C++
����ʵ�������������ڰ汾�����Ĵ����ʽ
�汾����(version controlling)��ÿ������Ա�Ļ������ܣ�C++ ����ԱҲ�����⡣�汾�����Ļ�������֮һ���ٴ���仯�������������֪�����������һ����������ڵ�������ӣ��Լ�ÿ��
check-in ������Ķ�����Щ�ڲ��������Ǵ�ͳ�ļ���ʽ�汾�������ߣ��� Subversion���������͵ķֲ�ʽ�������ߣ���
Git/Hg���Ƚ������汾(revision)�IJ��춼����������ܣ����׳ơ���һ�� diff����
diff ������Ǹ�����(peephole)���������������ޣ�diff �Cu Ĭ����ʾǰ�� 3 �У�������
code review ��ʱ�������ƾ�⡰һ��֮�������ܷ��ִ���Ķ������⣬�Ǿ��ٺ�Ҳ�����ˡ�
C �� C++ �������ɸ�ʽ�����ԣ������еĻ��з������� white space ���Դ�������Ȼ������˵����Ԥ����(preprocess)֮�����������Ա�������˵һģһ���Ĵ�������ж���д��������
foo(1, 2, 3, 4);
��
foo(1,
2,
3,
4);
�ʷ������Ľ����һ���ģ�����Ҳ��ȫһ����
������˵��������д����������һ��������汾����������˵��ͬ�����ܵ�����ɵIJ���(diff)Ҳ������һ������ν�������ڰ汾������������ָ�ڴ����к���ʹ�û��з�����
diff �����Ѻã��� diff �Ľ���������˵ر������ĸĶ�����diff һ������Ϊ��λ��Ҳ�����Ե���Ϊ��λ������ֻ���������
diff by lines����
�����һЩ���ӡ�
�� diff �ѺõĴ����ʽ
1. ����ע��Ҳ�� //������ /* */
Scott Meyers д�ġ�Effective C++���ڶ���� 4 ������ʹ�� C++ ���������Ϊ������һ�����ɣ���
diff �Ѻá����磬��Ҫע��һ��δ��루��ʵ�ⲻ�Ǹ��õ�������������ʵ������ʱ��������������� /*
*/����ô�õ��� diff �ǣ�
�������� diff output �ܿ���ע������Щ������
����� //������������ࣺܶ
ͬ���ĵ�����ȡ��ע�͵�ʱ�� // Ҳ�� /* */ ��������
���⣬����� /* */ ��������ע�ͣ��� diff ��һ���ܿ������������Ĵ��뻹����ע�͡���������
diff �ƺ����� muduo::EventLoop::runAfter �ĵ��ò�����
��֮����Ҫ�� /* */ ��ע�Ͷ��д��롣
������ʱ����Ǩ����Ҷ����� // ע���ˣ���Effective C++��������ȥ������һ�����顣
2. �ֲ��������Ա�����Ķ���
����ԭ���ǣ�һ�д���ֻ����һ������������
double x;
double y;
������������һ�� double z ��ʱ��diff ���һ�۾��ܿ�������ʲô��
@@ -63,6 +63,7 @@ private:
int count_;
double x;
double y;
+ double z;
};
int main()
����� x �� y д��һ�У�diff ������͵ö���۲�֪����
@@ -61,7 +61,7 @@ private:
muduo::net::EventLoop* loop1_;
muduo::net::EventLoop* loop2_;
int count_;
- double x, y;
+ double x, y, z;
};
int main()
���ԣ�һ��ֻ����һ�����������ڰ汾������ͬ���ĵ��������� enum ��Ա�Ķ��壬����ij�ʼ���б��ȵȡ�
3. ���������еIJ���
��������IJ������� 3 ������ô�ڶ��ź��滻�У�����ÿ������ռһ�У����� diff���� muduo::net::TcpClient
����
class TcpClient : boost::noncopyable
{
public:
TcpClient(EventLoop* loop,
const InetAddress& serverAddr,
const string& name);
������� TcpClient �Ĺ��캯�����ӻ���һ����������ô�����״� diff ������������±���һ�г�������������Ҫ��ЧһЩ��
4. ��������ʱ�IJ���
�ں������õ�ʱ������������� 3 ������ô��ʵ�η���д���� muduo::net::EPollPoller
����
Timestamp EPollPoller::poll(int timeoutMs, ChannelList*
activeChannels)
{
> int numEvents = ::epoll_wait(epollfd_,
&*events_.begin(),
static_cast<int>(events_.size()),
timeoutMs);
Timestamp now(Timestamp::now());
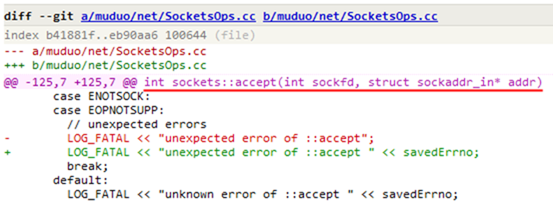
����һ������������ع�������һ���²������ðɣ�epoll_wait ������������⣩����ô��������ͺ������õĵط���
diff ������ͬ����ʽ���ȷ�˵�����ڵ����ڶ��м���һ�����ݣ���������������֤��û�д�λ���������д��һ����ߣ��͵������۾��������ˡ�
5. class ��ʼ���б���д��
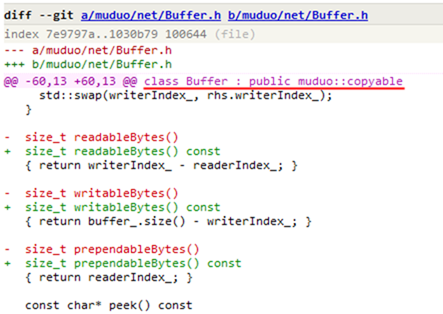
ͬ���ĵ�����class ��ʼ���б�(initializer list)Ҳ��ѭһ��һ����ԭ������������������µij�Ա��������ô������class
����� ctor ���壩�� diff ������ͬ����ʽ���ô����������Ρ��� muduo::net::Buffer
����
ע�⣬��ʼ���б���˳���������ݳ�Ա������˳����ͬ��
6. �� namespace �йص�����
Google �� C++ ��̹淶��ȷָ����namespace ��������������ô���dz��е��������� diff
�Cp �Ѻ�������ʾ��ÿ�� diff chunk ��ͷ�ϡ�
����Ժ���ʵ���� diff��chunk name �Ǻ�����������һ�۾��ܿ����ĵ����ĸ�����������ͼ����ɫ���߲��֡�
����� class �� diff����ô chunk name ���� class name��
diff ԭ����Ϊ C ������Ƶģ�C ����û�� namespace ����һ˵��������Ĭ�ϻ��ҵ�������д���ĺ�����Ϊһ��
diff chunk �����֣����������ǰ���пո����Ͳ��ϵ��ˡ�muduo �Ĵ��붼��ѭ��һ�������磺
�෴��boost �е�ijЩ��Ĵ����ǰ� namespace �������ģ������Ļ��� diff ������֪���Ķ������ĸ�
class ���ĸ���Ա������
�����������ͨ������ diff ȡ���������������ʽ������������������д�����ʱ���ע��Ѻ���������д������ô�Ͳ���ȥ��
diff ��Ĭ�������ˡ����⣬�������ʽ������ȫƥ�亯��������Ϊ�����������������(context-free
syntax)����û�취дһ�������ȥƥ�������������������д��ij�ֺ���������������������ʽʧЧ�����뺯���ķ������ͣ���������һ���dz����ӵĶ���������˵�����ˣ������ο�
C++ �������������صģ�������� Foo<Bar> qux; �Ǹ�����ʽ���DZ������壿
7. public �� private
����Ϊ���� C++ ���һ��ȱ�ݣ�����Ұ�һ����Ա������ public ���Ƶ� private ������ô��
diff �Ͽ��������Ҹ���ʲô�����磺
������� diff �ܿ����Ұ� retry() ��� private ���𣿶Դ���Ҳû�кõĽ���취���ܲ���ÿ������ǰ�涼д��
public: �� private: �ɣ�
�Դ� Java �� C# �����ñȽϺã����ǰ� public/private �����η��ŵ�ÿ����Ա�����Ķ����С���ô����������Ϣ������ȣ���
diff �Ľ����ֱ�ۡ�
�� grep �ѺõĴ�����
����������
C++�����ѷ�����һ����Ŀ�Ҫ�ҵ�һ�������Ķ����������̫�ѣ������Ƿ���һ�����غ�ģ���ػ���������Ҫ�ҵ�һ��������ʹ�þ��Ѷ��ˡ�����
Java���� Eclipse �� Ctrl+Shift+G �����ҵ����е����õ㡣
������Ҫ��һ���ع��������ҵ������������õ� muduo::timeDifference �ĵط����ж�һ�¹����Ƿ���У�������Ωһ�İ취��grep����
grep �������ų�ͬ���ĺ�����ע��������ݡ���Ҳ˵��ΪʲôҪ�� // ������ע�ͣ���Ϊ�� grep ��ʱ��һ�۾��ܿ������д�������ע����ġ�
���ҿ�����operator overloading Ӧ�����ں� STL algorithm/container
���ʱʹ�ã����� transform() �� map<T,U>������������þ�������Ϊ�ˡ�ԭ��֮һ�ǣ��Ҹ�����
grep �Ҳ������Ķ��õ��� operator-()����Ҳ�� muduo::Timestamp ֻ�ṩ
operator<() �����ṩ operator+() operator-() ��ԭ�����ṩ����������
timeDifference �� addTime ��ʵ������Ĺ��ܡ�
�ֱ��磬Google Protocol Buffers �Ļص��� class Closure�����Ľӿ��õ���
virtual function Run() ������ virtual operator()()��
static_cast �� C-style cast
Ϊʲô C++ Ҫ���� static_cast ֮���ת�Ͳ�������ԭ��֮һ������ (int*) pBuffer
�����ı���ʽ������û�취�� grep �жϳ����Ǹ�ǿ������ת����д����һ���պ�ֻƥ������ת�����������ʽ����again������������صģ���������㶨����
�������ת������ *_cast����ֻҪ grep һ���Ҿ���֪���������Ķ����� reinterpret_cast
ת��������Ѹ�ٵؼ����û���ô���Ϊ��ǿ����һ�㣬muduo �����˱���ѡ�� -Wold-style-cast
���������� C-style cast�������ڱ���ʱ���ܰ������ҵ����⡣
һ��Ϊ��Ч��
�����ͼ�λ����ļ��ȽϹ��ߣ��ƺ��ܱ��������оٵ����⡣�������� web ���ǿͻ��ˣ������� inline
diff ���� diff by lines �����ܽ��ȫ�����⣬Ч��Ҳ��һ�����ߡ�
����(2)�������֪����˭��ʲôʱ�����ӵ� double z���ڷ���д������£��� git blame
�� svn blame ���̾����ҵ�ʼ��ٸ�ߡ����д��һ�У��Ǿ͵ð��ļ��� revisions ����һ�����˹��Ƚϣ���Ϊ��һ��
double x = 0.0, y = 1.0, z = -1.0; �����Ĺ���Σ����һ��������֪��ʲôʱ������˱���
z����� blame �� case Ҳ������ 3��4��5��
����(6)�Ķ���һ�д��룬�㻹��Ҫ scroll up ȥ�Ҹĵ����ĸ� function�����ۿ��Ļ����С������ۡ��Ŀ��ܣ��ֵ��ٶ������ơ���һ�ж����˷��˵�ʱ�䣬ʹ�ø��õ�ͼ�λ����߲����ܼ����˷ѣ��෴������Ϊ�������˷ѡ�
����һ�������Ĺ������������������칫�ң�update һ�´��룬Ȼ��ɨһ�� diff output �����������춯����Щ�ļ���������Щ���룬�����һ����������£������Ӿ��ܽ��ս���������ͼ�λ��Ĺ��ߣ���һ�����㿪�ļ�
diff �����ӻ�㿪�� tab �����ļ��� side-by-side �Ƚϣ�����ô���Ļ��������㹻��������ģ�����
diff output ���죩��Ȼ����������ҳ��ȥ�����˵�����ʲô��˵ʵ���Ҿ�����ô��Ч�ʲ��� diff
�ߡ�
C++ ����ʵ���������Ƽ�����
C/C++ �Ķ����Ƽ����� (binary compatibility) �ж��غ��壬������Ҫ�ڡ�ͷ�ļ��Ϳ��ļ��ֱ���������ִ���ļ��Ƿ���Ӱ�족������������ۣ��ҳ�֮Ϊ
library ����Ҫ�� shared library������̬���ӿ⣩�� ABI (application
binary interface)�����ڱ����������ϵͳ�� ABI ������һƪ̸ C++ ����ʵ�������¡�
ʲô�Ƕ����Ƽ�����
�ڽ����������֮ǰ���ȿ��� Unix/C ���Ե�һ����ʷ���⣺open() �� flags ������ȡֵ��open(2)
������ԭ����
int open(const char *pathname, int flags);
���� flags ��ȡֵ�������� O_RDONLY, O_WRONLY, O_RDWR��
��һ���˵�ֱ���෴���⼸��ֵ���ǰ�λ�� (bitwise-OR) �Ĺ�ϵ���� O_RDONLY | O_WRONLY
!= O_RDWR����������Զ�д��ʽ���ļ��������� O_RDWR���������� (O_RDONLY |
O_WRONLY)��Ϊʲô����Ϊ O_RDONLY, O_WRONLY, O_RDWR ��ֵ�ֱ��� 0,
1, 2�����Dz����㰴λ��
��ôΪʲô C ���Դӵ���������һֱû�о����������֮�����ȷ�˵�� O_RDONLY, O_WRONLY,
O_RDWR �ֱ���Ϊ 1, 2, 3������ O_RDONLY | O_WRONLY == O_RDWR������ֱ��������������ֵ���Ǻ궨�壬Ҳ����Ҫ�����е�Դ���룬ֻ��Ҫ�ĸ�ϵͳ��ͷ�ļ������ˡ�
��Ϊ��ô�����ƻ������Ƽ����ԡ������Ѿ�����õĿ�ִ���ļ��������� open(2) �IJ�����д���ģ�����ͷ�ļ�������Ӱ���Ѿ�����õĿ�ִ���ļ����ȷ�˵�����ִ���ļ������
open(path, 1) ��д�ļ��������¹涨�У����ʾ���ļ�������ʹ����ˡ�
�����������˵��������� shared library ��ʽ�ṩ�����⣬��ôͷ�ļ��Ϳ��ļ����������ģ����������ƻ����еĶ����ƿ�ִ���ļ������������õ����
shared library �� library������ϵͳ�� system call ���Կ��� Kernel
�� User space �� interface��kernel �����������Ҳ���Ե��� shared library��������ں˴�
2.6.30 ������ 2.6.35��������Ҫ���±��������û�̬�ij���
��ν�������Ƽ����ԡ�ָ�ľ�����������Ҳ������ bug fix�����ļ���ʱ�������±���ʹ�������Ŀ�ִ���ļ���ʹ���������������ļ�������Ĺ��ܲ����ƻ���
�� Windows ���ж����� DLL Hell������ MFC ��һ�� DLL��mfc40.dll,
mfc42.dll, mfc71.dll, mfc80.dll, mfc90.dll�����Ƕ�̬���ӿ�ı������⣬�ֲ���
MFC ͷ�ϡ�
����Щ������ƻ���� ABI
��������ж�һ���Ķ��Dz��Ƕ����Ƽ����أ���� C++ ��ʵ�ַ�ʽֱ����أ���Ȼ C++ ��û�й涨
C++ �� ABI�����Ǽ�����������ƽ̨�������Ļ���ʵ�ϵ� ABI �����ȷ�˵ ARM �� EABI��Intel
Itanium �� http://www.codesourcery.com/public/cxx-abi/abi.html��x86-64
�з� Itanium �� ABI��SPARC �� MIPS Ҳ�������Ĺ涨�� ABI���ȵȡ�x86 �Ǹ����⣬��ֻ����ʵ�ϵ�
ABI������ Windows ���� Visual C++��Linux �� G++��G++ �� ABI ���ж���汾��Ŀǰ���µ���
G++ 3.4 �İ汾����Intel �� C++ ������Ҳ�ð��� Visual C++ �� G++ ��
ABI �����ɴ��룬����Ͳ�����ϵͳ�����������ݡ�
C++ ABI ����Ҫ���ݣ�
- �����������ݵķ�ʽ������ x86-64 �üĴ�������������ǰ 4 ����������
- �麯���ĵ��÷�ʽ��ͨ���� vptr/vtbl Ȼ���� vtbl[offset] ������
- struct �� class ���ڴ沼�֣�ͨ��ƫ�������������ݳ�Ա
- name mangling
- RTTI ���쳣������ʵ�֣����±��IJ������쳣������
C/C++ ͨ��ͷ�ļ���¶����̬���ʹ�÷����������ʹ�÷�������Ҫ�Ǹ����������ģ���������ݴ����ɶ����ƴ��룬Ȼ�������е�ʱ��ͨ��װ����(loader)�ѿ�ִ���ļ��Ͷ�̬���һ������ж�һ���Ķ��Dz��Ƕ����Ƽ��ݣ���Ҫ���ǿ�ͷ�ļ���¶����ݡ�ʹ��˵�����ܷ����°汾�Ķ�̬���ʵ��ʹ�÷������ݡ���Ϊ�µĿ��Ȼ���µ�ͷ�ļ����������еĶ����ƿ�ִ���ļ����ǰ��ɵ�ͷ�ļ������ö�̬�⡣
�����һЩԴ������ݵ��Ƕ����ƴ��벻��������
- ����������Ĭ�ϲ��������еĿ�ִ���ļ������������IJ�����
- �����麯��������� vtbl ������б仯������Ҫ���ǡ�ֻ��ĩβ���ӡ�����ȡ����Ϊ����Ϊ���
class �����ѱ��̳С���
- ����Ĭ��ģ�����Ͳ������ȷ�˵ Foo<T> ��Ϊ Foo<T, Alloc=alloc<T>
>�����ı� name mangling
- �ı� enum ��ֵ���� enum Color { Red = 3 }; ��Ϊ Red = 4�������ɴ�λ����Ȼ������
enum �Զ�����ȡֵ������ enum ��Ҳ�Dz���ȫ�ģ���������ĩβ���ӡ�
�� class Bar �������ݳ�Ա����� sizeof(Bar) ����Լ��ڲ����ݳ�Ա�� offset
�仯�����Dz��ǰ�ȫ�ģ�ͨ�����ǰ�ȫ�ģ���Ҳ�����⡣
- ����ͻ��������� new Bar����ô�϶�����ȫ����Ϊ new ���ֽ�������װ���� Bar���෴�����
library ͨ�� factory ���� Bar* ����ͨ�� factory �����ٶ�����ֱ�ӷ���
shared_ptr<Bar>���ͻ��˲���Ҫ�õ� sizeof(Bar)����ô�����ǰ�ȫ�ġ�
- ����ͻ��������� Bar* pBar; pBar->memberA = xx;����ô�϶�����ȫ����Ϊ
memberA ���� Bar ��ƫ�ƿ��ܻ�䡣�෴�����ֻͨ����Ա���������ʶ�������ݳ�Ա���ͻ��˲���Ҫ�õ�
data member �� offsets����ô�����ǰ�ȫ�ġ�
- ����ͻ����� pBar->setMemberA(xx); �� Bar::setMemberA()
�Ǹ� inline function����ô�϶�����ȫ����Ϊƫ�����Ѿ��� inline ���ͻ��Ķ����ƴ������ˡ����
setMemberA() �� outline function����ʵ��λ�� shared library
�У������� Bar �ĸ��¶����£���ô�����ǰ�ȫ�ġ�
��ôֻʹ�� header-only �Ŀ��ļ��Dz��ǰ�ȫ�أ���һ���������ij������� boost 1.36.0������������ij��
library �ڱ����ʱ���õ��� 1.33.1����ô��ij������� library �Ͳ���������������Ϊ
1.36.0 �� 1.33.1 �� boost::function ��ģ��������͵ĸ�����һ��������һ������
allocator��
��Щ��������ǰ�ȫ��
ǰ����˵�����������ġ�����ʾ��Щ�Ķ�����ǰ�ȫ�ģ�ֻҪ��Ķ���Ӱ�����еĿ�ִ���ļ��Ķ����ƴ������ȷ�ԣ���ô���ǰ�ȫ�ģ����ǿ����Ȳ����µĿ⣬�����еĶ����Ƴ������档
- �����µ� class
- ���� non-virtual ��Ա����
- �����ݳ�Ա�����ƣ���Ϊ�����Ķ����ƴ����ǰ�ƫ���������ʵģ���Ȼ��������Դ�뼶�IJ����ݡ�
- ���кܶ࣬��һһ�о��ˡ�
�� C++ �����麯����Ϊ�ӿڻ����Ͼ������Ƽ�����˵�ݰ��ˡ������˵����ֻ�����麯���� class
����Ϊ interface class����Ϊ�����Ľӿڣ������Ľӿ��ǽ�Ӳ�ģ�һ�����������ġ�
�ȷ�˵ M$ �� COM���� DirectX �� MSXML ���� COM �����ʽ�������������������Ĵ��汾�ӿ�
(versioned interfaces)��
- IDirect3D7, IDirect3D8, IDirect3D9, ID3D10*, ID3D11*
- IXMLDOMDocument, IXMLDOMDocument2, IXMLDOMDocument3
�����仰˵��ÿ�η����°汾�������µ� interface class�������������е� interface
�������䡣����һ�����ܼ������еĴ��룬ǿ�ȿͻ��˴���ҲҪ��д��
�ع�ͷ������ C ���ԣ�C/Posix ��Щ�������˺ܶ��º�����ͬʱ�����еĴ��벻����Ҳ�����еúܺá����Ҫ����Щ�º�����ֱ���þ����ˣ�Ҳ�������������еĴ��롣�෴��COM
���Ҫ���� IXMLDOMDocument3 �Ĺ��ܣ��͵ð����еĴ���� IXMLDOMDocument
ȫ�������� IXMLDOMDocument3���ܷ��̰ɡ�
tip����������Ĵ��� C++ ��ʹ������ӿڱ�̵��ˣ������ö����Ƽ����Կ�������
����취
���þ�̬����
������������ڷֲ�ʽϵͳ�⣬���þ�̬����Ҳ���������ϵĺô���ֻҪ�ѿ�ִ���ļ��ŵ������Ͼ������У����ÿ�����������
libraries��Ŀǰ muduo ���Dz��þ�̬���ӡ� ͨ����̬��İ汾���������Ƽ�����
����Ҫ�dz�С�ļ��ÿ�θĶ��Ķ����Ƽ����Բ����÷����ƻ������� 1.0.x ϵ�����������Ƽ��ݣ�1.1.x
ϵ�����������Ƽ��ݣ��� 1.0.x �� 1.1.x �����Ʋ����ݡ�������Ա��������������߽��� .so
�ļ�������������Ƽ�������صĻ��⣬ֵ��һ����
�� pimpl ����������������ǽ
��ͷ�ļ���ֻ��¶ non-virtual �ӿڣ����� class �Ĵ�С�̶�Ϊ sizeof(Impl*)����������������¿��ļ�����Ӱ���ִ���ļ�����Ȼ����ô���ж���һ������ԣ�������һ����������ʧ����
Exceptional C++ ������ C++ Coding Standards 101.
Java �����Ӧ�Ե�
Java ʵ���ϰ� C/C++ �� linking ��һ�����Ƴٵ� class loading ��ʱ���������Ͳ����ڡ����������麯��������������
data member�� �����⡣�� Java ��������� interface ���Զ�� C++ ��ͨ�ú���Ȼ��Ҳû�������ᵽ�ġ���Ӳ�Ľӿڡ����⡣
| 