| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЪВУДЪЧЪ§ОнКўЁЂЪ§ОнКўЕФЛљБОЬиеїЁЂЪ§ОнКўЛљБОМмЙЙЁЂИїГЇЩЬЕФЪ§ОнКўНтОіЗНАИЁЂЕфаЭЕФЪ§ОнКўгІгУГЁОАМАЪ§ОнКўНЈЩшЕФЛљБОЙ§ГЬЁЃ
БОЮФРДздгкЮЂаХЙЋжкКХМмЙЙЪІММЪѕСЊУЫЃЌгЩLindaБрМЁЂЭЦМіЁЃ |
|
БОЮФАќРЈЦпИіаЁНкЃК1ЁЂЪВУДЪЧЪ§ОнКўЃЛ2ЁЂЪ§ОнКўЕФЛљБОЬиеїЃЛ3ЁЂЪ§ОнКўЛљБОМмЙЙЃЛ4ЁЂИїГЇЩЬЕФЪ§ОнКўНтОіЗНАИЃЛ5ЁЂЕфаЭЕФЪ§ОнКўгІгУГЁОАЃЛ6ЁЂЪ§ОнКўНЈЩшЕФЛљБОЙ§ГЬЃЛ7ЁЂзмНсЁЃЪмЯогкИіШЫЫЎЦНЃЌУ§ЮѓдкЫљФбУтЃЌЛЖгЭЌбЇУЧвЛЦ№ЬНЬжЃЌХњЦРжИе§ЃЌВЛСпДЭНЬЁЃ
вЛЁЂЪВУДЪЧЪ§ОнКў
Ъ§ОнКўЪЧФПЧАБШНЯШШЕФвЛИіИХФюЃЌаэЖрЦѓвЕЖМдкЙЙНЈЛђепМЦЛЎЙЙНЈздМКЕФЪ§ОнКўЁЃЕЋЪЧдкМЦЛЎЙЙНЈЪ§ОнКўжЎЧАЃЌИуЧхГўЪВУДЪЧЪ§ОнКўЃЌУїШЗвЛИіЪ§ОнКўЯюФПЕФЛљБОзщГЩЃЌНјЖјЩшМЦЪ§ОнКўЕФЛљБОМмЙЙЃЌЖдгкЪ§ОнКўЕФЙЙНЈжСЙиживЊЁЃЙигкЪВУДЪЧЪ§ОнКўЃПгаВЛЭЌЕФЖЈвхЁЃ
WikipediaЩЯЫЕЪ§ОнКўЪЧвЛРрДцДЂЪ§ОнздШЛ/дЪМИёЪНЕФЯЕЭГЛђДцДЂЃЌЭЈГЃЪЧЖдЯѓПщЛђепЮФМўЃЌАќРЈдЪМЯЕЭГЫљВњЩњЕФдЪМЪ§ОнПНБДвдМАЮЊСЫИїРрШЮЮёЖјВњЩњЕФзЊЛЛЪ§ОнЃЌАќРЈРДздгкЙиЯЕаЭЪ§ОнПтжаЕФНсЙЙЛЏЪ§ОнЃЈааКЭСаЃЉЁЂАыНсЙЙЛЏЪ§ОнЃЈШчCSVЁЂШежОЁЂXMLЁЂJSONЃЉЁЂЗЧНсЙЙЛЏЪ§ОнЃЈШчemailЁЂЮФЕЕЁЂPDFЕШЃЉКЭЖўНјжЦЪ§ОнЃЈШчЭМЯёЁЂвєЦЕЁЂЪгЦЕЃЉЁЃ
AWSЖЈвхЪ§ОнКўЪЧвЛИіМЏжаЪНДцДЂПтЃЌдЪаэФњвдШЮвтЙцФЃДцДЂЫљгаНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃ
ЮЂШэЕФЖЈвхОЭИќМгФЃК§СЫЃЌВЂУЛгаУїШЗИјГіЪВУДЪЧData LakeЃЌЖјЪЧШЁЧЩЕФНЋЪ§ОнКўЕФЙІФмзїЮЊЖЈвхЃЌЪ§ОнКўАќРЈвЛЧаЪЙЕУПЊЗЂепЁЂЪ§ОнПЦбЇМвЁЂЗжЮіЪІФмИќМђЕЅЕФДцДЂЁЂДІРэЪ§ОнЕФФмСІЃЌетаЉФмСІЪЙЕУгУЛЇПЩвдДцДЂШЮвтЙцФЃЁЂШЮвтРраЭЁЂШЮвтВњЩњЫйЖШЕФЪ§ОнЃЌВЂЧвПЩвдПчЦНЬЈЁЂПчгябдЕФзіЫљгаРраЭЕФЗжЮіКЭДІРэЁЃ
ЙигкЪ§ОнКўЕФЖЈвхЦфЪЕКмЖрЃЌЕЋЪЧЛљБОЩЯЖМЮЇШЦзХвдЯТМИИіЬиадеЙПЊЁЃ
1ЁЂ Ъ§ОнКўашвЊЬсЙЉзуЙЛгУЕФЪ§ОнДцДЂФмСІЃЌетИіДцДЂБЃДцСЫвЛИіЦѓвЕ/зщжЏжаЕФЫљгаЪ§ОнЁЃ
2ЁЂ Ъ§ОнКўПЩвдДцДЂКЃСПЕФШЮвтРраЭЕФЪ§ОнЃЌАќРЈНсЙЙЛЏЁЂАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃ
3ЁЂ Ъ§ОнКўжаЕФЪ§ОнЪЧдЪМЪ§ОнЃЌЪЧвЕЮёЪ§ОнЕФЭъећИББОЁЃЪ§ОнКўжаЕФЪ§ОнБЃГжСЫЫћУЧдквЕЮёЯЕЭГжадРДЕФбљзгЁЃ
4ЁЂ Ъ§ОнКўашвЊОпБИЭъЩЦЕФЪ§ОнЙмРэФмСІЃЈЭъЩЦЕФдЊЪ§ОнЃЉЃЌПЩвдЙмРэИїРрЪ§ОнЯрЙиЕФвЊЫиЃЌАќРЈЪ§ОндДЁЂЪ§ОнИёЪНЁЂСЌНгаХЯЂЁЂЪ§ОнschemaЁЂШЈЯоЙмРэЕШЁЃ
5ЁЂ Ъ§ОнКўашвЊОпБИЖрбљЛЏЕФЗжЮіФмСІЃЌАќРЈЕЋВЛЯогкХњДІРэЁЂСїЪНМЦЫуЁЂНЛЛЅЪНЗжЮівдМАЛњЦїбЇЯАЃЛЭЌЪБЃЌЛЙашвЊЬсЙЉвЛЖЈЕФШЮЮёЕїЖШКЭЙмРэФмСІЁЃ
6ЁЂ Ъ§ОнКўашвЊОпБИЭъЩЦЕФЪ§ОнЩњУќжмЦкЙмРэФмСІЁЃВЛЙташвЊДцДЂдЪМЪ§ОнЃЌЛЙашвЊФмЙЛБЃДцИїРрЗжЮіДІРэЕФжаМфНсЙћЃЌВЂЭъећЕФМЧТМЪ§ОнЕФЗжЮіДІРэЙ§ГЬЃЌФмАяжњгУЛЇЭъећЯъЯИзЗЫнШЮвтвЛЬѕЪ§ОнЕФВњЩњЙ§ГЬЁЃ
7ЁЂ Ъ§ОнКўашвЊОпБИЭъЩЦЕФЪ§ОнЛёШЁКЭЪ§ОнЗЂВМФмСІЁЃЪ§ОнКўашвЊФмжЇГХИїжжИїбљЕФЪ§ОндДЃЌВЂФмДгЯрЙиЕФЪ§ОндДжаЛёШЁШЋСП/діСПЪ§ОнЃЛШЛКѓЙцЗЖДцДЂЁЃЪ§ОнКўФмНЋЪ§ОнЗжЮіДІРэЕФНсЙћЭЦЫЭЕНКЯЪЪЕФДцДЂв§ЧцжаЃЌТњзуВЛЭЌЕФгІгУЗУЮЪашЧѓЁЃ
8ЁЂ ЖдгкДѓЪ§ОнЕФжЇГжЃЌАќРЈГЌДѓЙцФЃДцДЂвдМАПЩРЉеЙЕФДѓЙцФЃЪ§ОнДІРэФмСІЁЃ
злЩЯЃЌИіШЫШЯЮЊЪ§ОнКўгІИУЪЧвЛжжВЛЖЯбнНјжаЁЂПЩРЉеЙЕФДѓЪ§ОнДцДЂЁЂДІРэЁЂЗжЮіЕФЛљДЁЩшЪЉЃЛвдЪ§ОнЮЊЕМЯђЃЌЪЕЯжШЮвтРДдДЁЂШЮвтЫйЖШЁЂШЮвтЙцФЃЁЂШЮвтРраЭЪ§ОнЕФШЋСПЛёШЁЁЂШЋСПДцДЂЁЂЖрФЃЪНДІРэгыШЋЩњУќжмЦкЙмРэЃЛВЂЭЈЙ§гыИїРрЭтВПвьЙЙЪ§ОндДЕФНЛЛЅМЏГЩЃЌжЇГжИїРрЦѓвЕМЖгІгУЁЃ

ЭМ1. Ъ§ОнКўЛљБОФмСІЪОвт
етРяашвЊдйЬиБ№жИГіСНЕуЃК
1ЃЉПЩРЉеЙЪЧжИЙцФЃЕФПЩРЉеЙКЭФмСІЕФПЩРЉеЙЃЌМДЪ§ОнКўВЛЕЋвЊФмЙЛЫцзХЪ§ОнСПЕФдіДѓЃЌЬсЙЉЁАзуЙЛЁБЕФДцДЂКЭМЦЫуФмСІЃЛЛЙашвЊИљОнашвЊВЛЖЯЬсЙЉаТЕФЪ§ОнДІРэФЃЪНЃЌР§ШчПЩФмвЛПЊЪМвЕЮёжЛашвЊХњДІРэФмСІЃЌЕЋЫцзХвЕЮёЕФЗЂеЙЃЌПЩФмашвЊНЛЛЅЪНЕФМДЯЏЗжЮіФмСІЃЛгжЫцзХвЕЮёЕФЪЕаЇадвЊЧѓВЛЖЯЬсЩ§ЃЌПЩФмашвЊжЇГжЪЕЪБЗжЮіКЭЛњЦїбЇЯАЕШЗсИЛЕФФмСІЁЃ
2ЃЉвдЪ§ОнЮЊЕМЯђЃЌЪЧжИЪ§ОнКўЖдгкгУЛЇРДЫЕвЊзуЙЛЕФМђЕЅЁЂвзгУЃЌАяжњгУЛЇДгИДдгЕФITЛљДЁЩшЪЉдЫЮЌЙЄзїжаНтЭбГіРДЃЌЙизЂвЕЮёЁЂЙизЂФЃаЭЁЂЙизЂЫуЗЈЁЂЙизЂЪ§ОнЁЃЪ§ОнКўУцЯђЕФЪЧЪ§ОнПЦбЇМвЁЂЗжЮіЪІЁЃФПЧАРДПДЃЌдЦдЩњгІИУЪЧЙЙНЈЪ§ОнКўЕФвЛжжБШНЯРэЯыЕФЙЙНЈЗНЪНЃЌКѓУцдкЁАЪ§ОнКўЛљБОМмЙЙЁБвЛНкЛсЯъЯИТлЪіетвЛЙлЕуЁЃ
ЖўЁЂЪ§ОнКўЕФЛљБОЬиеї
ЖдЪ§ОнКўЕФИХФюгаСЫЛљБОЕФШЯжЊжЎКѓЃЌЮвУЧашвЊНјвЛВНУїШЗЪ§ОнКўашвЊОпБИФФаЉЛљБОЬиеїЃЌЬиБ№ЪЧгыДѓЪ§ОнЦНЬЈЛђепДЋЭГЪ§ОнВжПтЯрБШЃЌЪ§ОнКўОпгаФФаЉЬиЕуЁЃдкОпЬхЗжЮіжЎЧАЃЌЮвУЧЯШПДвЛеХРДздAWSЙйЭјЕФЖдБШБэИёЃЈБэИёв§здЃКhttps://aws.amazon.com/cn/big-data/datalakes-and-analytics/what-is-a-data-lake/ЃЉ

ЩЯБэЖдБШСЫЪ§ОнКўгыДЋЭГЪ§ВжЕФЧјБ№ЃЌИіШЫОѕЕУПЩвдДгЪ§ОнКЭМЦЫуСНИіВуУцНјвЛВНЗжЮіЪ§ОнКўгІИУОпБИФФаЉЬиеїЁЃдкЪ§ОнЗНУцЃК
1ЃЉЁАБЃецадЁБЁЃЪ§ОнКўжаЖдгквЕЮёЯЕЭГжаЕФЪ§ОнЖМЛсДцДЂвЛЗнЁАвЛФЃвЛбљЁБЕФЭъећПНБДЁЃгыЪ§ОнВжПтВЛЭЌЕФЕиЗНдкгкЃЌЪ§ОнКўжаБиаывЊБЃДцвЛЗндЪМЪ§ОнЃЌЮоТлЪЧЪ§ОнИёЪНЁЂЪ§ОнФЃЪНЁЂЪ§ОнФкШнЖМВЛгІИУБЛаоИФЁЃдкетЗНУцЃЌЪ§ОнКўЧПЕїЕФЪЧЖдгквЕЮёЪ§ОнЁАдждЮЖЁБЕФБЃДцЁЃЭЌЪБЃЌЪ§ОнКўгІИУФмЙЛДцДЂШЮвтРраЭ/ИёЪНЕФЪ§ОнЁЃ
2ЃЉЁАСщЛюадЁБЃКЩЯБэвЛИіЕуЪЧ ЁАаДШыаЭschemaЁБ v.s.ЁАЖСШЁаЭschemaЁБЃЌЦфЪЕБОжЪЩЯРДНВЪЧЪ§ОнschemaЕФЩшМЦЗЂЩњдкФФИіНзЖЮЕФЮЪЬтЁЃЖдгкШЮКЮЪ§ОнгІгУРДЫЕЃЌЦфЪЕschemaЕФЩшМЦЖМЪЧБиВЛПЩЩйЕФЃЌМДЪЙЪЧmongoDBЕШвЛаЉЧПЕїЁАЮоФЃЪНЁБЕФЪ§ОнПтЃЌЦфзюМбЪЕМљРявРШЛНЈвщМЧТМОЁСПВЩгУЯрЭЌ/ЯрЫЦЕФНсЙЙЁЃЁАаДШыаЭschemaЁББГКѓвўКЌЕФТпМЪЧЪ§ОндкаДШыжЎЧАЃЌОЭашвЊИљОнвЕЮёЕФЗУЮЪЗНЪНШЗЖЈЪ§ОнЕФschemaЃЌШЛКѓАДееМШЖЈschemaЃЌЭъГЩЪ§ОнЕМШыЃЌДјРДЕФКУДІЪЧЪ§ОнгывЕЮёЕФСМКУЪЪХфЃЛЕЋЪЧетвВвтЮЖзХЪ§ВжЕФЧАЦкгЕгаГЩБОЛсБШНЯИпЃЌЬиБ№ЪЧЕБвЕЮёФЃЪНВЛЧхЮњЁЂвЕЮёЛЙДІгкЬНЫїНзЖЮЪБЃЌЪ§ВжЕФСщЛюадВЛЙЛЁЃ
Ъ§ОнКўЧПЕїЕФЁАЖСШЁаЭschemaЁБЃЌБГКѓЕФЧБдкТпМдђЪЧШЯЮЊвЕЮёЕФВЛШЗЖЈадЪЧГЃЬЌЃКЮвУЧЮоЗЈдЄЦквЕЮёЕФБфЛЏЃЌФЧУДЮвУЧОЭБЃГжвЛЖЈЕФСщЛюадЃЌНЋЩшМЦШЅбгКѓЃЌШУећИіЛљДЁЩшЪЉОпБИЪЙЪ§ОнЁААДашЁБЬљКЯвЕЮёЕФФмСІЁЃвђДЫЃЌИіШЫШЯЮЊЁАБЃецадЁБКЭЁАСщЛюадЁБЪЧвЛТіЯрГаЕФЃКМШШЛУЛАьЗЈдЄЙРвЕЮёЕФБфЛЏЃЌФЧУДЫїадБЃГжЪ§ОнзюЮЊдЪМЕФзДЬЌЃЌвЛЕЉашвЊЪБЃЌПЩвдИљОнашЧѓЖдЪ§ОнНјааМгЙЄДІРэЁЃвђДЫЃЌЪ§ОнКўИќМгЪЪКЯДДаТаЭЦѓвЕЁЂвЕЮёИпЫйБфЛЏЗЂеЙЕФЦѓвЕЁЃЭЌЪБЃЌЪ§ОнКўЕФгУЛЇвВЯргІЕФвЊЧѓИќИпЃЌЪ§ОнПЦбЇМвЁЂвЕЮёЗжЮіЪІЃЈХфКЯвЛЖЈЕФПЩЪгЛЏЙЄОпЃЉЪЧЪ§ОнКўЕФФПБъПЭЛЇЁЃ
3ЃЉЁАПЩЙмРэЁБЃКЪ§ОнКўгІИУЬсЙЉЭъЩЦЕФЪ§ОнЙмРэФмСІЁЃМШШЛЪ§ОнвЊЧѓЁАБЃецадЁБКЭЁАСщЛюадЁБЃЌФЧУДжСЩйЪ§ОнКўжаЛсДцдкСНРрЪ§ОнЃКдЪМЪ§ОнКЭДІРэКѓЕФЪ§ОнЁЃЪ§ОнКўжаЕФЪ§ОнЛсВЛЖЯЕФЛ§РлЁЂбнЛЏЁЃвђДЫЃЌЖдгкЪ§ОнЙмРэФмСІвВЛсвЊЧѓКмИпЃЌжСЩйгІИУАќКЌвдЯТЪ§ОнЙмРэФмСІЃКЪ§ОндДЁЂЪ§ОнСЌНгЁЂЪ§ОнИёЪНЁЂЪ§ОнschemaЃЈПт/Бэ/Са/ааЃЉЁЃЭЌЪБЃЌЪ§ОнКўЪЧЕЅИіЦѓвЕ/зщжЏжаЭГвЛЕФЪ§ОнДцЗХГЁЫљЃЌвђДЫЃЌЛЙашвЊОпгавЛЖЈЕФШЈЯоЙмРэФмСІЁЃ
4ЃЉЁАПЩзЗЫнЁБЃКЪ§ОнКўЪЧвЛИізщжЏ/ЦѓвЕжаШЋСПЪ§ОнЕФДцДЂГЁЫљЃЌашвЊЖдЪ§ОнЕФШЋЩњУќжмЦкНјааЙмРэЃЌАќРЈЪ§ОнЕФЖЈвхЁЂНгШыЁЂДцДЂЁЂДІРэЁЂЗжЮіЁЂгІгУЕФШЋЙ§ГЬЁЃвЛИіЧПДѓЕФЪ§ОнКўЪЕЯжЃЌашвЊФмзіЕНЖдЦфМфЕФШЮвтвЛЬѕЪ§ОнЕФНгШыЁЂДцДЂЁЂДІРэЁЂЯћЗбЙ§ГЬЪЧПЩзЗЫнЕФЃЌФмЙЛЧхГўЕФжиЯжЪ§ОнЭъећЕФВњЩњЙ§ГЬКЭСїЖЏЙ§ГЬЁЃ
дкМЦЫуЗНУцЃЌИіШЫШЯЮЊЪ§ОнКўЖдгкМЦЫуФмСІвЊЧѓЦфЪЕЗЧГЃЙуЗКЃЌЭъШЋШЁОігквЕЮёЖдгкМЦЫуЕФвЊЧѓЁЃ
5ЃЉЗсИЛЕФМЦЫув§ЧцЁЃДгХњДІРэЁЂСїЪНМЦЫуЁЂНЛЛЅЪНЗжЮіЕНЛњЦїбЇЯАЃЌИїРрМЦЫув§ЧцЖМЪєгкЪ§ОнКўгІИУФвРЈЕФЗЖГыЁЃвЛАуЧщПіЯТЃЌЪ§ОнЕФМгдиЁЂзЊЛЛЁЂДІРэЛсЪЙгУХњДІРэМЦЫув§ЧцЃЛашвЊЪЕЪБМЦЫуЕФВПЗжЃЌЛсЪЙгУСїЪНМЦЫув§ЧцЃЛЖдгквЛаЉЬНЫїЪНЕФЗжЮіГЁОАЃЌПЩФмгжашвЊв§ШыНЛЛЅЪНЗжЮів§ЧцЁЃЫцзХДѓЪ§ОнММЪѕгыШЫЙЄжЧФмММЪѕЕФНсКЯдНРДдННєУмЃЌИїРрЛњЦїбЇЯА/ЩюЖШбЇЯАЫуЗЈвВБЛВЛЖЯв§ШыЃЌР§ШчTensorFlow/PyTorchПђМмвбОжЇГжДгHDFS/S3/OSSЩЯЖСШЁбљБОЪ§ОнНјаабЕСЗЁЃвђДЫЃЌЖдгквЛИіКЯИёЕФЪ§ОнКўЯюФПЖјбдЃЌМЦЫув§ЧцЕФПЩРЉеЙ/ПЩВхАЮЃЌгІИУЪЧвЛРрЛљДЁФмСІЁЃ
6ЃЉЖрФЃЬЌЕФДцДЂв§ЧцЁЃРэТлЩЯЃЌЪ§ОнКўБОЩэгІИУФкжУЖрФЃЬЌЕФДцДЂв§ЧцЃЌвдТњзуВЛЭЌЕФгІгУЖдгкЪ§ОнЗУЮЪашЧѓЃЈзлКЯПМТЧЯьгІЪБМф/ВЂЗЂ/ЗУЮЪЦЕДЮ/ГЩБОЕШвђЫиЃЉЁЃЕЋЪЧЃЌдкЪЕМЪЕФЪЙгУЙ§ГЬжаЃЌЪ§ОнКўжаЕФЪ§ОнЭЈГЃВЂВЛЛсБЛИпЦЕДЮЕФЗУЮЪЃЌЖјЧвЯрЙиЕФгІгУвВЖрдкНјааЬНЫїЪНЕФЪ§ОнгІгУЃЌЮЊСЫДяЕНПЩНгЪмЕФадМлБШЃЌЪ§ОнКўНЈЩшЭЈГЃЛсбЁдёЯрЖдБувЫЕФДцДЂв§ЧцЃЈШчS3/OSS/HDFS/OBSЃЉЃЌВЂЧвдкашвЊЪБгыЭтжУДцДЂв§ЧцаЭЌЙЄзїЃЌТњзуЖрбљЛЏЕФгІгУашЧѓЁЃ
Ш§ЁЂЪ§ОнКўЛљБОМмЙЙ
Ъ§ОнКўПЩвдШЯЮЊЪЧаТвЛДњЕФДѓЪ§ОнЛљДЁЩшЪЉЁЃЮЊСЫИќКУЕФРэНтЪ§ОнКўЕФЛљБОМмЙЙЃЌЮвУЧЯШРДПДПДДѓЪ§ОнЛљДЁЩшЪЉМмЙЙЕФбнНјЙ§ГЬЁЃ
1ЃЉ ЕквЛНзЖЮЃКвдHadoopЮЊДњБэЕФРыЯпЪ§ОнДІРэЛљДЁЩшЪЉЁЃШчЯТЭМЫљЪОЃЌHadoopЪЧвдHDFSЮЊКЫаФДцДЂЃЌвдMapReduceЃЈМђГЦMRЃЉЮЊЛљБОМЦЫуФЃаЭЕФХњСПЪ§ОнДІРэЛљДЁЩшЪЉЁЃЮЇШЦHDFSКЭMRЃЌВњЩњСЫвЛЯЕСаЕФзщМўЃЌВЛЖЯЭъЩЦећИіДѓЪ§ОнЦНЬЈЕФЪ§ОнДІРэФмСІЃЌР§ШчУцЯђдкЯпKVВйзїЕФHBaseЁЂУцЯђSQLЕФHIVEЁЂУцЯђЙЄзїСїЕФPIGЕШЁЃЭЌЪБЃЌЫцзХДѓМвЖдгкХњДІРэЕФадФмвЊЧѓдНРДдНИпЃЌаТЕФМЦЫуФЃаЭВЛЖЯБЛЬсГіЃЌВњЩњСЫTezЁЂSparkЁЂPrestoЕШМЦЫув§ЧцЃЌMRФЃаЭвВж№НЅНјЛЏГЩDAGФЃаЭЁЃDAGФЃаЭвЛЗНУцЃЌдіМгМЦЫуФЃаЭЕФГщЯѓВЂЗЂФмСІЃКЖдУПвЛИіМЦЫуЙ§ГЬНјааЗжНтЃЌИљОнМЦЫуЙ§ГЬжаЕФОлКЯВйзїЕуЖдШЮЮёНјааТпМЧаЗжЃЌШЮЮёБЛЧаЗжГЩвЛИіИіЕФstageЃЌУПИіstageЖМПЩвдгавЛИіЛђепЖрИіTaskзщГЩЃЌTaskЪЧПЩвдВЂЗЂжДааЕФЃЌДгЖјЬсЩ§ећИіМЦЫуЙ§ГЬЕФВЂааФмСІЃЛСэвЛЗНУцЃЌЮЊМѕЩйЪ§ОнДІРэЙ§ГЬжаЕФжаМфНсЙћаДЮФМўВйзїЃЌSparkЁЂPrestoЕШМЦЫув§ЧцОЁСПЪЙгУМЦЫуНкЕуЕФФкДцЖдЪ§ОнНјааЛКДцЃЌДгЖјЬсИпећИіЪ§ОнЙ§ГЬЕФаЇТЪКЭЯЕЭГЭЬЭТФмСІЁЃ

ЭМ2. HadoopЬхЯЕНсЙЙЪОвт
2ЃЉ ЕкЖўНзЖЮЃКlambdaМмЙЙЁЃЫцзХЪ§ОнДІРэФмСІКЭДІРэашЧѓЕФВЛЖЯБфЛЏЃЌдНРДдНЖрЕФгУЛЇЗЂЯжЃЌХњДІРэФЃЪНЮоТлШчКЮЬсЩ§адФмЃЌвВЮоЗЈТњзувЛаЉЪЕЪБадвЊЧѓИпЕФДІРэГЁОАЃЌСїЪНМЦЫув§ЧцгІдЫЖјЩњЃЌР§ШчStormЁЂSpark
StreamingЁЂFlinkЕШЁЃШЛЖјЃЌЫцзХдНРДдНЖрЕФгІгУЩЯЯпЃЌДѓМвЗЂЯжЃЌЦфЪЕХњДІРэКЭСїМЦЫуХфКЯЪЙгУЃЌВХФмТњзуДѓВПЗжгІгУашЧѓЃЛЖјЖдгкгУЛЇЖјбдЃЌЦфЪЕЫћУЧВЂВЛЙиаФЕзВуЕФМЦЫуФЃаЭЪЧЪВУДЃЌгУЛЇЯЃЭћЮоТлЪЧХњДІРэЛЙЪЧСїМЦЫуЃЌЖМФмЛљгкЭГвЛЕФЪ§ОнФЃаЭРДЗЕЛиДІРэНсЙћЃЌгкЪЧLambdaМмЙЙБЛЬсГіЃЌШчЯТЭМЫљЪОЁЃЃЈЮЊСЫЪЁЪТЃЌlambdaМмЙЙКЭKappaМмЙЙЭМОљРДздгкЭјТчЃЉ

ЭМ3. LambdaМмЙЙЪОвт
LambdaМмЙЙЕФКЫаФРэФюЪЧЁАСїХњвЛЬхЁБЃЌШчЩЯЭМЫљЪОЃЌећИіЪ§ОнСїЯђздзѓЯђгвСїШыЦНЬЈЁЃНјШыЦНЬЈКѓвЛЗжЮЊЖўЃЌвЛВПЗжзпХњДІРэФЃЪНЃЌвЛВПЗжзпСїЪНМЦЫуФЃЪНЁЃЮоТлФФжжМЦЫуФЃЪНЃЌзюжеЕФДІРэНсЙћЖМЭЈЙ§ЗўЮёВуЖдгІгУЬсЙЉЃЌШЗБЃЗУЮЪЕФвЛжТадЁЃ
3ЃЉ ЕкШ§НзЖЮЃКKappaМмЙЙЁЃLambdaМмЙЙНтОіСЫгІгУЖСШЁЪ§ОнЕФвЛжТадЮЪЬтЃЌЕЋЪЧЁАСїХњЗжРыЁБЕФДІРэСДТЗдіДѓСЫбаЗЂЕФИДдгадЁЃвђДЫЃЌгаШЫОЭЬсГіФмВЛФмгУвЛЬзЯЕЭГРДНтОіЫљгаЮЪЬтЁЃФПЧАБШНЯСїааЕФзіЗЈОЭЪЧЛљгкСїМЦЫуРДзіЁЃСїМЦЫуЬьШЛЕФЗжВМЪНЬиеїЃЌзЂЖЈСЫЫћЕФРЉеЙадИќКУЁЃЭЈЙ§МгДѓСїМЦЫуЕФВЂЗЂадЃЌМгДѓСїЪНЪ§ОнЕФЁАЪБМфДАПкЁБЃЌРДЭГвЛХњДІРэгыСїЪНДІРэСНжжМЦЫуФЃЪНЁЃ

ЭМ4. KappaМмЙЙЪОвт
злЩЯЃЌДгДЋЭГЕФhadoopМмЙЙЭљlambdaМмЙЙЃЌДгlambdaМмЙЙЭљKappaМмЙЙЕФбнНјЃЌДѓЪ§ОнЦНЬЈЛљДЁМмЙЙЕФбнНјж№НЅФвРЈСЫгІгУЫљашЕФИїРрЪ§ОнДІРэФмСІЃЌДѓЪ§ОнЦНЬЈж№НЅбнЛЏГЩСЫвЛИіЦѓвЕ/зщжЏЕФШЋСПЪ§ОнДІРэЦНЬЈЁЃЕБЧАЕФЦѓвЕЪЕМљжаЃЌГ§СЫЙиЯЕаЭЪ§ОнПтвРЭагкИїИіЖРСЂЕФвЕЮёЯЕЭГЃЛЦфгрЕФЪ§ОнЃЌМИКѕЖМБЛПМТЧФЩШыДѓЪ§ОнЦНЬЈРДНјааЭГвЛЕФДІРэЁЃШЛЖјЃЌФПЧАЕФДѓЪ§ОнЦНЬЈЛљДЁМмЙЙЃЌЖМНЋЪгНЧЫјЖЈдкСЫДцДЂКЭМЦЫуЃЌЖјКіТдСЫЖдгкЪ§ОнЕФзЪВњЛЏЙмРэЃЌетЧЁЧЁЪЧЪ§ОнКўзїЮЊаТвЛДњЕФДѓЪ§ОнЛљДЁЩшЪЉЫљжиЕуЙизЂЕФЗНЯђжЎвЛЁЃ
ДѓЪ§ОнЛљДЁМмЙЙЕФбнНјЃЌЦфЪЕЗДгІСЫвЛЕуЃКдкЦѓвЕ/зщжЏФкВПЃЌЪ§ОнЪЧвЛРрживЊзЪВњвбОГЩЮЊСЫЙВЪЖЃЛЮЊСЫИќКУЕФРћгУЪ§ОнЃЌЦѓвЕ/зщжЏашвЊЖдЪ§ОнзЪВњ
1ЃЉНјааГЄЦкЕФдбљДцДЂЃЛ2ЃЉНјаагааЇЙмРэгыМЏжажЮРэЃЛ3ЃЉЬсЙЉЖрФЃЪНЕФМЦЫуФмСІТњзуДІРэашЧѓЃЛ4ЃЉвдМАУцЯђвЕЮёЃЌЬсЙЉЭГвЛЕФЪ§ОнЪгЭМЁЂЪ§ОнФЃаЭгыЪ§ОнДІРэНсЙћЁЃЪ§ОнКўОЭЪЧдкетИіДѓБГОАЯТВњЩњЕФЃЌГ§СЫДѓЪ§ОнЦНЬЈЫљгЕгаЕФИїРрЛљДЁФмСІжЎЭтЃЌЪ§ОнКўИќЧПЕїЖдгкЪ§ОнЕФЙмРэЁЂжЮРэКЭзЪВњЛЏФмСІЁЃТфЕНОпЬхЕФЪЕЯжЩЯЃЌЪ§ОнКўашвЊАќРЈвЛЯЕСаЕФЪ§ОнЙмРэзщМўЃЌАќРЈЃК1ЃЉЪ§ОнНгШыЃЛ2ЃЉЪ§ОнАсЧЈЃЛ3ЃЉЪ§ОнжЮРэЃЛ4ЃЉжЪСПЙмРэЃЛ5ЃЉзЪВњФПТМЃЛ6ЃЉЗУЮЪПижЦЃЛ7ЃЉШЮЮёЙмРэЃЛ8ЃЉШЮЮёБрХХЃЛ9ЃЉдЊЪ§ОнЙмРэЕШЁЃШчЯТЭМЫљЪОЃЌИјГіСЫвЛИіЪ§ОнКўЯЕЭГЕФВЮПММмЙЙЁЃЖдгквЛИіЕфаЭЕФЪ§ОнКўЖјбдЃЌЫќгыДѓЪ§ОнЦНЬЈЯрЭЌЕФЕиЗНдкгкЫќвВОпБИДІРэГЌДѓЙцФЃЪ§ОнЫљашЕФДцДЂКЭМЦЫуФмСІЃЌФмЬсЙЉЖрФЃЪНЕФЪ§ОнДІРэФмСІЃЛдіЧПЕудкгкЪ§ОнКўЬсЙЉСЫИќЮЊЭъЩЦЕФЪ§ОнЙмРэФмСІЃЌОпЬхЬхЯждкЃК
1ЃЉ ИќЧПДѓЕФЪ§ОнНгШыФмСІЁЃЪ§ОнНгШыФмСІЬхЯждкЖдгкИїРрЭтВПвьЙЙЪ§ОндДЕФЖЈвхЙмРэФмСІЃЌвдМАЖдгкЭтВПЪ§ОндДЯрЙиЪ§ОнЕФГщШЁЧЈвЦФмСІЃЌГщШЁЧЈвЦЕФЪ§ОнАќРЈЭтВПЪ§ОндДЕФдЊЪ§ОнгыЪЕМЪДцДЂЕФЪ§ОнЁЃ
2ЃЉ ИќЧПДѓЕФЪ§ОнЙмРэФмСІЁЃЙмРэФмСІОпЬхгжПЩЗжЮЊЛљБОЙмРэФмСІКЭРЉеЙЙмРэФмСІЁЃЛљБОЙмРэФмСІАќРЈЖдИїРрдЊЪ§ОнЕФЙмРэЁЂЪ§ОнЗУЮЪПижЦЁЂЪ§ОнзЪВњЙмРэЃЌЪЧвЛИіЪ§ОнКўЯЕЭГЫљБиаыЕФЃЌКѓУцЮвУЧЛсдкЁАИїГЇЩЬЕФЪ§ОнКўНтОіЗНАИЁБвЛНкЯраХЬжТлИїИіГЇЩЬЖдгкЛљБОЙмРэФмСІЕФжЇГжЗНЪНЁЃРЉеЙЙмРэФмСІАќРЈШЮЮёЙмРэЁЂСїГЬБрХХвдМАгыЪ§ОнжЪСПЁЂЪ§ОнжЮРэЯрЙиЕФФмСІЁЃШЮЮёЙмРэКЭСїГЬБрХХжївЊгУРДЙмРэЁЂБрХХЁЂЕїЖШЁЂМрВтдкЪ§ОнКўЯЕЭГжаДІРэЪ§ОнЕФИїРрШЮЮёЃЌЭЈГЃЧщПіЯТЃЌЪ§ОнКўЙЙНЈепЛсЭЈЙ§ЙКТђ/бажЦЖЈжЦЕФЪ§ОнМЏГЩЛђЪ§ОнПЊЗЂзгЯЕЭГ/ФЃПщРДЬсЙЉДЫРрФмСІЃЌЖЈжЦЕФЯЕЭГ/ФЃПщПЩвдЭЈЙ§ЖСШЁЪ§ОнКўЕФЯрЙидЊЪ§ОнЃЌРДЪЕЯжгыЪ§ОнКўЯЕЭГЕФШкКЯЁЃЖјЪ§ОнжЪСПКЭЪ§ОнжЮРэдђЪЧИќЮЊИДдгЕФЮЪЬтЃЌвЛАуЧщПіЯТЃЌЪ§ОнКўЯЕЭГВЛЛсжБНгЬсЙЉЯрЙиЙІФмЃЌЕЋЪЧЛсПЊЗХИїРрНгПкЛђепдЊЪ§ОнЃЌЙЉгаФмСІЕФЦѓвЕ/зщжЏгывбгаЕФЪ§ОнжЮРэШэМўМЏГЩЛђепзіЖЈжЦПЊЗЂЁЃ
3ЃЉ ПЩЙВЯэЕФдЊЪ§ОнЁЃЪ§ОнКўжаЕФИїРрМЦЫув§ЧцЛсгыЪ§ОнКўжаЕФЪ§ОнЩюЖШШкКЯЃЌЖјШкКЯЕФЛљДЁОЭЪЧЪ§ОнКўЕФдЊЪ§ОнЁЃКУЕФЪ§ОнКўЯЕЭГЃЌМЦЫув§ЧцдкДІРэЪ§ОнЪБЃЌФмДгдЊЪ§ОнжажБНгЛёШЁЪ§ОнДцДЂЮЛжУЁЂЪ§ОнИёЪНЁЂЪ§ОнФЃЪНЁЂЪ§ОнЗжВМЕШаХЯЂЃЌШЛКѓжБНгНјааЪ§ОнДІРэЃЌЖјЮоашНјааШЫЙЄ/БрГЬИЩдЄЁЃИќНјвЛВНЃЌКУЕФЪ§ОнКўЯЕЭГЛЙПЩвдЖдЪ§ОнКўжаЕФЪ§ОнНјааЗУЮЪПижЦЃЌПижЦЕФСІЖШПЩвдзіЕНЁАПтБэСаааЁБЕШВЛЭЌМЖБ№ЁЃ

ЭМ5. Ъ§ОнКўзщМўВЮПММмЙЙ
ЛЙгавЛЕугІИУжИГіЕФЪЧЃЌЩЯЭМЕФЁАМЏжаЪНДцДЂЁБИќЖрЕФЪЧвЕЮёИХФюЩЯЕФМЏжаЃЌБОжЪЩЯЪЧЯЃЭћвЛИіЦѓвЕ/зщжЏФкВПЕФЪ§ОнФмдквЛИіУїШЗЭГвЛЕФЕиЗННјааГСЕэЁЃЪТЪЕЩЯЃЌЪ§ОнКўЕФДцДЂгІИУЪЧвЛРрПЩАДашРЉеЙЕФЗжВМЪНЮФМўЯЕЭГЃЌДѓЖрЪ§Ъ§ОнКўЪЕМљжавВЪЧЭЦМіВЩгУS3/OSS/OBS/HDFSЕШЗжВМЪНЯЕЭГзїЮЊЪ§ОнКўЕФЭГвЛДцДЂЁЃ
ЮвУЧПЩвддйЧаЛЛЕНЪ§ОнЮЌЖШЃЌДгЪ§ОнЩњУќжмЦкЕФЪгНЧРДПДД§Ъ§ОнКўЖдгкЪ§ОнЕФДІРэЗНЪНЃЌЪ§ОндкЪ§ОнКўжаЕФећИіЩњУќжмЦкШчЭМ6ЫљЪОЁЃРэТлЩЯЃЌвЛИіЙмРэЭъЩЦЕФЪ§ОнКўжаЕФЪ§ОнЛсгРОУЕФБЃСєдЪМЪ§ОнЃЌЭЌЪБЙ§ГЬЪ§ОнЛсВЛЖЯЕФЭъЩЦЁЂбнЛЏЃЌвдТњзувЕЮёЕФашвЊЁЃ

ЭМ6. Ъ§ОнКўжаЕФЪ§ОнЩњУќжмЦкЪОвт
ЫФЁЂИїГЇЩЬЕФЪ§ОнКўНтОіЗНАИ
Ъ§ОнКўзїЮЊЕБЧАЕФвЛИіЗчПкЃЌИїДѓдЦГЇЩЬЗзЗзЭЦГіздМКЕФЪ§ОнКўНтОіЗНАИМАЯрЙиВњЦЗЁЃБОНкНЋЗжЮіИїИіжїСїГЇЩЬЭЦГіЕФЪ§ОнКўНтОіЗНАИЃЌВЂНЋЦфгГЩфЕНЪ§ОнКўВЮПММмЙЙЩЯЃЌАяжњДѓМвРэНтИїРрЗНАИЕФгХШБЕуЁЃ

ЭМ7. AWSЪ§ОнКўНтОіЗНАИ
ЭМ7ЪЧAWSЭЦМіЕФЪ§ОнКўНтОіЗНАИЁЃећИіЗНАИЛљгкAWS Lake FormationЙЙНЈЃЌAWS Lake
FormationБОжЪЩЯЪЧвЛИіЙмРэаджЪЕФзщМўЃЌЫќгыЦфЫћAWSЗўЮёЛЅЯрХфКЯЃЌРДЭъГЩећИіЦѓвЕМЖЪ§ОнКўЙЙНЈЙІФмЁЃЩЯЭМздзѓЯђгвЃЌЬхЯжСЫЪ§ОнСїШыЁЂЪ§ОнГСЕэЁЂЪ§ОнМЦЫуЁЂЪ§ОнгІгУЫФИіВНжшЁЃЮвУЧНјвЛВНРДПДЦфЙиМќЕуЃК
1ЃЉ Ъ§ОнСїШыЁЃ
Ъ§ОнСїШыЪЧећИіЪ§ОнКўЙЙНЈЕФЦ№ЪМЃЌАќРЈдЊЪ§ОнЕФСїШыКЭвЕЮёЪ§ОнСїШыСНИіВПЗжЁЃдЊЪ§ОнСїШыАќРЈЪ§ОндДДДНЈЁЂдЊЪ§ОнзЅШЁСНВНЃЌзюжеЛсаЮГЩЪ§ОнзЪдДФПТМЃЌВЂЩњГЩЖдгІЕФАВШЋЩшжУгыЗУЮЪПижЦВпТдЁЃНтОіЗНАИЬсЙЉзЈУХЕФзщМўЃЌЛёШЁЭтВПЪ§ОндДЕФЯрЙидЊаХЯЂЃЌИУзщМўФмСЌНгЭтВПЪ§ОндДЁЂМьВтЪ§ОнИёЪНКЭФЃЪНЃЈschemaЃЉЃЌВЂдкЖдгІЕФЪ§ОнзЪдДФПТМжаДДНЈЪєгкЪ§ОнКўЕФдЊЪ§ОнЁЃвЕЮёЪ§ОнЕФСїШыЪЧЭЈЙ§ETLРДЭъГЩЕФЁЃ
дкОпЬхЕФВњЦЗаЮЪНЩЯЃЌдЊЪ§ОнзЅШЁЁЂETLКЭЪ§ОнзМБИAWSНЋЦфЕЅЖРГщЯѓГіРДЃЌаЮГЩСЫвЛИіВњЦЗНаAWS GLUEЁЃAWS
GLUEгыAWS Lake FormationЙВЯэЭЌвЛИіЪ§ОнзЪдДФПТМЃЌдкAWS GLUEЙйЭјЮФЕЕЩЯУїШЗжИГіЃКЁАEach
AWS account has one AWS Glue Data Catalog per AWS
regionЁБЁЃ
ЖдгквьЙЙЪ§ОндДЕФжЇГжЁЃAWSЬсЙЉЕФЪ§ОнКўНтОіЗНАИЃЌжЇГжS3ЁЂAWSЙиЯЕаЭЪ§ОнПтЁЂAWS NoSQLЪ§ОнПтЃЌAWSРћгУGLUEЁЂEMRЁЂAthenaЕШзщМўжЇГжЪ§ОнЕФздгЩСїЖЏЁЃ
2ЃЉ Ъ§ОнГСЕэЁЃ
ВЩгУAmazon S3зїЮЊећИіЪ§ОнКўЕФМЏжаДцДЂЃЌАДашРЉеЙ/АДЪЙгУСПИЖЗбЁЃ
3ЃЉ Ъ§ОнМЦЫуЁЃ
ећИіНтОіЗНАИРћгУAWS GLUEРДНјааЛљБОЕФЪ§ОнДІРэЁЃGLUEЛљБОЕФМЦЫуаЮЪНЪЧИїРрХњДІРэФЃЪНЕФETLШЮЮёЃЌШЮЮёЕФГіЗЂЗНЪНЗжЮЊЪжЖЏДЅЗЂЁЂЖЈЪБДЅЗЂЁЂЪТМўДЅЗЂШ§жжЁЃВЛЕУВЛЫЕЃЌAWSЕФИїРрЗўЮёдкЩњЬЌЩЯЪЕЯжЕФЗЧГЃКУЃЌЪТМўДЅЗЂФЃЪНЩЯЃЌПЩвдРћгУAWS
LambdaНјааРЉеЙПЊЗЂЃЌЭЌЪБДЅЗЂвЛИіЛђЖрИіШЮЮёЃЌМЋДѓЕФЬсЩ§СЫШЮЮёДЅЗЂЕФЖЈжЦПЊЗЂФмСІЃЛЭЌЪБЃЌИїРрETLШЮЮёЃЌПЩвдЭЈЙ§CloudWatchНјааКмКУЕФМрПиЁЃ
4ЃЉ Ъ§ОнгІгУЁЃ
дкЬсЙЉЛљБОЕФХњДІРэМЦЫуФЃЪНжЎЭтЃЌAWSЭЈЙ§ИїРрЭтВПМЦЫув§ЧцЃЌРДЬсЙЉЗсИЛЕФМЦЫуФЃЪНжЇГжЃЌР§ШчЭЈЙ§Athena/RedshiftРДЬсЙЉЛљгкSQLЕФНЛЛЅЪНХњДІРэФмСІЃЛЭЈЙ§EMRРДЬсЙЉИїРрЛљгкSparkЕФМЦЫуФмСІЃЌАќРЈSparkФмЬсЙЉЕФСїМЦЫуФмСІКЭЛњЦїбЇЯАФмСІЁЃ
5ЃЉ ШЈЯоЙмРэЁЃ
AWSЕФЪ§ОнКўНтОіЗНАИЭЈЙ§Lake FormationРДЬсЙЉЯрЖдЭъЩЦЕФШЈЯоЙмРэЃЌСЃЖШАќРЈЁАПт-Бэ-СаЁБЁЃЕЋЪЧЃЌгавЛЕуР§ЭтЕФЪЧЃЌGLUEЗУЮЪLake
FormationЪБЃЌСЃЖШжЛгаЁАПт-БэЁБСНМЖЃЛетвВДгСэвЛИіВрУцЫЕУїЃЌGLUEКЭLake FormationЕФМЏГЩЪЧИќЮЊНєУмЕФЃЌGLUEЖдгкLake
FormationжаЕФЪ§ОнгаИќДѓЕФЗУЮЪШЈЯоЁЃ
Lake FormationЕФШЈЯоНјвЛВНПЩвдЯИЗжЮЊЪ§ОнзЪдДФПТМЗУЮЪШЈЯоКЭЕзВуЪ§ОнЗУЮЪШЈЯоЃЌЗжБ№ЖдгІдЊЪ§ОнгыЪЕМЪДцДЂЕФЪ§ОнЁЃЪЕМЪДцДЂЪ§ОнЕФЗУЮЪШЈЯогжНјвЛВНЗжЮЊЪ§ОнДцШЁШЈЯоКЭЪ§ОнДцДЂЗУЮЪШЈЯоЁЃЪ§ОнДцШЁШЈЯоРрЫЦгкЪ§ОнПтжаЖдгкПтБэЕФЗУЮЪШЈЯоЃЌЪ§ОнДцДЂШЈЯодђНјвЛВНЯИЛЏСЫЖдгкS3жаОпЬхФПТМЕФЗУЮЪШЈЯоЃЈЗжЮЊЯдЪОКЭвўЪНСНжжЃЉЁЃШчЭМ8ЫљЪОЃЌгУЛЇAдкжЛгаЪ§ОнДцШЁЕФШЈЯоЯТЃЌЮоЗЈДДНЈЮЛгкS3жИЖЈbucketЯТЕФБэЁЃ
ИіШЫШЯЮЊетНјвЛВНЬхЯжСЫЪ§ОнКўашвЊжЇГжИїжжВЛЭЌЕФДцДЂв§ЧцЃЌЮДРДЕФЪ§ОнКўПЩФмВЛжЛS3/OSS/OBS/HDFSвЛРрКЫаФДцДЂЃЌПЩФмИљОнгІгУЕФЗУЮЪашЧѓЃЌФЩШыИќЖрРраЭЕФДцДЂв§ЧцЃЌР§ШчЃЌS3ДцДЂдЪМЪ§ОнЃЌNoSQLДцДЂДІРэЙ§КѓЪЪКЯвдЁАМќжЕЁБФЃЪНЗУЮЪЕФЪ§ОнЃЌOLAPв§ЧцДцДЂашвЊЪЕЪБГіИїРрБЈБэ/adhocВщбЏЕФЪ§ОнЁЃЫфШЛЕБЧАИїРрВФСЯЖМдкЧПЕїЪ§ОнКўгыЪ§ОнВжПтЕФВЛЭЌЃЛЕЋЪЧЃЌДгБОжЪЩЯЃЌЪ§ОнКўИќгІИУЪЧвЛРрШкКЯЕФЪ§ОнЙмРэЫМЯыЕФОпЬхЪЕЯжЃЌЁАКўВжвЛЬхЛЏЁБвВКмПЩФмЪЧЮДРДЕФвЛИіЗЂеЙЧїЪЦЁЃ

ЭМ8. AWSЪ§ОнКўНтОіЗНАИШЈЯоЗжРыЪОвт
злЩЯЃЌAWSЪ§ОнКўЗНАИГЩЪьЖШИпЃЌЬиБ№ЪЧдЊЪ§ОнЙмРэЁЂШЈЯоЙмРэЩЯПМТЧГфЗжЃЌДђЭЈСЫвьЙЙЪ§ОндДгыИїРрМЦЫув§ЧцЕФЩЯЯТгЮЙиЯЕЃЌШУЪ§ОнФмЙЛздгЩЁАвЦЖЏЁБЦ№РДЁЃдкСїМЦЫуКЭЛњЦїбЇЯАЩЯЃЌAWSЕФНтОіЗНАИвВБШНЯЭъЩЦЁЃСїМЦЫуЗНУцAWSЭЦГіСЫзЈУХЕФСїМЦЫузщМўKinesisЃЌKinesisжаЕФKinesis
data FirehoseЗўЮёПЩвдДДНЈвЛИіЭъШЋБЛЭаЙмЕФЪ§ОнЗжЗЂЗўЮёЃЌЭЈЙ§Kinesis data StreamЪЕЪБДІРэЕФЪ§ОнЃЌПЩвдНшжњFirehoseЗНБуЕФаДШыS3жаЃЌВЂжЇГжЯргІЕФИёЪНзЊЛЛЃЌШчНЋJSONзЊЛЛГЩParquetИёЪНЁЃAWSећИіЗНАИзюХЃЕФЕиЗНЛЙдкгыKinesisПЩвдЗУЮЪGLUEжаЕФдЊЪ§ОнЃЌетвЛЕуГфЗжЬхЯжСЫAWSЪ§ОнКўНтОіЗНАИдкЩњЬЌЩЯЕФЭъБИадЁЃЭЌбљЃЌдкЛњЦїбЇЯАЗНУцЃЌAWSЬсЙЉСЫSageMakerЗўЮёЃЌSageMakerПЩвдЖСШЁS3жаЕФбЕСЗЪ§ОнЃЌВЂНЋбЕСЗКУЕФФЃаЭЛиаДжСS3жаЁЃЕЋЪЧЃЌгавЛЕуашвЊжИГіЕФЪЧЃЌдкAWSЕФЪ§ОнКўНтОіЗНАИжаЃЌСїМЦЫуКЭЛњЦїбЇЯАВЂВЛЪЧЙЬЖЈРІАѓЕФЃЌжЛЪЧзїЮЊМЦЫуФмСІРЉеЙЃЌФмЗНБуЕФМЏГЩЁЃ
зюКѓЃЌШУЮвУЧЛиЕНЭМ6ЕФЪ§ОнКўзщМўВЮПММмЙЙЃЌПДПДAWSЕФЪ§ОнКўНтОіЗНАИЕФзщМўИВИЧЧщПіЃЌВЮМћЭМ9ЁЃ

ЭМ9. AWS Ъ§ОнКўНтОіЗНАИдкВЮПММмЙЙжаЕФгГЩф
злЩЯЃЌAWSЕФЪ§ОнКўНтОіЗНАИИВИЧСЫГ§жЪСПЙмРэКЭЪ§ОнжЮРэЕФЫљгаЙІФмЁЃЦфЪЕжЪСПЙмРэКЭЪ§ОнжЮРэетИіЙЄзїКЭЦѓвЕЕФзщжЏНсЙЙЁЂвЕЮёРраЭЧПЯрЙиЃЌашвЊзіДѓСПЕФЖЈжЦПЊЗЂЙЄзїЃЌвђДЫЭЈгУНтОіЗНАИВЛФвРЈетПщФкШнЃЌвВЪЧПЩвдРэНтЕФЁЃЪТЪЕЩЯЃЌЯждквВгаБШНЯгХауЕФПЊдДЯюФПжЇГжетИіЯюФПЃЌБШШчApache
GriffinЃЌШчЙћЖджЪСПЙмРэКЭЪ§ОнжЮРэгаЧПЫпЧѓЃЌПЩвдздааЖЈжЦПЊЗЂЁЃ
4.2 ЛЊЮЊЪ§ОнКўНтОіЗНАИ 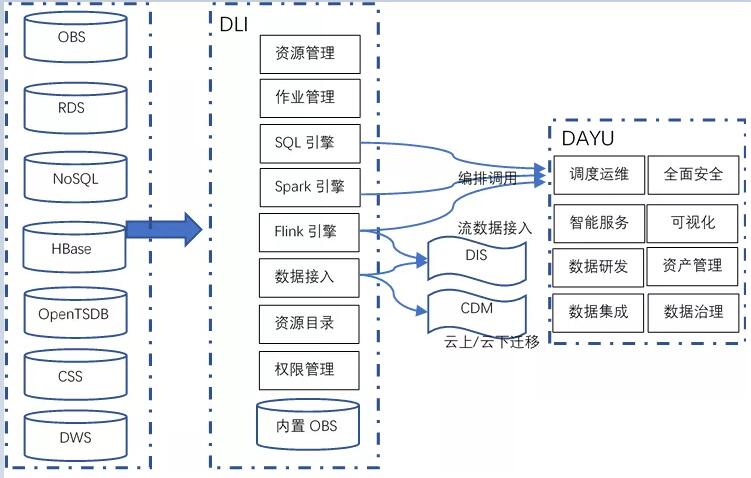
ЭМ10.ЛЊЮЊЪ§ОнКўНтОіЗНАИ
ЛЊЮЊЕФЪ§ОнКўНтОіЗНАИЯрЙиаХЯЂРДздЛЊЮЊЙйЭјЁЃФПЧАЙйЭјПЩМћЕФЯрЙиВњЦЗАќРЈЪ§ОнКўЬНЫїЃЈData Lake
InsightЃЌDLIЃЉКЭжЧФмЪ§ОнКўдЫгЊЦНЬЈЃЈDAYUЃЉЁЃЦфжаDLIЯрЕБгкЪЧAWSЕФLake FormationЁЂGLUEЁЂAthenaЁЂEMRЃЈFlink&SparkЃЉЕФМЏКЯЁЃЙйЭјЩЯУЛевЕНЙигкDLIЕФећЬхМмЙЙЭМЃЌЮвИљОнздМКЕФРэНтЃЌГЂЪдЛСЫвЛИіЃЌжївЊЪЧКЭAWSЕФНтОіЗНАИгавЛИіЖдБШЃЌЫљвдаЮЪНЩЯОЁСПвЛжТЃЌШчЙћгаЗЧГЃСЫНтЛЊЮЊDLIЕФЭЌбЇЃЌвВЧыВЛСпДЭНЬЁЃ
ЛЊЮЊЕФЪ§ОнКўНтОіЗНАИБШНЯЭъећЃЌDLIГаЕЃСЫЫљгаЕФЪ§ОнКўЙЙНЈЁЂЪ§ОнДІРэЁЂЪ§ОнЙмРэЁЂЪ§ОнгІгУЕФКЫаФЙІФмЁЃDLIзюДѓЕФЬиЩЋЪЧдкгкЗжЮів§ЧцЕФЭъБИадЃЌАќРЈЛљгкSQLЕФНЛЛЅЪНЗжЮівдМАЛљгкSpark+FlinkЕФСїХњвЛЬхДІРэв§ЧцЁЃдкКЫаФДцДЂв§ЧцЩЯЃЌDLIвРШЛЭЈЙ§ФкжУЕФOBSРДЬсЙЉЃЌКЭAWS
S3ЕФФмСІЛљБОЖдБъЁЃЛЊЮЊЪ§ОнКўНтОіЗНАИдкЩЯЯТгЮЩњЬЌЩЯзіЕФБШAWSЯрЖдЭъЩЦЃЌЖдгкЭтВПЪ§ОндДЃЌМИКѕжЇГжЫљгаФПЧАЛЊЮЊдЦЩЯЬсЙЉЕФЪ§ОндДЗўЮёЁЃ
DLIПЩвдгыЛЊЮЊЕФCDMЃЈдЦЪ§ОнЧЈвЦЗўЮёЃЉКЭDISЃЈЪ§ОнНгШыЗўЮёЃЉЖдНгЃК1ЃЉНшжњDISЃЌDLIПЩвдЖЈвхИїРрЪ§ОнЕуЃЌетаЉЕуПЩвддкFlinkзївЕжаБЛЪЙгУЃЌзіЮЊsourceЛђепsinkЃЛ2ЃЉНшжњCDMЃЌDLIЩѕжСФмНгШыIDCЁЂЕкШ§ЗНдЦЗўЮёЕФЪ§ОнЁЃ
ЮЊСЫИќКУЕФжЇГжЪ§ОнМЏГЩЁЂЪ§ОнПЊЗЂЁЂЪ§ОнжЮРэЁЂжЪСПЙмРэЕШЪ§ОнКўИпМЖЙІФмЃЌЛЊЮЊдЦЬсЙЉСЫDAYUЦНЬЈЁЃDAYUЦНЬЈЪЧЛЊЮЊЪ§ОнКўжЮРэдЫгЊЗНЗЈТлЕФТфЕиЪЕЯжЁЃDAYUКИЧСЫећИіЪ§ОнКўжЮРэЕФКЫаФСїГЬЃЌВЂЖдЦфЬсЙЉСЫЯргІЕФЙЄОпжЇГжЃЛЩѕжСдкЛЊЮЊЕФЙйЗНЮФЕЕжаЃЌИјГіСЫЪ§ОнжЮРэзщжЏЕФЙЙНЈНЈвщЁЃDAYUЕФЪ§ОнжЮРэЗНЗЈТлЕФТфЕиЪЕЯжШчЭМ11ЫљЪОЃЈРДздЛЊЮЊдЦЙйЭјЃЉЁЃ

ЭМ11 DAYUЪ§ОнжЮРэЗНЗЈТлСїГЬ
ПЩвдПДЕНЃЌБОжЪЩЯDAYUЪ§ОнжЮРэЕФЗНЗЈТлЦфЪЕЪЧДЋЭГЪ§ОнВжПтжЮРэЗНЗЈТлдкЪ§ОнКўЛљДЁЩшЪЉЩЯЕФбгЩьЃКДгЪ§ОнФЃаЭРДПДЃЌвРШЛАќРЈЬљдДВуЁЂЖрдДећКЯВуЁЂУїЯИЪ§ОнВуЃЌетЕугыЪ§ОнВжПтЭъШЋвЛжТЁЃИљОнЪ§ОнФЃаЭКЭжИБъФЃаЭЛсЩњГЩжЪСПЙцдђКЭзЊЛЛФЃаЭЃЌDAYUЛсКЭDLIЖдНгЃЌжБНгЕїгУDLIЬсЙЉЕФЯрЙиЪ§ОнДІРэЗўЮёЃЌЭъГЩЪ§ОнжЮРэЁЃЛЊЮЊдЦећИіЕФЪ§ОнКўНтОіЗНАИЃЌЭъећИВИЧСЫЪ§ОнДІРэЕФЩњУќжмЦкЃЌВЂЧвУїШЗжЇГжСЫЪ§ОнжЮРэЃЌВЂЬсЙЉСЫЛљгкФЃаЭКЭжИБъЕФЪ§ОнжЮРэСїГЬЙЄОпЃЌдкЛЊЮЊдЦЕФЪ§ОнКўНтОіЗНАИжаж№НЅПЊЪМЭљЁАКўВжвЛЬхЛЏЁБЗНЯђбнНјЁЃ
4.3 АЂРядЦЪ§ОнКўНтОіЗНАИ
АЂРядЦЩЯЪ§ОнРрВњЦЗжкЖрЃЌвђЮЊБОШЫФПЧАдкЪ§ОнBUЃЌЫљвдБОНкЗНАИНЋЙизЂдкШчКЮЪЙгУЪ§ОнПтBUЕФВњЦЗРДЙЙНЈЪ§ОнКўЃЌЦфЫћдЦЩЯВњЦЗЛсТдгаЩцМАЁЃАЂРядЦЕФЛљгкЪ§ОнПтВњЦЗЕФЪ§ОнКўНтОіЗНАИИќМгОлНЙЃЌжїДђЪ§ОнКўЗжЮіКЭСЊАюЗжЮіСНИіГЁОАЁЃАЂРядЦЪ§ОнКўНтОіЗНАИШчЭМ12ЫљЪОЁЃ

ЭМ12. АЂРядЦЪ§ОнКўНтОіЗНАИ
ећИіЗНАИвРШЛВЩгУOSSзїЮЊЪ§ОнКўЕФМЏжаДцДЂЁЃдкЪ§ОндДЕФжЇГжЩЯЃЌФПЧАвВжЇГжЫљгаЕФАЂРядЦЪ§ОнПтЃЌАќРЈOLTPЁЂOLAPКЭNoSQLЕШИїРрЪ§ОнПтЁЃКЫаФЙиМќЕуШчЯТЃК
1ЃЉ Ъ§ОнНгШыгыАсЧЈЁЃдкНЈКўЙ§ГЬжаЃЌDLAЕФFormationзщМўОпБИдЊЪ§ОнЗЂЯжКЭвЛМќНЈКўЕФФмСІЃЌдкБОЮФаДзїжЎЪБЃЌФПЧАЁАвЛМќНЈКўЁБЛЙжЛжЇГжШЋСПНЈКўЃЌЕЋЪЧЛљгкbinlogЕФдіСПНЈКўвбОдкПЊЗЂжаСЫЃЌдЄМЦНќЦкЩЯЯпЁЃдіСПНЈКўФмСІЛсМЋДѓЕФдіМгЪ§ОнКўжаЪ§ОнЕФЪЕЪБадЃЌВЂНЋЖддДЖЫвЕЮёЪ§ОнПтЕФбЙСІНЕЕНзюЯТЁЃетРяашвЊзЂвтЕФЪЧЃЌDLA
FormationЪЧвЛИіФкВПзщМўЃЌЖдЭтВЂУЛгаБЉТЖЁЃ
2ЃЉ Ъ§ОнзЪдДФПТМЁЃDLAЬсЙЉMeta data catalogзщМўЖдгкЪ§ОнКўжаЕФЪ§ОнзЪВњНјааЭГвЛЕФЙмРэЃЌЮоТлЪ§ОнЪЧдкЁАКўжаЁБЛЙЪЧдкЁАКўЭтЁБЁЃMeta
data catalogвВЪЧСЊАюЗжЮіЕФЭГвЛдЊЪ§ОнШыПкЁЃ
3ЃЉ дкФкжУМЦЫув§ЧцЩЯЃЌDLAЬсЙЉСЫSQLМЦЫув§ЧцКЭSparkМЦЫув§ЧцСНжжЁЃЮоТлЪЧSQLЛЙЪЧSparkв§ЧцЃЌЖМКЭMeta
data catalogЩюЖШМЏГЩЃЌФмЗНБуЕФЛёШЁдЊЪ§ОнаХЯЂЁЃЛљгкSparkЕФФмСІЃЌDLAНтОіЗНАИжЇГжХњДІРэЁЂСїМЦЫуКЭЛњЦїбЇЯАЕШМЦЫуФЃЪНЁЃ
4ЃЉ дкЭтЮЇЩњЬЌЩЯЃЌГ§СЫжЇГжИїРрвьЙЙЪ§ОндДзіЪ§ОнНгШыгыЛуОлжЎЭтЃЌдкЖдЭтЗУЮЪФмСІЩЯЃЌDLAгыдЦдЩњЪ§ОнВжПтЃЈдADBЃЉЩюЖШећКЯЁЃвЛЗНУцЃЌDLAДІРэЕФНсЙћПЩжЎМЪЭЦЫЭжСADBжаЃЌТњзуЪЕЪБЁЂНЛЛЅЪНЁЂad
hocИДдгВщбЏЃЛСэвЛЗНУцЃЌADBРяЕФЪ§ОнвВПЩвдНшжњЭтБэЙІФмЃЌКмЗНБуЕФНјааЪ§ОнЛиСїжСOSSжаЁЃЛљгкDLAЃЌАЂРядЦЩЯИїРрвьЙЙЪ§ОндДПЩвдЭъШЋБЛДђЭЈЃЌЪ§ОнздгЩСїЖЏЁЃ
5ЃЉ дкЪ§ОнМЏГЩКЭПЊЗЂЩЯЃЌАЂРядЦЕФЪ§ОнКўНтОіЗНАИЬсЙЉСНжжбЁдёЃКвЛжжЪЧВЩгУdataworksЭъГЩЃЛСэвЛжжЪЧВЩгУDMSРДЭъГЩЁЃЮоТлЪЧбЁдёФФжжЃЌЖМФмЖдЭтЬсЙЉПЩЪгЛЏЕФСїГЬБрХХЁЂШЮЮёЕїЖШЁЂШЮЮёЙмРэФмСІЁЃдкЪ§ОнЩњУќжмЦкЙмРэЩЯЃЌdataworksЕФЪ§ОнЕиЭМФмСІЯрЖдИќМгГЩЪьЁЃ
6ЃЉ дкЪ§ОнЙмРэКЭЪ§ОнАВШЋЩЯЃЌDMSЬсЙЉСЫЧПДѓЕФФмСІЁЃDMSЕФЪ§ОнЙмРэСЃЖШЗжЮЊЁАПт-Бэ-Са-ааЁБЃЌЭъЩЦЕФжЇГжЦѓвЕМЖЕФЪ§ОнАВШЋЙмПиашЧѓЁЃГ§СЫШЈЯоЙмРэжЎЭтЃЌDMSИќОЋЯИЕФЕиЗНЪЧАбдРДЛљгкЪ§ОнПтЕФdevopsРэФюРЉеЙЕНСЫЪ§ОнКўЃЌЪЙЕУЪ§ОнКўЕФдЫЮЌЁЂПЊЗЂИќМгОЋЯИЛЏЁЃ
НјвЛВНЯИЛЏећИіЪ§ОнКўЗНАИЕФЪ§ОнгІгУМмЙЙЃЌШчЯТЭМЫљЪОЁЃ

ЭМ13. АЂРядЦЪ§ОнКўЪ§ОнгІгУМмЙЙ
здзѓЯђгвДгЪ§ОнЕФСїЯђРДПДЃЌЪ§ОнЩњВњепВњЩњИїРрЪ§ОнЃЈдЦЯТ/дЦЩЯ/ЦфЫћдЦЃЉЃЌРћгУИїРрЙЄОпЃЌЩЯДЋжСИїРрЭЈгУ/БъзМЪ§ОндДЃЌАќРЈOSS/HDFS/DBЕШЁЃеыЖдИїРрЪ§ОндДЃЌDLAЭЈЙ§Ъ§ОнЗЂЯжЁЂЪ§ОнНгШыЁЂЪ§ОнЧЈвЦЕШФмСІЃЌЭъећНЈКўВйзїЁЃЖдгкЁАШыКўЁБЕФЪ§ОнЃЌDLAЬсЙЉЛљгкSQLКЭSparkЕФЪ§ОнДІРэФмСІЃЌВЂПЩвдЛљгкDataworks/DMSЃЌЖдЭтЬсЙЉПЩЪгЛЏЕФЪ§ОнМЏГЩКЭЪ§ОнПЊЗЂФмСІЃЛдкЖдЭтгІгУЗўЮёФмСІЩЯЃЌDLAЬсЙЉБъзМЛЏЕФJDBCНгПкЃЌПЩвджБНгЖдНгИїРрБЈБэЙЄОпЁЂДѓЦСеЙЪОЙІФмЕШЁЃАЂРядЦЕФDLAЕФЬиЩЋдкгкБГППећИіАЂРядЦЪ§ОнПтЩњЬЌЃЌАќРЈOLTPЁЂOLAPЁЂNoSQLЕШИїРрЪ§ОнПтЃЌЖдЭтЬсЙЉЛљгкSQLЕФЪ§ОнДІРэФмСІЃЌЖдгкДЋЭГЦѓвЕЛљгкЪ§ОнПтЕФПЊЗЂММЪѕеЛЖјбдЃЌзЊаЭГЩБОЯрЖдНЯЕЭЃЌбЇЯАЧњЯпБШНЯЦНЛКЁЃ
АЂРядЦЕФDLAНтОіЗНАИЕФСэвЛИіЬиЩЋдкгкЁАЛљгкдЦдЩњЕФКўВжвЛЬхЛЏЁБЁЃДЋЭГЕФЦѓвЕМЖЪ§ОнВжПтдкДѓЪ§ОнЪБДњЕФНёЬьЃЌдкИїРрБЈБэгІгУЩЯвРШЛЪЧЮоЗЈЬцДњЕФЃЛЕЋЪЧЪ§ВжЮоЗЈТњзуДѓЪ§ОнЪБДњЕФЪ§ОнЗжЮіДІРэЕФСщЛюадашЧѓЃЛвђДЫЃЌЮвУЧЭЦМіЪ§ОнВжПтгІИУзїЮЊЪ§ОнКўЕФЩЯВугІгУДцдкЃКМДЪ§ОнКўЪЧдЪМвЕЮёЪ§ОндквЛИіЦѓвЕ/зщжЏжаЮЈвЛЙйЗНЪ§ОнДцДЂЕиЃЛЪ§ОнКўИљОнИїРрвЕЮёгІгУашЧѓЃЌНЋдЪМЪ§ОнНјааМгЙЄДІРэЃЌаЮГЩПЩдйДЮРћгУЕФжаМфНсЙћЃЛЕБжаМфНсЙћЕФЪ§ОнФЃЪНЃЈSchemaЃЉЯрЖдЙЬЖЈКѓЃЌDLAПЩвдНЋжаМфНсЙћЭЦЫЭжСЪ§ОнВжПтЃЌЙЉЦѓвЕ/зщжЏПЊеЙЛљгкЪ§ВжЕФвЕЮёгІгУЁЃАЂРядЦдкЬсЙЉDLAЕФЭЌЪБЃЌЛЙЬсЙЉСЫдЦдЩњЪ§ВжЃЈдADBЃЉЃЌDLAКЭдЦдЩњЪ§ВждквдЯТСНЕуЩЯЩюЖШШкКЯЁЃ
1ЃЉ ЪЙгУЭЌдДЕФSQLНтЮів§ЧцЁЃDLAЕФSQLгыADBЕФSQLгяЗЈЩЯЭъШЋМцШнЃЌетвтЮЖзХПЊЗЂепЪЙгУвЛЬзММЪѕеЛМДФмЭЌЪБПЊЗЂЪ§ОнКўгІгУКЭЪ§ВжгІгУЁЃ
2ЃЉ ЖМФкжУСЫЖдгкOSSЕФЗУЮЪжЇГжЁЃOSSжБНгзїЮЊDLAЕФдЩњДцДЂДцдкЃЛЖдгкADBЖјбдЃЌПЩвдЭЈЙ§ЭтВПБэЕФФмСІЃЌКмЗНБуЕФЗУЮЪOSSЩЯЕФНсЙЙЛЏЪ§ОнЁЃНшжњЭтВПБэЃЌЪ§ОнПЩвдздгЩЕФдкDLAКЭADBжЎМфСїзЊЃЌзіЕНеце§ЕФКўВжвЛЬхЁЃ
DLA+ADBЕФзщКЯеце§зіЕНСЫдЦдЩњЕФКўВжвЛЬхЃЈЙигкЪВУДЪЧдЦдЩњЃЌВЛдкБОЮФЕФЬжТлЗЖГыЃЉЁЃБОжЪЩЯЃЌDLAПЩвдПДГЩвЛИіФмСІРЉеЙЕФЪ§ОнВжПтЬљдДВуЁЃгыДЋЭГЪ§ВжЯрБШЃЌИУЬљдДВуЃКЃЈ1ЃЉПЩвдБЃДцИїРрНсЙЙЛЏЁЂАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЃЛЃЈ2ЃЉПЩвдЖдНгИїРрвьЙЙЪ§ОндДЃЛЃЈ3ЃЉОпБИдЊЪ§ОнЗЂЯжЁЂЙмРэЁЂЭЌВНЕШФмСІЃЛЃЈ4ЃЉФкжУЕФSQL/SparkМЦЫув§ЧцОпБИИќЧПЕФЪ§ОнДІРэФмСІЃЌТњзуЖрбљЛЏЕФЪ§ОнДІРэашЧѓЃЛЃЈ5ЃЉОпБИШЋСПЪ§ОнЕФШЋЩњУќжмЦкЙмРэФмСІЁЃЛљгкDLA+ADBЕФКўВжвЛЬхЛЏЗНАИЃЌНЋЭЌЪБИВИЧЁАДѓЪ§ОнЦНЬЈ+Ъ§ОнВжПтЁБЕФДІРэФмСІЁЃ

DLAЛЙгавЛИіживЊФмСІЪЧЙЙНЈСЫвЛИіЁАЫФЭЈАЫДяЁБЕФЪ§ОнСїЖЏЬхЯЕЃЌВЂвдЪ§ОнПтЕФЬхбщЖдЭтЬсЙЉФмСІЃЌЮоТлЪ§ОндкдЦЩЯЛЙЪЧдЦЯТЃЌЮоТлЪ§ОндкзщжЏФкВПЛЙЪЧЭтВПЃЛНшжњЪ§ОнКўЃЌИїИіЯЕЭГжЎМфЕФЪ§ОнВЛдйДцдкБкРнЃЌПЩвдздгЩЕФСїНјСїГіЃЛИќживЊЕФЪЧЃЌетжжСїЖЏЪЧЪмМрЙмЕФЃЌЪ§ОнКўЭъећЕФМЧТМСЫЪ§ОнЕФСїЖЏЧщПіЁЃ
4.4 AzureЪ§ОнКўНтОіЗНАИ
AzureЕФЪ§ОнКўНтОіЗНАИАќРЈЪ§ОнКўДцДЂЁЂНгПкВуЁЂзЪдДЕїЖШгыМЦЫув§ЧцВуЃЌШчЭМ15ЫљЪОЃЈРДздAzureЙйЭјЃЉЁЃДцДЂВуЪЧЛљгкAzure
object StorageЙЙНЈЕФЃЌвРШЛЪЧЖдНсЙЙЛЏЁЂАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЬсЙЉжЇГХЁЃНгПкВуЮЊWebHDFSЃЌБШНЯЬиБ№ЕФЪЧдкAzure
object StorageЪЕЯжСЫHDFSЕФНгПкЃЌAzureАбетИіФмСІГЦЮЊЁАЪ§ОнКўДцДЂЩЯЕФЖравщДцШЁЁБЁЃдкзЪдДЕїЖШЩЯЃЌAzureЛљгкYARNЪЕЯжЁЃМЦЫув§ЧцЩЯЃЌAzureЬсЙЉСЫU-SQLЁЂhadoopКЭSparkЕШЖржжДІРэв§ЧцЁЃ

ЭМ15. Azure Data lake analysis МмЙЙ
AzureЕФЬиБ№жЎДІЪЧЛљгкvisual studioЬсЙЉИјСЫПЭЛЇПЊЗЂЕФжЇГжЁЃ
1ЃЉПЊЗЂЙЄОпЕФжЇГжЃЌгыvisual studioЕФЩюЖШМЏГЩЃЛAzureЭЦМіЪЙгУU-SQLзїЮЊЪ§ОнКўЗжЮігІгУЕФПЊЗЂгябдЁЃVisual
studioЮЊU-SQLЬсЙЉСЫЭъБИЕФПЊЗЂЛЗОГЃЛЭЌЪБЃЌЮЊСЫНЕЕЭЗжВМЪНЪ§ОнКўЯЕЭГПЊЗЂЕФИДдгадЃЌvisual
studioЛљгкЯюФПНјааЗтзАЃЌдкНјааU-SQLПЊЗЂЪБЃЌПЩвдДДНЈЁАU-SQL database projectЁБЃЌдкДЫРрЯюФПжаЃЌРћгУvisual
studioЃЌПЩвдКмЗНБуЕФНјааБрТыгыЕїЪдЃЌЭЌЪБЃЌвВЬсЙЉЯђЕМЃЌНЋПЊЗЂКУЕФU-SQLНХБОЗЂВМЕНЩњГЩЛЗОГЁЃU-SQLжЇГжPythonЁЂRНјааРЉеЙЃЌТњзуЖЈжЦПЊЗЂашЧѓЁЃ
2ЃЉЖрМЦЫув§ЧцЕФЪЪХфЃКSQL, Apache HadoopКЭApache SparkЁЃетРяЕФhadoopАќРЈAzureЬсЙЉЕФHDInsightЃЈAzureЭаЙмЕФHadoopЗўЮёЃЉЃЌSparkАќРЈAzure
DatabricksЁЃ
3ЃЉЖржжВЛЭЌв§ЧцШЮЮёжЎМфЕФздЖЏзЊЛЛФмСІЁЃЮЂШэЭЦМіU-SQLЮЊЪ§ОнКўЕФШБЪЁПЊЗЂЙЄОпЃЌВЂЬсЙЉИїРрзЊЛЛЙЄОпЃЌжЇГжU-SQLНХБОгыHiveЁЂSparkЃЈHDSight&databricksЃЉЁЂAzure
Data Factory data FlowжЎМфЕФзЊЛЏЁЃ
4.5 аЁНс
БОЮФЫљЬжТлЕФЪЧЪ§ОнКўЕФНтОіЗНАИЃЌВЛЛсЩцМАЕНШЮКЮдЦГЇЩЬЕФЕЅИіВњЦЗЁЃЮвУЧДгЪ§ОнНгШыЁЂЪ§ОнДцДЂЁЂЪ§ОнМЦЫуЁЂЪ§ОнЙмРэЁЂгІгУЩњЬЌМИИіЗНУцЃЌМђЕЅзіСЫвЛИіРрЫЦЯТБэЕФзмНсЁЃ

ГігкЦЊЗљЙиЯЕЃЌЦфЪЕжЊУћдЦГЇЩЬЕФЪ§ОнКўНтОіЗНАИЛЙгаЙШИшКЭЬкбЖЕФЁЃетСНМвДгЦфЙйЗНЭјеОЩЯПДЃЌЪ§ОнКўНтОіЗНАИЯрЖдРДНВБШНЯМђЕЅЃЌвВНіНіЪЧвЛаЉИХФюЩЯЕФВћЪіЃЌЭЦМіЕФТфЕиЗНАИЪЧЁАoss+hadoopЃЈEMRЃЉЁБЁЃЦфЪЕЪ§ОнКўВЛгІИУДгвЛИіМђЕЅЕФММЪѕЦНЬЈЪгНЧРДПДЃЌЪЕЯжЪ§ОнКўЕФЗНЪНвВЖржжЖрбљЃЌЦРМлвЛИіЪ§ОнКўНтОіЗНАИЪЧЗёГЩЪьЃЌЙиМќгІИУПДЦфЬсЙЉЕФЪ§ОнЙмРэФмСІЃЌОпЬхАќРЈЕЋВЛЯогкдЊЪ§ОнЁЂЪ§ОнзЪВњФПТМЁЂЪ§ОндДЁЂЪ§ОнДІРэШЮЮёЁЂЪ§ОнЩњУќжмЦкЁЂЪ§ОнжЮРэЁЂШЈЯоЙмРэЕШЃЛвдМАгыЭтЮЇЩњЬЌЕФЖдНгДђЭЈФмСІЁЃ
ЮхЁЂЕфаЭЕФЪ§ОнКўгІгУАИР§
5.1 ЙуИцЪ§ОнЗжЮі
НќФъРДЃЌСїСПЛёШЁЕФГЩБООЭдНРДдНИпЃЌЯпЩЯЧўЕРЛёПЭГЩБОЕФГЩБЖдіГЄШУИїааИївЕЖМУцСйзХбЯОўЕФЬєеНЁЃдкЛЅСЊЭјЙуИцГЩБОВЛЖЯХЪЩ§ЕФДѓБГОАЯТЃЌвдЛЈЧЎТђСїСПРаТЮЊжївЊЕФОгЊВпТдБиШЛааВЛЭЈСЫЁЃСїСПЧАЖЫЕФгХЛЏвбГЩЧПхѓжЎФЉЃЌРћгУЪ§ОнЙЄОпЬсИпСїСПЕНеОКѓЕФФПБъзЊЛЏЃЌОЋЯИЛЏдЫгЊЙуИцЭЖЗХЕФИїИіЛЗНкЃЌВХЪЧИФБфЯжзДИќЮЊжБНггааЇЕФЗНЪНЁЃЫЕЕНЕзЃЌвЊЬсИпЙуИцСїСПЕФзЊЛЏТЪЃЌБиаывРППДѓЪ§ОнЗжЮіЁЃ
ЮЊСЫФмЙЛЬсЙЉИќЖрЕФОіВпжЇГХвРОнЃЌашвЊВЩШЁИќЖрЕФТёЕуЪ§ОнЕФЪеМЏКЭЗжЮіЃЌАќРЈЕЋВЛЯогкЧўЕРЁЂЭЖЗХЪБМфЁЂЭЖЗХШЫШКЃЌвдЕуЛїТЪЮЊЪ§ОнжИБъНјааЪ§ОнЗжЮіЃЌДгЖјИјГіИќКУЕФЁЂИќбИЫйЕФЗНАИКЭНЈвщЃЌЪЕЯжИпаЇТЪИпВњГіЁЃвђДЫЃЌУцЖдЙуИцЭЖЗХСьгђЖрЮЌЖШЁЂЖрУНЬхЁЂЖрЙуИцЮЛЕШНсЙЙЛЏЁЂАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнВЩМЏЁЂДцДЂЁЂЗжЮіКЭОіВпНЈвщЕШвЊЧѓЃЌЪ§ОнКўЗжЮіВњЦЗНтОіЗНАИдкЙуИцжїЛђепЗЂВМЩЬНјаааТвЛДњММЪѕбЁаЭжаЩЯЪмЕНСЫКмШШСвЕФЧрэљЁЃ
DGЪЧвЛМвШЋЧђСьЯШЕФЦѓвЕЙњМЪЛЏжЧФмгЊЯњЗўЮёЩЬЃЌЛљгкЯШНјЕФЙуИцММЪѕЁЂДѓЪ§ОнКЭдЫгЊФмСІЃЌЮЊПЭЛЇЬсЙЉШЋЧђИпжЪСПгУЛЇЛёШЁМАСїСПБфЯжЗўЮёЁЃDGДгГЩСЂжЎГѕОЭОіЖЈвдЙЋгадЦЮЊЛљДЁРДЙЙНЈЦфITЛљДЁЩшЪЉЃЌзюГѕDGбЁдёСЫAWSдЦЦНЬЈЃЌжївЊНЋЦфЙуИцЪ§ОндкS3жавдЪ§ОнКўЕФаЮЬЌНјааДцЗХЃЌЭЈЙ§AthenaНјааНЛЛЅЪНЗжЮіЁЃШЛЖјЫцзХЛЅСЊЭјЙуИцЕФЗЩЫйЗЂеЙЃЌЙуИцаавЕДјРДСЫМИДѓЬєеНЃЌвЦЖЏЙуИцЕФЗЂВМгызЗзйЯЕЭГБиаыНтОіМИИіЙиМќЮЪЬтЃК
1ЃЉ ВЂЗЂадгыЗхжЕЮЪЬтЁЃдкЙуИцаавЕЃЌСїСПИпЗхЪБГЃГіЯжЃЌЫВМфЕФЕуЛїСППЩФмДяЕНЪ§ЭђЃЌЩѕжСЪ§ЪЎЭђЃЌетОЭвЊЧѓЯЕЭГОпБИЗЧГЃКУЕФПЩРЉеЙадвдПьЫйЯьгІКЭДІРэУПвЛДЮЕуЛї
2ЃЉ ШчКЮЪЕЯжЖдКЃСПЪ§ОнЕФЪЕЪБЗжЮіЁЃЮЊСЫМрПиЙуИцЭЖЗХаЇЙћЃЌЯЕЭГашвЊЪЕЪБЖдгУЛЇЕФУПвЛДЮЕуЛїКЭМЄЛюЪ§ОнНјааЗжЮіЃЌЭЌЪБАбЯрЙиЪ§ОнДЋЪфЕНЯТгЮЕФУНЬхЃЛ
3ЃЉ ЦНЬЈЕФЪ§ОнСПдкМБОчдіГЄЃЌУПЬьЕФвЕЮёШежОЪ§ОндкГжајЕФВњЩњКЭЩЯДЋЃЌЦиЙтЁЂЕуЛїЁЂЭЦЫЭЕФЪ§ОндкГжајДІРэЃЌУПЬьаТдіЕФЪ§ОнСПвбОдк10-50TBзѓгвЃЌЖдећИіЪ§ОнДІРэЯЕЭГЬсГіСЫИќИпЕФвЊЧѓЁЃШчКЮИпаЇЕиЭъГЩЖдЙуИцЪ§ОнЕФРыЯп/НќЪЕЪБЭГМЦЃЌАДееЙуИцПЭЛЇЕФЮЌЖШвЊЧѓНјааОлКЯЗжЮіЁЃ
еыЖдЩЯЪіШ§ЕувЕЮёЬєеНЃЌЭЌЪБDGетИіПЭЛЇШедіСПЪ§Оне§дкМБОчБфДѓЃЈЕБЧАШеЪ§ОнЩЈУшСПДяЕН100+TBЃЉЃЌМЬајдкAWSЦНЬЈЪЙгУгіЕНAthenaЖСШЁS3Ъ§ОнДјПэЦПОБЁЂЪ§ОнЗжЮіжЭКѓЪБМфдНРДдНГЄЁЂЮЊгІЖдЪ§ОнКЭЗжЮіашЧѓдіГЄЖјМБОчХЪЩ§ЕФЭЖШыГЩБОЕШЃЌОЙ§ШЯецЁЂзаЯИЕФВтЪдКЭЗжЮіЃЌзюжеОіЖЈДгAWSдЦЦНЬЈШЋСПАсеОЕНАЂРядЦЦНЬЈЃЌаТМмЙЙЭМШчЯТЃК
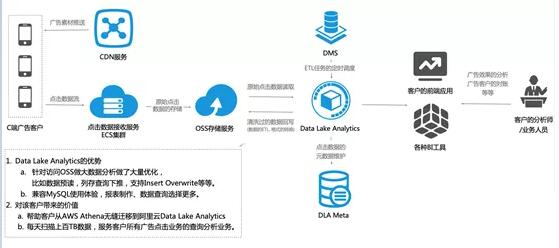
ЭМ16. ИФдьКѓЕФЙуИцЪ§ОнКўЗНАИМмЙЙ
ДгAWSАсеОЕНАЂРядЦКѓЃЌЮвУЧЮЊИУПЭЛЇЩшМЦСЫЁАРћгУData Lake Analytics + OSSЁБМЋжТЗжЮіФмСІРДгІЖдвЕЮёВЈЗхВЈЙШЁЃвЛЗНУцЧсЫЩгІЖдРДздЦЗХЦПЭЛЇЕФСйЪБЗжЮіЁЃСэвЛЗНУцРћгУData
Lake AnalyticsЕФЧПДѓМЦЫуФмСІЃЌЗжЮіАДдТЁЂМОЖШЙуИцЭЖЗХЃЌОЋШЗМЦЫуГівЛИіЦЗХЦЯТУцЛсгаЖрЩйИіЛюЖЏЃЌУПИіЛюЖЏЗжУНЬхЃЌЗжЪаГЁЃЌЗжЦЕЕРЃЌЗжDMPЕФЭЖЗХаЇЙћЃЌНјвЛВНдіЧПСЫМгКЭжЧФмСїСПЦНЬЈЮЊЦЗХЦгЊЯњДјРДЕФЯњЪлзЊЛЏТЪЁЃВЂЧвдкЙуИцЭЖЗХгыЗжЮіЕФзмгЕгаГЩБОЩЯЃЌData
Lake AnalyticsЬсЙЉЕФServerlessЕФЕЏадЗўЮёЮЊАДашЪеЗбЃЌВЛашвЊЙКТђЙЬЖЈЕФзЪдДЃЌЭъШЋЦѕКЯвЕЮёГБЯЋДјРДЕФзЪдДВЈЖЏЃЌТњзуЕЏадЕФЗжЮіашЧѓЃЌЭЌЪБМЋДѓЕиНЕЕЭСЫдЫЮЌГЩБОКЭЪЙгУГЩБОЁЃ

ЭМ17 Ъ§ОнКўВПЪ№ЪОвтЭМ
змЬхЩЯЃЌDGДгAWSЧаЛЛЕНАЂРядЦКѓЃЌМЋДѓЕиНкЪЁСЫгВМўГЩБОЁЂШЫСІГЩБОКЭПЊЗЂГЩБОЁЃгЩгкВЩгУDLA serverlessдЦЗўЮёЃЌDGЮоашЯШЦкЭЖШыДѓСПЕФзЪН№ШЅЙКТђЗўЮёЦїЁЂДцДЂЕШгВМўЩшБИЃЌвВЮоашвЛДЮадЙКТђДѓСПЕФдЦЗўЮёЃЌЦфЛљДЁЩшЪЉЕФЙцФЃЭъШЋЪЧАДашРЉеЙЃКашЧѓИпЕФЪБКђдіМгЗўЮёЪ§СПЃЌашЧѓМѕЩйЕФЪБКђМѕЩйЗўЮёЪ§СПЃЌЬсИпСЫзЪН№ЕФРћгУТЪЁЃЪЙгУАЂРядЦЦНЬЈДјРДЕФЕкЖўИіЯджјКУДІЪЧадФмЕФЬсЩ§ЁЃдкDGвЕЮёЕФПьЫйдіГЄЦквдМАКѓајЖрЬѕвЕЮёЯпНгШыЦкЃЌDGдквЦЖЏЙуИцЯЕЭГЕФЗУЮЪСПОГЃГЪБЌЗЂЪНдіГЄЃЌШЛЖјдЯШAWSЗНАИКЭЦНЬЈдкAthenaЖСШЁS3Ъ§ОнгіЕНЪ§ОнЖСШЁДјПэЕФМЋДѓЦПОБЃЌЪ§ОнЗжЮіЕФЪБМфБфЕУдНРДдНГЄЃЌАЂРядЦDLAСЊКЯOSSЭХЖгЕШНјааСЫМЋДѓЕФгХЛЏКЭИФдьЃЌЭЌЪБЃЌDLAЪ§ОнПтЗжЮідкМЦЫув§ЧцЩЯЃЈгыTPC-DSДђАёЪРНчЕквЛЕФAnalyticDBЙВЯэМЦЫув§ЧцЃЉБШPrestoдЩњМЦЫув§ЧцЕФФмСІЬсЩ§Ъ§ЪЎБЖадФмЃЌвВМЋДѓЕФЮЊDGЬсЩ§СЫЗжЮіадФмЁЃ
5.2 гЮЯЗдЫгЊЗжЮі
Ъ§ОнКўЪЧвЛРрTCOБэЯжМЋЦфгХауЕФДѓЪ§ОнЛљДЁЩшЪЉЁЃЖдгкКмЖрПьЫйдіГЄЕФгЮЯЗЙЋЫОЖјбдЃЌвЛИіБЌПюгЮЯЗЃЌЭљЭљдкЖЬЦкФкЯрЙиЪ§ОндіГЄМЋПьЃЛЭЌЪБЃЌЙЋЫОЕФбаЗЂШЫдБЕФММЪѕеЛКмФбдкЖЬЦкФкгыЪ§ОнЕФдіСПКЭдіЫйНјааЦЅХфЃЛДЫЪБЃЌГЪБЌЗЂдіГЄЕФЪ§ОнКмФбБЛгааЇРћгУЁЃЪ§ОнКўЪЧвЛИіНтОіДЫРрЮЪЬтЕФММЪѕбЁдёЁЃ
YJЪЧвЛМвИпЫйГЩГЄЕФгЮЯЗЙЋЫОЃЌЙЋЫОЯЃЭћФмвРЭаЯрЙигУЛЇааЮЊЪ§ОнНјааЩюШыЗжЮіЃЌжИЕМгЮЯЗЕФПЊЗЂКЭдЫгЊЁЃЪ§ОнЗжЮіБГКѓЕФКЫаФТпМдкгкЫцзХгЮЯЗаавЕЪаГЁОКељОжУцЕФРЉДѓЃЌЭцМвЖдгкЦЗжЪЕФвЊЧѓдНРДдНИпЃЌгЮЯЗЯюФПЕФЩњУќжмЦкдНРДдНЖЬЃЌжБНггАЯьЯюФПЕФЭЖШыВњГіБШЃЌЭЈЙ§Ъ§ОндЫгЊдђПЩвдгааЇЕФбгГЄЯюФПЕФЩњУќжмЦкЃЌЖдИїИіНзЖЮЕФвЕЮёзпЯђНјааОЋзМАбПиЁЃЖјЫцзХСїСПГЩБОЕФШевцЩЯЩ§ЃЌШчКЮЙЙНЈОМУЁЂИпаЇЕФОЋЯИЛЏЪ§ОндЫгЊЬхЯЕЃЌвдИќКУЕФжЇГХвЕЮёЗЂеЙЃЌвВБфЕУгњЗЂживЊЦ№РДЁЃЪ§ОндЫгЊЬхЯЕОЭашвЊгаЦфХфЬзЕФЛљДЁжЇГХЩшЪЉЃЌШчКЮбЁдёетРрЛљДЁжЇГХЩшЪЉЃЌЪЧЙЋЫОММЪѕОіВпепашвЊЫМПМЕФЮЪЬтЁЃЫМПМЕФГіЗЂЕуАќРЈЃК
1ЃЉ вЊгазуЙЛЕФЕЏадЁЃЖдгкгЮЯЗЖјбдЃЌЭљЭљОЭЪЧЖЬЪБМфБЌЗЂЃЌЪ§ОнСПМЄдіЃЛвђДЫЃЌФмЗёЪЪгІЪ§ОнЕФБЌЗЂаддіГЄЃЌТњзуЕЏадашЧѓЪЧвЛИіжиЕуПМСПЕФЕуЃЛЮоТлЪЧМЦЫуЛЙЪЧДцДЂЃЌЖМашвЊОпБИзуЙЛЕФЕЏадЁЃ
2ЃЉ вЊгазуЙЛЕФадМлБШЁЃЖдгкгУЛЇааЮЊЪ§ОнЃЌЭљЭљашвЊРЕНвЛИіКмГЄЕФжмЦкШЅЗжЮіШЅЖдБШЃЌБШШчСєДцТЪЃЌВЛЩйЧщПіЯТашвЊПМТЧ90ЬьЩѕжС180ЬьПЭЛЇЕФСєДцТЪЃЛвђДЫЃЌШчКЮвдзюОпадМлБШЕФЗНЪНГЄЦкДцДЂКЃСПЪ§ОнЪЧашвЊжиЕуПМТЧЕФЮЪЬтЁЃ
3ЃЉ вЊгаЙЛгУЕФЗжЮіФмСІЃЌЧвОпБИПЩРЉеЙадЁЃаэЖрЧщПіЯТЃЌгУЛЇааЮЊЬхЯждкТёЕуЪ§ОнжаЃЌТёЕуЪ§ОнгжашвЊгыгУЛЇзЂВсаХЯЂЁЂЕЧТНаХЯЂЁЂеЫЕЅЕШНсЙЙЛЏЪ§ОнЙиСЊЗжЮіЃЛвђДЫЃЌдкЪ§ОнЗжЮіЩЯЃЌжСЩйашвЊгаДѓЪ§ОнЕФETLФмСІЁЂвьЙЙЪ§ОндДЕФНгШыФмСІКЭИДдгЗжЮіЕФНЈФЃФмСІЁЃ
4ЃЉ вЊгыЙЋЫОЯжгаММЪѕеЛЯрЦЅХфЃЌЧвКѓајРћгкеаЦИЁЃЖдгкYJЃЌЦфдкММЪѕбЁаЭЕФЪБКђвЛИіживЊЕуОЭЪЧЦфММЪѕШЫдБЕФММЪѕеЛЃЌYJЕФММЪѕЭХЖгДѓВПЗжжЛЪьЯЄДЋЭГЕФЪ§ОнПтПЊЗЂЃЌМДMySQLЃЛВЂЧвШЫЪжНєеХЃЌзіЪ§ОндЫгЊЗжЮіЕФММЪѕШЫдБжЛга1ИіЃЌЖЬЪБМфФкИљБОУЛгаФмСІЖРСЂЙЙНЈДѓЪ§ОнЗжЮіЕФЛљДЁЩшЪЉЁЃДгYJЕФНЧЖШГіЗЂЃЌзюКУОјДѓЖрЪ§ЗжЮіФмЙЛЭЈЙ§SQLЭъГЩЃЛВЂЧвдкеаЦИЪаГЁЩЯЃЌSQLПЊЗЂШЫдБЕФЪ§СПвВдЖИпгкДѓЪ§ОнПЊЗЂЙЄГЬЪІЕФЪ§СПЁЃеыЖдПЭЛЇЕФЧщПіЃЌЮвУЧАяжњПЭЛЇЖдЯжгаЗНАИзіСЫИФдьЁЃ

ЭМ18. ИФдьЧАЕФЗНАИ
ИФдьЧАЃЌПЭЛЇЫљгаЕФНсЙЙЛЏЪ§ОнЖМдквЛИіИпЙцИёЕФMySQLРяУцЃЛЖјЭцМвааЮЊЪ§ОндђЪЧЭЈЙ§LogTailВЩМЏжСШежОЗўЮёЃЈSLSЃЉжаЃЌШЛКѓДгШежОЗўЮёжаЗжБ№ЭЖЕнЕНOSSКЭESРяЁЃетИіМмЙЙЕФЮЪЬтдкгкЃК1ЃЉааЮЊЪ§ОнКЭНсЙЙЛЏЪ§ОнЭъШЋИюСбЃЌЮоЗЈСЊЖЏЗжЮіЃЛ2ЃЉЖдгкааЮЊЪ§ОнжЧФмЬсЙЉМьЫїЙІФмЃЌЮоЗЈзіЩюВуДЮЕФЭкОђЗжЮіЃЛ3ЃЉOSSНіНізїЮЊЪ§ОнДцДЂзЪдДЪЙгУЃЌВЂУЛгаЭкОђГізуЙЛЕФЪ§ОнМлжЕЁЃ
ЪТЪЕЩЯЃЌЮвУЧЗжЮіПЭЛЇЯжДцМмЙЙЦфЪЕвбООпБИСЫЪ§ОнКўЕФГћаЮЃКШЋСПЪ§ОнвбОдкOSSжаБЃДцЯТРДСЫЃЌЯждкашвЊНјвЛВНВЙЦыПЭЛЇЖдгкOSSжаЕФЪ§ОнЕФЗжЮіФмСІЁЃЖјЧвЪ§ОнКўЛљгкSQLЕФЪ§ОнДІРэФЃЪНвВТњзуПЭЛЇЖдгкПЊЗЂММЪѕеЛЕФашЧѓЁЃзлЩЯЃЌЮвУЧЖдПЭЛЇЕФМмЙЙзіСЫШчЯТЕїећЃЌАяжњПЭЛЇЙЙНЈСЫЪ§ОнКўЁЃ

ЭМ19. ИФдьКѓЕФЪ§ОнКўНтОіЗНАИ
змЬхЩЯЃЌЮвУЧУЛгаИФБфПЭЛЇЕФЪ§ОнСДТЗСїзЊЃЌжЛЪЧдкOSSЕФЛљДЁЩЯЃЌдіМгСЫDLAзщМўЃЌЖдOSSЕФЪ§ОнНјааЖўДЮМгЙЄДІРэЁЃDLAЬсЙЉСЫБъзМSQLМЦЫув§ЧцЃЌЭЌЪБжЇГжНгШыИїРрвьЙЙЪ§ОндДЁЃЛљгкDLAЖдOSSЕФЪ§ОнНјааДІРэКѓЃЌЩњГЩвЕЮёжБНгПЩгУЕФЪ§ОнЁЃЕЋЪЧDLAЕФЮЪЬтдкгкЮоЗЈжЇГХЕЭбгГйашЧѓЕФНЛЛЅЪНЗжЮіГЁОАЃЌЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧв§ШыСЫдЦдЩњЪ§ОнВжПтADBРДНтОіНЛЛЅЪНЗжЮіЕФбгГйадЮЪЬтЃЛЭЌЪБЃЌдкзюЧАЖЫв§ШыQuickBIзїЮЊПЭЛЇЕФПЩЪгЛЏЗжЮіЙЄОпЁЃYJЗНАИЪЧЭМ14ЫљЪОЕФКўВжвЛЬхЛЏНтОіЗНАИдкгЮЯЗаавЕЕФвЛИіОЕфТфЕиАИР§ЁЃ
YMЪЧвЛМвЪ§ОнжЧФмЗўЮёЬсЙЉЩЬЃЌУцЯђИїРржааЁЩЬМвЬсЙЉвЛЯЕСаЪ§ОнЗжЮідЫгЊЗўЮёЁЃОпЬхЪЕЯжЕФММЪѕТпМШчЯТЭМЫљЪОЁЃ

ЭМ20. YMжЧФмЪ§ОнЗўЮёSaaSФЃЪНЪОвт
ЦНЬЈЗНЬсЙЉЖрЖЫSDKЙЉгУЛЇЃЈЩЬМвЬсЙЉЭјвГЁЂAPPЁЂаЁГЬађЕШЖржжНгШыаЮЪНЃЉНгШыИїРрТёЕуЪ§ОнЃЌЦНЬЈЗНвдSaaSЕФаЮЪНЬсЙЉЭГвЛЕФЪ§ОнНгШыЗўЮёКЭЪ§ОнЗжЮіЗўЮёЁЃЩЬМвЭЈЙ§ЗУЮЪИїРрЪ§ОнЗжЮіЗўЮёРДНјааИќЯИСЃЖШЕФТёЕуЪ§ОнЗжЮіЃЌЭъГЩааЮЊЭГМЦЁЂПЭЛЇЛЯёЁЂПЭЛЇШІбЁЁЂЙуИцЭЖЗХМрВтЕШЛљБОЗжЮіЙІФмЁЃШЛЖјЃЌетжжSaaSФЃЪНЯТЃЌЛсДцдквЛЖЈЕФЮЪЬтЃК
1ЃЉ гЩгкЩЬМвРраЭКЭашЧѓЕФЖрбљЛЏЃЌЦНЬЈЬсЙЉSaaSРрЗжЮіЙІФмКмФбИВИЧЫљгаРраЭЕФЩЬМвЃЌЮоЗЈТњзуЩЬМвЕФЖЈжЦЛЏашЧѓЃЛШчгааЉЩЬМвЙизЂЯњСПЃЌгааЉЙизЂПЭЛЇдЫгЊЃЌгааЉЙизЂГЩБОгХЛЏЃЌКмФбТњзуЫљгаЕФашЧѓЁЃ
2ЃЉ ЖдгквЛаЉИпМЖЗжЮіЙІФмЃЌШчвРРЕгкздЖЈвхБъЧЉЕФПЭЛЇШІбЁЁЂПЭЛЇздЖЈвхРЉеЙЕШЙІФмЃЌЭГвЛЕФЪ§ОнЗжЮіЗўЮёЮоЗЈТњзуЕФЃЛЬиБ№ЪЧвЛаЉздЖЈвхЕФБъЧЉвРРЕгкЩЬМвздЖЈвхЕФЫуЗЈЃЌЮоЗЈТњзуПЭЛЇЕФИпМЖЗжЮіашЧѓЁЃ
3ЃЉ Ъ§ОнЕФзЪВњЛЏЙмРэашЧѓЁЃдкДѓЪ§ОнЪБДњЃЌЪ§ОнЪЧвЛИіЦѓвЕ/зщжЏЕФзЪВњвбОГЩЮЊСЫДѓМвЕФЙВЪЖЃЌШчКЮФмШУЪєгкЩЬМвЕФЪ§ОнКЯРэЁЂГЄЦкЕФГСЕэЯТРДЃЌвВЪЧSaaSЗўЮёашвЊПМТЧЕФЪТЧщЁЃ
злЩЯЃЌЮвУЧдкЩЯЭМЕФЛљБОФЃЪНЩЯв§ШыСЫЪ§ОнКўФЃЪНЃЌШУЪ§ОнКўзїЮЊЩЬМвГСЕэЪ§ОнЁЂВњГіФЃаЭЁЂЗжЮідЫгЊЕФЛљДЁжЇГХЩшЪЉЁЃв§ШыЪ§ОнКўКѓЕФSaaSЪ§ОнжЧФмЗўЮёФЃЪНШчЯТЁЃ

ЭМ21. ЛљгкЪ§ОнКўЕФЪ§ОнжЧФмЗўЮё
ШчЭМ21ЫљЪОЃЌЦНЬЈЗНЮЊУПИігУЛЇЬсЙЉвЛМќНЈКўЗўЮёЃЌЩЬМвЪЙгУИУЙІФмЙЙНЈздМКЕФЪ§ОнКўЃЌЁАвЛМќНЈКўЁБФмСІвЛЗНУцАяжњЩЬМвНЋЫљгаТёЕуЪ§ОнЕФЪ§ОнФЃаЭЃЈschemaЃЉЭЌВНжСЪ§ОнКўжаЃЛСэвЛЗНУцЃЌНЋЪєгкИУЩЬМвЕФЫљгаТёЕуЪ§ОнШЋСПЭЌВНжСЪ§ОнКўжаЃЌВЂЛљгкЁАT+1ЁБЕФФЃЪНЃЌНЋУПЬьЕФдіСПЪ§ОнЙщЕЕШыКўЁЃЛљгкЪ§ОнКўЕФЗўЮёФЃЪНдкДЋЭГЕФЪ§ОнЗжЮіЗўЮёЕФЛљДЁЩЯЃЌИГгшСЫгУЛЇЪ§ОнзЪВњЛЏЁЂЗжЮіФЃаЭЛЏКЭЗўЮёЖЈжЦЛЏШ§ДѓФмСІЃК
1ЃЉ Ъ§ОнзЪВњЛЏФмСІЁЃРћгУЪ§ОнКўЃЌЩЬМвПЩвдНЋЪєгкздМКЕФЪ§ОнГжајГСЕэЯТРДЃЌБЃДцЖрГЄЪБМфЕФЪ§ОнЃЌКФЗбЖрЩйГЩБОЃЌЭъШЋгЩЩЬМвзджїОіЖЈЁЃЪ§ОнКўЛЙЬсЙЉСЫЪ§ОнзЪВњЙмРэФмСІЃЌЩЬМвГ§СЫФмЙмРэдЪМЪ§ОнЭтЃЌЛЙФмНЋДІРэЙ§ЕФЙ§ГЬЪ§ОнКЭНсЙћЪ§ОнЗжУХБ№РрБЃДцЃЌМЋДѓЕФЬсЩ§СЫТёЕуЪ§ОнЕФМлжЕЁЃ
2ЃЉ ЗжЮіФЃаЭЛЏФмСІЁЃЪ§ОнКўжаВЛНіНігадЪМЪ§ОнЃЌЛЙгаТёЕуЪ§ОнЕФФЃаЭЃЈschemaЃЉЁЃТёЕуЪ§ОнФЃаЭЬхЯжСЫШЋгђЪ§ОнжЧФмЗўЮёЦНЬЈЖдгквЕЮёТпМЕФГщЯѓЃЌЭЈЙ§Ъ§ОнКўЃЌГ§СЫНЋдЪМЪ§ОнзїЮЊзЪВњЪфГіЭтЃЌЛЙНЋЪ§ОнФЃаЭНјааСЫЪфГіЃЌНшжњТёЕуЪ§ОнФЃаЭЃЌЩЬМвПЩвдИќЩюШыЕФРэНтТёЕуЪ§ОнБГКѓЫљЬхЯжЕФгУЛЇааЮЊТпМЃЌАяжњЩЬМвИќКУЕФЖДВьПЭЛЇааЮЊЃЌЛёШЁгУЛЇашЧѓЁЃ
3ЃЉ ЗўЮёЖЈжЦЛЏФмСІЁЃНшжњЪ§ОнКўЬсЙЉЕФЪ§ОнМЏГЩКЭЪ§ОнПЊЗЂФмСІЃЌЛљгкЖдТёЕуЪ§ОнФЃаЭЕФРэНтЃЌЩЬМвПЩвдЖЈжЦЪ§ОнДІРэЙ§ГЬЃЌВЛЖЯЖддЪМЪ§ОнНјааЕќДњМгЙЄЃЌДгЪ§ОнжаЬсСЖгаМлжЕЕФаХЯЂЃЌзюжеЛёЕУГЌдНдгаЪ§ОнЗжЮіЗўЮёЕФМлжЕЁЃ
СљЁЂЪ§ОнКўНЈЩшЕФЛљБОЙ§ГЬ
ИіШЫШЯЮЊЪ§ОнКўЪЧБШДЋЭГДѓЪ§ОнЦНЬЈИќЮЊЭъЩЦЕФДѓЪ§ОнДІРэЛљДЁжЇГХЩшЪЉЃЌЭъЩЦдкЪ§ОнКўЪЧИќЬљНќПЭЛЇвЕЮёЕФММЪѕДцдкЁЃЫљгаЪ§ОнКўЫљАќРЈЕФЁЂЧвГЌГіДѓЪ§ОнЦНЬЈДцдкЕФЬиадЃЌР§ШчдЊЪ§ОнЁЂЪ§ОнзЪВњФПТМЁЂШЈЯоЙмРэЁЂЪ§ОнЩњУќжмЦкЙмРэЁЂЪ§ОнМЏГЩКЭЪ§ОнПЊЗЂЁЂЪ§ОнжЮРэКЭжЪСПЙмРэЕШЃЌЮовЛВЛЪЧЮЊСЫИќКУЕФЬљНќвЕЮёЃЌИќКУЕФЗНБуПЭЛЇЪЙгУЁЃЪ§ОнКўЫљЧПЕїЕФвЛаЉЛљБОЕФММЪѕЬиадЃЌР§ШчЕЏадЁЂДцДЂМЦЫуЖРСЂРЉеЙЁЂЭГвЛЕФДцДЂв§ЧцЁЂЖрФЃЪНМЦЫув§ЧцЕШЕШЃЌвВЪЧЮЊСЫТњзувЕЮёашЧѓЃЌВЂЧвИјвЕЮёЗНЬсЙЉзюОпадМлБШЕФTCOЁЃ
Ъ§ОнКўЕФНЈЩшЙ§ГЬгІИУгывЕЮёНєУмНсКЯЃЛЕЋЪЧЪ§ОнКўЕФНЈЩшЙ§ГЬгыДЋЭГЕФЪ§ОнВжПтЃЌЩѕжСЪЧДѓШШЕФЪ§ОнжаЬЈгІИУЪЧгаЫљЧјБ№ЕФЁЃЧјБ№дкгкЃЌЪ§ОнКўгІИУвдвЛжжИќУєНнЕФЗНЪНШЅЙЙНЈЃЌЁАБпНЈБпгУЃЌБпгУБпжЮРэЁБЁЃЮЊСЫИќКУЕФРэНтЪ§ОнКўНЈЩшЕФУєНнадЃЌЮвУЧЯШРДПДвЛЯТДЋЭГЪ§ВжЕФЙЙНЈЙ§ГЬЁЃвЕНчЖдгкДЋЭГЪ§ВжЕФЙЙНЈЬсГіСЫЁАздЯТЖјЩЯЁБКЭЁАздЖЅЖјЯТЁБСНжжФЃЪНЃЌЗжБ№гЩInmonКЭKimBallСНЮЛДѓХЃЬсГіЁЃОпЬхЕФЙ§ГЬОЭВЛЯъЪіСЫЃЌВЛШЛПЩвддйаДГіМИАйвГЃЌетРяжЛМђЕЅВћЪіЛљБОЫМЯыЁЃ
1ЃЉInmonЬсГіздЯТЖјЩЯЃЈEDW-DMЃЉЕФЪ§ОнВжПтНЈЩшФЃЪНЃЌМДВйзїаЭЛђЪТЮёаЭЯЕЭГЕФЪ§ОндДЃЌЭЈЙ§ETLГщШЁзЊЛЛКЭМгдиЕНЪ§ОнВжПтЕФODSВуЃЛODSВужаЕФЪ§ОнЃЌИљОндЄЯШЩшМЦКУЕФEDWЃЈЦѓвЕМЖЪ§ОнВжПтЃЉЗЖЪННјааМгЙЄДІРэЃЌШЛКѓНјШыЕНEDWЁЃEDWвЛАуЪЧЦѓвЕ/зщжЏЕФЭЈгУЪ§ОнФЃаЭЃЌВЛЗНБуЩЯВугІгУжБНгзіЪ§ОнЗжЮіЃЛвђДЫЃЌИїИівЕЮёВПУХЛсдйДЮИљОнздМКЕФашвЊЃЌДгEDWжаДІРэГіЪ§ОнМЏЪаВуЃЈDMЃЉЁЃ
гХЪЦЃКвзгкЮЌЛЄЃЌИпЖШМЏГЩЃЛСгЪЦЃКНсЙЙвЛЕЉШЗЖЈЃЌСщЛюадВЛзуЃЌЧвЮЊСЫЪЪгІвЕЮёЃЌВПЪ№жмЦкНЯГЄЁЃДЫРрЗНЪНЙЙдьЕФЪ§ВжЃЌЪЪКЯгкБШНЯГЩЪьЮШЖЈЕФвЕЮёЃЌР§ШчН№ШкЁЃ
2ЃЉKimBallЬсГіздЖЅЖјЯТЃЈDM-DWЃЉЕФЪ§ОнМмЙЙЃЌЭЈЙ§НЋВйзїаЭЛђЪТЮёаЭЯЕЭГЕФЪ§ОндДЃЌГщШЁЛђМгдиЕНODSВуЃЛШЛКѓЭЈЙ§ODSЕФЪ§ОнЃЌРћгУЮЌЖШНЈФЃЗНЗЈНЈЩшЖрЮЌжїЬтЪ§ОнМЏЪаЃЈDMЃЉЁЃИїИіDMЃЌЭЈЙ§вЛжТадЕФЮЌЖШСЊЯЕдквЛЦ№ЃЌзюжеаЮГЩЦѓвЕ/зщжЏЭЈгУЕФЪ§ОнВжПтЁЃ
гХЪЦЃКЙЙНЈбИЫйЃЌзюПьЕФПДЕНЭЖзЪЛиБЈТЪЃЌУєНнСщЛюЃЛСгЪЦЃКзїЮЊЦѓвЕзЪдДВЛЬЋКУЮЌЛЄЃЌНсЙЙИДдгЃЌЪ§ОнМЏЪаМЏГЩРЇФбЁЃГЃгІгУгкжааЁЦѓвЕЛђЛЅСЊЭјаавЕЁЃ
ЦфЪЕЩЯЪіжЛЪЧвЛИіРэТлЩЯЕФЙ§ГЬЃЌЦфЪЕЮоТлЪЧЯШЙЙдьEDWЃЌЛЙЪЧЯШЙЙдьDMЃЌЖМРыВЛПЊЖдгкЪ§ОнЕФУўЕзЃЌвдМАдкЪ§ВжЙЙНЈжЎЧАЕФЪ§ОнФЃаЭЕФЩшМЦЃЌАќРЈЕБЧАДѓШШЕФЁАЪ§ОнжаЬЈЁБЃЌЖМЬгВЛГіЯТЭМЫљЪОЕФЛљБОНЈЩшЙ§ГЬЁЃ

ЭМ22. Ъ§ОнВжПт/Ъ§ОнжаЬЈНЈЩшЛљБОСїГЬ
1ЃЉ Ъ§ОнУўЕзЁЃЖдгквЛИіЦѓвЕ/зщжЏЖјбдЃЌдкЙЙНЈЪ§ОнКўГѕЪМЙЄзїОЭЪЧЖдздМКЦѓвЕ/зщжЏФкВПЕФЪ§ОнзівЛИіШЋУцЕФУўЕзКЭЕїбаЃЌАќРЈЪ§ОнРДдДЁЂЪ§ОнРраЭЁЂЪ§ОнаЮЬЌЁЂЪ§ОнФЃЪНЁЂЪ§ОнзмСПЁЂЪ§ОндіСПЕШЁЃдкетИіНзЖЮвЛИівўКЌЕФживЊЙЄзїЪЧНшжњЪ§ОнУўЕзЙЄзїЃЌНјвЛВНЪсРэЦѓвЕЕФзщжЏНсЙЙЃЌУїШЗЪ§ОнКЭзщжЏНсЙЙжЎМфЙиЯЕЁЃЮЊКѓајУїШЗЪ§ОнКўЕФгУЛЇНЧЩЋЁЂШЈЯоЩшМЦЁЂЗўЮёЗНЪНЕьЖЈЛљДЁЁЃ
2ЃЉ ФЃаЭГщЯѓЁЃеыЖдЦѓвЕ/зщжЏЕФвЕЮёЬиЕуЪсРэЙщРрИїРрЪ§ОнЃЌЖдЪ§ОнНјааСьгђЛЎЗжЃЌаЮГЩЪ§ОнЙмРэЕФдЊЪ§ОнЃЌЭЌЪБЛљгкдЊЪ§ОнЃЌЙЙНЈЭЈгУЕФЪ§ОнФЃаЭЁЃ
3ЃЉ Ъ§ОнНгШыЁЃИљОнЕквЛВНЕФУўХХНсЙћЃЌШЗЖЈвЊНгШыЕФЪ§ОндДЁЃИљОнЪ§ОндДЃЌШЗЖЈЫљБиаыЕФЪ§ОнНгШыММЪѕФмСІЃЌЭъГЩЪ§ОнНгШыММЪѕбЁаЭЃЌНгШыЕФЪ§ОнжСЩйАќРЈЃКЪ§ОндДдЊЪ§ОнЁЂдЪМЪ§ОндЊЪ§ОнЁЂдЪМЪ§ОнЁЃИїРрЪ§ОнАДееЕкЖўВНаЮГЩЕФНсЙћЃЌЗжРрДцЗХЁЃ
4ЃЉ ШкКЯжЮРэЁЃМђЕЅРДЫЕОЭЪЧРћгУЪ§ОнКўЬсЙЉЕФИїРрМЦЫув§ЧцЖдЪ§ОнНјааМгЙЄДІРэЃЌаЮГЩИїРржаМфЪ§Он/НсЙћЪ§ОнЃЌВЂЭзЩЦЙмРэБЃДцЁЃЪ§ОнКўгІИУОпБИЭъЩЦЕФЪ§ОнПЊЗЂЁЂШЮЮёЙмРэЁЂШЮЮёЕїЖШЕФФмСІЃЌЯъЯИМЧТМЪ§ОнЕФДІРэЙ§ГЬЁЃдкжЮРэЕФЙ§ГЬжаЃЌЛсашвЊИќЖрЕФЪ§ОнФЃаЭКЭжИБъФЃаЭЁЃ
5ЃЉ вЕЮёжЇГХЁЃдкЭЈгУФЃаЭЛљДЁЩЯЃЌИїИівЕЮёВПУХЖЈжЦздМКЕФЯИЛЏЪ§ОнФЃаЭЁЂЪ§ОнЪЙгУСїГЬЁЂЪ§ОнЗУЮЪЗўЮёЁЃ
ЩЯЪіЙ§ГЬЃЌЖдгквЛИіПьЫйГЩГЄЕФЛЅСЊЭјЦѓвЕРДЫЕЃЌЬЋжиСЫЃЌКмЖрЧщПіЯТЪЧЮоЗЈТфЕиЕФЃЌзюЯжЪЕЕФЮЪЬтОЭЪЧЕкЖўВНФЃаЭГщЯѓЃЌКмЖрЧщПіЯТЃЌвЕЮёЪЧдкЪдДэЁЂдкЬНЫїЃЌИљБОВЛЧхГўЮДРДЕФЗНЯђдкФФРяЃЌвВОЭИљБОВЛПЩФмЬсСЖГіЭЈгУЕФЪ§ОнФЃаЭЃЛУЛгаЪ§ОнФЃаЭЃЌКѓУцЕФвЛЧаВйзївВОЭЮоДгЬИЦ№ЃЌетвВЪЧКмЖрИпЫйГЩГЄЕФЦѓвЕОѕЕУЪ§ОнВжПт/Ъ§ОнжаЬЈЮоЗЈТфЕиЁЂЮоЗЈТњзуашЧѓЕФживЊдвђжЎвЛЁЃ
Ъ§ОнКўгІИУЪЧвЛжжИќЮЊЁАУєНнЁБЕФЙЙНЈЗНЪНЃЌЮвУЧНЈвщВЩгУШчЯТВНжшРДЙЙНЈЪ§ОнКўЁЃ

ЭМ23. Ъ§ОнКўНЈЩшЛљБОСїГЬ
ЖдБШЭМ22ЃЌвРШЛЪЧЮхВНЃЌЕЋЪЧетЮхВНЪЧвЛИіШЋУцЕФМђЛЏКЭЁАПЩТфЕиЁБЕФИФНјЁЃ
1ЃЉ Ъ§ОнУўЕзЁЃвРШЛашвЊУўЧхГўЪ§ОнЕФЛљБОЧщПіЃЌАќРЈЪ§ОнРДдДЁЂЪ§ОнРраЭЁЂЪ§ОнаЮЬЌЁЂЪ§ОнФЃЪНЁЂЪ§ОнзмСПЁЂЪ§ОндіСПЁЃЕЋЪЧЃЌвВОЭашвЊзіетУДЖрСЫЁЃЪ§ОнКўЪЧЖддЪМЪ§ОнзіШЋСПБЃДцЃЌвђДЫЮоашЪТЯШНјааЩюВуДЮЕФЩшМЦЁЃ
2ЃЉ ММЪѕбЁаЭЁЃИљОнЪ§ОнУўЕзЕФЧщПіЃЌШЗЖЈЪ§ОнКўНЈЩшЕФММЪѕбЁаЭЁЃЪТЪЕЩЯЃЌетвЛВНвВЗЧГЃЕФМђЕЅЃЌвђЮЊЙигкЪ§ОнКўЕФММЪѕбЁаЭЃЌвЕНчгаКмЖрЕФЭЈааЕФзіЗЈЃЌЛљБОддђИіШЫНЈвщгаШ§ИіЃКЁАМЦЫугыДцДЂЗжРыЁБЁЂЁАЕЏадЁБЁЂЁАЖРСЂРЉеЙЁБЁЃНЈвщЕФДцДЂбЁаЭЪЧЗжВМЪНЖдЯѓДцДЂЯЕЭГЃЈШчS3/OSS/OBSЃЉЃЛМЦЫув§ЧцЩЯНЈвщжиЕуПМТЧХњДІРэашЧѓКЭSQLДІРэФмСІЃЌвђЮЊдкЪЕМљжаЃЌетСНРрФмСІЪЧЪ§ОнДІРэЕФЙиМќЃЌЙигкСїМЦЫув§ЧцКѓУцЛсдйЬжТлвЛЯТЁЃЮоТлЪЧМЦЫуЛЙЪЧДцДЂЃЌНЈвщгХЯШПМТЧserverlessЕФаЮЪНЃЛКѓајПЩвддкгІгУжаж№ВНбнНјЃЌецЕФашвЊЖРСЂзЪдДГиСЫЃЌдйПМТЧЙЙНЈзЈЪєМЏШКЁЃ
3ЃЉ Ъ§ОнНгШыЁЃШЗЖЈвЊНгШыЕФЪ§ОндДЃЌЭъГЩЪ§ОнЕФШЋСПГщШЁгыдіСПНгШыЁЃ
4ЃЉ гІгУжЮРэЁЃетвЛВНЪЧЪ§ОнКўЕФЙиМќЃЌЮвИіШЫАбЁАШкКЯжЮРэЁБИФГЩСЫЁАгІгУжЮРэЁБЁЃДгЪ§ОнКўЕФНЧЖШРДПДЃЌЪ§ОнгІгУКЭЪ§ОнжЮРэгІИУЪЧЯрЛЅШкКЯЁЂУмВЛПЩЗжЕФЁЃДгЪ§ОнгІгУШыЪжЃЌдкгІгУжаУїШЗашЧѓЃЌдкЪ§ОнETLЕФЙ§ГЬжаЃЌж№ВНаЮГЩвЕЮёПЩЪЙгУЕФЪ§ОнЃЛЭЌЪБаЮГЩЪ§ОнФЃаЭЁЂжИБъЬхЯЕКЭЖдгІЕФжЪСПБъзМЁЃЪ§ОнКўЧПЕїЖддЪМЪ§ОнЕФДцДЂЃЌЧПЕїЖдЪ§ОнЕФЬНЫїЪНЗжЮігыгІгУЃЌЕЋетОјЖдВЛЪЧЫЕЪ§ОнКўВЛашвЊЪ§ОнФЃаЭЃЛЧЁЧЁЯрЗДЃЌЖдвЕЮёЕФРэНтгыГщЯѓЃЌНЋМЋДѓЕФЭЦЖЏЪ§ОнКўЕФЗЂеЙгыгІгУЃЌЪ§ОнКўММЪѕЪЙЕУЪ§ОнЕФДІРэгыНЈФЃЃЌБЃСєСЫМЋДѓЕФУєНнадЃЌФмПьЫйЪЪгІвЕЮёЕФЗЂеЙгыБфЛЏЁЃ
ДгММЪѕЪгНЧРДПДЃЌЪ§ОнКўВЛЭЌгкДѓЪ§ОнЦНЬЈЛЙдкгкЪ§ОнКўЮЊСЫжЇГХЪ§ОнЕФШЋЩњУќжмЦкЙмРэгыгІгУЃЌашвЊОпБИЯрЖдЭъЩЦЕФЪ§ОнЙмРэЁЂРрФПЙмРэЁЂСїГЬБрХХЁЂШЮЮёЕїЖШЁЂЪ§ОнЫндДЁЂЪ§ОнжЮРэЁЂжЪСПЙмРэЁЂШЈЯоЙмРэЕШФмСІЁЃдкМЦЫуФмСІЩЯЃЌФПЧАжїСїЕФЪ§ОнКўЗНАИЖМжЇГжSQLКЭПЩБрГЬЕФХњДІРэСНжжФЃЪНЃЈЖдЛњЦїбЇЯАЕФжЇГжЃЌПЩвдВЩгУSparkЛђепFlinkЕФФкжУФмСІЃЉЃЛдкДІРэЗЖЪНЩЯЃЌМИКѕЖМВЩгУЛљгкгаЯђЮоЛЗЭМЕФЙЄзїСїЕФФЃЪНЃЌВЂЬсЙЉСЫЖдгІЕФМЏГЩПЊЗЂЛЗОГЁЃЖдгкСїЪНМЦЫуЕФжЇГжЃЌФПЧАИїИіЪ§ОнКўНтОіЗНАИВЩШЁСЫВЛЭЌЕФЗНЪНЁЃдкЬжТлОпЬхЕФЗНЪНжЎЧАЃЌЮвУЧЯШЖдСїМЦЫузівЛИіЗжРрЃК
1ЃЉ ФЃЪНвЛЃКЪЕЪБФЃЪНЁЃетжжСїМЦЫуФЃЪНЯрЕБгкЖдЪ§ОнВЩгУЁАРДвЛЬѕДІРэвЛЬѕЁБ/ЁАЮЂХњЁБЕФЗНЪННјааДІРэЃЛЖрМћгкдкЯпвЕЮёЃЌШчЗчПиЁЂЭЦМіЁЂдЄОЏЕШЁЃ
2ЃЉ ФЃЪНЖўЃКРрСїЪНЁЃетжжФЃЪНашвЊЛёШЁжИЖЈЪБМфЕужЎКѓБфЛЏЕФЪ§Он/ЖСШЁФГвЛИіАцБОЕФЪ§Он/ЖСШЁЕБЧАЕФзюаТЪ§ОнЕШЃЌЪЧвЛжжРрСїЪНЕФФЃЪНЃЛЖрМћгкЪ§ОнЬНЫїРргІгУЃЌШчЗжЮіФГвЛЪБМфЖЮФкЕФШеЛюЁЂСєДцЁЂзЊЛЏЕШЁЃ
ЖўепЕФБОжЪВЛЭЌдкгкЃЌФЃЪНвЛДІРэЪ§ОнЪБЃЌЪ§ОнЭљЭљЛЙУЛгаДцДЂЕНЪ§ОнКўжаЃЌНіНіЪЧдкЭјТЗ/ФкДцжаСїЖЏЃЛФЃЪНЖўДІРэЪ§ОнЪБЃЌЪ§ОнвбОДцДЂЕНЪ§ОнКўжаСЫЁЃзлЩЯЃЌЮвИіШЫНЈвщВЩгУШчЯТЭМФЃЪНЃК
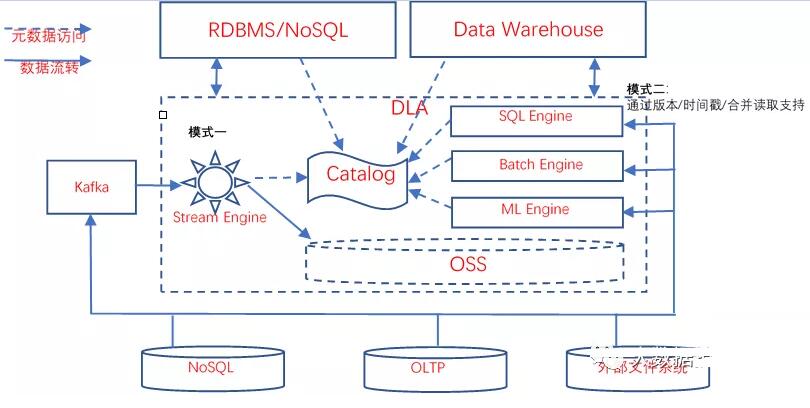
ЭМ24 Ъ§ОнКўЪ§ОнСїЯђЪОвтЭМ
ШчЭМ24ЫљЪОЃЌдкашвЊЪ§ОнКўОпБИФЃЪНвЛЕФДІРэФмСІЪБЃЌЛЙЪЧгІИУв§ШыРрKafkaжаМфМўЃЌзїЮЊЪ§ОнзЊЗЂЕФЛљДЁЩшЪЉЁЃЭъећЕФЪ§ОнКўНтОіЗНАИЗНАИгІИУЬсЙЉНЋдЪМЪ§ОнЕМСїжСKafkaЕФФмСІЁЃСїЪНв§ЧцОпБИДгРрKafkaзщМўжаЖСШЁЪ§ОнЕФФмСІЁЃСїЪНМЦЫув§ЧцдкДІРэЪ§ОнЙ§КѓЃЌИљОнашвЊЃЌПЩвдНЋНсЙћаДШыOSS/RDBMS/NoSQL/DWЃЌЙЉгІгУЗУЮЪЁЃФГжжвтвхЩЯЃЌФЃЪНвЛЕФСїМЦЫув§ЧцВЂЗЧвЛЖЈвЊзїЮЊЪ§ОнКўВЛПЩЗжИюЕФвЛВПЗжДцдкЃЌжЛашвЊдкгІгУашвЊЪБЃЌФмЙЛЗНБуЕФв§ШыМДПЩЁЃЕЋЪЧЃЌетРяашвЊжИГіЕФЪЧЃК
1ЃЉСїЪНв§ЧцвРШЛашвЊФмЙЛКмЗНБуЕФЖСШЁЪ§ОнКўЕФдЊЪ§ОнЃЛ
2ЃЉСїЪНв§ЧцШЮЮёвВашвЊЭГвЛЕФФЩШыЪ§ОнКўЕФШЮЮёЙмРэЃЛ
3ЃЉСїЪНДІРэШЮЮёвРШЛашвЊФЩШыЕНЭГвЛЕФШЈЯоЙмРэжаЁЃ
ЖдгкФЃЪНЖўЃЌБОжЪЩЯИќНгНќгкХњДІРэЁЃЯждкаэЖрОЕфЕФДѓЪ§ОнзщМўвбОЬсЙЉСЫжЇГжЗНЪНЃЌШчHUDI/IceBerg/DeltaЕШЃЌОљжЇГжSparkЁЂPrestoЕШОЕфЕФМЦЫув§ЧцЁЃвдHUDIЮЊР§ЃЌЭЈЙ§жЇГжЬиЪтРраЭЕФБэЃЈCOW/MORЃЉЃЌЬсЙЉЗУЮЪПьееЪ§ОнЃЈжИЖЈАцБОЃЉЁЂдіСПЪ§ОнЁЂзМЪЕЪБЪ§ОнЕФФмСІЁЃФПЧАAWSЁЂЬкбЖЕШвбОНЋHUDIМЏГЩЕНСЫЦфEMRЗўЮёжаЃЌАЂРядЦЕФDLAвВе§дкМЦЛЎЭЦГіDLA
on HUDIЕФФмСІЁЃ
ШУЮвУЧдйЛиЕНБОЮФПЊЭЗЕФЕквЛеТЃЌЮвУЧЫЕЙ§ЃЌЪ§ОнКўЕФжївЊгУЛЇЪЧЪ§ОнПЦбЇМвКЭЪ§ОнЗжЮіЪІЃЌЬНЫїЪНЗжЮіКЭЛњЦїбЇЯАЪЧетРрШЫШКЕФГЃМћВйзїЃЛСїЪНМЦЫуЃЈЪЕЪБФЃЪНЃЉЖргУгкдкЯпвЕЮёЃЌбЯИёРДПДЃЌВЂЗЧЪ§ОнКўФПБъгУЛЇЕФИеашЁЃЕЋЪЧЃЌСїЪНМЦЫуЃЈЪЕЪБФЃЪНЃЉЪЧФПЧАДѓЖрЪ§ЛЅСЊЭјЙЋЫОдкЯпвЕЮёЕФживЊзщГЩВПЗжЃЌЖјЪ§ОнКўзїЮЊЦѓвЕ/зщжЏФкВПЕФЪ§ОнМЏжаДцЗХЕиЃЌашвЊдкМмЙЙЩЯБЃГжвЛЖЈЕФРЉеЙФмСІЃЌПЩвдКмЗНБуЕФНјааРЉеЙЃЌећКЯСїЪНМЦЫуФмСІЁЃ
5ЃЉ вЕЮёжЇГХЁЃЫфШЛДѓЖрЪ§Ъ§ОнКўНтОіЗНАИЖМЖдЭтЬсЙЉБъзМЕФЗУЮЪНгПкЃЌШчJDBCЃЌЪаУцЩЯСїааЕФИїРрBIБЈБэЙЄОпЁЂДѓЦСЙЄОпвВЖМПЩвджБНгЗУЮЪЪ§ОнКўжаЕФЪ§ОнЁЃЕЋЪЧдкЪЕМЪЕФгІгУжаЃЌЮвУЧЛЙЪЧНЈвщНЋЪ§ОнКўДІРэКУЕФЪ§ОнЭЦЫЭЕНЖдгІЕФИїРржЇГждкЯпвЕЮёЕФЪ§Онв§ЧцжаШЅЃЌФмЙЛШУгІгУгаИќКУЕФЬхбщЁЃ
ЦпЁЂзмНс
Ъ§ОнКўзїЮЊаТвЛДњДѓЪ§ОнЗжЮіДІРэЕФЛљДЁЩшЪЉЃЌашвЊГЌдНДЋЭГЕФДѓЪ§ОнЦНЬЈЁЃИіШЫШЯЮЊФПЧАдквдЯТЗНУцЃЌЪЧЪ§ОнКўНтОіЗНАИЮДРДПЩФмЕФЗЂеЙЗНЯђЁЃ
1ЃЉ дЦдЩњМмЙЙЁЃЙигкЪВУДЪЧдЦдЩњМмЙЙЃЌжкЫЕЗзчЁЃЌКмФбевЕНЭГвЛЕФЖЈвхЁЃЕЋЪЧОпЬхЕНЪ§ОнКўетИіГЁОАЃЌИіШЫШЯЮЊОЭЪЧвдЯТШ§ЕуЬиеїЃКЃЈ1ЃЉДцДЂКЭМЦЫуЗжРыЃЌМЦЫуФмСІКЭДцДЂФмСІОљПЩЖРСЂРЉеЙЃЛЃЈ2ЃЉЖрФЃЬЌМЦЫув§ЧцжЇГжЃЌSQLЁЂХњДІРэЁЂСїЪНМЦЫуЁЂЛњЦїбЇЯАЕШЃЛЃЈ3ЃЉЬсЙЉserverlessЬЌЗўЮёЃЌШЗБЃзуЙЛЕФЕЏадвдМАжЇГжАДашИЖЗбЁЃ
2ЃЉ зуЙЛгУЕФЪ§ОнЙмРэФмСІЁЃЪ§ОнКўашвЊЬсЙЉИќЮЊЧПДѓЕФЪ§ОнЙмРэФмСІЃЌАќРЈЕЋВЛЯогкЪ§ОндДЙмРэЁЂЪ§ОнРрФПЙмРэЁЂДІРэСїГЬБрХХЁЂШЮЮёЕїЖШЁЂЪ§ОнЫндДЁЂЪ§ОнжЮРэЁЂжЪСПЙмРэЁЂШЈЯоЙмРэЕШЁЃ
3ЃЉ ДѓЪ§ОнЕФФмСІЃЌЪ§ОнПтЕФЬхбщЁЃФПЧАОјДѓЖрЪ§Ъ§ОнЗжЮіШЫдБЖМжЛгаЪ§ОнПтЕФЪЙгУОбщЃЌДѓЪ§ОнЦНЬЈЕФФмСІЫфЧПЃЌЕЋЪЧЖдгкгУЛЇРДЫЕВЂВЛгбКУЃЌЪ§ОнПЦбЇМвКЭЪ§ОнЪ§ОнЗжЮіЪІгІИУЙизЂЪ§ОнЁЂЫуЗЈЁЂФЃаЭМАЦфгывЕЮёГЁОАЕФЪЪХфЃЌЖјВЛЪЧЛЈДѓСПЕФЪБМфОЋСІШЅбЇЯАДѓЪ§ОнЦНЬЈЕФПЊЗЂЁЃЪ§ОнКўвЊЯыПьЫйЗЂеЙЃЌШчКЮЮЊгУЛЇЬсЙЉСМКУЕФЪЙгУЬхбщЪЧЙиМќЁЃЛљгкSQLЕФЪ§ОнПтгІгУПЊЗЂвбОЩюШыШЫаФЃЌШчКЮНЋЪ§ОнКўЕФФмСІЭЈЙ§SQLЕФаЮЪНЪЭЗХГіРДЃЌЪЧЮДРДЕФвЛИіжївЊЗНЯђЁЃ
4ЃЉ ЭъЩЦЕФЪ§ОнМЏГЩгыЪ§ОнПЊЗЂФмСІЁЃЖдИїжжвьЙЙЪ§ОндДЕФЙмРэгыжЇГжЃЌЖдвьЙЙЪ§ОнЕФШЋСП/діСПЧЈвЦжЇГжЃЌЖдИїжжЪ§ОнИёЪНЕФжЇГжЖМЪЧашвЊВЛЖЯЭъЩЦЕФЗНЯђЁЃЭЌЪБЃЌашвЊОпБИвЛИіЭъБИЕФЁЂПЩЪгЛЏЕФЁЂПЩРЉеЙЕФМЏГЩПЊЗЂЛЗОГЁЃ
5ЃЉ гывЕЮёЕФЩюЖШШкКЯгыМЏГЩЁЃЕфаЭЪ§ОнКўМмЙЙЕФЙЙГЩЛљБОвбОГЩЮЊСЫвЕНчЙВЪЖЃКЗжВМЪНЖдЯѓДцДЂ+ЖрФЃЬЌМЦЫув§Чц+Ъ§ОнЙмРэЁЃОіЖЈЪ§ОнКўЗНАИЪЧЗёЪЄГіЕФЙиМќЧЁЧЁдкгкЪ§ОнЙмРэЃЌЮоТлЪЧдЪМЪ§ОнЕФЙмРэЁЂЪ§ОнРрФПЕФЙмРэЁЂЪ§ОнФЃаЭЕФЙмРэЁЂЪ§ОнШЈЯоЕФЙмРэЛЙЪЧДІРэШЮЮёЕФЙмРэЃЌЖМРыВЛПЊгывЕЮёЕФЪЪХфКЭМЏГЩЃЛЮДРДЃЌЛсгадНРДдНЖрЕФаавЕЪ§ОнКўНтОіЗНАИгПЯжГіРДЃЌгыЪ§ОнПЦбЇМвКЭЪ§ОнЗжЮіЪІаЮГЩСМадЗЂеЙгыЛЅЖЏЁЃШчКЮдкЪ§ОнКўНтОіЗНАИжадЄжУаавЕЪ§ОнФЃаЭЁЂETLСїГЬЁЂЗжЮіФЃаЭКЭЖЈжЦЫуЗЈЃЌПЩФмЪЧЮДРДЪ§ОнКўСьгђВювьЛЏОКељЕФвЛИіЙиМќЕуЁЃ
|





