| БрМЭЦМі: |
БОЮФНЋЬНЫївЛаЉгааЇЕФЖрЮЌЪ§ОнПЩЪгЛЏВпТдЃЈЗЖЮЇДг 1 ЮЌЕН 6 ЮЌЃЉ
ЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгк
ЛњЦїжЎаФ
ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂПЩЪгЛЏНщЩм
УшЪіадЗжЮіЃЈdescriptive analyticsЃЉЪЧШЮКЮЗжЮіЩњУќжмЦкЕФЪ§ОнПЦбЇЯюФПЛђЬиЖЈбаОПЕФКЫаФзщГЩВПЗжжЎвЛЁЃЪ§ОнОлКЯЃЈaggregationЃЉЁЂЛузмЃЈsummarizationЃЉКЭПЩЪгЛЏЃЈvisualizationЃЉЪЧжЇГХЪ§ОнЗжЮіСьгђЕФжївЊжЇжљЁЃДгДЋЭГЩЬвЕжЧФмЃЈBusiness IntelligenceЃЉПЊЪМЃЌЩѕжСЕНШчНёШЫЙЄжЧФмЪБДњЃЌЪ§ОнПЩЪгЛЏЖМЪЧвЛИіЧПгаСІЕФЙЄОпЃЛгЩгкЦфФмгааЇГщШЁе§ШЗЕФаХЯЂЃЌЭЌЪБЧхГўШнвзЕиРэНтКЭНтЪЭНсЙћЃЌПЩЪгЛЏБЛвЕНчзщжЏЙуЗКЪЙгУЁЃШЛЖјЃЌДІРэЖрЮЌЪ§ОнМЏЃЈЭЈГЃОпга 2 ИівдЩЯЪєадЃЉПЊЪМв§Ц№ЮЪЬтЃЌвђЮЊЮвУЧЕФЪ§ОнЗжЮіКЭЭЈаХЕФУННщЭЈГЃЯогк 2 ИіЮЌЖШЁЃдкБОЮФжаЃЌЮвУЧНЋЬНЫївЛаЉгааЇЕФЖрЮЌЪ§ОнПЩЪгЛЏВпТдЃЈЗЖЮЇДг 1 ЮЌЕН 6 ЮЌЃЉЁЃ
ЖўЁЂПЩЪгЛЏЖЏЛњ
ЁИвЛЭМЪЄЧЇбдЁЙ
етЪЧвЛОфЮвУЧЪьЯЄЕФЗЧГЃСїааЕФгЂгяЯАгяЃЌПЩвдГфЕБНЋЪ§ОнПЩЪгЛЏзїЮЊЗжЮіЕФгааЇЙЄОпЕФСщИаКЭЖЏСІЁЃгРдЖМЧзЁЃКЁИгааЇЕФЪ§ОнПЩЪгЛЏМШЪЧвЛУХвеЪѕЃЌвВЪЧвЛУХПЦбЇЁЃЁЙдкПЊЪМжЎЧАЃЌЮвЛЙвЊЬсМАЯТУцвЛОфЗЧГЃЯрЙиЕФв§бдЃЌЫќЧПЕїСЫЪ§ОнПЩЪгЛЏЕФБивЊадЁЃ
ЁИвЛеХЭМЦЌЕФзюДѓМлжЕдкгкЃЌЫќЦШЪЙЮвУЧзЂвтЕНЮвУЧДгЮДЦкЭћПДЕНЕФЖЋЮїЁЃЁЙ
ЁЊЁЊJohn Tukey
Ш§ЁЂПьЫйЛиЙЫПЩЪгЛЏ
БОЮФМйЩшвЛАуЖСепжЊЕРгУгкЛцЭМКЭПЩЪгЛЏЪ§ОнЕФЛљБОЭМБэРраЭЃЌвђДЫетРяВЛдйзИЪіЃЌЕЋдкБОЮФЫцКѓЕФЪЕМљжаЃЌЮвУЧНЋЛсЩцМАДѓВПЗжЭМБэРраЭЁЃжјУћЕФПЩЪгЛЏЯШЧ§КЭЭГМЦбЇМв Edward Tufte ЫЕЙ§ЃЌЪ§ОнПЩЪгЛЏгІИУдкЪ§ОнЕФЛљДЁЩЯЃЌвдЧхЮњЁЂОЋШЗКЭИпаЇЕФЗНЪНДЋДяЪ§ОнФЃЪНКЭЖДВьаХЯЂЁЃ
НсЙЙЛЏЪ§ОнЭЈГЃАќРЈгЩааКЭЬиеїБэеїЕФЪ§ОнЙлВтжЕЛђгЩСаБэеїЕФЪ§ОнЪєадЁЃУПСавВПЩвдБЛГЦЮЊЪ§ОнМЏЕФФГЬиЖЈЮЌЖШЁЃзюГЃМћЕФЪ§ОнРраЭАќРЈСЌајаЭЪ§жЕЪ§ОнКЭРыЩЂаЭЗжРрЪ§ОнЁЃвђДЫЃЌШЮКЮЪ§ОнПЩЪгЛЏНЋЛљБОЩЯвдЩЂЕуЭМЁЂжБЗНЭМЁЂЯфЯпЭМЕШМђЕЅвзЖЎЕФаЮЪНУшЪівЛИіЛђЖрИіЪ§ОнЪєадЁЃБОЮФНЋКИЧЕЅБфСПЃЈ1 ЮЌЃЉКЭЖрБфСПЃЈЖрЮЌЃЉЪ§ОнПЩЪгЛЏВпТдЁЃетРяНЋЪЙгУ Python ЛњЦїбЇЯАЩњЬЌЯЕЭГЃЌЮвУЧНЈвщЯШМьВщгУгкЪ§ОнЗжЮіКЭПЩЪгЛЏЕФПђМмЃЌАќРЈ pandasЁЂmatplotlibЁЂseabornЁЂplotly КЭ bokehЁЃГ§ДЫжЎЭтЃЌШчЙћФугааЫШЄгУЪ§ОнжЦзїОЋУРЖјгавтвхЕФПЩЪгЛЏЮФМўЃЌФЧУДСЫНт D3.jsЃЈhttps://d3js.org/ЃЉвВЪЧБиаыЕФЁЃгааЫШЄЕФЖСепПЩвддФЖС Edward Tufte ЕФЁИThe Visual Display of Quantitative InformationЁЙЁЃ
ЯаЛАжСДЫЃЌШУЮвУЧРДПДПДПЩЪгЛЏЃЈКЭДњТыЃЉАЩЃЁ
Б№дкетЖљЬИТлРэТлКЭИХФюСЫЃЌШУЮвУЧПЊЪМНјШые§ЬтАЩЁЃЮвУЧНЋЪЙгУ UCI ЛњЦїбЇЯАПтЃЈhttps://archive.ics.uci.edu/ml/index.phpЃЉжаЕФ Wine Quality Data SetЁЃетаЉЪ§ОнЪЕМЪЩЯЪЧгЩСНИіЪ§ОнМЏзщГЩЕФЃЌетСНИіЪ§ОнМЏУшЪіСЫЦЯЬббРЁИVinho VerdeЁЙЦЯЬбОЦжаКьЩЋКЭАзЩЋОЦЕФИїжжГЩЗжЁЃБОЮФжаЕФЫљгаЗжЮіЖМдкЮвЕФ GitHub ДцДЂПтжаЃЌФуПЩвдгУ Jupyter Notebook жаЕФДњТыРДГЂЪдвЛЯТЃЁ
ЮвУЧНЋЪзЯШМгдивдЯТБивЊЕФвРРЕАќНјааЗжЮіЁЃ

ЮвУЧНЋжївЊЪЙгУ matplotlib КЭ seaborn зїЮЊЮвУЧЕФПЩЪгЛЏПђМмЃЌЕЋФуПЩвдздгЩбЁдёВЂГЂЪдШЮКЮЦфЫќПђМмЁЃЪзЯШНјааЛљБОЕФЪ§ОндЄДІРэВНжшЁЃ

ЮвУЧЭЈЙ§КЯВЂгаЙиКьЁЂАзЦЯЬбОЦбљБОЕФЪ§ОнМЏРДДДНЈЕЅИіЦЯЬбОЦЪ§ОнПђМмЁЃЮвУЧЛЙИљОнЦЯЬбОЦбљЦЗЕФжЪСПЪєадДДНЈвЛИіаТЕФЗжРрБфСП quality_labelЁЃЯждкЮвУЧРДПДПДЪ§ОнЧАМИааЁЃ

ЦЯЬбОЦжЪСПЪ§ОнМЏ
КмУїЯдЃЌЮвУЧгаМИИіЦЯЬбОЦбљБОЕФЪ§жЕКЭЗжРрЪєадЁЃУПИіЙлВтбљБОЪєгкКьЦЯЬбОЦЛђАзЦЯЬбОЦбљЦЗЃЌЪєадЪЧДгЮяРэЛЏбЇВтЪджаВтСПКЭЛёЕУЕФЬиЖЈЪєадЛђаджЪЁЃШчЙћФуЯыСЫНтУПИіЪєадЃЈЪєадЖдгІЕФБфСПУћГЦвЛФПСЫШЛЃЉЯъЯИЕФНтЪЭЃЌФуПЩвдВщПД Jupyter NotebookЁЃШУЮвУЧПьЫйЖдетаЉИааЫШЄЕФЪєадНјааЛљБОЕФУшЪіадИХРЈЭГМЦЁЃ

ЦЯЬбОЦРраЭЕФЛљБОУшЪіадЭГМЦ
БШНЯетаЉВЛЭЌРраЭЕФЦЯЬбОЦбљБОЕФЭГМЦЗНЗЈЯрЕБШнвзЁЃзЂвтвЛаЉЪєадЕФУїЯдВювьЁЃЩдКѓЮвУЧНЋдквЛаЉПЩЪгЛЏжаЧПЕїетаЉФкШнЁЃ
1.ЕЅБфСПЗжЮі
ЕЅБфСПЗжЮіЛљБОЩЯЪЧЪ§ОнЗжЮіЛђПЩЪгЛЏЕФзюМђЕЅаЮЪНЃЌвђЮЊжЛЙиаФЗжЮівЛИіЪ§ОнЪєадЛђБфСПВЂНЋЦфПЩЪгЛЏЃЈ1 ЮЌЃЉЁЃ
ПЩЪгЛЏ 1 ЮЌЪ§ОнЃЈ1-DЃЉ
ЪЙЫљгаЪ§жЕЪ§ОнМАЦфЗжВМПЩЪгЛЏЕФзюПьЁЂзюгааЇЕФЗНЗЈжЎвЛЪЧРћгУ pandas ЛжБЗНЭМЃЈhistogramЃЉЁЃ

НЋЪєадзїЮЊ 1 ЮЌЪ§ОнПЩЪгЛЏ
ЩЯЭМИјГіСЫПЩЪгЛЏШЮКЮЪєадЕФЛљБОЪ§ОнЗжВМЕФвЛИіКУжївтЁЃ
ШУЮвУЧНјвЛВНПЩЪгЛЏЦфжавЛИіСЌајаЭЪ§жЕЪєадЁЃжБЗНЭМЛђКЫУмЖШЭМФмЙЛКмКУЕиАяжњРэНтИУЪєадЪ§ОнЕФЗжВМЁЃ

ПЩЪгЛЏ 1 ЮЌСЌајаЭЪ§жЕЪ§Он
ДгЩЯУцЕФЭМБэжаПЩвдПДГіЃЌЦЯЬбОЦжаСђЫсбЮЕФЗжВМДцдкУїЯдЕФгвЦЋЃЈright skewЃЉЁЃ
ПЩЪгЛЏвЛИіРыЩЂЗжРраЭЪ§ОнЪєадЩдгаВЛЭЌЃЌЬѕаЮЭМЪЧЃЈbar plotЃЉзюгааЇЕФЗНЗЈжЎвЛЁЃФувВПЩвдЪЙгУБ§ЭМЃЈpie-chartЃЉЃЌЕЋвЛАуРДЫЕвЊОЁСПБмУтЃЌгШЦфЪЧЕБВЛЭЌРрБ№ЕФЪ§СПГЌЙ§ 3 ИіЪБЁЃ

ПЩЪгЛЏ 1 ЮЌРыЩЂЗжРраЭЪ§Он
ЯждкЮвУЧМЬајЗжЮіИќИпЮЌЕФЪ§ОнЁЃ
2.ЖрБфСПЗжЮі
ЖрдЊЗжЮіВХЪЧеце§гавтЫМВЂЧвгаИДдгадЕФСьгђЁЃетРяЮвУЧЗжЮіЖрИіЪ§ОнЮЌЖШЛђЪєадЃЈ2 ИіЛђИќЖрЃЉЁЃЖрБфСПЗжЮіВЛНіАќРЈМьВщЗжВМЃЌЛЙАќРЈетаЉЪєаджЎМфЕФЧБдкЙиЯЕЁЂФЃЪНКЭЯрЙиадЁЃФувВПЩвдИљОнашвЊНтОіЕФЮЪЬтЃЌРћгУЭЦЖЯЭГМЦЃЈinferential statisticsЃЉКЭМйЩшМьбщЃЌМьВщВЛЭЌЪєадЁЂШКЬхЕШЕФЭГМЦЯджјадЃЈsignificanceЃЉЁЃ
ПЩЪгЛЏ 2 ЮЌЪ§ОнЃЈ2-DЃЉ
МьВщВЛЭЌЪ§ОнЪєаджЎМфЕФЧБдкЙиЯЕЛђЯрЙиадЕФзюМбЗНЗЈжЎвЛЪЧРћгУХфЖдЯрЙиадОиеѓЃЈpair-wise correlation matrixЃЉВЂНЋЦфПЩЪгЛЏЮЊШШСІЭМЁЃ

гУЯрЙиадШШСІЭМПЩЪгЛЏ 2 ЮЌЪ§Он
ШШСІЭМжаЕФЬнЖШИљОнЯрЙиадЕФЧПЖШЖјБфЛЏЃЌФуПЩвдКмШнвзЗЂЯжБЫДЫжЎМфОпгаЧПЯрЙиадЕФЧБдкЪєадЁЃСэвЛжжПЩЪгЛЏЕФЗНЗЈЪЧдкИааЫШЄЕФЪєаджЎМфЪЙгУХфЖдЩЂЕуЭМЁЃ

гУХфЖдЩЂЕуЭМПЩЪгЛЏ 2 ЮЌЪ§Он
ИљОнЩЯЭМЃЌПЩвдПДЕНЩЂЕуЭМвВЪЧЙлВьЪ§ОнЪєадЕФ 2 ЮЌЧБдкЙиЯЕЛђФЃЪНЕФгааЇЗНЪНЁЃСэвЛжжНЋЖрдЊЪ§ОнПЩЪгЛЏЮЊЖрИіЪєадЕФЗНЗЈЪЧЪЙгУЦНаазјБъЭМЁЃ
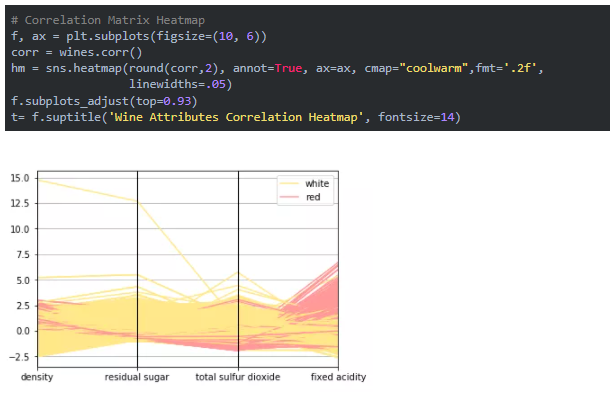
гУЦНаазјБъЭМПЩЪгЛЏЖрЮЌЪ§Он
ЛљБОЩЯЃЌдкШчЩЯЫљЪіЕФПЩЪгЛЏжаЃЌЕуБЛБэеїЮЊСЌНгЕФЯпЖЮЁЃУПЬѕДЙжБЯпДњБэвЛИіЪ§ОнЪєадЁЃЫљгаЪєаджаЕФвЛзщЭъећЕФСЌНгЯпЖЮБэеївЛИіЪ§ОнЕуЁЃвђДЫЃЌЧїгкЭЌвЛРрЕФЕуНЋЛсИќМгНгНќЁЃНіНіЭЈЙ§ЙлВьОЭПЩвдЧхГўПДЕНЃЌгыАзЦЯЬбОЦЯрБШЃЌКьЦЯЬбОЦЕФУмЖШТдИпЁЃгыКьЦЯЬбОЦЯрБШЃЌАзЦЯЬбОЦЕФВаЬЧКЭЖўбѕЛЏСђзмСПвВНЯИпЃЌКьЦЯЬбОЦЕФЙЬЖЈЫсЖШИпгкАзЦЯЬбОЦЁЃВщвЛЯТЮвУЧжЎЧАЕУЕНЕФЭГМЦБэжаЕФЭГМЦЪ§ОнЃЌПДПДФмЗёбщжЄетИіМйЩшЃЁ
вђДЫЃЌШУЮвУЧПДПДПЩЪгЛЏСНИіСЌајаЭЪ§жЕЪєадЕФЗНЗЈЁЃЩЂЕуЭМКЭСЊКЯЗжВМЭМЃЈjoint plotЃЉЪЧМьВщФЃЪНЁЂЙиЯЕвдМАЪєадЗжВМЕФЬиБ№КУЕФЗНЗЈЁЃ

ЪЙгУЩЂЕуЭМКЭСЊКЯЗжВМЭМПЩЪгЛЏ 2 ЮЌСЌајаЭЪ§жЕЪ§Он
ЩЂЕуЭМдкЩЯЭМзѓВрЃЌСЊКЯЗжВМЭМдкгвВрЁЃОЭЯёЮвУЧЬсЕНЕФФЧбљЃЌФуПЩвдВщПДСЊКЯЗжВМЭМжаЕФЯрЙиадЁЂЙиЯЕвдМАЗжВМЁЃ
ШчКЮПЩЪгЛЏСНИіСЌајаЭЪ§жЕЪєадЃПвЛжжЗНЗЈЪЧЮЊЗжРрЮЌЖШЛЕЅЖРЕФЭМЃЈзгЭМЃЉЛђЗжУцЃЈfacetЃЉЁЃ

ЪЙгУЬѕаЮЭМКЭзгЭМПЩЪгЛЏ 2 ЮЌРыЩЂаЭЗжРрЪ§Он
ЫфШЛетЪЧвЛжжПЩЪгЛЏЗжРрЪ§ОнЕФКУЗНЗЈЃЌЕЋе§ШчЫљМћЃЌРћгУ matplotlib ашвЊБраДДѓСПЕФДњТыЁЃСэвЛИіКУЗНЗЈЪЧдкЕЅИіЭМжаЮЊВЛЭЌЕФЪєадЛЖбЛ§ЬѕаЮЭМЛђЖрИіЬѕаЮЭМЁЃПЩвдКмШнвзЕиРћгУ seaborn зіЕНЁЃ

дквЛИіЬѕаЮЭМжаПЩЪгЛЏ 2 ЮЌРыЩЂаЭЗжРрЪ§Он
етПДЦ№РДИќЧхЮњЃЌФувВПЩвдгааЇЕиДгЕЅИіЭМжаБШНЯВЛЭЌЕФРрБ№ЁЃ
ШУЮвУЧПДПДПЩЪгЛЏ 2 ЮЌЛьКЯЪєадЃЈДѓЖрЪ§МцгаЪ§жЕКЭЗжРрЃЉЁЃвЛжжЗНЗЈЪЧЪЙгУЗжЭМ\згЭМгыжБЗНЭМЛђКЫУмЖШЭМЁЃ


РћгУЗжУцКЭжБЗНЭМ\КЫУмЖШЭМПЩЪгЛЏ 2 ЮЌЛьКЯЪєад
ЫфШЛетКмКУЃЌЕЋЪЧЮвУЧдйвЛДЮБраДСЫДѓСПДњТыЃЌЮвУЧПЩвдЭЈЙ§РћгУ seaborn БмУтетаЉЃЌдкЕЅИіЭМБэжаЛГіетаЉЭМЁЃ

РћгУЖрЮЌжБЗНЭМПЩЪгЛЏ 2 ЮЌЛьКЯЪєад
ПЩвдПДЕНЩЯУцЩњГЩЕФЭМаЮЧхЮњМђНрЃЌЮвУЧПЩвдЧсЫЩЕиБШНЯИїжжЗжВМЁЃГ§ДЫжЎЭтЃЌЯфЯпЭМЃЈbox plotЃЉЪЧИљОнЗжРрЪєаджаЕФВЛЭЌЪ§жЕгааЇУшЪіЪ§жЕЪ§ОнзщЕФСэвЛжжЗНЗЈЁЃЯфЯпЭМЪЧСЫНтЪ§ОнжаЫФЗжЮЛЪ§жЕвдМАЧБдквьГЃжЕЕФКУЗНЗЈЁЃ
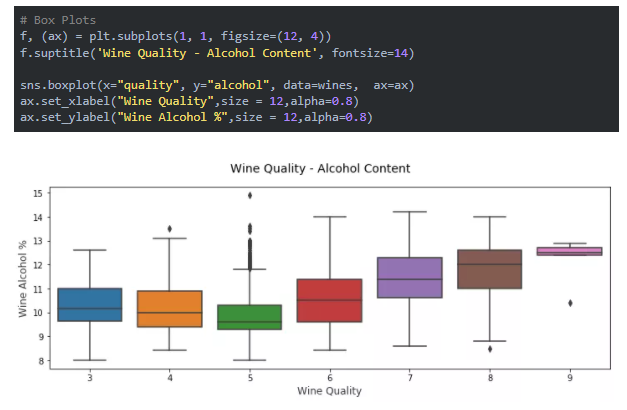
2 ЮЌЛьКЯЪєадЕФгааЇПЩЪгЛЏЗНЗЈЁЊЁЊЯфЯпЭМ
СэвЛИіРрЫЦЕФПЩЪгЛЏЪЧаЁЬсЧйЭМЃЌетЪЧЪЙгУКЫУмЖШЭМЯдЪОЗжзщЪ§жЕЪ§ОнЕФСэвЛжжгааЇЗНЗЈЃЈУшЛцСЫЪ§ОндкВЛЭЌжЕЯТЕФИХТЪУмЖШЃЉЁЃ

2 ЮЌЛьКЯЪєадЕФгааЇПЩЪгЛЏЗНЗЈЁЊЁЊаЁЬсЧйЭМ
ФуПЩвдЧхГўПДЕНЩЯУцЕФВЛЭЌОЦЦЗжЪРрБ№ЕФЦЯЬбОЦСђЫсбЮЕФУмЖШЭМЁЃ
НЋ 2 ЮЌЪ§ОнПЩЪгЛЏЗЧГЃМђЕЅжБНгЃЌЕЋЪЧЫцзХЮЌЪ§ЃЈЪєадЃЉЪ§СПЕФдіМгЃЌЪ§ОнПЊЪМБфЕУИДдгЁЃдвђЪЧвђЮЊЮвУЧЪмЕНЯдЪОУННщКЭЛЗОГЕФЫЋжидМЪјЁЃ
Ждгк 3 ЮЌЪ§ОнЃЌПЩвдЭЈЙ§дкЭМБэжаВЩгУ z жсЛђРћгУзгЭМКЭЗжУцРДв§ШыЩюЖШЕФащФтзјБъЁЃ
ЕЋЪЧЃЌЖдгк 3 ЮЌвдЩЯЕФЪ§ОнРДЫЕЃЌИќФбвджБЙлЕиБэеїЁЃИпгк 3 ЮЌЕФзюКУЗНЗЈЪЧЪЙгУЭМЗжУцЁЂбеЩЋЁЂаЮзДЁЂДѓаЁЁЂЩюЖШЕШЕШЁЃФуЛЙПЩвдЪЙгУЪБМфзїЮЊЮЌЖШЃЌЮЊЫцЪБМфБфЛЏЕФЪєаджЦзївЛЖЮЖЏЛЃЈетРяЪБМфЪЧЪ§ОнжаЕФЮЌЖШЃЉЁЃПДПД Hans Roslin ЕФОЋВЪбнНВОЭЛсЛёЕУЯрЭЌЕФЯыЗЈЃЁ
ПЩЪгЛЏ 3 ЮЌЪ§ОнЃЈ3-DЃЉ
етРябаОПга 3 ИіЪєадЛђЮЌЖШЕФЪ§ОнЃЌЮвУЧПЩвдЭЈЙ§ПМТЧХфЖдЩЂЕуЭМВЂв§ШыбеЩЋЛђЩЋЕїНЋЗжРрЮЌЖШжаЕФжЕЗжРыГіРДЁЃ


гУЩЂЕуЭМКЭЩЋЕїЃЈбеЩЋЃЉПЩЪгЛЏ 3 ЮЌЪ§Он
ЩЯЭМПЩвдВщПДЯрЙиадКЭФЃЪНЃЌвВПЩвдБШНЯЦЯЬбОЦзщЁЃОЭЯёЮвУЧПЩвдЧхГўЕиПДЕНАзЦЯЬбОЦЕФзмЖўбѕЛЏСђКЭВаЬЧБШКьЦЯЬбОЦИпЁЃ
ШУЮвУЧРДПДПДПЩЪгЛЏ 3 ИіСЌајаЭЪ§жЕЪєадЕФВпТдЁЃвЛжжЗНЗЈЪЧНЋ 2 ИіЮЌЖШБэеїЮЊГЃЙцГЄЖШЃЈx жсЃЉКЭПэЖШЃЈy жсЃЉВЂЧвНЋЕк 3 ЮЌБэеїЮЊЩюЖШЃЈz жсЃЉЕФИХФюЁЃ

ЭЈЙ§в§ШыЩюЖШЕФИХФюРДПЩЪгЛЏ 3 ЮЌЪ§жЕЪ§Он
ЮвУЧЛЙПЩвдРћгУГЃЙцЕФ 2 ЮЌзјБъжсЃЌВЂНЋГпДчДѓаЁЕФИХФюзїЮЊЕк 3 ЮЌЃЈБОжЪЩЯЪЧЦјХнЭМЃЉЃЌЦфжаЕуЕФГпДчДѓаЁБэеїЕк 3 ЮЌЕФЪ§СПЁЃ

ЭЈЙ§в§ШыГпДчДѓаЁЕФИХФюРДПЩЪгЛЏ 3 ЮЌЪ§жЕЪ§Он
вђДЫЃЌФуПЩвдПДЕНЩЯУцЕФЭМБэВЛЪЧвЛИіДЋЭГЕФЩЂЕуЭМЃЌЖјЪЧЕуЃЈЦјХнЃЉДѓаЁЛљгкВЛЭЌВаЬЧСПЕФЕФЦјХнЭМЁЃЕБШЛЃЌВЂВЛзмЯёетжжЧщПіПЩвдЗЂЯжЪ§ОнУїШЗЕФФЃЪНЃЌЮвУЧПДЕНЦфЫќСНИіЮЌЖШЕФДѓаЁвВВЛЭЌЁЃ
ЮЊСЫПЩЪгЛЏ 3 ИіРыЩЂаЭЗжРрЪєадЃЌЮвУЧПЩвдЪЙгУГЃЙцЕФЬѕаЮЭМЃЌПЩвдРћгУЩЋЕїЕФИХФювдМАЗжУцЛђзгЭМБэеїЖюЭтЕФЕк 3 ИіЮЌЖШЁЃseaborn ПђМмАяжњЮвУЧзюДѓГЬЖШЕиМѕЩйДњТыЃЌВЂИпаЇЕиЛцЭМЁЃ

ЭЈЙ§в§ШыЩЋЕїКЭЗжУцЕФИХФюПЩЪгЛЏ 3 ЮЌЗжРрЪ§Он
ЩЯУцЕФЭМБэЧхГўЕиЯдЪОСЫгыУПИіЮЌЖШЯрЙиЕФЦЕТЪЃЌПЩвдПДЕНЃЌЭЈЙ§ЭМБэФмЙЛШнвзгааЇЕиРэНтЯрЙиФкШнЁЃ
ПМТЧЕНПЩЪгЛЏ 3 ЮЌЛьКЯЪєадЃЌЮвУЧПЩвдЪЙгУЩЋЕїЕФИХФюРДНЋЦфжавЛИіЗжРрЪєадПЩЪгЛЏЃЌЭЌЪБЪЙгУДЋЭГЕФШчЩЂЕуЭМРДПЩЪгЛЏЪ§жЕЪєадЕФ 2 ИіЮЌЖШЁЃ

ЭЈЙ§РћгУЩЂЕуЭМКЭЩЋЕїЕФИХФюПЩЪгЛЏ 3 ЮЌЛьКЯЪєад
вђДЫЃЌЩЋЕїзїЮЊРрБ№ЛђШКЬхЕФСМКУЧјЗжЃЌЫфШЛШчЩЯЭМЙлВьУЛгаЯрЙиадЛђЯрЙиадЗЧГЃШѕЃЌЕЋДгетаЉЭМжаЮвУЧШдПЩвдРэНтЃЌгыАзЦЯЬбОЦЯрБШЃЌКьЦЯЬбОЦЕФСђЫсбЮКЌСПНЯИпЁЃФувВПЩвдЪЙгУКЫУмЖШЭМДњЬцЩЂЕуЭМРДРэНт 3 ЮЌЪ§ОнЁЃ

ЭЈЙ§РћгУКЫУмЖШЭМКЭЩЋЕїЕФИХФюПЩЪгЛЏ 3 ЮЌЛьКЯЪєад
гыдЄЦквЛжТЧвЯрЕБУїЯдЃЌКьЦЯЬбОЦбљЦЗБШАзЦЯЬбОЦОпгаИќИпЕФСђЫсбЮКЌСПЁЃФуЛЙПЩвдИљОнЩЋЕїЧПЖШВщПДУмЖШХЈЖШЁЃ
ШчЙћЮвУЧе§дкДІРэгаЖрИіЗжРрЪєадЕФ 3 ЮЌЪ§ОнЃЌЮвУЧПЩвдРћгУЩЋЕїКЭЦфжавЛИіГЃЙцжсНјааПЩЪгЛЏЃЌВЂЪЙгУШчЯфЯпЭМЛђаЁЬсЧйЭМРДПЩЪгЛЏВЛЭЌЕФЪ§ОнзщЁЃ

ЭЈЙ§РћгУЗжЭМаЁЬсЧйЭМКЭЩЋЕїЕФИХФюРДПЩЪгЛЏ 3 ЮЌЛьКЯЪєад
дкЩЯЭМжаЃЌЮвУЧПЩвдПДЕНЃЌдкгвБпЕФ 3 ЮЌПЩЪгЛЏЭМжаЃЌЮвУЧгУ x жсБэЪОЦЯЬбОЦжЪСПЃЌwine_type гУЩЋЕїБэеїЁЃЮвУЧПЩвдЧхГўЕиПДЕНвЛаЉгаШЄЕФМћНтЃЌР§ШчгыАзЦЯЬбОЦЯрБШКьЦЯЬбОЦЕФЛгЗЂадЫсЖШИќИпЁЃ
ФувВПЩвдПМТЧЪЙгУЯфЯпЭМРДДњБэОпгаЖрИіЗжРрБфСПЕФЛьКЯЪєадЁЃ

ЭЈЙ§РћгУЯфЯпЭМКЭЩЋЕїЕФИХФюПЩЪгЛЏ 3 ЮЌЛьКЯЪєад
ЮвУЧПЩвдПДЕНЃЌЖдгкжЪСПКЭ quality_label ЪєадЃЌЦЯЬбОЦОЦОЋКЌСПЖМЛсЫцзХжЪСПЕФЬсИпЖјдіМгЁЃСэЭтКьЦЯЬбОЦгыЯрЭЌЦЗжЪРрБ№ЕФАзЦЯЬбОЦЯрБШОпгаИќИпЕФОЦОЋКЌСПЃЈжаЮЛЪ§ЃЉЁЃШЛЖјЃЌШчЙћМьВщжЪСПЕШМЖЃЌЮвУЧПЩвдПДЕНЃЌЖдгкНЯЕЭЕШМЖЕФЦЯЬбОЦЃЈ3 КЭ 4ЃЉЃЌАзЦЯЬбОЦОЦОЋКЌСПЃЈжаЮЛЪ§ЃЉДѓгкКьЦЯЬбОЦбљЦЗЁЃЗёдђЃЌКьЦЯЬбОЦгыАзЦЯЬбОЦЯрБШЫЦКѕОЦОЋКЌСПЃЈжаЮЛЪ§ЃЉТдИпЁЃ
ПЩЪгЛЏ 4 ЮЌЪ§ОнЃЈ4-DЃЉ
ЛљгкЩЯЪіЬжТлЃЌЮвУЧРћгУЭМБэЕФИїИізщМўПЩЪгЛЏЖрИіЮЌЖШЁЃвЛжжПЩЪгЛЏ 4 ЮЌЪ§ОнЕФЗНЗЈЪЧдкДЋЭГЭМШчЩЂЕуЭМжаРћгУЩюЖШКЭЩЋЕїБэеїЬиЖЈЕФЪ§ОнЮЌЖШЁЃ
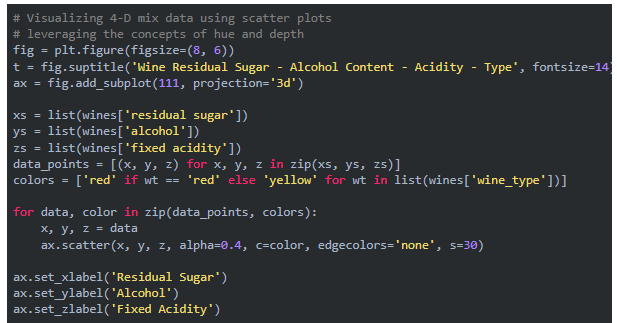

ЭЈЙ§РћгУЩЂЕуЭМвдМАЩЋЕїКЭЩюЖШЕФИХФюПЩЪгЛЏ 4 ЮЌЪ§Он
wine_type ЪєадгЩЩЯЭМжаЕФЩЋЕїБэеїЕУЯрЕБУїЯдЁЃДЫЭтЃЌгЩгкЭМЕФИДдгадЃЌНтЪЭетаЉПЩЪгЛЏПЊЪМБфЕУРЇФбЃЌЕЋЮвУЧШдШЛПЩвдПДГіЃЌР§ШчКьЦЯЬбОЦЕФЙЬЖЈЫсЖШИќИпЃЌАзЦЯЬбОЦЕФВаЬЧИќИпЁЃЕБШЛЃЌШчЙћОЦОЋКЭЙЬЖЈЫсЖШжЎМфгаФГжжСЊЯЕЃЌЮвУЧПЩФмЛсПДЕНвЛИіж№НЅдіМгЛђМѕЩйЕФЪ§ОнЕуЧїЪЦЁЃ
СэвЛИіВпТдЪЧЪЙгУЖўЮЌЭМЃЌЕЋРћгУЩЋЕїКЭЪ§ОнЕуДѓаЁзїЮЊЪ§ОнЮЌЖШЁЃЭЈГЃЧщПіЯТЃЌетНЋРрЫЦгкЦјХнЭМЕШЮвУЧЯШЧАПЩЪгЛЏЕФЭМБэЁЃ


ЭЈЙ§РћгУЦјХнЭМвдМАЩЋЕїКЭДѓаЁЕФИХФюПЩЪгЛЏ 4 ЮЌЪ§Он
ЮвУЧгУЩЋЕїДњБэ wine_type КЭЪ§ОнЕуДѓаЁДњБэВаЬЧЁЃЮвУЧШЗЪЕПДЕНСЫгыЧАУцЭМБэжаЙлВьЕНЕФЯрЫЦФЃЪНЃЌАзЦЯЬбОЦЦјХнГпДчИќДѓБэеїСЫАзЦЯЬбОЦЕФВаЬЧжЕИќИпЁЃ
ШчЙћЮвУЧгаЖргкСНИіЗжРрЪєадБэеїЃЌПЩдкГЃЙцЕФЩЂЕуЭМУшЪіЪ§жЕЪ§ОнЕФЛљДЁЩЯРћгУЩЋЕїКЭЗжУцРДУшЪіетаЉЪєадЁЃЮвУЧРДПДМИИіЪЕР§ЁЃ

ЭЈЙ§РћгУЩЂЕуЭМвдМАЩЋЕїКЭЗжУцЕФИХФюПЩЪгЛЏ 4 ЮЌЪ§Он
етжжПЩЪгЛЏЕФгааЇадЪЙЕУЮвУЧПЩвдЧсЫЩЪЖБ№ЖржжФЃЪНЁЃАзЦЯЬбОЦЕФЛгЗЂЫсЖШНЯЕЭЃЌЭЌЪБИпЦЗжЪЦЯЬбОЦОпгаНЯЕЭЕФЫсЖШЁЃвВЛљгкАзЦЯЬбОЦбљБОЃЌИпЦЗжЪЕФЦЯЬбОЦгаИќИпЕФОЦОЋКЌСПКЭЕЭЦЗжЪЕФЦЯЬбОЦгазюЕЭЕФОЦОЋКЌСПЃЁ
ШУЮвУЧНшжњвЛИіРрЫЦЪЕР§ЃЌВЂНЈСЂвЛИі 4 ЮЌЪ§ОнЕФПЩЪгЛЏЁЃ

ЭЈЙ§РћгУЩЂЕуЭМвдМАЩЋЕїКЭЗжУцЕФИХФюПЩЪгЛЏ 4 ЮЌЪ§Он
ЮвУЧЧхГўЕиПДЕНЃЌИпЦЗжЪЕФЦЯЬбОЦгаНЯЕЭЕФЖўбѕЛЏСђКЌСПЃЌетЪЧЗЧГЃЯрЙиЕФЃЌгыЦЯЬбОЦГЩЗжЕФЯрЙиСьгђжЊЪЖвЛжТЁЃЮвУЧвВПДЕНКьЦЯЬбОЦЕФЖўбѕЛЏСђзмСПЕЭгкАзЦЯЬбОЦЁЃдкМИИіЪ§ОнЕужаЃЌКьЦЯЬбОЦЕФЛгЗЂадЫсЖШЫЎЦННЯИпЁЃ
ПЩЪгЛЏ 5 ЮЌЪ§ОнЃЈ5-DЃЉ
ЮвУЧееОЩзёДгЩЯЮФЬсГіЕФВпТдЃЌвЊЯыПЩЪгЛЏ 5 ЮЌЪ§ОнЃЌЮвУЧвЊРћгУИїжжЛцЭМзщМўЁЃЮвУЧЪЙгУЩюЖШЁЂЩЋЕїЁЂДѓаЁРДБэеїЦфжаЕФШ§ИіЮЌЖШЁЃЦфЫќСНЮЌШдЮЊГЃЙцжсЁЃвђЮЊЮвУЧЛЙЛсгУЕНДѓаЁетИіИХФюЃЌВЂНшДЫЛГівЛИіШ§ЮЌЦјХнЭМЁЃ


РћгУЦјХнЭМКЭЩЋЕїЁЂЩюЖШЁЂДѓаЁЕФИХФюРДПЩЪгЛЏ 5 ЮЌЪ§ОнЁЃ
ЦјХнЭМСщИаРДдДгыЩЯЮФЫљЪівЛжТЁЃЕЋЪЧЃЌЮвУЧЛЙПЩвдПДЕНвдЖўбѕЛЏСђзмСПЮЊжИБъЕФЕуЪ§ЃЌЗЂЯжАзЦЯЬбОЦЕФЖўбѕЛЏСђКЌСПИпгкКьЦЯЬбОЦЁЃ
Г§СЫЩюЖШжЎЭтЃЌЮвУЧЛЙПЩвдЪЙгУЗжУцКЭЩЋЕїРДБэеїетЮхИіЪ§ОнЮЌЖШжаЕФЖрИіЗжРрЪєадЁЃЦфжаБэеїДѓаЁЕФЪєадПЩвдЪЧЪ§жЕБэеїЩѕжСЪЧРрБ№ЃЈЕЋЪЧЮвУЧПЩФмвЊгУЫќЕФЪ§жЕБэеїРДБэеїЪ§ОнЕуДѓаЁЃЉЁЃгЩгкШБЗІРрБ№ЪєадЃЌДЫДІЮвУЧВЛзїеЙЪОЃЌЕЋЪЧФуПЩвддкздМКЕФЪ§ОнМЏЩЯЪдЪдЁЃ


НшжњЩЋЕїЁЂЗжУцЁЂДѓаЁЕФИХФюКЭЦјХнЭМРДПЩЪгЛЏ 5 ЮЌЪ§ОнЁЃ
ЭЈГЃЛЙгавЛИіЧАЮФНщЩмЕФ 5 ЮЌЪ§ОнПЩЪгЛЏЕФБИбЁЗНЗЈЁЃЕБПДЕНЮвУЧЯШЧАЛцжЦЕФЭМЪБЃЌКмЖрШЫПЩФмЛсЖдЖрГіРДЕФЮЌЖШЩюЖШРЇЛѓЁЃИУЭМжиИДРћгУСЫЗжУцЕФЬиадЃЌЫљвдШдПЩвддк 2 ЮЌУцАхЩЯЛцжЦГіРДЧввзгкЫЕУїКЭЛцжЦЁЃ

ЮвУЧвбОСьТдЕНЖрЮЛЪ§ОнПЩЪгЛЏЕФИДдгадЃЁШчЙћЛЙгаШЫЯыЮЪЃЌЮЊКЮВЛдіМгЮЌЖШЃПШУЮвУЧМЬајМђЕЅЬНЫїЯТЃЁ
ПЩЪгЛЏ 6 ЮЌЪ§ОнЃЈ6-DЃЉ
ФПЧАЮвУЧЛЕУКмПЊаФЃЈЮвЯЃЭћЪЧШчДЫЃЁЃЉЮвУЧМЬајдкПЩЪгЛЏжаЬэМгвЛИіЪ§ОнЮЌЖШЁЃЮвУЧНЋРћгУЩюЖШЁЂЩЋЕїЁЂДѓаЁКЭаЮзДМАСНИіГЃЙцжсРДУшЪіЫљга 6 ИіЪ§ОнЮЌЖШЁЃ
ЮвУЧНЋРћгУЩЂЕуЭМКЭЩЋЕїЁЂЩюЖШЁЂаЮзДЁЂДѓаЁЕФИХФюРДПЩЪгЛЏ 6 ЮЌЪ§ОнЁЃ


етПЩЪЧдквЛеХЭМЩЯЛГі 6 ЮЌЪ§ОнЃЁЮвУЧгУаЮзДБэеїЦЯЬбОЦЕФжЪСПБъзЂЃЌгХжЪЃЈгУЗНПщБъМЧЃЉЃЌвЛАуЃЈгУ x БъМЧЃЉЃЌВюЃЈгУдВБъМЧЃЉЃКгУЩЋЕїБэЪОКьОЦЕФРраЭЃЌгЩЩюЖШКЭЪ§ОнЕуДѓаЁШЗЖЈЕФЫсЖШБэеїзмЖўбѕЛЏСђКЌСПЁЃ
етИіНтЪЭЦ№РДПЩФмгаЕуЗбОЂЃЌЕЋЪЧдкЪдЭМРэНтЖрЮЌЪ§ОнЕФвўВиаХЯЂЪБЃЌзюКУНсКЯвЛаЉЛцЭМзщМўНЋЦфПЩЪгЛЏЁЃ
- НсКЯаЮзДКЭ y жсЕФБэЯжЃЌЮвУЧжЊЕРИпжаЕЕЕФЦЯЬбОЦЕФОЦОЋКЌСПБШЕЭжЪЦЯЬбОЦИќИпЁЃ
- НсКЯЩЋЕїКЭДѓаЁЕФБэЯжЃЌЮвУЧжЊЕРАзЦЯЬбОЦЕФзмЖўбѕЛЏСђКЌСПБШКьЦЯЬбОЦИќИпЁЃ
- НсКЯЩюЖШКЭЩЋЕїЕФБэЯжЃЌЮвУЧжЊЕРАзЦЯЬбОЦЕФЫсЖШБШКьЦЯЬбОЦИќЕЭЁЃ
- НсКЯЩЋЕїКЭ x жсЕФБэЯжЃЌЮвУЧжЊЕРКьЦЯЬбОЦЕФВаЬЧБШАзЦЯЬбОЦИќЕЭЁЃ
- НсКЯЩЋЕїКЭаЮзДЕФБэЯжЃЌЫЦКѕАзЦЯЬбОЦЕФИпЦЗжЪВњСПИпгкКьЦЯЬбОЦЁЃЃЈПЩФмЪЧгЩгкАзЦЯЬбОЦЕФбљБОСПНЯДѓЃЉ
ЮвУЧвВПЩвдгУЗжУцЪєадРДДњЬцЩюЖШЙЙНЈ 6 ЮЌЪ§ОнПЩЪгЛЏаЇЙћЁЃ


НшжњЩЋЕїЁЂЩюЖШЁЂУцЁЂДѓаЁЕФИХФюКЭЩЂЕуЭМРДПЩЪгЛЏ 6 ЮЌЪ§ОнЁЃ
вђДЫЃЌдкетжжЧщПіЯТЃЌЮвУЧРћгУЗжУцКЭЩЋЕїРДБэеїШ§ИіЗжРрЪєадЃЌВЂЪЙгУСНИіГЃЙцжсКЭДѓаЁРДБэеї 6 ЮЌЪ§ОнПЩЪгЛЏЕФШ§ИіЪ§жЕЪєадЁЃ
ЫФЁЂНсТл
Ъ§ОнПЩЪгЛЏгыПЦбЇвЛбљживЊЁЃШчЙћФуПДЕНетЃЌЮвКмаРЮПФуФмМсГжПДЭъетЦЊГЄЮФЁЃЮвУЧЕФФПЕФВЛЪЧЮЊСЫМЧзЁЫљгаЪ§ОнЃЌвВВЛЪЧИјГівЛЬзЙЬЖЈЕФЪ§ОнПЩЪгЛЏЙцдђЁЃБОЮФЕФжївЊФПЕФЪЧРэНтВЂбЇЯАИпаЇЕФЪ§ОнПЩЪгЛЏВпТдЃЌгШЦфЪЧЕБЪ§ОнЮЌЖШдіДѓЪБЁЃЯЃЭћФувдКѓПЩвдгУБОЮФжЊЪЖПЩЪгЛЏФуздМКЕФЪ§ОнМЏ
|








