| БрМЭЦМі: |
БОЮФДјДѓМвЪЙгУ
Docker Compose ПьЫйЩЯЪж Flink SQL ЕФБрГЬЃЌВЂЖдБШ Window
Aggregate КЭ Group Aggregate ЕФЧјБ№ЃЌвдМАетСНжжРраЭЕФзївЕШчКЮаДШыЕН
ЭтВПЯЕЭГжаЁЃ
БОЮФРДздгкИіШЫВЉПЭJark's Blog
ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
ЭЈЙ§БОПЮФуФмбЇЕНЪВУДЃП
БОЮФНЋЭЈЙ§ЮхИіЪЕР§РДЙсДЉ Flink SQL ЕФБрГЬЪЕМљЃЌжївЊЛсКИЧвдЯТМИИіЗНУцЕФФкШнЁЃ
1.ШчКЮЪЙгУ SQL CLI ПЭЛЇЖЫ
2.ШчКЮдкСїЩЯдЫаа SQL ВщбЏ
3.дЫаа window aggregate гы non-window
aggregateЃЌРэНтЦфЧјБ№
4.ШчКЮгУ SQL ЯћЗб Kafka Ъ§Он
5.ШчКЮгУ SQL НЋНсЙћаДШы Kafka КЭ ElasticSearch
БОЮФМйЖЈФњвбОпБИЛљДЁЕФ SQL жЊЪЖЁЃ
ЛЗОГзМБИ
БОЮФНЬГЬЪЧЛљгк Docker НјааЕФЃЌвђДЫФужЛашвЊАВзАСЫ Docker МДПЩЁЃВЛашвЊвРРЕ JavaЁЂScala
ЛЗОГЁЂЛђЪЧIDEЁЃ
зЂвтЃКDocker ФЌШЯХфжУЕФзЪдДПЩФмВЛЬЋЙЛЃЌЛсЕМжТдЫаа Flink Job ЪБПЈЫРЁЃвђДЫЭЦМіХфжУ
Docker зЪдДЕН 3-4 GBЃЌ3-4 CPUsЁЃ
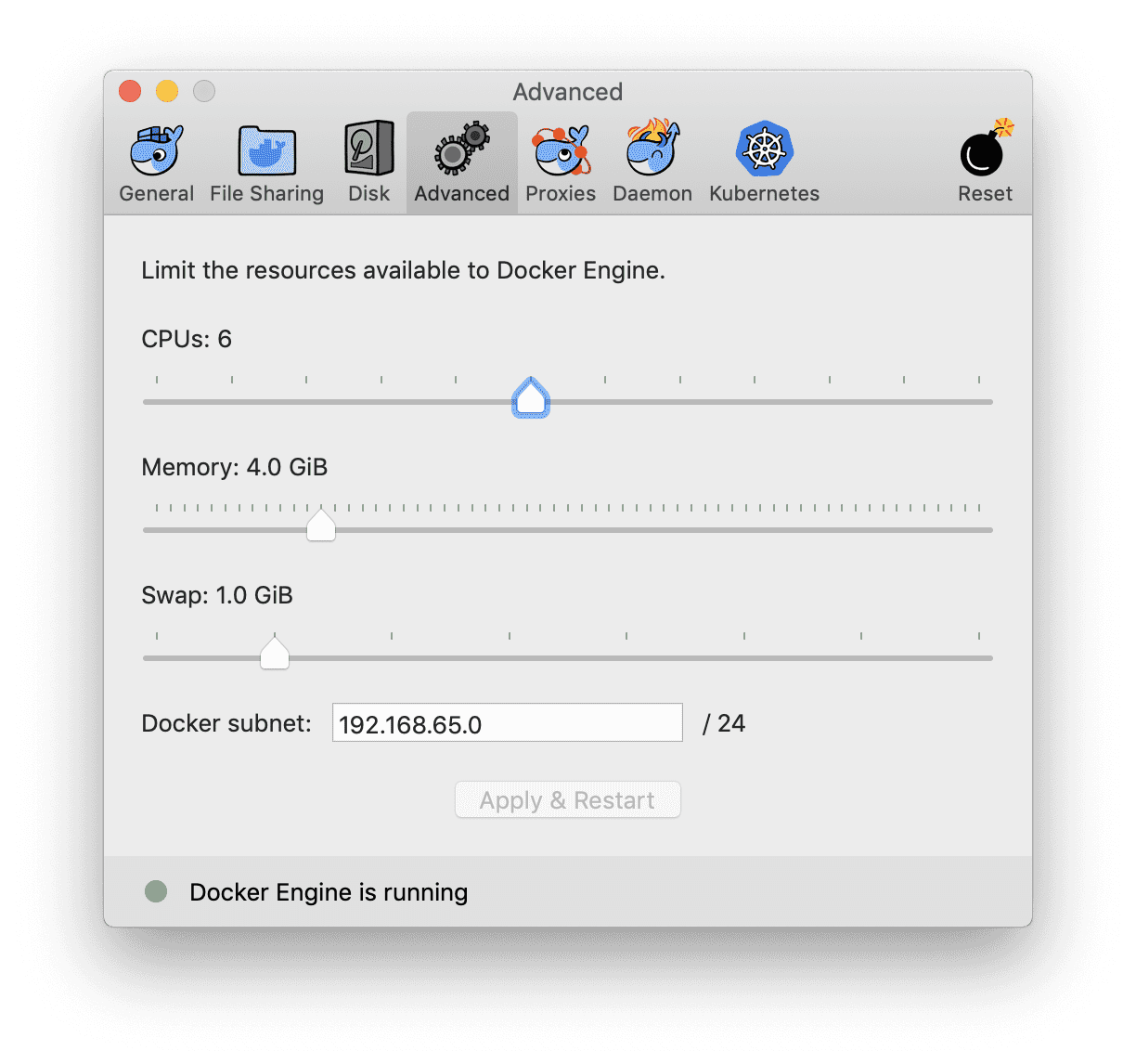
БОДЮНЬГЬЕФЛЗОГЪЙгУ Docker Compose РДАВзАЃЌАќКЌСЫЫљашЕФИїжжЗўЮёЕФШнЦїЃЌАќРЈЃК
1.Flink SQL ClientЃКгУРДЬсНЛqueryЃЌвдМАПЩЪгЛЏНсЙћ
2.Flink JobManager КЭ TaskManagerЃКгУРДдЫаа
Flink SQL ШЮЮёЁЃ
3.Apache KafkaЃКгУРДЩњГЩЪфШыСїКЭаДШыНсЙћСїЁЃ
4.Apache ZookeeperЃКKafka ЕФвРРЕЯю
5.ElasticSearchЃКгУРДаДШыНсЙћ
ЮвУЧвбОЬсЙЉКУСЫDocker Compose ХфжУЮФМўЃЌПЩвджБНгЯТди docker-compose.yml
ЮФМўЁЃ
ШЛКѓДђПЊУќСюааДАПкЃЌНјШыДцЗХ docker-compose.yml ЮФМўЕФФПТМЃЌШЛКѓдЫаавдЯТУќСюЃК
Linux & MacOS
Windows
set COMPOSE_CONVERT_WINDOWS_PATHS=1
docker-compose up -d |
docker-compose УќСюЛсЦєЖЏЫљгаЫљашЕФШнЦїЁЃЕквЛДЮдЫааЕФЪБКђЃЌDocker ЛсздЖЏЕиДг
Docker Hub ЯТдиОЕЯёЃЌетПЩФмЛсашвЊвЛЖЮЪБМфЃЈНЋНќ 2.3GBЃЉЁЃжЎКѓдЫааЕФЛАЃЌМИУыжгОЭФмЦєЖЏЦ№РДСЫЁЃдЫааГЩЙІЕФЛАЃЌЛсдкУќСюаажаПДЕНвдЯТЪфГіЃЌВЂЧввВПЩвддк
http://localhost:8081 ЗУЮЪЕН Flink Web UIЁЃ
дЫаа Flink SQL CLI ПЭЛЇЖЫ
дЫааЯТУцУќСюНјШы Flink SQL CLI ЁЃ
| docker-compose
exec sql-client ./sql-client.sh |
docker-compose exec sql-client ./sql-client.sh
ИУУќСюЛсдкШнЦїжаЦєЖЏ Flink SQL CLI ПЭЛЇЖЫЁЃШЛКѓФуЛсПДЕНШчЯТЕФЛЖгНчУцЁЃ
Ъ§ОнНщЩм
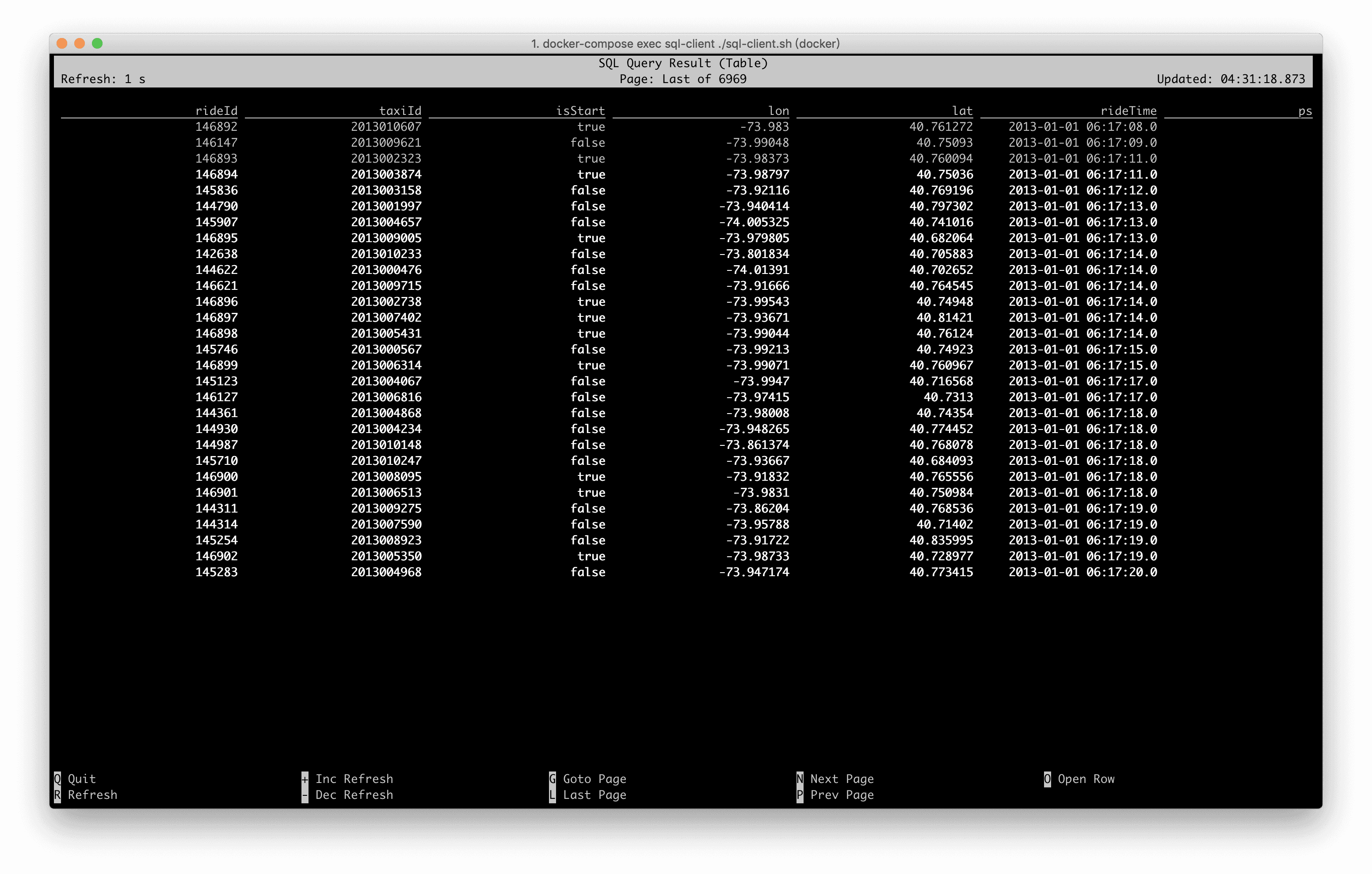
Docker Compose жавбОдЄЯШзЂВсСЫвЛаЉБэКЭЪ§ОнЃЌПЩвддЫаа SHOW TABLES; РДВщПДЁЃБОЮФЛсгУЕНЕФЪ§ОнЪЧ
Rides БэЃЌетЪЧвЛеХГізтГЕЕФааГЕМЧТМЪ§ОнСїЃЌАќКЌСЫЪБМфКЭЮЛжУаХЯЂЃЌдЫаа DESCRIBE Rides;
ПЩвдВщПДБэНсЙЙЁЃ
Flink SQL>
DESCRIBE Rides;
root
|-- rideId: Long // ааЮЊID (АќКЌСНЬѕМЧТМЃЌвЛЬѕШывЛЬѕГіЃЉ
|-- taxiId: Long // ГізтГЕID
|-- isStart: Boolean // ПЊЪМ or НсЪј
|-- lon: Float // ОЖШ
|-- lat: Float // ЮГЖШ
|-- rideTime: TimeIndicatorTypeInfo(rowtime) //
ЪБМф
|-- psgCnt: Integer // ГЫПЭЪ§ |
Rides БэЕФЯъЯИЖЈвхМћ training-config.yamlЁЃ
ЪЕР§1ЃКЙ§ТЫ
Р§ШчЮвУЧЯждкжЛЯыВщПДЗЂЩњдкХІдМЕФааГЕМЧТМЁЃ
зЂЃКDocker ЛЗОГжавбОдЄЖЈвхСЫвЛаЉФкжУКЏЪ§ЃЌШч isInNYC(lon, lat) ПЩвдШЗЖЈвЛИіОЮГЖШЪЧЗёдкХІдМЃЌtoAreaId(lon,
lat) ПЩвдНЋОЮГЖШзЊЛЛГЩЧјПщЁЃ
вђДЫЃЌДЫДІЮвУЧПЩвдЪЙгУ isInNYC РДПьЫйЙ§ТЫГіХІдМЕФааГЕМЧТМЁЃдк SQL CLI жадЫааШчЯТ
QueryЃК
| SELECT * FROM
Rides WHERE isInNYC(lon, lat); |
SQL CLI БуЛсЬсНЛвЛИі SQL ШЮЮёЕН Docker МЏШКжаЃЌДгЪ§ОндДЃЈRides СїДцДЂдкKafkaжаЃЉВЛЖЯРШЁЪ§ОнЃЌВЂЭЈЙ§
isInNYC Й§ТЫГіЫљашЕФЪ§ОнЁЃSQL CLI вВЛсНјШыПЩЪгЛЏФЃЪНЃЌВЂВЛЖЯЫЂаТеЙЪОЙ§ТЫКѓЕФНсЙћЃК
вВПЩвдЕН http://localhost:8081 ВщПД Flink зївЕЕФдЫааЧщПіЁЃ
ЪЕР§2ЃКGroup Aggregate
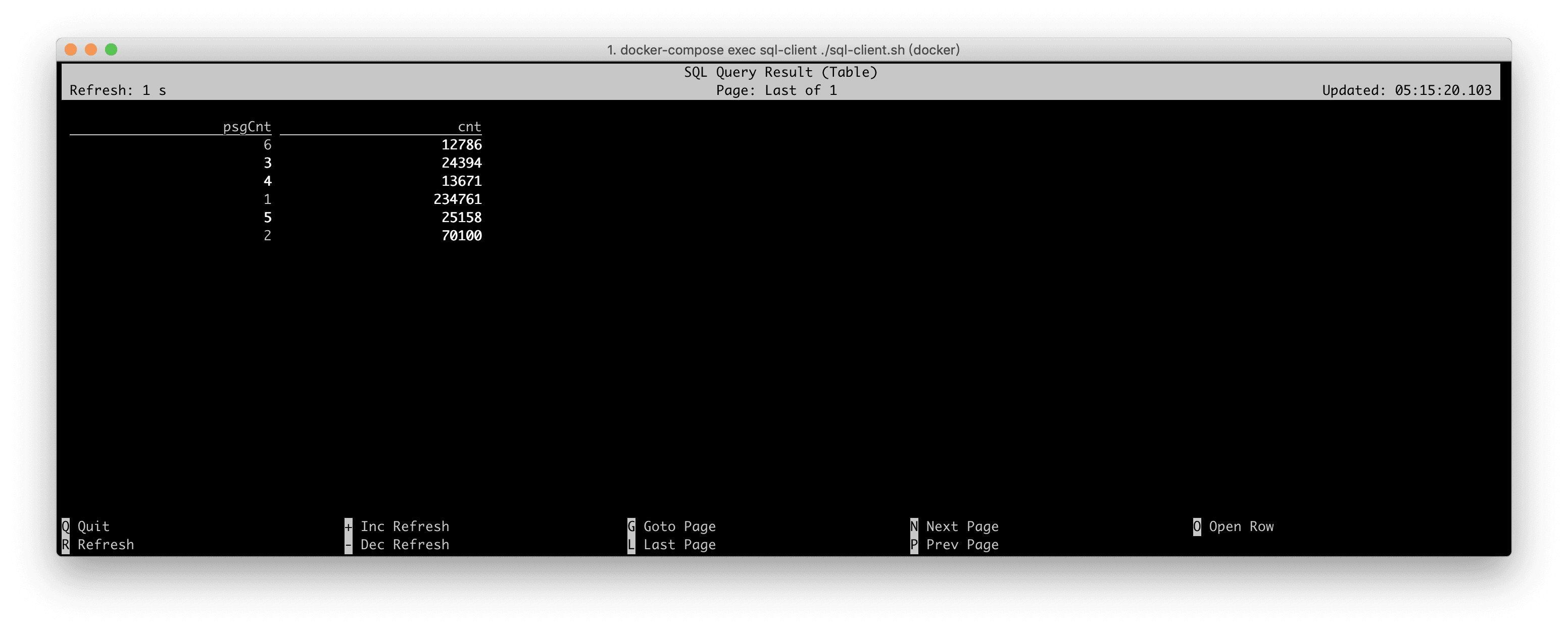
ЮвУЧЕФСэвЛИіашЧѓЪЧМЦЫуДюдиУПжжГЫПЭЪ§СПЕФааГЕЪТМўЪ§ЁЃвВОЭЪЧДюди1ИіГЫПЭЕФааГЕЪ§ЁЂДюди2ИіГЫПЭЕФааГЕЁ
ЕБШЛЃЌЮвУЧШдШЛжЛЙиаФХІдМЕФааГЕЪТМўЁЃ
вђДЫЃЌЮвУЧПЩвдАДееГЫПЭЪ§psgCntзіЗжзщЃЌЪЙгУ COUNT(*) МЦЫуГіУПИіЗжзщЕФЪТМўЪ§ЃЌзЂвтдкЗжзщЧАашвЊЯШЙ§ТЫГіisInNYCЕФЪ§ОнЁЃдк
SQL CLI жадЫааШчЯТ QueryЃК
SELECT psgCnt,
COUNT(*) AS cnt
FROM Rides
WHERE isInNYC(lon, lat)
GROUP BY psgCnt; |
SQL CLI ЕФПЩЪгЛЏНсЙћШчЯТЫљЪОЃЌНсЙћУПУыЖМдкЗЂЩњБфЛЏЁЃВЛЙ§зюДѓЕФГЫПЭЪ§ВЛЛсГЌЙ§ 6 ШЫЁЃ
ЪЕР§3ЃКWindow Aggregate
ЮЊСЫГжајЕиМрВтХІдМЕФНЛЭЈСїСПЃЌашвЊМЦЫуГіУПИіЧјПщУП5ЗжжгЕФНјШыЕФГЕСОЪ§ЁЃЮвУЧжЛЙиаФжСЩйга5СОГЕзгНјШыЕФЧјПщЁЃ
ДЫДІашвЊЩцМАЕНДАПкМЦЫуЃЈУП5ЗжжгЃЉЃЌЫљвдашвЊгУЕН Tumbling Window ЕФгяЗЈЁЃЁАУПИіЧјПщЁБ
ЫљвдЛЙвЊАДее toAreaId НјааЗжзщМЦЫуЁЃЁАНјШыЕФГЕСОЪ§ЁБ ЫљвддкЗжзщЧАашвЊИљОн isStart
зжЖЮЙ§ТЫГіНјШыЕФааГЕМЧТМЃЌВЂЪЙгУ COUNT(*) ЭГМЦГЕСОЪ§ЁЃзюКѓЛЙгавЛИі ЁАжСЩйга5СОГЕзгЕФЧјПщЁБ
ЕФЬѕМўЃЌетЪЧвЛИіЛљгкЭГМЦжЕЕФЙ§ТЫЬѕМўЃЌЫљвдПЩвдгУ SQL HAVING згОфРДЭъГЩЁЃ
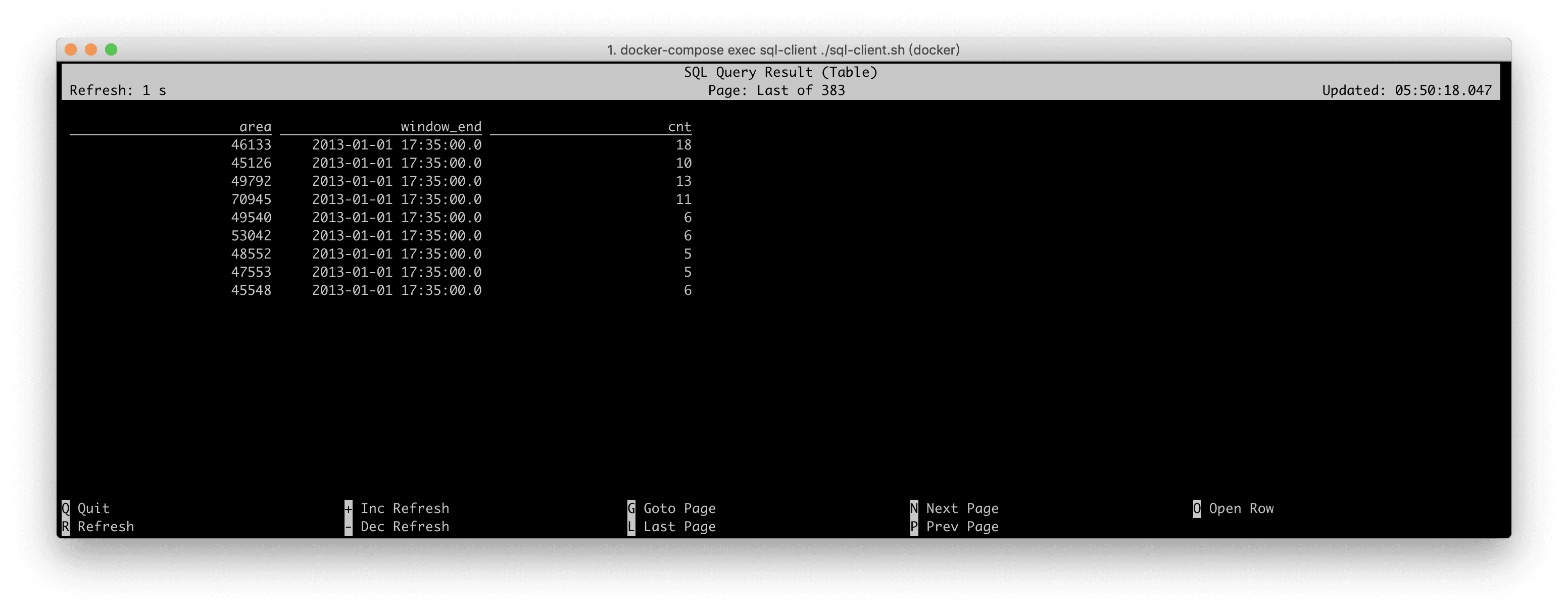
зюКѓЕФ Query ШчЯТЫљЪОЃК
SELECT
toAreaId(lon, lat) AS area,
TUMBLE_END(rideTime, INTERVAL '5' MINUTE) AS window_end,
COUNT(*) AS cnt
FROM Rides
WHERE isInNYC(lon, lat) and isStart
GROUP BY
toAreaId(lon, lat),
TUMBLE(rideTime, INTERVAL '5' MINUTE)
HAVING COUNT(*) >= 5; |
дк SQL CLI жадЫааКѓЃЌЦфПЩЪгЛЏНсЙћШчЯТЫљЪОЃЌУПИі area + window_end ЕФНсЙћЪфГіКѓОЭВЛЛсдйЗЂЩњБфЛЏЃЌЕЋЪЧЛсУПИє
5 ЗжжгЛсЪфГівЛХњаТДАПкЕФНсЙћЁЃвђЮЊ Docker ЛЗОГжаЕФsourceЮвУЧзіСЫ10БЖЕФМгЫйЖСШЁЃЈЯрЖдгкдЪМЫйЖШЃЉЃЌЫљвдбнЪОЕФЪБКђЃЌДѓИХУПИє30УыОЭЛсЪфГівЛХњаТДАПкЁЃ
Window Aggregate гы Group Aggregate ЕФЧјБ№
ДгЪЕР§2КЭЪЕР§3ЕФНсЙћЯдЪОЩЯЃЌПЩвдЬхбщГіРД Window Aggregate гы Group Aggregate
ЪЧгавЛаЉУїЯдЕФЧјБ№ЕФЁЃЦфжївЊЕФЧјБ№ЪЧЃЌWindow Aggregate ЪЧЕБwindowНсЪјЪБВХЪфГіЃЌЦфЪфГіЕФНсЙћЪЧзюжежЕЃЌВЛЛсдйНјаааоИФЃЌЦфЪфГіСїЪЧвЛИі
Append СїЁЃЖј Group Aggregate ЪЧУПДІРэвЛЬѕЪ§ОнЃЌОЭЪфГізюаТЕФНсЙћЃЌЦфНсЙћЪЧдкВЛЖЯИќаТЕФЃЌОЭКУЯёЪ§ОнПтжаЕФЪ§ОнвЛбљЃЌЦфЪфГіСїЪЧвЛИі
Update СїЁЃ
СэЭтвЛИіЧјБ№ЪЧЃЌwindow гЩгкга watermark ЃЌПЩвдОЋШЗжЊЕРФФаЉДАПквбОЙ§ЦкСЫЃЌЫљвдПЩвдМАЪБЧхРэЙ§ЦкзДЬЌЃЌБЃжЄзДЬЌЮЌГждкЮШЖЈЕФДѓаЁЁЃЖј
Group Aggregate вђЮЊВЛжЊЕРФФаЉЪ§ОнЪЧЙ§ЦкЕФЃЌЫљвдзДЬЌЛсЮоЯодіГЄЃЌетЖдгкЩњВњзївЕРДЫЕВЛЪЧКмЮШЖЈЃЌЫљвдНЈвщЖд
Group Aggregate ЕФзївЕХфЩЯ State TTL ЕФХфжУЁЃ

Р§ШчЭГМЦУПИіЕъЦЬУПЬьЕФЪЕЪБPVЃЌФЧУДОЭПЩвдНЋ TTL ХфжУГЩ 24+ аЁЪБЃЌвђЮЊвЛЬьЧАЕФзДЬЌвЛАуРДЫЕОЭгУВЛЕНСЫЁЃ
SELECT DATE_FORMAT(ts,
'yyyy-MM-dd'), shop_id, COUNT(*) as pv
FROM T
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd'), shop_id
|
ЕБШЛЃЌШчЙћ TTL ХфжУЕиЬЋаЁЃЌПЩФмЛсЧхГ§ЕєвЛаЉгагУЕФзДЬЌКЭЪ§ОнЃЌДгЖјЕМжТЪ§ОнОЋШЗадЕиЮЪЬтЁЃетвВЪЧгУЛЇашвЊШЈКтЕивЛИіВЮЪ§ЁЃ
ЪЕР§4ЃКНЋ Append СїаДШы Kafka
ЩЯвЛаЁНкНщЩмСЫ Window Aggregate КЭ Group Aggregate ЕФЧјБ№ЃЌвдМА
Append СїКЭ Update СїЕФЧјБ№ЁЃдк Flink жаЃЌФПЧА Update СїжЛФмаДШыжЇГжИќаТЕФЭтВПДцДЂЃЌШч
MySQL, HBase, ElasticSearchЁЃAppend СїПЩвдаДШыШЮвтЕиДцДЂЃЌВЛЙ§вЛАуаДШыШежОРраЭЕФЯЕЭГЃЌШч
KafkaЁЃ
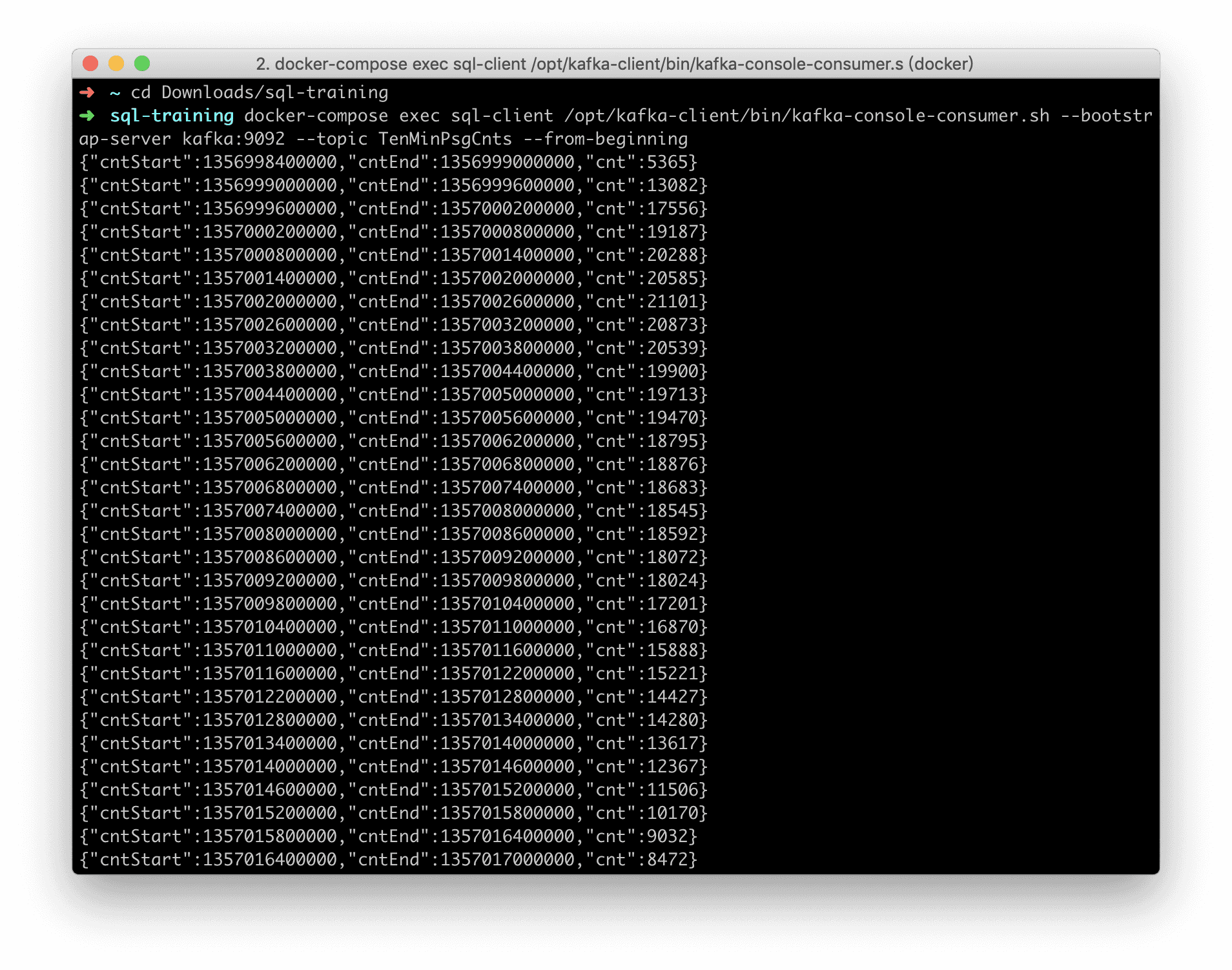
етРяЮвУЧЯЃЭћНЋЁАУП10ЗжжгЕФДюГЫЕФГЫПЭЪ§ЁБаДШыKafkaЁЃ
ЮвУЧвбОдЄЖЈвхСЫвЛеХ Kafka ЕФНсЙћБэ Sink_TenMinPsgCntsЃЈtraining-config.yaml
жагаЭъећЕФБэЖЈвхЃЉЁЃ
дкжДаа Query ЧАЃЌЮвУЧЯШдЫааШчЯТУќСюЃЌРДМрПиаДШыЕН TenMinPsgCnts topic
жаЕФЪ§ОнЃК
| docker-compose
exec sql-client /opt/kafka-client/bin/kafka-console-consumer.sh
--bootstrap-server kafka:9092 --topic TenMinPsgCnts
--from-beginning |
УП10ЗжжгЕФДюГЫЕФГЫПЭЪ§ПЩвдЪЙгУ Tumbling Window РДУшЪіЃЌЮвУЧЪЙгУ INSERT INTO
Sink_TenMinPsgCnts РДжБНгНЋ Query НсЙћаДШыЕННсЙћБэЁЃ
INSERT INTO Sink_TenMinPsgCnts
SELECT
TUMBLE_START(rideTime, INTERVAL '10' MINUTE) AS
cntStart,
TUMBLE_END(rideTime, INTERVAL '10' MINUTE) AS
cntEnd,
CAST(SUM(psgCnt) AS BIGINT) AS cnt
FROM Rides
GROUP BY TUMBLE(rideTime, INTERVAL '10' MINUTE);
|
ЮвУЧПЩвдМрПиЕН TenMinPsgCnts topic ЕФЪ§Онвд JSON ЕФаЮЪНаДШыЕНСЫ Kafka
жаЃК
ЪЕР§5ЃКНЋ Update СїаДШы ElasticSearch
зюКѓЮвУЧЪЕМљвЛЯТНЋвЛИіГжајИќаТЕФ Update СїаДШы ElasticSearch жаЁЃЮвУЧЯЃЭћНЋЁАУПИіЧјгђГіЗЂЕФааГЕЪ§ЁБЃЌаДШыЕН
ES жаЁЃ
ЮвУЧвВвбОдЄЖЈвхКУСЫвЛеХ Sink_AreaCnts ЕФ ElasticSearch НсЙћБэЃЈtraining-config.yaml
жагаЭъећЕФБэЖЈвхЃЉЁЃИУБэжажЛгаСНИізжЖЮ areaId КЭ cntЁЃ
ЭЌбљЕФЃЌЮвУЧвВЪЙгУ INSERT INTO НЋ Query НсЙћжБНгаДШыЕН Sink_AreaCnts
БэжаЁЃ
INSERT INTO Sink_AreaCnts
SELECT toAreaId(lon, lat) AS areaId, COUNT(*)
AS cnt
FROM Rides
WHERE isStart
GROUP BY toAreaId(lon, lat); |
дк SQL CLI жажДааЩЯЪі Query КѓЃЌElasticsearch ЛсздЖЏЕиДДНЈ area-cnts
Ыїв§ЁЃElasticsearch ЬсЙЉСЫвЛИі REST API ЁЃЮвУЧПЩвдЗУЮЪ
ВщПДarea-cntsЫїв§ЕФЯъЯИаХЯЂЃК http://localhost:9200/area-cnts
ВщПДarea-cntsЫїв§ЕФЭГМЦаХЯЂЃК http://localhost:9200/area-cnts/_stats
ЗЕЛиarea-cntsЫїв§ЕФФкШнЃКhttp://localhost:9200/area-cnts/_search
ЯдЪО ЧјПщ 49791 ЕФааГЕЪ§ЃКhttp://localhost:9200/area-cnts/_search?q=areaId:49791
ЫцзХ Query ЕФвЛжБдЫааЃЌФувВПЩвдЙлВьЕНвЛаЉЭГМЦжЕЃЈ_all.primaries.docs.count,
_all.primaries.docs.deletedЃЉдкВЛЖЯЕФдіГЄЃКhttp://localhost:9200/area-cnts/_stats
змНс
БОЮФДјДѓМвЪЙгУ Docker Compose ПьЫйЩЯЪж Flink SQL ЕФБрГЬЃЌВЂЖдБШ Window
Aggregate КЭ Group Aggregate ЕФЧјБ№ЃЌвдМАетСНжжРраЭЕФзївЕШчКЮаДШыЕН ЭтВПЯЕЭГжаЁЃИааЫШЄЕФЭЌбЇЃЌПЩвдЛљгкетИі
Docker ЛЗОГИќМгЩюШыЕиШЅЪЕМљЃЌР§ШчдЫааздМКаДЕФ UDF , UDTF, UDAFЁЃВщбЏФкжУЕиЦфЫћдДБэЕШЕШЁЃ |








