| 编辑推荐: |
本文主要介绍了CUDA编程入门相关知识。 希望能为大家提供一些参考或帮助。
文章来自于简书,由火龙果Linda编辑推荐。 |
|
1. CPU vs. GPU
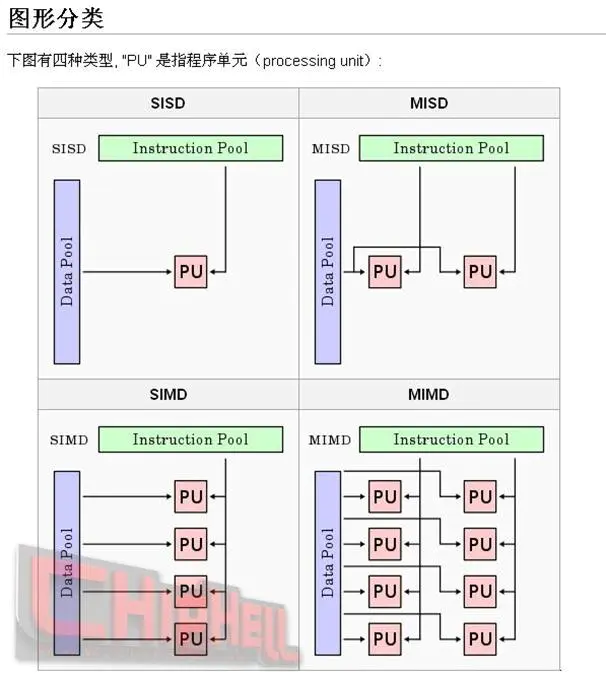
1.1 四种计算机模型
GPU设计的初衷就是为了减轻CPU计算的负载,将一部分图形计算的功能设计到一块独立的处理器中,将矩阵变换、顶点计算和光照计算等操作从
CPU 中转移到 GPU中,从而一方面加速图形处理,另一方面减小了 CPU 的工作负载,让 CPU
有时间去处理其它的事情。
在GPU上的各个处理器采取异步并行的方式对数据流进行处理,根据费林分类法(Flynn's Taxonomy),可以将资讯流(information
stream)分成指令(Instruction)和数据(Data)两种,据此又可分成四种计算机类型:
单一指令流单一数据流计算机(SISD):单核CPU
单一指令流多数据流计算机(SIMD):GPU的计算模型
多指令流单一数据流计算机(MISD):流水线模型
多指令流多数据流计算机(MIMD):多核CPU
1.2 CPU 与 GPU 结构差异
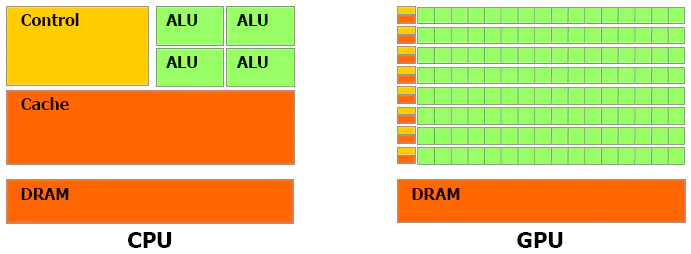
1.3 CPU设计理念:低延时
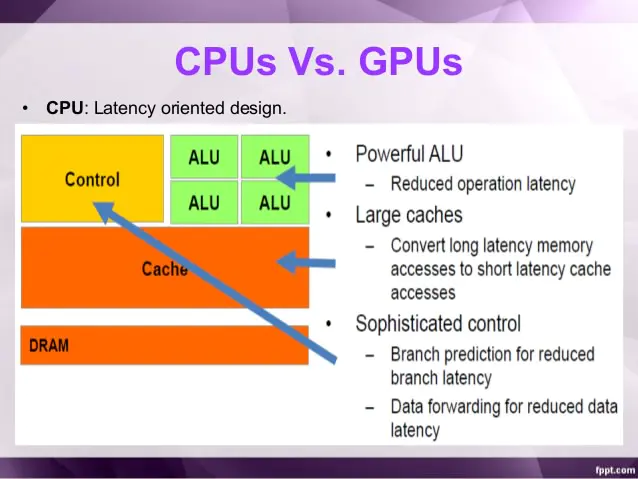
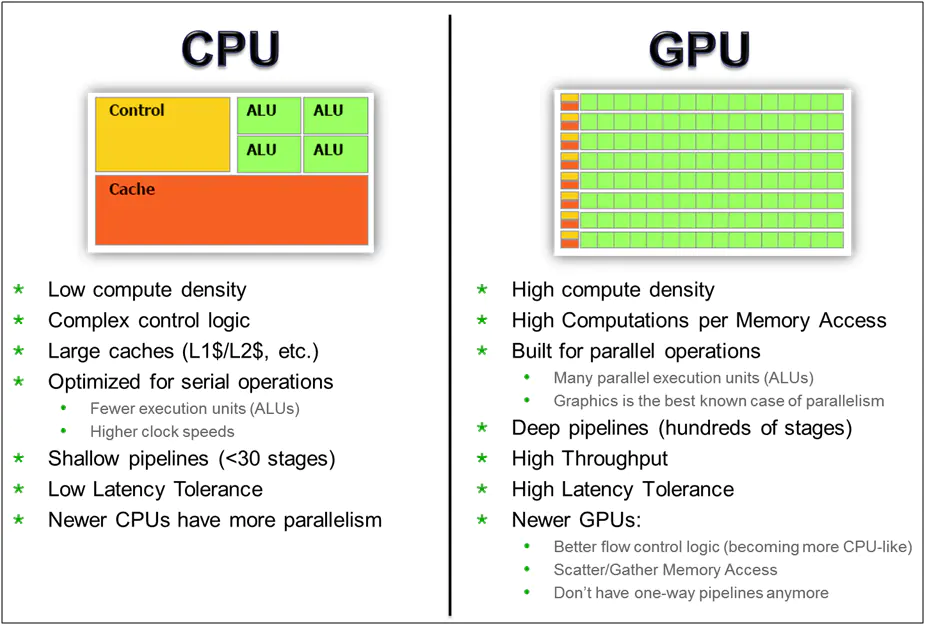
■ ALU:CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期。
CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方).
■ Cache:大的缓存也可以降低延时。保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
■ Control:复杂的逻辑控制单元。
当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。
1.4 GPU设计理念:大吞吐量
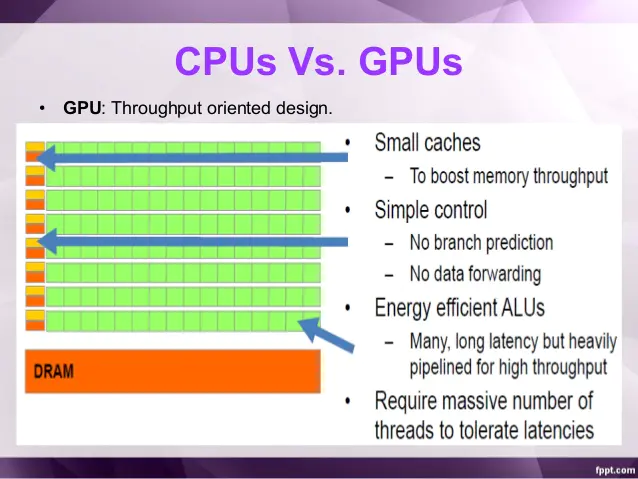
■ ALU,Cache:GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
■ Control:控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多的thread. 为了平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的Threads.通常来看GPU
ALU会有非常重的pipeline就是因为这样。
2. Nvidia GPU架构
2.1 硬件架构
■ SP:最基本的处理单元,streaming processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
■ SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp
scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared
memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active
warps有非常严格的限制,也就限制了并行能力。
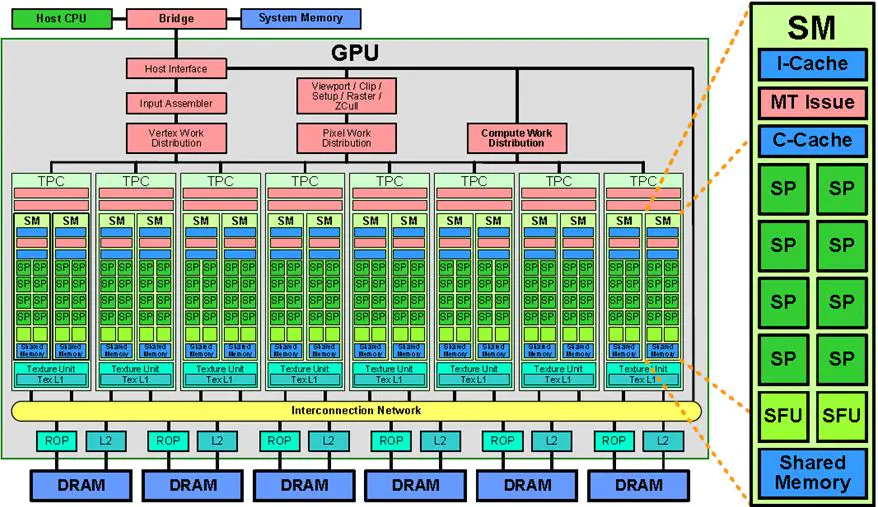
具有Tesla架构的GPU是具有芯片共享存储器的一组SIMT(单指令多线程)多处理器。它以一个可伸缩的多线程流处理器(Streaming
Multiprocessors,SMs)阵列为中心实现了MIMD(多指令多数据)的异步并行机制,其中每个多处理器包含多个标量处理器(Scalar
Processor,SP),为了管理运行各种不同程序的数百个线程,SIMT架构的多处理器会将各线程映射到一个标量处理器核心,各标量线程使用自己的指令地址和寄存器状态独立执行。
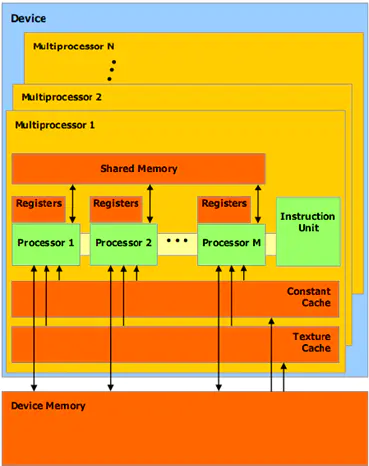 GPU的共享存储器的SIMT多处理器模型
如上图所示,每个多处理器(Multiprocessor)都有一个属于以下四种类型之一的芯片存储器:
每个处理器上有一组本地 32 位寄存器(Registers);
并行数据缓存或共享存储器(Shared Memory),由所有标量处理器核心共享,共享存储器空间就位于此处;
只读固定缓存(Constant Cache),由所有标量处理器核心共享,可加速从固定存储器空间进行的读取操作(这是设备存储器的一个只读区域);
一个只读纹理缓存(Texture Cache),由所有标量处理器核心共享,加速从纹理存储器空间进行的读取操作(这是设备存储器的一个只读区域),每个多处理器都会通过实现不同寻址模型和数据过滤的纹理单元访问纹理缓存。
多处理器 SIMT 单元以32个并行线程为一组来创建、管理、调度和执行线程,这样的线程组称为 warp
块(束),即以线程束为调度单位,但只有所有32个线程都在诸如内存读取这样的操作时,它们就会被挂起,如下所示的状态变化。当主机CPU上的CUDA程序调用内核网格时,网格的块将被枚举并分发到具有可用执行容量的多处理器;SIMT
单元会选择一个已准备好执行的 warp 块,并将下一条指令发送到该 warp 块的活动线程。一个线程块的线程在一个多处理器上并发执行,在线程块终止时,将在空闲多处理器上启动新块。
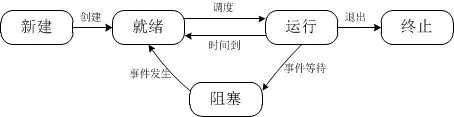 CPU五种状态的转换
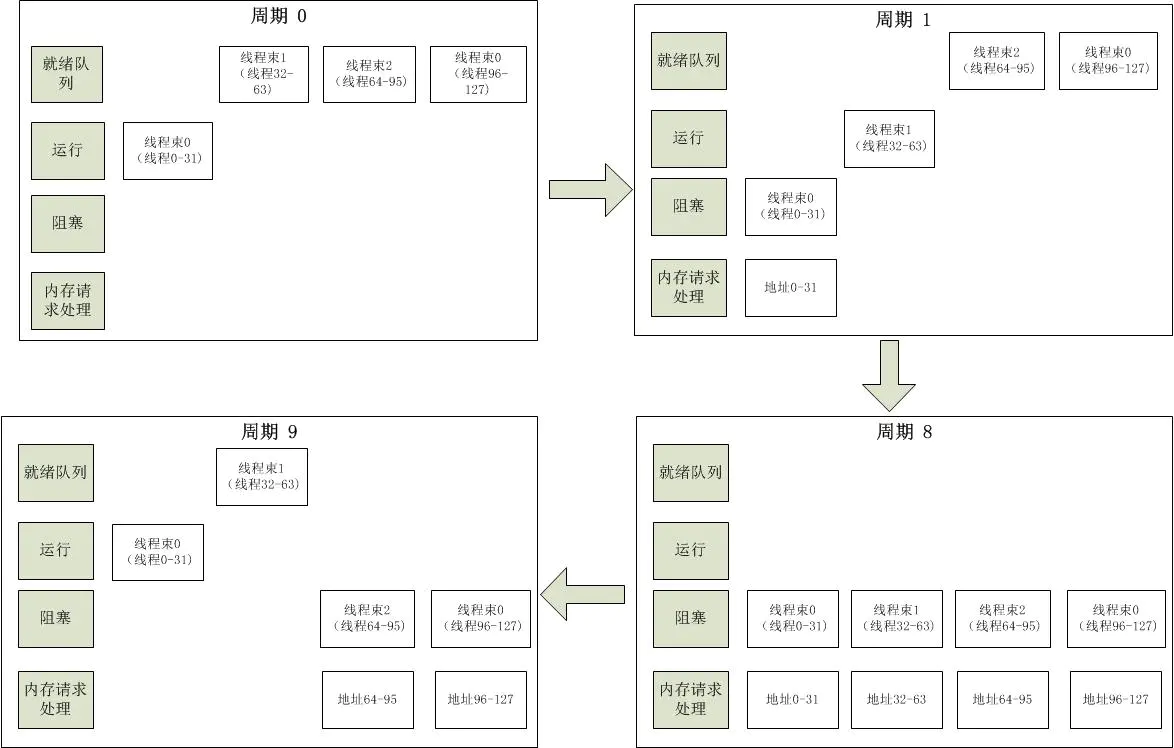
线程束调度变化
2.2 软件架构
CUDA是一种新的操作GPU计算的硬件和软件架构,它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。目前Tesla架构具有在笔记本电脑、台式机、工作站和服务器上的广泛可用性,配以C/C++语言的编程环境和CUDA软件,使这种架构得以成为最优秀的超级计算平台。
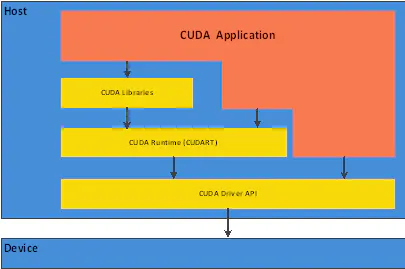 CUDA软件层次结构
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA
提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
■ thread:一个CUDA的并行程序会被以许多个threads来执行。
■ block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared
memory通信。
■ grid:多个blocks则会再构成grid。
■ warp:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓
SIMT。
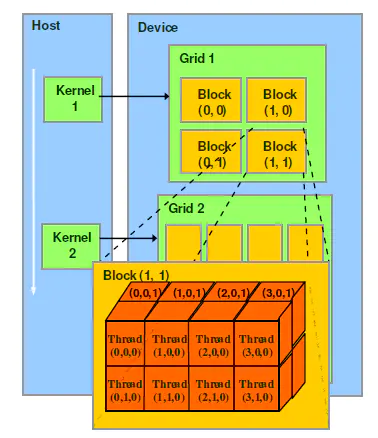
2.3 软硬件架构对应关系
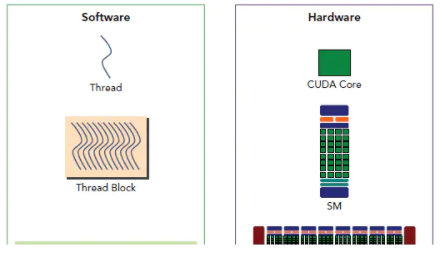
1)SM像一个独立的CPU core
从软件上看,SM更像一个独立的CPU core。SM(Streaming Multiprocessors)是GPU架构中非常重要的部分,GPU硬件的并行性就是由SM决定的。以Fermi架构为例,其包含以下主要组成部分:
CUDA cores
Shared Memory/L1Cache
Register File
Load/Store Units
Special Function Units
Warp Scheduler
2)同一个block的threads在同一个SM并行执行
GPU中每个sm都设计成支持数以百计的线程并行执行,并且每个GPU都包含了很多的SM,所以GPU支持成百上千的线程并行执行。当一个kernel启动后,thread会被分配到这些SM中执行。大量的thread可能会被分配到不同的SM,同一个block中的threads必然在同一个SM中并行(SIMT)执行。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single
Instruction Multiple Thread。
3)warp是调度和运行的基本单元,一个warp占用一个SM运行
一个SP可以执行一个thread,但是实际上并不是所有的thread能够在同一时刻执行。Nvidia把32个threads组成一个warp,warp是调度和运行的基本单元。warp中所有threads并行的执行相同的指令。一个warp需要占用一个SM运行,多个warps需要轮流进入SM。由SM的硬件warp
scheduler负责调度。目前每个warp包含32个threads(Nvidia保留修改数量的权利)。所以,一个GPU上resident
thread最多只有 SM*warp个。
block是软件概念,一个block只会由一个sm调度,程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps
scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。一个SM可以同时拥有多个blocks,但需要序列执行。下图显示了软件硬件方面的术语对应关系:
需要注意的是,大部分threads只是逻辑上并行,并不是所有的thread可以在物理上同时执行。例如,遇到分支语句(if
else,while,for等)时,各个thread的执行条件不一样必然产生分支执行,这就导致同一个block中的线程可能会有不同步调。另外,并行thread之间的共享数据会导致竞态:多个线程请求同一个数据会导致未定义行为。CUDA提供了cudaThreadSynchronize()来同步同一个block的thread以保证在进行下一步处理之前,所有thread都到达某个时间点。
同一个warp中的thread可以以任意顺序执行,active warps被sm资源限制。当一个warp空闲时,SM就可以调度驻留在该SM中另一个可用warp。在并发的warp之间切换是没什么消耗的,因为硬件资源早就被分配到所有thread和block,所以该新调度的warp的状态已经存储在SM中了。不同于CPU,CPU切换线程需要保存/读取线程上下文(register内容),这是非常耗时的,而GPU为每个threads提供物理register,无需保存/读取上下文。
4)SIMT和SIMD
CUDA是一种典型的SIMT架构(单指令多线程架构),SIMT和SIMD(Single Instruction,
Multiple Data)类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行官单元来实现并行。一个主要的不同就是,SIMD要求所有的vector
element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。SIMT有三个SIMD没有的主要特征:
每个thread拥有自己的instruction address counter
每个thread拥有自己的状态寄存器
每个thread可以有自己独立的执行路径
更细节的差异可以看这里。
3. CUDA C编程入门
Nvidia官方教程看这里
3.1 编程模型
CUDA程序构架分为两部分:Host和Device。一般而言,Host指的是CPU,Device指的是GPU。在CUDA程序构架中,主程序还是由
CPU 来执行,而当遇到数据并行处理的部分,CUDA 就会将程序编译成 GPU 能执行的程序,并传送到GPU。而这个程序在CUDA里称做核(kernel)。CUDA允许程序员定义称为核的C语言函数,从而扩展了
C 语言,在调用此类函数时,它将由N个不同的CUDA线程并行执行N次,这与普通的C语言函数只执行一次的方式不同。执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。
在 CUDA 程序中,主程序在调用任何 GPU 内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。
1)线程层次结构
在GPU中要执行的线程,根据最有效的数据共享来创建块(Block),其类型有一维、二维或三维。在同一个块内的线程可彼此协作,通过一些共享存储器来共享数据,并同步其执行来协调存储器访问。一个块中的所有线程都必须位于同一个处理器核心中。因而,一个处理器核心的有限存储器资源制约了每个块的线程数量。在早起的
NVIDIA 架构中,一个线程块最多可以包含 512 个线程,而在后期出现的一些设备中则最多可支持1024个线程。一般
GPGPU 程序线程数目是很多的,所以不能把所有的线程都塞到同一个块里。但一个内核可由多个大小相同的线程块同时执行,因而线程总数应等于每个块的线程数乘以块的数量。这些同样维度和大小的块将组织为一个一维或二维线程块网格(Grid)。具体框架如下图所示。
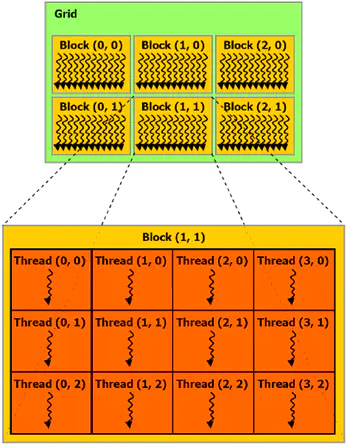 线程块网格
核函数只能在主机端调用,其调用形式为:Kernel<<<Dg,Db, Ns, S>>>(param
list)
Dg:用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3
Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
Db:用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3
Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。一个block中共有Db.xDb.yDb.z个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
Ns:是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared
memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
S:是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
如下是一个CUDA简单的求和程序:
 CUDA求和程序
2)存储器层次结构
CUDA 设备拥有多个独立的存储空间,其中包括:全局存储器、本地存储器、共享存储器、常量存储器、纹理存储器和寄存器,如下图所示。
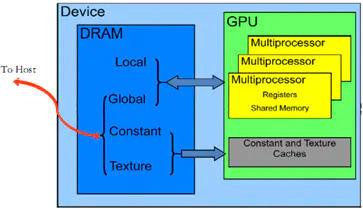 CUDA设备上的存储器
CUDA线程可在执行过程中访问多个存储器空间的数据,如下图所示其中:
每个线程都有一个私有的本地存储器。
每个线程块都有一个共享存储器,该存储器对于块内的所有线程都是可见的,并且与块具有相同的生命周期。
所有线程都可访问相同的全局存储器。
此外还有两个只读的存储器空间,可由所有线程访问,这两个空间是常量存储器空间和纹理存储器空间。全局、固定和纹理存储器空间经过优化,适于不同的存储器用途。纹理存储器也为某些特殊的数据格式提供了不同的寻址模式以及数据过滤,方便
Host对流数据的快速存取。
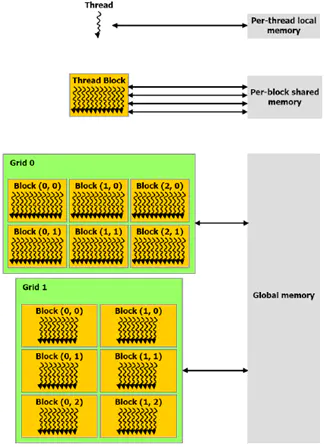 存储器的应用层次
3)主机(Host)和设备(Device)
如下图所示,CUDA 假设线程可在物理上独立的设备上执行,此类设备作为运行C语言程序的主机的协处理器操作。内核在GPU上执行,而C语言程序的其他部分在CPU上执行(即串行代码在主机上执行,而并行代码在设备上执行)。此外,CUDA还假设主机和设备均维护自己的DRAM,分别称为主机存储器和设备存储器。因而,一个程序通过调用CUDA运行库来管理对内核可见的全局、固定和纹理存储器空间。这种管理包括设备存储器的分配和取消分配,还包括主机和设备存储器之间的数据传输。
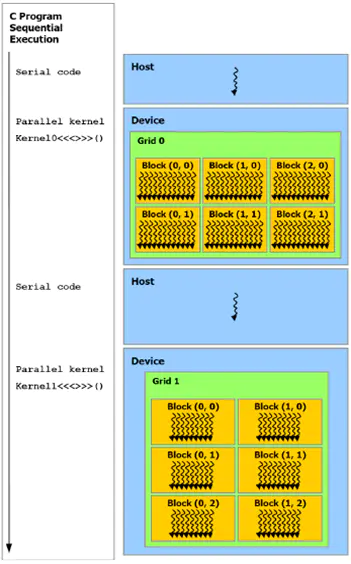 CUDA异构编程模型
3.2 编程入门
3.2.1 CUDA C基础
CUDA C是对C/C++语言进行拓展后形成的变种,兼容C/C++语法,文件类型为".cu"文件,编译器为"nvcc",相比传统的C/C++,主要添加了以下几个方面:
函数类型限定符
执行配置运算符
五个内置变量
变量类型限定符
其他的还有数学函数、原子函数、纹理读取、绑定函数等
1)函数类型限定符
用来确定某个函数是在CPU还是GPU上运行,以及这个函数是从CPU调用还是从GPU调用
device表示从GPU调用,在GPU上执行
global表示从CPU调用,在GPU上执行,也称之为kernel函数
host表示在CPU上调用,在CPU上执行
在计算能力3.0及以后的设备中,global类型的函数也可以调用__global类型的函数。
| #include <stdio.h>
__device__ void device_func(void) {
}
__global__ void global_func(void) {
device_func();
}
int main() {
printf("%s\n", __FILE__);
global_func<<<1,1>>>();
return 0;
} |
2)执行配置运算符
执行配置运算符<<<>>>,用来传递内核函数的执行参数。格式如下:
kernel<<<gridDim, blockDim, memSize, stream>>>(para1,
para2, ...);
gridDim表示网格的大小,可以是1,2,3维
blockDim表示块的·大小,可以是1,2,3维
memSize表示动态分配的共享存储器大小,默认为0
stream表示执行的流,默认为0
para1, para2等为核函数参数
| #include <stdio.h>
__global__ void func(int a, int b) {
}
int main() {
int a = 0, b = 0;
func<<<128, 128>>>(a, b);
func<<<dim3(128, 128), dim3(16, 16)>>>(a,
b);
func<<<dim3(128, 128, 128), dim3(16,
16, 2)>>>(a, b);
return 0;
} |
3)五个内置变量
这些内置变量用来在运行时获得Grid和Block的尺寸及线程索引等信息
gridDim: 包含三个元素x, y, z的结构体,表示Grid在三个方向上的尺寸,对应于执行配置中的第一个参数
blockDim: 包含上元素x, y, z的结构体,表示Block在三个方向上的尺寸,对应于执行配置中的第二个参数
blockIdx: 包含三个元素x, y, z的结构体,分别表示当前线程所在块在网格中x, y, z方向上的索引
threadIdx: 包含三个元素x, y, z的结构体,分别表示当前线程在其所在块中x, y, z方向上的索引
warpSize: 表明warp的尺寸
 线程tid的计算
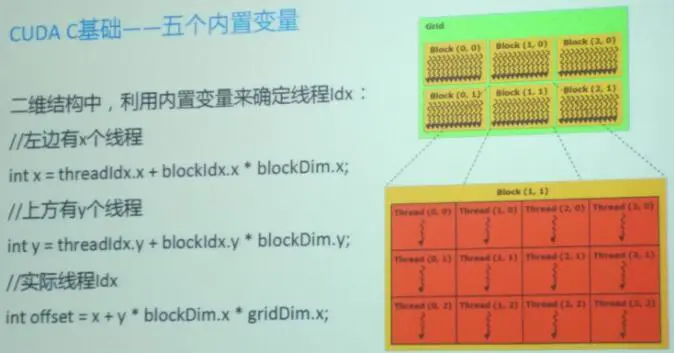 线程tid的计算
4)变量类型限定符
用来确定某个变量在设备上的内存位置
_device_表示位于全局内存空间,默认类型
_share_表示位于共享内存空间
_constant_表示位于常量内存空间
texture表示其绑定的变量可以被纹理缓存加速访问
3.2.2 示例
向量的点积——假设向量大小为N,按照上下文的方法,将申请N的空间,用来存放向量元素互乘的结果,然后在CPU上对N个乘积进行累加。
类似于Map-Reduce:
Map——GPU上对N个变量分别相乘
Reduce——CPU上对N个乘积进行累加
 点积
 点积
|






 订阅
订阅