| 编辑推荐: |
本文主要介绍了使用 Flink Hudi 构建流式数据湖平台,主要包括: Apache
Hudi 101 、Flink Hudi Integration 、Flink
Hudi Use Case、 Apache Hudi Roadmap, 希望对你的学习有帮助。
本文来自于淘嘟嘟,由Linda编辑、推荐。 |
|
一、Apache Hudi 101
提到数据湖,大家都会有这样的疑问,什么是数据湖?为什么数据湖近两年热度很高?数据湖其实不是一个新的概念,最早的数据湖概念在
80 年代就已经提出,当时对数据湖的定义是原始数据层,可以存放各种结构化、半结构化甚至非结构化的数据。像机器学习、实时分析等很多场景都是在查询的时候确定数据的
Schema。

湖存储成本低、灵活性高的特性,非常适用于做查询场景的中心化存储。伴随着近年来云服务的兴起,尤其是对象存储的成熟,越来越多的企业选择在云上构建存储服务。数据湖的存算分离架构非常适合当前的云服务架构,通过快照隔离的方式,提供基础的
acid 事务,同时支持对接多种分析引擎适配不同的查询场景,可以说湖存储在成本和开放性上占了极大优势。

当前的湖存储已经开始承担数仓的功能,通过和计算引擎对接实现湖仓一体的架构。湖存储是一种 table
format,在原有的 data format 基础上封装了 table 的高级语义。Hudi 从
2016 年开始将数据湖投入实践,当时是为了解决大数据场景下文件系统上的数据更新问题,Hudi 类
LSM 的 table format 当前在湖格式中是独树一帜的,对近实时更新比较友好,语义也相对完善。
Table format 是当前流行的三种数据湖格式的基础属性,而 Hudi 从项目之初就一直朝着平台方向去演化,拥有比较完善的数据治理和
table service,比如用户在写入的时候可以并发地优化文件的布局,metadata table
可以大幅优化写入时查询端的文件查找效率。
下面介绍一些 Hudi 的基础概念。
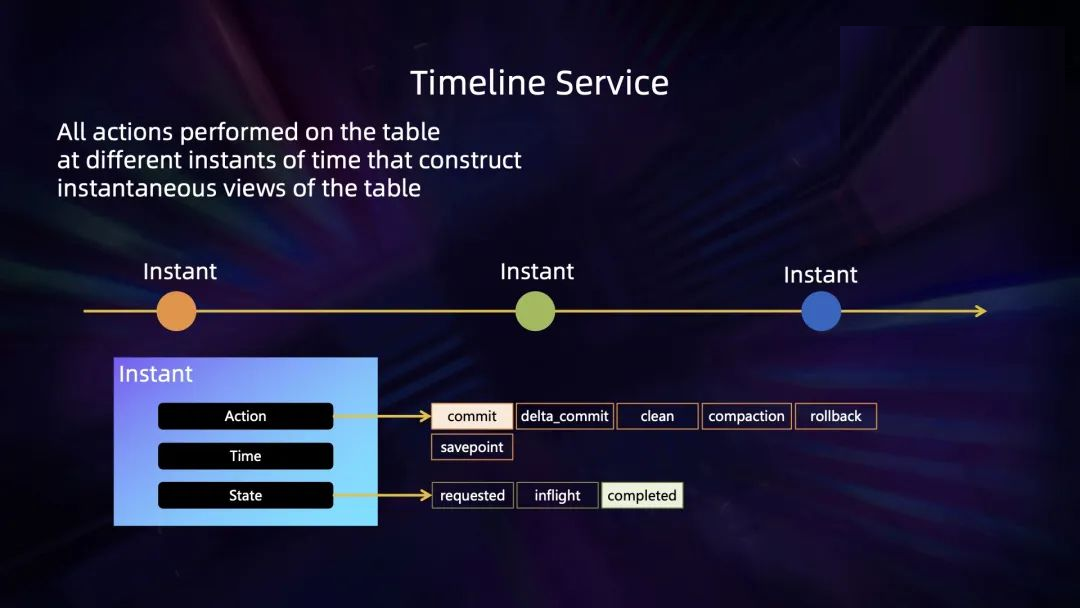
Timeline service 是 Hudi 事务层的核心抽象,Hudi 所有数据操作都是围绕着
timeline service 来展开的,每次操作通过 instant 抽象绑定一个特定的时间戳,一连串的
instant 构成了 timeline service,每一个 instance 记录了对应的 action
和状态。通过 timeline service,Hudi 可以知道当前表操作的状态,通过一套文件系统视图的抽象结合
timeline service,可以对 table 当前的 reader 和 writer 暴露特定时间戳下的文件布局视图。

file group 是 Hudi 在文件布局层的核心抽象,每一个 file group 相当于一个
bucket,通过文件大小来来划分,它的每次写入行为都会产生一个新的版本,一个版本被抽象为一个 file
slice,file slice 内部维护了相应版本的数据文件。当一个 file group 写入到规定的文件大小的时候,就会切换一个新的
file group。
Hudi 在 file slice 的写入行为可以抽象成两种语义, copy on write 和
merge on read。

copy on write 每次都会写全量数据,新数据会和上一个 file slice 的数据 merge,然后再写一个新的
file slice,产生一个新的 bucket 的文件。
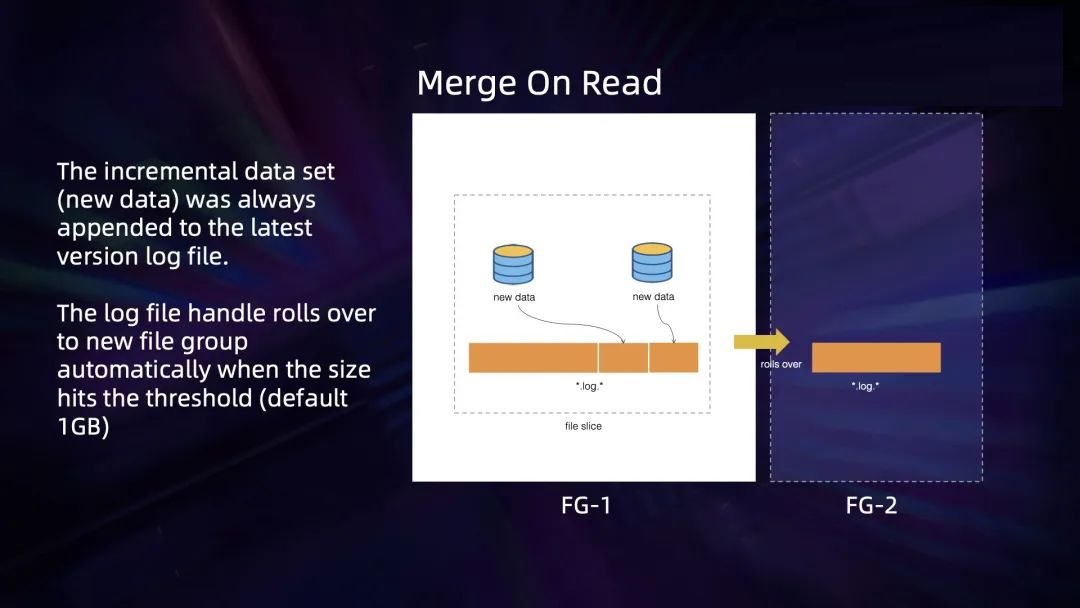
而 merge on read 则比较复杂一些,它的语义是追加写入,即每次只写增量数据,所以不会写新的
file slice。它首先会尝试追加之前的 file slice,只有当该写入的 file slice
被纳入压缩计划之后,才会切新的 file slice。
二、Flink Hudi Integration
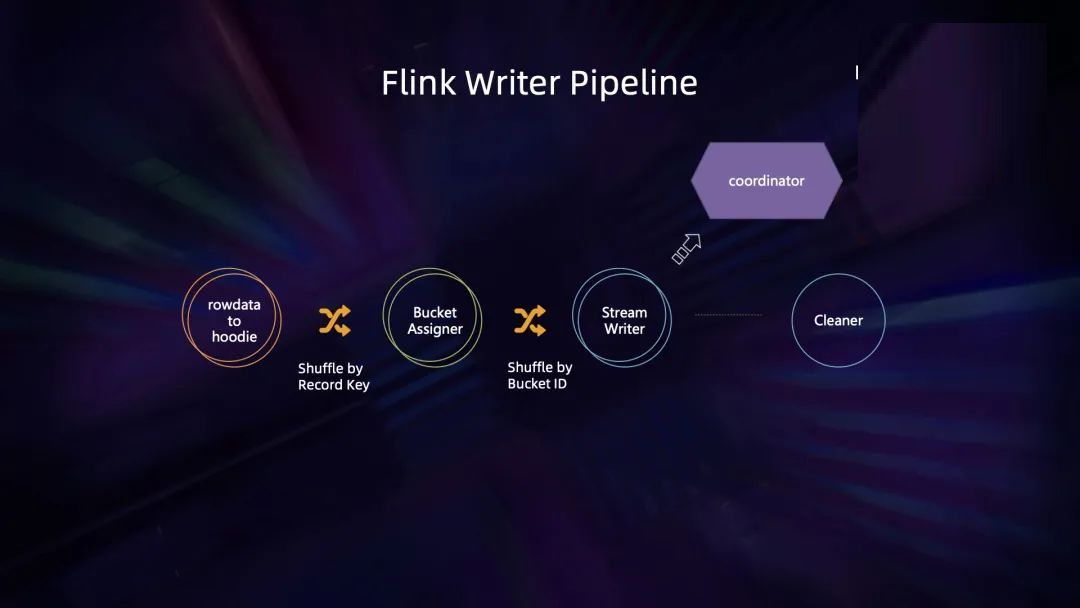
Flink Hudi 的写入 pipeline 由几个算子构成。第一个算子负责将 table 层的
rowdata 转换成 Hudi 的消息格式 HudiRecord。接着经过一个 Bucket Assigner,它主要负责将已经转好的
HudiRecord 分配到特定的 file group 中,接着分好 file group 的 record
会流入 Writer 算子执行真正的文件写入。最后还有一个 coordinator,负责 Hudi
table 层的 table service 调度以及新事务的发起和提交。此外,还有一些后台的清理角色负责清理老版本的数据。
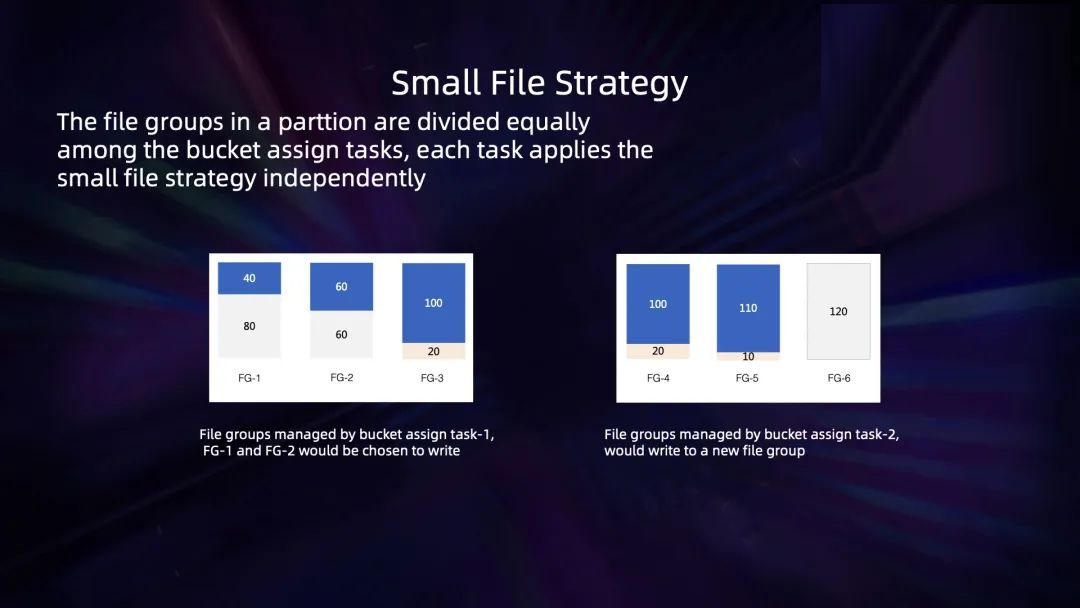
当前的设计中,每一个 bucket assign task 都会持有一个 bucket assigner,它独立维护自己的一组
file group。在写入新数据或非更新 insert 数据的时候,bucket assign task
会扫描文件视图,优先将这一批新的数据写入到被判定为小 bucket 的 file group 里。
比如上图, file group 默认大小是 120M,那么左图的 task1 会优先写到 file
group1和 file group2,注意这里不会写到 file group3,这是因为 file
group3 已经有 100M 数据,对于比较接近目标阈值的 bucket 不再写入可以避免过度写放大。而右图中的
task2 会直接写一个新的 file group,不会去追加那些已经写的比较大的 file group
了。
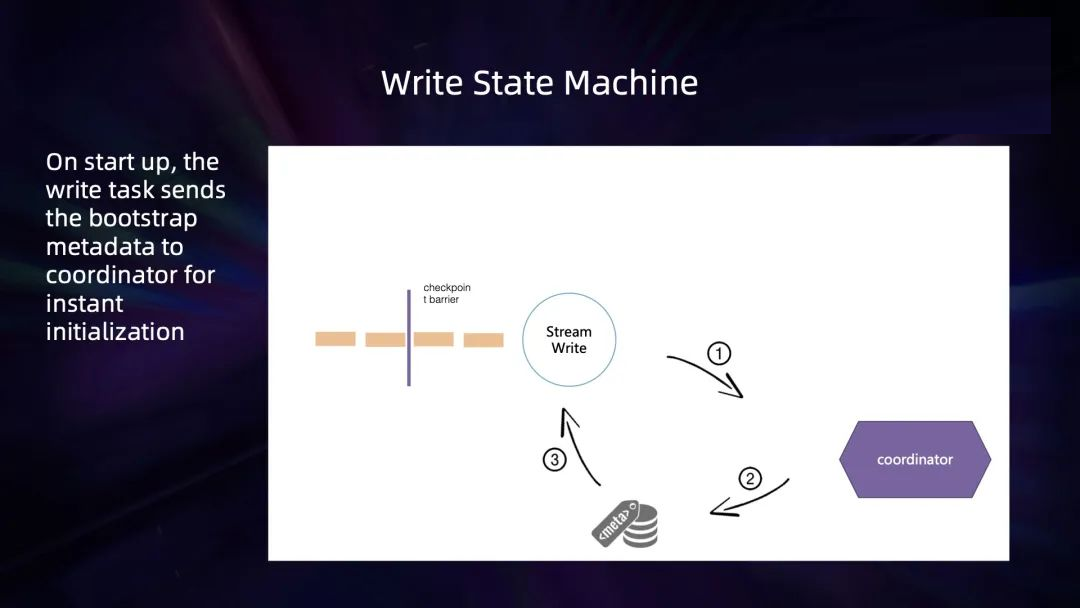
接下来介绍 Flink Hudi 写流程的状态切换机制。作业刚启动时,coordinator 会先尝试去文件系统上新建这张表,如果当前表不存在,它就会去文件目录上写一些
meta 信息,也就是构建一个表。收到所有 task 的初始化 meta 信息后,coordinator
会开启一个新的 transaction,write task 看到 transaction 的发起后,就会解锁当前数据的
flush 行为。
Write Task 会先积攒一批数据,这里有两种 flush 策略,一种是当前的数据 buffer
达到了指定的大小,就会把内存中的数据 flush 出去;另一种是当上游的 checkpoint barrier
到达需要做快照的时候,会把所有内存中的数据 flush 到磁盘。每次 flush 数据之后都会把 meta
信息发送给 coordinator。coordinator 收到 checkpoint 的 success
事件后,会提交对应的事务,并且发起下一个新的事务。writer task 看到新事务后,又会解锁下一轮事务的写入。这样,整个写入流程就串起来了。

Flink Hudi Write 提供了非常丰富的写入场景。当前支持对 log 数据类型的写入,即非更新的数据类型,同时支持小文件合并。另外对于
Hudi 的核心写入场景比如更新流、CDC 数据也都是 Hudi 重点支持的。同时,Flink Hudi
还支持历史数据的高效率批量导入,bucket insert 模式可以一次性将比如 Hive 中的离线数据或者数据库中的离线数据,通过批量查询的方式,高效导入
Hudi 格式中。另外,Flink Hudi 还提供了全量和增量的索引加载,用户可以一次性将批量数据高效导入湖格式,再通过对接流的写入程序,实现全量接增量的数据导入。

Flink Hudi read 端也支持了非常丰富的查询视图,目前主要支持的有全量读取、历史时间
range 的增量读取以及流式读取。

上图是一段通过 Flink sql 写 Hudi 的例子,Hudi 支持的 use case 非常丰富,也尽量简化了用户需要配置的参数。通过简单配置表
path、 并发以及 operation type,用户可以非常方便地将上游的数据写入到 Hudi
格式中。
三、Flink Hudi Use Case
下面介绍 Flink Hudi 的经典应用场景。

第一个经典场景是 DB 导入数据湖。目前 DB 数据导入数据湖有两种方式:可以通过 CDC connector
一次性将全量和增量数据导入到 Hudi 格式中;也可以通过消费 Kafka 上的 CDC changelog,通过
Flink 的 CDC format 将数据导入到 Hudi 格式。

第二个经典场景是流计算的 ETL (近实时的 olap 分析)。通过对接上游流计算简单的一些 ETL,比如双流
join 或双流 join 接一个 agg,直接将变更流写入到 Hudi 格式中,然后下游的 read
端可以对接传统经典的 olap 引擎比如 presto、spark 来做端到端的近实时查询。
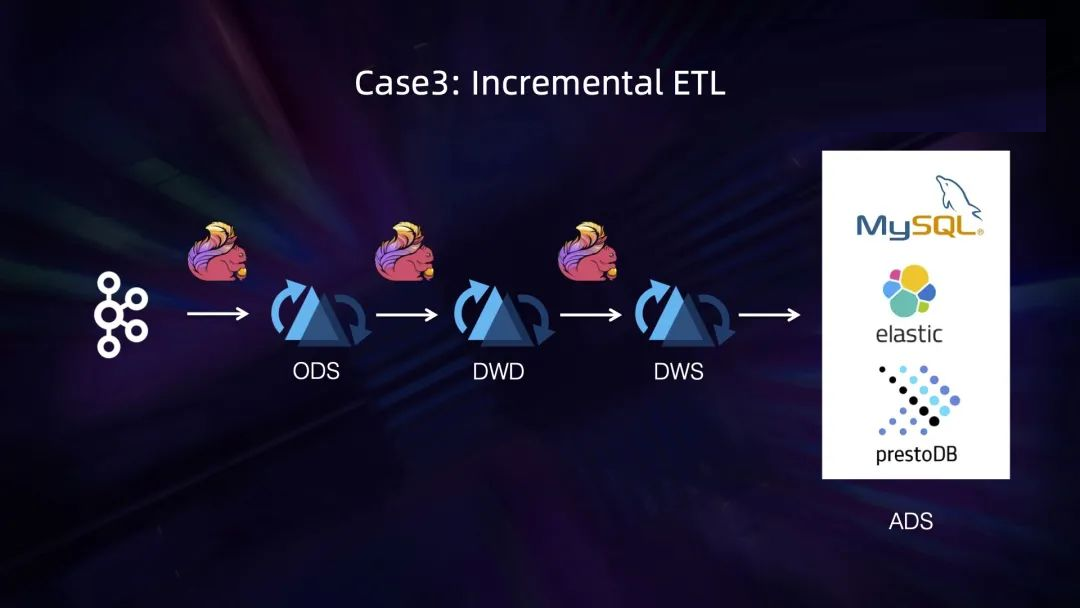
第三个经典场景和第二个有些类似, Hudi 支持原生的 changelog,也就是支持保存 Flink
计算中行级别的变更。基于这个能力,通过流读消费变更的方式,可以实现端到端的近实时的 ETL 生产。

未来,社区两个大版本主要的精力还是放在流读和流写方向,并且会加强流读的语义;另外在 catalog
和 metadata 方面会做自管理;我们还会在近期推出一个 trino 原生的 connector
支持,取代当前读 Hive 的方式,提高效率。
四、Apache Hudi Roadmap
下面是一个 MySql 到 Hudi 千表入湖的演示。
首先数据源这里我们准备了两个库,benchmark1 和 benchmark2,benchmark1
下面有 100 张表,benchmark2 下面有 1000 张表。因为千表入湖强依赖于 catalog,所以我们首先要创建
catalog,对于数据源我们要创建 MySql catalog,对于目标我们要创建 Hudi catalog。MySql
catalog 用于获取所有源表相关的信息,包括表结构、表的数据等。Hudi catalog 用于创建目标。

执行两条 sql 语句以后,两条 catalog 就创建成功了。
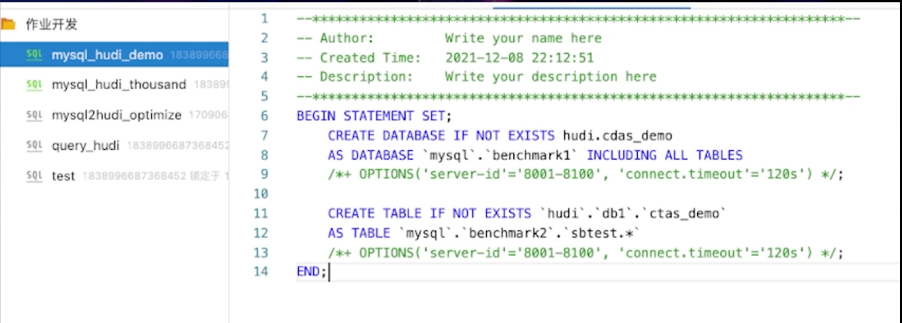
接下来到作业开发页面创建一个千表入湖的作业。只需要简单的 9 行 SQL,第一种语法是 create
database as database,它的作用是把 MySql benchmark1 库下所有的表结构和表数据一键同步到
Hudi CDS demo 库,表的关系是一对一映射。第二条语法是 create table as
table,它的作用是把 MySql benchmark2 库下所有匹配 sbtest. 正则表达式的表同步到
Hudi 的 DB1 下的 ctas_dema 表里面,是多对一的映射关系,会做分库分表的合并。
接着我们运行并上线,然后到作业运维的页面去启动作业,可以看到配置信息已经更新了,说明已经重新上线过。接着点击启动按钮,启动作业。然后就可以到作业总览页面查看作业相关的状态信息。
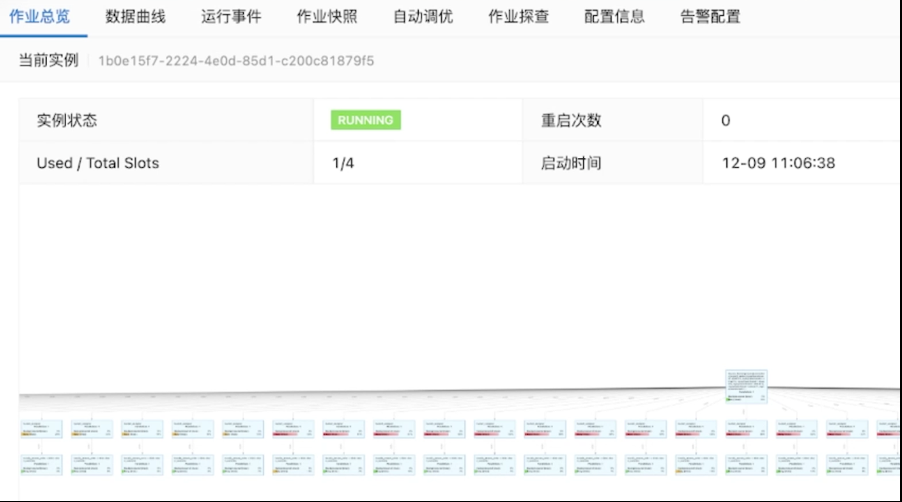
上图是作业的拓扑,非常复杂,有 1100 张源表和 101 张目标表。这里我们做了一些优化 ——
source merge,把所有的表合并到一个节点里,可以在增量 binlog 拉取阶段只拉取一次,减轻对
MySql 的压力。
接下来刷新 oss 页面,可以看到已经多了一个 cdas_demo 路径,进入 subtest1
路径,可以看到已经有元数据在写入,表明数据其实在写入过程中。
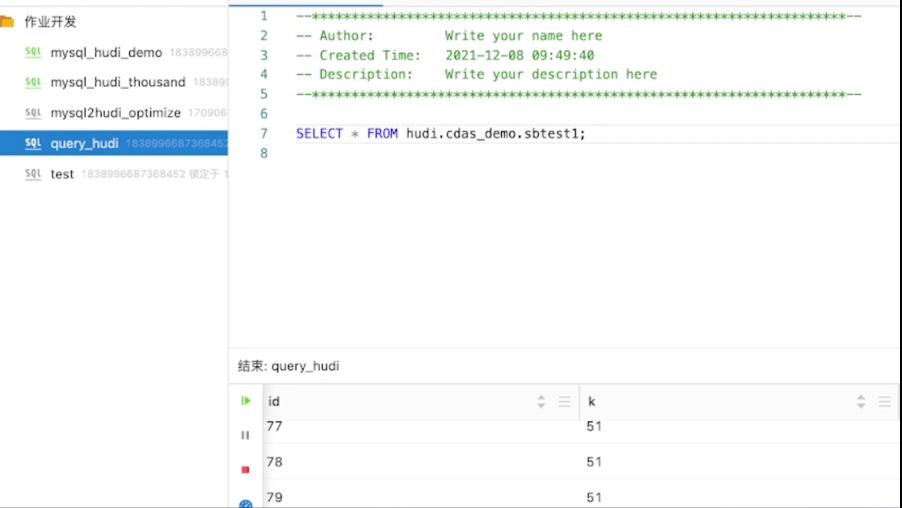
再到作业开发页面写一个简单的 SQL 查询某张表,来验证一下数据是否真的在写入。执行上图 SQL
语句,可以看到数据已经可以查询到,这些数据与插入的数据是一致的。
我们利用 catalog 提供的元数据能力,结合 CDS 和 CTS 语法,通过几行简单的 SQL,就能轻松实现几千张表的数据入湖,极大简化了数据入湖的流程,降低了开发运维的工作量。 |








