| БрМЭЦМі: |
БОЮФжївЊНщЩмЭјвзЕФДѓЪ§ОнгІгУЯжзДЃЌДѓЪ§ОнЙмПиЦНЬЈЕФЯжзДвдМАЭЈгУЕФДѓЪ§ОнЗўЮёдЫЮЌПђМмЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкДѓЪ§ОнЦНЬЈ ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|

ИїЮЛSACCЙлжкЃЌДѓМвКУЃЌИааЛИїЮЛВЮМгБОДЮжЧФмдЫЮЌЪЕМљЛсГЁЕФзюКѓвЛГЁЗжЯэЛсЁЃЫуЪЧбЙжсГіГЁАЩЃЌвВЯЃЭћБОДЮЕФЗжЯэФмИјДѓМвДјРДвЛаЉЪЕгУЕФИЩЛѕЃЌЬиБ№ЪЧЖдгкгажиЙЙЗўЮёЦНЬЈашЧѓЕФХѓгбЁЃ
ШчЙћдкЗжЯэЙ§ГЬжагаШЮКЮЮЪЬтЃЌДѓМвПЩвдЯШдкЦРТлРИжаСєбдЃЌдкЪТКѓЕФQAЛЗНкЛсЮЊДѓМвЭГвЛзіНтД№ЁЃ

ЮвБОДЮЕФЗжЯэЕФФкШнАќРЈвдЯТМИИіВПЗжЃК
ЪзЯШЃЌНщЩмЭјвзЕФДѓЪ§ОнгІгУЯжзДЃЛ
ЦфДЮЃЌЫЕУїЯТЭјвзДѓЪ§ОнЙмПиЦНЬЈЕФЯжзДЃЌФкВПднЖЈЕФУћГЦЪЧEasyOpsЁЃШЁЪЙгУЗНБуСщЛюжЎвтЃЛ
дйепЃЌНщЩмЭЈгУЕФДѓЪ§ОнЗўЮёдЫЮЌПђМмЃЛ
ШЛКѓЃЌЫЕУїЛљгкPrometheusЬзМўЕФЭЈгУЕФДѓЪ§ОнМрПиБЈОЏЪЕЯжЃЛ
зюКѓЃЌДѓЪ§ОнЦНЬЈдЫЮЌЪЕеНОбщЗжЯэЁЃ

етРяСаОйСЫФПЧАЮвУЧЕФДѓЪ§ОнЦНЬЈжЇГХЕФЛЅСЊЭјВњЦЗОиеѓЃЌДѓЭЗжївЊЪЧдЦвєРжЁЂбЯбЁет2ИіЃЌЭЌЪБФкВПЛЙгаЦфЫћД§ЗѕЛЏЕФВњЦЗЯпЃЌетРяОЭВЛзіОйР§СЫЁЃ

ЦНЬЈЪЙгУЕФММЪѕеЛЕзВуЪЧHadoopЩњЬЌЯЕЭГЃЌДѓИХга22ЖрИізщМўЃЛжаЬЈЪЧЭјвзздбаЕФгаЪ§ЃЌДѓИХ27ИізщМўЁЃЮвУЧРыЯпМЏШКЗжЮЊ6ИіЃЌДЫЭтЪЕЪБМЏШКвВга2ИіжївЊЪЧдЫааsparkstreamingЛђflinkзївЕЁЃ
етРяЪЧЮвУЧгаЪ§жаЬЈЕФвЛаЉЙІФмФЃПщЃЌОпЬхЕФЪЙгУЕФНщЩметРяВЛзіеЙПЊЃЌгааЫШЄЕФХѓгбЧыЙизЂЭјвзгаЪ§ЙЋжкКХЃЌеыЖдИїИіФЃПщЖМгаЯъЯИЕФЮФеТНщЩмЁЃ

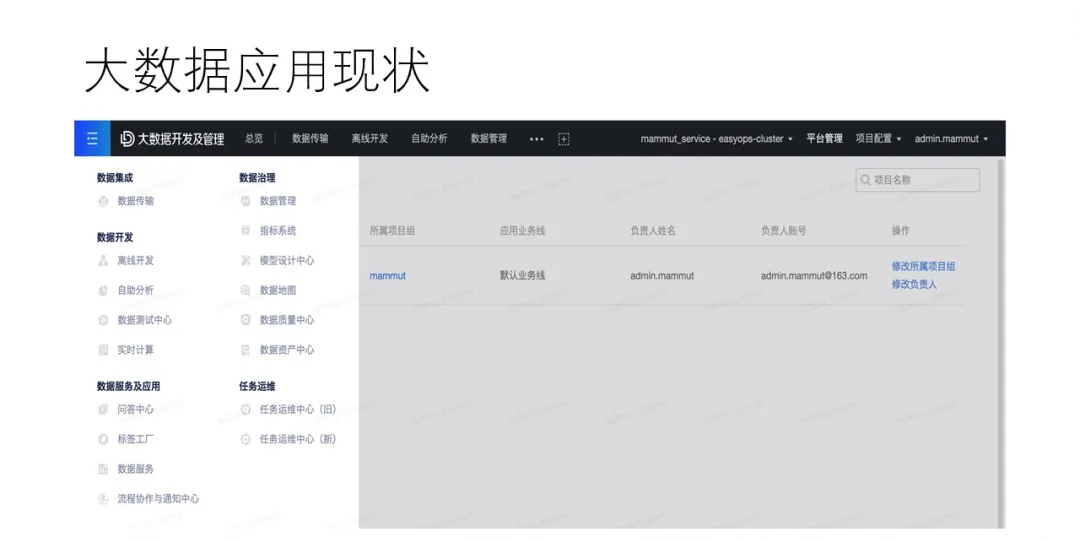
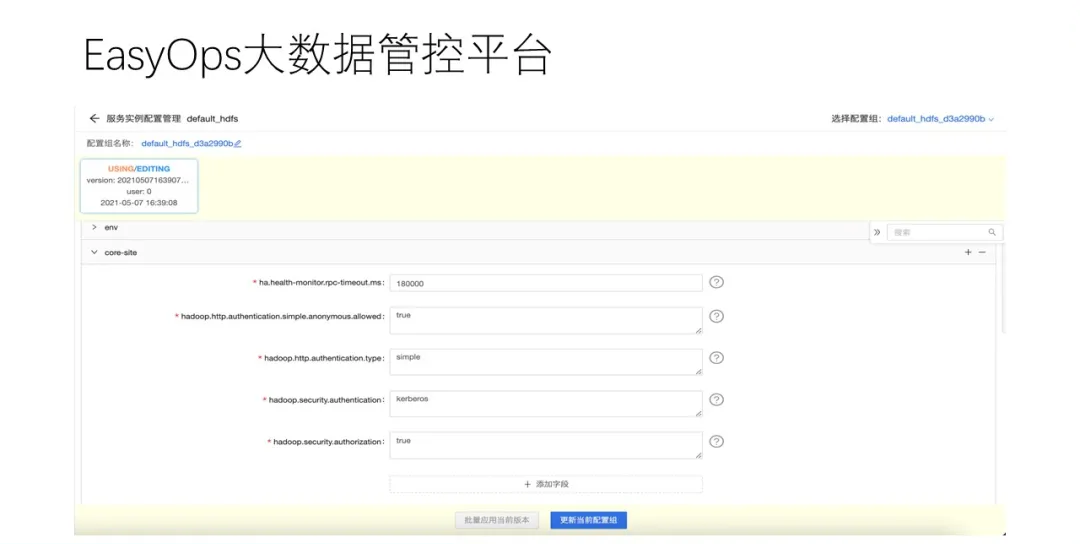
НгЯТРДЃЌНщЩмЯТЮвУЧЪЙгУЕФДѓЪ§ОнЙмПиЦНЬЈEasyOpsЁЃжЎЫљвдвЊжиаТзівЛЬзЙмПиЙЄОпЃЌЪЧвђЮЊЮвУЧдкЪЙгУПЊдДЕФAmbariЯЕЭГРДВПЪ№КЭЙмРэДѓЪ§ОнЦНЬЈЪБЃЌгіЕНСЫЕФИїРрЮЪЬтЁЃаТЕФЙмПиЦНЬЈОЭЪЧвЊНтОіетаЉЮЪЬтЃЌЕБШЛетвВЪЧвЛИіж№НЅЕќДњЕФЙ§ГЬЃЌВЛЛсЪЧвЛѕэЖјОЭЕФЪТЧщЁЃ
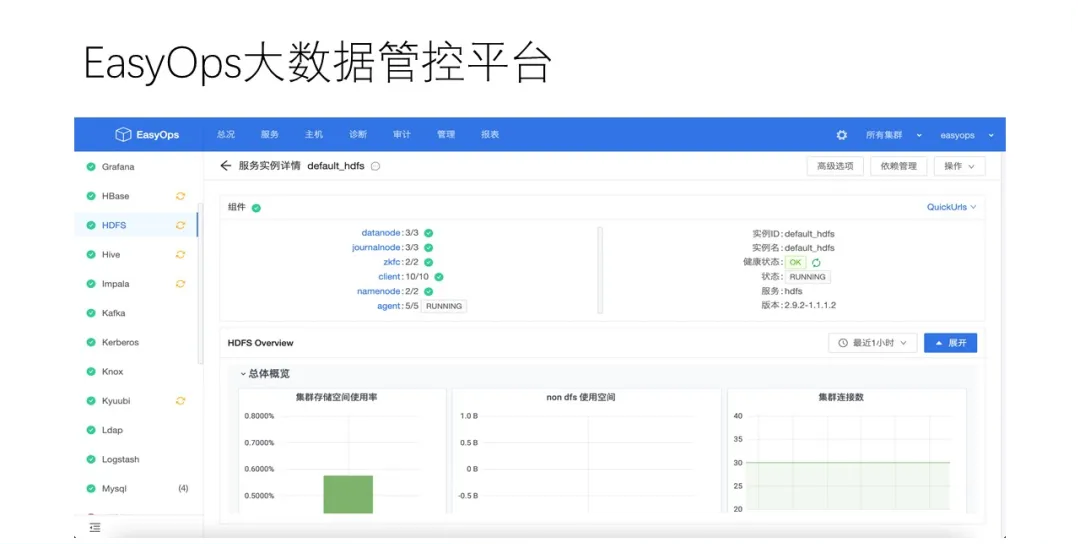
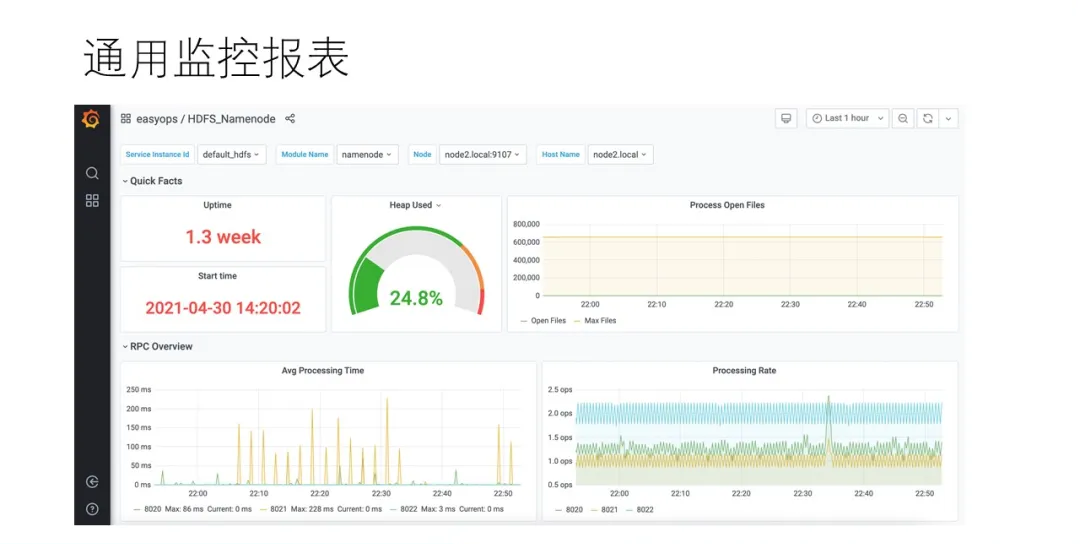
етвГЪЧEasyOpsЙмПиЦНЬЈЙигкHDFSЗўЮёЕФвЛИіЪЕР§ЕФЯъЧщвГУцЃЌетРяАќРЈСЫИУЪЕР§ЫљЪєЕФИїРрзщМўКЭНкЕуЁЃзѓВрЪЧЫљгаЕФЗўЮёСаБэЃЌгвВрЪЧЗўЮёЯъЧщЃЌЩЯЗНЪЧЙигкЗўЮёЕФвЛИіИХвЊБЈБэЁЃ
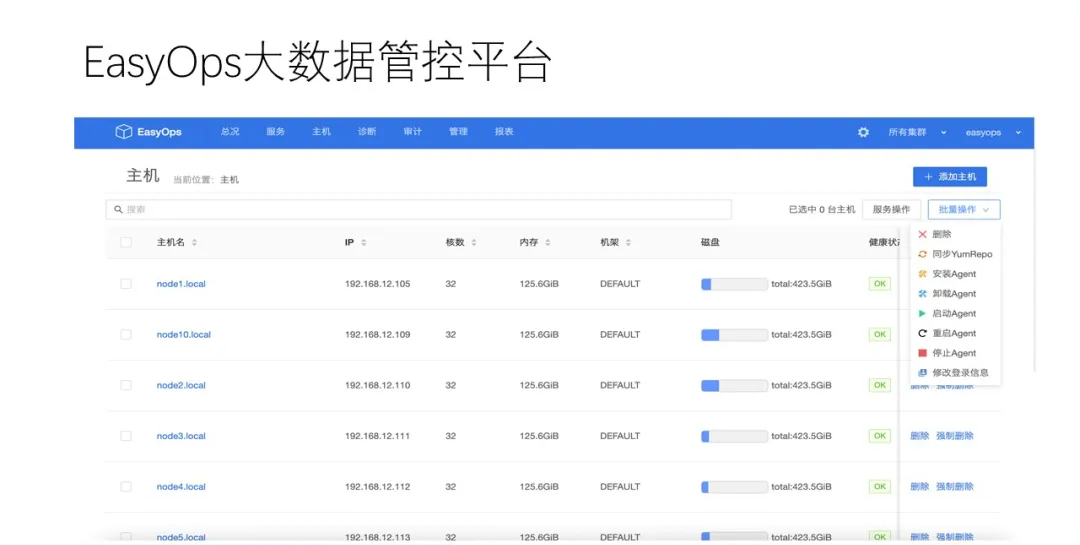
НгЯТРДЪЧЙмПиЦНЬЈЕФжїЛњвГУцЃЌЮвУЧПЩвдПДЕННгШыЕФЫљгажїЛњЃЌШЛКѓЪЧжїЛњжЇГжЕФШєИЩВйзїЁЃ
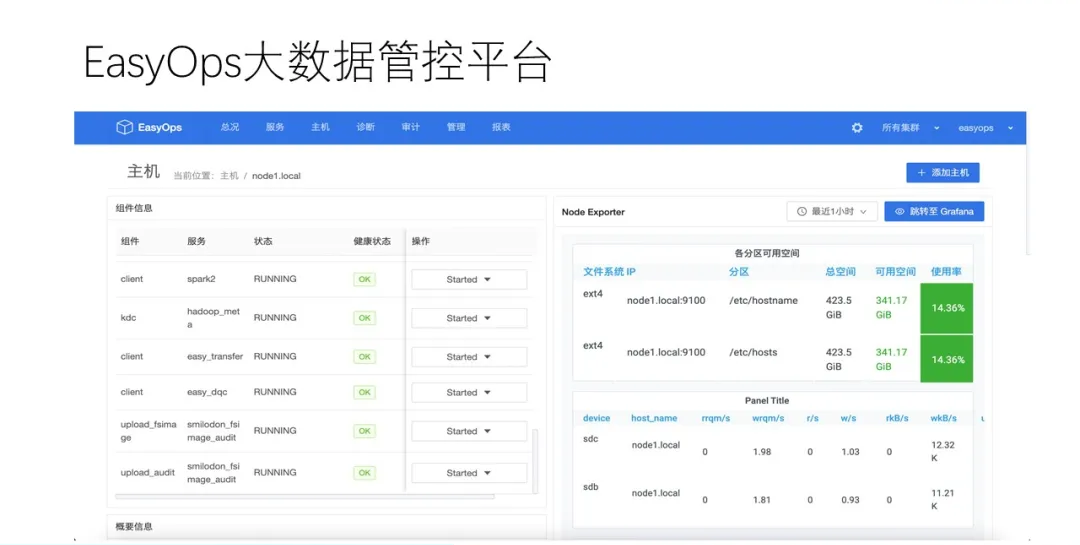
етИіЪЧжїЛњЕФЯъЧщвГЃЌетРяПЩвдПДЕНетЬЈжїЛњЩЯАВзАЕФЫљгаЗўЮёКЭзщМўЃЌАќРЈжїЛњБОЩэЕФвЛаЉБЈБэЁЃЯИаФЕФЭЌбЇПЩФмЛсПДГігвЭМЕФМрПиБЈБэКЭNodeExporterКмЯёЃЌЪЧЕФЃЌЮвУЧМрПижїЛњзДЬЌгУЕФОЭЪЧNode
ExporterЃЌЙигкМрПиЕФЪЕЯжЃЌЮвУЧдкКѓУцЛсНјааНщЩмЃЌетРяднЧвВЛБэЁЃ
етРяЪЧЮвУЧЕФЗўЮёХфжУвГУцЃЌПЩвджЇГжГЃЙцЕФХфжУзщЁЂБфИќРњЪЗЧаЛЛКЭШЮвтЕФХфжУЯТЗЂЙІФмЁЃ
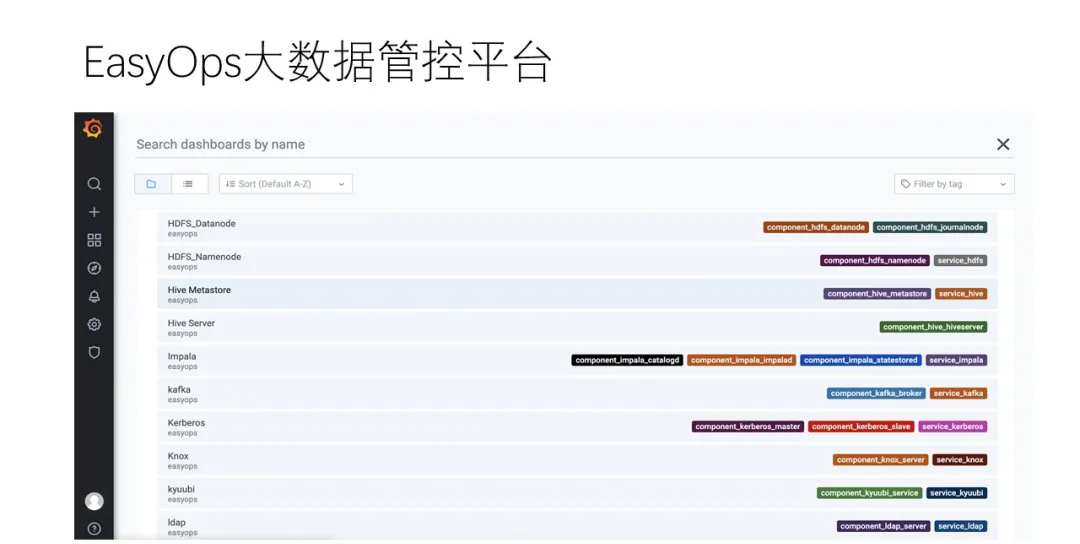
етЪЧЮвУЧЛљгкGrafanaЕФDashboardДѓХЬЃЌЛузмСЫЫљгаЯрЙиЗўЮёЕФМрПивЧБэХЬЁЃ

НгЯТРДЮЊДѓМвНщЩмЯТЭЈгУЕФДѓЪ§ОнЗўЮёдЫЮЌПђМмЃЌОпБИвЛаЉПЊЗЂзЪдДЕФЭХЖгПЩвддкЖЬЪБМфФкЭъГЩвЛИіПЩгУЕФЗўЮёдЫЮЌЦНЬЈЃЌетРяЮвУЧЛсЗжетУДМИИіЧјПщРДИјДѓМвНщЩмЁЃ

вЛИіЭЈгУЕФЗўЮёдЫЮЌЦНЬЈЭљЭљЛсАќРЈвдЯТВйзїЃК
ЦфЫћЗўЮёЕФЬивьадВйзїЃЌЦЉШчHDFSЪ§ОнЧЈвЦЃЌHDFSЪ§ОнОљКтЃЌYARNЕФЖгСаЛђШЮЮёВйзїЕШЕШ

вдЗўЮёАВзАСїГЬЮЊР§ЃЌЫЕУївЛЯТећИіСїГЬЁЁ

етИіЭЈгУЕФдЫЮЌПђМмЪЧвдAnsibleММЪѕеЛЮЊЛљДЁЃЌАќРЈвдЩЯШ§ИіжївЊЕФЙІФмФЃПщЁЃ
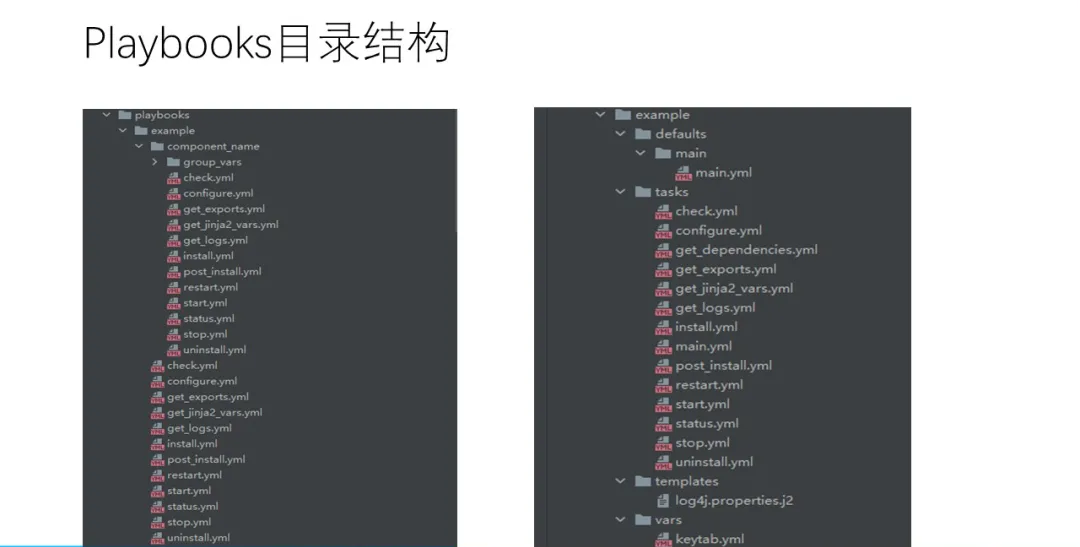
ЮвУЧЪЙгУAnsible RunnerФПТМНсЙЙРДзщжЏPlaybooksЃЌЛљБОЕФНсЙЙМћЩЯЭМЃЌдкplaybookФПТМЯТУцЪЧИїИізщМўЛђЗўЮёЕФдЫЮЌВйзїЕФШыПкЁЃ
дкrolesЯТвдЗўЮёУћДДНЈФПТМЃЌФПТМЯТДДНЈdefaults,tasks,templates,varsФПТМЁЃ
defaultsЃКгУгкДцЗХФЌШЯЕФБфСПжЕЃЌБиаыДДНЈmain.ymlЮФМўЃЌЕїгУroleЪБЛсздЖЏМгди
tasks: ЫљгаЕФШЮЮёНХБОДцЗХЕФФПТМЃЌБиаыДДНЈmain.ymlЃЌЕБЕїгУroleЪБЃЌЛсЕїгУmain.yml
templates: гУгкДцЗХtemplatesФЃАхЃЌЩњГЩХфжУЮФМў
vars: гУгкДцЗХЖЏЬЌЕФБфСПжЕЃЌашвЊincludeЖдгІЕФБфСПЮФМўВХЛсМгди


ЦНЬЈЕФЧАЖЫЮвУЧЪЙгУЕФММЪѕЗНАИЪЧЁЁ
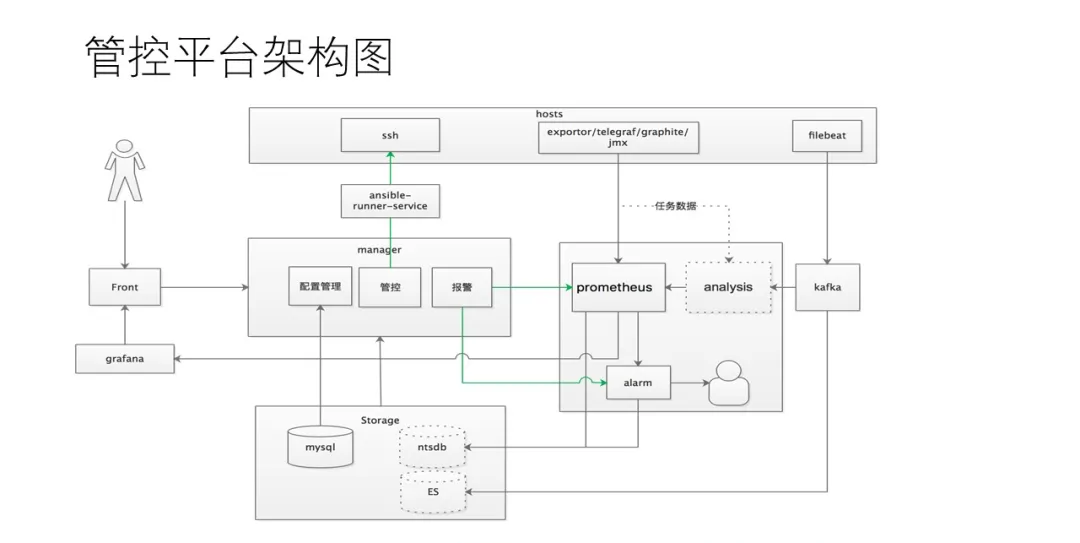
ЦНЬЈКѓЖЫЕФММЪѕеЛЪЧЁЁ
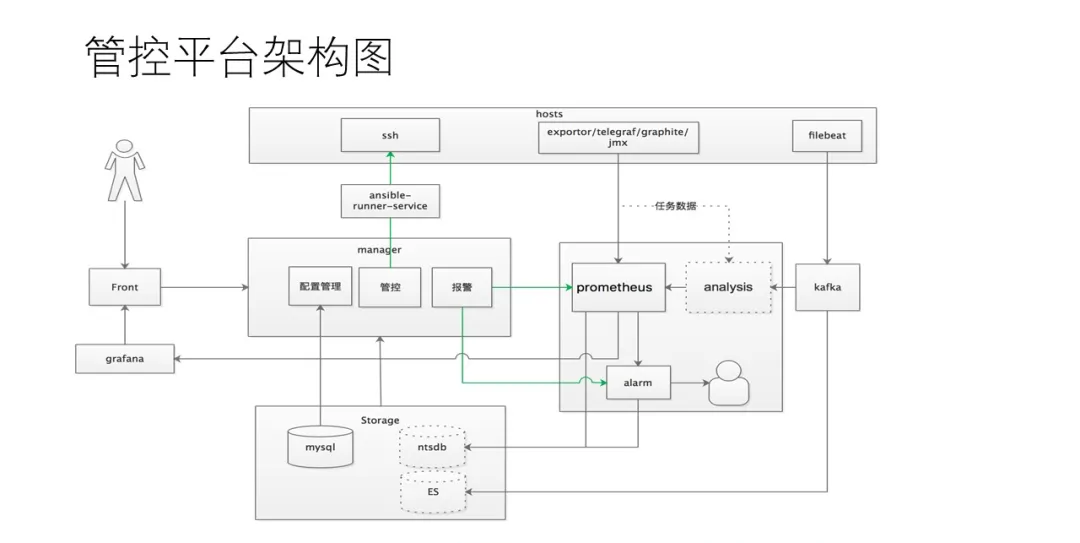
ећИіЦНЬЈЕФМмЙЙЭМШчЩЯЁЁ
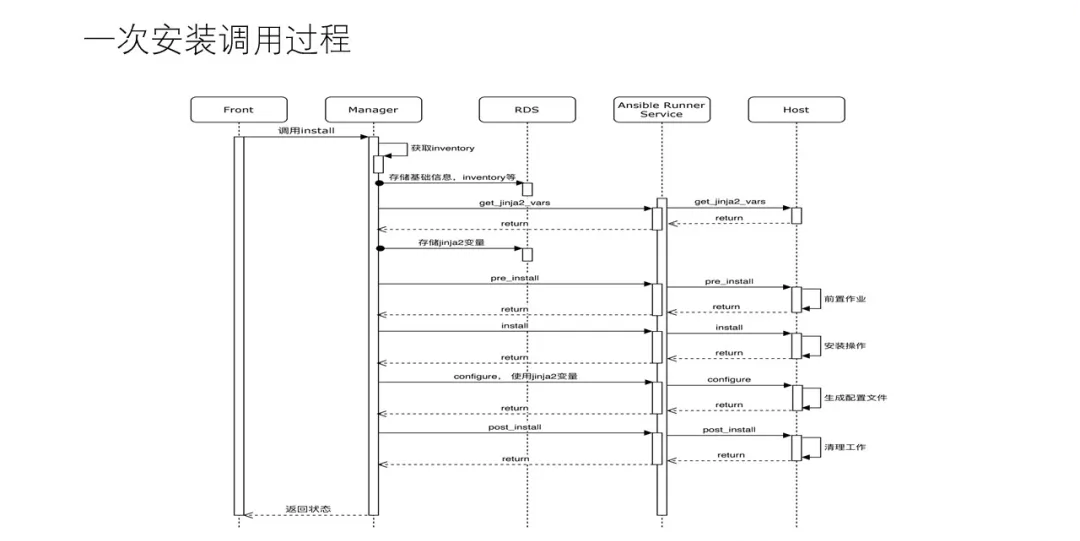
вджЎЧАЬсЕНЕФAnsibleЕФЗўЮёАВзАЕїгУТпМЮЊР§ЃЌЫЕУїЯТећИіЕїгУСїГЬЁЁ

ЗўЮёЕФХфжУЙмРэЗжЮЊвдЩЯМИИіВПЗжЃК
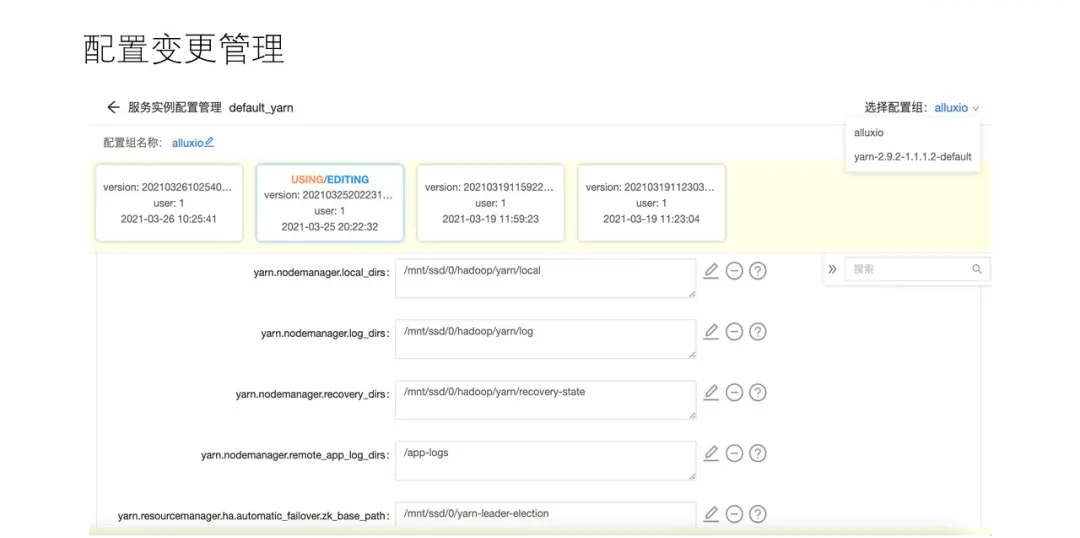
ЩЯЭМЪЧYARNЗўЮёЕФХфжУЙмРэЃЌПЩвдПДЕНБфИќЕФРњЪЗМЧТМЁЃ
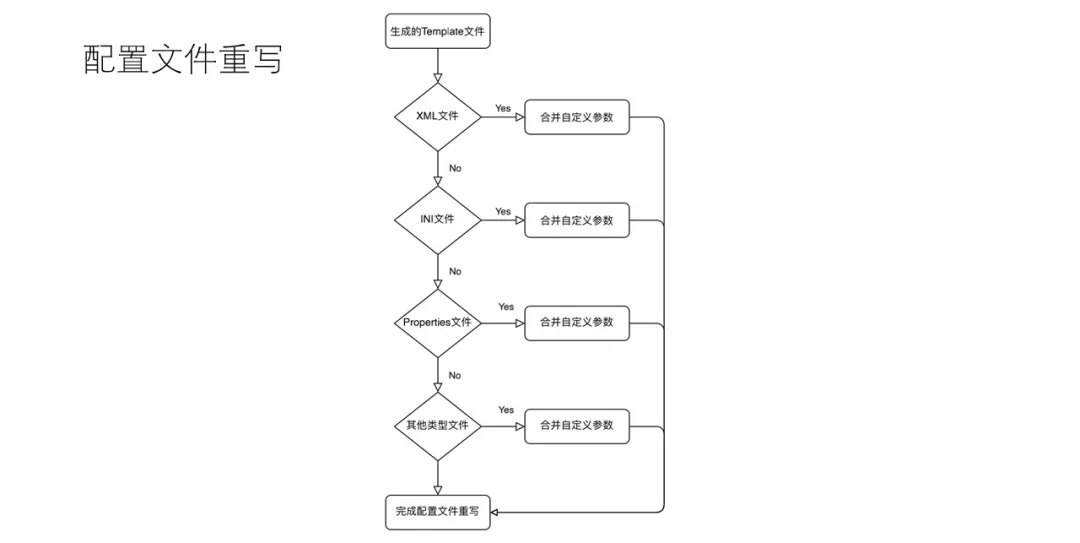
ЙигкХфжУЮФМўЕФВЮЪ§БфИќЃЌЮвУЧгаетУДвЛИіГЁОАЃЌашвЊФмжЇГжШЮвтВЮЪ§ЕФХфжУЭИДЋЁЃЮвУЧЖЈвхСЫвЛЬзСїГЬРДНтОіЩЯЪіЮЪЬтЃЌЩЯУцОЭЪЧвЛИіЕїгУЭМР§ЁЃ
ЮЊЪВУДвЊгаХфжУЭИДЋЃПКмМђЕЅЃЌвђЮЊПЊЗЂРСЃЌВЛЯыУПДЮЗўЮёАцБОБфИќдіМгХфжУВЮЪ§КѓЃЌЛЙашвЊНјаавЛДЮЪЪХфЁЃЖјЪЧАДееЙцЗЖЃЌЮЊЬиЖЈЕФХфжУЮФМўЪЕЯжЖЏЬЌХфжУЬэМгВпТдЁЃ

НгЯТРДЮвУЧНщЩмЯТЭЈгУЕФДѓЪ§ОнЗўЮёМрПиБЈОЏПђМмЃЌЫќЛљгкPrometheus/GrafanaЕШзщМўЪЕЯжЃЛФкВПЪЙгУЕФTSDBЪЧЛљгкInfluxDBИФдьКѓЕФNTSDBЁЃ
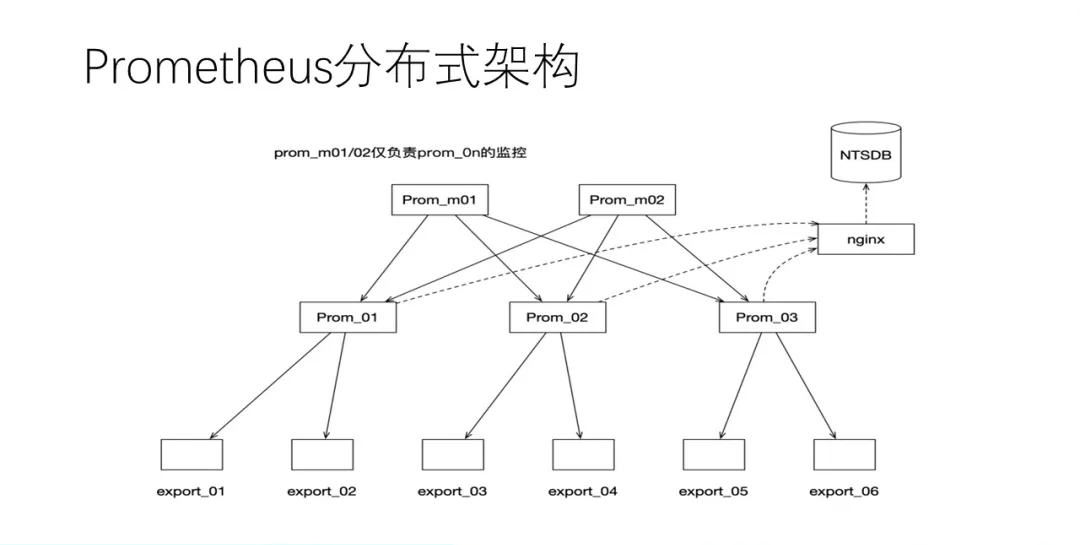
ЫљвдКмУїЯдЃЌдкМЏШКФЃЪНЯТPrometheusЗўЮёЪЧЮвУЧМрПиЕФКЫаФФЃПщЃЌЮЊДЫЮвУЧеыЖдЗжВМЪНКЭИпПЩгУЮЪЬтЃЌЖЈжЦСЫвЛЬзМмЙЙЃЌЯТУцЪЧЗжВМЪНЖСаДЪЕЯжЁЃ
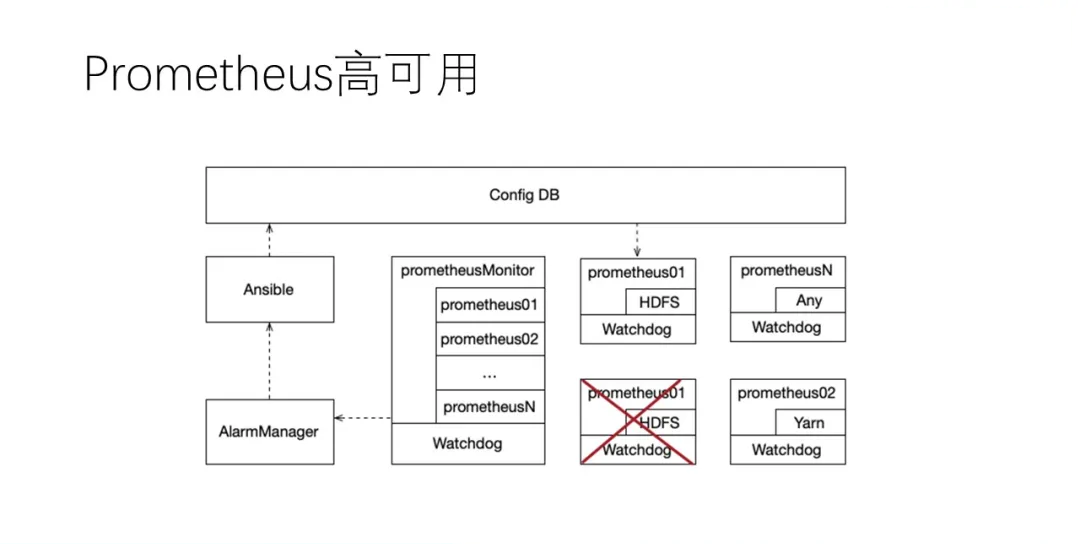
етРяЪЧPrometheusЕФИпПЩгУМмЙЙЃЌЫљгаВЩМЏЖЫЕФprometheusОљгЩprometheusMonitorНјааМрПиЁЃЕБвЛИіprometheusЮоЗЈЬсЙЉЗўЮёЪБЃЌЛсЯШгЩwatchdogНјаажиЦєЃЛШчЙћвРОЩЮоЗЈЬсЙЉЗўЮёЃЌalarmManagerЛсНјааБЈОЏЃЌЕїгУAnsibleЕФЯрЙиНгПкЃЌРШЁЮоЗЈЬсЙЉЗўЮёЕФprometheusЕФЭъећХфжУЮФМўЃЌШЛКѓдкКЯЪЪЕФжїЛњЩЯДДНЈаТЕФЪЕР§ЁЃ
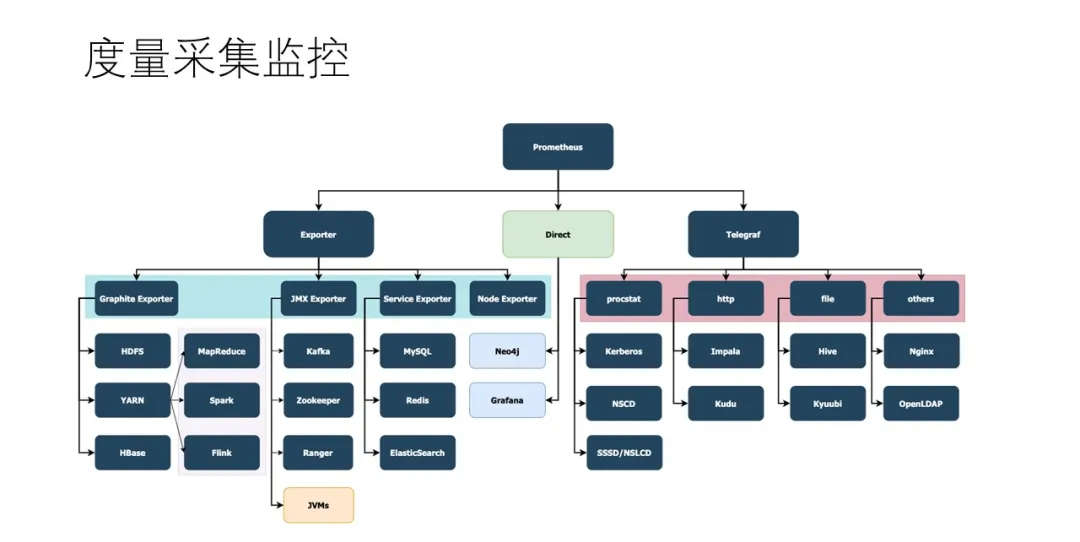
ЩЯЭМЪЧЮвУЧЕФЖШСПВЩМЏЗНАИЃЌгааЉЗўЮёздМКОЭБЉТЖСЫprometheusЕФЖШСПНгПкЃЌЦЉШчNeo4jЃЌGrafanaЃЌPrometheusЕШЃЌетРрЗўЮёЮвУЧжБНгЭЈЙ§prometheusзЅШЁЯрЙиМрПиЪ§ОнМДПЩЁЃJVMЗўЮёЮвУЧЪЙгУЕФЪЧmicrometerВхМўЃЈhttps://micrometer.io/ЃЉЁЃ
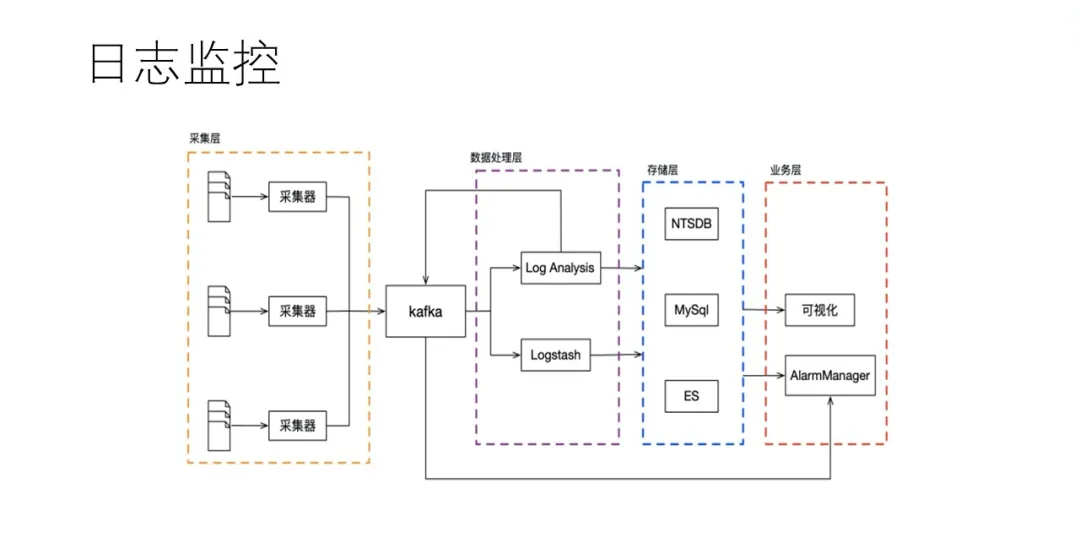
НгЯТРДЪЧЮвУЧздЖЈвхЕФШежОМрПиСїГЬЃЌШежОВЩМЏПЩвдЪЙгУfilebeatЃЌlogstashЕШвбгаЕФзщМўЃЌЕЋЮвУЧгаФкВПЕФвЛИіDSAgentЗНАИЁЃЭЈЙ§ШежОВЩМЏЃЌСїШыЕНkafkaЃЌШЛКѓЮвУЧЛсгаЖЈжЦЕФШежОЗжЮіТпМЃЌЦЉШчЗжЮівьГЃШежОЃЌОлКЯЖШСПЕШЃЌЯћЗбКѓЕФЪ§ОнЛсЗжСїжСESЃЌNTSDBЛђепMySQLЕШДцДЂЃЌгУгкПЩЪгЛЏЛђепБЈОЏЦНЬЈТпМЁЃ
ЮвУЧЕФБЈБэЯЕЭГЛљгкGrafanaЖЈжЦЖјГЩЁЃ
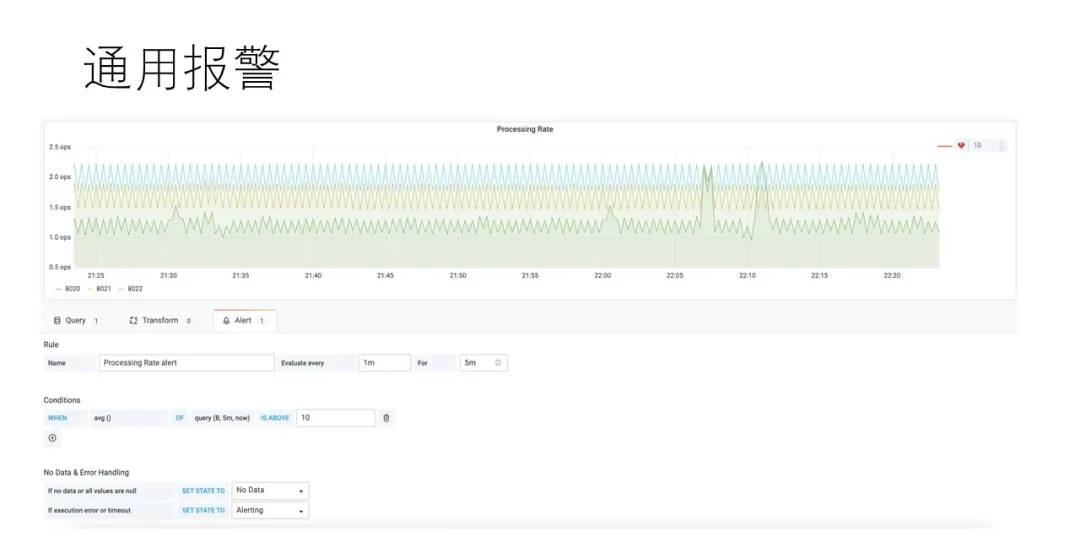
БЈОЏЮвУЧПЩвджБНгЪЙгУGrafanaЕФAlertФЃПщРДЪЕЯжЃЌЭЈЙ§ЕМШыЖЈжЦЕФAlertЙцдђЃЌПЩвдЗНБуЖдМЏШКЕФЭЈгУаджИБъЭГвЛЬэМгМрПиБЈОЏЁЃ
МђЕЅЃЌвзгУЃЌЗНБувЦжВЁЃЪЙгУGrafanaИќМгЭЈгУ
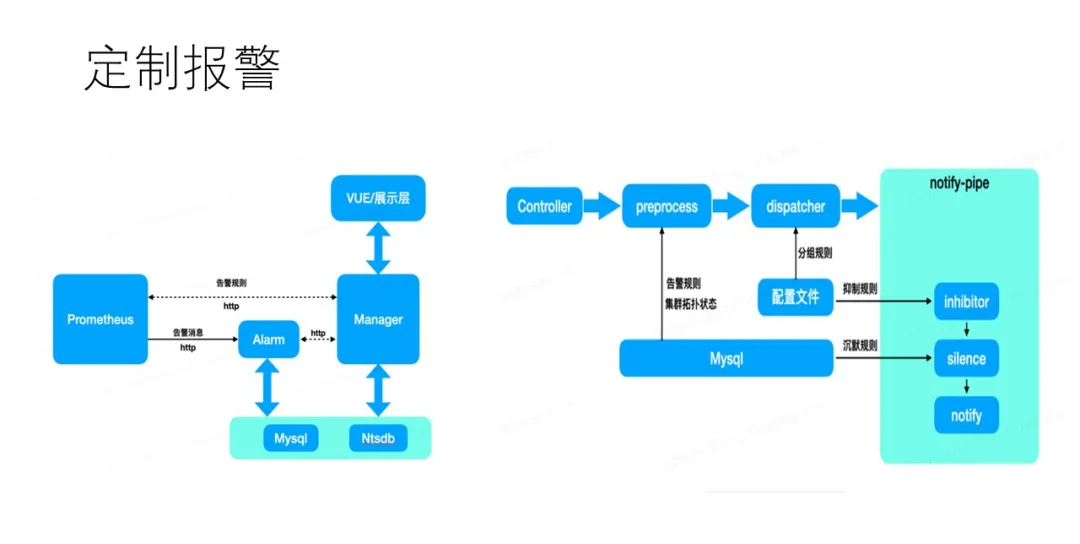
Г§ДЫжЎЭтЮвУЧВЮПМPrometheusЕФAlertMangerзщМўЃЌИФдьСЫPrometheusЃЌгУЫќРДЪЕЯжИќСщЛюЕФздЖЈвхБЈОЏТпМЁЃ

НгЯТРДЮвУЧНјШызюКѓвЛИіЛЗНкЃЌдЫЮЌОбщЕФНЛСїЁЃЮветБпЛсвдетУДМИПщФкШнРДЫЕУїЮвУЧЕФЦНЬЈдкбнНјЙ§ГЬжаЕФЮЪЬтКЭЫМТЗЁЃ
ДгЭјТчМмЙЙЁЂДцЫуЗжРыЁЂЗўЮёЩЯдЦЕШЗНУцРДНщЩмЦНЬЈЕФбнНјЙ§ГЬЃЌетаЉЗНУцЕФбнНјзюжеФПБъЛЙЪЧДяГЩГЩБОгХЛЏЁЃзюКѓДгЯЕЭГЁЂЗўЮёЕШЗНУцНщЩмвЛаЉадФмгХЛЏЕФИФНјЕу
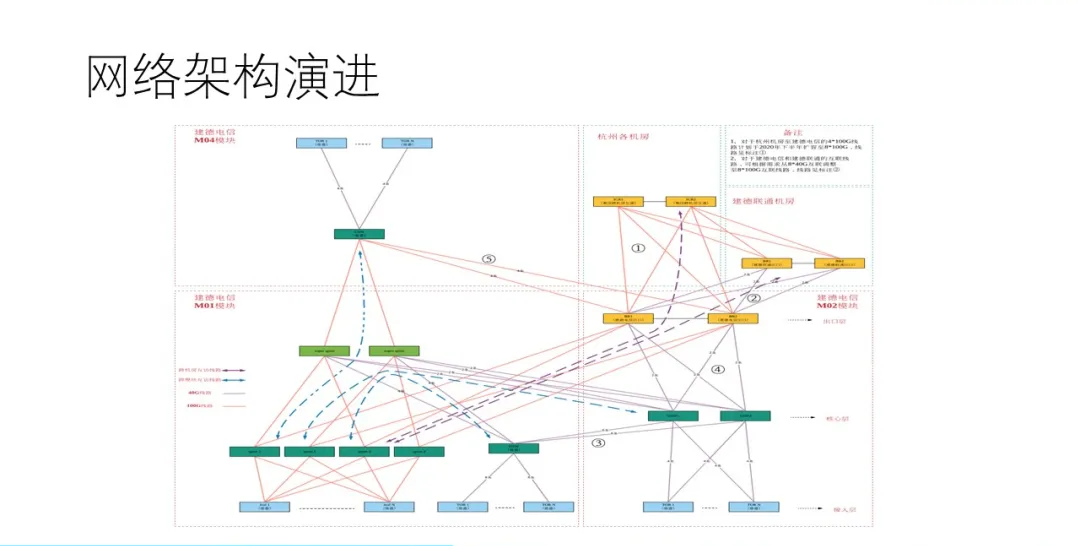
ДѓЪ§ОнHADOOPвЕЮёЯрНЯгкГЃЙцвЕЮёдкСїСПЗНУцгаКмДѓЕФЧјБ№ЃЌhadoopвЕЮёвђЪ§ОнЗжЮіЁЂРыЯпМЦЫуЕШашЧѓЛсЖдЖЋЮїЯђЕФСїСПгаЗЧГЃДѓЕФашЧѓЃЌЕЋЪЧгжвђЦфЪ§ОнДцДЂЙІФмЭЌЪБвВЛсДцдкДѓСПЦфЫћвЕЮёЕФЪ§ОнДцДЂЕНhadoopЗўЮёЦїжаЕМжТФЯББЯђЕФСїСПвВЗЧГЃДѓЁЃвЊТњзуетбљЕФСїСПФЃаЭЕФашЧѓОЭашвЊгавЛИіДѓЪеСВБШЕФЭјТчМмЙЙЃЌspine
leafМмЙЙЧЁКУФмТњзуетЕуЁЃЃЈЪЙгУРЯМмЙЙЃЌНтОіARPЕФЙуВЅЮЪЬтЃЌЖјЧвИєРыадКУЃЉ
SpineРрЫЦШ§ВуМмЙЙжаЕФКЫаФНЛЛЛЛњЃЌЕЋаЮЬЌгаЫљБфЛЏЃКИпЖЫПкУмЖШИпЭЬЭТСПЕФШ§ВуНЛЛЛЛњЬцДњСЫДѓаЭПђЪНКЫаФНЛЛЛЛњЃЌ4ЬЈspineЩшБИЮЊвЛИіpodНкЕуЃЌНсКЯARPзЊТЗгЩЪЙгУНЋЭјТчЕФбЙСІДгМЏжаЪНИКдигкКЫаФНЛЛЛЛњЃЌБфГЩИјаэЖрЕФleafНЛЛЛЛњРДОљКтЗжЕЃЁЃ
ДцДЂЗжРыдкЩЯдЦЙ§ГЬжавЛжБгаЬсИпЃЌетИіЖдгкећЬхЕФГЩБОгХЛЏгаУїЯдЕФКУДІЃЌЮвУЧздМКФкВПЕФЦРЙРОЭЪЧЭЌЕШДцДЂКЭМЦЫуЙцИёЬѕМўЯТЃЌЪЙгУДцДЂЗжРыПЩвдНкЪЁжСЩй20%ЕФГЩБОЃЌЭЌЪБШЮЮёЕФадФмвВФмЕУЕННЯДѓЬсЩ§ЁЃ
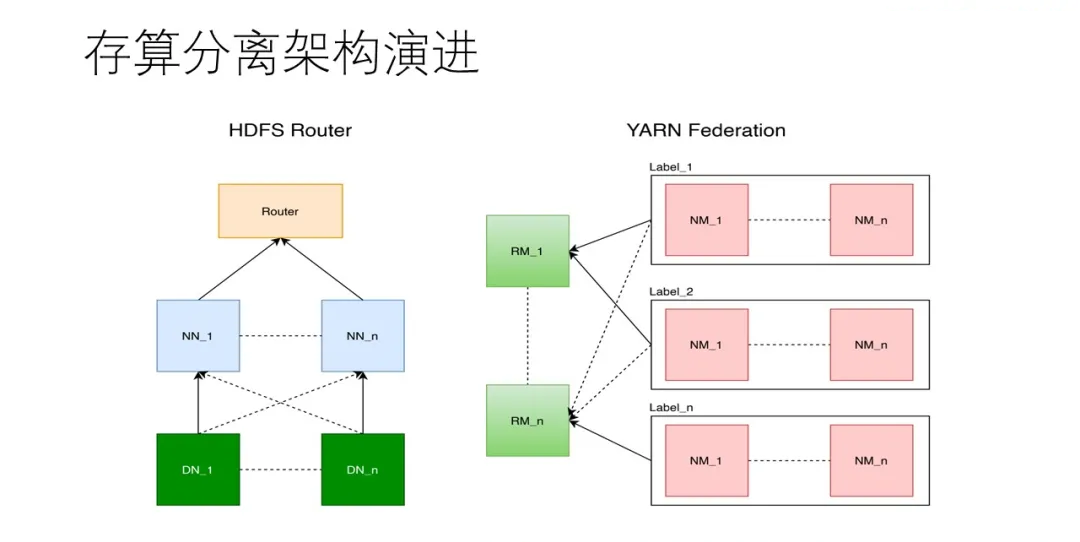
етРяЮвУЧжївЊЪЙгУHDFS Router/FederationМмЙЙЃЌвдМАYarnЕФNode LabelЕШЬиадРДЪЕЯжЁЃ
зюКѓЫЕЕНЗўЮёЩЯдЦЕФЪЕМљЃЌетРяЪЧЮвУЧдЦЩЯЪЕМљЕФВПЪ№МмЙЙЭМЁЃДѓЪ§ОнЩЯдЦвЛАуРДЫЕзюДѓЕФРЇФбЛЙЪЧДцДЂНгПкЕФЮЪЬтЃЌжїСїЕФдЦДцДЂЗНАИЃЌАќРЈs3ЃЌobsЃЌossЕШЕШЁЃ
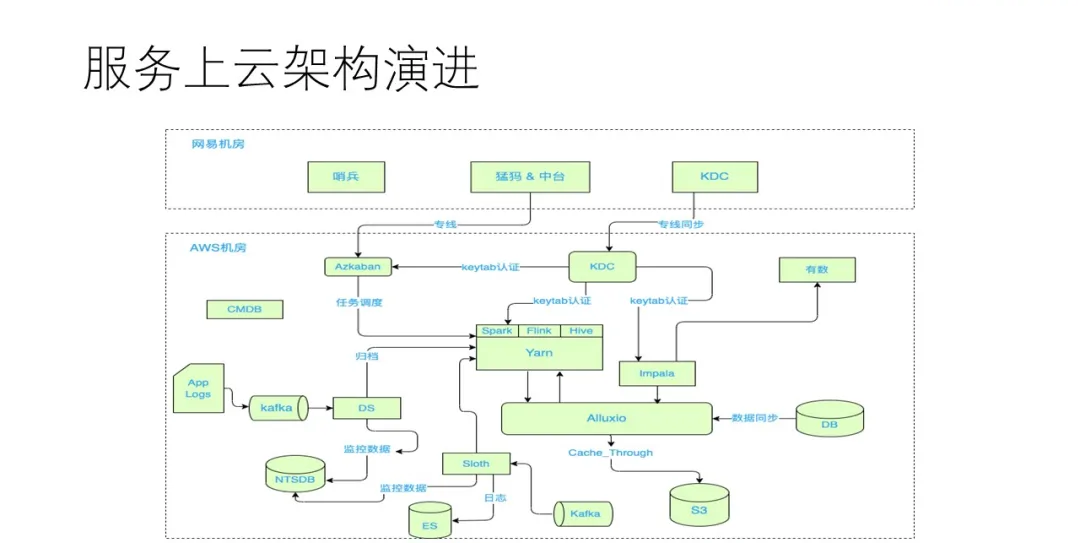
ЮЊСЫЬсЙЉЭГвЛЕФЕзВуНгШыЛЗОГЃЌЮвУЧв§ШыAlluxioРДзїЮЊжаМфВуРДЦСБЮЕзВуЕФДцДЂЯИНкЃЌДгЖјЩЯВуЕФМЦЫуПђМмКЭЦНЬЈжЛашвЊзіЩдЮЂЕФВЮЪ§ЪЪХфРДЪЕЯжЭЈгУЕФдЦЩЯВПЪ№ТпМЁЃ
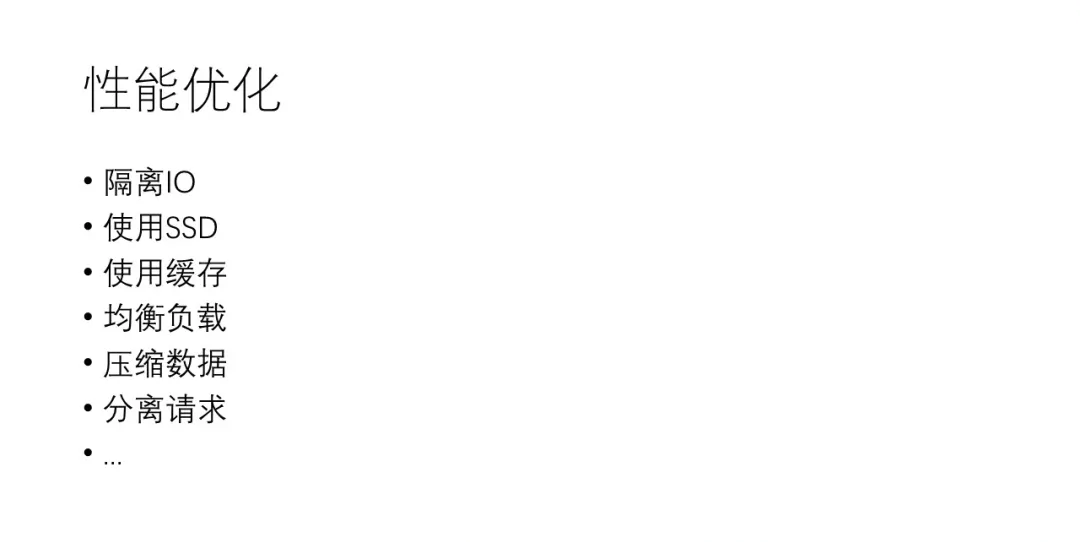
зюКѓЫЕЕНадФмгХЛЏЃЌЮветРяВЛЛсЫЕЕНвЛаЉОпЬхЕФЯИНкЃЌИХвЊЕФРДЫЕЃЌЮвУЧПЩвдВЮПМвдЩЯЕФМИИіддђРДНјаагХЛЏЁЃ
|








