| БрМЭЦМі: |
БОЮФжївЊНщЩм
дкЪ§ОндДЭЗМгЧПЦѓвЕЪ§ОнЕФжЮРэЃЌШУГЃЬЌЛЏжЮРэГЩЮЊШеГЃвЕЮёЃЌВХФмДгИљБОЩЯГЙЕзНтОіЦѓвЕЪ§ОнжЪСПЕФИїжжЮЪЬтЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгк
Ъ§РНЩчЧј
ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЪ§ОнВжПт
Ъ§ОнВжПтИХФю
гЂЮФУћГЦЮЊData WarehouseЃЌПЩМђаДЮЊDWЛђDWHЁЃЪ§ОнВжПтЕФФПЕФЪЧЙЙНЈУцЯђЗжЮіЕФМЏГЩЛЏЪ§ОнЛЗОГЃЌЮЊЦѓвЕЬсЙЉОіВпжЇГжЃЈDecision SupportЃЉЁЃЫќГігкЗжЮіадБЈИцКЭОіВпжЇГжФПЕФЖјДДНЈЁЃ
Ъ§ОнВжПтБОЩэВЂВЛЁАЩњВњЁБШЮКЮЪ§ОнЃЌЭЌЪБздЩэвВВЛашвЊЁАЯћЗбЁБШЮКЮЕФЪ§ОнЃЌЪ§ОнРДдДгкЭтВПЃЌВЂЧвПЊЗХИјЭтВПгІгУЃЌетвВЪЧЮЊЪВУДНаЁАВжПтЁБЃЌЖјВЛНаЁАЙЄГЇЁБЕФдвђЁЃ
ЛљБОЬиеї
Ъ§ОнВжПтЪЧУцЯђжїЬтЕФЁЂМЏГЩЕФЁЂЗЧвзЪЇЕФКЭЪББфЕФЪ§ОнМЏКЯЃЌгУвджЇГжЙмРэОіВпЁЃ
УцЯђжїЬт:
ДЋЭГЪ§ОнПтжаЃЌзюДѓЕФЬиЕуЪЧУцЯђгІгУНјааЪ§ОнЕФзщжЏЃЌИїИівЕЮёЯЕЭГПЩФмЪЧЯрЛЅЗжРыЕФЁЃЖјЪ§ОнВжПтдђЪЧУцЯђжїЬтЕФЁЃжїЬтЪЧвЛИіГщЯѓЕФИХФюЃЌЪЧНЯИпВуДЮЩЯЦѓвЕаХЯЂЯЕЭГжаЕФЪ§ОнзлКЯЁЂЙщРрВЂНјааЗжЮіРћгУЕФГщЯѓЁЃдкТпМвтвхЩЯЃЌЫќЪЧЖдгІЦѓвЕжаФГвЛКъЙлЗжЮіСьгђЫљЩцМАЕФЗжЮіЖдЯѓЁЃ
МЏГЩад:
ЭЈЙ§ЖдЗжЩЂЁЂЖРСЂЁЂвьЙЙЕФЪ§ОнПтЪ§ОнНјааГщШЁЁЂЧхРэЁЂзЊЛЛКЭЛузмБуЕУЕНСЫЪ§ОнВжПтЕФЪ§ОнЃЌетбљБЃжЄСЫЪ§ОнВжПтФкЕФЪ§ОнЙигкећИіЦѓвЕЕФвЛжТадЁЃ
Ъ§ОнВжПтжаЕФзлКЯЪ§ОнВЛФмДгдгаЕФЪ§ОнПтЯЕЭГжБНгЕУЕНЁЃвђДЫдкЪ§ОнНјШыЪ§ОнВжПтжЎЧАЃЌБиШЛвЊОЙ§ЭГвЛгызлКЯЃЌетвЛВНЪЧЪ§ОнВжПтНЈЩшжазюЙиМќЁЂзюИДдгЕФвЛВНЃЌЫљвЊЭъГЩЕФЙЄзїгаЃК
вЊЭГвЛдДЪ§ОнжаЫљгаУЌЖмжЎДІЃЌШчзжЖЮЕФЭЌУћвьвхЁЂвьУћЭЌвхЁЂЕЅЮЛВЛЭГвЛЁЂзжГЄВЛвЛжТЃЌЕШЕШЁЃ
НјааЪ§ОнзлКЯКЭМЦЫуЁЃЪ§ОнВжПтжаЕФЪ§ОнзлКЯЙЄзїПЩвддкДгдгаЪ§ОнПтГщШЁЪ§ОнЪБЩњГЩЃЌЕЋаэЖрЪЧдкЪ§ОнВжПтФкВПЩњГЩЕФЃЌМДНјШыЪ§ОнВжПтвдКѓНјаазлКЯЩњГЩЕФЁЃ
ЯТЭМЫЕУївЛИіБЃЯеЙЋЫОзлКЯЪ§ОнЕФМђЕЅДІРэЙ§ГЬЃЌЦфжаЪ§ОнВжПтжагыЁАБЃЯеЁБ жїЬтгаЙиЕФЪ§ОнРДздгкЖрИіВЛЭЌЕФВйзїаЭЯЕЭГЁЃетаЉЯЕЭГФкВПЪ§ОнЕФУќУћПЩФмВЛЭЌЃЌЪ§ОнИёЪНвВПЩФмВЛЭЌЁЃАбВЛЭЌРДдДЕФЪ§ОнДцДЂЕНЪ§ОнВжПтжЎЧАЃЌашвЊШЅГ§етаЉВЛвЛжТЁЃ

ЗЧвзЪЇадЃЈВЛПЩИќаТадЃЉ
Ъ§ОнВжПтЕФЪ§ОнЗДгГЕФЪЧвЛЖЮЯрЕБГЄЕФЪБМфФкРњЪЗЪ§ОнЕФФкШнЃЌЪЧВЛЭЌЪБЕуЕФЪ§ОнПтПьееЕФМЏКЯЃЌвдМАЛљгкетаЉПьееНјааЭГМЦЁЂзлКЯКЭжизщЕФЕМГіЪ§ОнЁЃ
Ъ§ОнЗЧвзЪЇаджївЊЪЧеыЖдгІгУЖјбдЁЃЪ§ОнВжПтЕФгУЛЇЖдЪ§ОнЕФВйзїДѓЖрЪЧЪ§ОнВщбЏЛђБШНЯИДдгЕФЭкОђЃЌвЛЕЉЪ§ОнНјШыЪ§ОнВжПтвдКѓЃЌвЛАуЧщПіЯТБЛНЯГЄЪБМфБЃСєЁЃЪ§ОнВжПтжавЛАугаДѓСПЕФВщбЏВйзїЃЌЕЋаоИФКЭЩОГ§ВйзїКмЩйЁЃвђДЫЃЌЪ§ОнОМгЙЄКЭМЏГЩНјШыЪ§ОнВжПтКѓЪЧМЋЩйИќаТЕФЃЌЭЈГЃжЛашвЊЖЈЦкЕФМгдиКЭИќаТЁЃ
ЪББфад
Ъ§ОнВжПтАќКЌИїжжСЃЖШЕФРњЪЗЪ§ОнЁЃЪ§ОнВжПтжаЕФЪ§ОнПЩФмгыФГИіЬиЖЈШеЦкЁЂаЧЦкЁЂдТЗнЁЂМОЖШЛђепФъЗнгаЙиЁЃЪ§ОнВжПтЕФФПЕФЪЧЭЈЙ§ЗжЮіЦѓвЕЙ§ШЅвЛЖЮЪБМфвЕЮёЕФОгЊзДПіЃЌЭкОђЦфжавўВиЕФФЃЪНЁЃЫфШЛЪ§ОнВжПтЕФгУЛЇВЛФмаоИФЪ§ОнЃЌЕЋВЂВЛЪЧЫЕЪ§ОнВжПтЕФЪ§ОнЪЧгРдЖВЛБфЕФЁЃЗжЮіЕФНсЙћжЛФмЗДгГЙ§ШЅЕФЧщПіЃЌЕБвЕЮёБфЛЏКѓЃЌЭкОђГіЕФФЃЪНЛсЪЇШЅЪБаЇадЁЃвђДЫЪ§ОнВжПтЕФЪ§ОнашвЊИќаТЃЌвдЪЪгІОіВпЕФашвЊЁЃДгетИіНЧЖШНВЃЌЪ§ОнВжПтНЈЩшЪЧвЛИіЯюФПЃЌИќЪЧвЛИіЙ§ГЬЁЃЪ§ОнВжПтЕФЪ§ОнЫцЪБМфЕФБфЛЏБэЯждквдЯТМИИіЗНУцЃК
ЃЈ1ЃЉ Ъ§ОнВжПтЕФЪ§ОнЪБЯовЛАувЊдЖдЖГЄгкВйзїаЭЪ§ОнЕФЪ§ОнЪБЯоЁЃ
ЃЈ2ЃЉ ВйзїаЭЯЕЭГДцДЂЕФЪЧЕБЧАЪ§ОнЃЌЖјЪ§ОнВжПтжаЕФЪ§ОнЪЧРњЪЗЪ§ОнЁЃ
ЃЈ3ЃЉ Ъ§ОнВжПтжаЕФЪ§ОнЪЧАДееЪБМфЫГађзЗМгЕФЃЌЫќУЧЖМДјгаЪБМфЪєадЁЃ
Ъ§ОнВжПтгыЪ§ОнПтЕФЧјБ№
Ъ§ОнПтгыЪ§ОнВжПтЕФЧјБ№ЪЕМЪНВЕФЪЧ OLTP гы OLAP ЕФЧјБ№ЁЃ
ВйзїаЭДІРэЃЌНаСЊЛњЪТЮёДІРэ OLTPЃЈOn-Line Transaction ProcessingЃЌЃЉЃЌвВПЩвдГЦУцЯђНЛвзЕФДІРэЯЕЭГЃЌЫќЪЧеыЖдОпЬхвЕЮёдкЪ§ОнПтСЊЛњЕФШеГЃВйзїЃЌЭЈГЃЖдЩйЪ§МЧТМНјааВщбЏЁЂаоИФЁЃ гУЛЇНЯЮЊЙиаФВйзїЕФЯьгІЪБМфЁЂЪ§ОнЕФАВШЋадЁЂЭъећадКЭВЂЗЂжЇГжЕФгУЛЇЪ§ЕШЮЪЬтЁЃ ДЋЭГЕФЪ§ОнПтЯЕЭГзїЮЊЪ§ОнЙмРэЕФжївЊЪжЖЮЃЌжївЊгУгкВйзїаЭДІРэЃЌЯёMysqlЃЌOracleЕШЙиЯЕаЭЪ§ОнПтвЛАуЪєгкOLTPЁЃ
ЗжЮіаЭДІРэЃЌНаСЊЛњЗжЮіДІРэ OLAPЃЈOn-Line Analytical ProcessingЃЉвЛАуеыЖдФГаЉжїЬтЕФРњЪЗЪ§ОнНјааЗжЮіЃЌжЇГжЙмРэОіВпЁЃ
ЪзЯШвЊУїАзЃЌЪ§ОнВжПтЕФГіЯжЃЌВЂВЛЪЧвЊШЁДњЪ§ОнПтЁЃЪ§ОнПтЪЧУцЯђЪТЮёЕФЩшМЦЃЌЪ§ОнВжПтЪЧУцЯђжїЬтЩшМЦЕФЁЃЪ§ОнПтвЛАуДцДЂвЕЮёЪ§ОнЃЌЪ§ОнВжПтДцДЂЕФвЛАуЪЧРњЪЗЪ§ОнЁЃ
Ъ§ОнПтЩшМЦЪЧОЁСПБмУтШпгрЃЌвЛАуеыЖдФГвЛвЕЮёгІгУНјааЩшМЦЃЌБШШчвЛеХМђЕЅЕФUserБэЃЌМЧТМгУЛЇУћЁЂУмТыЕШМђЕЅЪ§ОнМДПЩЃЌЗћКЯвЕЮёгІгУЃЌЕЋЪЧВЛЗћКЯЗжЮіЁЃ Ъ§ОнВжПтдкЩшМЦЪЧгавтв§ШыШпгрЃЌвРееЗжЮіашЧѓЃЌЗжЮіЮЌЖШЁЂЗжЮіжИБъНјааЩшМЦЁЃ
Ъ§ОнПтЪЧЮЊВЖЛёЪ§ОнЖјЩшМЦЃЌЪ§ОнВжПтЪЧЮЊЗжЮіЪ§ОнЖјЩшМЦЁЃ
вдвјаавЕЮёЮЊР§ЁЃЪ§ОнПтЪЧЪТЮёЯЕЭГЕФЪ§ОнЦНЬЈЃЌПЭЛЇдквјаазіЕФУПБЪНЛвзЖМЛсаДШыЪ§ОнПтЃЌБЛМЧТМЯТРДЃЌетРяЃЌПЩвдМђЕЅЕиРэНтЮЊгУЪ§ОнПтМЧеЫЁЃЪ§ОнВжПтЪЧЗжЮіЯЕЭГЕФЪ§ОнЦНЬЈЃЌЫќДгЪТЮёЯЕЭГЛёШЁЪ§ОнЃЌВЂзіЛузмЁЂМгЙЄЃЌЮЊОіВпепЬсЙЉОіВпЕФвРОнЁЃБШШчЃЌФГвјааФГЗжаавЛИідТЗЂЩњЖрЩйНЛвзЃЌИУЗжааЕБЧАДцПюгрЖюЪЧЖрЩйЁЃШчЙћДцПюгжЖрЃЌЯћЗбНЛвзгжЖрЃЌФЧУДИУЕиЧјОЭгаБивЊЩшСЂATMСЫЁЃ
ЯдШЛЃЌвјааЕФНЛвзСПЪЧОоДѓЕФЃЌЭЈГЃвдАйЭђЩѕжСЧЇЭђДЮРДМЦЫуЁЃЪТЮёЯЕЭГЪЧЪЕЪБЕФЃЌетОЭвЊЧѓЪБаЇадЃЌПЭЛЇДцвЛБЪЧЎашвЊМИЪЎУыЪЧЮоЗЈШЬЪмЕФЃЌетОЭвЊЧѓЪ§ОнПтжЛФмДцДЂКмЖЬвЛЖЮЪБМфЕФЪ§ОнЁЃЖјЗжЮіЯЕЭГЪЧЪТКѓЕФЃЌЫќвЊЬсЙЉЙизЂЪБМфЖЮФкЫљгаЕФгааЇЪ§ОнЁЃетаЉЪ§ОнЪЧКЃСПЕФЃЌЛузмМЦЫуЦ№РДвВвЊТ§вЛаЉЃЌЕЋЪЧЃЌжЛвЊФмЙЛЬсЙЉгааЇЕФЗжЮіЪ§ОнОЭДяЕНФПЕФСЫЁЃ
Ъ§ОнВжПтЃЌЪЧдкЪ§ОнПтвбОДѓСПДцдкЕФЧщПіЯТЃЌЮЊСЫНјвЛВНЭкОђЪ§ОнзЪдДЁЂЮЊСЫОіВпашвЊЖјВњЩњЕФЃЌЫќОіВЛЪЧЫљЮНЕФЁАДѓаЭЪ§ОнПтЁБЁЃ
Ъ§ОнВжПтЗжВуМмЙЙ
АДееЪ§ОнСїШыСїГіЕФЙ§ГЬЃЌЪ§ОнВжПтМмЙЙПЩЗжЮЊЃК дДЪ§ОнЁЂЪ§ОнВжПтЁЂЪ§ОнгІгУ

Ъ§ОнВжПт
Ъ§ОнВжПтЕФЪ§ОнРДдДгкВЛЭЌЕФдДЪ§ОнЃЌВЂЬсЙЉЖрбљЕФЪ§ОнгІгУЃЌЪ§ОнздЯТЖјЩЯСїШыЪ§ОнВжПтКѓЯђЩЯВуПЊЗХгІгУЃЌЖјЪ§ОнВжПтжЛЪЧжаМфМЏГЩЛЏЪ§ОнЙмРэЕФвЛИіЦНЬЈЁЃ
дДЪ§Он ЃКДЫВуЪ§ОнЮоШЮКЮИќИФЃЌжБНгбигУЭтЮЇЯЕЭГЪ§ОнНсЙЙКЭЪ§ОнЃЌВЛЖдЭтПЊЗХЃЛЮЊСйЪБДцДЂВуЃЌЪЧНгПкЪ§ОнЕФСйЪБДцДЂЧјгђЃЌЮЊКѓвЛВНЕФЪ§ОнДІРэзізМБИЁЃ
Ъ§ОнВжПт ЃКвВГЦЮЊЯИНкВуЃЌDWВуЕФЪ§ОнгІИУЪЧвЛжТЕФЁЂзМШЗЕФЁЂИЩОЛЕФЪ§ОнЃЌМДЖддДЯЕЭГЪ§ОнНјааСЫЧхЯДЃЈШЅГ§СЫдгжЪЃЉКѓЕФЪ§ОнЁЃ
Ъ§ОнгІгУ ЃКЧАЖЫгІгУжБНгЖСШЁЕФЪ§ОндДЃЛИљОнБЈБэЁЂзЈЬтЗжЮіашЧѓЖјМЦЫуЩњГЩЕФЪ§ОнЁЃ
Ъ§ОнВжПтДгИїЪ§ОндДЛёШЁЪ§ОнМАдкЪ§ОнВжПтФкЕФЪ§ОнзЊЛЛКЭСїЖЏЖМПЩвдШЯЮЊЪЧETL ЃЈГщШЁExtra, зЊЛЏTransfer, зАдиLoadЃЉ ЕФЙ§ГЬЃЌETLЪЧЪ§ОнВжПтЕФСїЫЎЯпЃЌвВПЩвдШЯЮЊЪЧЪ§ОнВжПтЕФбЊвКЃЌЫќЮЌЯЕзХЪ§ОнВжПтжаЪ§ОнЕФаТГТДњаЛЃЌЖјЪ§ОнВжПтШеГЃЕФЙмРэКЭЮЌЛЄЙЄзїЕФДѓВПЗжОЋСІОЭЪЧБЃГжETLЕФе§ГЃКЭЮШЖЈЁЃ
ФЧУДЮЊЪВУДвЊЪ§ОнВжПтНјааЗжВуФи?
гУПеМфЛЛЪБМфЃЌЭЈЙ§ДѓСПЕФдЄДІРэРДЬсЩ§гІгУЯЕЭГЕФгУЛЇЬхбщЃЈаЇТЪЃЉЃЌвђДЫЪ§ОнВжПтЛсДцдкДѓСПШпгрЕФЪ§ОнЃЛВЛЗжВуЕФЛАЃЌШчЙћдДвЕЮёЯЕЭГЕФвЕЮёЙцдђЗЂЩњБфЛЏНЋЛсгАЯьећИіЪ§ОнЧхЯДЙ§ГЬЃЌЙЄзїСПОоДѓЁЃ
ЭЈЙ§Ъ§ОнЗжВуЙмРэПЩвдМђЛЏЪ§ОнЧхЯДЕФЙ§ГЬЃЌвђЮЊАбдРДвЛВНЕФЙЄзїЗжЕНСЫЖрИіВНжшШЅЭъГЩЃЌЯрЕБгкАбвЛИіИДдгЕФЙЄзїВ№ГЩСЫЖрИіМђЕЅЕФЙЄзїЃЌАбвЛИіДѓЕФКкКаБфГЩСЫвЛИіАзКаЃЌУПвЛВуЕФДІРэТпМЖМЯрЖдМђЕЅКЭШнвзРэНтЃЌетбљЮвУЧБШНЯШнвзБЃжЄУПвЛИіВНжшЕФе§ШЗадЃЌЕБЪ§ОнЗЂЩњДэЮѓЕФЪБКђЃЌЭљЭљЮвУЧжЛашвЊОжВПЕїећФГИіВНжшМДПЩЁЃ
Ъ§ОнВжПтдЊЪ§ОнЕФЙмРэ
дЊЪ§ОнЃЈMeta DateЃЉЃЌжївЊМЧТМЪ§ОнВжПтжаФЃаЭЕФЖЈвхЁЂИїВуМЖМфЕФгГЩфЙиЯЕЁЂМрПиЪ§ОнВжПтЕФЪ§ОнзДЬЌМАETLЕФШЮЮёдЫаазДЬЌЁЃ вЛАуЛсЭЈЙ§дЊЪ§ОнзЪСЯПтЃЈMetadata RepositoryЃЉРДЭГвЛЕиДцДЂКЭЙмРэдЊЪ§ОнЃЌЦфжївЊФПЕФЪЧЪЙЪ§ОнВжПтЕФЩшМЦЁЂВПЪ№ЁЂВйзїКЭЙмРэФмДяГЩаЭЌКЭвЛжТЁЃ
дЊЪ§ОнЪЧЪ§ОнВжПтЙмРэЯЕЭГЕФживЊзщГЩВПЗжЃЌдЊЪ§ОнЙмРэЪЧЦѓвЕМЖЪ§ОнВжПтжаЕФЙиМќзщМўЃЌЙсДЉЪ§ОнВжПтЙЙНЈЕФећИіЙ§ГЬЃЌжБНггАЯьзХЪ§ОнВжПтЕФЙЙНЈЁЂЪЙгУКЭЮЌЛЄЁЃ
ЙЙНЈЪ§ОнВжПтЕФжївЊВНжшжЎвЛЪЧETLЁЃетЪБдЊЪ§ОнНЋЗЂЛгживЊЕФзїгУЃЌЫќЖЈвхСЫдДЪ§ОнЯЕЭГЕНЪ§ОнВжПтЕФгГЩфЁЂЪ§ОнзЊЛЛЕФЙцдђЁЂЪ§ОнВжПтЕФТпМНсЙЙЁЂЪ§ОнИќаТЕФЙцдђЁЂЪ§ОнЕМШыРњЪЗМЧТМвдМАзАдижмЦкЕШЯрЙиФкШнЁЃЪ§ОнГщШЁКЭзЊЛЛЕФзЈМввдМАЪ§ОнВжПтЙмРэдБе§ЪЧЭЈЙ§дЊЪ§ОнИпаЇЕиЙЙНЈЪ§ОнВжПтЁЃ
гУЛЇдкЪЙгУЪ§ОнВжПтЪБЃЌЭЈЙ§дЊЪ§ОнЗУЮЪЪ§ОнЃЌУїШЗЪ§ОнЯюЕФКЌвхвдМАЖЈжЦБЈБэЁЃ
Ъ§ОнВжПтЕФЙцФЃМАЦфИДдгадРыВЛПЊе§ШЗЕФдЊЪ§ОнЙмРэЃЌАќРЈдіМгЛђвЦГ§ЭтВПЪ§ОндДЃЌИФБфЪ§ОнЧхЯДЗНЗЈЃЌПижЦГіДэЕФВщбЏвдМААВХХБИЗнЕШЁЃ
дЊЪ§ОнПЩЗжЮЊММЪѕдЊЪ§ОнКЭвЕЮёдЊЪ§ОнЁЃ ММЪѕдЊЪ§Он ЮЊПЊЗЂКЭЙмРэЪ§ОнВжПтЕФIT ШЫдБЪЙгУЃЌЫќУшЪіСЫгыЪ§ОнВжПтПЊЗЂЁЂЙмРэКЭЮЌЛЄЯрЙиЕФЪ§ОнЃЌАќРЈЪ§ОндДаХЯЂЁЂЪ§ОнзЊЛЛУшЪіЁЂЪ§ОнВжПтФЃаЭЁЂЪ§ОнЧхЯДгыИќаТЙцдђЁЂЪ§ОнгГЩфКЭЗУЮЪШЈЯоЕШЁЃЖј вЕЮёдЊЪ§Он ЮЊЙмРэВуКЭвЕЮёЗжЮіШЫдБЗўЮёЃЌДгвЕЮёНЧЖШУшЪіЪ§ОнЃЌАќРЈЩЬЮёЪѕгяЁЂЪ§ОнВжПтжагаЪВУДЪ§ОнЁЂЪ§ОнЕФЮЛжУКЭЪ§ОнЕФПЩгУадЕШЃЌАяжњвЕЮёШЫдБИќКУЕиРэНтЪ§ОнВжПтжаФФаЉЪ§ОнЪЧПЩгУЕФвдМАШчКЮЪЙгУЁЃ
гЩЩЯПЩМћЃЌдЊЪ§ОнВЛНіЖЈвхСЫЪ§ОнВжПтжаЪ§ОнЕФФЃЪНЁЂРДдДЁЂГщШЁКЭзЊЛЛЙцдђЕШЃЌЖјЧвЪЧећИіЪ§ОнВжПтЯЕЭГдЫааЕФЛљДЁЃЌдЊЪ§ОнАбЪ§ОнВжПтЯЕЭГжаИїИіЫЩЩЂЕФзщМўСЊЯЕЦ№РДЃЌзщГЩСЫвЛИігаЛњЕФећЬхЁЃ
Ъ§ВжНЈФЃЗНЗЈ
Ъ§ОнВжПтЕФНЈФЃЗНЗЈгаКмЖржжЃЌУПвЛжжНЈФЃЗНЗЈДњБэСЫембЇЩЯЕФвЛИіЙлЕуЃЌДњБэСЫвЛжжЙщФЩЁЂИХРЈЪРНчЕФвЛжжЗНЗЈЁЃГЃМћЕФга ЗЖЪННЈФЃЗЈЁЂЮЌЖШНЈФЃЗЈЁЂЪЕЬхНЈФЃЗЈ ЕШЃЌУПжжЗНЗЈДгБОжЪЩЯНЋЪЧДгВЛЭЌЕФНЧЖШПДД§вЕЮёжаЕФЮЪЬтЁЃ
1. ЗЖЪННЈФЃЗЈЃЈThird Normal FormЃЌ3NFЃЉ
ЗЖЪННЈФЃЗЈЦфЪЕЪЧЮвУЧдкЙЙНЈЪ§ОнФЃаЭГЃгУЕФвЛИіЗНЗЈЃЌИУЗНЗЈЕФжївЊгЩ Inmon ЫљЬсГЋЃЌжївЊНтОіЙиЯЕаЭЪ§ОнПтЕФЪ§ОнДцДЂЃЌРћгУЕФвЛжжММЪѕВуУцЩЯЕФЗНЗЈЁЃФПЧАЃЌЮвУЧдкЙиЯЕаЭЪ§ОнПтжаЕФНЈФЃЗНЗЈЃЌДѓВПЗжВЩгУЕФЪЧШ§ЗЖЪННЈФЃЗЈЁЃ
ЗЖЪН ЪЧЗћКЯФГвЛжжМЖБ№ЕФЙиЯЕФЃЪНЕФМЏКЯЁЃЙЙдьЪ§ОнПтБиаызёбвЛЖЈЕФЙцдђЃЌЖјдкЙиЯЕаЭЪ§ОнПтжаетжжЙцдђОЭЪЧЗЖЪНЃЌетвЛЙ§ГЬвВБЛГЦЮЊЙцЗЖЛЏЁЃФПЧАЙиЯЕЪ§ОнПтгаСљжжЗЖЪНЃКЕквЛЗЖЪНЃЈ1NFЃЉЁЂЕкЖўЗЖЪНЃЈ2NFЃЉЁЂЕкШ§ЗЖЪНЃЈ3NFЃЉЁЂBoyce-CoddЗЖЪНЃЈBCNFЃЉЁЂЕкЫФЗЖЪНЃЈ4NFЃЉКЭЕкЮхЗЖЪНЃЈ5NFЃЉЁЃ
дкЪ§ОнВжПтЕФФЃаЭЩшМЦжаЃЌвЛАуВЩгУЕкШ§ЗЖЪНЁЃвЛИіЗћКЯЕкШ§ЗЖЪНЕФЙиЯЕБиаыОпгавдЯТШ§ИіЬѕМў :
УПИіЪєаджЕЮЈвЛЃЌВЛОпгаЖрвхад ;
УПИіЗЧжїЪєадБиаыЭъШЋвРРЕгкећИіжїМќЃЌЖјЗЧжїМќЕФвЛВПЗж ;
УПИіЗЧжїЪєадВЛФмвРРЕгкЦфЫћЙиЯЕжаЕФЪєадЃЌвђЮЊетбљЕФЛАЃЌетжжЪєадгІИУЙщЕНЦфЫћЙиЯЕжаШЅЁЃ

ЗЖЪННЈФЃ
ИљОн Inmon ЕФЙлЕуЃЌЪ§ОнВжПтФЃаЭЕФНЈЩшЗНЗЈКЭвЕЮёЯЕЭГЕФЦѓвЕЪ§ОнФЃаЭРрЫЦЁЃдквЕЮёЯЕЭГжаЃЌЦѓвЕЪ§ОнФЃаЭОіЖЈСЫЪ§ОнЕФРДдДЃЌЖјЦѓвЕЪ§ОнФЃаЭвВЗжЮЊСНИіВуДЮЃЌМДжїЬтгђФЃаЭКЭТпМФЃаЭЁЃЭЌбљЃЌжїЬтгђФЃаЭПЩвдПДГЩЪЧвЕЮёФЃаЭЕФИХФюФЃаЭЃЌЖјТпМФЃаЭдђЪЧгђФЃаЭдкЙиЯЕаЭЪ§ОнПтЩЯЕФЪЕР§ЛЏЁЃ
2. ЮЌЖШНЈФЃЗЈЃЈDimensional ModelingЃЉ
ЮЌЖШФЃаЭЪЧЪ§ОнВжПтСьгђСэвЛЮЛДѓЪІRalph KimallЫљГЋЕМЃЌЫћЕФЁЖЪ§ОнВжПтЙЄОпЯфЁЗЪЧЪ§ОнВжПтЙЄГЬСьгђзюСїааЕФЪ§ВжНЈФЃОЕфЁЃЮЌЖШНЈФЃвдЗжЮіОіВпЕФашЧѓГіЗЂЙЙНЈФЃаЭЃЌЙЙНЈЕФЪ§ОнФЃаЭЮЊЗжЮіашЧѓЗўЮёЃЌвђДЫЫќжиЕуНтОігУЛЇШчКЮИќПьЫйЭъГЩЗжЮіашЧѓЃЌЭЌЪБЛЙгаНЯКУЕФДѓЙцФЃИДдгВщбЏЕФЯьгІадФмЁЃ

ЮЌЖШНЈФЃ
ЕфаЭЕФДњБэЪЧЮвУЧБШНЯЪьжЊЕФаЧаЮФЃаЭЃЈStar-schemaЃЉЃЌвдМАдквЛаЉЬиЪтГЁОАЯТЪЪгУЕФбЉЛЈФЃаЭЃЈSnow-schemaЃЉЁЃ
ЮЌЖШНЈФЃжаБШНЯживЊЕФИХФюОЭЪЧ ЪТЪЕБэЃЈFact tableЃЉКЭЮЌЖШБэЃЈDimension tableЃЉЁЃЦфзюМђЕЅЕФУшЪіОЭЪЧЃЌАДееЪТЪЕБэЁЂЮЌЖШБэРДЙЙНЈЪ§ОнВжПтЁЂЪ§ОнМЏЪаЁЃ
ФПЧАдкЛЅСЊЭјЙЋЫОзюГЃгУЕФНЈФЃЗНЗЈОЭЪЧЮЌЖШНЈФЃЃЌЩдКѓНЋжиЕуНВНт
3. ЪЕЬхНЈФЃЗЈЃЈEntity ModelingЃЉ
ЪЕЬхНЈФЃЗЈВЂВЛЪЧЪ§ОнВжПтНЈФЃжаГЃМћЕФвЛИіЗНЗЈЃЌЫќРДдДгкембЇЕФвЛИіСїХЩЁЃДгембЇЕФвтвхЩЯЫЕЃЌПЭЙлЪРНчгІИУЪЧПЩвдЯИЗжЕФЃЌПЭЙлЪРНчгІИУПЩвдЗжГЩгЩвЛИіИіЪЕЬхЃЌвдМАЪЕЬхгыЪЕЬхжЎМфЕФЙиЯЕзщГЩЁЃФЧУДЮвУЧдкЪ§ОнВжПтЕФНЈФЃЙ§ГЬжаЭъШЋПЩвдв§ШыетИіГщЯѓЕФЗНЗЈЃЌНЋећИівЕЮёвВПЩвдЛЎЗжГЩвЛИіИіЕФЪЕЬхЃЌЖјУПИіЪЕЬхжЎМфЕФЙиЯЕЃЌвдМАеыЖдетаЉЙиЯЕЕФЫЕУїОЭЪЧЮвУЧЪ§ОнНЈФЃашвЊзіЕФЙЄзїЁЃ
ЫфШЛЪЕЬхЗЈДжПДЦ№РДКУЯёгавЛаЉГщЯѓЃЌЦфЪЕРэНтЦ№РДКмШнвзЁЃМДЮвУЧПЩвдНЋШЮКЮвЛИівЕЮёЙ§ГЬЛЎЗжГЩ 3 ИіВПЗжЃЌ ЪЕЬхЃЌЪТМўЃЌЫЕУї ЃЌШчЯТЭМЫљЪОЃК

ЪЕЬхНЈФЃ
ЩЯЭМБэЪіЕФЪЧвЛИіГщЯѓЕФКЌвхЃЌШчЙћЮвУЧУшЪівЛИіМђЕЅЕФЪТЪЕЃКЁАаЁУїПЊГЕШЅбЇаЃЩЯбЇЁБЁЃвдетИівЕЮёЪТЪЕЮЊР§ЃЌЮвУЧПЩвдАбЁАаЁУїЁБЃЌЁАбЇаЃЁБПДГЩЪЧвЛИіЪЕЬхЃЌЁАЩЯбЇЁБУшЪіЕФЪЧвЛИівЕЮёЙ§ГЬЃЌЮвУЧдкетРяПЩвдГщЯѓЮЊвЛИіОпЬхЁАЪТМўЁБЃЌЖјЁАПЊГЕШЅЁБдђПЩвдПДГЩЪЧЪТМўЁАЩЯбЇЁБЕФвЛИіЫЕУїЁЃ
ЮЌЖШНЈФЃ
ЮЌЖШНЈФЃЪЧзЈУХгІгУгкЗжЮіаЭЪ§ОнПтЁЂЪ§ОнВжПтЁЂЪ§ОнМЏЪаНЈФЃЕФЗНЗЈЁЃЪ§ОнМЏЪаПЩвдРэНтЮЊЪЧвЛжж"аЁаЭЪ§ОнВжПт"ЁЃ
1. ЮЌЖШНЈФЃжаБэЕФРраЭ
ЪТЪЕБэЗЂЩњдкЯжЪЕЪРНчжаЕФВйзїаЭЪТМўЃЌЦфЫљВњЩњЕФПЩЖШСПЪ§жЕЃЌДцДЂдкЪТЪЕБэжаЁЃДгзюЕЭЕФСЃЖШМЖБ№РДПДЃЌЪТЪЕБэааЖдгІвЛИіЖШСПЪТМўЃЌЗДжЎврШЛЁЃ

ЪТЪЕБэБэЪОЖдЗжЮіжїЬтЕФЖШСП ЁЃБШШчвЛДЮЙКТђааЮЊЮвУЧОЭПЩвдРэНтЮЊЪЧвЛИіЪТЪЕЁЃ
ЪТЪЕгыЮЌЖШ
ЭМжаЕФЖЉЕЅБэОЭЪЧвЛИіЪТЪЕБэЃЌФуПЩвдРэНтЫћОЭЪЧдкЯжЪЕжаЗЂЩњЕФвЛДЮВйзїаЭЪТМўЃЌЮвУЧУПЭъГЩвЛИіЖЉЕЅЃЌОЭЛсдкЖЉЕЅжадіМгвЛЬѕМЧТМЁЃЪТЪЕБэЕФЬиеїЃКБэРяУЛгаДцЗХЪЕМЪЕФФкШнЃЌЫћЪЧвЛЖбжїМќЕФМЏКЯЃЌетаЉIDЗжБ№ФмЖдгІЕНЮЌЖШБэжаЕФвЛЬѕМЧТМЁЃЪТЪЕБэАќКЌСЫгыИїЮЌЖШБэЯрЙиСЊЕФЭтМќЃЌПЩгыЮЌЖШБэЙиСЊЁЃЪТЪЕБэЕФЖШСПЭЈГЃЪЧЪ§жЕРраЭЃЌЧвМЧТМЪ§ЛсВЛЖЯдіМгЃЌБэЪ§ОнЙцФЃбИЫйдіГЄЁЃ
УїЯИБэЃЈПэБэЃЉ ЃК
ЪТЪЕБэЕФЪ§ОнжаЃЌгааЉЪєадЙВЭЌзщГЩСЫвЛИізжЖЮЃЈєлКЯдквЛЦ№ЃЉЃЌБШШчФъдТШеЪБЗжУыЙЙГЩСЫЪБМф,ЕБашвЊИљОнФГвЛЪєадНјааЗжзщЭГМЦЕФЪБКђЃЌашвЊНиШЁЦДНгжЎРрЕФВйзїЃЌаЇТЪМЋЕЭЁЃШчЃК

ЮЊСЫЗжЮіЗНБуЃЌПЩвдЪТЪЕБэжаЕФвЛИізжЖЮЧаИюЬсШЁЖрИіЪєадГіРДЙЙГЩаТЕФзжЖЮЃЌвђЮЊзжЖЮБфЖрСЫЃЌЫљвдГЦЮЊПэБэЃЌдРДЕФГЩЮЊеБэЁЃ
НЋЩЯЪіЕФlocal_timeзжЖЮРЉеЙЮЊШчЯТ6ИізжЖЮЃК

гжвђЮЊПэБэЕФаХЯЂИќМгЧхЮњУїЯИЃЌЫљвдвВПЩвдГЦжЎЮЊУїЯИБэЁЃ
2ЃЎЮЌЖШБэ
УПИіЮЌЖШБэЖМАќКЌЕЅвЛЕФжїМќСаЁЃЮЌЖШБэЕФжїМќПЩвдзїЮЊгыжЎЙиСЊЕФШЮКЮЪТЪЕБэЕФЭтМќЃЌЕБШЛЃЌЮЌЖШБэааЕФУшЪіЛЗОГгІгыЪТЪЕБэааЭъШЋЖдгІЁЃЮЌЖШБэЭЈГЃБШНЯПэЃЌЪЧБтЦНаЭЗЧЙцЗЖБэЃЌАќКЌДѓСПЕФЕЭСЃЖШЕФЮФБОЪєадЁЃ
ЮЌЖШБэЪОФувЊЖдЪ§ОнНјааЗжЮіЪБЫљгУЕФвЛИіСПЃЌБШШчФувЊЗжЮіВњЦЗЯњЪлЧщПіЃЌ ФуПЩвдбЁдёАДРрБ№РДНјааЗжЮіЃЌЛђАДЧјгђРДЗжЮіЁЃУПИіРрБ№ОЭЙЙГЩвЛИіЮЌЖШЁЃЩЯЭМжаЕФгУЛЇБэЁЂЩЬМвБэЁЂЪБМфБэетаЉЖМЪєгкЮЌЖШБэЃЌетаЉБэЖМгавЛИіЮЈвЛЕФжїМќЃЌШЛКѓдкБэжаДцЗХСЫЯъЯИЕФЪ§ОнаХЯЂЁЃ
змЕФЫЕРДЃЌдкЪ§ОнВжПтжаВЛашвЊбЯИёзёЪиЙцЗЖЛЏЩшМЦддђЁЃвђЮЊЪ§ОнВжПтЕФжїЕМЙІФмОЭЪЧУцЯђЗжЮіЃЌвдВщбЏЮЊжїЃЌВЛЩцМАЪ§ОнИќаТВйзїЁЃ ЪТЪЕБэЕФЩшМЦЪЧвдФмЙЛе§ШЗМЧТМРњЪЗаХЯЂЮЊзМдђЃЌЮЌЖШБэЕФЩшМЦЪЧвдФмЙЛвдКЯЪЪЕФНЧЖШРДОлКЯжїЬтФкШнЮЊзМдђЁЃ
2. ЮЌЖШНЈФЃШ§жжФЃЪН
аЧаЭФЃЪН
аЧаЮФЃЪН(Star Schema)ЪЧзюГЃгУЕФЮЌЖШНЈФЃЗНЪНЁЃаЧаЭФЃЪНЪЧвдЪТЪЕБэЮЊжааФЃЌЫљгаЕФЮЌЖШБэжБНгСЌНгдкЪТЪЕБэЩЯЃЌЯёаЧаЧвЛбљЁЃаЧаЮФЃЪНЕФЮЌЖШНЈФЃ
гЩвЛИіЪТЪЕБэКЭвЛзщЮЌБэГЩЃЌЧвОпгавдЯТЬиЕуЃКa. ЮЌБэжЛКЭЪТЪЕБэЙиСЊЃЌЮЌБэжЎМфУЛгаЙиСЊЃЛb. УПИіЮЌБэжїМќЮЊЕЅСаЃЌЧвИУжїМќЗХжУдкЪТЪЕБэжаЃЌзїЮЊСНБпСЌНгЕФЭтМќЃЛc. вдЪТЪЕБэЮЊКЫаФЃЌЮЌБэЮЇШЦКЫаФГЪаЧаЮЗжВМЃЛ
2.бЉЛЈФЃЪН
бЉЛЈФЃЪН(Snowflake Schema)ЪЧЖдаЧаЮФЃЪНЕФРЉеЙЁЃбЉЛЈФЃЪНЕФЮЌЖШБэПЩвдгЕгаЦфЫћЮЌЖШБэЕФЃЌЫфШЛетжжФЃаЭЯрБШаЧаЭИќЙцЗЖвЛаЉЃЌЕЋЪЧгЩгкетжжФЃаЭВЛЬЋШнвзРэНтЃЌЮЌЛЄГЩБОБШНЯИпЃЌЖјЧвадФмЗНУцашвЊЙиСЊЖрВуЮЌБэЃЌадФмвВБШаЧаЭФЃаЭвЊЕЭЁЃЫљвдвЛАуВЛЪЧКмГЃгУЁЃ
 
3ЃЎаЧзљФЃЪН
аЧзљФЃЪНЪЧаЧаЭФЃЪНбгЩьЖјРДЃЌаЧаЭФЃЪНЪЧЛљгквЛеХЪТЪЕБэЕФЃЌЖјаЧзљФЃЪНЪЧЛљгкЖреХЪТЪЕБэЕФЃЌЖјЧвЙВЯэЮЌЖШаХЯЂЁЃЧАУцНщЩмЕФСНжжЮЌЖШНЈФЃЗНЗЈЖМЪЧЖрЮЌБэЖдгІЕЅЪТЪЕБэЃЌЕЋдкКмЖрЪБКђЮЌЖШПеМфФкЕФЪТЪЕБэВЛжЙвЛИіЃЌЖјвЛИіЮЌБэвВПЩФмБЛЖрИіЪТЪЕБэгУЕНЁЃдквЕЮёЗЂеЙКѓЦкЃЌОјДѓВПЗжЮЌЖШНЈФЃЖМВЩгУЕФЪЧаЧзљФЃЪНЁЃ

3. ЮЌЖШНЈФЃЙ§ГЬ
ЮвУЧжЊЕРЮЌЖШНЈФЃЕФБэРраЭгаЪТЪЕБэЃЌЮЌЖШБэЃЛФЃЪНгааЧаЮФЃаЭЃЌбЉЛЈФЃаЭЃЌаЧзљФЃаЭетаЉИХФюСЫЃЌЕЋЪЧЪЕМЪвЕЮёжаЃЌИјСЫЮвУЧвЛЖбЪ§ОнЃЌЮвУЧдѕУДФУетаЉЪ§ОнНјааЪ§ВжНЈЩшФиЃЌЪ§ВжЙЄОпЯфзїепИљОнздЩэ60ЖрФъЕФЪЕМЪвЕЮёОбщЃЌИјЮвУЧзмНсСЫШчЯТЫФВНЃЌЧыЮёБиМЧзЁЃЁ
Ъ§ВжЙЄОпЯфжаЕФЮЌЖШНЈФЃЫФВНзпЃК

ЮЌЖШНЈФЃЫФВНзп
Чы РЮМЧ вдЩЯЫФВНЃЌВЛЙмЪВУДвЕЮёЃЌОЭАДееетИіВНжшРДЃЌЫГађВЛвЊИуТвЃЌвђЮЊетЫФВНЪЧЛЗЛЗЯрПлЃЌВНВНЯрСЌЁЃЯТУцЯъЯИВ№НтЯТУПИіВНжшдѕУДзі
1ЁЂбЁдёвЕЮёЙ§ГЬ
ЮЌЖШНЈФЃЪЧНєЬљвЕЮёЕФЃЌЫљвдБиаывдвЕЮёЮЊИљЛљНјааНЈФЃЃЌФЧУДбЁдёвЕЮёЙ§ГЬЃЌЙЫУћЫМвхОЭЪЧдкећИівЕЮёСїГЬжабЁШЁЮвУЧашвЊНЈФЃЕФвЕЮёЃЌИљОндЫгЊЬсЙЉЕФашЧѓМАШеКѓЕФвзРЉеЙадЕШНјаабЁдёвЕЮёЁЃБШШчЩЬГЧЃЌећИіЩЬГЧСїГЬЗжЮЊЩЬМвЖЫЃЌгУЛЇЖЫЃЌЦНЬЈЖЫЃЌдЫгЊашЧѓЪЧзмЖЉЕЅСПЃЌЖЉЕЅШЫЪ§ЃЌМАгУЛЇЕФЙКТђЧщПіЕШЃЌЮвУЧбЁдёвЕЮёЙ§ГЬОЭбЁдёгУЛЇЖЫЕФЪ§ОнЃЌЩЬМвМАЦНЬЈЖЫднВЛПМТЧЁЃвЕЮёбЁдёЗЧГЃживЊЃЌвђЮЊКѓУцЫљгаЕФВНжшЖМЪЧЛљгкДЫвЕЮёЪ§ОнеЙПЊЕФЁЃ
2ЁЂЩљУїСЃЖШ
ЯШОйИіР§згЃКЖдгкгУЛЇРДЫЕЃЌвЛИігУЛЇгавЛИіЩэЗнжЄКХЃЌвЛИіЛЇМЎЕижЗЃЌЖрИіЪжЛњКХЃЌЖреХвјааПЈЃЌФЧУДгыгУЛЇСЃЖШЯрЭЌЕФСЃЖШЪєадгаЩэЗнжЄСЃЖШЃЌЛЇМЎЕижЗСЃЖШЃЌБШгУЛЇСЃЖШИќЯИЕФСЃЖШгаЪжЛњКХСЃЖШЃЌвјааПЈСЃЖШЃЌДцдквЛЖдвЛЕФЙиЯЕОЭЪЧЯрЭЌСЃЖШЁЃЮЊЪВУДвЊЬсЯрЭЌСЃЖШФиЃЌвђЮЊЮЌЖШНЈФЃжавЊЧѓЮвУЧЃЌдкЭЌвЛЪТЪЕБэжаЃЌБиаыОпгаЯрЭЌЕФСЃЖШЃЌЭЌвЛЪТЪЕБэжаВЛвЊЛьгУЖржжВЛЭЌЕФСЃЖШЃЌВЛЭЌЕФСЃЖШЪ§ОнНЈСЂВЛЭЌЕФЪТЪЕБэЁЃВЂЧвДгИјЖЈЕФвЕЮёЙ§ГЬЛёШЁЪ§ОнЪБЃЌЧПСвНЈвщДгЙизЂдзгСЃЖШПЊЪМЩшМЦЃЌвВОЭЪЧДгзюЯИСЃЖШПЊЪМЃЌвђЮЊдзгСЃЖШФмЙЛГаЪмЮоЗЈдЄЦкЕФгУЛЇВщбЏЁЃЕЋЪЧЩЯОэЛузмСЃЖШЖдВщбЏадФмЕФЬсЩ§КмживЊЕФЃЌЫљвдЖдгкгаУїШЗашЧѓЕФЪ§ОнЃЌЮвУЧНЈСЂеыЖдашЧѓЕФЩЯОэЛузмСЃЖШЃЌЖдашЧѓВЛУїРЪЕФЪ§ОнЮвУЧНЈСЂдзгСЃЖШЁЃ
3ЁЂШЗШЯЮЌЖШ
ЮЌЖШБэЪЧзїЮЊвЕЮёЗжЮіЕФШыПкКЭУшЪіадБъЪЖЃЌЫљвдвВБЛГЦЮЊЪ§ОнВжПтЕФЁАСщЛъЁБЁЃдквЛЖбЕФЪ§ОнжадѕУДШЗШЯФФаЉЪЧЮЌЖШЪєадФиЃЌШчЙћИУСаЪЧЖдОпЬхжЕЕФУшЪіЃЌЪЧвЛИіЮФБОЛђГЃСПЃЌФГвЛдМЪјКЭааБъЪЖЕФВЮгыепЃЌДЫЪБИУЪєадЭљЭљЪЧЮЌЖШЪєадЃЌЪ§ВжЙЄОпЯфжаИцЫпЮвУЧРЮРЮеЦЮеЪТЪЕБэЕФСЃЖШЃЌОЭФмНЋЫљгаПЩФмДцдкЕФЮЌЖШЧјЗжПЊЃЌВЂЧввЊШЗБЃЮЌЖШБэжаВЛФмГіЯжжиИДЪ§ОнЃЌгІЪЙЮЌЖШжїМќЮЈвЛ
4ЁЂШЗШЯЪТЪЕ
ЪТЪЕБэЪЧгУРДЖШСПЕФЃЌЛљБОЩЯЖМвдЪ§СПжЕБэЪОЃЌЪТЪЕБэжаЕФУПааЖдгІвЛИіЖШСПЃЌУПаажаЕФЪ§ОнЪЧвЛИіЬиЖЈМЖБ№ЕФЯИНкЪ§ОнЃЌГЦЮЊСЃЖШЁЃЮЌЖШНЈФЃЕФКЫаФддђжЎвЛЪЧЭЌвЛЪТЪЕБэжаЕФЫљгаЖШСПБиаыОпгаЯрЭЌЕФСЃЖШЁЃетбљФмШЗБЃВЛЛсГіЯжжиИДМЦЫуЖШСПЕФЮЪЬтЁЃгаЪБКђЭљЭљВЛФмШЗЖЈИУСаЪ§ОнЪЧЪТЪЕЪєадЛЙЪЧЮЌЖШЪєадЁЃМЧзЁзюЪЕгУЕФЪТЪЕОЭЪЧЪ§жЕРраЭКЭПЩМгРрЪТЪЕЁЃЫљвдПЩвдЭЈЙ§ЗжЮіИУСаЪЧЗёЪЧвЛжжАќКЌЖрИіжЕВЂзїЮЊМЦЫуЕФВЮгыепЕФЖШСПЃЌетжжЧщПіЯТИУСаЭљЭљЪЧЪТЪЕЁЃ
ЪЕМЪвЕЮёжаЪ§ВжЗжВу
Ъ§ВжЗжВувЊНсКЯЙЋЫОвЕЮёНјааЃЌВЂЧвашвЊЧхЮњУїШЗИїВужАд№ЃЌвЊБЃжЄЪ§ОнВуЕФЮШЖЈгжвЊЦСБЮЖдЯТгЮгАЯьЃЌвЛАуВЩгУШчЯТЗжВуНсЙЙЃК

Ъ§ОнЗжВуМмЙЙ
Ъ§ОнВуОпЬхЪЕЯж
ЪЙгУЫФеХЭМЫЕУїУПВуЕФОпЬхЪЕЯж
Ъ§ОндДВуODS

Ъ§ОндДВу
Ъ§ОндДВужївЊНЋИїИівЕЮёЪ§ОнЕМШыЕНДѓЪ§ОнЦНЬЈЃЌзїЮЊвЕЮёЪ§ОнЕФПьееДцДЂЁЃ
Ъ§ОнУїЯИВуDW

Ъ§ОнУїЯИВу
ЪТЪЕБэжаЕФУПааЖдгІвЛИіЖШСПЃЌУПаажаЕФЪ§ОнЪЧвЛИіЬиЖЈМЖБ№ЕФЯИНкЪ§ОнЃЌГЦЮЊСЃЖШЁЃЮЌЖШНЈФЃЕФКЫаФддђжЎвЛЪЧ ЭЌвЛЪТЪЕБэжаЕФЫљгаЖШСПБиаыОпгаЯрЭЌЕФСЃЖШ ЁЃетбљФмШЗБЃВЛЛсГіЯжжиИДМЦЫуЖШСПЕФЮЪЬтЁЃ
ЮЌЖШБэвЛАуЖМЪЧЕЅвЛжїМќЃЌЩйЪ§ЪЧСЊКЯжїМќЃЌзЂвтЮЌЖШБэВЛвЊГіЯжжиИДЪ§ОнЃЌЗёдђКЭЪТЪЕБэЙиСЊЛсГіЯж Ъ§ОнЗЂЩЂ ЮЪЬтЁЃ
гаЪБКђЭљЭљВЛФмШЗЖЈИУСаЪ§ОнЪЧЪТЪЕЪєадЛЙЪЧЮЌЖШЪєадЁЃ МЧзЁзюЪЕгУЕФЪТЪЕОЭЪЧЪ§жЕРраЭКЭПЩМгРрЪТЪЕ ЁЃЫљвдПЩвдЭЈЙ§ЗжЮіИУСаЪЧЗёЪЧвЛжжАќКЌЖрИіжЕВЂзїЮЊМЦЫуЕФВЮгыепЕФЖШСПЃЌетжжЧщПіЯТИУСаЭљЭљЪЧЪТЪЕЃЛШчЙћИУСаЪЧЖдОпЬхжЕЕФУшЪіЃЌЪЧвЛИіЮФБОЛђГЃСПЃЌФГвЛдМЪјКЭааБъЪЖЕФВЮгыепЃЌДЫЪБИУЪєадЭљЭљЪЧЮЌЖШЪєадЁЃЕЋЪЧЛЙЪЧвЊНсКЯвЕЮёНјаазюжеХаЖЯЪЧЮЌЖШЛЙЪЧЪТЪЕЁЃ
Ъ§ОнЧсЖШЛузмВуDM
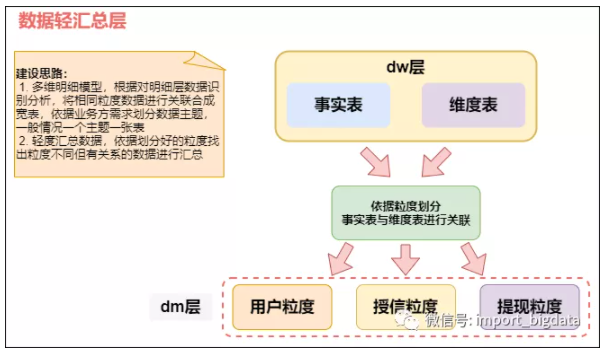
Ъ§ОнЧсЖШЛузмВу
ДЫВуУќУћЮЊЧсЛузмВуЃЌОЭДњБэетвЛВувбОПЊЪМЖдЪ§ОнНјааЛузмЃЌЕЋЪЧВЛЪЧЭъШЋЛузмЃЌжЛЪЧЖдЯрЭЌСЃЖШЕФЪ§ОнНјааЙиСЊЛузмЃЌВЛЭЌСЃЖШЕЋЪЧгаЙиЯЕЕФЪ§ОнвВПЩНјааЛузмЃЌДЫЪБашвЊНЋСЃЖШЭЈЙ§ОлКЯЕШВйзїНјааЭГвЛЁЃ
Ъ§ОнгІгУВуAPP
Ъ§ОнгІгУВу
Ъ§ОнгІгУВуЕФБэОЭЪЧЬсЙЉИјгУЛЇЪЙгУЕФЃЌЪ§ВжНЈЩшЕНДЫОЭНгНќЮВЩљСЫЃЌНгЯТРДОЭИљОнВЛЭЌЕФашЧѓНјааВЛЭЌЕФШЁЪ§ЃЌШчжБНгНјааБЈБэеЙЪОЃЌЛђЬсЙЉИјЪ§ОнЗжЮіЕФЭЌЪТЫљашЕФЪ§ОнЃЌЛђЦфЫћЕФвЕЮёжЇГХЁЃ
зюКѓ
ММЪѕЪЧЮЊвЕЮёЗўЮёЕФЃЌвЕЮёЪЧЮЊЙЋЫОДДдьМлжЕЕФЃЌРыПЊвЕЮёЕФММЪѕЪЧЮовтвхЕФЁЃЫљвдЪ§ВжЕФНЈЩшгывЕЮёЪЧЯЂЯЂЯрЙиЕФЃЌЙЋЫОЕФвЕЮёВЛЭЌЃЌЪ§ВжЕФНЈЩшвВЪЧВЛЭЌЕФЃЌжЛгаЪЪКЯЕФВХЪЧзюКУЕФЁЃ
ЖўЁЂжИБъЬхЯЕ
жИБъЬхЯЕЪЧЪВУДЃПШчКЮЪЙгУOSMФЃаЭКЭAARRRФЃаЭДюНЈжИБъЬхЯЕЃПШчКЮЭГвЛСїГЬЁЂЙцЗЖЛЏЁЂЙЄОпЛЏЙмРэжИБъЬхЯЕЃПБОЮФЛсЖдНЈЩшЕФЗНЗЈТлНсКЯЕЮЕЮЪ§ОнжИБъЬхЯЕНЈЩшЪЕМљНјааНтД№ЗжЮіЁЃ
ЪВУДЪЧжИБъЬхЯЕ
1. жИБъЬхЯЕЖЈвх
жИБъЬхЯЕЪЧНЋСуЩЂЕЅЕуЕФОпгаЯрЛЅСЊЯЕЕФжИБъЃЌЯЕЭГЛЏЕФзщжЏЦ№РДЃЌЭЈЙ§ЕЅЕуПДШЋОжЃЌЭЈЙ§ШЋОжНтОіЕЅЕуЕФЮЪЬтЁЃЫќжївЊгЩжИБъКЭЬхЯЕСНВПЗжзщГЩЁЃ
жИБъЪЧжИНЋвЕЮёЕЅдЊЯИЗжКѓСПЛЏЕФЖШСПжЕЃЌЫќЪЙЕУвЕЮёФПБъПЩУшЪіЁЂПЩЖШСПЁЂПЩВ№НтЃЌЫќЪЧвЕЮёКЭЪ§ОнЕФНсКЯЃЌЪЧЭГМЦЕФЛљДЁЃЌвВЪЧСПЛЏаЇЙћЕФживЊвРОнЁЃ
жИБъжївЊЗжЮЊНсЙћаЭКЭЙ§ГЬаЭЃК
НсЙћаЭжИБъЃКгУгкКтСПгУЛЇЗЂЩњФГИіЖЏзїКѓЫљВњЩњЕФНсЙћЃЌЭЈГЃЪЧбгКѓжЊЕРЕФЃЌКмФбНјааИЩдЄЁЃНсЙћаЭжИБъИќЖрЕФЪЧМрПиЪ§ОнвьГЃЃЌЛђепЪЧМрПиФГИіГЁОАЯТгУЛЇашЧѓЪЧЗёБЛТњзу
Й§ГЬаЭжИБъЃКгУЛЇдкзіФГИіЖЏзїЪБКђЫљВњЩњЕФжИБъЃЌПЩвдЭЈЙ§ФГаЉдЫгЊВпТдРДгАЯьетИіЙ§ГЬжИБъЃЌДгЖјгАЯьзюжеЕФНсЙћЃЌЙ§ГЬаЭжИБъИќМгЙизЂгУЛЇЕФашЧѓЮЊЪВУДБЛТњзуЛђУЛБЛТњзу
ЬхЯЕЪЧгЩВЛЭЌЕФЮЌЖШзщГЩЃЌЖјЮЌЖШЪЧжИгУЛЇЙлВьЁЂЫМПМгыБэЪіФГЪТЮяЕФЁАЫМЮЌНЧЖШЁБЃЌЮЌЖШЪЧжИБъЬхЯЕЕФКЫаФЃЌУЛгаЮЌЖШЃЌЕЅДПЫЕжИБъЪЧУЛгаШЮКЮвтвхЕФЁЃ
ЮЌЖШжївЊЗжЮЊЖЈадЮЌЖШКЭЖЈСПЮЌЖШЃЌЖЈадЮЌЖШЃЌжївЊЪЧЦЋЮФзжУшЪіРрШчГЧЪаЁЂадБ№ЁЂжАвЕЕШ;ЖЈСПЮЌЖШЃЌжївЊЪЧЪ§жЕРрУшЪіШчЪеШыЁЂФъСфЕШЃЌЖдЖЈСПЮЌЖШашвЊзіЪ§жЕЗжзщДІРэЁЃ
2. жИБъЬхЯЕЩњУќжмЦк
ЩњУќжмЦкжївЊАќКЌЖЈвхЁЂЩњВњЁЂЯћЗбЁЂЯТЯпЫФИіНзЖЮЁЃеыЖдећИіЩњУќжмЦквЊГжајзіжИБъдЫЮЌЁЂжЪСПБЃеЯЃЌЭЌЪБЮЊСЫЬсИпжИБъЪ§ОнИДгУЖШЃЌНЕЕЭгУЛЇЪЙгУГЩБОашвЊзіЖдгІЕФЪ§ОндЫгЊЙЄзїЁЃ

3. злКЯЪЙгУГЁОА
жИБъЬхЯЕжївЊЪЧНсКЯгУЛЇЕФвЕЮёГЁОАРДНјааЪЙгУЃЌЖрИіВЛЭЌЕФжИБъКЭЮЌЖШПЩвдзщКЯЦ№РДНјаавЕЮёЕФзлКЯЗжЮіЃЌгУЛЇПЩЭЈЙ§жИБъЕФБфЛЏПДЕНећЬхвЕЮёЕФБфЛЏЃЌВЂФмЙЛПьЫйЗЂЯжЮЪЬтЁЂЖЈЮЛЮЪЬтЁЃГЃгУЕФГЁОАвЛжжЪЧОіВпЗжЮіЕФГЁОАЃЌЭЈЙ§Ъ§ОнПДЧхвЕЮёЯжзДНјааеНТдОіВпжЇГжЃЛСэвЛжжЪЧдЫгЊЗжЮіГЁОАЃЌЮоТлЪЧзігУЛЇдЫгЊЁЂВњЦЗдЫгЊЛЙЪЧЛюЖЏдЫгЊЖМашвЊИїРржИБъЪ§ОнЕФжЇГХШЅПДЧхЮЪЬтЁЂЗжЮіЮЪЬтКЭжИЕМНтОіЮЪЬтЁЃ
ЮЊЪВУДДюНЈжИБъЬхЯЕ
1. КтСПвЕЮёЗЂеЙжЪСП
жИБъЬхЯЕПЩвдЗДгГвЕЮёПЭЙлЪТЪЕЃЌПДЧхвЕЮёЗЂеЙЯжзДЃЌЭЈЙ§жИБъЖдвЕЮёжЪСПНјааКтСПЃЌАбПивЕЮёЗЂеЙЧщПіЃЌеыЖдЗЂЯжЕФвЕЮёЮЪЬтОлНЙНтОіЃЌДйНјвЕЮёгаађдіГЄ
2. НЈСЂжИБъвђЙћЙиЯЕ
жївЊУїШЗНсЙћаЭжИБъКЭЙ§ГЬаЭжИБъЙиЯЕЃЌЭЈЙ§НсЙћжИБъЛиЫнЙ§ГЬжИБъЃЌевЕННтОіЮЪЬтЕФКЫаФдвђ
3. жИЕМгУЛЇЗжЮіЙЄзї
ФПЕФНЈСЂВњЦЗЦРЙРЬхЯЕЁЂЛюЖЏаЇЙћЦРЙРЬхЯЕЁЂжЧФмдЫгЊЗжЮіЬхЯЕ
4. жИЕМЛљДЁЪ§ОнНЈЩш
УїШЗЛљДЁЪ§ОнНЈЩшЗНЯђЃЌМЏжазЪдДЃЌБмУтЙ§ГЬКЭНсЙћЗжЮіжИБъЪ§ОнЕФвХТЉЛђШБЪЇ
5. жИЕМФкШнВњЦЗНЈЩш
НсКЯгУЛЇЕФвЕЮёГЁОАРДНјааЪЙгУЃЌЖрИіВЛЭЌЕФжИБъКЭЮЌЖШПЩвдзщКЯЦ№РДНјаавЕЮёЕФзлКЯЗжЮіЃЌгУЛЇПЩЭЈЙ§жИБъЕФБфЛЏПДЕНећЬхвЕЮёЕФБфЛЏЃЌВЂФмЙЛПьЫйЗЂЯжЮЪЬтЁЂЖЈЮЛЮЪЬт
6. ЭГвЛжИБъЯћЗбПкОЖ
ЦѓвЕФкЭГвЛЙиМќжИБъвЕЮёПкОЖМАМЦЫуПкОЖЃЌЭГвЛЦѓвЕвЕЮёФПБъЃЌЪЕЯжздЩЯЖјЯТФПБъЧ§ЖЏ
ШчКЮДюНЈжИБъЬхЯЕ
жИБъЬхЯЕНЈЩшЕФГЃгУЗНЗЈЪЧЭЈЙ§ГЁОАЛЏНјаажИБъЬхЯЕЕФДюНЈЃЌвдгУЛЇЕФЪгНЧГЁОАЛЏЫМПМЃЌздЩЯЖјЯТвЕЮёЧ§ЖЏжИБъЬхЯЕНЈЩшЃЌЫљвдвЊдкЬиЖЈГЁОАЯТзіКУжИБъЬхЯЕНЈЩшЃЌашвЊЯШбЁКУжИБъЃЌШЛКѓгУПЦбЇЕФЗНЗЈДюНЈжИБъЬхЯЕЁЃ
1. ПЦбЇЗНЗЈбЁжИБъ
бЁжИБъГЃгУЗНЗЈЪЧжИБъЗжМЖЗНЗЈКЭOSMФЃаЭЁЃ
жИБъЗжМЖжївЊЪЧжИБъФкШнзнЯђЕФЫМПМЃЌИљОнЦѓвЕеНТдФПБъЁЂзщжЏМАвЕЮёЙ§ГЬНјааздЩЯЖјЯТЕФжИБъЗжМЖЃЌЖджИБъНјааВуВуЦЪЮіЃЌжївЊЗжЮЊШ§МЖT1ЁЂT2ЁЂT3ЁЃ
T1жИБъЃКЙЋЫОеНТдВуУцжИБъ
гУгкКтСПЙЋЫОећЬхФПБъДяГЩЧщПіЕФжИБъЃЌжївЊЪЧОіВпРржИБъЃЌT1жИБъЪЙгУЭЈГЃЗўЮёгкЙЋЫОеНТдОіВпВу
T2жИБъЃКвЕЮёВпТдВуУцжИБъ
ЮЊДяГЩT1жИБъЕФФПБъЃЌЙЋЫОЛсЖдФПБъВ№НтЕНвЕЮёЯпЛђЪТвЕШКЃЌВЂгаеыЖдадзіГівЛЯЕСадЫгЊВпТдЃЌT2жИБъЭЈГЃЗДгГЕФЪЧВпТдНсЙћЪєгкжЇГжаджИБъЭЌЪБвВЪЧвЕЮёЯпЛђЪТвЕШКЕФКЫаФжИБъЁЃT2жИБъЪЧT1жИБъЕФзнЯђЕФТЗОЖВ№НтЃЌБугкT1жИБъЕФЮЪЬтЖЈЮЛЃЌT2жИБъЪЙгУЭЈГЃЗўЮёвЕЮёЯпЛђЪТвЕШК
T3жИБъЃКвЕЮёжДааВуУцжИБъ
T3жИБъЪЧЖдT2жИБъЕФВ№НтЃЌгУгкЖЈЮЛT2жИБъЕФЮЪЬтЁЃT3жИБъЭЈГЃвВЪЧвЕЮёЙ§ГЬжазюЖрЕФжИБъЁЃИљОнИїжАФмВПУХФПБъЕФВЛЭЌЃЌЦфЙизЂЕФжИБъвВИїгаВювьЁЃT3жИБъЕФЪЙгУЭЈГЃПЩвджИЕМвЛЯпдЫгЊЛђЗжЮіШЫдБПЊеЙЙЄзїЃЌФкШнЦЋЙ§ГЬаджИБъЃЌПЩвдПьЫйв§ЕМвЛЯпШЫдБзіГіЯргІЕФЖЏзїЁЃ
Р§ШчЃКГЩНЛТЪЕФжИБъЗжМЖ

OSMФЃаЭЃЈObejectiveЃЌStrategyЃЌMeasurementЃЉЪЧжИБъЬхЯЕНЈЩшЙ§ГЬжаИЈжњШЗЖЈКЫаФЕФживЊЗНЗЈЃЌАќКЌвЕЮёФПБъЁЂвЕЮёВпТдЁЂвЕЮёЖШСПЃЌЪЧжИБъФкШнКсЯђЕФЫМПМЁЃ
O
гУЛЇЪЙгУВњЦЗЕФФПБъЪЧЪВУДЃПВњЦЗТњзуСЫгУЛЇЕФЪВУДашЧѓЃПжївЊДггУЛЇЪгНЧКЭвЕЮёЪгНЧШЗЖЈФПБъЃЌддђЪЧЧаЪЕПЩааЁЂвзРэНтЁЂПЩИЩдЄЁЂе§Яђгавц
S
ЮЊСЫДяГЩЩЯЪіФПБъЮвВЩШЁЕФВпТдЪЧЪВУДЃП
M
етаЉВпТдЫцжЎДјРДЕФЪ§ОнжИБъБфЛЏгаФФаЉЃП
вдЕЮЕЮЭјдМГЕЮЊР§ЃЌАДееOSMФЃаЭЃЌЫќЕФжИБъЪЧЪВУДбљЕФЃП
OЃКгУЛЇРДЪЙгУЕЮЕЮетИіВњЦЗЃЌашЧѓКЭФПБъЪЧЪВУДЃП
гУЛЇашЧѓМАФПБъЪЧБуНнЁЂПьЫйДђЕНГЕЃЌАВШЋЕНДяФПЕФЕи
ФЧШчКЮШУгУЛЇИаЪмЕНздМКЕФашЧѓБЛТњзуСЫФиЃП
SЃКЕЮЕЮзіЕФВпТдЪЧЃК
БуНнЗНУцЃЌЬсЙЉСЫЖРСЂAPPАцБОЁЂаЁГЬађАцБОЃЌЛЙПЩвдЖрЧўЕРДђЕНГЕЃЌР§ШчдкИпЕТЁЂЮЂаХЁЂжЇИЖБІЖМгаДђГЕШыПкЃЛЦ№ЪМЁЂФПЕФЕиЕиЭМжЧФмОЋзМЖЈЮЛЃЛзюгХТЗЯпбЁдёЕШ
ПьЫйЗНУцЃЌеыЖдВЛЭЌШЫШКВЛЭЌЫпЧѓЬсЙЉСЫЖрЦЗРрВњЦЗбЁдёЃЌР§ШчПьГЕЁЂгХЯэЁЂЦДГЕЁЂГізтГЕЕШвЕЮёЃЌИљОндчЭэИпЗхЬсИпШШЕуЧјгђдЫСІЃЌМѕЩйгУЛЇХХЖгЪБМф
АВШЋЗНУцЃЌЫОЛњзМШыЛњжЦЃЌЫОЛњКЯЙцЛњжЦЃЌЫОЛњЛЯё
MЃКЮвУЧашвЊеыЖдетаЉВпТдШЅзіжИБъЃЌдкетРяУцЮвУЧЕФжИБъЗжБ№ЪЧНсЙћжИБъКЭЙ§ГЬжИБъЃК
НсЙћжИБъЃКЧўЕРзЊЛЏЭъГЩТЪЁЂГЫПЭШЁЯћТЪЁЂЙЉашБШЁЂЫОЛњЗўЮёЗж
Й§ГЬжИБъЃКЧўЕРЗЂЕЅЪ§ЁЂЧўЕРЭъЕЅЪ§ЁЂХХЖгГЫПЭЪ§ЁЂГЫПЭХХЖгЪБГЄЁЂЫОЛњКУЦРТЪЁЂЫОЛњНгЕЅСПЁЂЫОЛњШЁЯћЪ§ЕШ
жИБъбЁШЁжЎКѓЃЌЯТУцОЭЪЧзюживЊЕФЗжЮіЮЌЖШбЁдёСЫЃЌЧАУцжИБъЬхЯЕЖЈвхРяНВЙ§ЮЌЖШЪЧжИБъЬхЯЕЕФКЫаФЃЌУЛгаЮЌЖШЃЌЕЅДПЫЕжИБъЪЧУЛгаШЮКЮвтвхЕФЁЃЫљвдЮЌЖШбЁдёВуУцжївЊЭЈЙ§Ъ§ОнЗжЮіЪгНЧНсКЯЪЕМЪЗжЮівЕЮёГЁОАРДШЗЖЈЁЃР§ШчГЧЪаЮЌЖШЁЂЩЬШІЮЌЖШЁЂЧўЕРЮЌЖШЁЂЪБМфЮЌЖШЁЂгУЛЇБъЧЉЮЌЖШЕШЁЃ
2. гУЗжЮіФЃаЭДюНЈжИБъЬхЯЕ
дкЁЖОЋвцЪ§ОнЗжЮіЁЗвЛЪщжаИјГіСЫСНЬзБШНЯГЃгУЕФжИБъЬхЯЕНЈЩшЗНЗЈТлЃЌЦфжавЛИіОЭЪЧБШНЯгаУћЕФКЃЕСжИБъЗЈЃЌвВОЭЪЧЮвУЧОГЃЬ§ЕНЕФAARRRКЃЕСФЃаЭЁЃКЃЕСФЃаЭЪЧгУЛЇЗжЮіЕФОЕфФЃаЭЃЌЫќЗДгГСЫдіГЄЪЧЯЕЭГадЕиЙсДЉгкгУЛЇЩњУќжмЦкИїИіНзЖЮЕФЃКгУЛЇРаТ(Acquisition)ЁЂгУЛЇМЄЛю(Activation)ЁЂгУЛЇСєДц(Retention)ЁЂЩЬвЕБфЯж(Revenue)ЁЂгУЛЇЭЦМі(Referral)ЁЃ
AARRRФЃаЭ
AРаТ
ЭЈЙ§ИїжжЭЦЙуЧўЕРЃЌвдИїжжЗНЪНЛёШЁФПБъгУЛЇЃЌВЂЖдИїжжгЊЯњЧўЕРЕФаЇЙћЦРЙРЃЌВЛЖЯгХЛЏЭЖШыВпТдЃЌНЕЕЭЛёПЭГЩБОЁЃЩцМАЙиМќжИБъР§ШчаТдізЂВсгУЛЇЪ§ЁЂМЄЛюТЪЁЂзЂВсзЊЛЏТЪЁЂаТПЭСєДцТЪЁЂЯТдиСПЁЂАВзАСПЕШ
AЛюдО
ЛюдОгУЛЇжИеце§ПЊЪМЪЙгУСЫВњЦЗЬсЙЉЕФМлжЕЃЌЮвУЧашвЊеЦЮегУЛЇЕФааЮЊЪ§ОнЃЌМрПиВњЦЗНЁПЕГЬЖШЁЃетИіФЃПщжївЊЗДгГгУЛЇНјШыВњЦЗЕФааЮЊБэЯжЃЌЪЧВњЦЗЬхбщЕФКЫаФЫљдкЁЃЩцМАЙиМќжИБъР§ШчDAU/MAU ЁЂШеОљЪЙгУЪБГЄЁЂЦєЖЏAPPЪБГЄЁЂЦєЖЏAPPДЮЪ§ЕШ
RСєДц
КтСПгУЛЇеГадКЭжЪСПЕФжИБъЁЃЩцМАЙиМќжИБъР§ШчСєДцТЪЁЂСїЪЇТЪЕШ
RБфЯж
жївЊгУРДКтСПВњЦЗЩЬвЕМлжЕЁЃЩцМАЙиМќжИБъР§ШчЩњУќжмЦкМлжЕ(LTV)ЁЂПЭЕЅМлЁЂGMVЕШ
RЭЦМі
КтСПгУЛЇздДЋВЅГЬЖШКЭПкБЎЧщПіЁЃЩцМАЙиМќжИБъР§ШчбћЧыТЪЁЂСбБфЯЕЪ§ЕШ
ПЩвдИљОнЪЕМЪвЕЮёГЁОАЃЌНсКЯЪЙгУOSMКЭAARRRФЃаЭЃЌРДЯЕЭГадЕФбЁдёВЛЭЌНзЖЮЫљашвЊЕФКЫаФЪ§ОнжИБъЁЃ

3. ГЁОАЛЏДюНЈжИБъЬхЯЕ
ФПЧАНзЖЮЛЅСЊЭјвЕЮёБШНЯСїааЕФвЛжжЭЈгУГщЯѓГЁОАЁАШЫЁЂЛѕЁЂГЁЁБЃЌЪЕМЪОЭЪЧЮвУЧШеГЃЫљЫЕЕФгУЛЇЁЂВњЦЗЁЂГЁОАЃЌдкЭЈЫзЕуНВОЭЪЧЫдкЪВУДГЁОАЯТЪЙгУСЫЪВУДВњЦЗЃЌВЛЭЌЕФЩЬвЕФЃЪНЛсгаВЛЭЌЕФзщКЯФЃЪНЁЃвдЕЮЕЮЪЕМЪГЁОАЮЊР§ЃКФФаЉГЁОАЃЈДЫДІГЁОАЖЈвхЮЊжеЖЫЃЌШчNativeЃЌЮЂаХЃЌжЇИЖБІЃЉЕФЪВУДШЫЃЈГЫПЭЃЉдкЦНЬЈЩЯЪЙгУСЫФФаЉЛѕЃЈЦНЬЈвЕЮёЯпЃЌШчПьГЕ/зЈГЕЕШЃЉЃЌНјЖјЮЊЦРЙРгУЛЇдіГЄЕФМлжЕКЭаЇЙћЁЃ
"ШЫ"ЕФЪгНЧ
ДгЁАШЫЁБЕФЪгНЧЃЌЮвУЧБШНЯЙиаФЕФЪЧЪВУДГЫПЭдкЪВУДЪБМфДђЕФГЕЃЌХХСЫЖрГЄЪБМфЃЌЕШСЫЖрГЄЪБМфЩЯГЕЃЌжмЦкФкЕкМИДЮДђГЕЃЌДђГЕЛЈСЫЖрЩйЧЎЃЌЪЧЗёгаЭЖЫпКЭШЁЯћааЮЊЃЌОпЬхЕНЪ§ОнжИБъжївЊПДЗЂЕЅгУЛЇЪ§ЁЂЭъЕЅгУЛЇЪ§ЁЂПЭЕЅМлЁЂжмЦкФкЭъЕЅЖЉЕЅЪ§ЁЂШЁЯћЖЉЕЅЪ§ЁЂЦРМлЖЉЕЅЪ§ЕШЁЃ

"Лѕ"ЕФЪгНЧ
ДгЁАЛѕЁБЕФЪгНЧЃЌЮвУЧБШНЯЙиаФЕФОЭЪЧГЩНЛСЫЖрЩйЃЌНЛвзЖюЖрЩйЃЌЛЈСЫЖрЩйЃЌЕНОпЬхЪ§ОнжИБъжївЊЛсПДGMVЁЂГЩНЛТЪЁЂШЁЯћТЪжИБъЃЌдкНјвЛВНЛсЯИЗжЕНГЧЪаЁЂЧјгђЃЌвЛМЖЦЗРрЁЂЖўМЖЦЗРрЁЃЪ§ОнЕФаЇЙћЭЈЙ§ФПБъЖдБШЃЌКсЯђЖдБШЁЂРњЪЗБШНЯЕШЗНЪННјааЗжЮіШЗЖЈЁЃ
"ГЁ"ЕФЪгНЧ
ДгЁАГЁЁБЕФЪгНЧЃЌЮвУЧБШНЯЙиаФЕФОЭЪЧФФИіЧўЕРгУЛЇЕуЛїСПДѓЦиЙтТЪДѓЃЌДјРДСЫЖрЩйаТгУЛЇЃЌЭъГЩЖрЩйНЛвзЖЉЕЅЃЌПЭЕЅМлЪЧЖрЩйЃЛЛђепЪЧФФИіЛюЖЏРаТЛђДйЛюаЇЙћдѕУДбљзЊЛЏТЪЖрЩйЃЌНсКЯГЁОАЪ§ОнЪЕМЪЧщПіжЦЖЈЖдгІВпТдЁЃ

вдЩЯЗжБ№ДгЁАШЫЁБЁЂЁАЛѕЁБЁЂЁАГЁЁБШ§ИіНЧЖШНјааСЫЪ§ОнжИБъКЭЗжЮіЮЌЖШЕФЬсСЖЃЌЯТУцЮвУЧАбШ§РржИБъНсКЯжИБъЗжМЖЗНЗЈНјааЗжНтЙиСЊЁЃ

дѕУДЙмРэжИБъЬхЯЕ
1. ЭДЕуЗжЮі
жївЊДгвЕЮёЁЂММЪѕЁЂВњЦЗШ§ИіЪгНЧРДПДЃК
вЕЮёЪгНЧ
вЕЮёЗжЮіГЁОАжИБъЁЂЮЌЖШВЛУїШЗЃЛ
ЦЕЗБЕФашЧѓБфИќКЭЗДИДЕќДњЃЌЪ§ОнБЈБэгЗжзЃЌЪ§ОнВЮВюВЛЦыЃЛ
гУЛЇЗжЮіОпЬхвЕЮёЮЪЬтевЪ§ОнЁЂКЫЖдШЗШЯЪ§ОнГЩБОНЯИпЁЃ
ММЪѕЪгНЧ
жИБъЖЈвхЃЌжИБъУќУћЛьТвЃЌжИБъВЛЮЈвЛЃЌжИБъЮЌЛЄПкОЖВЛвЛжТЃЛ
жИБъЩњВњЃЌжиИДНЈЩшЃЛЪ§ОнЛуЫуГЩБОНЯИпЃЛ
жИБъЯћЗбЃЌЪ§ОнГіПкВЛЭГвЛЃЌжиИДЪфГіЃЌЪфГіПкОЖВЛвЛжТЃЛ
ВњЦЗЪгНЧ
ШБЗІЯЕЭГВњЦЗЛЏжЇГжДгЩњВњЕНЯћЗбЪ§ОнСїУЛгаЯЕЭГВњЦЗВуУцДђЭЈЃЛ
2. ЙмРэФПБъ
ММЪѕФПБъ
ЭГвЛжИБъКЭЮЌЖШЙмРэЃЌжИБъУќУћЁЂМЦЫуПкОЖЁЂЭГМЦРДдДЮЈвЛЃЌ ЮЌЖШЖЈвхЙцЗЖЁЂЮЌЖШжЕвЛжТ
вЕЮёФПБъ
ЭГвЛЪ§ОнГіПкЁЂГЁОАЛЏИВИЧ
ВњЦЗФПБъ
жИБъЬхЯЕЙмРэЙЄОпВњЦЗЛЏТфЕиЃЛжИБъЬхЯЕФкШнВњЦЗЛЏТфЕижЇГжОіВпЁЂЗжЮіЁЂдЫгЊР§ШчОіВпББМЋаЧЁЂжЧФмдЫгЊЗжЮіВњЦЗЕШ
3. ФЃаЭМмЙЙ

вЕЮёАхПщЖЈвхддђЃКвЕЮёТпМВуУцНјааГщЯѓЁЂЮяРэзщжЏМмЙЙВуУцНјааЯИЗжЃЌПЩИљОнЪЕМЪвЕЮёЧщПіНјааВуМЖЗжВ№ЯИЛЏЃЌВуМЖЗжМЖНЈвщНјаазюЖрНјааШ§МЖЗжВ№ЃЌвЛМЖЯИЗжПЩЙЋЫОВуУцЭГвЛЙцЗЖШЗЖЈЃЌЖўМЖМАКѓајВ№ЗжПЩИљОнвЕЮёЯпЪЕМЪвЕЮёНјааВ№ЗжЁЃ
Р§ШчЕЮЕЮГіааСьгђвЕЮёТпМВуУцСНТжГЕКЭЫФТжГЕЖМЪєгкГіааСьгђПЩГщЯѓГіаавЕЮёАхПщ(levelвЛМЖ)ЃЌИљОнЮяРэзщжЏМмЙЙВуУцдкНјааЯИЗжЦеЛнЁЂЭјдМГЕЁЂГізтГЕЁЂЫГЗчГЕЃЈlevelЖўМЖЃЉЃЌКѓајИљОнЪЕМЪвЕЮёашЧѓПЩдкЯИЗж,ЭјдМГЕПЩЯИЗжЖРГЫЁЂКЯГЫЃЌЦеЛнПЩЯИЗжЕЅГЕЁЂЦѓвЕМЖЁЃ
ЙцЗЖЖЈвх
Ъ§Онгђ
жИУцЯђвЕЮёЗжЮіЃЌНЋвЕЮёЙ§ГЬЛђепЮЌЖШНјааГщЯѓЕФМЏКЯЁЃЦфжаЃЌвЕЮёЙ§ГЬПЩвдИХРЈЮЊвЛИіИіВЛВ№ЗжЕФааЮЊЪТМўЃЌдквЕЮёЙ§ГЬжЎЯТЃЌПЩвдЖЈвхжИБъЃЛЮЌЖШЃЌЪЧЖШСПЕФЛЗОГЃЌШчГЫПЭКєЕЅЪТМўЃЌКєЕЅРраЭЪЧЮЌЖШЁЃЮЊСЫБЃеЯећИіЬхЯЕЕФЩњУќСІЃЌЪ§ОнгђЪЧашвЊГщЯѓЬсСЖЃЌВЂЧвГЄЦкЮЌЛЄИќаТЕФЃЌБфЖЏашжДааБфИќСїГЬЁЃ
вЕЮёЙ§ГЬ
жИЙЋЫОЕФвЕЮёЛюЖЏЪТМўЃЌШчКєЕЅЁЂжЇИЖЖМЪЧвЕЮёЙ§ГЬЁЃЦфжаЃЌвЕЮёЙ§ГЬВЛПЩВ№ЗжЁЃ
ЪБМфжмЦк
гУРДУїШЗЭГМЦЕФЪБМфЗЖЮЇЛђепЪБМфЕуЃЌШчзюНќ30ЬьЁЂздШЛжмЁЂНижЙЕБШеЕШЁЃ
аоЪЮРраЭ
ЪЧЖдаоЪЮДЪЕФвЛжжГщЯѓЛЎЗжЁЃаоЪЮРраЭДгЪєгкФГИівЕЮёгђЃЌШчШежОгђЕФЗУЮЪжеЖЫРраЭКИЧAPPЖЫЁЂPCЖЫЕШаоЪЮДЪЁЃ
аоЪЮДЪ
жИЕФЪЧЭГМЦЮЌЖШвдЭтжИБъЕФвЕЮёГЁОАЯоЖЈГщЯѓЃЌаоЪЮДЪЪєгквЛжжаоЪЮРраЭЃЌШчдкШежОгђЕФЗУЮЪжеЖЫРраЭЯТЃЌгааоЪЮДЪAPPЁЂPCЖЫЕШЁЃ
ЖШСП/дзгжИБъ
дзгжИБъКЭЖШСПКЌвхЯрЭЌЃЌЛљгкФГвЛвЕЮёЪТМўааЮЊЯТЕФЖШСПЃЌЪЧвЕЮёЖЈвхжаВЛПЩдйВ№ЗжЕФжИБъЃЌОпгаУїШЗвЕЮёКЌвхЕФУћГЦЃЌШчжЇИЖН№ЖюЁЃ
ЮЌЖШ
ЮЌЖШЪЧЖШСПЕФЛЗОГЃЌгУРДЗДгГвЕЮёЕФвЛРрЪєадЃЌетРрЪєадЕФМЏКЯЙЙГЩвЛИіЮЌЖШЃЌвВПЩвдГЦЮЊЪЕЬхЖдЯѓЁЃЮЌЖШЪєгквЛИіЪ§ОнгђЃЌШчЕиРэЮЌЖШЃЈЦфжаАќРЈЙњМвЁЂЕиЧјЁЂЪЁЪаЕШЃЉЁЂЪБМфЮЌЖШЃЈЦфжаАќРЈФъЁЂМОЁЂдТЁЂжмЁЂШеЕШМЖБ№ФкШнЃЉЁЃ
ЮЌЖШЪєад
ЮЌЖШЪєадСЅЪєгквЛИіЮЌЖШЃЌШчЕиРэЮЌЖШРяУцЕФЙњМвУћГЦЁЂЙњМвIDЁЂЪЁЗнУћГЦЕШЖМЪєгкЮЌЖШЪєадЁЃ
жИБъЗжРржївЊЗжЮЊдзгжИБъЁЂХЩЩњжИБъЁЂбмЩњжИБъ
дзгжИБъ
ЛљгкФГвЛвЕЮёЪТМўааЮЊЯТЕФЖШСПЃЌЪЧвЕЮёЖЈвхжаВЛПЩдйВ№ЗжЕФжИБъЃЌОпгаУїШЗвЕЮёКЌвхЕФУћГЦЃЌШчКєЕЅСПЁЂНЛвзН№Жю
ХЩЩњжИБъ
ЪЧ1ИідзгжИБъ+ЖрИіаоЪЮДЪЃЈПЩбЁЃЉ+ЪБМфжмЦкЃЌЪЧдзгжИБъвЕЮёЭГМЦЗЖЮЇЕФШІЖЈЁЃХЩЩњжИБъгжЗжвдЯТЖўжжРраЭЃК
ЪТЮёаЭжИБъ
ЪЧжИЖдвЕЮёЙ§ГЬНјааКтСПЕФжИБъЁЃР§ШчЃЌКєЕЅСПЁЂЖЉЕЅжЇИЖН№ЖюЃЌетРржИБъашвЊЮЌЛЄдзгжИБъвдМАаоЪЮДЪЃЌдкДЫЛљДЁЩЯДДНЈХЩЩњжИБъЁЃ
ДцСПаЭжИБъ
ЪЧжИЖдЪЕЬхЖдЯѓЃЈШчЫОЛњЁЂГЫПЭЃЉФГаЉзДЬЌЕФЭГМЦЃЌР§ШчзЂВсЫОЛњзмЪ§ЁЂзЂВсГЫПЭзмЪ§ЃЌетРржИБъашвЊЮЌЛЄдзгжИБъвдМАаоЪЮДЪЃЌдкДЫЛљДЁЩЯДДНЈХЩЩњжИБъЃЌЖдгІЕФЪБМфжмЦквЛАуЮЊЁАРњЪЗНижЙЕБЧАФГИіЪБМфЁБЁЃ
бмЩњжИБъ
ЪЧдкЪТЮёаджИБъКЭДцСПаЭжИБъЕФЛљДЁЩЯИДКЯГЩЕФЁЃжївЊгаБШТЪаЭЁЂБШР§аЭЁЂЭГМЦаЭОљжЕЁЃ
ФЃаЭЩшМЦ
жївЊВЩгУЮЌЖШНЈФЃЗНЗЈНјааЙЙНЈЃЌЛљДЁвЕЮёУїЯИЪТЪЕБэжївЊДцДЂЮЌЖШЪєадМЏКЯКЭЖШСП/дзгжИБъЃЛЗжЮівЕЮёЛузмЪТЪЕБэАДеежИБъРрБ№(ШЅжижИБъЁЂЗЧШЅжижИБъ)ЗжРрДцДЂЃЌЗЧШЅжижИБъЛузмЪТЪЕБэДцДЂЭГМЦЮЌЖШМЏКЯЁЂдзгжИБъЛђХЩЩњжИБъЃЌШЅжижИБъЛузмЪТЪЕБэжЛДцДЂЗжЮіЪЕЬхЭГМЦБъЧЉМЏКЯЁЃ
жИБъЬхЯЕдкЪ§ВжЮяРэЪЕЯжВуУцжївЊЪЧНсКЯЪ§ВжФЃаЭЗжВуМмЙЙНјаажИЕМНЈЩшЃЌЕЮЕЮЕФжИБъЪ§ОнжївЊДцДЂдкDWMВуЃЌзїЮЊжИБъЕФКЫаФЙмРэВуЁЃ

жИБъЬхЯЕдЊЪ§ОнЙмРэ
ЮЌЖШЙмРэ
АќРЈЛљДЁаХЯЂКЭММЪѕаХЯЂЃЌгЩВЛЭЌНЧЩЋНјааЮЌЛЄЙмРэЁЃ
ЛљДЁаХЯЂЖдгІЮЌЖШЕФвЕЮёаХЯЂЃЌгЩвЕЮёЙмРэШЫдБЁЂЪ§ОнВњЦЗЛђBIЗжЮіЪІЮЌЛЄЃЌжївЊАќРЈЮЌЖШУћГЦЁЂвЕЮёЖЈвхЁЂвЕЮёЗжРрЁЃ
ММЪѕаХЯЂЖдгІЮЌЖШЕФЪ§ОнаХЯЂЃЌгЩЪ§ОнбаЗЂЮЌЛЄЃЌжївЊАќРЈЪЧЗёгаЮЌБэЃЈЪЧУЖОйЮЌЖШЛЙЪЧгаЖРСЂЕФЮяРэЮЌБэЃЉЁЂЪЧЗёЪЧШеЦкЮЌЁЂЖдгІcodeгЂЮФУћГЦКЭжаЮФУћГЦЁЂЖдгІnameгЂЮФУћГЦКЭжаЮФУћГЦЁЃШчЙћЮЌЖШгаЮЌЖШЮяРэБэЃЌдђашвЊКЭЖдгІЕФЮЌЖШЮяРэБэАѓЖЈЃЌЩшжУcodeКЭnameЖдгІЕФзжЖЮЁЃШчЙћЮЌЖШЪЧУЖОйЮЌЃЌдђашвЊЬюаДЖдгІЕФcodeКЭnameЁЃЮЌЖШЕФЭГвЛЙмРэЃЌгаРћгквдКѓЪ§ОнБэЕФБъзМЛЏЃЌвВБугкгУЛЇЕФВщбЏЪЙгУЁЃ
жИБъЙмРэ
АќРЈЛљДЁаХЯЂЁЂММЪѕаХЯЂКЭбмЩњаХЯЂЃЌгЩВЛЭЌНЧЩЋНјааЮЌЛЄЙмРэЁЃ
ЛљДЁаХЯЂЖдгІжИБъЕФвЕЮёаХЯЂЃЌгЩвЕЮёЙмРэШЫдБЁЂЪ§ОнВњЦЗЛђBIЗжЮіЪІЮЌЛЄЃЌжївЊАќРЈЙщЪєаХЯЂ(вЕЮёАхПщЁЂЪ§ОнгђЁЂвЕЮёЙ§ГЬ)ЃЌЛљБОаХЯЂ(жИБъУћГЦЁЂжИБъгЂЮФУћГЦЁЂжИБъЖЈвхЁЂЭГМЦЫуЗЈЫЕУїЁЂжИБъРраЭ(ШЅжиЁЂЗЧШЅжи))ЃЌвЕЮёГЁОАаХЯЂ(ЗжЮіЮЌЖШЃЌГЁОАУшЪі)ЃЛ
ММЪѕаХЯЂЖдгІжИБъЕФЮяРэФЃаЭаХЯЂЃЌгЩЪ§ОнбаЗЂНјааЮЌЛЄЃЌжївЊАќРЈЖдгІЮяРэБэМАзжЖЮаХЯЂЃЛ
бмЩњаХЯЂЖдгІЙиСЊХЩЩњЛђбмЩњжИБъаХЯЂЁЂЙиСЊЪ§ОнгІгУКЭвЕЮёГЁОАаХЯЂЃЌБугкгУЛЇВщбЏжИБъБЛФФаЉЦфЫќжИБъКЭЪ§ОнгІгУЪЙгУЃЌЬсЙЉжИБъбЊдЕЗжЮізЗВщЪ§ОнРДдДЕФФмСІЁЃ
дзгжИБъЖЈвхЙщЪєаХЯЂ + ЛљБОаХЯЂ + вЕЮёГЁОАаХЯЂХЩЩњжИБъЖЈвхЪБМфжмЦк + аоЪЮДЪМЏКЯ + дзгжИБъаоЪЮРраЭжївЊАќКЌРраЭЫЕУїЁЂЭГМЦЫуЗЈЫЕУїЁЂЪ§ОндД(ПЩбЁ)
жИБъЬхЯЕНЈЩшСїГЬ
НЈФЃСїГЬ
НЈФЃСїГЬжївЊЪЧДгвЕЮёЪгНЧжИЕМЙЄГЬЪІЖдашЧѓГЁОАЩцМАЕФжИБъНјаажїЬтГщЯѓЃЌЙщРрЃЌЭГвЛвЕЮёЪѕгяЃЌМѕЩйЙЕЭЈГЩБОЃЌЭЌЪББмУтКѓајЕФжИБъжиИДНЈЩшЁЃ
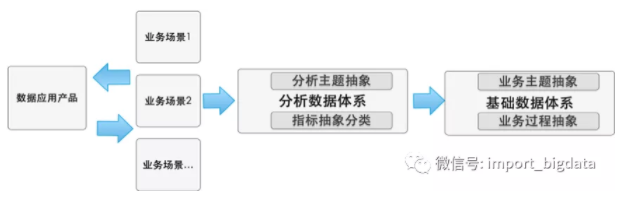
ЗжЮіЪ§ОнЬхЯЕЪЧФЃаЭМмЙЙжаЛузмЪТЪЕБэЕФЮяРэМЏКЯЃЌвЕЮёТпМВуУцИљОнвЕЮёЗжЮіЖдЯѓЛђГЁОАНјаажИБъЬхЯЕГщЯѓГСЕэЁЃЕЮЕЮГіаажївЊЪЧИљОнЗжЮіЖдЯѓНјаажїЬтГщЯѓЕФЃЌР§ШчЫОЛњжїЬтЁЂАВШЋжїЬтЁЂЬхбщжїЬтЁЂГЧЪажїЬтЕШЁЃжИБъЗжРржївЊЪЧИљОнЪЕМЪвЕЮёЙ§ГЬНјааГщЯѓЗжРрЃЌР§ШчЫОЛњНЛвзРржИБъЁЂЫОЛњзЂВсРржИБъЁЂЫОЛњдіГЄРржИБъЕШЁЃЛљДЁЪ§ОнЬхЯЕЪЧФЃаЭМмЙЙжаУїЯИЪТЪЕБэКЭЛљДЁЮЌЖШБэЕФЮяРэМЏКЯЃЌвЕЮёТпМВуУцИљОнЪЕМЪвЕЮёГЁОАНјааГщЯѓР§ШчЫОЛњКЯЙцЁЂГЫПЭзЂВсЕШЃЌЛЙдвЕЮёКЫаФвЕЮёЙ§ГЬЁЃ
ПЊЗЂСїГЬ
ПЊЗЂСїГЬЪЧДгММЪѕЪгНЧжИЕМЙЄГЬЪІНјаажИБъЬхЯЕЩњВњЁЂдЫЮЌМАжЪСПЙмПиЃЌвВЪЧЪ§ОнВњЦЗЛђЪ§ОнЗжЮіЪІКЭЪ§ВжбаЗЂЙЕЭЈаЕїЕФЧХСКЁЃ

жИБъЬхЯЕЭМЦзНЈЩш
жИБъЬхЯЕЭМЦзИХЪі
жИБъЬхЯЕЭМЦзвВПЩГЦЮЊЪ§ОнЗжЮіЭМЦзжївЊЪЧвРОнЪЕМЪвЕЮёГЁОАГщЯѓвЕЮёЗжЮіЪЕЬхЃЌећКЯЪсРэЪЕЬхЩцМАЕФвЕЮёЗжРрЁЂЗжЮіжИБъКЭЮЌЖШЕФМЏКЯЁЃ
НЈЩшЗНЗЈЃКжївЊЪЧЭЈЙ§вЕЮёЫМЮЌЁЂгУЛЇЪгНЧШЅЙЙНЈЃЌАбвЕЮёКЭЪ§ОнНєУмЙиСЊЦ№РДЃЌАбжИБъНсЙЙЛЏЗжРрзщжЏ
НЈЩшФПЕФЃК
ЖдгкгУЛЇЃК
БугкгУЛЇФмЙЛПьЫйЖЈЮЛЫљашжИБъКЭЮЌЖШЃЌЭЌЪБЭЈЙ§вЕЮёГЁОАЛЏГСЕэжИБъЬхЯЕЃЌФмЙЛПьЫйДЅДягУЛЇЪ§ОнЫпЧѓ
ЖдгкбаЗЂЃК
РћгкКѓајжИБъЩњВњФЃаЭЩшМЦЁЂЪ§ОнФкШнБпНчЛЏЁЂЪ§ОнЬхЯЕНЈЩшЕќДњСПЛЏКЭЪ§ОнзЪВњЕФТфЕи


жИБъЬхЯЕВњЦЗЛЏ

жИБъЬхЯЕЩцМАЕФВњЦЗМЏжївЊЪЧвРОнЦфЩњУќжмЦкНјааЯргІНЈЩшЃЌЭЈЙ§ВњЦЗЙЄОпДђЭЈЪ§ОнСїЃЌЪЕЯжжИБъЬхЯЕЭГвЛЛЏЁЂздЖЏЛЏЁЂЙцЗЖЛЏЁЂСїГЬЛЏЙмРэЁЃвђЮЊжИБъЬхЯЕНЈЩшБОжЪФПБъЪЧЗўЮёвЕЮёЃЌЪЕЯжЪ§ОнЧ§ЖЏвЕЮёМлжЕЃЌЫљвдНЈЩшЕФКЫаФддђЪЧЁАЧсБъзМЁЂжиГЁОАЃЌДгЙмПиЪНЕНЗўЮёЪНЁБЁЃЭЈЙ§ЙЄОпЁЂВњЦЗЁЂММЪѕКЭзщжЏЕФШкКЯЬсИпгУЛЇЪЙгУЪ§ОнаЇТЪЃЌМгЫйвЕЮёДДаТЕќДњЁЃ
ЦфжаКЭжИБъЬхЯЕЗНЗЈТлЧПЯрЙиВњЦЗОЭЪЧжИБъзжЕфЙЄОпЕФТфЕиЃЌЦфВњЦЗЕФЖЈЮЛМАМлжЕЃК
жЇГХжИБъЙмРэЙцЗЖДгЗНЗЈЕНТфЕиЕФЙЄОпЃЌздЖЏЩњГЩЙцЗЖжИБъЃЌНтОіжИБъУћГЦЛьТвЁЂжИБъВЛЮЈвЛЕФЮЪЬтЃЌЯћГ§Ъ§ОнЕФЖўвхад
ЭГвЛЖдЭтЬсЙЉБъзМЕФжИБъПкОЖКЭдЊЪ§ОнаХЯЂ

ЙЄОпЩшМЦСїГЬ (ЗНЗЈТл->ЖЈвх->ЩњВњ->ЯћЗб)

жИБъЖЈвх

жИБъЩњВњ
етВПЗжећЬхНщЩмСЫжИБъЬхЯЕНЈЩшЗНЗЈТлКЭЙЄОпВњЦЗЕФНЈЩшЧщПіЃЌФПЧАжИБъзжЕфКЭПЊЗЂЙЄОпвбЪЕЯжСїГЬДђЭЈЃЌгыЪ§ОнЯћЗбВњЦЗЕФДђЭЈКѓајЛсЭЈЙ§DataAPIЗНЪНЬсЙЉЪ§ОнЗўЮёЃЌЙцЛЎНЈЩшжаЁЃ
Ш§ЁЂЪ§ОнжЮРэ
1ЁЂЪ§ОнжЮРэ жЮЕФЪЧЁАЪ§ОнЁБТ№ЃП
Ъ§ОнЪЧжИЖдПЭЙлЪТМўНјааМЧТМВЂПЩвдМјБ№ЕФЗћКХЃЌЪЧЖдПЭЙлЪТЮяЕФаджЪЁЂзДЬЌвдМАЯрЛЅЙиЯЕЕШНјааМЧдиЕФЮяРэЗћКХЛђетаЉЮяРэЗћКХЕФзщКЯЁЃЦфЪЕдкЮвПДРДЃЌЪ§ОнПЩвдЗжЮЊСНИіВПЗжЃЌвЛЪЧЪ§зжЃЌЖўЪЧЮФзжЁЃЪ§зжЪЧУЛгавтвхЕФГщЯѓЗћКХЃЌЪ§ОнЪЧгавтвхЕФЪ§зжЁЃЮФзжБэвтЃЌЪ§зжБэСПЃЌЕБСНепНсКЯЦ№РДЃЌЪ§ОнОЭВњЩњСЫЁЃ
дкЮвУЧЕФЩњЛюКЭЙЄзїЕБжаЃЌЪ§ОнЮоДІВЛдкЁЃЖдЦѓвЕРДНВЃЌгаКмЖрЪ§ОнЪЧЮоЙиЦѓвЕжиДѓРћвцЕФЪ§ОнЃЌЪЧУЛгажЮРэЕФБивЊЕФЁЃЪ§ОнжЮРэЕФЖдЯѓБиаыЪЧживЊЕФЪ§ОнзЪдДЃЌЪЧЙиКѕЦѓвЕжиДѓЩЬвЕРћвцЕФЪ§ОнзЪдДЃЌетбљЕФЪ§ОнзЪдДПЩвдГЦЦфЮЊЁАЪ§ОнзЪВњЁБЁЃе§ШчББДѓНЬЪкЭѕККЩњЯШЩњЫљЫЕЃКЁАЪ§ОнжЮРэВЛЪЧЖдЁАЪ§ОнЁБЕФжЮРэЃЌЖјЪЧЖдЁАЪ§ОнзЪВњЁБЕФжЮРэЃЌЪЧЖдЪ§ОнзЪВњЫљгаЯрЙиЗНРћвцЕФаЕїгыЙцЗЖЁЃЁБ
ЮвУЧашвЊЗжПЊРДРэНтетОфЛАЃК
ЂйЪВУДЪЧЪ§ОнзЪВњЃП
ЂкЪ§ОнзЪВњЕФЯрЙиРћвцЗНЪЧЫЃП
ЂлаЕїгыЙцЗЖЪВУДЃП
ЯШЫЕвЛЫЕЪВУДЪЧЪ§ОнзЪВњЁЃ ЮвУЧЫЕВЛЪЧЫљгаЪ§ОнЖМЪЧЪ§ОнзЪВњЃЌФЧЕНЕзЪВУДВХЪЧЪ§ОнзЪВњФиЃП
ЁЖЦѓвЕЛсМЦзМдђ-ЛљБОзМдђЁЗЕк20ЬѕЙцЖЈЃКЁАзЪВњЪЧжИЦѓвЕЙ§ШЅЕФНЛвзЛђепЪТЯюаЮГЩЕФЁЂгЩЦѓвЕгЕгаЛђепПижЦЕФЁЂдЄЦкЛсИјЦѓвЕДјРДОМУРћвцЕФзЪдДЁЃЁБ ШчЙћееУЈЛЛЂаоИФвЛЯТЃЌВЛФбЛёЕУвЛИіЙигкЪ§ОнзЪВњЕФЖЈвхЃКЁАЪ§ОнзЪВњЪЧжИЦѓвЕЙ§ШЅЕФНЛвзЛђепЪТЯюаЮГЩЕФЃЌгЩЦѓвЕгЕгаЛђепПижЦЕФЃЌдЄЦкЛсИјЦѓвЕДјРДОМУРћвцЕФЪ§ОнзЪдДЁЃЁБгЩДЫПЩМћЃЌЪ§ОнвЊГЩЮЊЪ§ОнзЪВњЃЌжСЩйвЊТњзу3ИіКЫаФБивЊЬѕМўЃК
ЂйЪ§ОнзЪВњгІИУЪЧЦѓвЕЕФНЛвзЛђепЪТЯюаЮГЩЕФЃЛ
ЂкЦѓвЕгЕгаЛђепПижЦЃЛ
ЂлдЄЦкЛсИјЦѓвЕДјРДОМУРћвцЁЃ
Ъ§ОнзЪВњЕФРћвцЯрЙиЗНЪЧЫЃП
ИљОнЪ§ОнзЪВњЕФЖЈвхЃЌЪ§ОнзЪВњЕФРћвцЯрЙиЗНЃЌАќРЈЃК
ЂйЪ§ОнЕФЩњВњепЃЌМДЭЈЙ§вЕЮёНЛвзЛђЪТЯюВњЩњЪ§ОнЕФШЫЛђзщжЏЁЃ
ЂкЪ§ОнЕФгЕгаЛђПижЦепЃЌЩњВњЪ§ОнЕФШЫВЛвЛЖЈЪЧгЕгаЪ§ОнЃЌОЭЯёЮвУЧЬьЬьЩЯЭјЕФИїжжЪ§ОнЖМВЛЙщЮвУЧздМКЫљгаЃЌЖјЪЧТфдкСЫИїИіЛЅСЊЭјЙЋЫОЕФЪ§ОнПтжаЁЃ
ЂлЪ§ОнМлжЕКЭОМУРћвцЕФЪевцепЁЃЪ§ОнжЮРэОЭЪЧЖдЪ§ОнЩњВњепЁЂгЕгаЛђПижЦепЃЌЪ§ОнМлжЕЛёвцепЕФЙцЗЖКЭаЕїЁЃ
ЖМЪВУДЪЧашвЊаЕїКЭЙцЗЖЃП
ЪзЯШЪЧЪ§ОнЕФБъзМЛЏ ЃЌЖЈвхЭГвЛЕФЪ§ОнБъзМЃЌЁАаДжаЙњзжЁЂЫЕЦеЭЈЛАЁБШУЪ§ОнзЪВњЕФЯрЙиРћвцЗНдкЭЌвЛИіЁАЦЕЕРЁБЙЕЭЈЁЃЪ§ОнЕФБъзМЛЏАќКЌМИИіВуУцЃКЂйЪ§ОнФЃаЭБъзМЛЏЁЃЂкКЫаФЪ§ОнЪЕЬхЕФБъзМЛЏЃЈжїЪ§ОнЕФБъзМЛЏЃЉЁЃЂлЙиМќжИБъЕФБъзМЛЏЁЃ
ЦфДЮЪЧЪ§ОнЕФШЗШЈЁЃ Ъ§ОнвЛЕЉГЩЮЊзЪВњЃЌОЭвЛЖЈгагЕгаЗНЃЌЛђепЪЕМЪПижЦШЫЃЌПЩвдАбЫћУЧЭГГЦВњШЈШЫЁЃгыЪЕЮяВЛЭЌЕФЪЧЃЌЪЕЮяЕФВњШЈЪЧБШНЯУїШЗЕФЃЌЪ§ОндђБШНЯИДдгЁЃВњЦЗдкЩњВњжЦдьЙ§ГЬжаЃЌВЂУЛгагыЯћЗбепНЛвзжЎЧАЃЌжЦдьЩЬгЕгаЭъШЋВњШЈЁЃВњЦЗЩњВњГіРДКѓЃЌЯћЗбепЭЈЙ§ЙКТђжЇИЖЯргІЕФЛѕБвЃЌБугЕгаСЫВњЦЗЕФВњШЈЁЃЖјЪ§ОнЕФЩњВњЙ§ГЬОЭВЛвЛбљСЫЃЌЮвУЧЕФИїжжЩЯЭјааЮЊУПЬьЖМЛсВњЩњДѓСПЕФЪ§ОнЃЌР§ШчЃКЭјЩЯЙКЮяЁЂфЏРРЭјвГЁЂЪЙгУЕиЭМЁЂЦРТл/ЦРМлЁЁЁЃетаЉЪ§ОнЕНЕзЙщЫЫљгаЃППижЦШЈИУШчКЮжЮРэЃПетЪЧАкдкУцЧАЕФвЛИіФбЬтЃЁЮвУЧПДЕННќМИФъвЛаЉВЛСМЩЬМвЃЌРћгУЮвУЧЕФЩЯЭјЪ§ОнЃЌЕМжТАВШЋвўЫНаЙУмЕФЪТМўвВВуГіВЛЧюЁЃЯЃЭћЫцзХММЪѕКЭЩЬвЕЕФНјВНЃЌОЁПьФмЙЛевЕННтОіЗНАИЃЁ
ЕкШ§ЪЧСїГЬЕФгХЛЏЁЃ Ъ§ОнжЮРэЕФСНИіФПБъЃКвЛИіЪЧЬсжЪСПЃЌвЛИіЪЧПиАВШЋЁЃЛЅСЊЭјЪ§ОнЕФШЗШЈФПЧАвбОЪЧвЛИіЪРНчМЖФбЬтЃЌзіКУЦѓвЕвЕЮёСїГЬЕФгХЛЏПЩФмЛсЖдвўЫНБЃЛЄЦ№ЕНвЛЖЈЕФзїгУЁЃЭЈЙ§вЕЮёСїГЬгХЛЏЃЌЙцЗЖЪ§ОнДгВњЩњЁЂДІРэЁЂЪЙгУЕНЯњЛйЕФећИіЩњУќжмЦкЃЌЪЙЕУЪ§ОндкИїНзЖЮЁЂИїСїГЬЛЗНкАВШЋПЩПиЃЌКЯЙцЪЙгУЁЃСэЭтЃЌЭЈЙ§вЛЖЈЕФСїГЬгХЛЏЃЌЭЈЙ§ЖдЯрЙиСїГЬНјааМрЙмЃЌАДееЪ§ОнЕФжЪСПЙцдђНјааЪ§ОнаЃбщЃЌЗћКЯЁАРЌЛјНјЁЂРЌЛјГіЁБЕФЪ§ОнВЩМЏЁЂДІРэЁЂДцДЂддђЃЌЬсЩ§Ъ§ОнжЮРэЃЌИГФмвЕЮёгІгУЁЃ
2ЁЂЪ§ОнжЮРэ ЕНЕздкФФРяжЮЃП
Ъ§ОнжЮРэЕНЕзгІИУЗХдкжаЬЈЃЌЛЙЪЧКѓЬЈЃЌЮвИіШЫЕФРэНтЪЧЃК аЁЪ§ОнБъзМЛЏжЮРэППШЫЙЄЁЂДѓЪ§ОндЄВтадЗжЮіППжЧФмЃЌНЋСНепНсКЯЦ№РДЃКЁАШЫЙЄ+жЧФмЁБаЮГЩСЫЭъећЕФЪ§ОнжЮРэММЪѕЬхЯЕЁЃ вЛИіЦѓвЕЕФЪ§ОнжЮРэМШРыВЛПЊаЁЪ§ОнЕФБъзМЛЏжЮРэЃЌвВРыВЛПЊДѓЪ§ОнЕФдЄВтадЗжЮіЁЃ
етРяЕФаЁЪ§ОнЃЌЪЧдкГадиЪТЮяЪЕЬхЕФЪ§ОнЃЌР§ШчЃКШЫЁЂВЦЁЂЮяЕШЃЌЪЧЦѓвЕЫљгавЕЮёПЊеЙЕФдиЬхЁЃЦфЪЕЫЕАзСЫОЭЪЧжїЪ§ОнЙмРэЁЃЖдгкжїЪ§ОнЕФжЮРэБЪепШЯЮЊЪЧвЛИіКѓЬЈааЮЊЃЌжЮРэКЫаФЪЧЁАЮЈвЛЪ§ОндДЁЂЭГвЛЪ§ОнБъзМЁБЃЌЖјвЊДяЕНетвЛФПБъЪЧашвЊДгЪ§ОнЕФдДЭЗзЅЦ№ЕФЃЌВЂЧвашвЊДѓСПЕФШЫЮЊИЩдЄЃЌБШШчЃКЪ§ОнБъзМЕФжЦЖЈКЭТфЪЕЃЌЪ§ОнжЪСПЕФЧхЯДЃЌЪ§ОнЕФЩъЧыЩѓХњЃЌЪ§ОнЕФЗжЗЂКЭЙВЯэЕШЁЃДгетРявВФмЙЛПДГіаЁЪ§ОнЕФжЮРэЃЌзЗЧѓЕФЪЧБъзМЛЏЁЂОЋШЗЛЏЃЌгІИУЪЧвЛИіКѓЬЈааЮЊЁЃ
ЖјдкДѓЪ§ОнЪБДњЃЌЕУвцгкДѓЪ§ОнММЪѕЕФЭЛЦЦЃЌДѓСПЕФНсЙЙЛЏЁЂЗЧНсЙЙЛЏЁЂвьЙЙЛЏЕФЪ§ОнФмЙЛЕУЕНДЂДцЁЂДІРэЁЂМЦЫуКЭЗжЮіЃЌетвЛЗНУцЬсЩ§СЫЮвУЧДгКЃСПЪ§ОнжаЛёШЁжЊЪЖКЭЖДМћЕФФмСІЁЃЖдгкДѓЪ§ОнЃЌДЋЭГЕФвЛЮЖзЗЧѓОЋШЗЕФЫМЮЌЪмЕНСЫЬєеНЁЃЖјЖдгкДѓЪ§ОнЕФжЮРэЃЌдЪаэвЛЖЈГЬЖШЩЯЕФШнДэЃЌЗДЖјПЩвддкКъЙлВуУцгЕгаИќКУЕФжЊЪЖКЭЖДВьСІЁЃЖдгкДѓЪ§ОнЕФжЮРэИќЖрЕФЪЧВЩгУAIММЪѕЃЌР§ШчЃКжЊЪЖЭМЦзЁЂгявєЪЖБ№ЕШЃЌЖдДѓЪ§ОнЕФВЩМЏЁЂДІРэЁЂЪЙгУЙ§ГЬМгвдПижЦЃЌЪЙЦфФмЙЛКЯЙцЪЙгУЁЃЫљвдЃЌДѓЪ§ОнЕФжЮРэЗХдкжаЬЈЫЦКѕИќЮЊКЯЪЪЁЃ
3ЁЂЪ§ОнжЮРэ ЕНЕзгІИУдѕУДжЮЃП
1ЁЂевжЂзДЃЌУїШЗФПБъ
ШЮКЮЦѓвЕЪЕЪЉЪ§ОнжЮРэЖМВЛЪЧЮЊСЫжЮРэЪ§ОнЖјжЮРэЪ§ОнЃЌЦфБГКѓЖМЪЧЙмРэКЭвЕЮёФПБъЕФЧ§ЖЏЁЃЦѓвЕжаЦеБщДцдкЕФЪ§ОнжЪСПЮЪЬтгаЃКЪ§ОнВЛвЛжТЁЂЪ§ОнжиИДЁЂЪ§ОнВЛзМШЗЁЂЪ§ОнВЛЭъећЁЂЪ§ОнЙиЯЕЛьТвЁЂЪ§ОнВЛМАЪБЕШЁЃ

гЩгкетаЉЪ§ОнЮЪЬтЕФДцдкЖдвЕЮёЕФПЊеЙКЭвЕЮёВПУХжЎМфЕФЙЕЭЈдьГЩСЫНЯДѓЕФРЇШХЃЌВњЩњСЫКмДѓЕФГЩБОЃЛИївьЙЙЕФЯЕЭГжаЪ§ОнВЛвЛжТЃЌЕМжТвЕЮёЯЕЭГжЎМфЕФгІгУМЏГЩЮоЗЈПЊеЙЃЛЪ§ОнжЪСПВюЮоЗЈжЇГХЪ§ОнЗжЮіЃЌЗжЮіНсЙћгыЪЕМЪЦЋВюНЯДѓЁЃШЛЖјвЊЪЕЯжЪ§ОнЧ§ЖЏЙмРэЁЂЪ§ОнЧ§ЖЏвЕЮёЕФФПБъЃЌУЛгаИпжЪСПЕФЪ§ОнжЇГХЪЧааВЛЭЈЕФЁЃ
ФПБъЃКЦѓвЕЪЕЪЉЪ§ОнжЮРэЕФЕквЛВНЃЌОЭЪЧвЊУїШЗЪ§ОнжЮРэЕФФПБъЃЌРэЧхЪ§ОнжЮРэЕФЙиМќЕуЁЃ
ММЪѕЙЄОпЃКЪЕЕиЕїбаЁЂИпВуЗУЬИЁЂзщжЏМмЙЙЭМЁЃ
ЪфШыЃКЦѓвЕЪ§ОнеНТдЙцЛЎЃЌиНД§НтОіЕФвЕЮёЮЪЬтЃЌОгЊЗЂеЙашЧѓЃЌвЕЮёашЧѓЕШЃЛ
ЪфГіЃКЪ§ОнжЮРэЕФГѕВНЙЕЭЈЗНАИЃЌЯюФПШЮЮёЪщЃЌЙЄзїМЦЛЎБэЃЛ
2ЁЂРэЪ§ОнЃЌЯжзДЗжЮі
еыЖдЦѓвЕЪ§ОнжЮРэЫљДІЕФФкЭтВПЛЗОГЃЌДгзщжЏЁЂШЫдБЁЂСїГЬЁЂЪ§ОнЫФИіЗНУцШыЪжЃЌНјааЪ§ОнжЮРэЯжзДЕФЗжЮіЁЃ

ФГЦѓвЕЪ§ОнжЮРэЭДЕуЗжЮі
зщжЏЗНУцЃКЪЧЗёгазЈвЕЕФЪ§ОнжЮРэзщжЏЃЌЪЧЗёУїШЗИкЮЛжАд№КЭЗжЙЄЁЃ
ШЫдБЗНУцЃКЪ§ОнШЫВХЕФзЪдДХфжУЧщПіЃЌАќРЈЪ§ОнБъзМЛЏШЫдБЁЂЪ§ОнНЈФЃШЫдБЃЌЪ§ОнЗжЮіШЫдБЃЌЪ§ОнПЊЗЂШЫдБЕШЃЌвдМАЪ§ОнШЫВХЕФеМБШЧщПіЁЃ
СїГЬЗНУцЃКЪ§ОнЙмРэЕФЯжзДЃЌЪЧЗёгаЙщПкЙмРэВПУХЃЌЪЧЗёгаЪ§ОнЙмРэЕФСїГЬЁЂСїГЬИїЛЗНкЕФЪ§ОнПижЦЧщПіЕШЃЛ
Ъ§ОнЗНУцЃКЪсРэЪ§ОнжЪСПЮЪЬтСаБэЃЌР§ШчЃКЪ§ОнВЛвЛжТЮЪЬтЃЌЪ§ОнВЛЭъећЃЌЪ§ОнВЛзМШЗЁЂЪ§ОнВЛецЪЕЁЂЪ§ОнВЛМАЪБЁЂЪ§ОнЙиЯЕЛьТвЃЌвдМАЪ§ОнЕФвўЫНгыАВШЋЮЪЬтЕШЁЃ
ФПБъЃКЗжЮіЦѓвЕЪ§ОнЙмРэКЭЪ§ОнжЪСПЕФЯжзДЃЌШЗЖЈГѕВНЪ§ОнжЮРэГЩЪьЖШЦРЙРЗНАИЁЃ
ММЪѕЙЄОпЃКЪЕЕиЗУЬИЁЂЕїбаБэЁЂЪ§ОнжЪСПЮЪЬтЦРвщБэЁЂЙиМќЪ§ОнЪЖБ№ЗНЗЈТлЃЈР§ШчЃКжїЪ§ОнЬиеїЪЖБ№ЗЈЃЉЃЛ
ЪфШыЃКашЧѓМАЯжзДЕїбаБэЁЂЗУЬИМЧТМЁЂЪ§ОнбљБОЁЂЪ§ОнМмЙЙЁЂЪ§ОнЙмРэжЦЖШКЭСїГЬЮФМўЃЛ
ЪфГіЃКЪ§ОнЮЪЬтСаБэЁЂЪ§ОнU/CОиеѓЁЂЪ§ОнжЮРэЯжзДЗжЮіБЈИцЁЂЪ§ОнжЮРэЦРЙРЗНАИЃЛ
3ЁЂЪ§ОнжЮРэГЩЪьЖШЦРЙР
Ъ§ОнжЮРэГЩЪьЖШЗДгГСЫзщжЏНјааЪ§ОнжЮРэЫљОпБИЕФЬѕМўКЭЫЎЦНЃЌАќРЈдЊЪ§ОнЙмРэЁЂЪ§ОнжЪСПЙмРэЁЂвЕЮёСїГЬећКЯЁЂжїЪ§ОнЙмРэКЭаХЯЂЩњУќжмЦкЙмРэЁЃ

CMMI DMMЪ§ОнЙмРэФмСІГЩЪьЖШЦРЙРФЃаЭ
Ъ§ОнжЮРэГЩЪьЖШЦРЙРЪЧРћгУБъзМЕФГЩЪьЖШЦРЙРЙЄОпНсКЯаавЕзюМбЪЕМљЃЌеыЖдЦѓвЕЕФЪ§ОнжЮРэЯжзДНјааЕФПЭЙлЦРМлКЭДђЗжЃЌевЕНЦѓвЕЪ§ОнжЮРэЕФЖЬАхЃЌвдБужЦЖЈЧаЪЕПЩааЕФааЖЏЗНАИЁЃЪ§ОнжЮРэГЩЪьЖШНсЪјКѓаЮГЩГѕВНЕФааЖЏЗНАИЃЌвЛАуАќРЈЪ§ОнжЮРэеНТдЃЌЪ§ОнжЮРэжИБъЃЌЪ§ОнжЮРэЙцдђЃЌЪ§ОнжЮРэШЈд№ЁЃЪ§ОнжЮРэдИОАКЭЪЙУќЪЧЪ§ОнжЮРэЕФећЬхФПБъЃЛЪ§ОнжЮРэжИБъЖЈвхСЫЪ§ОнжЮРэФПБъЕФКтСПЗНЗЈЃЛЪ§ОнжЮРэЙцдђКЭЖЈвхАќРЈгыЪ§ОнЯрЙиЕФеўВпЁЂБъзМЁЂКЯЙцвЊЧѓЁЂвЕЮёЙцдђКЭЪ§ОнЖЈвхЕШЃЛШЈРћКЭжАд№ЙцЖЈСЫгЩЫРДИКд№жЦЖЉЪ§ОнЯрЙиЕФОіВпЁЂКЮЪБЪЕЪЉЁЂШчКЮЪЕЪЉЃЌвдМАзщжЏКЭИіШЫдкЪ§ОнжЮРэВпТджаИУзіЪВУДЁЃ
ФПБъЃКНсКЯвЕНчБъзМЕФЪ§ОнжЮРэГЩЪьЖШФЃаЭЃЌИљОнЦѓвЕЙмРэКЭвЕЮёашЧѓНјааЪ§ОнжЮРэГЩЪьЕФЦРЙРЃЌаЮГЩГѕВНЕФЪ§ОнжЮРэВпТдКЭааЖЏТЗЯпЁЃ
ММЪѕЙЄОпЃКЪ§ОнжЮРэЦРЙРФЃаЭЃЌР§ШчЃКDCMMЃЌCMMI DMMЃЌIBMЪ§ОнжЮРэГЩЪьЖШЦРЙРФЃаЭЕШЃЛ
ЪфШыЃКЕк2ВНЕФЪфШывдМАЪ§ОнжЮРэЦРЙРФЃаЭЁЂЪ§ОнжЮРэЦРЙРЙЄОпЃЈЦРЙРжИБъЁЂДђЗжБэЕШЃЉЃЛ
ЪфГіЃКЪ§ОнжЮРэЦРЙРНсЙћЃЌЪ§ОнжЮРэВпТдЃЌГѕВНЕФааЖЏЗНАИЃЛ
4ЁЂЪ§ОнжЪСПЮЪЬтИљвђЗжЮі
Ъ§ОнжЮРэЕФФПЕФЪЧНтОіЪ§ОнжЪСПЮЪЬтЬсЩ§Ъ§ОнжЪСПЃЌДгЖјЮЊЪ§ОнЧ§ЖЏЕФЪ§зжЛЏЦѓвЕЬсЙЉдДЖЏСІЃЌЖјЬсЕНЪ§ОнжЪСПЮЪЬтЃЌзіЙ§BIЁЂЪ§ВжЕФЭЌбЇвЛЖЈжЊЕРЃЌетЪЧвЛИіММЪѕКЭвЕЮёЁАОГЃДђМмЁБЯрЛЅЭЦкУЕФЮЪЬтЁЃ

ФГЦѓвЕЪ§ОнЮЪЬтИљвђЗжЮігуЙЧЭМ
ВњЩњЪ§ОнжЪСПЮЪЬтЕФдвђгаКмЖрЃЌгавЕЮёЗНУцЕФЁЂгаЙмРэЗНУцЕФЁЂвВгаММЪѕЗНУцЕФЃЌАДее80/20ЗЈдђЃЌ80%ЕФЮЪЬтЪЧгЩ20%ЕФдвђдьГЩЦ№ЕФЁЃЫљвдЃЌШчЙћФмЙЛНтОіет20%ЕФЮЪЬтЃЌОЭФмЕУЕН80%ЕФИФНјЁЃ
ФПБъЃКЗжЮіВЂевЕНЪ§ОнжЪСПЮЪЬтВњЩњЕФИљБОдвђЃЌжЦЖЈаажЎгааЇЕФНтОіЗНАИЃЛ
ММЪѕЙЄОпЃКЭЗФдЗчБЉЁЂ5W1HЁЂSWOTЁЂвђЙћЃЈгуДЬЃЉЭМЁЂХСРЭМЕШЃЛ
ЪфШыЃКЪ§ОнЮЪЬтСаБэЁЂЪ§ОнU/CОиеѓЁЂЪ§ОнжЮРэЯжзДЗжЮіБЈИцЁЂЪ§ОнжЮРэЦРЙРНсЙћЃЛ
ЪфГіЃКЪ§ОнжЪСПЦРЙРНсЙћЁЂЖдвЕЮёЕФЧБдкгАЯьКЭИљБОдвђЁЃ
5ЁЂвЕЮёгАЯьМАЪЕЪЉгХЯШМЖЦРЙР
ЭЈЙ§Ъ§ОнжЮРэГЩЪьЖШЦРЙРЃЌДгзщжЏЁЂСїГЬЁЂжЦЖШЁЂШЫдБЁЂММЪѕЕШЗНУцевЕНЦѓвЕдкЪ§ОнжЮРэЕФД§ЬсЩ§ЕФСьгђКЭЛЗНкЃЌдйЭЈЙ§Ъ§ОнжЪСПИљвђЗжЮіевЕНЪ§ОнжЪСПЮЪЬтЗЂЩњЕФИљБОдвђЃЌНјвЛВНУїШЗСЫЪ§ОнжЮРэЕФФПБъКЭФкШнЁЃдйНгЯТРДЃЌОЭашвЊШЗЖЈЪ§ОнжЮРэВпТдЃЌЖЈвхЪ§ОнжЮРэЕФЪЕЪЉгХЯШМЖЁЃ

ФГЦѓвЕжїЪ§ОнжЮРэЪЕЪЉгХЯШМЖЦРЙР
ВЛЭЌЕФЪ§ОнжЮРэСьгђНтОіЕФЪЧВЛЭЌЕФЮЪЬтЃЌЖјЪ§ОнжЮРэЕФУПИіСьгђЖМгаЫќЕФЪЕЪЉФбЕуЃЌЖдЦѓвЕРДЫЕЃЌашвЊДгвЕЮёЕФгАЯьГЬЖШЃЌЮЪЬтЕФНєМБГЬЖШЁЂЪЕЪЉЕФФбвзГЬЖШЕШЖрИіЮЌЖШНјааЗжЮіКЭШЈКтЃЌДгЖјевЕНЗћКЯЦѓвЕашЧѓВЂТњзуЦѓвЕЗЂеЙЕФЗНАИЁЃ
ФПБъЃКШЗЖЈЪ§ОнжЮРэКЫаФСьгђКЭжЇГХЬхЯЕЕФНЈЩш/ЪЕЪЉгХЯШМЖЃЛ
ММЪѕЙЄОпЃКЫФЯѓЯоЗЈдђЃЈЗжБ№ДгвЕЮёгАЯьГЬЖШ/ЪЕЪЉФбвдГЬЖШЃЌЮЪЬтживЊГЬЖШ/ЮЪЬтНєМБГЬЖШЛцжЦгХЯШМЖОиеѓЃЉЁЂKANOФЃаЭ
ЪфШыЃКЪ§ОнжЮРэГЩЪьЖШФмСІЦРЙРНсЙћЁЂЪ§ОнжЪСПЮЪЬтИљвђЗжЮіНсЙћЃЛ
ЪфГіЃКЪ§ОнжЮРэЪЕЪЉгХЯШМЖВпТд
6ЁЂжЦЖЈЪ§ОнжЮРэааЖЏТЗЯпКЭМЦЛЎ
ТЗЯпЭМЪЧЪЙгУЬиЖЈММЪѕЗНАИАяжњДяЕНЖЬЦкЛђепГЄЦкФПБъЕФМЦЛЎЃЌгУгкаТВњЦЗЁЂЯюФПЛђММЪѕСьгђЕФПЊЗЂЃЌЪЧжИгІгУМђНрЕФЭМаЮЁЂБэИёЁЂЮФзжЕШаЮЪНУшЪіММЪѕБфЛЏЕФВНжшЛђММЪѕЯрЙиЛЗНкжЎМфЕФТпМЙиЯЕЁЃТЗЯпЭМЪЧвЛжжФПБъМЦЛЎЃЌОЭЪЧАбЮДРДМЦЛЎвЊзіЕФЪТСаГіРДЃЌжБжСДяЕНФГвЛИіФПБъЃЌОЭКУЯёбизХЕиЭМТЗЯпвЛВНвЛВНевЕНжеЕувЛбљЃЌЙЪГЦТЗЯпЭМЁЃ
ФГЦѓвЕЪ§ОнжЮРэЪЕЪЉТЗЯпЭМ
ЦѓвЕЪ§ОнжЮРэЕФЪЕЪЉТЗЯпЭМЕФжЦЖЈЪЧвдЦѓвЕЪ§ОнеНТдЁЊЁЊдИОАКЭЪЙУќЮЊИйСьЃЌвдМБгУгХЯШЮЊддђЃЌвдЗжВНЪЕЪЉЮЊВпТдНјааСЫећЬхЩшМЦКЭЙцЛЎЁЃЪЕЪЉТЗЯпЭМжївЊАќКЌЕФФкШнЃКЗжМИИіНзЖЮЪЕЪЉЃЌУПИіНзЖЮЕФФПБъЁЂЙЄзїФкШнЁЂЪБМфНкЕувЊЧѓЁЂЛЗОГЬѕМўЕШЁЃБЪепЙлЕуЃКШЮКЮвЛИіЦѓвЕЕФЪ§ОнжЮРэЖМВЛЪЧвЛѕэЖјОЭЃЌвЛВНЕНЮЛЕФЃЌашвЊбађНЅНјЁЂГжајгХЛЏЃЁЪЕЪЉТЗЯпЭМОЭЪЧЛљгкДЫВњЩњЕФЃЌвђДЫЫЕЪ§ОнжЮРэЪЕЪЉТЗЯпЭМвВЪЧЫЕЗўРћвцЯрЙиепжЇГжЕФвЛИіживЊЪжЖЮЁЃ
ФПБъЃКШЗЖЈЪ§ОнжЮРэЕФНзЖЮвдМАУПИіНзЖЮЕФФПБъЃЛ
ММЪѕЙЄОпЃКТЗЯпЭМЗЈ
ЪфШыЃКЪ§ОнжЮРэГЩЪьЖШФмСІЦРЙРНсЙћЁЂвЕЮёгАЯьМАЪЕЪЉгХЯШМЖЦРЙРНсЙћЃЛ
ЪфГіЃКЪ§ОнжЮРэЪЕЪЉТЗЯпЭМЛђГЦНзЖЮФПБъМЦЛЎ
7ЁЂжЦЖЈЪ§ОнжЮРэЯъЯИЪЕЪЉЗНАИ
Ъ§ОнжЮРэЯъЯИЪЕЪЉЗНАИЪЧгУгкжИЕМжїЪ§ОнЕФИїЯюЪЕЪЉЙЄзїЃЌвЛАуАќРЈЃКЪ§ОнжЮРэКЫаФСьгђЁЂЪ§ОнжЮРэжЇГХЬхЯЕЁЂЪ§ОнжЮРэЯюФПЙмРэШ§ИіЗНУцЁЃ

Ъ§ОнжЮРэзмЬхПђМмЭМ
Ъ§ОнжЮРэКЫаФСьгђАќРЈЃКЪ§ОнМмЙЙЁЂЪ§ОнЗўЮёЁЂдЊЪ§ОнЙмРэЁЂЪ§ОнжЪСПЙмРэЁЂЪ§ОнБъзМЙмРэЁЂжїЪ§ОнЙмРэЁЂЪ§ОнАВШЋЙмРэЁЂЪ§ОнЩњУќжмЦкЙмРэЁЃ
Ъ§ОнжЮРэжЇГХЬхЯЕАќРЈЃКзщжЏЃЈзщжЏМмЙЙЁЂзщжЏВуДЮЁЂИкЮЛжАд№ЃЉЁЂжЦЖШЃЈЙмПиФЃЪНЁЂЙцеТжЦЖШЁЂПМКЫЛњжЦЃЉЁЂСїГЬЃЈЙщПкВПУХЁЂЙмРэСїГЬЁЂСїГЬШЮЮёЕШЃЉЁЂММЪѕЃЈЪ§ОнМЏГЩЁЂЪ§ОнЧхЯДЁЂЪ§ОнПЊЗЂЁЂЪ§ОнгІгУЁЂЪ§ОндЫгЊЁЂжЇГХЦНЬЈЁЂЪЕЪЉЗНАИЕШЃЉЁЃ
Ъ§ОнжЮРэЯюФПЙмРэЗНАИАќРЈЃКЯюФПзщЖгЁЂЯюФПМЦЛЎЁЂжЪСПБЃжЄМЦЛЎЁЂХфжУЙмРэМЦЛЎЁЂХрбЕКЭЪлКѓЕШЁЃ
ЙигкЪ§ОнжЮРэЕФКЫаФСьгђЃЌЯъМћБЪепжЎЧАЗжЯэЕФЪ§ОнжЮРэПђМмНтЖСЯЕСаЮФеТЁЃ
ЙигкЪ§ОнжЮРэЕФжЇГХЬхЯЕЃЌЯъМћБЪепжЎЧАЗжЯэЕФЪ§ОнжЮРэГЩЙІЙиМќвЊЫиЯЕСаЮФеТЁЃ
ФПБъЃКЛљгкЪ§ОнжЪСПИљвђЗжЮіЁЂвЕЮёгАЯьКЭЪЕЪЉгХЯШМЖЦРЙРНсЙћЃЌжЦЖЈЯъЯИЪЕЪЉЗНАИЃЛ
ЪфШыЃКвЕЮёгАЯьМАЪЕЪЉгХЯШМЖЦРЙРНсЙћЃЌааЖЏТЗЯпКЭМЦЛЎЃЛ
ЪфГіЃКЪ§ОнжЮРэЯъЯИЪЕЪЉЗНАИЁЃ
8ЁЂЪ§ОнжЮРэЪЕЪЉЙ§ГЬПижЦ
Ъ§ОнжЮРэЪЕЪЉЙ§ГЬПижЦЪЧЖдЪ§ОнжЮРэЯюФПЕФЗЖЮЇПижЦЁЂНјЖШПижЦЁЂжЪСППижЦКЭГЩБОПижЦЃЌЭЈЙ§ЖдЦѓвЕЕФИїЯюзЪдДЕФКЯРэаЕїгыРћгУЃЌЖјДяГЩЕФЪ§ОнжЮРэФПБъЕФИїжжДыЪЉЁЃДгЯюФПЙмРэЕФНЧЖШРДНВвВЪЧЯюФПЙмРэЕФЛЦН№Ш§НЧЃКЗЖЮЇЁЂЪБМфЁЂжЪСПЁЂГЩБОЁЃ

ШЮКЮЯюФПЕФжЪСПКЭНјЖШЪЧашвЊСМКУЕФЯюФПЙмРэРДБЃжЄЕФЃЌЪ§ОнжЮРэвВвЛбљЁЃгыДЋЭГЕФШэМўЙЄГЬЯюФПВЛЭЌЃЌЪ§ОнжЮРэЯюФПгазХЗЖЮЇБпНчФЃК§ЁЂгАЯьЗЖЮЇЙуЁЂЖЬЦкФбМћаЇЁЂЪЕЪЉжмЦкГЄЕШЬиЕуЃК
ЂйЗЖЮЇБпНчФЃК§ЃЌЪ§ОнжЮРэЩцМАЕНЕФЙиМќСьгђШчдЊЪ§ОнЙмРэЁЂЪ§ОнжЪСПЙмРэЁЂЪ§ОнБъзМЙмРэЁЂжїЪ§ОнЙмРэЕШКмЖрЪЧДцдкНЛВцЕФЃЌБпНчКмФбНчЖЈЃЌР§ШчЃКЪЕЪЉЪ§ОнжЪСПЙмРэЯюФПЃЌЛсЩцМАдЊЪ§ОнЙмРэЁЂЪ§ОнБъзМЙмРэЕШЃЌЭЌбљвЛИідЊЪ§ОнЙмРэЯюФПвВЛсЩцМАЪ§ОнБъзМКЭЪ§ОнжЪСПЁЃ
ЂкгАЯьЗЖЮЇЙуЃЌЪ§ОнжЮРэЕФЪЕЪЉВЛЪЧвЛИіВПУХФмЙЛЭъГЩЕФЃЌЪЧашвЊДгИпМЖЙмРэВуЁЂЕНИївЕЮёВПУХЁЂаХЯЂВПУХЭЈСІазїЃЌЙВЭЌЭъГЩЕФЃЛ
ЂлЖЬЦкФбМћаЇЃЌЪ§ОнжЮРэЯюФПЪЕЪЉЭъГЩКѓЃЌЦфЪ§ОнжЮРэЕФаЇЙћБЛУПИівЕЮёЕуЕЮВйзїЫљЁАЯЁЪЭЁБЃЌВЂВЛЯёЦфЫћЯюФПЃЌР§ШчBIЃЌФЧбљУїЯдЕФЬхЯжГіРДЃЌЫљвджїЕМЪ§ОнжЮРэЕФВПУХЛсОГЃдтЕНжЪвЩЁЃ
ЂмЪЕЪЉжмЦкГЄЃЌдкУЛгаЧхЮњЕФЪ§ОнжЮРэФПБъКЭЗЖЮЇдМЖЈЕФЧщПіЯТЃЌЪ§ОнжЮРэЪЧвЛИіЁАЮоЕзЖДЁБЁЃЫљвдЃЌдкЪЕЪЉЪ§ОнжЮРэЯюФПжЎЧАжЦЖЈКУЪЕЪЉТЗЯпЭМКЭЯъЯИЕФЪЕЪЉЗНАИОЭЯдЕУИёЭтживЊЃЈЕк6ЁЂ7ВНЃЉЁЃ
ФПБъЃКЭЈЙ§ЖдЪ§ОнжЮРэЯюФПЪЕЪЉЙ§ГЬЕФНјЖШПижЦЁЂжЪСППижЦКЭГЩБОПижЦвдЪЕЯжЪ§ОнжЮРэЕФФПБъЃЛ
ММЪѕЙЄОпЃКPPЃЈЯюФПМЦЛЎЃЉЁЂPMCЃЈЯюФППижЦЃЉЁЂIPMЃЈМЏГЩЯюФПЙмРэЃЉЁЂRSKMЃЈЗчЯеЙмРэЃЉЁЊЁЊCMMIЙ§ГЬгђЃЛ
ЪфШыЃК6-7ВНЕФЪфГіЃКЪ§ОнжЮРэЪЕЪЉТЗЯпЭМЃЌЪ§ОнжЮРэЯъЯИЪЕЪЉЗНАИЃЛ
ЪфГіЃКИїЯюЯюФППижЦДыЪЉЃЌР§ШчЃКЯюФПМЦЛЎЁЂSOWЁЂЯюФПЗчЯеСаБэЁЂЯюФПБЈИцЁЂЯюФПзмНсЕШЃЛ
9ЁЂМрПиЦРЙРЪ§ОнжЮРэЪЕЪЉаЇЙћ
ЫцзХДѓЪ§ОнММЪѕЕФВЛЖЯЗЂеЙЃЌгІЕБДгЦѓвЕЕФШЋОжЪ§ОнжЮРэЛЗОГЕФНЧЖШЃЌУїШЗЪ§ОнжЮРэЙиМќММЪѕдЫгУМАЦфБъзМЙцЗЖЃЌЙЙНЈГЩаЇЦРЙРжИБъЬхЯЕЃЌНјаажЮРэаЇЙћЦРМлЃЛВЂдЫгУЪ§ОнжЮРэФмСІГЩЪьЖШФЃаЭдйДЮЦРЙРЃЌНчЖЈЪ§ОнЙмРэВуДЮЃЌДгЖјЪЙЕУПчЯЕЭГЁЂПчвЕЮёЁЂПчВПУХЕФЪ§ОнжЮРэЬхЯЕЕФНЈЩшгыЪЕЪЉФмЙЛЭЈЙ§ИїЗНазїЫГРћНјааЃЌЪЕЯжзПдНЪ§ОнжЮРэЃЌНјЖјЭЈЙ§Ъ§ОнЧ§ЖЏвЕЮёЁЂЪ§ОнЧ§ЖЏЙмРэКЭдЫгЊвдЪЕЯжЦѓвЕЕФНЕБОЁЂдіаЇЁЂЬсжЪЁЂДДаТЁЃ

ФГЦѓвЕЪ§ОнжЮРэПДАхЃЈЪ§ОнвбЭбУєЃЉ
Ъ§ОнжЮРэГЩаЇЦРЙРжИБъЬхЯЕгІИљОнЦѓвЕМАЪ§ОнжЮРэЯюФПЕФЪЕМЪЧщПіжЦЖЈЃЌвЛАуАќРЈЃКЪБМфадЁЂЪ§СПадЁЂЭъећадЁЂзМШЗадЫФИіЮЌЖШЁЃ
ЂйЪБМфадМДЪ§ОнЕФМАЪБадЁЃИУЮЌЖШжївЊЭЈЙ§дДвЕЮёЯЕЭГЪ§ОнНгШыЕФЩЯБЈМАЪБадЁЂНгШыМАЪБадЕШЗНУцНјааКЫЖдЁЃЭЈЙ§ЗжЮідТжИБъЁЂжмжИБъЁЂШежИБъЕФЪ§ОнМАЪБТЪЃЌЕУГідкЙцЖЈЪБМфКЭЦЕЖШжмЦкФкНгШыЯЕЭГЕФБШР§ЃЌвдДЫЗДгГЪ§ОнНгШыМАЪБадЁЃ
ЂкЪ§СПадЁЃИУЮЌЖШЪЧДгЪ§ОнДцСПЃЌЪ§ОндіСПЃЌЪ§ОнЗУЮЪСПЃЌЪ§ОнНЛЛЛСПЁЂЪ§ОнЪЙгУСПЕШжИБъЗДгГЪ§ОнЕФЪЙгУЧщПіЃЌПЩвдЗжЮЊдТЖШжИБъЁЂжмжИБъЁЂШежИБъЁЂЪБЗжжИБъЕШЁЃ
ЂлзМШЗадЁЃетИіЮЌЖШжївЊгЩИїРрЪ§ОнжаТпМЕФзМШЗадЁЂЪ§ОнжЕЕФзМШЗадЁЂЪ§ОнЦЕЖЮКЭзжЖЮжЎМфЕФзМШЗадвдМАЪ§ОнЕФОЋЖШЕШФкШнзщГЩЁЃИУзМШЗТЪЭЌбљАќРЈЃКдТЖШЁЂУПжмЁЂУПШеЕШзМШЗТЪжИБъЁЃ
ЂмЭъећадЁЃДЫЮЌЖШжївЊвдЕЅдЊЮЌЖШЭъећадЁЂЪ§ОнвЕЮёЮЌЖШзщКЯЭъећадЁЂЫїв§жЕЭъећадЕШВЛЭЌЗНУцНјааКЫЖдЃЌЪЧбщжЄЪ§ОнжЪСПЭъећадЕФжївЊзщГЩВПЗжЃЌАќРЈдТЖШжИБъЁЂжмжИБъЁЂШежИБъЪ§ОнЕФЭъећадЕШФкШнЁЃ
ФПБъЃКМьбщИїЯюЪ§ОнжЮРэжИБъЕФТфЪЕЧщПіЃЌВщТЉВЙШБЃЌКЛЪЕЪ§ОнжЮРэаЇЙћЃЛ
ММЪѕЙЄОпЃКЪ§ОнжЮРэаЇЙћЕФЦРМлжИБъЬхЯЕЁЂИїжжЪ§ОнЭМБэЙЄОпЃЛ
ЪфШыЃКЪ§ОнжЮРэаЇЙћЦРЙРжИБъЃЛ
ЪфГіЃКЪ§ОнжЮРэЦРЙРЕФдТБЈЁЂжмБЈЁЂШеБЈЕШЃЛ
10ЁЂЪ§ОнжЮРэГжајИФНј
Ъ§ОнжЮРэФЃЪНгІвЕЮёЛЏЁЂГЃЬЌЛЏЃЌВЛгІЪЧвЛИіЯюФПЁЂЁАвЛеѓЗчЁБЕФФЃЪНЁЃ

Ъ§ОнжЮРэЙЄзїгІЯђЦѓвЕЩњВњЁЂЯњЪлвЕЮёвЛбљзїЮЊвЛЯюжиЕуЕФвЕЮёЙЄзїРДПЊеЙЃЌЙЙНЈзЈвЕЕФЪ§ОнжЮРэзщжЏЃЌЩшжУКЯЪЪЕФИкЮЛШЈд№ЃЌНЈСЂЯргІЕФЙмРэСїГЬКЭжЦЖШЃЌШУЪ§ОнБъзМЙсГЙЕНУПИівЕЮёЛЗНкЃЌаЮГЩвЛжжГЃЬЌЕФЙЄзїЁЃ
дкБЪепПДРДЃЌдкЪ§ОндДЭЗМгЧПЦѓвЕЪ§ОнЕФжЮРэЃЌШУГЃЬЌЛЏжЮРэГЩЮЊШеГЃвЕЮёЃЌВХФмДгИљБОЩЯГЙЕзНтОіЦѓвЕЪ§ОнжЪСПЕФИїжжЮЪЬтЃЌШУЪ§Онеце§зЊЛЏЮЊЦѓвЕзЪВњЃЌвдЪЕЯжЪ§ОнЧ§ЖЏСїГЬгХЛЏЁЂЪ§ОнЧ§ЖЏвЕЮёДДаТЁЂЪ§ОнЧ§ЖЏЙмРэОіВпЕФФПБъЁЃ
|








