| БрМЭЦМі: |
БОЮФЯЕЭГадЕиЯђФњНщЩмСЫЪ§ОнЦНЬЈЕФФЃаЭЁЂЛёШЁФЃЪНЁЂЛёШЁв§ЧцЗўЮёЁЂЪ§ОнКўМДЗўЮёЁЂвдМАЪ§ОнКўЕФЙІгУгыНјЛЏЁЃЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгк51CTOЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
вЛЬсЕНЦѓвЕЪ§ОнЦНЬЈЃЌШЫУЧЭљЭљЯыЕНЕФЪЧИїжжЪ§ОнФПТМНсЙЙЁЂЪ§ОнжЪСПМрПиЁЂCI/CDЁЂвдМАЪ§ОнУёжїЙЋжкЛЏ(Data
DemocratizationЃЌМДЃКЬсЙЉЪ§ОнВщбЏЕФЙЋЙВЧўЕР)ЕШЗНУцЁЃЫќУЧдкТњзугУЛЇЕФЖрдЊЛЏашЧѓгыЬхбщЕФЭЌЪБЃЌВЛЖЯЭЈЙ§КЯРэЕФМмЙЙЁЂвдМАИпаЇЕФЗжМ№ЪжЖЮЃЌРДГжајЬсИпЦфздЩэЕФжЪСПКЭЪЙгУМлжЕЁЃВЛЙ§ЃЌЮвУЧдкЪ§ОнЛёШЁЁЂЙ§ТЫЁЂвдМАЗжЮіЛЗНкЃЌЭљЭљЛсЪмЕНвђЫиЕФЯожЦЃК
1.ЭХЖгГЩдБЕФжЊЪЖДЂБИЁЃ
2.дкдЦЗўЮёжаЕФЪЙгУаЇТЪЁЃ
3.гыЯжгавЕЮёКЭВњЦЗЕФМЏГЩЖШЁЃ
4.змЬхДІжУЕФГЩБОЁЃ

здЖЈвхЕФЪ§ОнЛёШЁв§Чц
ЛљгкЩЯЪіПМТЧЃЌЦѓвЕдкДюНЈгыМЏГЩЪ§ОнЦНЬЈЪБЃЌЭљЭљЛсвдПЊдДММЪѕзїЮЊЦНЬЈЕФКЫаФЃЌвдСїЪНКЭХњДІРэЕФЗНЪНЬсЙЉЪ§ОнЗўЮёЃЌВЂЪдЭМНЋЪ§ОнЗўЮёВугыЪ§ОнГжОУЛЏв§ЧцНјааНтёюЁЃЕБШЛЃЌЫћУЧвВПЩвдвЛЙЩФдЕиНЋетаЉШЮЮёНЛИјжюШчЃКBigQueryЁЂRedshiftЁЂвдМАSnowflakeЕШдіжЕЗўЮёЬсЙЉЩЬЁЂМАЦфЬиЖЈВњЦЗРДЪЕЯжЁЃ

Ъ§ОнЦНЬЈМмЙЙЕФЪОР§
Ъ§ОнФЃаЭ(гђЧ§ЖЏЩшМЦ)
ЫЕЕНЪ§ОнЦНЬЈЃЌЫќЭљЭљашвЊШЋОжадЕФЪ§ОнФЃаЭЖЈвхЁЃФПЧАЃЌаэЖрЦѓвЕЁЂЬиБ№ЪЧвЛаЉММЪѕРраЭЕФЙЋЫОЃЌЖМЛсВЩгУгђЧ§ЖЏЩшМЦ(Domain
Driven DesignЃЌDDD)ЕФЗНЗЈЁЃИУЗНЗЈЭЈГЃЛсЩцМАЕНШчЯТЗНУцЃК
ЩњВњеп(producers)КЭЯћЗбеп(consumers)ЁЃЦфжаЃЌЯћЗбепгђЪЧгЩРДздЖрИіЩњВњепгђЕФЪ§ОнзщКЯЖјГЩЁЃ
ЬиЖЈЕФЪ§ОнПЩвдгЕгавЛИіжїгђКЭвЛИіИЈгђЁЃ
Ъ§ОнгђЕФзщжЏНсЙЙВЂЗЧвЛГЩВЛБфЃЌПЩФмЛсГіЯжИќИФЁЂКЯВЂЁЂбнЛЏЁЂвдМАвЦГ§ЁЃ
дкЪ§ОнгђДІжУЗНУцЃЌЮвУЧГЃгУЕФЗНЗЈЪЧзёбздЕзЯђЩЯЕФЩшМЦддђЁЃетвтЮЖзХЃКДгЩњВњепЕФЪ§ОнгђПЊЪМЃЌЪ§ОнВњЦЗНЋБЛЪгЮЊздМКЕФЯћЗбепНјааЙЙНЈЁЃвђДЫЃЌЪ§ОнЦНЬЈашвЊЮЊЫќУЧЬсЙЉЫљгаБивЊЕФЙЄОпЁЂЗўЮёЁЂжЇГжЁЂБъзМЛЏСїГЬЁЂвдМАМЏГЩЁЃ
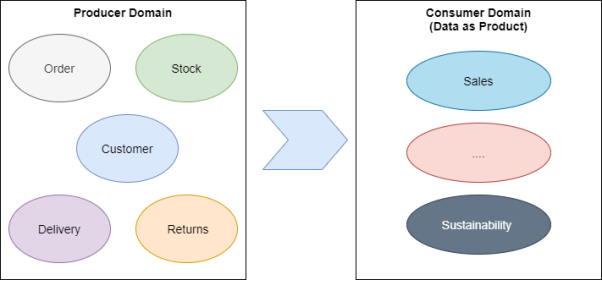
ДгЩњВњепгђЕНЯћЗбепгђ(Ъ§ОнМДВњЦЗ)
ЯњЪлгђЪЧЯћЗбепЪ§ОнгђЕФвЛИіМЋЦфГЃМћЕФР§згЃЌЕБШЛвВЪЧЗЧГЃИДдгЕФЁЃдкФЧаЉгЕгаЖрЧўЕРЖЉЕЅ(ШчЃКЕчзгЩЬЮёЁЂЩчНЛУНЬхЁЂЪЕЬхЕъЕШ)ЕФДѓЙЋЫОжаЃЌЧўЕРКЭВПУХжЎМфгаЙиЯњЪлЕФИХФюЫфШЛТдгаВЛЭЌЃЌЕЋЪЧЫќЭљЭљЪЧгЩФЧаЉРДздЖрИігђЕФЪ§ОнЫљзщГЩЁЃ
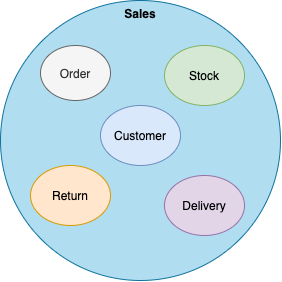
ЯњЪлгђ
Р§ШчЃКгЩгкУПИіЭХЖгЫљашвЊЕФЪ§ОнЁЂЪ§ОнЕФбщжЄЙ§ГЬЁЂвдМАКтСПжИБъгаЫљВЛЭЌЃЌвђДЫЕчЩЬВПУХКЭВЦЮёВПУХЕФЯњЪлЪ§ОнВњЦЗОЭПЩФмВЛвЛбљЁЃ
Ъ§ОнЕФЛёШЁФЃЪН
жкЫљжмжЊЃЌЪ§ОнЦНЬЈзюОпМлжЕЕФзЪдДБуЪЧЪ§ОнЁЃЭЌЪБЃЌЪ§ОнвВЪЧзюЮЊИДдгЕФЁЃЮвУЧЭЈГЃгаСНжжЩЯДЋЪ§ОнЕФЗНЪНЃК
РЪН(Pull)ЃККЫаФЭХЖгЛљгкМЏжаЪНЕФЙмРэЃЌЭЈЙ§ПЊЗЂЪ§ОнЙмЕРЃЌНЋЪ§Онв§ШыЦНЬЈжаЁЃВЛЙ§ЃЌгЩгкзюГѕЯЪЩйгагыЦфЫћЭХЖгЕФвРРЕЙиЯЕЃЌвђДЫИУЗНЗЈБШНЯгааЇ;ЕЋЪЧЕНСЫКѓЦкЃЌдђПЩФмЯнШыЦПОБЁЃ
ЭЦЪН(Push)ЃКЫќЖдгкдЫгЊЁЂМмЙЙКЭЗЖЪНРДЫЕЪЧОјКУЕФЗНЗЈЃЌЕЋВЛвЛЖЈЪЪКЯЦфЫћЭХЖгЁЃР§ШчЃЌЗжЯњЭХЖгдкЗжЮіЯњЪлЪ§ОнЪБЃЌашвЊЯњЪлЭХЖгНЋЫћУЧЕФЪ§ОнЭЦЫЭЕНЪ§ОнЦНЬЈжаЁЃЖјгЩгкЯњЪлЭХЖгвЕЮёЗБУІЃЌЖјЧветВЂВЛЪЧЫћУЧЕФЪзвЊШЮЮёЃЌвђДЫЗжЯњЭХЖгПЩФмЛсЕШД§НЯГЄЕФЪБМфЁЃ
ПЩМћЃЌЁАЭЦЪНЁБЗНЗЈЫфКУЃЌЕЋЪЧаэЖрЙЋЫОЭљЭљгазХИїжжвХСєЯТРДЕФЯЕЭГЃЌвджСгкЭХЖгЮоЗЈМАЪБзМБИКУЪЪКЯЭЦЫЭЕФЪ§ОнЁЃЖјЭЈЙ§ЬсЙЉЁАРЪНЁБЗНЗЈЃЌЮвУЧдђПЩвдПЊЗЂздЖЏЛЏЕФЪ§ОнЛёШЁв§ЧцЗўЮёЁЃ
ЪВУДЪЧЪ§ОнЛёШЁв§ЧцЗўЮё(Data Ingestion Engine Service)?
змЕФЫЕРДЃЌЫќЪЧвЛИіЮоашДњТыЃЌжЛашИїжжSQLгяОфКЭгГЩфЃЌМДПЩДДНЈETLСїГЬКЭЪ§ОнСїГЬЕФзджњЗўЮёЦНЬЈЁЃЦфФПБъЪЧЭЈЙ§ЬсЙЉЖржжЗчИёЃЌРДКИЧШчЯТЗНУцЃК
дЪаэЭХЖгздааНЋЪ§ОнЭЦЫЭЕННЛЛЛЧјЁЃ
ЬсЙЉвЛИіМЏжаЪНЕФКЫаФЭХЖгЃЌЮЊЗЧММЪѕЭХЖгЩЯДЋЪ§ОнЁЃ
ЭЈЙ§ЬсЙЉзджњЗўЮёЦНЬЈЃЌРДМђЛЏММЪѕЭХЖгЕФЪ§ОнЛёШЁЙ§ГЬЁЃ
ШчЙћЮвУЧЖдЫљгаРраЭЕФЪ§ОнЛёШЁЙмЕРЃЌЖМВЩШЁЯрЭЌЕФЗНЗЈЃЌНЋЛсгЕгавЛећЬзздЖЏЛЏЕФСЌНгЦїЃЌПЩЗНБуЭХЖгЭЦЫЭЫћУЧЕФИїжжЪ§ОнЁЃР§ШчЃКБфИќЪ§ОнЕФВЖЛёЃЌИїРрЪТМўЁЂОЕЯёЁЂвдМАЮФМўЕШЁЃвВОЭЪЧЫЕЃЌЭЈЙ§ЮЊВњЦЗЫљгаепЙЙНЈПЩгУгкЪ§ОнЭЦЫЭЕФЭЈгУзщМўЃЌЮвУЧНЋФмЙЛЪЕЯжздЖЏЛЏЕФЛёШЁВуЁЃ
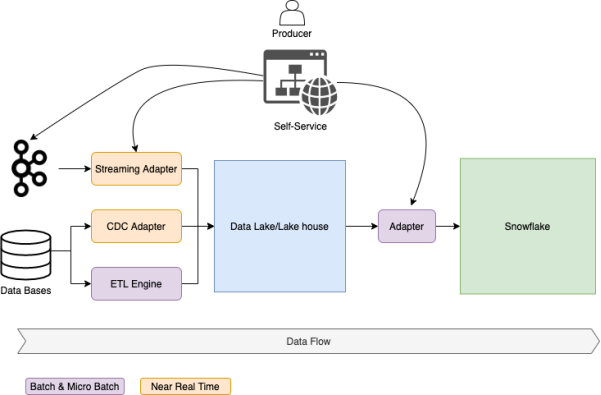
ХњДІРэЕФЪ§ОнСї
ШчЩЯЭМЫљЪОЃЌЮвУЧБиаыЬсЙЉИїжжЙЄОпКЭБъзМЛЏЕФСїГЬ(АќРЈЃКЪ§ОнЛёШЁгыжЪСППижЦЕШ)ЃЌвддЪаэЩњВњепНЋЫћУЧЕФЪ§ОнЃЌЭЈЙ§WebУХЛЇЛђGitOpsЕШздЖЏЛЏЕФЗНЪНЃЌЭЦЫЭЕНЪ§ОнЦНЬЈЩЯЁЃ
ЯТУцЃЌЮвУЧНЋжиЕуЬжТлШчКЮПЊЗЂвЛИіЛёШЁв§ЧцЁЃ
ЮЂЗўЮёМмЙЙжЎЭЦЫЭ
ЪТМўЧ§ЖЏаЭЕФЮЂЗўЮёМмЙЙЃЌЪЧБЛгІгУЕНЛљгкЪ§ОнСїЕФЁАЭЦЫЭВпТд(Push Strategy)ЁБЕФзюМбГЁОАжЎвЛЁЃДЫРрМмЙЙЭЈГЃЪЧЛљгкжюШчApache
KafkaЕШГжОУадЕФЯћЯЂДЋЕнЯЕЭГЃЌВЂзёбЕФЪЧЁАЗЂВМ-ЖЉдФ(publish-subscribe)ЁБЕФЭЈаХФЃЪНЁЃ
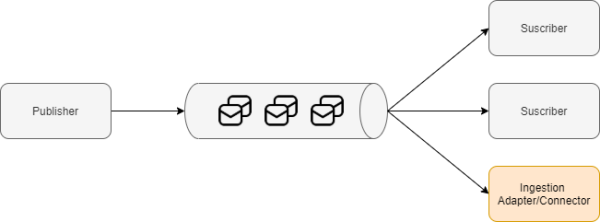
ЮЂЗўЮёМмЙЙФЃЪН
ШчЩЯЭМЫљЪОЃЌетжжФЃЪНЬсЙЉСЫвЛжжПЩРЉеЙЕФЁЂЫЩЩЂёюКЯЕФМмЙЙЃЌМДЃК
ЗЂВМепЯђжїЬт(topic)ЗЂЫЭвЛЬѕЯћЯЂЁЃ
ЫљгавбзЂВсИУжїЬтЕФЖЉдФепЖМЛсЪеЕНДЫЯћЯЂЃЌвВОЭЪЕЯжСЫЃКЪТМўБЛвЛДЮВњЩњЃЌЖрДЮЯћЗбЕФаЇЙћЁЃ
гЩгкЗЂВМепКЭЖЉдФепжЎМфВЂЮовРРЕЙиЯЕЃЌвђДЫЫћУЧЕФВйзї??ПЩвдБЫДЫЖРСЂЁЃ
ЮвУЧПЩвдЭЈЙ§ЬсЙЉБъзМЛЏЕФЛёШЁСЌНгЦїЃЌРДЖЉдФДЫРржїЬтЃЌВЂНЋИїжжЪТМўвдНќКѕЪЕЪБЕФЗНЪНЃЌЛёШЁЕНЮвУЧЕФЪ§ОнЦНЬЈЁЃЕБШЛЃЌДЫРрМмЙЙдкаХЯЂЗЖЮЇЗНУцЛсДцдкзХШчЯТШБЯнЃК
гЩгкГжОУаджїЬтЭЈГЃОпгаЛљгкЪБМфЛђДѓаЁЕФЯожЦЃЌвђДЫдкГіЯжДэЮѓЪБЃЌЦфжиаТДІРэЕФЙ§ГЬНЯЮЊИДдгЁЃ
ВЛОпБИжиаТЗЂЫЭРњЪЗЪ§ОнЕФСїГЬЁЃ
ВЛЬсЙЉеыЖдИїжжКЃСПГЁОАЕФвьВНЪ§ОнжЪСПадAPIЁЃ
Ъ§ОнКў(Data Lake)
дкДцДЂгыЗжЮідЪМЪ§ОнЃЌвдМАЛњЦїбЇЯАЛЗОГжаЃЌвВОЭВњЩњСЫЪ§ОнКўЕФИХФюЁЃЫќЪЧвЛжжЛљгкЖдЯѓДцДЂЕФЪ§ОнДцДЂПтЃЌФмЙЛЗНБуЮвУЧНјааШчЯТДцДЂЃК
РДздЙиЯЕаЭЪ§ОнПтЕФНсЙЙЛЏЪ§ОнЁЃ
РДздNoSQLЛђЦфЫћРДдД(ШчЃКCSVЁЂXMLЁЂJSONЕШ)ЕФАыНсЙЙЛЏЪ§ОнЁЃ
ЗЧНсЙЙЛЏЪ§ОнКЭЖўНјжЦЪ§Он(ШчЃКЮФЕЕЁЂЪгЦЕЁЂЭМЯёЕШ)ЁЃ
ФПЧАЃЌдЦДцДЂЗўЮёМШФмЙЛЮЊЦЕЗБЕїгУЕФЪ§ОнЬсЙЉИпадФмгыЕЭбгГйЕФДІРэФмСІЃЌгжФмЙЛЮЊЗЧЦЕЗБЕїгУЕФЪ§ОнЬсЙЉЕЭГЩБОЕФДѓШнСПДцДЂПеМфЁЃвђДЫЃЌЮвУЧПЩвдЭЈЙ§бЁгУAzure
Data Lake Storage Gen2ЃЌРДЮЊдЦЖдЯѓЕФДцДЂЬсЙЉШчЯТЙІФмЃК
ОэЃКПЩвдЙмРэКЃСПЪ§ОнЁЂPBМЖаХЯЂЁЂвдМАЧЇезЮЛ(gigabits)ЕФЭЬЭТСПЁЃ
адФмЃКеыЖдИїжжД§ЗжЮіЕФгУР§НјаагХЛЏЁЃ
АВШЋадЃКдЪаэЖдФПТМЛђЕЅИіЮФМўЩшжУPOSIX(ПЩвЦжВВйзїЯЕЭГНгПкЃЌPortable Operating
System Interface)ШЈЯоЁЃМДЃКЪЙгУЗўЮёжїЬхКЭOAuth2.0ЃЌНЋAzure Data
Lake Storage Gen2ЕФЮФМўЯЕЭГЙвдиЕНDBFS(Ъ§ОнПтЮФМўЯЕЭГ)ЩЯЁЃ
ЪТМўЃКзїЮЊвЛжжЗўЮёЃЌПЩвдЮЊУПИіжДааВйзї(ШчЃКДДНЈКЭЩОГ§ЮФМў)здЖЏЩњГЩвЛИіЪТМўЁЃЭЈЙ§етаЉЪТМўЃЌЮвУЧПЩвдЩшМЦЪТМўЧ§ЖЏЕФЪ§ОнСїГЬЁЃ
ЮвУЧашвЊИљОнгУЛЇЕФЪЕМЪашЧѓКЭгУР§зіЕНЃК
ЬсЙЉЖдгкЪ§ОнЕФжЛЖСЗУЮЪШЈЯоЃЌвдБуШУЪ§ОнКўГЩЮЊЫљгагУЛЇЕФЪ§ОнРДдДЃЌвдМАЕЅвЛЕФЪ§ОнДцДЂПтЁЃ
НсЙЙЛЏЪ§ОнКЭАыНсЙЙЛЏЪ§ОнФмЙЛЭЈЙ§жюШчDelta LakeЕФДцДЂПтЃЌвдСаЕФИёЪНДцДЂЁЃ
ШУЪ§ОнФмЙЛАДеевЕЮёгђНјааЗжЧјДцДЂЃЌВЂЗжВМдкЖрИіЖдЯѓДцДЂжаЁЃ
ЬсЙЉHiveЕФMetastoreЗўЮёЃЌВЂЭЈЙ§ЪЙгУИїжжЭтВПБэЬсЙЉspark-SQLЕФЗУЮЪЁЃетНЋдЪаэгУЛЇДгЪ§ОнЕФЮяРэЮЛжУжаГщЯѓГіРДЃЌВЂгЕгаЪ§ОнЕФЕЅЖРОЕЯёЁЃ
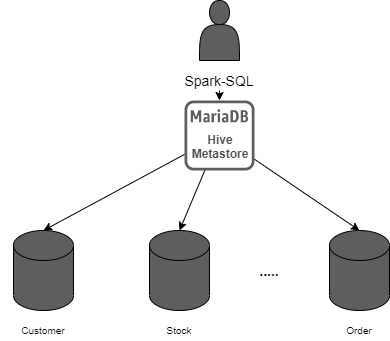
Spark-SQLСїОMariaDB
ШчЩЯЭМЫљЪОЃЌЮвУЧПЩвдЪЙгУЭтВППЊдДАцБОЕФHive MetastoreЃЌЖјЗЧОпгаМЏГЩЯожЦЕФЙЉгІЩЬЙмРэЗўЮёЃЌРДздгЩЕиМЏГЩШЮКЮSparkЦНЬЈЛЗОГ(ШчЃКDatabricksЁЂClouderaЕШ)ЁЃ
Spark-SQLКЭHiveMetastore
Spark-SQLЮЊЮвУЧЬсЙЉСЫвЛИіЗжВМЪНЕФВщбЏв§ЧцЃЌвдЗНБуЮвУЧвдИќЮЊгХЛЏЕФЗНЪНЪЙгУНсЙЙЛЏгыАыНсЙЙЛЏЪ§ОнЃЌВЂЪЙгУРрЫЦгкЪ§ОнФПТМЕФHive
MetastoreЁЃЭЈЙ§SQLЃЌЮвУЧПЩвдДгШчЯТЮЛжУВщбЏЕНЪ§ОнЃК
Ъ§ОнжЁКЭЪ§ОнМЏAPIЁЃ
ЭтВПЙЄОпЃЌШчDatabricks NotebooksБуЪЧвЛИігУЛЇгбКУЕФЙЄОпЁЃЫќФмЙЛажњЗЧММЪѕгУЛЇШЅЯћЗбЪ§ОнЁЃ
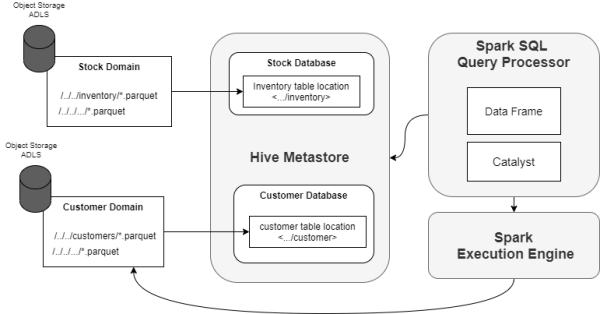
Spark-SQLКЭHiveMetastoreЕФСїГЬ
Ъ§ОнКўМДЗўЮё(Data Lake as a Service)
ЛљгкЩЯЪіРэТлгыжЊЪЖЛљДЁЃЌЮвУЧПЩвдЩшМЦКЭЙЙНЈГіОпгаШчЯТЬиеїЕФЪ§ОнКўЦНЬЈЃК
ЦфЪ§ОнЛёШЁв§ЧцИКд№ЛёШЁЪ§ОнЃЌДДНЈКЭЙмРэдкHive MetastoreЕФдЊЪ§ОнЁЃ
ЦфКЫаФЪЧгЩЖдЯѓДцДЂВуКЭHive MetastoreСНИіжївЊзщМўЙЙГЩЃЌЫќУЧЬсЙЉСЫМЦЫуВуМДЗўЮё(compute
layer as a service)ЁЃ
ЦфжаЕФМЦЫуВуЪЧгЩМЏГЩЕНЪ§ОнКўжаЕФЖрИіSparksШКМЏзщГЩЁЃЫќУЧЭЈЙ§ИїжжSparkзївЕЁЂSQLAnalyticsЛђDatabrick
NotebookРДЗУЮЪЪ§ОнЁЃ
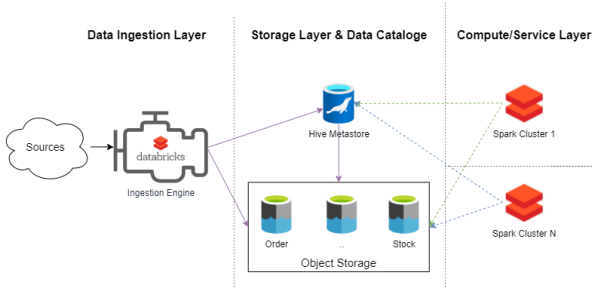
Ъ§ОнКўМДЗўЮёЕФМмЙЙ
Ъ§ОнКўЦНЬЈМДЗўЮёЪЧвЛжжЖЏЬЌЧвПЩРЉеЙЕФМЦЫугыЗўЮёВуФмСІЁЃЦфжаЃЌзїЮЊКЫаФЕФSparkМЏШКЪЧЪ§ОнКўЦНЬЈЕФзюаЁЗўЮёФПТМЁЃЮвУЧМШПЩвдДДНЈвЛИі7x24ЕФгРОУадМЏШКЃЌгжПЩвдДДНЈвЛИіСйЪБЕФЙЄзїМЏШКЁЃР§ШчЃЌШєЯыЮЊЪ§ОнВњЦЗЭХЖгЬсЙЉЩГКаЗжЮіЗўЮёЃЌЮвУЧПЩвдЮЊУПИіГЩдБЖМДДНЈвЛИіАќКЌгаЯрЭЌЪ§ОнЃЌЕЋБЫДЫИєРыЕФМЦЫуЛЗОГЁЃЖдДЫЃЌЮвУЧашвЊЪЕЯжЃК
ИљОнSparkММЪѕЃЌРДЖЈвхзщГЩЩГЯфЗжЮіЕФзщМўЁЃ
ЭЈЙ§WebЗўЮёФПТМЁЂЛђДњТыЗНЪН(Шчgit-ops)ЃЌЬсЙЉзджњЪНЕФЗўЮёЙІФмЁЃ
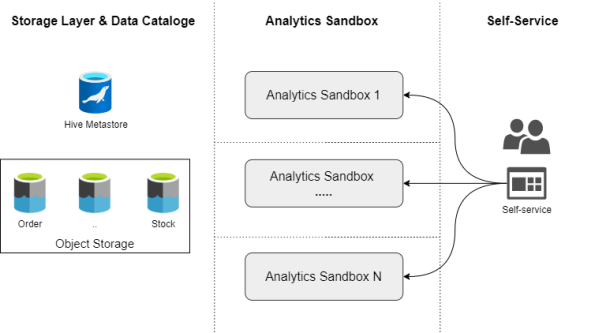
зджњЪНЕФЗўЮёВу
ЕБШЛЃЌЩЯЭМжЛЪЧвЛИіЗЧГЃМђЕЅЛЏЕФЪгЭМЃЌЦфжаВЂУЛгаЖЈвхАВШЋадЁЂИпПЩгУадЁЂвдМАЪ§ОнжЪСПЕФЯрЙиЗўЮёЁЃ
Ъ§ОнКўФмЙЛЬсЙЉЪВУД?
ШчЯТЭМЫљЪОЃЌзїЮЊвЛИіПЊдДВуЃЌЪ§ОнКўЬсЙЉСЫACIDЙІФмЃЌВЂШЗБЃгУЛЇФмЙЛПДЕНвЛжТадЕФЪ§ОнЁЃИїжжЪ§ОнЙмЕРПЩвдБЛгУРДЫЂаТЪ§ОнЃЌЕЋВЛЛсгАЯье§дкдЫаажаЕФSparkЙ§ГЬЁЃ
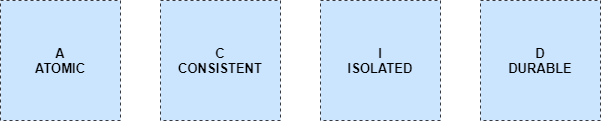
ACIDЃКдзгадЁЂвЛжТадЁЂИєРыадЁЂГжОУад
ЦфЫћживЊЕФЙІФмЛЙАќРЈЃК
Schemaon-writeЃКЫќдкаДШыЪ§ОнЪБЧПжЦжДааФЃЪНМьВщЃЌШчЙћМьВтЕНФЃЪНВЛЦЅХфЃЌдђЗЕЛизївЕЪЇАмЁЃ
SchemaEvolutionЃКЫќжЇГжжюШчЬэМгаТЕФСаЕШЃЌеыЖдМцШнадЗНАИЕФФЃЪННјЛЏЁЃ
Time travelЃКЪ§ОнАцБОПижЦПЩЗНБуЮвУЧНЋЪ§ОнзїЮЊДњТыНјааЙмРэЁЃдкДњТыДцДЂПтжаЃЌгУЛЇФмЙЛШУЪ§ОнМЏЕФУПДЮИќИФЃЌЖМЛсдкЦфећИіЩњУќжмЦкжаЩњГЩаТЕФЪ§ОнАцБОЁЃ
MergeЃКжЇГжКЯВЂЁЂИќаТКЭЩОГ§ВйзїЃЌвдЪЕЯжИДдгЕФЪ§ОнЛёШЁГЁОАЁЃ
Ъ§ОнКўЕФНјЛЏ
ШчЯТЭМЫљЪОЃЌДЋЭГЕФЪ§ОнКўЁЂЪ§ОнВжПтЁЂвдМАЪ§ОнжааФ(Hub)жЎМфгазХИХФюадКЭММЪѕадЕФЧјБ№ЁЃ

Ъ§ОнКўЁЂЪ§ОнжааФЁЂЪ§ОнВжПтЭМБэ
Apache HudiЮЊДЋЭГЕФЁЂЛљгкHadoopЁЂSparkЁЂParquetЁЂHiveЕШЪ§ОнКўММЪѕЩњЬЌЃЌЬэМгСЫаТЕФЪЕгУЙІФмЁЃЦфжаАќРЈЃКНЋМЦЫуКЭДцДЂВуНјааМмЙЙЩЯЕФНтёюЁЂЮоЗўЮёЦїЛЏЁЂSQLЗжЮіЁЂDelta
EngineЁЂвдМАDatabricksЕШаТвЛДњЕФЪ§ОнКўЦНЬЈЁЃЖјИљОнDatabricksЕФРэТлЃЌLake
HouseПЩвдБЛРэНтЮЊаТвЛДњЁЂИќЮЊГЩЪьЕФЪ§ОнКўЁЃЫќАќКЌСЫШчЯТСНИіВПЗжЃК
Ъ§ОнжааФ
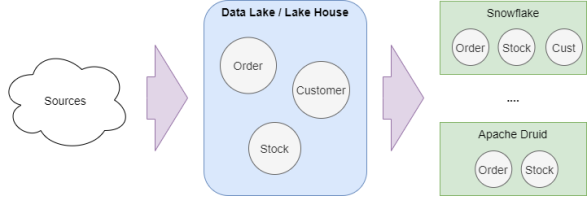
Ъ§ОнжааФСїГЬЭМ
гУгкЬиЖЈЛђМђЛЏГЁОАЕФЪ§ОнВжПт
Ъ§ОнВжПтСїГЬЭМ
ФПЧАЃЌЫцзХЪ§ОнВжПтЕФФмСІЕУЕНСЫДѓЗљЬсЩ§ЃЌжюШчSnowflakeЁЂBigqueryЁЂвдМАOracle
Autonomous Data WarehouseЕШММЪѕВњЦЗЃЌдкЪ§ОнЗжЗЂЕШЗНУцЖМБэЯжГіСЫВЛЫзЕФадФмЁЃ
аЁНс
змЕФЫЕРДЃЌНсКЯСЫKafkaЕШЪТМўжааФЕФаТвЛДњЪ§ОнКўЃЌЪЧЮвУЧЙЙНЈЪ§ОнЦНЬЈКЫаФЕФгХЯШбЁдёЁЃЫќзїЮЊвЛЯюГЩЪьЕФММЪѕЃЌВЛЕЋПЊдДЁЂГжајНјЛЏЃЌЖјЧвОпгаМЋОпОКељСІЕФадМлБШЁЃЮвУЧПЩвдНЋЦфВПЪ№ЕНИїжждЦЖЫЗўЮёЛЗОГжаЃЌвдИќКУЕиЗЂОђЪ§ОнЕФМлжЕЁЃ
|








