| 编辑推荐: |
文章介绍了c++关联容器,并且阐述了两个主要的关联容器类型map与set的详细用法,希望对您有所帮助。
文章来自于csdn,由火龙果Luca编辑推荐。 |
|
三、关联容器
关联容器与序列容器有着根本性的不同,序列容器的元素是按照在容器中的位置来顺序保存和访问的,而关联容器的元素是按关键元素来保存和访问的。关联容器支持高效的关键字查找与访问。两个主要的关联容器类型是map与set。
1.set
1.1 简介:set里面每个元素只存有一个key,它支持高效的关键字查询操作。set对应数学中的“集合”。
1.2 特点:
储存同一类型的数据元素(这点和vector、queue等其他容器相同)
每个元素的值都唯一(没有重复的元素)
根据元素的值自动排列大小(有序性)
无法直接修改元素
高效的插入删除操作
1.3 声明:set<T> a
1.4 常用函数
以下设 set<T> a,其中a是T类型的set容器。
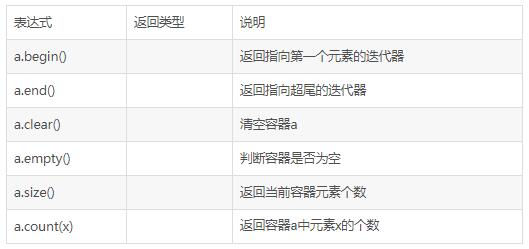
1.6 插入元素:
a.insert(x) :其中a为set<T>型容器,x为T型变量
set<int>
a={0,1,2,9};
a.insert(6);
for(auto it = a.begin();it != a.end();it++) cout
<< *it;//输出01269 |
a.insert(first,second):其中first为指向区间左侧的迭代器,second为指向右侧的迭代器。作用是将first到second区间内元素插入到a(左闭右开)。
set<int>
a = {0,1,2,9};
set<int> b = {3,4,5};
auto first = b.begin();
auto second = b.end();
a.insert(first,second);
for(auto it = a.begin();it != a.end();it++) cout
<< *it; |
插入元素会自动插入到合适的位置,使整个集合有序
1.7 删除元素:
a.erase(x):删除建值为x的元素
a.erase(first,second):删除first到second区间内的元素(左闭右开)
a.erase(iterator):删除迭代器指向的元素
set中的删除操作是不进行任何的错误检查的,比如定位器的是否合法等等,所以用的时候自己一定要注意。
1.8 lower_bound 和 upper_bound 迭代器:
lower_bound(x1):返回第一个不小于键参数x1的元素的迭代器
upper_bound(x2):返回最后一个大于键参数x2的元素的迭代器
由以上俩个函数,可以得到一个目标区间,即包含集合中从'x1'到'x2'的所有元素
#include<iostream>
#include<set>
#include<algorithm>
using namespace std;
int main()
{
set<int> a = {0,1,2,5,9};
auto it2 = a.lower_bound(2);//返回指向第一个大于等于x的元素的迭代器
auto it = a.upper_bound(2);//返回指向第一个大于x的元素的迭代器
cout << *it2 << endl;//输出为2
cout << *it << endl;//输出为5
return 0;
} |
1.9 set_union() 与 set_intersection()
set_union():对集合取并集
set_union()函数接受5个迭代器参数。前两个迭代器定义了第一个集合的区间,接下来的俩个迭代器定义了第二个集合的区间,最后一个迭代器是输出迭代器,指出将结果集合复制到什么位置。例如:要将A与B的集合复制到C中,可以这样写:
#include<iostream>
#include<set>
#include<algorithm>
using namespace std;
int main()
{
set<int> A = {1,2,3}, B= {2,4,5},C;
set_union(A.begin(),A.end(),B.begin(),B.end(),
insert_iterator<set<int> >(C,C.begin()));
for(auto it = C.begin();it != C.end();it++)
cout << *it <<" ";
return 0;
} |
注意:
其中第五个参数不能写C.begin(),原因有两个:首先,关联集合将建看作常量,所以C.begin()返回的迭代器是常量迭代器,不能作为输出迭代器(详情请参考迭代器相关概念)。其次,与copy()相同,set_union()将覆盖容器中已有的数据,并且要求容器用足够的空间容纳新信息,而C不满足,因为它是空的。
解决方法:可以创建一个匿名的insert_iterator,将信息复制给C。如上述代码所为。另一种方法如下:
set_union(A.begin(),A.end(),B.begin(),B.end(),
inserter(C,C.begin()));//调用inserter |
set_intersection():对集合取交集,它的接口与set_union()相同。
附:使用set_union()和set_intersection()还有另一种技巧。由于需要五个迭代器,看起来会很累赘和麻烦,如果多次使用会增加出错的几率,所以我们可以试试用宏定义的方法来简化代码。如下:
#include<iostream>
#include<set>
#include<algorithm>
using namespace std;
#define ALL(x) x.begin(),x.end()
#define INS(x) inserter(x,x.begin())
int main()
{
set<int> A = {1,2,3}, B= {2,4,5},C;
set_union(ALL(A),ALL(B),INS(C));
for(auto it = C.begin();it != C.end();it++)
cout << *it <<" ";
return 0;
} |
其中使用到了宏定义。
1.10 set的几个问题:
(1)为何map和set的插入删除效率比用其他序列容器高?
因为对于关联容器来说,不需要做内存拷贝和内存移动。set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点也OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
(2)为何每次insert之后,以前保存的iterator不会失效?
iterator这里就相当于指向节点的指针,内存没有变,指向内存的指针怎么会失效呢(当然被删除的那个元素本身已经失效了)。相对于vector来说,每一次删除和插入,指针都有可能失效,调用push_back在尾部插入也是如此。因为为了保证内部数据的连续存放,iterator指向的那块内存在删除和插入过程中可能已经被其他内存覆盖或者内存已经被释放了。即使时push_back的时候,容器内部空间可能不够,需要一块新的更大的内存,只有把以前的内存释放,申请新的更大的内存,复制已有的数据元素到新的内存,最后把需要插入的元素放到最后,那么以前的内存指针自然就不可用了。特别时在和find等算法在一起使用的时候,牢记这个原则:不要使用过期的iterator。
(3)当数据元素增多时,set的插入和搜索速度变化如何?
如果你知道log2的关系你应该就彻底了解这个答案。在set中查找是使用二分查找,也就是说,如果有16个元素,最多需要比较4次就能找到结果,有32个元素,最多比较5次。那么有10000个呢?最多比较的次数为log10000,最多为14次,如果是20000个元素呢?最多不过15次。看见了吧,当数据量增大一倍的时候,搜索次数只不过多了1次,多了1/14的搜索时间而已。你明白这个道理后,就可以安心往里面放入元素了。
2.map
2.1 简介:如果说set对应数学中的“集合”,那么map对应的就是“映射”。map是一种key-value型容器,其中key是关键字,起到索引作用,而value就是其对应的值。与set不同的是它支持下标访问。头文件是<map>
2.2 特点:
增加和删除节点对迭代器的影响很小(高效的插入与删除)
快速的查找(同set)
自动建立key-value的对应,key和value可以是任何你需要的类型
可以根据key修改value的记录
支持下标[]操作
2.3 声明:map<T1,T2> m
其中T1是key类型,T2是value类型,m就是一个T1-T2的key-value。
| map<string,int>
m;//声明一个key为string,value为int的map型容器 |
下述代码更清楚的解释了map容器的特点:
#include<iostream>
#include<map>
using namespace std;
int main()
{
map<string,int> m;
m["abc"] = 5;
m["cdf"] = 6;
m["b"] = 1;
for(auto it = m.begin();it != m.end();it++)
cout << it->first <<" "
<< it->second << endl;
return 0;
} |
在上述代码中,m容器被按照key的字典序升序排列了,而且我们可以通过将key当作索引来获取value的值。(同时这也是一种插入方法)
2.4 插入元素:
使用insert()函数插入pair类型的元素
使用下标操作向map容器中插入元素
map<string,int>
m;
m.insert(make_pair("b",6));//insert插入
m["a"] = 5;//使用下标插入 |
2.5 删除元素:
erase(key):删除键为key的元素
erase(it):删除迭代器it所指向的元素
#include<iostream>
#include<map>
using namespace std;
int main()
{
map<string,int> m;
m.insert(make_pair("b",6));
m["a"] = 5;
m["c"] = 5;
m["d"] = 5;
m["e"] = 5;
m.erase("d");
auto pr = m.begin();
m.erase(pr);
for(auto it = m.begin();it != m.end();it++)
cout << it->first <<" "
<< it->second << endl;
return 0;
} |
2.6 map容器的遍历:
使用迭代器遍历(代码如上)
注:使用迭代器遍历map容器,其中每一个元素可以看成是pair类型的,访问第一个位置的key值可以用it->first访问,第二个位置value的值可以用it->second访问,其中it是指向该元素的迭代器。
2.7 常用函数:
下表中m为map类型的容器,it为和m同类型的迭代器,key表示该类型的一个键。
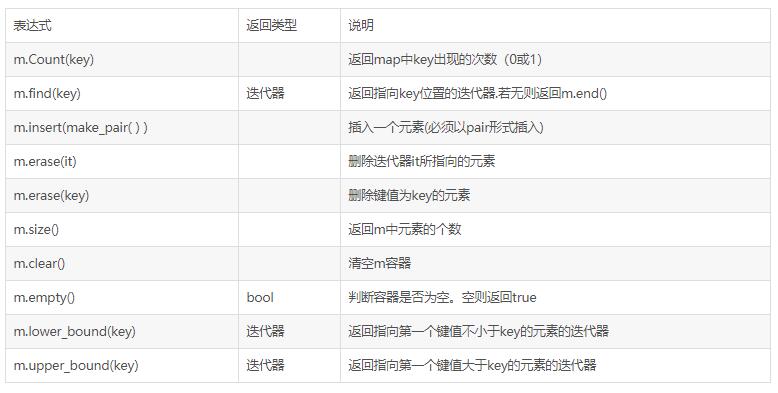
3.重要例题:
题目来自UVa12096
有一个专门为了集合运算而设计的“集合栈”计算机。该机器有一个初始为空的栈,并且支持以下操作:
PUSH:空集“{}”入栈
DUP:把当前栈顶元素复制一份后再入栈
UNION:出栈两个集合,然后把二者的并集入栈
INTERSECT:出栈两个集合,然后把二者交集入栈
ADD:出栈两个集合,然后把先出栈的集合加入到后出栈的集合中,把结果入栈
每次操作后,输出栈顶集合的大小(即元素个数)。例如,栈顶元素是A={ {},{ {} } },,下一个元素是B=
{ {},? { { {} } }? },则:
UNION操作将得到{ {},{ {} },{ { {} } }? },输出3
INTERSECT操作将得到{ {} },输出1
ADD操作将得到{ {},{ { {} } } ,{ {},{ {} } }? },输出3
输出不超过2000个操作,并且保证操作均能顺利进行(不需要对空栈执行出栈操作)
#include<cstdio>
#include<iostream>
#include<algorithm>//set_union等函数定义在这里
#include<vector>
#include<set>
#include<map>
#include<stack>
#define ALL(x) x.begin(),x.end()
#define INS(x) inserter(x,x.begin()) //注意宏的括号和inserter
using namespace std;
typedef set<int> Set;
map<Set,int> IDCache;
vector<Set> setCache;
int t,n;
char cmd[10];
int getID(Set s){
if(IDCache.count(s))return IDCache[s];
setCache.push_back(s); //将新集合加入Setcache
return IDCache[s]=setCache.size()-1;//将ID加入map
,同时返回新分配的ID值
}
int main(){
scanf("%d",&t);
while(t--){
scanf("%d",&n);
// setCache.clear();
stack<int> s;
while(n--){
scanf(" %s",&cmd);
if(cmd[0]=='P')s.push(getID(Set()));
else if(cmd[0]=='D')s.push(s.top());
else{
Set s1=setCache[s.top()];s.pop();
Set s2=setCache[s.top()];s.pop();
Set x;
if(cmd[0]=='U')set_union(ALL(s1),ALL(s2),INS(x));
if(cmd[0]=='I')set_intersection(ALL(s1),ALL(s2),INS(x));
if(cmd[0]=='A'){ x=s2; x.insert(getID(s1)); }
s.push(getID(x));
}
printf("%d\n",setCache[s.top()].size());
}
puts("***");
}
} |
代码出自:《算法竞赛入门经典(第二版)》――刘汝佳
|








