|
�����C++ͬ��̸̸�������Լ������ۡ��������ֻ�ǹ��ߣ�Ҫ�ѹ����õ�����ʵĵط������䳤�ұ���̣�������м�ֵ��������Ʒ����ôʹ����ߵ�����Ȼ���۾��ˡ�
C++���Ե�����
C++��������Щ�����أ���Ȼ�кܶ࣬��Ȼ�������ˡ���������˵���кܶࡱû���塣��������Щ�أ���ͬ�˿����в�ͬ�Ļش�ͬһ�����ڲ�ͬʱ��Ҳ���ܻش�ͬ���������Dz�������C++֮��Bjarne
Stroustrup�������˵����ǰ���þٰ�ġ�2016 C++��ϵͳ����������ᡱ�ϣ�Bjarne����������Ϊ��What
C++ is and what it will become���������ݽ���������̵ز����˵���ʲô��C++����˵��C++���Եĸ������������ơ���һҳ�������Ŀ�С�C++
in two lines���������л�������C++������ν�����㾦֮�ʡ���������ʲô�أ���һ���ǡ�Direct
map to hardware�����ڶ����ǡ�Zero overhead abstraction������dz����һ�£����ǡ�ֱ��ӳ�䵽Ӳ�����͡�0��������
��ֱ��ӳ�䵽Ӳ������˵C++���Ժ�Ӳ��֮��ֱ�Ӷ�Ӧ��C++��������ֱ�Ӷ�Ӧ��CPUָ�C++����������Ҳ����ֱ�Ӷ�Ӧ��CPU֧�ֵ��������͡�Ҳ����˵��C++���ԵĴ�������ݿ��Ժ�ֱ�ӵط��뵽CPU֧�ֵ�ָ������ݣ�����Ҫ������������ת��������֮������Ч�ʺܸߡ�
������Ч����������ֱ�ӵ����Ե�ȻҪ����࣬��������Ե�������ȱ����������������֯������Bjarne�����ĵڶ����ǡ�0��������������һ���ְ���������˼����һ����˼��C++���г���ģ��ڶ�����˼��֧�ֳ���ĸ���Ϊ0���ڽ��������������ʱ������ʹ�DZȽ�С�͵�������Ŀ��ʹ�ó���Ҳ�DZ���ġ��������еı�����Լ�����֧�ֳ�����Java����C#��F#����Ȼ��֧�ֳ�����Щ����Ϊ�˳����Ĵ��ۺܴ���Դ���Ķ࣬�����ٶ�����Ҳ���Ƕ�����ߡ���C++��0��������0�������Bjarne����һ��Ҳ֪��Java�����У�һ��Ҳ����������C++��Java������ǵ����ۡ�˵C++��0���������Щ���ţ����������������ߵ�������˵���൱����0�ˡ�������˵�Ļ���˵����ԶԶ�����������ԣ����£�һ����ʦ����һ�����Լ����࣬��Ҳ���˸ҳ���˵������ǡ�

ͼ1 C++֮��Bjarne�����ڽ���C++�ĸ�������
�����л���������һ����Ч�ʸߣ�һ���Ǹ���С��������һ���г�C++�ĺ������ƣ������ޱȣ�����һ����
�����ϵ��ģ���һ������Bjarne���������������л���һ�����ֻ������������ʷ˲�䡣�ص����Ϻ��ֶ�����ŵ�ϲ���ǾƵ꣬ʱ����2016��10��28������10��12�֡�
��ʦ�Ļ�ֵ�÷�����ζ��ÿ��C++����Ա��Ӧ���μǡ��������ʱ������Ӧ���������仰������Լ�����ƣ��Ƿ��������ܷ�Ӳ�������ܡ���д�ͼ�����ʱ�����Ǹ�Ӧ�����������仰�������ҵ�����˳��������Ĵ���ɾ���������Ż�ÿ�д��룬��Ӳ�������ܷ��ӵ����¡���Ȼ�Ļ�����ô�Ե���C++���ԣ���ô�Ե���Bjarne������

ͼ2 C++֮��Bjarne����ϣ�����뵽C++17�е���������
����˵��Ӳ��̫ǿ���ˣ�д����ʱ����Ҫ��ô�����������⡣�⻰���Ƿ�ƨ��ÿһλ�������ĵ�C++����Ա��Ӧ��վ����ʹ�����������ۡ�
��Bjarne��������C++��δ����չʱ����̸������ϣ�����뵽C++17�е��������������������ʮ�����ݵ��б��У���8����SIMD�����Ͳ��л��㷨���պ�����Ϊ���Ľ��ⲻı���ϡ�
SIMD��Single Instruction��Multiple Data����д������Ϊ��ָ������ݡ�������Intel�����ڼ���˵��������ģ��ö���ǰ�ˣ�ʲô�����Ѿ��Dz��壬���Լǵõ�ʱ��ǰһ�����·�һ��ϼ�⣬������̾��������̫�����ˡ�SIMD˼��������ɫ�������Ǽ���Ȼ�����˷��أ��ط��죬�취����������Ȼ��Ϊʲô���˵�أ���ΪSIMD˼���Ӧ��ʵ�������ǵ��������洦�ɼ��������������������ݵ�ԭʼ��ᡣ
��ϲ���������������������Ϊ��������ij����Ҫ��1000�������ÿ�����Ҫ�������͡���¯���濾��ȡ���Ȳ��衣���ÿ��ֻ����һ���������ô���������������Ҫ�ظ�1000�Ρ������ʹ��һ��ͼ3��ʾ�ļ�ģ�ߣ��������ĸ������ᣨ���֮�ᣬ���ҳƴ�����������ô�����һ�β����ĸ����������һ�����ܶ�����㶼�dz������ˣ�һ�γ����ĸ����������ʱ��һ���ĸ����ó���ʱ������һ���ĸ������Ǻܶ�������ظ��������1000���½�����250������Ч�ʴ����ߡ�

ͼ3 SIMD˼��Դ������
�߽������ʵ�кܶ��������ӣ���Сʱ���û������������Ͷ����棬һ����Ϊ��ģ�ӵ�ľ�������ж�����ӣ�ÿ�����Ӷ�Ӧһ������������������һ�£���ô�����ˡ��ܶ����ʹ��SIMD˼�룬�������������Ͷ������ǻۣ�����ͬ����Ӧ�úú�����ʵ���ѧϰ��
SIMD�ڼ��������Ӧ��Ҳ�кܶ����ˣ�Ŀǰ�Ƚ��ձ����Ϊ������ILLIAC IV���ͻ���SIMD˼������ִ�������е�����ʵ�֡�ILLIAC
IV������Illinois��ѧ��ƣ�������˾��Burroughs�����죬��Ŀ��1965�꿪ʼ����������ʱ�������ǧ����Ԫ��ɣ���װ���������Һ��պ���֣�NASA�������۶��ֱ꣬��1981���ͣ�����ۡ�
Դ��ILLIAC IVʹ���ֲ��ͼ4��������ILLIAC IV�ĺ��IJ������ֲ��������Ĺ���ԭ����ͼ�е�PE��Processor
Element����д������������Ԫ���书�ܺ������������ǽ�����˵��Execution Unit��EU����GPU�ڵĻ���ִ�е�Ԫ���dz����ơ�PEM��Processing
Element Memory����������Ԫ�����壬�������Ҫ��������ݺͼ�������

ͼ4 ILLIAC IV����ԭ��
ILLIAC IV��64��PE����������Ԫ��������ͬʱ��64�����㡣ͼ����ʾ�ı��ǰ�����B������C��ӣ�����ŵ�����A��һ�α����64��Ԫ�ء�
��ILLIAC IV�ֲ�������Կ���һЩ��Ȥ�IJ�ͼ������ͼ5�����ͨ���dz�����������ILLIAC
IV���Գ����������ݵ�������������Ա�ô���Ӱ��ļ�һ����һ������Ͷ��ILLIAC IV�Ĵ��졣ILLIAC
IV���ڶ���㵥Ԫ�ų�һ���ڵȴ���ιʳ����
IA CPU��SIMDʵ��
�ղŽ�����SIMD��˼���Լ������ʵ�֣�������������Intel�ܹ������IA���ϵ�SIMDʵ�֣�Ȼ���ٸ���ʵ����
�ܶ��˲�֪��SIMD��ʲô����֪��MMX��MMX��MultiMedia eXtensions����д����˼�Ƕ�ý����չ��1997���Ƴ��Ļ���P5�ܹ��ı��ڴ������ǰ���MMX�����ĵ�һ��IA
CPU����Ӳ���Ƕ�������MMX��������8��64λ�ļĴ�������ΪMM0-MM7�����Զ�8�����ֽ�����������4���֣�����2��˫����������ϲ�����MMX��֧���������ͣ���֧�ָ�������
1999����ͬ����II�������Ƴ���SSE��Streaming SIMD Extensions�������ֲ���MMX��֧�ָ������IJ��㣬����MMX���˺ܶ�Ľ��������ѼĴ����Ŀ�����չΪ128λ�����Ҳ��ٸ���x87�Ĵ�������������70���µ�ָ�
2008�깫����AVX��Advanced Vector Extensions����һ���ѼĴ����Ŀ�����չΪ256λ�����Ҹ�����ָ���ʽ��֧����Ŀ�������2011�귢����Sandy
Bridge������������AVX������

ͼ5 ����ILLIAC IVǿ���д��������Ŀ�ͨ��

ͼ6 IA CPU�ϵ�SIMDʵ��
����Ӷ��š����ɹ�����ѧ������ѧ���Ƶij��������ϵͳ����ֵ�����ٶȿ��Դﵽÿ��5.49���ڴΡ����������ٶ�ÿ��3.39���ڴΡ���2014��11��17�չ�����ȫ�������500ǿ���У�����Ӷ��š����йھ�����Ӷ����Ǹ��Ӵ��ϵͳ����������Ƶļ���ڵ���ɣ���˵ÿ���ڵ��������Xeon������������Xeon
PhiЭ�������㿨��Xeon Phi����ǿ��IJ��м�������������ļ���������ΪAVX-512��SIMD������AVX-512�Ƕ�AVX������չ���Ĵ����Ŀ�����չΪ512λ������Ҳ�Ӵ�һ������16����ߵ�32����
���������Ѿ�������SIMD��˼�롢��ʷ�Լ���X86�ܹ�CPU��ʵ�֣���������ͨ��һ�������ͼ����ʵ����������ΰ�SIMD����Ӧ�õ�C++��Ŀ�̽�����ײ�ͬ�Ķ��ַ������Լ���κ�����ȡ�õ�����������
��C++������ʹ��SIMD����
ͼ7�г���ʹ��SIMD�����Ķ��ַ����������Ȱ��������µ�˳���Ҫ����ÿһ�֣�Ȼ���ص���ܻ�����Է�����

ͼ7 ʹ��SIMD�����Ķ��ַ���
��һ�ַ�����ʹ��������IPP�⣬IPP��ȫ����Intel Integrated Performance
Primitives�� ��Ӣ�ض���˾������һ��ƽ̨���������⣬�ṩ�˷dz��㷺�Ĺ��ܣ��������ֳ��õ�ͼ��ͼ������Ƶ������������Ϊ���еĺܶຯ�����Ѿ�ʹ��SIMD���������Ż�������ʹ���������ʹ��SIMD������һ�����;����ͨ������https://software.intel.com/en-us/intel-ipp/
���Է���IPP�Ĺٷ����ܣ��˽������Ϣ��
�ڶ��ַ�����ʹ�ñ��������Զ���������Auto-vectorization��֧�֡�����ͼ8����Visual
Studio��C++����ͨ����Ŀ���ԶԻ��������Զ��������Ľ�ͼ��

ͼ8 ��Visual Studio�������Զ�������֧��
�����߷������������ú����õij�����ȷʵʹ����һЩSIMDָ�����ͼ9�Ҳ���ɫ������һ��ʹ�õı���SSE2�е�cvtsi2sdָ������Խ�Դ�������е��з���˫������ת����Ŀ��������е�˫���ȸ���ֵ��
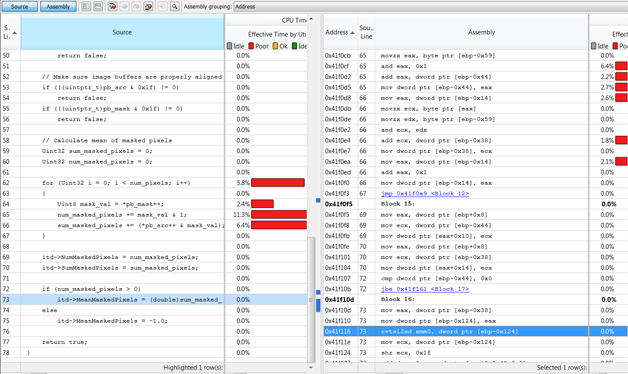
ͼ9 �۲�������Զ�������������SIMDָ��
���ʹ��GCC����������ô����ʹ�����������������������룺
gcc -O3 -o hisimd -ftree-vectorize -msse2 hisimd.c |
���ϣ����������������ȡ����������������ô��������-ftree-vectorizer-verbose=1�����ǿ�������ͼ10�������Ϣ��

ͼ10 ʹ��GCC���Զ�������֧��
ʹ��GDB�ķ����ܣ����Ժ����ع۲쵽GCC������SIMDָ���ͼ11��ʾ��

ͼ11 GCC���Զ����������ܲ����Ļ��ָ��
�����ַ�����ʹ�ñ�����ָʾ����compiler directive�������磬���ʹ��Ӣ�ض���C/C++��������ICC���������´��룬��ôICC����#pragma
simdָʾ�������forѭ�������������������������������������Ϣ��remark: SIMD LOOP
WAS VECTORIZED.
int a[256], b[256], c[256];
void foo () {
int i; #pragma simd
for (i=0; i<256; i++){
a[i] = b[i] + c[i];
}
} |
�����ַ�����ʹ��Cilk������Cilkһ��Դ�ڷ��������Silkһ�ʣ��̺�����˼��Ҫ�Ѳ��б��������˿��һ��������Cilk����������MIT��������һ�汾��1994�귢�������������ߴ�����һ������
Cilk Arts�Ĺ�˾���Ƴ��Ľ���˽�а汾��2009�꣬Ӣ�ض��չ���Cilk Arts����Cilk�������Ͻ�Ӣ�ض��������С�2012���Cilk�ٴγ�Ϊ��Դ��Ŀ��GCC�б���֧�֣���Ҫ4.8���߸��߰汾��������Ȥ�����ѿ��Դ�https://www.cilkplus.org��վ�˽������Ϣ�������йع���ʾ�����롣
�����ַ�����ʹ�ñ��������ڽ�������intrinsic����������˵���������ѭ����������Ҫ��ϸ���۵�ͼ���ֵ�������C++���롣
for (Uint32 i = 0; i < num_pixels; i++)
*pb_mask++ = (*pb_src++ > threshold) ? 0xff : 0x00; |
���ʹ��Visual C++��������SIMD intrinsic���и�д����ô�µĴ������嵥1��ʾ��
�嵥1 ͨ��intrinsicʹ��SIMD����
pimask = _mm_cvtsi32_si128(0);
piscale = _mm_cvtsi32_si128(0x80);
piscale = _mm_shuffle_epi8(piscale, pimask);
pithreshold = _mm_cvtsi32_si128(threshold);
pithreshold = _mm_shuffle_epi8(pithreshold, pimask);
pithreshold = _mm_sub_epi8(pithreshold, piscale);
for (Uint32 i = 0; i < num_pixels; i += 16)
{ pipixels = *(__m128i*)(pb_src+i);
pipixels = _mm_sub_epi8(pipixels, piscale);
*((__m128i*)(pb_mask+i)) =
_mm_cmpgt_epi8(pipixels, pithreshold); } |
�����ַ�����ֱ��ʹ�û�����Ա�д��ຯ����Ȼ���ٴ�C++�����е��û�ຯ�����Ժ����ϸ���ܡ�
�Ƚ�ͼ7�е����ַ��������ȺͿɿ�����������Խ��Խ�ߣ�����ʹ�õ��ѶȻ���Ҳ��Խ��Խ��

��д�͵��Թ�SIMD��ຯ��
�����ַ���������C++��Ŀ��ʹ�û����룬һ����ͨ��__asm{}������ָʾ���Űѻ�����Ƕ����C++�����У���һ���ǰѻ�������ڵ�������.asm��β���ļ��С�ǰһ�ַ�����Ϊ��֧��64λ�����Ի�����ʱ�ˡ�
��ʹ�ú�һ�ַ���ʱ������Ҫ����Ŀ��Solution Explorer���οؼ����һ�ϣ���������ļ�����Ŀ��Ȼ��ѡ��Build
Dependencies �� Build Customizations����ͼ6��ʾ�ĶԻ���Ȼ��ѡ��masm�С�

��ϸ������α�д�����볬���˱��ĵķ�Χ������ֻ�ܹ��п������������������۵�forѭ�����嵥1�Ϸ�����Ӧ��һ�λ��ָ����ԡ��ִ�x86������Գ�����ơ�һ�飩�����嵥2��ʾ��
�嵥2 �ԻҶ�ͼ����ж�ֵ��������SSE2������Ƭ��

���ڳ���û��д��Ϥ�������ͬ�У������嵥2�еĴ��������Щ���ѣ��ر������е�SIMDָ����潫�Ա��߹��õĵ��Է���������������⡪���ڵ������SIMD��
���嵥2�ĵ�һ��ָ����öϵ㣨����C++���������öϵ㷽����ͬ��������������������ຯ�����ϵ����к����߹�����ָ�
movzx eax,byte ptr [edx+ITD.Threshold]
|
��˵������ָ����ǰ�edxָ���ITD�ṹ���Threshold�ֶθ���EAX�Ĵ�����
��ര�ڣ�������ָ��Ϊ��
movzx eax,byte ptr [edx+0Ch] |
����ζ�ţ�Threshold�ֶ��ڽṹ���е�ƫ����0xC��Ctrl + Alt + A����Visual
Studio������ڣ��۲��ڴ�ͼĴ�����ֵ������ӡ֤��

����������ָ������þ��ǰѶ�ֵ������ֵ���ص�EAX�Ĵ�����
������һ��ָ��Ƚϼ�movd xmm1,eax�����ǰѳ���Ĵ���EAX�д�ŵ���ֵ���ݸ�SSE��SSE�Ĵ���XMM1��Visual
Studio�ļĴ�������Ĭ�ϲ���ʾSIMD�ļĴ��������ǿ���ͨ����ݲ˵��������������⣬����Ҽ�������ͼ12��ʾ�Ŀ�ݲ˵���ѡ��SSE���ɡ�

ͼ12 ������ʾSSE�Ĵ���
ѡ��SSE����ִ�У��ٹ۲�Ĵ������ڣ����Կ���XMM1��ֵ���£�
XMM1 = 00000000000000000000000000000098 |
������������ָ����Ҫ���Ѿ���XMM1����ֽ��е���ֵ��0x98��ɢ�У�shuffle���������ֽ��С�
pxor xmm0,xmm0
pshufb xmm1,xmm0 |
����ָ���е�p����packed�������������SIMD�еij������pshufb��Packed Shuffle
Bytes����д�������ݵڶ���������ָ���Ŀ�������Ե�һ��������ִ��ɢ�в���������һ������������������Ƚ��ֿڣ�����ִ��������ָ���һ��Ч����Ҿ������ˣ�
XMM0 = 00000000000000000000000000000000
XMM1 = 98989898989898989898989898989898 |
��Ȥ�ɡ�������������ָ�movdqa xmm2,xmmword ptr [PixelScale]���ǰ�PixelScale���������е�����ֵ����XMM2��
PixelScale byte 32 dup(80h) |
ִ�к�XMM2��ֵΪ��
XMM2 = 80808080808080808080808080808080 |
��������ָ��������ϼ���������SIMD��ɫ�IJ�����
����ǰ�����Ĵ�����ֵΪ��
XMM1 = 98989898989898989898989898989898
XMM2 = 80808080808080808080808080808080
|
��������
XMM1 = 18181818181818181818181818181818
XMM2 = 80808080808080808080808080808080 |
Ҳ����һ�����16������������
�����������������Ϳ�ʼ����ESIָ���ͼ�������ˣ�movdqa xmm0,[esi]ÿ�ο���16���ֽڼ��ص�XMM0��psubb
xmm0,xmm2��ȥ����ֵ��128����Ȼ��ʹ����������pcmpgtbָ����бȽϡ�
pcmpgtb��ȫ����Compare packed signed byte integers for
greater than��������ݱȽϽ������Ŀ���ֽ�дΪȫ0����ȫ1�����ڣ������磬����ǰ��XMM0��XMM1����ǣ�
XMM0 = 80808012808080801080808080808320
XMM1 = 18181818181818181818181818181818 |
��ô��������ǣ�
XMM0 = 000000000000000000000000000000FF
XMM1 = 18181818181818181818181818181818 |
����movdqa [edi],xmm0ָ��ѽ��д��EDIָ���Ŀ�껺�����С�Ȼ���ESI��EDI������16��������һ��ѭ����
ͼ13�DZȽϱ�д�IJ��Գ�����棬�б��ؼ��а������Բ�ͬ��ʽ��ͬһ��ͼ��ִ�ж�ֵ��������������ʱ�䡣

ͼ13 �Ƚϲ�ͬ���㷽ʽ�IJ��Գ���
��ͼ13���Կ���������ͨ��C++���루ͼ����ALU��ʾ����ȣ�ʹ��SSE�������ٶ������Ƿdz����Եģ���ԭ����1000����룬�ӿ쵽��10/20����룬�����SIMD��������ƪ����ϵ��Ҫ�ʹ˴�ס�ˣ�����Ȥ�����ѿ�������ʾ�����������Դ���루http://advdbg.org/����Դ��飩��������һ�¡�
|





