| БрМЭЦМі: |
етЦЊЮФеТНЋНтЪЭЖЮЪєадЕФдЫзїЛњжЦвдМАЫќЪЧШчКЮЬсЙЉвЛИіИпаЇЕФМќжЕДцДЂЃЌГЩЮЊЦфЫќЩЯВуИпМЖЬиадЕФЛљЪЏжЎвЛЕФЁЃ
БОЮФРДздгкinfoQЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1 БГОАгыМђНщ
ФмЙЛНЋЪТМўЃЈEventЃЉАДСїЫЎЯпЕФЗНЪНзЂШыЖЮДцДЂЃЈSegment StoreЃЉЪЧ Pravega ПЭЛЇЖЫЪЕЯжИпЭЬЭТСПЕФЙиМќММЪѕжЎвЛЃЌМДБуЪЧДІРэаЁГпДчЕФаДВйзївВЪЧШчДЫЁЃWriter
дкНгЪеЕНЪТжЎКѓСЂМДНЋЦфзЗМгЕНЯргІЕФЖЮЃЈSegmentЃЉжаЃЌВЂВЛЛсЕШД§жЎЧАЕФаДВйзїЕУЕНШЗШЯЁЃ ЮЊБЃжЄЫГађКЭНівЛДЮЃЈExactly-OnceЃЉгявхЃЌЖЮДцДЂвЊЧѓЫљгаетаЉзЗМгВйзїЖМгаЬѕМўЕиЛљгкФГИівбжЊзДЬЌЃЌЖјИУзДЬЌЖдгкУПвЛИі
Writer ЖМЪЧЮЈвЛЕФЁЃетвЛзДЬЌДцДЂдкУПИіЖЮЕФЖЮЪєадЃЈSegment AttributeЃЉжа ЃЌВЂЧвдкУПИіЖЮВйзїжаПЩвдБЛдзгадЕиВщбЏЛђепИќаТЁЃ
ЫцзХЪБМфЕФЭЦвЦЃЌЖЮЪєадвбОж№НЅбнЛЏВЂжЇГжвЛЯЕСаВЛЭЌЕФгУР§ЃЌДгМЧТМФГИіЖЮЃЈПЊЦє Auto-Scaling
ЬиадЃЉФкЕФЪТМўЪ§СПЕНДцДЂЙўЯЃБэЕФЫїв§ЁЃБэЖЮЃЈTable SegmentЃЌвЛжжгУгкБЃДц Pravega
ЫљгаСїЁЂЪТЮёКЭЖЮЕФдЊаХЯЂЕФМќжЕДцДЂЃЉЕФв§ШыдђвЊЧѓУПИіЖЮОпгаЮоЗьЙмРэГЩЧЇЩЯЭђЬѕЪєадЕФФмСІЁЃ
етЦЊЮФеТНЋНтЪЭЖЮЪєадЕФдЫзїЛњжЦвдМАЫќЪЧШчКЮЬсЙЉвЛИіИпаЇЕФМќжЕДцДЂЃЌГЩЮЊЦфЫќЩЯВуИпМЖЬиадЕФЛљЪЏжЎвЛЕФЁЃЮвУЧЯШДгвЛИіИХРРПЊЪМЃЌПДПД
Pravega Writer ЪЧШчКЮЪЙгУЖЮЪєадРДБмУтЪ§ОнжиИДКЭЖЊЪЇЕФЁЃНгзХЃЌЮвУЧЛсЯъЯИУшЪіЖЮЪєадЪЧШчКЮдкЖўМЖДцДЂЩЯБЛзщжЏГЩ
B+ЪїЃЌВЂЪЙгУвЛжжДДаТЕФбЙЫѕЗНЗЈРДМѕЩйаДЗХДѓаЇгІЕФЁЃ
2 РћгУЖЮЪєадРДБмУтЪ§ОнжиИДЛђЖЊЪЇ
EventStreamWriter дкаДШыИќЖрЪ§ОнжЎЧАЃЌБиаыЪзЯШжЊЕРЫќдкЗўЮёЦїЖЫвбОаДШыЪ§ОнЕФзДЬЌЃЌМДБуЪЧдкФГаЉГЃМћЕФЪЇАмГЁОАЯТвВЪЧШчДЫЁЃЫќашвЊЬсЙЉФГаЉЪ§жЕЃЌЖјЗўЮёЦїЖЫУПДЮдкГЂЪдНјаааоИФВйзїЪБЖМПЩвддзгадЕиМьВщКЭИќаТетаЉЪ§жЕЁЃ
дкгыЗўЮёЦїНЛЛЅЕФЙ§ГЬжаЃЌДѓЖрЪ§ЙЪеЯБэЯжГіРДЕФаЮЪНЖМЪЧЪТМўУЛгаЕУЕНШЗШЯЛиИДЃЌЖјдкетжжЧщПіЯТЃЌЯрЙиЕФ
EventStreamWriter ЛсЪЙгУгыжЎЧАЯрЭЌЕФЬѕМўжиЪдаДВйзїЁЃ
ШчЙћдкжЎЧАЕФГЂЪджаЪТМўвбОБЛГжОУЛЏСЫЃЌФЧУДЖЮДцДЂЛсЪЙгУ ConditionalAppendFailedException
вьГЃОмОјБОДЮжиЪдЃЌЖј EventStreamWriter дђЯђЕїгУепШЗШЯБОДЮЪТМўВЂМЬајДІРэЯТвЛХњЪТМўЁЃЯрЗДЃЌШчЙћЪТМўЛЙУЛгаБЛГжОУЛЏЃЌдђЖЮДцДЂЛсСЂПЬНјааГжОУЛЏВЂЯђ
Writer ЗЂЫЭШЗШЯЁЃетжжДэЮѓжиЪдКЭгаЬѕМўЪЇАмЕФзщКЯгажњгкБмУтЪ§ОнЖЊЪЇЃЈЪТМўЮДБЛГжОУЛЏЃЉКЭжиИДЃЈЪТМўБЛГжОУЛЏСЫЃЌЕЋШДУЛгаБЛШЗШЯЃЉЁЃ
УПИі EventStreamWriter ЖМгавЛИіЮЈвЛЕФБъЪЖЗћЃЌWriter IDЃЌВЂЧввРОнЕБЧАе§дкДІРэЕФЪТМўЕФТЗгЩМќЃЈRouting
KeyЃЉЃЌПЩвдЭЌЪБаДШыЖрИіЖЮДцДЂЁЃЫќЕФФкВПзДЬЌгЩвЛИізжЕфНсЙЙзщГЩЃЌЖдУПИіНЛЛЅЕФЖЮМЧТМвЛИіЪТМўБрКХЃЈEvent
NumberЃЉЁЃУПДЮДІРэвЛИіаТЪТМўЪБЃЌИУФкВПзДЬЌЖМЛсЗЂЩњИФБфЁЃУПвЛИіЪТМўЖМБЛзїЮЊвЛИіЬѕМўзЗМгЃЈConditional
AppendЃЌвдЕБЧАЕФЪТМўБрКХКЭ Writer ID ЮЊЬѕМўЃЌЦкЭћдкЖдгІЕФЖЮЩЯЕУЕНЦЅХфЃЉВйзїЗЂЭљЖЮДцДЂЁЃЖЮДцДЂЩЯЕФзЂШыСїЫЎЯпАДзЗМгВйзїЕФНгЪеЫГађвРДЮДІРэЫљгаЕФзЗМгЃЌВЂЧвУПвЛИіЬѕМўзЗМгВйзїЖМЛсБЛдзгадЕиМьВщЃЌЬсНЛКЭИќаТЃЌвђДЫБЃжЄСЫЪ§ОнДцДЂЕФвЛжТадЁЃ
ЖЮДцДЂвдЖЮЪєадЕФаЮЪНЮЌЛЄетвЛзДЬЌЁЃЭМ 1 гУвЛИіЪОР§еЙЪОСЫетвЛдЫзїЛњжЦЁЃ
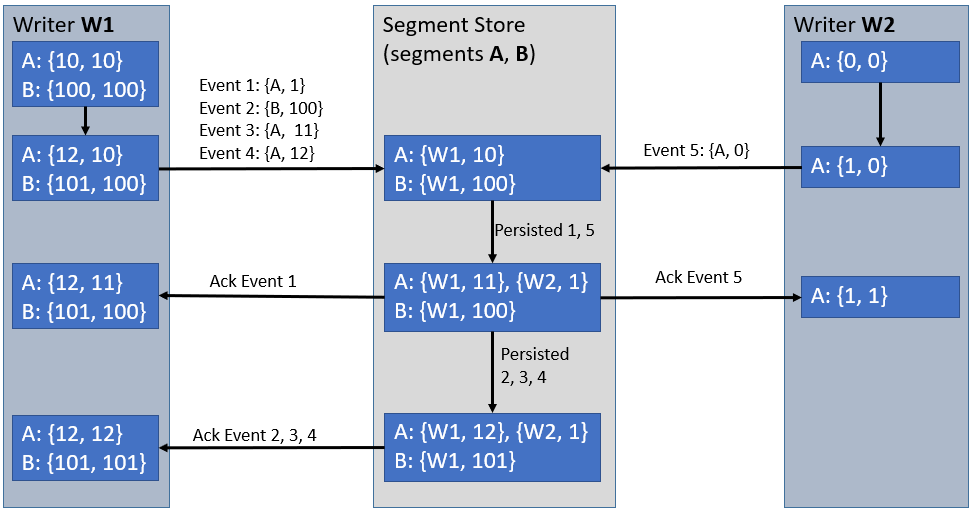
ЭМ 1 Writer W1 КЭ W2 ЯђЖЮ A КЭЖЮ B зЗМгЪТМўЁЃУПИі Writer ЖдУПвЛИіаДШыЕФЖЮЖМгавЛеХгГЩфБэЃЌШчЯТЃК{ЖЮЃЌзюКѓЗЂЫЭЕФЪТМўБрКХЃЌзюКѓШЗШЯЕФЪТМўБрКХ}ЁЃЖЮДцДЂЖдУПвЛИіЫќЙмРэЕФЖЮЖМгавЛИіДг
Writer ID ЕНЪТМўБрКХЕФгГЩфЃЌИУгГЩфдкУПДЮзЗМгВйзїжаЖМЛсБЛдзгадЕиМьВщВЂИќаТЁЃWriter
УПДЮЯђЖЮДцДЂЗЂЫЭЪТМўЪБИќаТЯргІЕФзюКѓЗЂЫЭЪТМўЕФБрКХЃЌВЂдкУПДЮЪеЕНШЗШЯЛиИДЪБИќаТЯргІЕФзюКѓШЗШЯЪТМўЕФБрКХЁЃ
3 ЖЮЪєад
УПИіЖЮЖМгавЛзщЪєадМЏКЯЃЌПЩвдБЛЖРСЂЪЙгУЛђепгыВЛЭЌЕФЖЮВйзїзщКЯЪЙгУЁЃР§ШчЃЌЮвУЧПЩвдбЁдёНіИќаТФГаЉЖЮЪєадЃЌвВПЩвдбЁдёдзгадЕиЯђФГИіЖЮзЗМгВЂИќаТвЛаЉЪєадЁЃWriter
ID ЪЧвЛИі 128 ЮЛЕФ UUIDЃЌЖјЪТМўБрКХЪЧвЛИі 64 ЮЛЕФГЄећаЭЪ§жЕЃЌвђДЫЮвУЧНЋЖЮЪєадЩшМЦЮЊжЇГж
16 зжНкМќЃЌ8 зжНкжЕЕФМќжЕЖдЁЃ
ФПЧАгаСНжжРраЭЕФЪєадЃККЫаФЪєадЃЈCore AttributeЃЉЃЌЫќЕФ ID ЪЧгВБрТыЕФЃЌгУгкБЃДцЖЮЕФФкВПзДЬЌЃЈР§ШчЪТМўзмЪ§ЃЌРЉеЙВпТдЕШЃЉЃЛРЉеЙЪєадЃЈExtended
AttributeЃЉЃЌЫќЪЧДгЭтВПжИЖЈЕФЃЌВЂЮоШЮКЮФкВПКЌвхЁЃСНжжРраЭЕФЖЮЪєадОпгаЯрЭЌЕФгявхЃЌЮЈвЛЕФЧјБ№ЪЧКЫаФЪєадЪЧгРОУФкДцАѓЖЈЕФЃЌЖјРЉеЙЪєадПЩвдБЛЛЛГіЁЃWriter
ID ОЭЪЧЪЙгУЖЮЪєадгГЩфЕНЪТМўБрКХЕФЁЃ
ЖЮЪєадПЩвдЪЙгУШчЯТЖЏДЪдгяНјааИќаТЃК
ЬцЛЛЃКФГИіЪєаджЕБЛЩшжУЮЊЛђИќаТЮЊвЛИіаТжЕЁЃ
ШчЙћДѓгкдђЬцЛЛЃЈReplace-If-GreaterЃЉЃКФГИіЪєаджЕБЛИќаТЮЊвЛИіаТжЕ vЃЌНіЕБДцдквЛИіЕБЧАжЕ
vЁЏВЂЧв v>vЁЏЁЃ
ШчЙћЕШгкдђЬцЛЛЃЈReplace-If-EqualЃЉЃКФГИіЪєаджЕБЛИќаТЮЊвЛИіаТжЕ vЃЌНіЕБЕБЧАжЕгы
vЁЏЃЈгЩЕїгУепЬсЙЉЃЉЦЅХфЁЃетЪЧОЕфЕФ CASЃЈCompare-And-SetЃЉВйзїЃЌПЩвдгУРДБЃжЄЪєаджЕдкБОДЮИќаТжЎЧАЮДБЛВЂЗЂЩшжУЁЃ
РлМгЃКФГИіЪєаджЕБЛИќаТЮЊЕБЧАжЕМгЩЯвЛИіЕїгУепЬсЙЉЕФжЕЁЃ
вдЯТЪЧвЛИіДг Pravega ЕФЖЮДцДЂдДТыжаНиШЁЕФЪОР§ЃЌеЙЪОСЫШчКЮЪЙгУЖЮЪєадЃК
private CompletableFuture<Void>
storeAppend(Append append) {
ArrayList<AttributeUpdate> attributes =
new ArrayList<>();
// Atomically check-and-update the Writer Position
while
// performing this append.
attributes.add (new AttributeUpdate(
append.getWriterId(), // Attribute Key.
AttributeUpdateType.ReplaceIfEquals, // Compare-and-set.
append.getEventNumber(), // Value to set.
append.getLastEventNumber())); // Value to compare.
// Atomically increase the number of events
stored with this append.
attributes.add(new AttributeUpdate(
Attributes.EVENT_COUNT, // Core Attribute.
AttributeUpdateType.Accumulate, // Add to existing
value.
append.getEventCount())); // Value to add.
// Perform the append. Pass the append payload
and the attributes,
// which tells the Segment Store to apply them
atomically.
return store.append(append.getSegment(), append.getData(),
attributes);
}
|
дкетЖЮдДТыжаЃЌУПДЮзЗМгВйзїЩцМАЕНСНИіЖЮЪєадЃКНЋ Writer ЕФЪТМўБрКХЬѕМўИќаТжСвЛИіаТжЕЃЌВЂЧвИќаТЖЮжаЫљДцДЂЕФЪТМўзмЪ§ЁЃЖЮДцДЂЕФзЂШыСїЫЎЯпздЖЏдкБОДЮзЗМгВйзїЩцМАЕФЖЮЃЈappend.getSegment()ЃЉЩЯНјааШчЯТВйзїЃК
бщжЄЪТМўБрКХЪєаджЕжЕгы append.getLastEventNumber()ЦЅХфЁЃ
ИќаТЪТМўБрКХЪєаджЕжС append.getEventNumber()ЁЃ
ИќаТ Attributes.EVENT_COUNT жСЯШЧАжЕМгЩЯ append.getEventCount()ЁЃ
НЋ append.getData()зїЮЊвЛЖЮСЌајзжНкађСазЗМгЕНЖЮЮВЖЫЁЃ
4 ДцДЂЖЮЪєад
ЖЮЪєадЪЧУПИіЖЮЩЯЕФЖюЭтдЊаХЯЂЃЌЫќПЩвдБЛПЭЛЇЖЫздгЩЕиЩшжУЛђЖСШЁЁЃШЛЖјЃЌЖЮЪєадУЛгаБЛШЮКЮ API ЖдЭтБЉТЖЁЃШчЙћетЪЧЖЮЪєадЕФЮЈвЛгУЭОЃЌФЧУДжЛвЊАбЫќУЧДцДЂдквЛИігыжїЖЮЯрЙиСЊЕФвЛИіЖРСЂЕФФкВПЖЮЩЯОЭзуЙЛСЫЁЃ
ЕЋЪЧЃЌе§ШчЩЯЮФЬсЕНЕФЃЌЖЮЪєадЭЌЪБвВдкзЂШыСїЫЎЯпЕФФкВПМЦЫужаБЛДѓСПЪЙгУЃЌШчЙћдкУПДЮашвЊЕФЪБКђЖМднЪБЙвЦ№СїЫЎЯпВЂДгДцДЂжаМгдиЪєаджЕЃЌБиШЛЛсдьГЩЯрЕБДѓЕФадФмЫ№ЪЇЁЃЮвУЧашвЊвЛжжЗНЗЈЛКДцШЋВПЛђепВПЗжЪєаддкФГжжФкДцЪ§ОнНсЙЙжаЃЌЪЙЦфПЩвдКмШнвзЕиБЛСїЫЎЯпЗУЮЪКЭИќаТЃЌЕЋЭЌЪББиаыгУвЛжжИпаЇЕФЗНЪНзюжеНЋетаЉИќаТГжОУЛЏЕНЖўМЖДцДЂжаШЅЁЃ
ЮЊНтОіетвЛФбЬтЃЌЮвУЧЩшМЦ СЫвЛжжСНВуЛКДцЗНАИЃЌзюжеНЋЪєаджЕБЃДцЕНЖўМЖДцДЂЕФЪєадЖЮЃЈAttribute
SegmentЃЉЩЯЁЃЕквЛВуЛКДцЪЧвЛИіжБНгЕФ Java ЙўЯЃБэЃЈHashMap НгПкЃЉЃЌгУгкБЃДцзюНќЪЙгУЕФЪєадЁЃетВуЛКДцжБНгНјааМќжЕгГЩфЃЌЪЙЕУВщевКЭИќаТВйзїЗЧГЃИпаЇЁЃЯТВуЛКДцвддЪМИёЪННЋЖўМЖДцДЂЩЯЕФЪєадЖЮВПЗжБЃДцдкФкДцжаЃЌОЁЙметвЊЧѓЗДађСаЛЏвдБуГщШЁаХЯЂЃЌЕЋЖдИУВуЛКДцЕФЗУЮЪвРШЛЯджјПьгкжБНгДгЖўМЖДцДЂМгдиЁЃ
ЯТВуЛКДцКЭЖўМЖДцДЂЩЯЕФЪєадЖЮвЛЭЌЙЙГЩСЫЫљЮНЕФЪєадЫїв§ЃЈAttribute IndexЃЉЃЌЫќНЋЖЮЪєадзщжЏГЩвЛжжЪЪКЯжЛзЗМгЃЈAppend-OnlyЃЉДцДЂНщжЪЕФЪ§ОнНсЙЙЁЃ

ЭМ 2 ЪєадСїЫЎЯпЁЃЪєадБЛБЃДцдкЖўМЖДцДЂЩЯЃЛЭЈЙ§ЪєадЫїв§ЗУЮЪетаЉЪєадЃЌЪєадЫїв§дкФкДцжаЛКДцСЫВПЗжЖўМЖДцДЂЕФЪ§ОнЃЌВЂЭЈЙ§ЖЮШнЦїЃЈSegment
ContainerЃЉЕФзЂШыСїЫЎЯпНјааИќаТЁЃ
ЮвУЧзіГіЕФЙиМќОіВпжЎвЛБуЪЧОЁСПБмУтдкзЂШыСїЫЎЯпФкжБНгДгЖўМЖДцДЂМгдиЪєаджЕЃЌЖјЪЧОЁПЩФмдкДІРэВйзїжЎЧАОЭНјаадЄШЁЁЃЭМ
2 жаЕФВНжш 1.1 ЕНВНжш 1.3 еЙЪОСЫетвЛЙЄзїСїГЬЁЃ
ЮвУЧЖдФЧаЉвбОдкФкДцжаЕФЪєадНјаадЊЪ§ОнВщбЏЃЈВНжш 1.1ЃЉЃЌВЂДгЪєадЫїв§РШЁЦфгрЕФЪєадЃЈВНжш 1.2ЃЉЁЃЮЊСЫдкФЧаЉеыЖдЯрЭЌЪ§ОнЕФВЂЗЂЧыЧѓМфБЃжЄвЛжТадЃЌЮвУЧЪЙгУЬѕМўЪєадИќаТЃЈConditional
Attribute UpdateЃЉЃЌЭЈЙ§зЂШыСїЫЎЯпдкЖЮЕФдЊЪ§ОнжаМгдиЪєадЃКШчЙћФГаЉЪєадвбОБЛМгдиСЫЃЌдђЮвУЧВЛЯЃЭћЫќУЧЕФжЕБЛФГаЉдрзДЬЌИВИЧЁЃ
ЮЊСЫНЋЪєаджЕГжОУЛЏЕНЖўМЖДцДЂЩЯШЅЃЌЮвУЧЪЙгУЯжгаЕФЛљДЁЩшЪЉЁЃStorage Writer НЋНЯаЁЕФЖЮзЗМгВйзїОлКЯГЩЮЊНЯДѓЕФЛКГхЧјвЛДЮадаДШыЖўМЖДцДЂЃЌЭЌЪБЫќвВФмЙЛНЋЖрИіЪєадИќаТзщКЯГЩНЯДѓЕФХњВйзїЃЌЭЈЙ§ЪєадЫїв§ГжОУЛЏЕНЖўМЖДцДЂЁЃетДјРДСЫвЛаЉЖюЭтЕФКУДІЃЌФЧаЉЦЕЗБИќаТЕФЪєадЃЈР§ШчЪТМўЪ§ЃЉВЛБиУПДЮИќИФКѓЖМГжОУЛЏЕНЖўМЖДцДЂЃКЮвУЧПЩвдНЋЖрИіИќаТОлКЯЦ№РДЃЈНіБЃСєзюаТЕФжЕЃЉЃЌШчДЫБмУтСЫвЛаЉЗЧБивЊЕФЃЌАКЙѓЕФЖўМЖДцДЂаДВйзїЁЃ
5 ЖЮЪєадЫїв§
ЮвУЧУцСйЕФзюДѓЬєеНЛђаэОЭЪЧИУШчКЮНЋДѓСПЪєадБЃДцЕН Pravega ЕФЖўМЖДцДЂЩЯЁЃЪзЯШУїШЗвЛЕуЃЌЮвУЧЫљЫЕЕФДѓСПОПОЙЪЧЖрДѓЃПЯжЪЕвЛЕуЫЕЃЌЭЈГЃвЛИіЖЮДѓдМЛсгаЩЯЭђИі
WriterЃЌЮвУЧашвЊПМТЧБШетИќДѓЕФЪ§ОнСПТ№ЃП
ЮвУЧзюГѕВЩгУЕФЗНАИЖдУПИіЖЮаЁгк 10 ЭђЬѕЪєадЕФГЁОАНјааСЫгХЛЏЃЌЗНЗЈКмМђЕЅЃКЮвУЧНЋУПвЛИіИќаТЃЈ24
зжНкЃЉзЗМгЕНЪєадЖЮЃЌдкГжајаДШыСЫДѓдММИеззжНкЕФЪ§ОнКѓЃЌдйНЋЫљгаЪ§ОнбЙЫѕГЩвЛИігаађЪ§зщВЂЭЌбљНјаазЗМгЁЃЭЌЪБЮЌЛЄСЫвЛИіжИЯђзюКѓвЛДЮбЙЫѕЪзВПЕФжИеыЃЌУПДЮашвЊЖСШЁЪБЃЌОЭДгИУЪзВПвЛжБЖСШЁЕНЖЮЕФЮВЖЫЁЃетИіЗНЗЈКмМђЕЅЃЌУЛгаЪВУДИДдгЕФВПЗжЃЌвВФмКмКУЕиДІРэЮвУЧЕФгУР§ЃЈ10
ЭђЬѕЪєадвтЮЖзХЖўМЖДцДЂЩЯЕФДѓдМ 2.5MB ЕН 5MB Ъ§ОнЃЌЭъШЋПЩвдвЛДЮадЖСШЁВЂЛКДцЃЉЁЃ
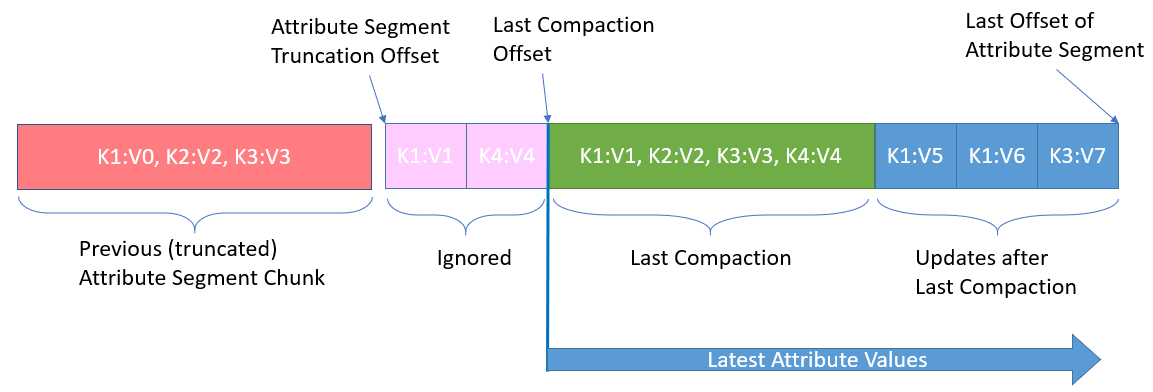
ЭМ 3 зюГѕЕФЗНАИЁЃЫљгаЕФЪєадИќаТЖМБЛзЗМгЕНЪєадЖЮЁЃЮвУЧЛсНјаавЛаЉжмЦкадЕФбЙЫѕВйзїЃЌНіБЃСєзюаТЕФЪєаджЕЁЃЪєадЖЮЭЌЪБвВБЛДгЭЗВПНиЖЯЃЌЖЊЦњЙ§ЦкЪ§ОнЁЃ
ДгГЄдЖЩЯПДЃЌЮвУЧЛЙЗЂЯжСЫгаЙиЪєадЕФСэЭтвЛаЉживЊгУЭОЁЃБэЖЮЃЌдк Pravega ЕФ 0.5 АцБОжаБЛв§ШыЃЌгУгкБЃДц
Pravega ЫљгаЕФдЊЪ§ОнЃЌВЂПЊЗХвЛИіЛљгкЦеЭЈЖЮЕФМќжЕ APIЁЃзїЮЊвЛИіЙўЯЃБэЃЌЫќНЋећИіЫїв§ЖМДцДЂдкЖЮЕФЪєаджаЃЌвђДЫЫќБШ
EventStreamWriters ашвЊИќЖрЕФЖЮЪєаджЇГжЁЃЮвУЧвтЪЖЕНЮвУЧашвЊжЇГжУПЖЮЧЇЭђМЖБ№ЕФЪєадЃЌеташвЊвЛжжЭъШЋВЛЭЌЕФЗНЗЈНЋЦфБЃДцЕНЖўМЖДцДЂЩЯЁЃЮвУЧЕФНтОіЗНАИОЭЪЧ
B+ЪїЃЌШЛЖјЃЌЮвУЧЫљбЁдёЕФЪЕЯжгыДѓЖрЪ§ЕфаЭЕФЪ§ОнПтЯЕЭГЩдгаВЛЭЌЁЃ
6 жЛзЗМгДцДЂЩЯЕФ B+Ъї
ЕБаоИФВйзїжЛдЪаэБЛзЗМгЕНЮФМўЕФЮВЖЫЪБЃЌB+ЪїЭЈГЃВЛЛсЪЧЫїв§НсЙЙЕФЪзбЁЁЃжЛзЗМгЕФ B+ЪїБфЬхвбОгаЯжгаЕФЪЕЯжЃЌЕЋЫќУЧЖМгавЛИіЯджјЕФШБЕуЃКаДЗХДѓЃЈWrite
AmplificationЃЉЁЃЫљгаЖдИУНсЙЙЕФаоИФЖМашвЊНЋДгИљНкЕуЕНБЛИќаТЪ§ОнНкЕуТЗОЖЩЯЕФЫљгаНкЕужиаТзЗМгЕНЮФМўЩЯЁЃ
ЫцзХЪБМфЕФЭЦвЦЃЌетЕМжТСЫГЌДѓЕФЮФМўГпДчЃЌЦфжаАќКЌСЫДѓСПЙ§ЦкЪ§ОнЁЃжмЦкадЕФШЋЫїв§бЙЫѕЫЦКѕПЩвдНтОіетИіЮЪЬтЃЌЕЋетвЛЗНЗЈЖд
Pravega ВЂВЛЪЪгУЁЃгЩгкЮвУЧЕФЯЕЭГБОжЪЩЯЪЧвЛИіЗжВМЪНЯЕЭГЃЌНкЕуЪЇаЇЪБВЛПЩБмУтЕФЃЌжюШчбЙЫѕВйзїетРрЕФЗЧдзгадВйзїКмФбдкВЛгАЯьЖЮДцДЂадФмЕФЧАЬсЯТе§ШЗЪЕЯжЁЃ
СэвЛжжЗНЗЈОЭЪЧЪЙгУ LSM ЪїЃЈLog-Structured Merge TreeЃЉЃЌЕЋетжжЪ§ОнНсЙЙвВДѓСПЪЙгУСЫбЙЫѕВйзїЁЃвђДЫЃЌЮвУЧЪЙгУСЫвЛаЉаТММЪѕКЭгХЛЏЗНЗЈЃЌШУЮвУЧПЩвдИпаЇЕиНЋЖЮЪєадБЃДцЕНЖўМЖДцДЂЩЯЕФ
B+ЪїЩЯЁЃ
ЮвУЧЕФМќжЕгРдЖЪЧЙЬЖЈГЄЖШЃЈЗжБ№ЮЊ 16 зжНкКЭ 8 зжНкЃЉЃЌетШУЮвУЧЕУвдМђЛЏ B+ЪїЕФНкЕуНсЙЙЃЌВЂдЪаэЪЙгУНЯДѓЕФЗжВцвђзгЃЈBranching
FactorЃЉЁЃЩшЖЈзюДѓНкЕуДѓаЁЮЊ 32KB ВЂЯожЦУПЬѕМЧТМ 32 зжНкЃЌЪЙЕУЮвУЧЕФЗжВцвђзгПЩвдГЌЙ§
1000ЁЃЖдгквЛИіДцДЂГЌЙ§ 10 вкЬѕМЧТМЕФЫїв§НсЙЙЃЌЮвУЧзюЖржЛашвЊ 3 ЕН 4 ДЮЖўМЖДцДЂЩЯЕФЖСВйзїОЭПЩвдЭъГЩФГИіМќЕФВщбЏЁЃ
ОЁЙмЮвУЧЫљвЊВщбЏЕФМќЕФЩюЖШПЩФмгаЪ§ВуЃЌЕЋШЮКЮ B+ЪїЕФВйзїЖМашвЊВщбЏИљНкЕуЃЌВЂЧвУПвЛИіЖўВуНкЕуЖМгаДѓдМЧЇЗжжЎвЛЕФИХТЪБЛВщбЏЁЃНЋНкЕуНјааЛКДцПЩвдМЋДѓМѕЩйЖдЖўМЖДцДЂЕФЫцЛњЖСШЁЃЌгШЦфЪЧЖдгкЩюЖШНЯДѓЕФНкЕуЁЃЖдгкзюДѓНкЕуДѓаЁ
32KB етбљЕФЩшжУЃЌећИіЖўВуНкЕужЛеМгУДѓдМ 32MB ЕФЛКДцПеМфЃЌЮвУЧЭъШЋПЩвдАбЫќУЧШЋВПМгдиЕНФкДцжаЁЃгЩгкЗУЮЪФЃЪНЕФВЛЭЌЃЌЛКДцУќжаТЪвВЛсЯргІгаКмДѓБфЛЏЃЌЕЋЮвУЧЕФВтЪдЯдЪОЃЌЖдгквЛИівбОдЄШШЕФЫїв§ЃЌЕБЪЙгУЛКДцЪБЃЌЖЈЮЛвЛИіМќНіашвЊВЛГЌЙ§вЛДЮЕФЖўМЖДцДЂЖСВйзїЁЃ
НЯДѓЕФЗжВцвђзгвВФмЛКНтаДЗХДѓЮЪЬтЃЌЕЋВЛФмЭъШЋЯћГ§ЫќЁЃШЛЖјЃЌвЛИіКмЙиМќЕФЪТЪЕЪЧЃЌОЁЙмЪєадЖЮПЩФмЛсЮоЯодіГЄЃЌЕЋЛюЖЏЪ§ОнЃЈзюаТАцБОЕФЪ§ОнЃЉзмЪЧМЏжадкЖЮЕФЮВЖЫЃЌЖјЖЮЕФЪзВПЧуЯђгкАќКЌДѓВПЗжЕФЙ§ЦкЪ§ОнЁЃЭЈЙ§ЪЙгУгы
Retention ЯрЭЌЕФЗНЗЈЃЌЮвУЧПЩвдЖдЖЮНјааЭЗВПНиЖЯЃЌЩОГ§ФЧаЉвбОБЛНиЖЯЕФЪ§ОнПщЃЈChunkЃЉЁЃЖЮЩЯЕФЪ§ОнПщЪЧвЛзщСЌајЕФзжНкађСаЃЌУПвЛИіЪ§ОнПщЖМЖдгІЖўМЖДцДЂЩЯЕФвЛИіЮФМўЛђепЖдЯѓЁЃвђДЫЃЌЭЈЙ§ЖдЪєадЖЮЪЙгУЯжгаЕФЙіЖЏДцДЂЃЈRolling
StorageЃЉЪЪХфЦїЃЌЮвУЧвбОЗЧГЃНгНќЮвУЧЕФЦкЭћФПБъСЫЁЃ
ШЛЖјЃЌЮвУЧжЛгадкШЗШЯБЛЖЊЦњЕФЪ§ОнжаВЛдйАќКЌШЮКЮШддкЪЙгУЕФ B+ЪїНкЕуЃЈФЧаЉдкИќаТВйзїКѓвбБЛжиаТзЗМгЕФНкЕуЃЉКѓЃЌВХФмНјааЭЗВПНиЖЯЁЃЖЮЕФЪзВПгаКмДѓИХТЪАќКЌЙ§ЦкЪ§ОнЃЌЕЋХМЖћвВЛсАќКЌвЛаЉШддкЪЙгУЕФ
B+ЪїНкЕуЁЃОЕфЕФбЙЫѕВйзївбОПМТЧЕНетжжЧщПіСЫЃКЩЈУшЫїв§ЮФМўЃЌевЕНзюдчЕФБЛЙ§ЦкЪ§ОнАќЮЇЕФНкЕуЃЌЭЈЙ§зЗМгЕФЗНЪННЋЫќУЧвЦЖЏЕНЮФМўЕФЮВЖЫЁЃЫфШЛетВЂВЛЛсзшШћНиЖЯЃЌЕЋЫќЛЙЪЧашвЊЭЌЪБЖдДѓСПЖЮЮЌЛЄвЛЖЮНЯГЄЕФЗЧдзгадЕФбЙЫѕЙ§ГЬЁЃ
ЮвУЧВЩгУСЫСэвЛжжБЛГЦЮЊНЅНјЪНбЙЫѕЃЈProgressive CompactionЃЉЕФЗНЗЈЁЃУПДЮаоИФ
B+ЪїЃЌЮвУЧЖМЛсЖЈЮЛЪєадЖЮЩЯЦЋвЦзюаЁЕФЯрЙиНкЕуЃЌЭЈЙ§зЗМгЕФЗНЪННЋЦфвЦЖЏЕНЖЮЮВЖЫЃЈЭЌЪБПЩФмЛЙЛсвЦЖЏЫќЕФзцЯШНкЕуЃЉЁЃОЁЙметПДЦ№РДгаЕуЯёЮвУЧАбаДЗХДѓЮЪЬтБфЕУИќдуИтСЫЃЌЕЋетШЗЪЕЪЧвЛИіШУЪєадЖЮЮФМўГпДчБфаЁЕФелждЗНАИЁЃЖўМЖДцДЂЕФаДВйзїЭЈГЃБЛШЯЮЊЪЧИпЭЬЭТСПЕФЃЌЫљвдУПДЮЖраД
32KB ЕН 100KB ЕФЪ§ОнВЛЛсгаЖрЩйВюБ№ЁЃЖјЮвУЧЫљЕУЕНЕФЛиБЈОЭЪЧЃЌЮвУЧДгвЛПЊЪМОЭПЩвдЖдДѓЪ§ОнПщНјааНиЖЯЃЌвђДЫФмЙЛШУЪєадЖЮЕФДѓаЁЪМжеБЃГждкКЯРэЗЖЮЇФкЁЃ
ЮЊСЫЖЈЮЛОпгазюаЁЦЋвЦЕФНсЕуЃЌУПИі B+ЪїНкЕуБЃДцСЫвдЫќЮЊИљЕФзгЪїжаЫљгаНкЕуЦЋвЦЕФзюаЁжЕЁЃжЊЕРСЫетИіжЕЃЌЮвУЧОЭПЩвдбизХИљНкЕуЕФТЗОЖЃЌЖЈЮЛЕНОпгазюаЁЦЋвЦЕФФЧИіНкЕуЁЃ
ЮЌЛЄетИіжЕвВЗЧГЃМђЕЅЃКвђЮЊУПДЮИќаТЖМашвЊаоИФДгвЖНкЕуЕНИљНкЕуМфЕФЫљгаНкЕуЃЌЮвУЧЫљвЊзіЕФОЭЪЧРћгУЯжгаНкЕуФкБрТыЕФаХЯЂжиаТЮЊУПИіНкЕуМЦЫуИУжЕЁЃЮвУЧВЛашвЊЖюЭтЕФ
IO ВйзїЃЌвђДЫвВВЛЛсЖдадФмдьГЩгАЯьЁЃ
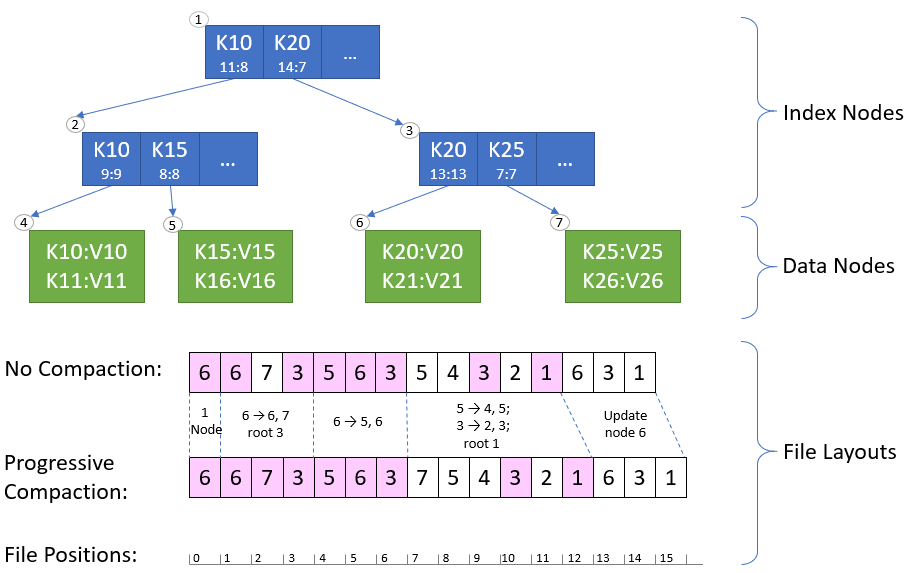
ЭМ 4 Ш§Ву B+ЪївдМАЪєадЖЮЕФВМОжЃЈгаНЅНјЪНбЙЫѕКЭЮоНЅНјЪНбЙЫѕЃЉЁЃЫїв§ЭМР§ЃКМќЧАзКБъзЂдкЖЅВПЃЛЕзВПЪЧзгвГЦЋвЦ:зюаЁвГЦЋвЦЁЃИУЪїДІгкзюжезДЬЌЁЃ
ЮвУЧПДвЛЯТдкЭМ 4 жаЃЌЫцзХ B+ЪїЕФДДНЈЃЌЮФМўВМОжЪЧШчКЮБфЛЏЕФЁЃ
Ц№ЪМЃЌЮвУЧжЛгавЛПУЕЅНкЕуЕФЪїЃЌНіАќКЌНкЕу 6ЁЃ
ЮоТлгаЮоНЅНјЪНбЙЫѕЃЌЮвУЧЖМЖдНкЕу 6 НјаазЗМгЁЃ
НкЕу 6 ЗжСбЮЊ 6 КЭ 7ЃЌНкЕу 3 зїЮЊИљНкЕуЃЌЖјНкЕу 6 КЭ 7 ЮЊзгНкЕуЁЃ
ЮоТлгаЮоНЅНјЪНбЙЫѕЃЌЮвУЧЖМзЗМгНкЕу 6ЃЌ7 КЭ 3ЁЃЮФМўВМОжЮЊЃК6ЃЌ6ЃЌ7ЃЌ3ЁЃ
ЖдгкНЅНјЪНбЙЫѕЃЌЮвУЧЬјЙ§жиаТзЗМгНкЕу 6ЃЌвђЮЊЫќвбОАќКЌдкИќаТжаСЫЁЃ
НкЕу 6 ЗжСбЮЊ 5 КЭ 6ЁЃНкЕу 3 ЕФзгНкЕуЮЊНкЕу 5ЃЌ6 КЭ 7ЁЃ
ЮоТлгаЮоНЅНјЪНбЙЫѕЃЌЮвУЧЖМзЗМгНкЕу 5ЃЌ6 КЭ 3ЁЃЮФМўВМОжЮЊЃК6ЃЌ6ЃЌ7ЃЌ3ЃЌ5ЃЌ6ЃЌ3ЁЃ
ЖдгкНЅНјЪНбЙЫѕЃЌЮвУЧЬјЙ§жиаТзЗМгНкЕу 6ЃЌвђЮЊЫќвбОАќКЌдкИќаТжаСЫЁЃ
НкЕу 5 ЗжСбЮЊ 4 КЭ 5ЃЛНкЕу 3 ЗжСбЮЊ 2 КЭ 3ЃЛНкЕу 1 ДДНЈЮЊИљЁЃНкЕу 1 ЕФзгНкЕуЮЊ
2 КЭ 3ЃЌНкЕу 2 ЕФзгНкЕуЮЊ 4 КЭ 5ЃЌНкЕу 3 ЕФзгНкЕуЮЊ 6 КЭ 7ЁЃ
ЮоНЅНјЪНбЙЫѕЃКЮвУЧзЗМгНкЕу 5ЃЌ4ЃЌ3ЃЌ2 КЭ 1ЁЃЮФМўВМОжЮЊЃК6ЃЌ6ЃЌ7ЃЌ3ЃЌ5ЃЌ6ЃЌ3ЃЌ5ЃЌ4ЃЌ3ЃЌ2ЃЌ1ЁЃ
гаНЅНјЪНбЙЫѕЃКЮвУЧзЗМгНкЕу 7ЃЌШЛКѓЪЧНкЕу 5ЃЌ4ЃЌ3ЃЌ2 КЭ 1ЁЃЮФМўВМОжЪЧЃК6ЃЌ6ЃЌ7ЃЌ3ЃЌ5ЃЌ6ЃЌ3ЃЌ7ЃЌ5ЃЌ4ЃЌ3ЃЌ2ЃЌ1ЁЃ
НкЕу 6 БЛИќаТЁЃB+ЪїУЛгаНсЙЙадБфЛЏЁЃ
ЮоТлгаЮоНЅНјЪНбЙЫѕЃЌЮвУЧЖМашвЊзЗМг 6ЃЌ3 КЭ 1ЁЃ
ЖдгкНЅНјЪНбЙЫѕЃЌЮвУЧЬјЙ§жиаТзЗМгНкЕу 6ЃЌвђЮЊЫќвбОАќКЌдкИќаТжаЁЃ
ЮоНЅНјЪНбЙЫѕЕФВМОжЃК6ЃЌ6ЃЌ7ЃЌ3ЃЌ5ЃЌ6ЃЌ3ЃЌ5ЃЌ4ЃЌ3ЃЌ2ЃЌ1ЃЌ6ЃЌ3ЃЌ1ЁЃ
гаНЅНјЪНбЙЫѕЕФВМОжЃК6ЃЌ6ЃЌ7ЃЌ3ЃЌ5ЃЌ6ЃЌ3ЃЌ7ЃЌ5ЃЌ4ЃЌ3ЃЌ2ЃЌ1ЃЌ6ЃЌ3ЃЌ1ЁЃ
дкетИіР§згжаЃЌНЅНјЪНбЙЫѕдЪаэЮвУЧдкЮЛжУ 7ЃЈдкЮобЙЫѕЕФР§згжаЮЊЮЛжУ 2ЃЉНјааЪєадЖЮЕФНиЖЯЃЌвђДЫАяжњЮвУЧЪЭСЫЗХВЛдйашвЊЕФДХХЬПеМфЁЃ
7 ЪЕМЪгІгУжаЕФНЅНјЪНбЙЫѕ
ЮЊСЫбщжЄНЅНјЪНбЙЫѕдкЯжЪЕГЁОАжаЕФдЫзїЧщПіЃЌЮвУЧЩшМЦВЂдЫааСЫвЛЯЕСаВтЪдЁЃЭЈЙ§НЋЖрИіИќаТВйзїзщКЯГЩвЛИіДѓЕФХњВйзїЃЌЮвУЧПЩвдМѕЩйаДЗХДѓЃЌвђЮЊХњВйзїдНДѓЃЌB+ЪїОЭдНЩйашвЊжиаДЫќЕФЩЯВуНкЕуЁЃЮвУЧЪЙгУВЛЭЌЕФВхШы/ИќаТХњВйзїДѓаЁЃЌВЂЖдБШгабЙЫѕКЭЮобЙЫѕЧщПіЯТЕФЫїв§ЃЈдкЖўМЖДцДЂЩЯЃЉДѓаЁЁЃдкетаЉВтЪджаЪЙгУЕФХњВйзїГпДчЗДгГСЫ
Storage Writer ШчКЮОлКЯИќаТВйзїЃКНЯаЁЕФХњГпДчЪЪгУгкФЧаЉОпгаНЯЩйВЂЗЂ Writer ЕФЖЮЃЌЖјНЯДѓЕФХњГпДчЭЈГЃБЛгУгкБэЖЮЁЃ
| ХњГпДч |
Ыїв§ДѓаЁЃЈMBЃЉ |
|
| |
ЮобЙЫѕ |
НЅНјЪНбЙЫѕ |
| 10 |
3,991 |
115 (3%) |
| 100 |
416 |
97 (23%) |
| 1,000 |
60 |
54 (89%) |
Бэ 1 ЫГађВхШы 1,000.000 ЬѕЖЮЪєадЁЃЖдНЯаЁЕФХњГпДчЃЌНЅНјЪНбЙЫѕЕФаЇЙћзюЯджјЃЈДѓаЁМѕЩйСЫ
97%ЃЉЃЌЖјНЯДѓЕФХњГпДчдђаЇЙћВЂВЛУїЯдЃЈгЩгкНЯаЁЕФаДЗХДѓЃЉЁЃ
| ХњГпДч |
Ыїв§ДѓаЁЃЈMBЃЉ |
|
| |
ЮобЙЫѕ |
НЅНјЪНбЙЫѕ |
| 10 |
32,990 |
72 (0.22%) |
| 100 |
29,402 |
103 (0.35%) |
| 1,000 |
17,083 |
91 (0.53%) |
Бэ 2 ХњСПМгди 1,000,000 ЬѕЖЮЪєадЃЌВЂАДЫцЛњЫГађИќаТЁЃЮоТлХњГпДчШчКЮЃЌаДЗХДѓЮЪЬтЖМЪЎЗжбЯжиЃЌНЅНјЪНбЙЫѕвВвђДЫШЁЕУСЫЯджјаЇЙћЃКЫїв§ДѓаЁБЛМѕЩйСЫжСЩй
99.5%ЁЃ
8 змНс
ЪєаддкЖЮЕФећИіЩњУќжмЦкжаАчбнзХКЫаФНЧЩЋЁЃГ§СЫДцДЂЖЮБОЩэЕФдЊаХЯЂЭтЃЌЫќУЧЛЙДѓСПВЮгыЕНЖЮЕФаоИФВйзїжаШЅЁЃЫќУЧБЛгУгкБЃДцЖЮФкЕФЭГМЦЪ§ОнЃЈР§ШчЪТМўзмЪ§ЃЉЃЌдЪаэ
EventStreamWriters ЪЕЯжНівЛДЮгявхЁЃдкДЋЭГЪ§ОнНсЙЙЩЯЪЙгУДДаТЕФЗНЗЈЪЙЕУЖЮДцДЂПЩвдЮЊУПИіЖЮгааЇЙмРэ
10 вкЪ§СПМЖЕФЖЮЪєадЁЃНЅНјЪНбЙЫѕдкВЛЪЙгУКѓЬЈШЮЮёКЭВЛгАЯьадФмЕФЧщПіЯТМѕаЁСЫаДЗХДѓаЇгІЃЌЮЊжЛзЗМг B+ЪїМѕаЁСЫ
99.5%ЕФГпДчЁЃ
|








