| 编辑推荐: |
本文主要介绍了什么是数据模型、数据模型的主要构成、数据模型的建设思路及其主要活动等相关知识。希望对你的学习有帮助。
本文来自于微信公众号十三说IT,由Linda编辑、推荐。 |
|
一、什么是数据模型?
首先从一个更高的视角来看看数据模型所处的位置,它毕竟不是最顶层的组件。它是属于数据架构中的四大重要构成之一,其余三个是数据资产目录、数据标准和数据分布。
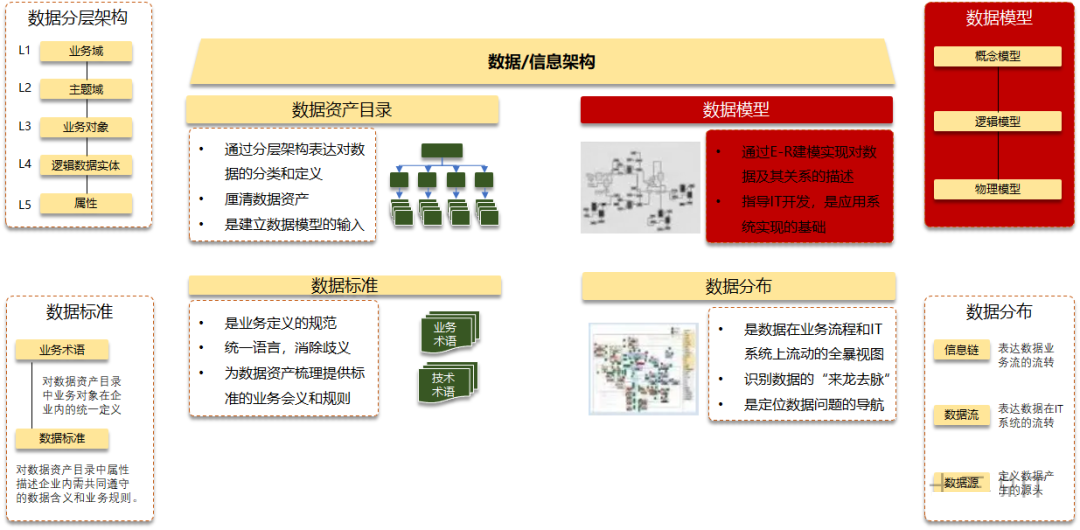
注:来自《华为数据之道》
数据模型其自身是描述数据、数据关系、数据操作以及数据约束的一种规则和标准,目的是明确数据的组织方式、存储关系和数据之间的约束关系,它为数据库系统的信息表示与操作提供了一个抽象的框架,能够指导IT开发,是应用系统实现的基础。通常认为数据模型包含有三层模型,概念模型(业务顶层设计)→逻辑模型(业务需求完整性)→物理模型(代码实现,兼顾性能),箭头的方向代表了设计的先后,逐层细化到可落地代码实现。
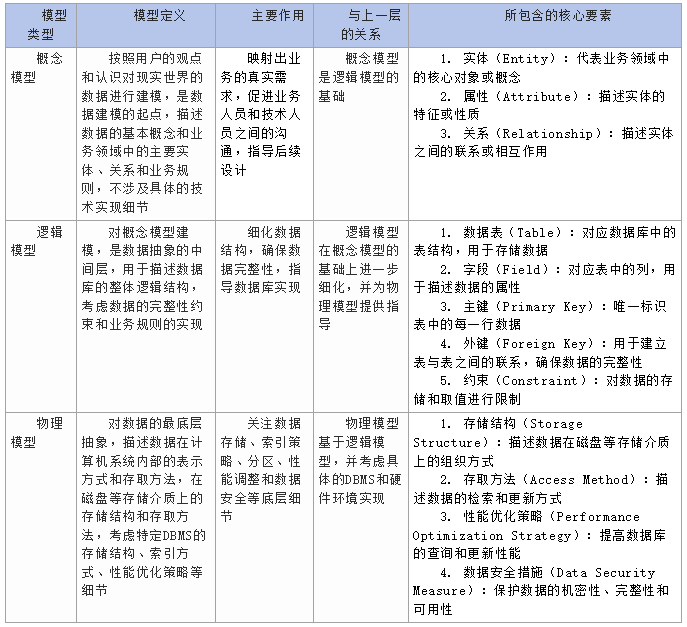
二、数据模型的主要构成(令人悲伤,目前没有统一标准)
数据模型的主要构成包含如下几个内容:
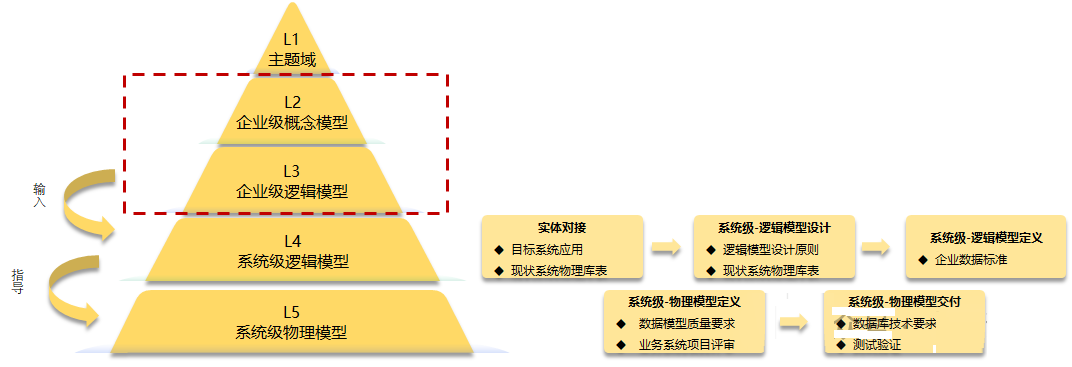
注:来自《企业数据架构实践指南1.0》
这个图更多的是站在企业级的视角来看数据模型,视角较高,而且理解上需要较多的大项目经验。重点关注点是区分清楚企业级和系统级的区别。企业级是全司级别的,由多个系统级构成。
但是这个数据模型的主要构成要素,目前没有大一统的标准分类,下面的是《华为数据之道》的建议定义:
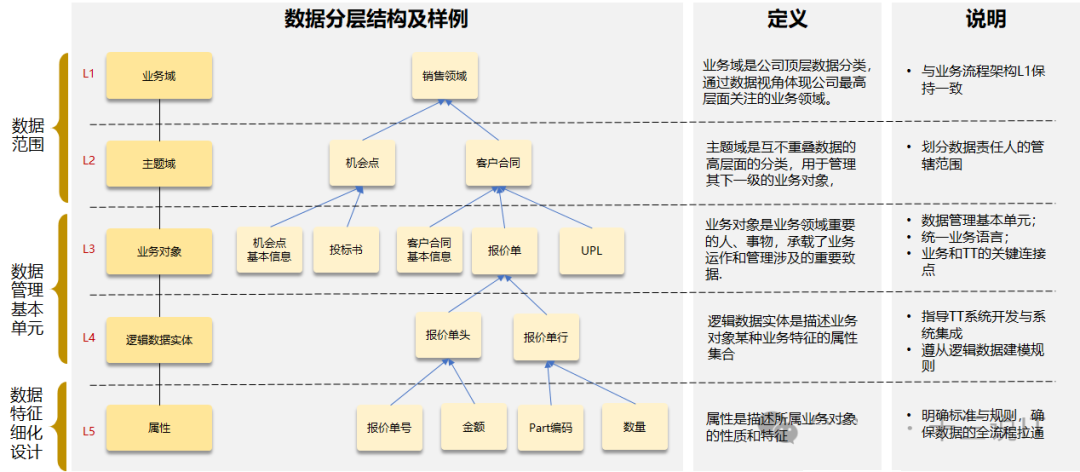
这个图中,带来对应的示例,理解上也更具体些。但是还是要注意,这些分层没有标准化的分类,即便是DAMA的,也都是给出的建议,在真正落地的时候还是要切合实际业务领域进行划分。
三、数据模型的建设思路及其主要活动
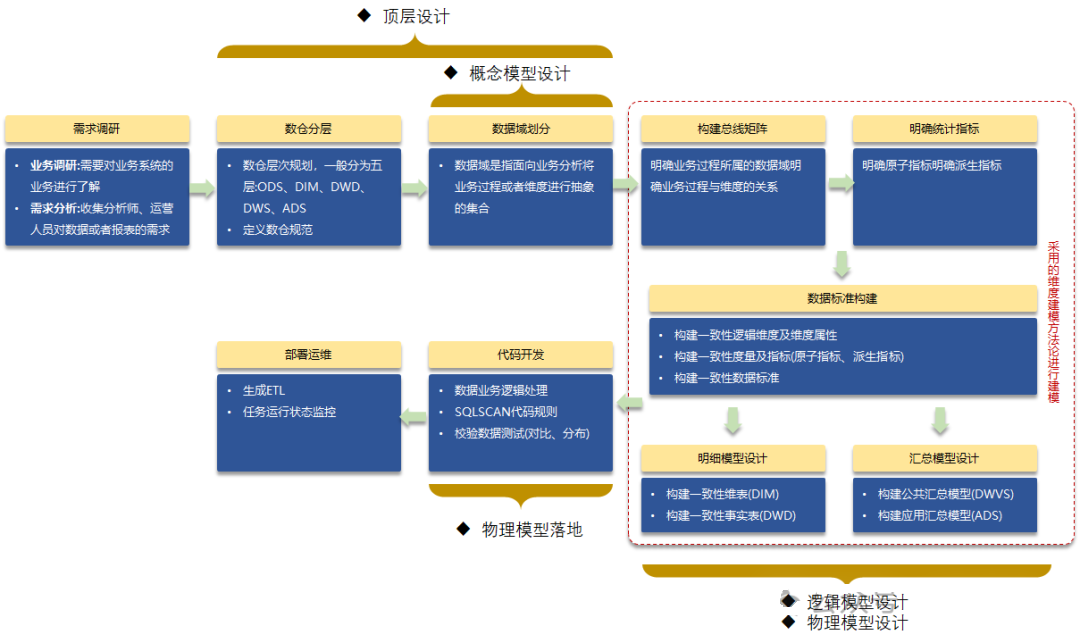
这个图来自阿里云的帮助问题,个人只是做了略微调整,对于这张图已经一图胜千言,算是很清楚了。唯一需要关注的有三个重点:
1、什么是维度建模?这个后面有时间了再介绍;
2、数据标准的构建。这个也等后面有时间了再介绍。
3、概念模型、逻辑模型、物理模型的核心要素,这些现在有很多材料了。很容易查找到相关材料。
四、数据仓库的顶层设计示例
顺手写了一个数仓的顶层设计的示例,这里有点脱离数据模型了,但是这些内容在现代数据开发流程,又都紧紧勾稽在一起。
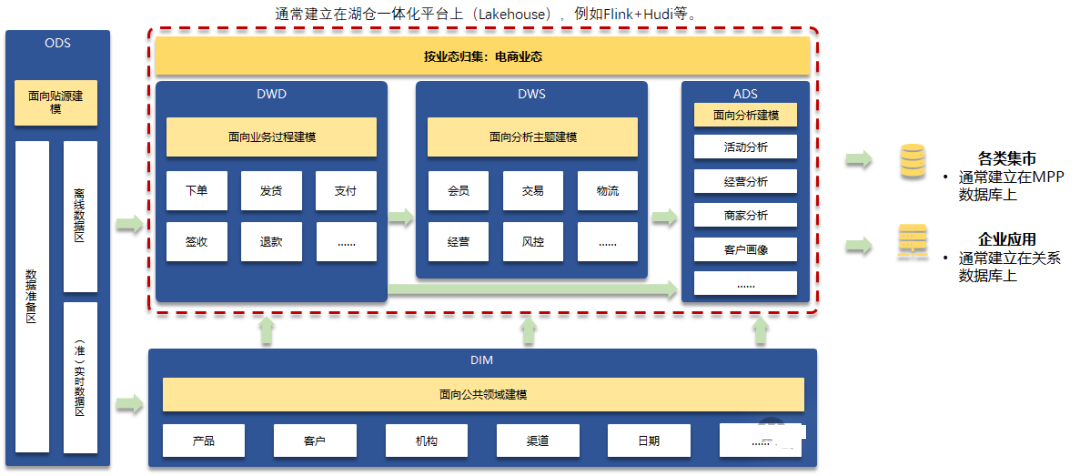
主要点解释:
1.ODS是企业级的,面向全司构建的。这个按照子公司→来源系统分类→来源系统→来源Schema →来源物理表就可以,简简单单,清清楚楚。
2.DWD、DWS最好按照业态进行逻辑分类隔离。一级分类按照业态,二级分类在按照个各自的业务过程。
3.DIM的构建是很复杂的,不同业态下想抽出公共维度的难度是极高,通常能抽取出来做公共维度的模型,也就客户、日期、机构等。机构本身都比较很麻烦,很多公司的机构组织形式极其复杂。
4.什么叫企业级的?就是全司的所有业务形态合并到一起的。如果小公司,通常业务很单一,以上建模爱怎么搞也不会乱到哪里去。但是如果是大公司,公司有多种业务形态,例如有电商子公司、有金融子公司、有旅游子公司,那么不好好分类归集,后续还要做跨子公司的分析,那就不太可能咯。
五、实际构建的示例
这个示例来自阿里云的数仓构建示例:如何使用维度建模_大数据开发治理平台 DataWorks(DataWorks)-阿里云帮助中心
这个示例将整个数仓的构建流程讲的非常清楚,个人也觉得难以写得更好了,也没有能力再去重复这个工作了。如果真要看一些的小的实战例子,可以看看我以前写的ODS、DWD、DWS构建相关的文章。
下面的示意图是抽取了阿里云示例中的与用户注册相关的构建活动内容,完整的还是建议看看下阿里云帮助文档,会更容易的理解。
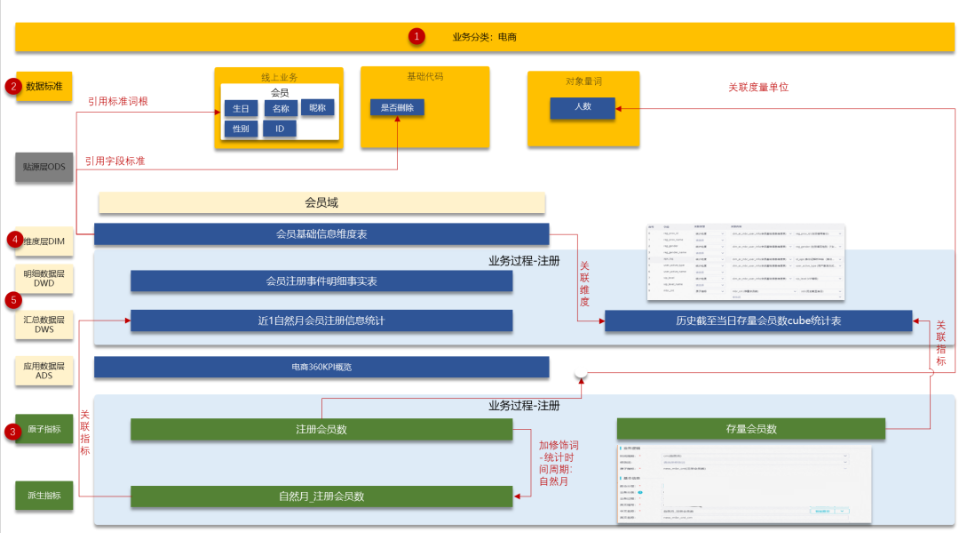
步骤一:对数仓设计主题域(业务分类),其次做数据分层。其次,示例中对标准做了一些简单的规范,实际工作还涉及调度、代码等规范:
步骤二:制定数据标准。数据标准包含字段标准(标准词根,通常是业务词汇,例如产品的中文名、英文名)、标准代码(性别,其代码值为男和女)、度量单位(人数、元)。要做企业级的数据标准是很难的,因为大公司有太多的存量系统,即便是一个性别字段都有很多套不同的码值,所以对于新项目一定要建立统一的标准,不然以后极其难以维护,避免在数仓和集市花费大量的精力去转换码值。
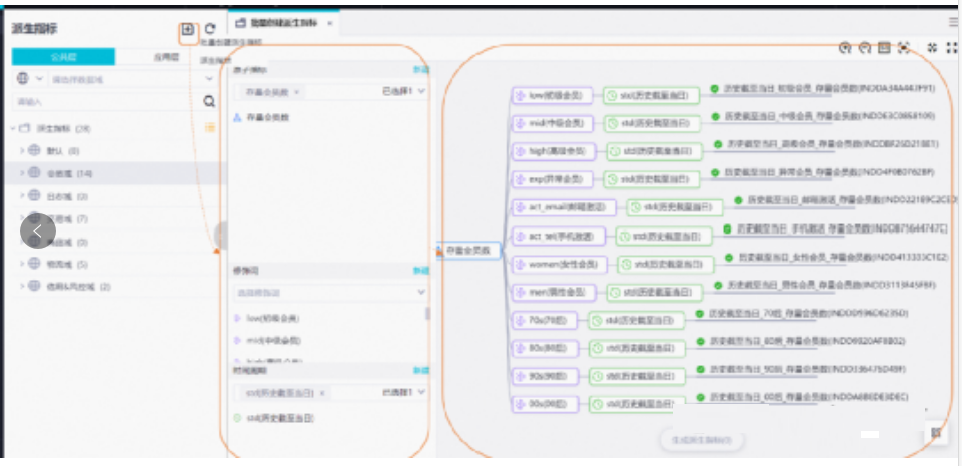
步骤三:设计数据指标。包括原子指标和衍生指标。
原子指标:也称为度量,是不加任何修饰词的指标,一般存在于OLAP(联机分析处理)表中,涉及聚合操作。它是业务定义中不可再拆分的指标,具有明确业务含义的名词。原子指标等于业务过程(原子的业务动作)加上统计方式,统计方式通常是做聚合计算。简单来说,原子指标就是描述一个业务过程的量化属性,例如“订单金额”、“交易笔数”、“交易用户数”等。这些指标是构建更复杂指标的基础。
衍生指标:则是基于原子指标进行二次计算或结合其他因素(如时间周期、修饰词等)产生的指标。它可以是利用公式对原子指标进行加减乘除运算得到的,也可以是通过添加修饰词对原子指标进行限定得到的。例如,“近7天订单量”、“近1个月的新增用户数”、“平均订单金额”等都是衍生指标。这些指标提供了对业务过程的更深入分析和理解。
两者的关联性:
基础与衍生:原子指标是衍生指标的基础。没有原子指标,就无法构建衍生指标。衍生指标是在原子指标的基础上,通过一定的计算规则或添加修饰词得到的。派生指标由原子指标、修饰词、时间周期构成。
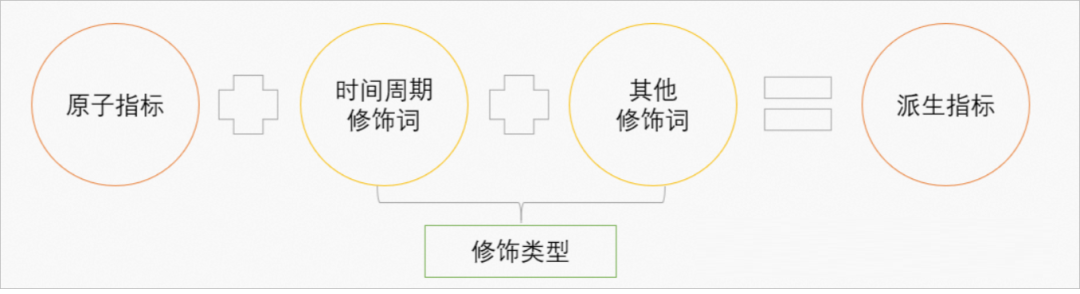
衍生指标构建在基础指标之上,形成结构化的指标体系。
互补性:原子指标和衍生指标在数仓架构中相互补充。原子指标提供了对业务过程的基本量化描述,而衍生指标则提供了更深入、更细致的分析视角。
共同服务于业务分析:无论是原子指标还是衍生指标,它们都是为业务分析服务的。通过这些指标,企业可以更好地了解业务状况,发现业务问题,并制定相应的业务策略。
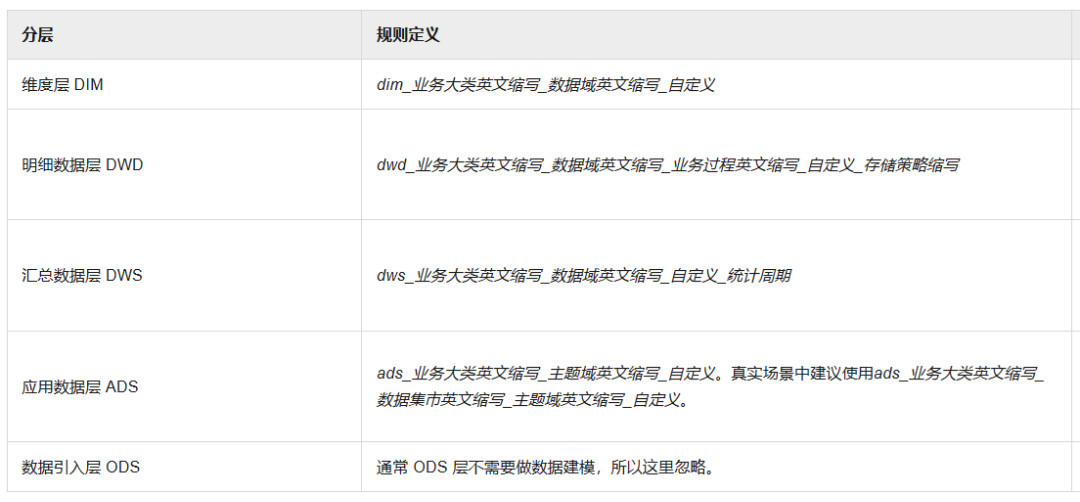
步骤四:设计公共维度和明细数据层。这块略显复杂,多参悟下阿里云的帮助文档,以及维度建模的相关资料。
步骤五:设计汇总模型和应用模型。
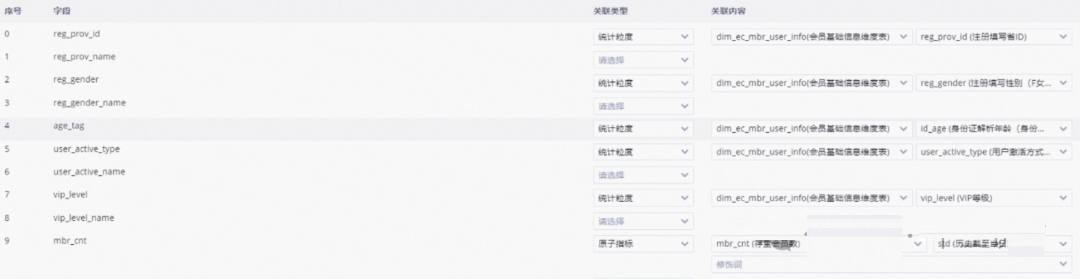
汇总模型会涉及统计的维度和对应的指标
应用模型也会涉及使用相应的指标:
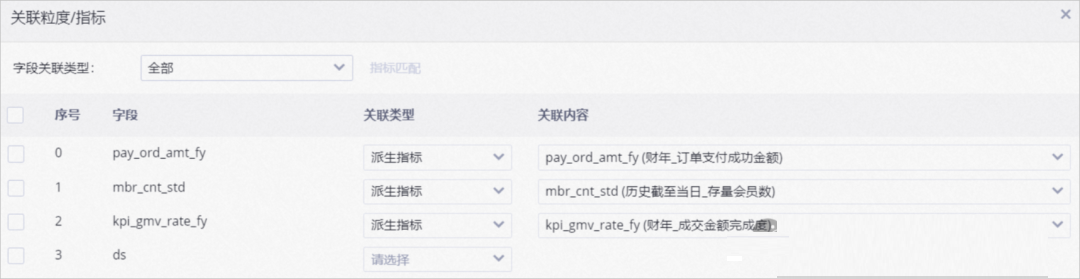
以上至少简要的描述,具体请参考阿里云例子,并仔细参悟。
六、后记
这块内容太过复杂,个人也是想到什么写点什么,大家参考到阿里云的实际例子。但是,这个例子本身也是极好的,一定要好好的学习和参悟。读书百遍其义自见,一遍看不懂,就多看几遍吧。 | 








