСМКУЕФЗжЧјРЉеЙЛњжЦЪЙЕУЦѓвЕдкУцСйвЕЮёдіГЄЪБПЩвдБфЕУИќЕУаФгІЪжЁЃКЭаэЖрЛљгкОВЬЌЗжЧјЃЌЛђепашвЊЪжЖЏРЉеЙЗжЧјЃЈШч
KafkaЃЉЕФЯЕЭГВЛЭЌЕФЪЧЃЌPravega ПЩвдИљОнЪ§ОнИКдиЖЏЬЌЕиЩьЫѕ StreamЃЌвдДЫРДЪЕЪБЕигІЖдСїСПИКдиЕФБфЛЏЁЃ
ЕБЧАНтОіЗНАИЕФвЛаЉЮЪЬт
дкЕБЧАЕФДѓЪ§ОнММЪѕЛЗОГЯТЃЌЮвУЧЭЈЙ§НЋЪ§ОнВ№ЗжГЩЖрИіЗжЧјВЂЖРСЂДІРэРДЛёЕУВЂааадЁЃ Р§ШчЃЌHadoop
ЭЈЙ§ HDFS КЭ map-reduce ЪЕЯжСЫХњДІРэВЂааЛЏЁЃ ЖдгкСїЪНЙЄзїИКдиЃЌЮвУЧНёЬьвЊЪЙгУЖрЯћЯЂЖгСаЛђ
Kafka ЗжЧјРДЪЕЯжВЂааЛЏЁЃ етСНИібЁЯюЖМгаЭЌбљЕФЮЪЬтЃКЗжЧјЛњжЦЛсЭЌЪБгАЯьЖСПЭЛЇЖЫКЭаДПЭЛЇЖЫЁЃ УцЖдГжајЪ§ОнДІРэЕФЖС/аДЃЌЮвУЧЕФРЉеЙвЊЧѓЭљЭљЛсгаВЛЭЌЃЌЖјвЛИіЭЌЪБгАЯьЖСаДЕФЗжЧјЛњжЦЛсдіМгЯЕЭГЕФИДдгадЁЃ
ДЫЭтЃЌЫфШЛФуПЩвдЭЈЙ§ЬэМгЖгСаЛђЗжЧјРДНјааРЉеЙЃЌЕЋеташвЊЗжБ№ЖдЖСЁЂаДПЭЛЇЖЫКЭДцДЂНјааЪжЖЏЕїећЃЌШЛКѓашвЊЪжЖЏаЕїЕїећКѓЕФВЮЪ§ЁЃ
етбљЕФВйзїКмИДдгЃЌЖјЧвВЛЪЧЖЏЬЌЕФЃЌВЂашвЊШЫЙЄНщШыЁЃ
ЖјЪЙгУ Pravega ЕФЛАЃЌЮвУЧПЩвдЧсЫЩЕиЁЂЕЏадВЂЧвЖРСЂЕиРЉеЙЪ§ОнЕФЩуШыЁЂДцДЂКЭДІРэЃЌМДаЕїЪ§ОнЙмЕРжаУПИізщМўЕФРЉеЙЁЃ
Pravega Stream ЕФЖЏЬЌЩьЫѕЪЕЯж
Pravega ЖдЖЏЬЌЩьЫѕЕФжЇГждДздгкАб Stream БЛЛЎЗжГЩ Segment ЕФЯыЗЈЁЃ дкжЎЧАЕФЮФеТжагаНщЩмЙ§ЃЌвЛИі
Stream ПЩвдОпгавЛИіЛђЖрИі SegmentЁЃЮвУЧПЩвдАбвЛИі Segment РрБШГЩвЛИіЗжЧјЃЌаДШы
Stream ЕФШЮКЮЪ§ОнЖМЛсИљОнжИЖЈТЗгЩМќЃЌЭЈЙ§ЙўЯЃМЦЫуТЗгЩжСФГвЛИі SegmentЁЃ ЪЕМЪгІгУГЁОАЯТЃЌЮвУЧНЈвщгІгУПЊЗЂепЛљгквЛаЉгагІгУвтвхЕФзжЖЮЃЌБШШч
customer-idЃЌtimestampЃЌmachine-id ЕШРДЩњГЩТЗгЩМќЃЌетбљОЭПЩвдШЗБЃНЋЭЌРрЕФгІгУЪ§ОнТЗгЩжСЭЌвЛИі
SegmentЁЃ
Segment ЪЧ Stream жазюЛљБОЕФВЂааЕЅдЊЁЃ
ВЂаааДЃКвЛИіОпгаИќЖрИі Segment ЕФ Stream ПЩвджЇГжИќДѓЕФаДШыВЂааЖШЃЌЖрИіаДПЭЛЇЖЫПЩвдВЂааЕиЖдЖрИі
Segment НјаааДШыЃЌЖјетаЉ Segment ПЩФмдкЮяРэЩЯЗжВМгкМЏШКжаЕФЖрЬЈЗўЮёЦїЩЯЁЃ
ВЂааЖСЃКЖдгкЖСПЭЛЇЖЫРДЫЕЃЌSegment ЕФЪ§СПвтЮЖзХзюДѓЕФЖСВЂааЖШЁЃвЛИіОпга N ИіЖСПЭЛЇЖЫЕФЖСепзщПЩвдвдзюДѓЮЊ
N ЕФВЂааЖШРДЯћЗбЭЌвЛИі StreamЁЃетбљЃЌЕБвЛИі Stream жаЕФ Segment Ъ§СПБЛЖЏЬЌдіМгЪБЃЌЮвУЧПЩвдЯргІЕидіМгЭЌЕШЪ§СПЕФЖСПЭЛЇЖЫЃЈЭЌвЛЖСепзщЃЉРДдіМгВЂааЖШЃЛЗДжЎврШЛЃЌЕБ
Segment Ъ§СПЖЏЬЌМѕЩйЪБЃЌЮвУЧвВПЩвдМѕЩйЯргІЕФЖСПЭЛЇЖЫРДНкЪЁзЪдДЁЃ
Stream ПЩвдБЛХфжУЮЊЫцзХИќЖрЪ§ОнаДШыЖјдіМг Segment ЕФЪ§СПЃЌВЂдкЪ§ОнСПЯТНЕЪБЫѕаЁ Segment
Ъ§ЁЃ ЮвУЧНЋетжжХфжУГЦЮЊ Stream ЕФЗўЮёМЖФПБъЃЈService Level ObjectiveЃЌSLOЃЉЁЃPravega
МрПиЪфШыЕН Stream ЕФЪ§ОнЫйТЪЃЌВЂИљОн SLO дк Stream жаЖЏЬЌдіМгЛђвЦГ§ SegmentЁЃ
ЕБашвЊдіМг Segment ЪБЃЌPravega ЛсЭЈЙ§В№Зж Segment РДЩњГЩИќЖрЕФ SegmentЃЛЖјЕБашвЊМѕЩй
Segment Ъ§СПЪБЃЌPravega ЭЈЙ§КЯВЂ Segment РДМѕЩй Segment Ъ§СПЁЃ
ЪЕМЪгІгУжаЃЌгІгУГЬађЛЙПЩвдЖдНг Pravega ЬсЙЉЕФдЊЪ§ОнЃЌИљОн Stream ЕФЩьЫѕадРДзіЯргІЕФЩьЫѕЁЃОйР§РДНВЃЌFlink
ПЩвдИљОндЊЪ§ОнжаЕФ Segment Ъ§СПРДЕїећ Flink зївЕЕФВЂааЖШЃЌЛђепПЩвдвРРЕШнЦїЦНЬЈЃЈШч
Cloud FoundryЃЌMesos/MarathonЃЌKubernetes Лђеп Docker
StackЃЉЬсЙЉЕФЖЏЬЌРЉЫѕШнЛњжЦРДЖЏЬЌЕїећШнЦїЪЕР§ЕФЪ§СПЃЌвдДЫРДгІЖдЪ§ОнСїСПЕФБфЛЏЁЃ
ЩюШыЦЪЮі
Pravega ИљОнвЛжТадЩЂСаЫуЗЈНЋТЗгЩМќЩЂСажСЁАМќПеМфЁБЃЌИУМќПеМфБЛЛЎЗжЮЊЖрИіЗжЧјЃЌЗжЧјЪ§СПКЭ Segment
Ъ§СПЯрвЛжТЃЌЭЌЪББЃжЄУПвЛИі Segment БЃДцзХвЛзщТЗгЩМќТфШыЭЌвЛЧјМфЕФЪТМўЁЃ
ИљОнТЗгЩМќЃЌЮвУЧНЋвЛИі Stream В№ЗжГЩСЫШєИЩИі SegmentЃЌУПвЛИі Segment БЃДцзХвЛзщТЗгЩМќТфШыЭЌвЛЧјМфЕФЪТМўЃЌВЂЧвгЕгазХЯрЭЌЕФ
SLOЁЃ
ЭЌЪБЃЌSegment ПЩвдБЛЗтБеЃЈsealЃЉЃЌвЛИіБЛЗтБеЕФ Segment НЋНћжЙаДШыЁЃетвЛИХФюдкЖЏЬЌЩьЫѕжаНЋЗЂЛгживЊзїгУЁЃ
ЪЕР§ЫЕУїЩьЫѕЙ§ГЬ
МйЩшФГжЦдьЦѓвЕга 400 ИіДЋИаЦїЃЌЗжБ№БрКХЮЊ 0~399ЃЌЮвУЧНЋБрКХзіЮЊ routing keyЃЌВЂНЋЦфЩЂСаЗжВМЕН(0,
1)ЕФМќПеМфжаЃЈPravega вВжЇГжНЋЗЧЪ§жЕаЭЕФТЗгЩМќЩЂСаЕНМќПеМфжаЃЉЁЃЫцзХВПЗжДЋИаЦїДЋЪфЦЕТЪЕФБфЛЏЃЌЮвУЧРДЙлВьЦф
Segment ЕФБфЛЏЁЃ
ШчЭМ 1 ЫљЪОЃЌдк 0~1 ЧјМфЕФМќПеМфжаЃЌSegment ЕФКЯВЂКЭВ№ЗжЕМжТСЫТЗгЩМќЫцзХЪБМфЕФЭЦвЦЖјБЛТЗгЩжСВЛЭЌЕФ
SegmentЁЃ
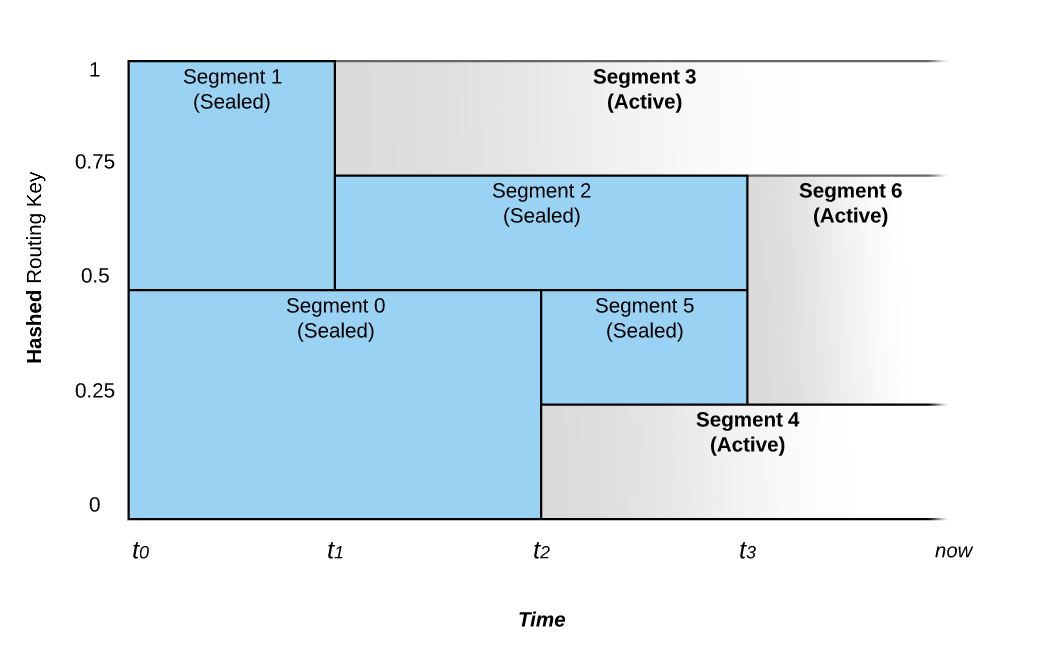
ЭМ 1: Segment ЕФКЯВЂКЭВ№ЗжЖдЪТМўТЗгЩЕФгАЯь
ЩЯЭМЫљЪОЕФ Stream ДгЪБМф t0 ПЊЪМЃЌЫќБЛХфжУГЩОпгаЖЏЬЌЩьЫѕЙІФмЁЃ ШчЙћаДШыСїЕФЪ§ОнЫйТЪВЛБфЃЌдђЖЮЕФЪ§СПВЛЛсИФБфЁЃ
дкЪБМфЕу t1ЃЌPravega МрПиЦїзЂвтЕНЪ§ОнЫйТЪЕФдіМгЃЌВЂЧвбЁдёНЋ Segment 1 В№ЗжГЩ
Segment 2 КЭ Segment 3 СНВПЗжЃЌетИіЙ§ГЬЮвУЧГЦжЎЮЊ Scale-up ЪТМўЁЃдк
t1 жЎЧАЃЌТЗгЩМќЩЂСаЕНМќПеМфЩЯАыВПЕФЃЈжЕЮЊ 200~399ЃЉЕФЪТМўНЋБЛЗХжУдк Segment 1
жаЃЌЖјТЗгЩМќЩЂСаЕНМќПеМфЯТАыВПЕФЃЈжЕЮЊ 0~199ЃЉЕФЪТМўдђБЛЗХжУдк Segment 0 жаЁЃдк t1
жЎКѓЃЌSegment 1 БЛВ№ЗжГЩ Segment 2 КЭ Segment 3ЃЛSegment 1
дђБЛЗтБеЃЌМДВЛдйНгЪмаДШыЁЃ ДЫЪБЃЌОпгаТЗгЩМќ 300 МАвдЩЯЕФЪТМўБЛаДШы Segment 3ЃЌЖјТЗгЩМќдк
200 КЭ 299 жЎМфЕФЪТМўНЋБЛаДШы Segment 2ЁЃSegment 0 дђШдШЛБЃГжНгЪмгы t1
жЎЧАЯрЭЌЗЖЮЇЕФЪТМўЁЃ
дк t2 ЪБМфЕуЃЌЮвУЧПДЕНСэвЛИі Scale-up ЪТМўЁЃетДЮЪТМўНЋ Segment 0 В№ЗжГЩ
Segment 4 КЭ Segment 5ЁЃSegment 0 вђДЫБЛЗтБеЖјВЛдйНгЪмаДШыЁЃ
ОпгаЯрСкТЗгЩМќЩЂСаПеМфЕФ Segment вВПЩвдБЛКЯВЂЃЌБШШчдк t3 ЪБМфЕуЃЌSegment 2
КЭ Segment 5 БЛКЯВЂГЩЮЊ Segment 6ЃЌSegment 2 КЭ Segment 5
ЖМЛсБЛЗтБеЃЌЖј t3 жЎКѓЃЌжЎЧАаДШы Segment 2 КЭ Segment 5 ЕФЪТМўЃЌвВОЭЪЧТЗгЩМќдк
100 КЭ 299 жЎМфЕФЪТМўНЋБЛаДШыаТЕФ Segment 6 жаЁЃКЯВЂЪТМўЕФЗЂЩњБэУї Stream
ЩЯЕФИКдие§дкМѕЩйЁЃ
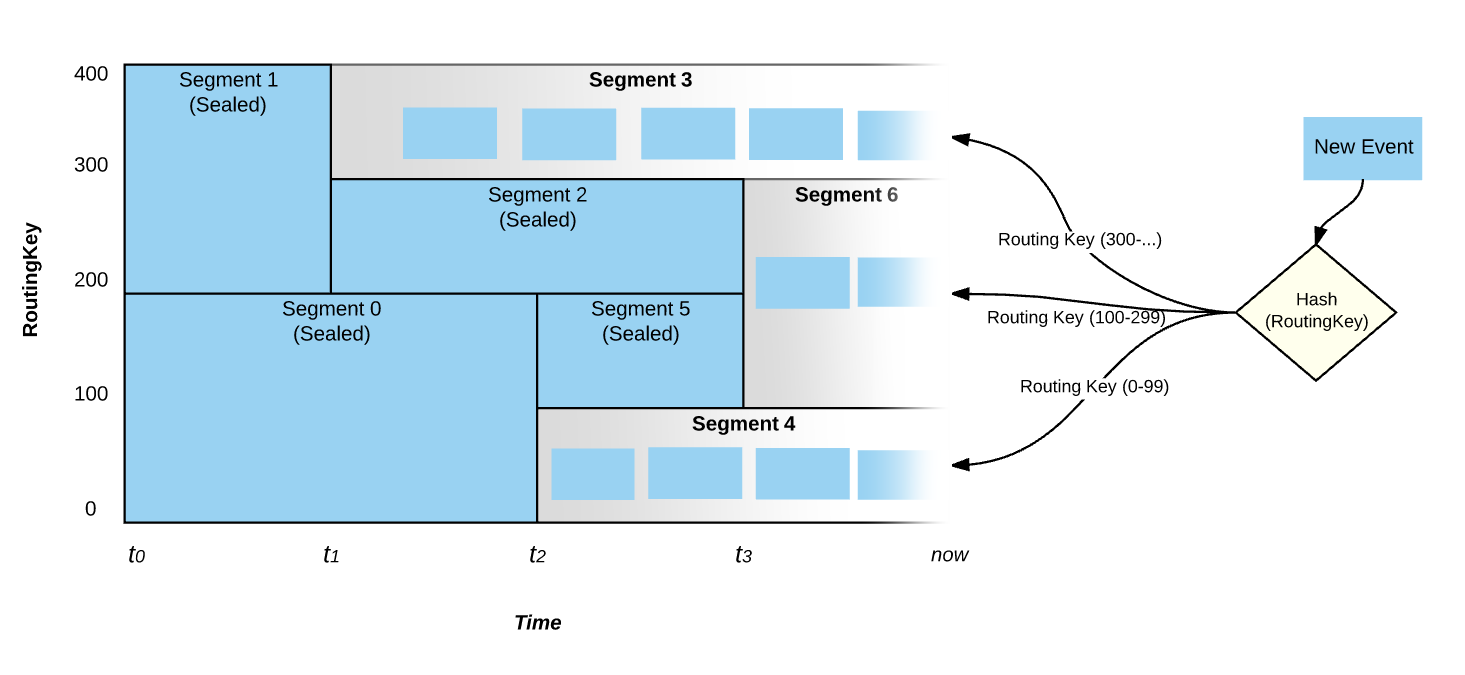
ЭМ 2: ЪТМўЕФТЗгЩ
ШчЭМ 2ЃЌдкЁАЯждкЁБетИіЪБПЬЃЌжЛга Segment 3ЃЌ6 КЭ 4 ДІгкЛюЖЏзДЬЌЃЌВЂЧвЫљгаЛюдОЕФ
Segment НЋЛсИВИЧећИіМќПеМфЁЃдкЩЯЪіЕФЙцдђ 2 КЭ 3 жаЃЌМДЪЙЪфШыИКдиДяЕНСЫЖЈвхЕФуажЕЃЌPravega
вВВЛЛсСЂМДДЅЗЂ scale-up/down ЕФЪТМўЃЌЖјЪЧашвЊИКдидквЛЖЮзуЙЛГЄЕФЪБМфФкГЌдНВпТдуажЕЃЌетвВБмУтСЫЙ§гкЦЕЗБЕФЩьЫѕВпТдгАЯьЖСаДадФмЁЃ
ХфжУЩьЫѕЙцдђ
ЮвУЧдкДДНЈ Stream ЪБЃЌЛсЪЙгУЩьЫѕЙцдђРДХфжУ StreamЃЌИУЙцдђЖЈвхСЫ Stream ШчКЮЯьгІЦфИКдиБфЛЏЁЃ
ФПЧА Stream жЇГжШ§жжХфжУЙцдђЃК
ЙЬЖЈЙцдђЃЌМДЮоЖЏЬЌЩьЫѕЁЃ дкДЫЙцдђЯТЃЌSegment ЕФЪ§СПВЛЫцИКдиЖјБфЛЏЁЃЦфХфжУНгПкШчЯТЃК
| static ScalingPolicy
fixed(int numSegments) |
ЦфжаnumSegmentжИ stream жаЙЬЖЈЕФ segment Ъ§СП
ЛљгкДѓаЁЕФЩьЫѕЙцдђЁЃдкДЫЙцдђЯТЃЌЕБаДШы Stream ЕФУПУызжНкЪ§ГЌЙ§ФГИіФПБъЫйТЪЪБЃЌSegment
ЕФЪ§СПНЋдіМгЃЌВПЗж Segment НЋБЛВ№ЗжЃЛШчЙћЫќЕЭгкФГИіГЬЖШЃЌдђ Segment Ъ§СПНЋМѕЩйЃЌВПЗж
Segment НЋБЛКЯВЂЁЃЦфХфжУНгПкШчЯТЃК
| static ScalingPolicy
byEventRate (int targetRate, int scaleFactor,
int minNumSegments)
|
ЦфжаtargetRateжИУПИі segment ЫљФмГаЪмЕФзюДѓИКдиЃЈУПУыЕФ event Ъ§СПЃЉЃЌscaleFactorЪЧжИУПвЛДЮ
scale-up ЪТМўжаЕФЗжСбЯЕЪ§ЃЌМД segment вЛЗжЮЊМИЃЌШчЩЯР§гІЩшЮЊ 2ЃЌminNumSegmentsжИ
stream жаЫљгаЕФ segment Ъ§СПЕФзюаЁжЕЃЌгУвдЗРжЙЙ§ЖШ scale-downЁЃ
ЛљгкЪТМўЪ§ЕФЩьЫѕЙцдђЁЃДЫЙцдђгыЙцдђ 2.ЯрЫЦЃЌВЛЭЌЕудкЫќЪЧгУЪТМўЪ§ЖјВЛЪЧзжНкЪ§РДзїЮЊЩьЫѕЕФХаЖЈвРОнЁЃЦфХфжУНгПкШчЯТЃК
static ScalingPolicy
byDataRate (int targetKBps, int scaleFactor, int
minNumSegments)
|
ЦфжаtargetKBpsжИУПИі segment ЫљФмГаЪмЕФзюДѓИКдиЃЈУПУыЪ§ОнСПДѓаЁЃЌвд KB МЦЪ§ЃЉЃЌЦфЫћЭЌЩЯЁЃ
ЪЙгУЪБЃЌдкДДНЈ Stream ЪБЃЌНЋЖдгІЕФScalingPolicyЖдЯѓДЋЕнИј Stream ЕФХфжУЖдЯѓStreamConfigМДПЩЁЃ
StreamManager
streamManager = StreamManager.create( controllerURI);
StreamConfiguration streamConfig = StreamConfiguration.builder()
.scalingPolicy (ScalingPolicy.byEventRate(100,
2, 1))
.build();
streamManager.createStream (scope, streamName,
streamConfig);
|
ЖСаДПЭЛЇЖЫЕФЕЏадЖРСЂЩьЫѕ
Pravega ДгЩшМЦГѕЪМОЭжМдкНтОіСїЪНЪ§ОнЕФЖСаДПЭЛЇЖЫЖРСЂРЉеЙЮЪЬтЃЌвдЧѓДяЕНЖСаДРЉеЙОпгаЕЏадЃЌЛЅВЛгАЯьЁЃЮвУЧРДПДвЛЯТвдЯТСНжжГЁОАЃК
ГЁОА 1ЃКаДЫйТЪ<ДІРэЫйТЪ
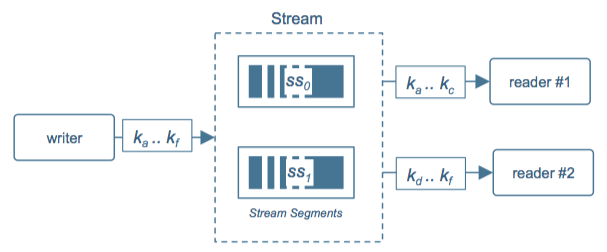
ЭМ 3: аДЫйТЪ < ДІРэЫйТЪ
дкЭМ 3 жаЃЌДІРэЫйЖШДѓгкаДШыЫйЖШЃЌЫљвдЫфШЛжЛгавЛИіаДПЭЛЇЖЫЃЌЮвУЧШдШЛПЩвдНЋ Stream В№ЗжГЩЖрИі
SegmentЃЌгЩЖСПЭЛЇЖЫ reader#1 РДЖСТЗгЩМќЧјМфЮЊ ka Ё kc ЕФЪТМўЃЌЖјПЭЛЇЖЫ reader#2
ЖСТЗгЩМќЧјМфЮЊ kd Ё kf ЕФЪТМўЁЃдкЭЌвЛЖСепзщЃЈReader GroupЃЉФкЕФЖСПЭЛЇЖЫЛсИљОнздЩэЖСПЭЛЇЖЫЪ§СПЃЌздЖЏвдИКдиОљКтЕФЗНЪНЖдгІЕНСуЕНЖрИіВЛЭЌЕФ
segment ЪЕЯжВЂааЕФЖСЁЃЖј Pravega ЕФЕЏадЩьЫѕЛњжЦвВдЪаэЖСепзщИњзй segment ЕФЫѕЗХВЂВЩШЁЪЪЕБЕФДыЪЉЃЌР§ШчЃКдкдЫааЪБЬэМгЛђЩОГ§ЖСПЭЛЇЖЫЪЕР§ЃЌЪЙећИіЯЕЭГФмЙЛвдаЕїЕФЗНЪНЖЏЬЌРЉеЙЁЃPravega
ЭХЖгвбОКЭ Flink ЩчЧјКЯзїЃЌЭЈЙ§МрЬ§ segment Ъ§СПИФБф Flink ЖСШЁКЭДІРэ Pravega
Ъ§ОнЕФВЂааЖШЃЌЪЕЯжСЫ Flink Pravega Source ЕФЖЏЬЌЩьЫѕЁЃ
ГЁОА 2ЃК аДЫйТЪ > ДІРэЫйТЪ
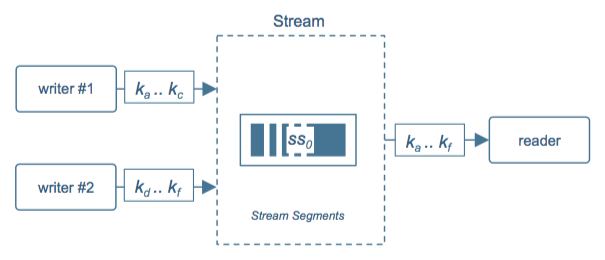
ЭМ 4: аДЫйТЪ > ДІРэЫйТЪ
дкЭМ 4 жаЃЌДІРэЫйЖШаЁгкаДШыЫйЖШЃЌЫљвдЮвУЧПЩвддкаДПЭЛЇЖЫНјааВЂааЛЏЃЈгЩгІгУЭъГЩЃЉЃЌЕЋжЛашЗжХфвЛИіЖСПЭЛЇЖЫРДЖСЁЃгЩгкгаСЫ
stream КЭ segment ЕФГщЯѓЃЌЪ§ОнДцДЂЕФеце§ЕФЗжЧјЛсдк stream ФкВПЪЕЯжЃЌжЛвЊТЗгЩМќВЛЗЂЩњИФБфЃЌаДПЭЛЇЖЫЕФВЂааЁЂЪ§ОнСПЕФдіМгВЂВЛЛсгАЯьЪ§ОнЕФе§ГЃЗжЧјЁЃ
ЯжЪЕЧщПіЯТЃЌЮвУЧЭљЭљЛсДІгкЩЯЪіСНжжЧщПіжЎМфЃЌВЂЧвАщЫцзХЪ§ОндДЕФБфЛЏКЭЪБМфЕФЭЦНјЖјЗЂЩњИФБфЁЃЖдаДПЭЛЇЖЫРДЫЕЃЌSegment
ЕФЭиЦЫЪЧЭИУїЕФЃЌЫќУЧжЛашИКд№ТЗгЩМќЕФЗжЧјЁЃЖдЖСПЭЛЇЖЫРДЫЕЃЌжЛашМђЕЅжИЯђ StreamЃЌЖј Segment
ЕФЖЏЬЌБфЛЏЛсздЖЏЗДРЁИјЖСПЭЛЇЖЫЁЃ
жСДЫЃЌЖСПЭЛЇЖЫКЭаДПЭЛЇЖЫПЩвдЗжБ№ЖРСЂЕиНјааЕЏадЫѕЗХЃЌЖјВЛЪмБЫДЫгАЯьЁЃ
ецЪЕЪ§ОнгУР§
ЮвУЧЪЙгУгЩУРЙњХІдМЪаеўИЎЪкШЈПЊдДЕФГізтГЕЪ§Он
ЃЌАќРЈЩЯЯТГЕЪБМфЃЌЕиЕуЃЌааГЬОрРыЃЌж№ЯюЦБМлЃЌИЖПюРраЭЁЂГЫПЭЪ§СПЕШзжЖЮЁЃЮвУЧАбРњЪЗЪ§ОнМЏФЃФтГЩСЫСїЪНЪ§ОнЪЕЪБЕиаДШы
PravegaЁЃЫљШЁЕФЪ§ОнМЏКИЧЕФЪЧ 2015 Фъ 3 дТЕФЛЦЩЋГізтГЕЕФааГЬЪ§ОнЃЌЦфЪ§ОнСПЮЊ 1.9GBЃЌАќРЈНќЧЇЭђЬѕМЧТМЃЌУПЬѕМЧТМ
17 ИізжЖЮЁЃЮвУЧбЁШЁСЫЦфжа 12 ИіаЁЪБЕФЪ§ОнЃЌаЮГЩШчЭМ 4 ЫљЪОЪ§ОнЭГМЦЃК
ЛЦЩЋКЭТЬЩЋЕФГізтГЕааГЬМЧТМАќРЈВЖЛёЬсЛѕКЭЯТГЕШеЦк/ЪБМфЃЌНгЫЭКЭЯТГЕЕиЕуЃЌааГЬОрРыЃЌж№ЯюЦБМлЃЌЗбТЪРраЭЃЌИЖПюРраЭКЭЫОЛњБЈИцЕФГЫПЭЪ§СПЕФзжЖЮЁЃЮвУЧАбРњЪЗЪ§ОнМЏФЃФтГЩСЫСїЪНЪ§ОнЪЕЪБЕиаДШы
PravegaЁЃЫљШЁЕФЪ§ОнМЏКИЧЕФЪЧ 2015 Фъ 3 дТЕФЛЦЩЋГізтГЕЕФааГЬЪ§ОнЃЌЦфЪ§ОнСПЮЊ 1.9GBЃЌАќРЈНќЧЇЭђЬѕМЧТМЃЌУПЬѕМЧТМ
17 ИізжЖЮЁЃЮвУЧбЁШЁСЫЦфжа 12 ИіаЁЪБЕФЪ§ОнЃЌаЮГЩШчЭМ 5 ЫљЪОЪ§ОнЭГМЦЃК
ЭМ 5: ГізтГЕЪ§ОнСїСПМЧТМ
гЩЩЯЭМЮвУЧПЩвдЙлВьЕНЃЌЪ§ОнСїСПдкдчЩЯ 4 ЕузѓгвДІгкЙШЕуЃЌЖјдкдчГП 9 ЕузѓгвДяЕНЗхжЕЁЃЗхжЕСїСПЕФаДШызжНкЪ§ДѓдМЮЊЙШЕуСїСПЕФ
10 БЖЁЃЮвУЧНЋ Stream ЕФЩьЫѕЙцдђХфжУЮЊЩЯЪіЙцдђ 2ЃЈЛљгкДѓаЁЕФЩьЫѕЙцдђЃЉЁЃ
ЯрЖдгІЕиЃЌStream ЕФ Segment ШШЕуЭМШчЭМ 6 ЫљЪОЖЏЬЌБфЛЏЃК
ЭМ 6: Segment ШШЕуЭМ
ДгЩЯЭМПЩвдПДГіЃЌДгЭэ 11 ЕужССшГП 2 ЕуЃЌSegment ж№НЅКЯВЂЃЛДгдчГП 6 ЕужС 10 ЕуЃЌSegment
ж№ВНВ№ЗжЁЃДгВ№ЗжДЮЪ§РДПДЃЌДѓВПЗж Segment змЙВВ№Зж 3 ДЮЃЌаЁВПЗжВ№Зж 4 ДЮЃЌетвВгЁжЄСЫСїСПЗхжЕ
10 БЖгкЙШЕзЕФЭГМЦжЕЃЈ3 < lg10 < 4ЃЉЁЃ
ЮвУЧЪЙгУГізтГЕааГЬжаЕФГіЗЂЕузјБъЮЛжУРДзїЮЊТЗгЩМќЁЃЕБИпЗхРДСйЪБЃЌЗБУІЕиЖЮВњЩњЕФДѓСПЪТМўЛсЕМжТ Segment
БЛВ№ЗжЃЌДгЖјЛсгаИќЖрЕФЖСПЭЛЇЖЫРДНјааДІРэЃЛЕБЙШЗхРДСйЪБЃЌЗЧЗБУІЕиЖЮВњЩњЕФЪТМўЫљдкЕФ Segment
ЛсНјааКЯВЂЃЌВПЗжЕФЖСПЭЛЇЖЫЛсЯТЯпЃЌЪЃЯТЕФЖСПЭЛЇЖЫЛсДІРэИќЖрЕиРэЧјПщЩЯВњЩњЕФЪТМўЁЃ
змНс
Pravega ЕФЖЏЬЌЩьЫѕЛњжЦПЩвдШУгІгУПЊЗЂКЭдЫЮЌШЫдБВЛБиЙиаФвђСїСПБфЛЏЖјЕМжТЕФЗжЧјБфЛЏашвЊЃЌЮоашЪжЖЏЕїЖШМЏШКЁЃЗжЧјЕФСїСПМрПиКЭЯргІБфЛЏгЩ
Pravega РДНјааЃЌДгЖјЪЙСїСПБфЛЏФмЙЛЪЕЪБЖјЧвЦНЛЌЕиЬхЯжЕНгІгУГЬађЕФЩьЫѕЩЯЁЃ
ЖРСЂЩьЫѕЛњжЦЪЙЕУЩњВњепКЭЯћЗбепПЩвдИїздЖРСЂЕиНјааЩьЫѕЃЌЖјВЛгАЯьБЫДЫЁЃећИіЪ§ОнДІРэЙмЕРвђДЫБфЕУИЛгаЕЏадЃЌПЩвдгІЖдЪЕЪБЪ§ОнЕФВЛЖЯБфЛЏЃЌНсКЯЪЕМЪДІРэФмСІЖјзіГізюЮЊЪЪЪБЕФЗДгІЁЃ
|








