| БрМЭЦМі: |
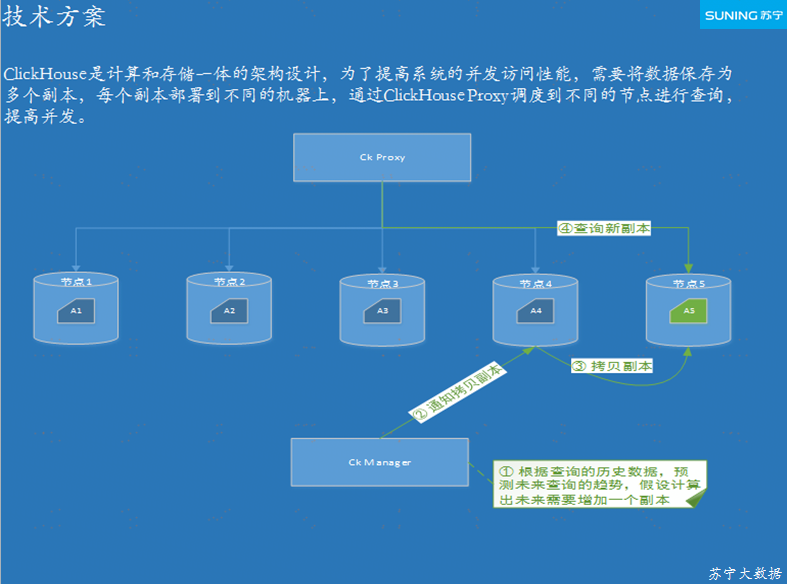
БОЮФжївЊНщЩмЫеФўШЋСДТЗМрПиЦНЬЈЩшМЦЃЌШчКЮНЋ
ClickHouse ФЩШыШЋСДТЗМрПиЦНЬЈЃЌClickHouse МЏШКзДЬЌМрПиЃЌШЋСДТЗМрПиЕФгХЪЦКЭеЙЭћЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкЫбКќЭјЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
МђНщ
ClickHouse ЪЧвЛПюгХауЕФ OLAP ЗжЮів§ЧцЃЌгШЦфЪЧдкЕЅБэЗжЮі ЁЂColocate Join
ЗНУцадФмБэЯжгШЮЊЭЛГіЁЃ
ClickHouse жЎЫљвддкжкЖрЕФ OLAP ЗжЮів§ЧцжаГЩЮЊйЎйЎепЃЌжївЊЪЧвђЮЊЫќОпБИвдЯТЬиЕуЃКСаЪНДцДЂЁЂLSM-Tree
ДцДЂв§ЧцЁЂЯђСПЛЏжДаав§ЧцЁЂвьВН Merge КЭ Mutation ЛњжЦЁЂВЂЗЂ MPP+ SMP ЕШЁЃ
ФПЧАЃЌClickHouse дкЫеФўДѓЪ§ОнЕФжИБъКЭБъЧЉЕФгІгУНЯЖрЃК
ДгММЪѕВуУцРДПДЃЌжївЊНтОіЕФГЁОАгаЃКИпЛљЪ§ЕФЪ§ОнЗжЮіЁЂОЋШЗШЅжиЁЂНЛЛЅЪНЗжЮіЁЂЖрБфФЃЪНВщбЏЁЂДѓПэБэЗжЮіЁЂЪБађЛЏЪ§ОнДцДЂЁЂЪЕЪБОлКЯЕФЮяЛЏЪгЭМЕШЃЛ
ДгвЕЮёВуУцРДПДЃЌжївЊгІгУЕФГЁОАгаЃКаТТђМвЁЂРЯТђМвЁЂИДЙКЁЂСєДцЁЂЪЕЪБгУЛЇЛЯёЁЂШЫШКАќШІбЁЕШЁЃЖјЛљгк ClickHouse
ЕФ RoaringBitmap ЗНАИЃЌБЃжЄСЫвдЩЯГЁОАЪ§ОнЗжЮіЕФЪЕЪБКЭИпаЇЁЃ
дк ClickHouse МрПиЗНУцЃЌФПЧАЪаУцЩЯЬсЙЉЕФПЩЪЪХфЗНАИВЛЖрЃЌГЃгУЕФга Prometheus
+Grafana+ ClickHouse_Exporter зщКЯЕФЗНЪНЃЌПЩЭЈЙ§ЬсЙЉЕФ Dashboards
РДМрПиМЏШКзДПіЃЌЕЋашвЊАВзА Prometheus КЭ ClickHouse_ExporterЃЌВЛБрвыЕФЛАЛЙашвЊАВзА
GO ЛЗОГКЭ DockerЃЌећИіПђМмЙ§жиЃЌГЩБОЙ§ИпЃЌЖдИіадЛЏЕФМрПивВВЛжЇГжЁЃЛЙгавЛаЉЦфЫћМрПизщМўШч
Graphite + GrafanaЃЌдкетРяОЭВЛзіНщЩмЁЃ
ЮвУЧНЋ ClickHouse ШкШыЫеФўШЋСДТЗМрПиЩњЬЌЬхЯЕЃЌдкЭъЩЦМрПиЬхЯЕЕФЭЌЪБЃЌвВжЇГХСЫИіадЛЏЕФМрПиЃЌНјвЛВНЭиеЙСЫШЋСДТЗМрПиЦНЬЈЕФЩюЖШКЭЙуЖШЁЃ
вЛЁЂЫеФўДѓЪ§ОнШЋСДТЗМрПиЦНЬЈ
1ЁЂЫеФўШЋСДТЗМрПиЦНЬЈНщЩм
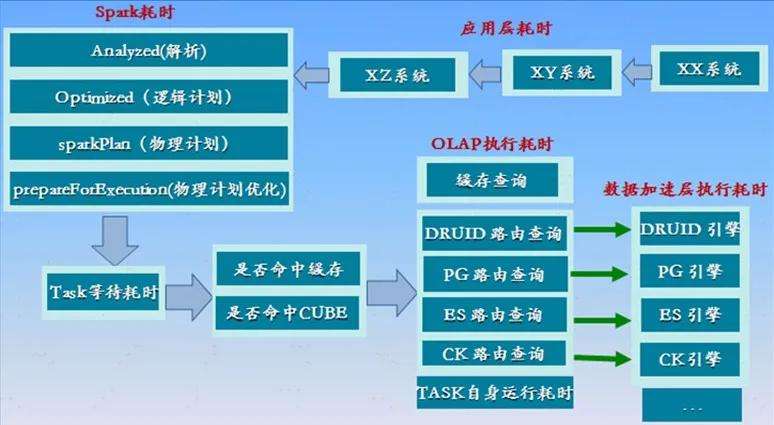
ЭМ 2-1 ШЋСДТЗМрПиМмЙЙ
ЫеФўДѓЪ§ОнжааФЪ§ОнжаЬЈгавЛећЬзЭъЩЦЕФжИБъНЈЩшЬхЯЕЃЌАќКЌСЫжИБъЩњУќжмЦкЙмРэЁЂжИБъЗжЮіЬхЯЕвдМАЪ§ОнПьЫйПЩЪгЛЏЦНЬЈЃЌЪ§ОнЗжЮіЪБПчдНПЩЪгЛЏЦНЬЈЁЂжИБъЗўЮёЦНЬЈМА
OLAP ЗжЮів§ЧцШ§ДѓЦНЬЈЃЌВщбЏСДТЗНЯГЄЁЃШчЙћУЛгавЛЬзЭъећЕФШЋСДТЗМрПиЗжЮіЦНЬЈЃЌЖдгкЖЈЮЛЮЪЬтЛсДцдкНЯДѓЕФРЇФбЁЃ
ШЋСДТЗМрПиећЬхЕФЩшМЦЫМЯыЪЧНЋвГУцЕФУПДЮ http ЧыЧѓЩњГЩЮЈвЛЕФСїЫЎКХ (serialId)ЃЌКѓајУПЗУЮЪвЛДЮжИБъЙмРэЯЕЭГЃЌЩњГЩЮЈвЛЕФ
traceIdЃЌУПДЮЕїгУ OLAP НгПкЩњГЩЮЈвЛЕФ olapIdЃЌетбљ 1 ИіСїЫЎКХЖдгІЖрИі traceIdЃЌЙиСЊЖдгІКѓајЖрИі
olapIdЃЌаЮГЩвЛИіЪїзДЧыЧѓЃЌвдДЫЕУЕНвЛИіЭъећЕФЧыЧѓСДТЗЁЃ
ОпЬхЩшМЦШчЯТЃК
БЈБэЩшМЦЯЕЭГКѓЖЫеыЖдБЈБэЧАЖЫЕФУПДЮЧыЧѓЩњГЩЮЈвЛ traceIdЃЌеыЖдЧыЧѓЕФУПвЛВНЩњГЩВуМЖЙиЯЕЕФ spanIdЃЌВЂЯђжИБъЙмРэЯЕЭГЭИДЋ
traceId КЭЖдгІЕФ spanIdЃЛ
жИБъЙмРэЯЕЭГНгЪмЧыЧѓКѓЃЌИљОнЪсРэЕФВщбЏШЈжиМЦЫуЗНЪНЩњГЩЁАВщбЏШЈжиЁБpriorityЃЌдкБЈБэЩшМЦЯЕЭГЕФ
spanId ЛљДЁЩЯМЬајЩњГЩЕїгУВуМЖЙиЯЕЕФ spanIdЃЌВЂЯђ OLAP ЭИДЋ traceId КЭЖдгІЕФ
spanIdЃЛ
Spark RDD ЪЕЯжНЋ DruidЁЂPostGreSQL КЭ ClickHouse жаЕФ queryId
гы Spark worker жаЕФ StageID вдМА JobID ЙиСЊЦ№РДЃЛ
OLAP НгЪмЧыЧѓКѓЃЌдкжИБъЙмРэЯЕЭГЕФ spanId ЛљДЁЩЯМЬајЩњГЩЕїгУВуМЖЙиЯЕЕФ spanIdЃЌВЂЯђ
OLAP в§ЧцВуЭИДЋ traceId КЭЖдгІЕФ spanIdЃЛ
OLAP ЗжЮів§ЧцВуЃЌЭЈЙ§ДђЭЈ traceId КЭИїздЗжЮів§ЧцжДааТЗОЖЕФЗНЪНЃЌЪЕЯжИњзйИїжДааМЦЛЎЁЂжДааТЗОЖЕФКФЪБЁЃР§ШчЃЌПЩЭЈЙ§
bigQueryId гы Druid ЙиСЊЃЌЖј PostGreSQL КЭ ClickHouse дђПЩвдЭЈЙ§
traceId гГЩфЕНв§ЧцФкВПЕФЗНЪННјааЙиСЊЁЃ
2ЁЂ ШчКЮНЋ ClickHouse ФЩШыШЋСДТЗМрПиЦНЬЈ
ClickHouse ШЋСДТЗМрПиИВИЧЗЖЮЇНЯЙуЃЌАќРЈЃКВщбЏЩцМАЕНЕФНкЕуЁЂЗжЦЌЁЂИИВщбЏКЭзгВщбЏЕФЙиЯЕЁЂдкИїИіНкЕуЕФВщбЏКФЪБЁЂЧыЧѓФкДцЪЙгУЁЂИпЗхЪЙгУФкДцЁЂCPU
ЪЙгУЪ§ЁЂВщбЏааЪ§ЁЂMergeTree ЪЙгУзДПіЁЂВщбЏЗНЪНЃЈTCP/HTTPЃЉвдМАВЮгыВщбЏЯпГЬЪ§ЕШЁЃ
дкЕїгУ ClickHouse ЬсЙЉЗўЮёВщбЏЃЈspark-jdbcЃЉЕФЪБКђЃЌШчКЮНЋ traceId
ЭИДЋИј ClickHouse ЕФ query_id Фи?
ЪЕЯжШЋСДТЗМрПиЃЌжївЊЪЧЭЈЙ§ traceId ЙсДЉећИіСДТЗЁЃБэ system.processes КЭБэ
system.query_log жаЕФ query_id ЪЧЫцЛњЩњГЩЕФЃЌClickHouse ЕФ query_id
жЇГжздЖЈвхЃЌПЩНЋздЖЈвхЕФ query_id гГЩфЕНЯЕЭГздЩњГЩЕФ query_id ЩЯЃЌетбљ ClickHouse
ФкВПЕФМрПиОЭФмгыШЋСДТЗДђЭЈЃЌОпЬхВйзїШчЯТЃК
ClickHouse-client --port 1***5 --time --format=Null
--query="select count() from aggr_member"
--query_id="suning20200706ЁА echo 'select count()
from aggr***member' | curl 'http://localhost:8**3/?query_id=suning2020&query='
--data-binary @-
ЖўЁЂClickHouse Т§ВщбЏМрПи
1ЁЂЪЕЪБТ§ВщбЏМрПи
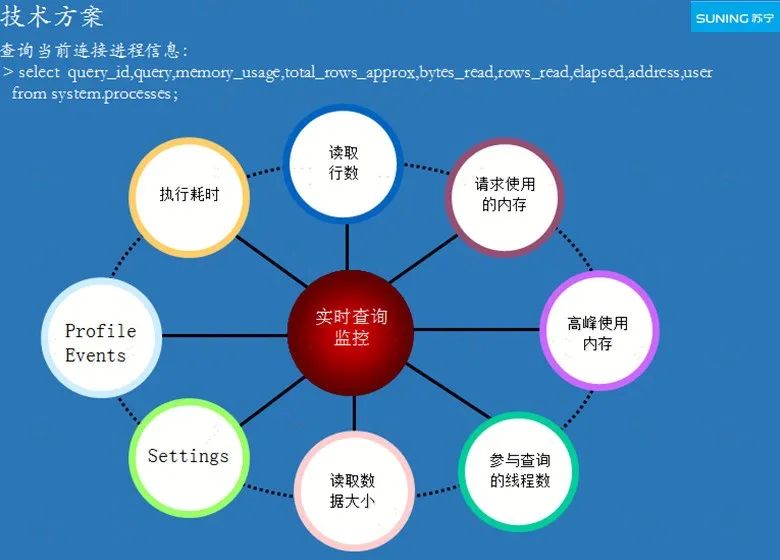
ЭМ 3-1 ЪЕЪБТ§ВщбЏМрПи
ИИНкЕуВщбЏ ID(initial_query_id) ЪЧДгЩЯгЮЯЕЭГДЋШыЕФ traceIdЃЌДЫДЮВщбЏЕФЫљгазгВщбЏОљПЩИљОн
traceId ЛёШЁЃЌПЩвдЪЕЪБЗжЮіФГДЮВщбЏдкМЏШКжаИїИіНкЕуЕФзДЬЌЃЌЦфжаАќРЈВщбЏ query_id ЕФИИзгЙиЯЕМАЖдгІЕФНкЕуаХЯЂЁЂИїИіНкЕуЕФВщбЏНХБОЁЂВщбЏКФЪБЁЂЖСШЁЕФааЪ§ЁЂЧыЧѓЪЙгУЕФФкДцЁЂИпЗхЪЙгУЕФФкДцЁЂВЮгыВщбЏЕФЯпГЬЪ§ЁЂuserЁЂProfileEventsЁЂSettings
ЕШЁЃ
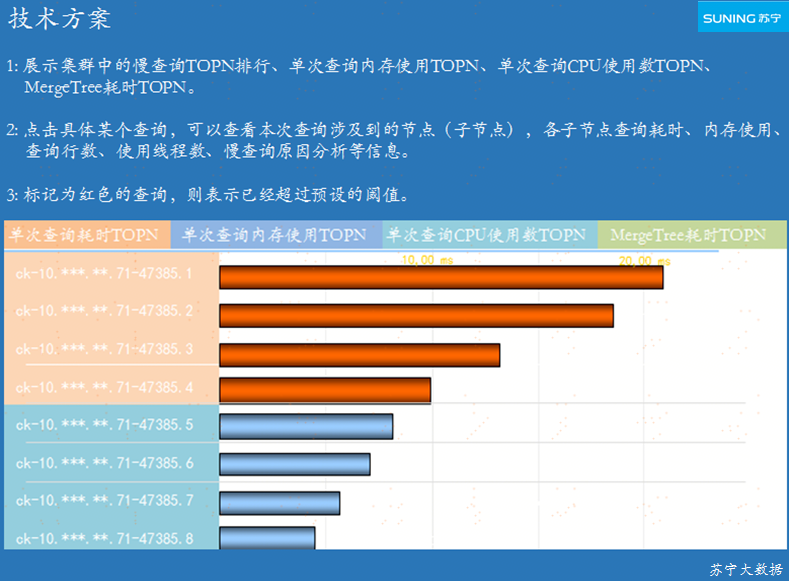
ЭМ 3-2 ЕЅДЮВщбЏФкДц /CPU/MergeTree/ КФЪБ TOPN МрПи
ЭМ 3-2 еЙЪОИїМЏШКжаЕФТ§ВщбЏ TOPNЁЂЕЅДЮВщбЏФкДцЪЙгУ TOPNЁЂЕЅДЮВщбЏ CPU ЪЙгУЪ§
TOPNЁЂMergeTree КФЪБ TOPNЃЌжЇГжЖдГЌЙ§дЄЦкуажЕЕФВщбЏНјааИцОЏЁЃ
2ЁЂРњЪЗТ§ВщбЏМрПи
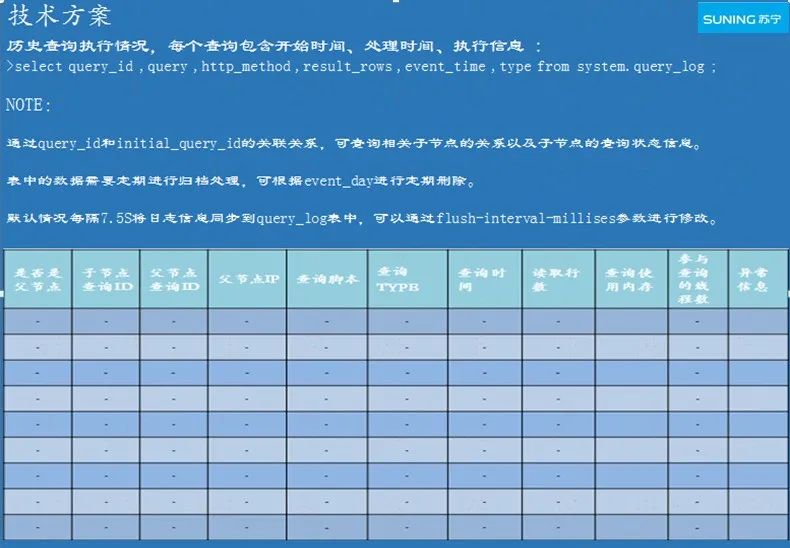
ЭМ 3-3 РњЪЗТ§ВщбЏМрПи
ClickHouse ФЌШЯЕФЧщПіЯТ query_log БэЪЧЮДПЊЦєЕФзДЬЌЃЌБиаыНЋЦфПЊЦєЃЌаоИФХфжУЮФМў
users.xmlЃЌТЗОЖЮЊ /etc/clickhouse-server/ЃЌаТдіХфжУЯю<log_queries>1</log_queries>ЃЌЕБВщбЏШежОЗўЮёЦїВЮЪ§log_queries=1
ЪБЃЌClickHouse ВХЛсДДНЈДЫБэЁЃ
УПИіВщбЏдк query_log БэжаЛсДДНЈвЛЬѕЛђСНЬѕМЧТМЃЌОпЬхШЁОігкВщбЏЕФзДЬЌЃК
ШчЙћВщбЏжДааГЩЙІЃЌдђЛсЗжБ№ДДНЈЪТМўРраЭЮЊ 1 КЭ 2 ЕФСНЬѕМЧТМЃЛ
ШчЙћдкВщбЏДІРэЦкМфЗЂЩњДэЮѓЃЌдђЛсЗжБ№ДДНЈЪТМўРраЭЮЊ 1 КЭ 4 ЕФСНЬѕМЧТМЃЛ
ШчЙћдкВщбЏЦєЖЏжЎЧАЗЂЩњДэЮѓЃЌдђЛсДДНЈЪТМўРраЭЮЊ 3 ЕФЕЅЬѕМЧТМЃЛ
Бэ query_log жаЕФМЧТМЃЌДцДЂЕФЪЧРњЪЗВщбЏдкМЏШКжаЕФИїИіНкЕуЕФзДЬЌЃЌЦфжаАќРЈВщбЏ query_id
ЕФИИзгЙиЯЕМАЖдгІЕФНкЕуаХЯЂЁЂИїИіНкЕуЕФВщбЏНХБОЁЂВщбЏПЊЪМЪБМфЁЂВщбЏШеЦкЁЂВщбЏЪБМфЁЂВщбЏКФЪБЁЂВщбЏааЪ§ЁЂВщбЏНсЙћЕФзжНкДѓаЁЁЂЧыЧѓЪЙгУЕФФкДцЁЂИпЗхЪЙгУЕФФкДцЁЂВЮгыВщбЏЕФЯпГЬЪ§ЁЂЖбеЛИњзйвдМАВщбЏвьГЃаХЯЂЕШЁЃ
3ЁЂMergeTree МрПи
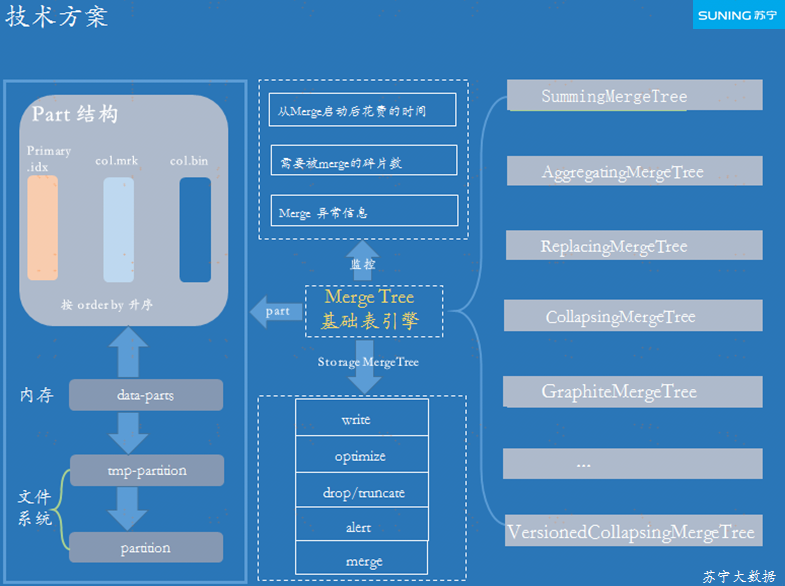
ЭМ 3-4 MergeTree ЛљДЁБэв§Чц
MergeTree БэжаЪ§ОнДцДЂдк Part жаЃЌЕБВхШыЪ§ОнЕФЪБКђЃЌЛсНЋЪ§ОнДДНЈдквЛИіаТЕФ Part
жаЃЌPart ЕФЪ§СПДњБэзХЬсНЛЕФЦЕТЪЁЃКѓЬЈЛсНјаавьВНЕФ Merge Й§ГЬЃЌНЋаЁЕФ Part НјааКЯВЂЃЌВЂЧвЛсЯрЖдОљКтЕФЦНКтКУКЯВЂЫйЖШКЭ
Part Ъ§СПЕФЙиЯЕЁЃ
ЖдгкУПИі Part ОљЛсЩњГЩвЛИіЫїв§ЮФМўЃЌЫїв§ЮФМўДцДЂЕФЪЧУПИіЫїв§ПщЪ§ОнжїМќЕФ value жЕЁЃЖдгк
MergeTree ЕФМрПиЃЌжївЊМрПи MergeTree ЕФвьГЃЧщПіЃЌИљОнвьГЃаХЯЂНјааИцОЏЁЃ
4ЁЂТ§ВщбЏЙщвђЗжЮі
ЭЈЙ§вдЩЯЕФМрПиЃЌПЩвдПьЫйЖЈЮЛГіТ§ВщбЏЁЃЕМжТТ§ВщбЏЕФдвђПЩФмгаКмЖрЃЌПЩвдДгШчЯТМИИіЗНУцНјааЗжЮіЃК
ХаЖЯВщбЏЕФЪ§ОнЪЧЗёДцдк page cache жаЃЌДг page cache ЛёШЁЪ§ОнЫйЖШдЖИпгкДХХЬЃЛ
ИпЛљЪ§ЕФОлКЯЛђХХађЖдВщбЏаЇТЪгАЯьНЯДѓЃЌJOIN ВйзїЪБгІНЋаЁБэЗХгвБпЃЌЗжЧјзжЖЮВЛвЫЙ§ЖрЃЌЕМШыЪ§ОнЪБКђзюКУЖдЪ§ОнНјааЪТЯШХХађЃЛ
гАЯьадФмзюЙиМќЕФжИБъЪЧ CPU КЭФкДцЃЌCPU ГЌЙ§ 70% дђПЩФмЛсГіЯжДѓЗЖЮЇЕФВщбЏГЌЪБЁЃСэЭташвЊЙиБеащФтФкДцЃЌЗёдђЮяРэФкДцКЭащФтФкДцПЩФмЛсНјааЪ§ОнНЛЛЛЃЌДгЖјЕМжТВщбЏБфТ§ЃЛClickHouse
ЖдИпВЂЗЂжЇГжВЛЬЋгбКУЃЌашвЊЖдЕЅИіВщбЏЕФзЪдДМгвдЯожЦЃЌЗёдђЛсгАЯьЕБЧАЦфЫќВщбЏЕФжДаааЇТЪЁЃ
вдЩЯЪЧГЃЙцЕФТ§ВщбЏдвђЗжЮіЃЌЖјгааЉИДдгЁЂИпЛљЪ§ЕФВщбЏПЩЭЈЙ§ЧЩУюЕФЩшМЦЗНЪНЃЌДяЕНИпаЇВщбЏЕФФПБъЁЃ
дкЛљгк ClickHouse МЦЫуЛсдБаТТђМвЁЂРЯТђМвЪ§ЁЂИДЙКЁЂСєДцЕШГЁОАЕФЪБКђЗЂЯжЃЌШчЙћгУЛсдБ ID
Нјаа HASH ЗжЦЌКѓдйзі RoaringBitmap МЦЫуЃЌзюКѓдйНЋУПИіЗжЦЌЕФМЦЫуНсЙћЛузмЃЌЦфжДаааЇТЪНЋЬсИпЪ§БЖЁЃ
СэЭтдкМЦЫуДПаТТђМвКЭДЮаТТђМвЕФЪБКђЃЌЭЈЙ§дкзгВщбЏжаЪЙгУ ClickHouse-CTE ЕФ WITH
ЗНЪНЃЌЭЌбљПЩвдДяЕНЪЕЪБЁЂИпаЇЕФВщбЏФПБъЁЃ
Ш§ЁЂClickHouse МЏШКзДЬЌМрПи
1ЁЂМЏШКЁЂНкЕузДЬЌМрПи
ПЩЖдМЏШКЁЂНкЕуЕФВщбЏзДЬЌНјааМрПиЃЌШчГЩЙІДЮЪ§ЁЂвьГЃДЮЪ§КЭЪЇАмДЮЪ§ЃЌВЂЧвИљОнЩшЖЈЕФуажЕЖдЪЇАмЛђГЌЪБЕФВщбЏНјаадЄОЏЁЃ
ЭЌЪБПЩЖдИїИіНкЕуЕФСЌНгЪ§ЁЂCPU ЪЙгУТЪЁЂФкДцЪЙгУТЪЁЂFileOpenЁЂИљЗжЧјЪЙгУТЪвдМАзюДѓЗжЧјЪЙгУТЪНјааМрПиЁЃ
2ЁЂМЏШКЁЂНкЕуЁЂЗжЦЌ QPS КЭСЌНгЪ§МрПи
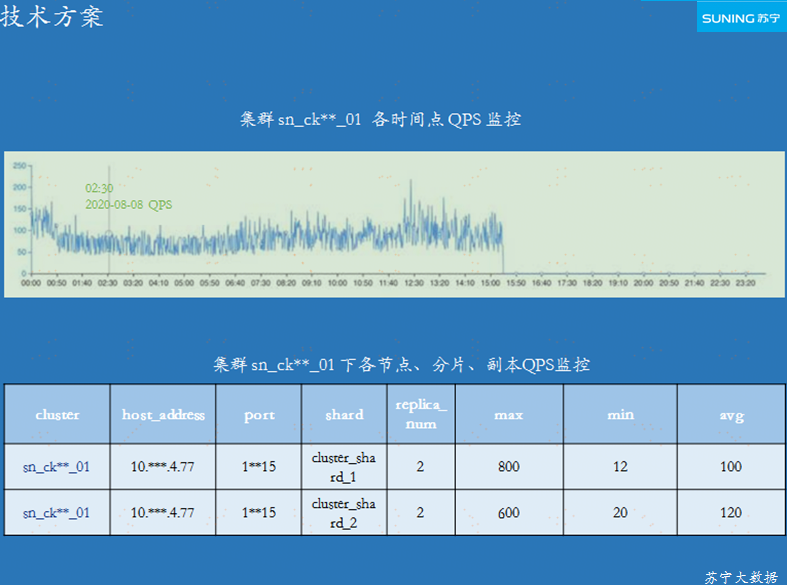
ЭМ 4-1 МЏШКЁЂНкЕуЁЂЗжЦЌ QPS МрПи
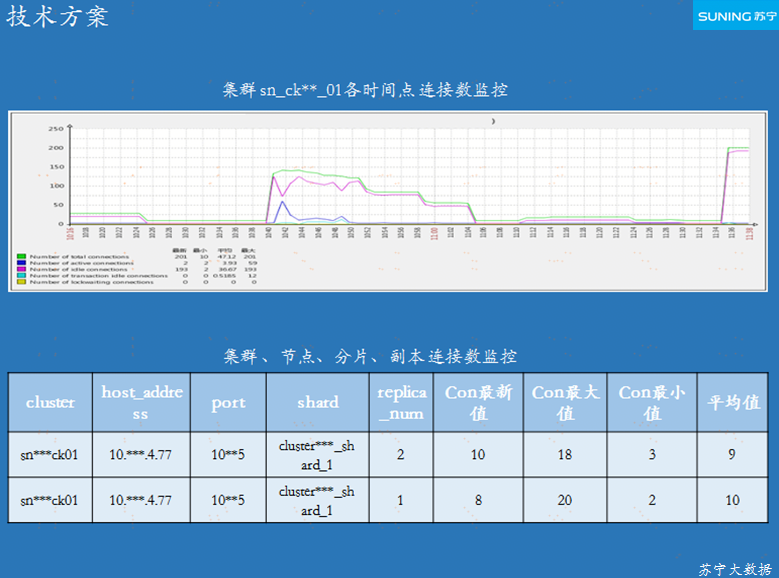
ЭМ 4-2 МЏШКЁЂНкЕуЁЂЗжЦЌСЌНгЪ§МрПи
ClickHouse ЕФМЦЫуКЭДцДЂЪЧвЛЬхЪНЕФЃЌВЂЮДзізЪдДИєРыЃЌЮЊСЫЬсИпЯЕЭГЕФВЂЗЂФмСІЃЌПЩвдНЋЪ§ОнБЃДцЮЊЖрИіИББОЃЌУПИіИББОВПЪ№ЕНВЛЭЌЕФНкЕуЩЯЃЌдйЭЈЙ§
Chproxy ТЗгЩЕНВЛЭЌЕФНкЕуНјааВщбЏЁЃ
ЮЊСЫБЃжЄМЏШКЕФГжајЮШЖЈЁЂПЩгУЃЌашвЊЖдЕЅИіВщбЏЕФзЪдДвдМАМЏШКзюДѓжЇГжЕФВЂЗЂНјааЯожЦЃЌОпЬхЗНЪНШчЯТЃК
МЏШКЭЌЪБжЇГжЕФзюДѓВЂЗЂСЌНгЪ§ПЩЭЈЙ§ Max_Concurrent_queries РДЩшжУЃЌФЌШЯЮЊ
100ЃЛ
вЛИіВщбЏдкЕЅЬЈЗўЮёЩЯзюДѓЪЙгУЕФФкДцПЩЭЈЙ§ Max_memory_usage РДЩшжУЃЛ
ЕЅИіНкЕуЩЯЫљгаВщбЏЕФзюДѓФкДцЯожЦЪЧПЩЭЈЙ§ Max_memory_usage_for_all_queries
РДЩшжУЃЛ
ЕЅДЮВщбЏЕФзюГЄжДааЪБМфПЩЭЈЙ§ Max_execution_time РДЩшжУЁЃ
3ЁЂМЏШКЁЂНкЕуЁЂЗжЦЌПЩгУадМрПи
ОпЬхПЩвдЭЈЙ§ HTTP API МрЪгЗўЮёЦїЕФПЩгУадРДЪЕЯжЁЃЭЈЙ§ HTTP GET ЧыЧѓКѓЃЌШчЙћЗўЮёЦїПЩгУЃЌдђЗЕЛи
200 OKЃЌЗёдђЗЕЛивьГЃЯћЯЂЁЃ
ДЫДІашвЊгаИіИцОЏХфжУМрПиЯюЃЌвЛЕЉМрВтЕННкЕуВЛПЩгУЃЌПЩМАЪБЭЈжЊЯрЙиММЪѕШЫдБНјааЮЌЛЄЃЌЦфжаИцОЏаХЯЂПЩЭЈЙ§ЖЬаХЁЂгЪМўЕШЗНЪННјааЭЦЫЭЁЃ
4ЁЂШЋСДТЗ Replicas Delay МрПи
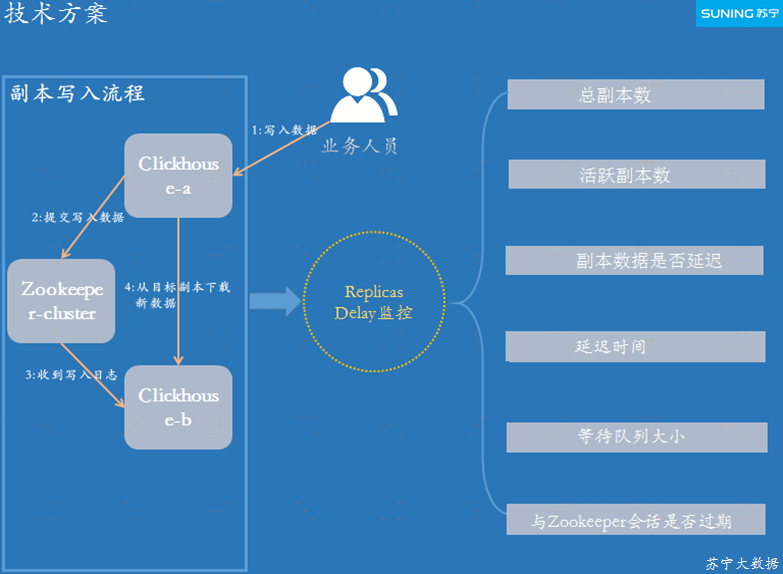
ЭМ 4-3 Replicas Delay МрПи
Random ЗжВМЪНЫцЛњбЁШЁИББОгаЫФжжЫуЗЈЃК
RandomЃКбЁШЁИББОЕФФЌШЯЗНЪНЃЌИУЫуЗЈжївЊЪЧЭЈЙ§МЦЫуИББОЕФДэЮѓЪ§СПЃЌВщбЏЗЂЫЭЕНГіДэзюЩйЕФИББОЃЌЕЋетжжЫуЗЈУЛгаПМТЧЕНЗўЮёНкЕуЪЧЗёЯрСкЕФГЁОАЃЛ
In orderЃКбЁШЁИББОЕФЗНЪНЪЧИљОнХфжУжажИЖЈЕФЫГађЃЛ
First or randomЃКбЁдёМЏКЯжаЕквЛИіИББОЃЌШчЙћЕквЛИіИББОВЛПЩгУЃЌдђЫцЛњНјааИББОбЁдёЃЛ
Nearest hostnameЃКУПИє 5 ЗжжгМЦЫуИББОЕФДэЮѓЪ§СПЃЌШчЙћИББОЕФДэЮѓЪ§СПзюЩйЃЌдђНЋВщбЏЗЂЫЭИјЫќЁЃ
ИББОдЪаэЕФзюГЄбгГйЪБМфЃЌПЩЭЈЙ§ВЮЪ§ max_replica_delay_for_distributed_queries
РДЩшжУЃЛИББОЕФбгГйЪБМфЃЌПЩвдЪЙгУ HTTP resource /replicas-delay РДВщбЏЃЌВЛбгГйдђЗЕЛи
200 OKЃЌбгГйдђЗЕЛиКЭФЌШЯЪБМфЕФВюОрЁЃ
5ЁЂШЋСДТЗ Chproxy МрПиаХЯЂ
ЭМ 4-4 ClickHouse Manger ЙЄзїСїГЬ
ClickHouse ЕФ Http ДњРэКЭИКдиОљКтЦїЪЧ ChproxyЃЌЫеФўЭЈЙ§ ClickHouse
Manger РДЙмРэ Chproxy зщМўЕФЦєЖЏЁЂЭЃжЙЁЂЙіЖЏЩ§МЖвдМАМрПиЃЌВЂЭЈЙ§ ZK Яђ Chproxy
ЭЌВНХфжУЪ§ОнЁЃ
ClickHouse МЏШКПЩвдВПЪ№ЖрИі Chproxy ЪЕР§ЃЌПЭЛЇЖЫСЌНг ClickHouse МЏШКЕФДњРэЗўЮёКѓЃЌЭЈЙ§ЖдВщбЏ
SQL НтЮіЃЌжЧФмЕФНјааИКдиОљКтЁЃЭЌЪБЃЌChproxy вВжЇГжЫЎЦНРЉеЙЁЃ
Chproxy ФмМрПиЕНЕФжиЕужИБъгаЃКМЏШКЧыЧѓЖгСаДѓаЁЁЂдЖГЬПЭЛЇЖЫСЌНгЪ§ЁЂВщбЏзмЧыЧѓЪ§ЁЂШЁЯћЧыЧѓЪ§ЁЂБЛОмОјЧыЧѓЪ§ЁЂЛКДцУќжаЧщПіЁЂМЏШККЭНкЕуНЁПЕзДЬЌЕШЃЌЫеФўШЋСДТЗМрПиЦНЬЈПЩЖдЩЯЪіжиЕужИБъНјааМрПиЁЃ
ЫФЁЂШЋСДТЗМрПиЕФгХЪЦКЭеЙЭћ
ШЋСДТЗМрПиЦНЬЈЭиеЙСЫЮвУЧМрПиЯЕЭГФмСІЕФЩюЖШКЭЙуЖШЃЌЭЌЪБЮЊ ClickHouse ЕФзЪдДИєРыКЭЗўЮёЛЏЬсЙЉСЫВЮПМЁЃ
ШЋСДТЗМрПиЦНЬЈФПЧАвбОНЋЪ§ОнгІгУВуЁЂSparkSQL НтЮіВуЁЂOLAP ТЗгЩМгЫйВувдМАЪ§ОнМгЫйВуШЋВПЙсДЉЃЌгУЛЇЗЂЦ№ЕФЧыЧѓдкИїИіНзЖЮЕФКФЪБвЛФПСЫШЛЁЃ
ЮвУЧФмАбИїИі OLAP ЗжЮів§ЧцФкВПжДааЕФКФЪБЃЌЭЈЙ§ЭГвЛЕФ queryId ФЩШыЕНЫеФўШЋСДТЗМрПиЦНЬЈЃЌаЮГЩвЛЬѕЭъећЕФжДааКФЪБМрПиСДТЗЁЃИїНзЖЮдЄЩшЕФГЌЪБдЄОЏЃЌЛсдкЕквЛЪБМфЭЈжЊЯрЙид№ШЮШЫЃЌетжжЗНЪНЖдЮЪЬтЖЈЮЛЁЂжїЖЏдЄОЏЖМЦ№ЕНСЫживЊЕФзїгУЃЌЭЌЪБИјМрПидЫЮЌДјРДСЫМЋДѓЕФБуРћЁЃ
дк OLAP ТЗгЩВуЃЌЮвУЧвбОЖдНгСЫ DruidЁЂElasticsearchЁЂPostGreSQL
вдМА ClickHouse ЗжЮів§ЧцЃЌКѓајЮвУЧНЋЖдНгЦфЫќИќЖрЕФ OLAP ЗжЮів§ЧцЃЌШч DorisЁЂDremio
КЭ RocksDB ЕШЃЌЭЌЪБЮвУЧвВНЋГжајЯИЛЏЁЂЗжЮіИїв§ЧцФкВПжДааНзЖЮЕФКФЪБЧщПіЃЌЖдШЋСДТЗМрПиФмСІНјааИќНјвЛВНЕФгХЛЏЬсЩ§ЁЃ
|








