| 编辑推荐: |
本文主要是针对代码中的数据在内存中的存储情况以及存储中数值的变化来对指针进行介绍,是对指针以及数据在内存中数值是如何变化的,为什么需要使用到指针,为什么有时候使用指针很容易会报错,怎么去使用指针才能让错误尽可能的减少等知识做一个初步的介绍以及分析。
希望能为大家提供一些参考或帮助。
文章来自于博客园,由火龙果Linda编辑推荐。 |
|
本文是对自我学习的一个总结以及回顾,文章内容主要是针对代码中的数据在内存中的存储情况以及存储中数值的变化来对指针进行介绍,是对指针以及数据在内存中数值是如何变化的,为什么需要使用到指针,为什么有时候使用指针很容易会报错,怎么去使用指针才能让错误尽可能的减少等知识做一个初步的介绍以及分析。文章中的每个知识点都会有相应的案例代码及其代码数据所占内存的变化情况分析,然而言语的抽象表达能力是比较晦涩的,所以最好是结合文中图像示例来对其进行理解。
1.数据的保存
前提说明:本节是了解操作系统如何存储c/c++语言中的数据,只要知晓这部分即可,其他不懂的地方在后文有详细介绍。
首先我们需要了解数据在机器中是如何保存的,在计算机中,所有的命令和数据都是被分配了唯一的地址,每种不同类型的数据(以及命令)所占的存储空间不同,但是所有存储都以字节为单位;而每种类型在计算机中所占的字节数因操作系统不同而有所不同,为了便于理解,我们统一默认常用的几个类型数据所占的字节数:int所占存储空间为4个字节,chat为1个字节,指针为4个字节。
由此我们可以得到下图所示:
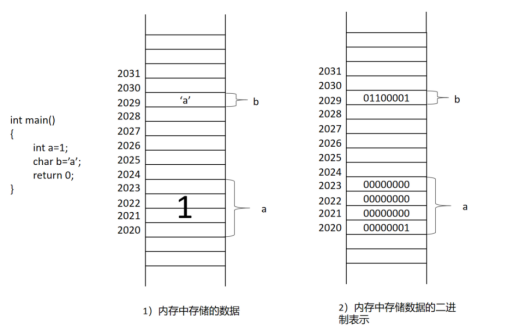
首先最左边是简单的三句代码,a是int类型,其值为1,因为a为int类型,所以a所占的地址是2020-2023(但是为了方便说明,我们一般把a的地址当成是2020,默认其是含有2020-2023四个字节!);b是char类型,其值是’a’,所占地址是2029(变量的地址是操作系统随机分配的,并不固定)上图是变量a和变量b在内存地址中所占字节及其数值的表述,1)是使用十进制来表达,2)是使用二进制来表达(字符的二进制使用ASCII码进行对应)。
对于其他类型数据的存储,与上述int和chat的存储一致,但是其所占字节的大小及其保存的内容不尽相同。
这里多提一点,比如说a所占的地址是四个字节,那么四个字节中的二进制合起来才会是a,但是当用指针取出a所占字节内部的任一一个字节,并且打印出来都会有其对应的数值;比如说用字符指针获得地址2022这一个字节,再用十进制打印其值,就会是0;如果用指针获得地址2020用十进制打印其值,就会是1(后面会有比较具体的介绍)
然后我们需要对编辑器保存数据有一个大概的认识,在我们编写的代码中,数据会被存储在以下四个区域:
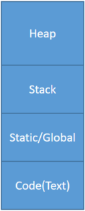
分别为Head,Stack,Static/Global,和Code区域。
其中Head是我们手动申请存储空间时编辑器给我们分配的存储空间,c语言可以使用malloc,remalloc,calloc来申请空间,c++则使用new来分配空间;该区域除非手动销毁空间,不然会一直保存到程序结束。

如图所示,左边分别为c代码和c++代码在Heap中申请空间,正如第一小节所描述的一般,int类型数据在内存中所占的是四个字节,所以这里的整数10是占了四个字节的存储空间,但是这里仅用2020(首字节)来表示其所占的地址。
Stack空间是操作系统按照一定的顺序自动分配和释放空间,即给函数分配了空间,函数一旦结束,函数所占用的空间都会被释放,比如我们有如下一段代码:

在main函数运行时,操作系统会开辟相应的空间来存储main函数内部的变量,此时变量a在stack空间内分配4个字节来存储其值。

当main函数运行到执行Add函数时,会在暂停main函数,再在main函数地址的上面分配空间给Add,同样的也是给Add函数中的变量分配空间

当Add函数执行完毕后,会自动销毁给其分配的空间(如下图所示)然后继续执行main函数,直到main函数结束,退出程序。这里需要注意,传入Add函数的不是a,而是Add函数中的变量b复制了a的数值;因为我们可以在图中看到,a是在main函数中分配的地址,所以不可能把a直接放入Add函数了(其他数据类型也一样,在什么函数里面被定义,就在什么函数里面分配空间)

这里还需要强调一下,从main函数传入Add函数的变量a不是其本身,而是a变量的副本,相当于重新在Add函数中创建了一个该类型的变量b,并且把a的数值赋予给b;而当Add函数结束时,b就会被销毁(所以当我们想调用函数但是不想传入变量进函数时,我们一定要传入该变量的地址!想修改整型变量的值就传入该变量的地址,想改变指针所指向的对象就要传入该指针的地址!这个点很重要,尤其是对后面各种不同指针在函数间的传递)
如果是执行多个函数语句,操作系统会按照先后顺序一个个的往stack空间里面“堆”起来;而只有最上面一个执行完后,才会执行下一个,并且执行完的函数所占有的空间会被释放;比如下面是一个递归函数,递归函数会一次次在stack上面“堆”该函数,直到遇到中止条件,或者是stack泄露从而程序报错,这里因为没有中止条件,所有print函数会不断递归,打印1的语句不会被执行,而且因为Stack内存溢出了,程序会报错停止(递归函数很危险!一定要有返回的语句)

Static/Global是存储带有关键字static和global变量的空间,也就是说单独定义的全局变量和静态变量都会在函数中单独拿出来,独立于其他变量存储;其他所有的函数都能访问他们,并且也只会在程序结束时被释放(全局变量可以简单的认为是定义在所有函数以外的变量,Static变量,即静态变量可以理解为在任何地方定义的变量的前面加上static即是静态变量)。
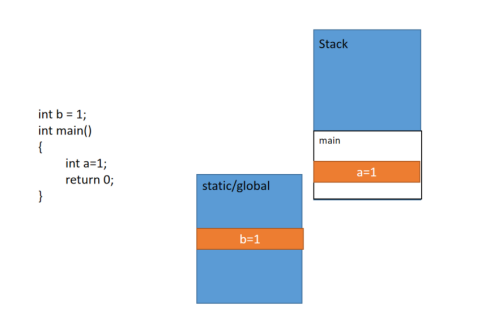
以上所有的变量定义都会针对其类型分配存储空间,所以所有的变量都会有一个地址,这里没有一一把上面所有变量的地址标明出来,仅为强调Static/Global的作用。
Code区域则是存放相应程序语句的空间,即我们所执行的命令都会保存在此。
对于以上四个存储空间我们需要了解他们是存储什么的,什么时候会被使用,什么时候会被销毁,这样对我们理解代码的运行有很大的帮助。后面对指针的分析也会一一使用到上述的存储空间来进行分析讲解,在这里我们需要对它们有一种熟悉感觉,知道他们分别是用来存储什么的即可。
而且十分重要的一点,我们要想真的理解我们所编写的程序,那么我们应该对所写的每一句代码都需要明白它是存储在哪,有什么用;定义声明的变量存储在哪,什么情况下可以改变它,什么情况下无法改变它,诸如此类。(开始可能有点麻烦和琐碎,但是习惯以后会使得我们对程序的理解有很大的帮助)
对以上我们使用一段完整且简单的代码来进行一个简单的总结:
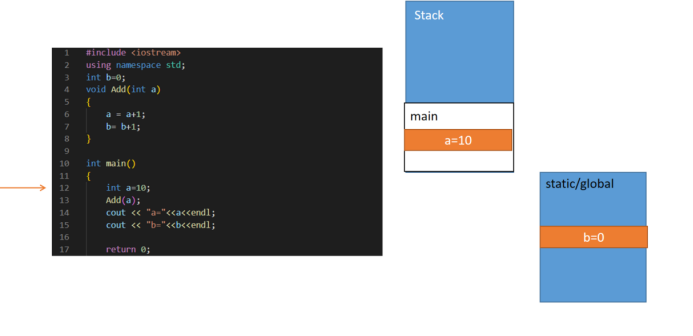
对以上一段c++的代码,我们可以看到我们在定义了全局变量b且初始值为0,则编辑器会给它在global区域中分配空间存储,可以让所有变量或者函数题进行访问;然后我们定义了Add函数以及main函数。程序刚开始运行时,会在stack局域分配给main函数内变量的空间,程序是从上述代码第10行开始运行,会在stack上给main函数分配存储空间,用来存储其定义的变量a;当运行到第13行时,会暂停main函数跳转到Add函数,stack给Add函数分配空间,存储其定义的变量,如下图所示。
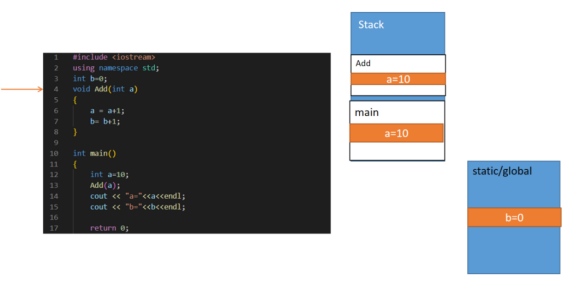
当运行完第7行时,如下图所示:

Add函数中a的数值变成了11,全局变量b的数值变成了1,虽然b没有在Add函数所占有的存储中,但是global变量是允许其访问并且修改其内部变量的值!这里注意,main函数里面的a没有发生变化,因为main函数是暂停了的,我们还在Add函数内运行。
当Add函数运行结束,分配给Add函数的空间被释放,如下图所示:

因为Add函数运行结束,所有我们到了第14行;此时main内部a的数值还是10,没有发生任何变化,但是全局变量b现在的值为1。之后使用cout打印变量a和变量b;分别会得到:a=10
b=1
所以要想让Add函数改变main函数中的变量,就必须在Add函数结束前将其值返回给main函数中的变量;或者是使用指针,把要改变的变量的地址传入函数,即便Add函数不返回其值,也可以对main函数中的变量进行改变。而使用指针将变量的地址传入其他函数,与变量传入其他函数一样,具体的分析我们在介绍完指针后进行介绍。
下面我们对指针进行介绍。
2.指针介绍
1)指针
指针是c/c++中的一种数据类型,它的主要目的是为了直接调用地址并且对其进行操作。就像之前所说的一样,在函数内部定义的变量,会在stack中分配存储空间;全局变量,会在global区域分配空间,如果是自己手动申请的就会在heap分配存储空间。只要是分配了存储空间,那么在程序结束前,变量都有一个唯一的地址,而指针就是去获得变量地址的数据类型,至于为什么要用指针,指针具体是什么,本文简单的举一个例子。
比如你在自己的电脑上编写了一个博客,博客的页面、内容等都包装好放在了电脑里面;此时如果你不上传到网上,那么别人要看你博客时都需要去你的电脑上查看,或者是你把别人需要看的内容复制一份发给别人;显然这样十分浪费时间和存储空间,要是查看一个博客需要把内容全部下载下来,电脑需要十分庞大的存储空间。
所以此时你把博客内容上传到了网上,变成了一个网页,那么以后只要有人需要查看你的博客,你就可以把你的博客网址发给别人,别人就只需要通过博客网址就能直接访问,而不需要拷贝一份。
在上面例子中,博客的内容就是我们在程序内定义的变量,而博客地址就是指针;只要指针指向了一个变量,那么我们只需要通过指针就能访问,而不是从新复制一份,(也许对一个数据量小的程序来说,并不能起到很大的方便,但是对数据量大的项目来说,则能大大的节省存储空间,并且使得代码变得更加简便)
可能看上去有一些绕,但是我们先记住几点:指针保存的是变量的地址,并且指针也是一种数据类型,当然指针自身也有地址(只要是在代码中定义的变量一定都有一个地址来存储)。
我们用代码和内存分配来看一个具体的例子。
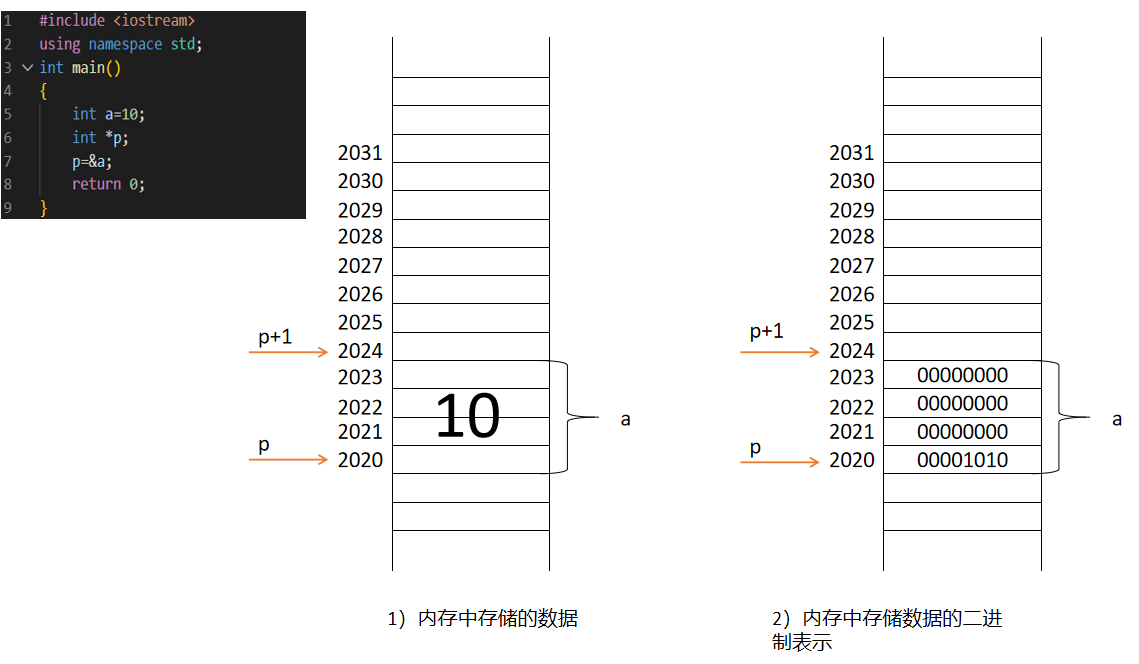
如下图所示,我们定义一个指针,并且让他指向相同类型的变量:

我们先定义了整型数据a=10,那么在stack空间上main函数内会分配a的存储空间,并且我们这里假设其地址为2020(地址是自动随机分配的),那么此时我们定义一个指针p(如上述代码第6行所示:int
*p),并且让其等于a的地址(如上述代码第7行所示:p=&a)。这里我们可以得到如下关系(如图片右下角所示)
p=&a=2020
*p=a=10
这里指针为p,其类型是int类型,所以p可以保存int类型变量的地址;且p保存的是地址,*p是p保存的地址的数值。也就是说指针p保存了一个地址,我们使用*p来去得到该地址里面的数值。
此时p是int指针类型,所以你可以随便让*p等于任何一个int类型的数据,但是要记住的是,*p改变,a的数值也发生改变。
因为p是保存a的地址,a的数值保存在其地址里面,*p是去得到p保存的地址里面所保存的值,也就是和a绑定在了一起,所以改变*p相当于改变了a。
如果实在有点绕,那么记住,只要p一直是保存的a的地址,把*p看成a就行,*p就是a,改变*p就是改变a,改变a就是改变*p。
对上述举一个小例子:

a原本是赋值为10,但是*p=11,表示p保存的地址2020里面的值变成11;而a的地址是2020,所以a从原本的10变成了11。(也就是*p和a绑定在了一起)而后续代码中a被重新赋值为12,那么*p此时也是数值12.
注意,我们并没有对p也就是2020进行改变,*p的改变是会去改变的是p保存的地址也就是2020所保存的数值。
上述代码中,&是引用变量地址,也就是得到保存该变量的地址;*是解引用,也就是得到指针所保存地址中的数值,比如这里p保存了a的地址,所以*p就是找到p保存的地址,然后得到该地址里面的数值。(所有的变量一定是要保存在相应的地址中,并且每个地址是唯一的)
以上所有的话都说为了说明对与一个指针p:
p是保存的地址;
*p是p保存的地址里面存储的数值!
2)指针运算
对于指针p我们可以做出下面简单的运算:p+1
这条语句并非是完整的表述,因为p的类型是int*(或者指针p的类型是int,为了便于理解下面都用这样的表述),所以完整的表述应该是:p+1*(sizeof(int)),如果指针p的类型是char,那么p+1的完整形式是p+1*(sizeof(char));但是为了简便,我们直接都写成p+1,然后由编辑器自动的去识别p来加上相应的数值。
sizeof(p)表示得到变量p所占的字节数,sizeof(int)表示得到一个int类型所占的字节数。
p所保存的地址是2020,其类型指针类型是int,所以当p=p+1时,p所指向的地址为2024;如果我们没有在地址2024里面保存有数值,那么这时去得到该地址所保存的数值会得到一些垃圾数据,这是操作系统随意给地址分配的数值。
下面我们用第一小节的例子来详细讲述一下指针p的变化:

上图中p保存的地址是2020,那么当我们进行加1时,即p+1的地址则为2024;如下图所示:
在1)中时a的十进制表达,在2)中是a的二进制表达;int类型a所占字节为4个字节,指针指向的是a的首字节,p=p+1(即p+1*sizeof(int))的地址时从2024开始到2027,(因为p的指针类型是int,所以占四个字节长度)
要注意,我们并没有给2024地址赋予任何值,所以如果打印*(p+1)则会得到一些垃圾数值!
此时,我们如果对p做一个类型转换,比如说我们把p赋值给一个char*的指针q,那么q等于多少?q+1等于多少?*q等于多少?*(q+1)又等于多少?
我们可以对照下面的图进行思考:
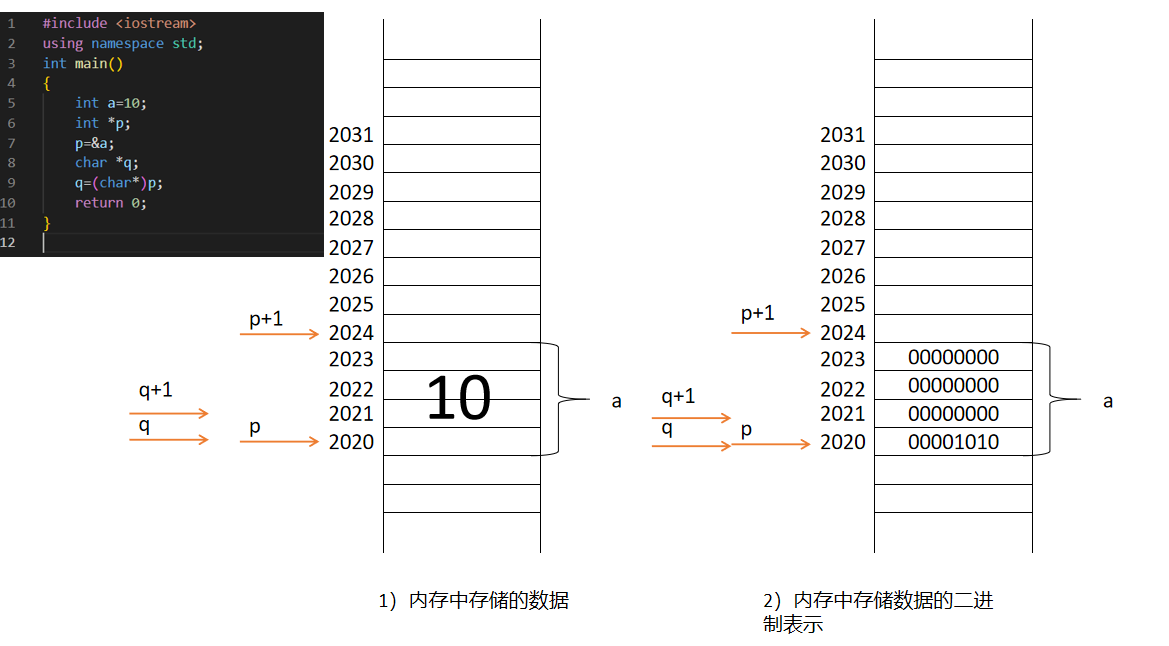
q也是指针,因为上文说过,指针指向的是一个变量的首地址,所以用指针q去获得p,那么就是p把其指向的地址赋予q,即q=2020;那么q+1相当于q+sizeof(char),所以q+1的数值是2021(如果q的类型也为int类型,那么q+1的地址是2024,其他类型同理)
注意了,这里p和q的数值表示为地址,也就是他们保存着的地址;*p和*q就是我们去得到该地址保存的数值;那么*(p+1)和*(q+1)也就是得到地址2024和2021里面存储的数值,而在最开始我们说过,字节保存的是二进制数据,int类型是该值转化为二进制存然后分别存储进四个字节中,所以2020到2024四个字节合在一起是10的二进制。
故*(q+1)就是去获得q+1保存的地址也就是2021里面的数值,并且用十进制的形式打印出来时其值为0;同理*(q+2)就是获得2022地址里面的数值;值得注意的是,*(q+4)也就是2024地址内我们没有分配数值,所以里面是垃圾值!
练习:如果a的数值不是10,而是100或者1000,*q和*(q+1)分别又是多少呢?
对于以上我们需要记住:不管指针指向的变量类型是什么,该变量占了多少字节,指针一直是指向其首地址,而其移动则是该类型所占字节的倍数!
现在我们知道了指针,我们可以直接把指向一个变量的指针传递给一个函数内部,让其对指针所指向的地址里面的数值进行修改,这样就不需要把变量赋值到函数里面,从而节约内存空间,例子如下所示:
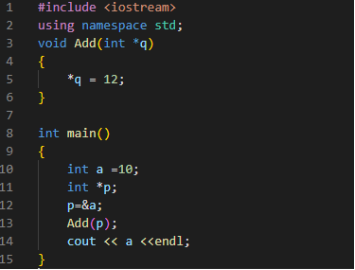
程序运行结束时a的数值应该是多少?
让我们继续想起那四个存储区域,分析一下程序变量分别存储在什么地方,如下图所示:
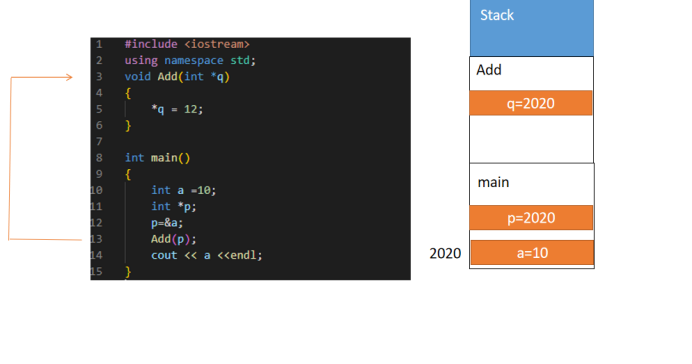
当我们从main函数开始执行到13行代码是,在stack中,分别给a和p分配的相应的空间来存储空间(我们假设a的地址时2020),值得强调的一点是,不管指针是什么类型,其所占字节是固定的!比如这里假设其所占四个字节,那么不管指针存储char*类型还是int*类型还是其他什么类型,其所占空间都是四个字节。
当运行到Add函数时,stack会给指针q分配存储空间,如上文所说,函数外面来的变量都是复制一份后,在再函数内存操作;这里就是q复制了p的数值,也就是q的值为地址2020;然后我们对q保存的地址2020里面的值重新赋值12,也就是a重新赋值为了12;注意的是,Add函数是不知道a这个变量的存在(因为a所占有的空间在main函数内),它只是通过a的地址来修改了a的数值。
最后当Add函数运行结束时,其分配的空间被销毁,也就是指针q被销毁;此时a的数值还是12,因为a的存储空间在main函数中,其他函数没有对a的地址进行操作的话就不会改变a的变量。

当main函数结束后,内存被释放销毁。
以上便是指针的一个十分重要的作用,通过操作一个变量的地址来修改其值,这样就不需要去复制该变量,从而极大的节省空间。(想象一下,如果一个数据所占字节上万,那么复制一份该数据的存储成本太大了,但是使用指针就仅需要四个字节即可)
对于上述例子,说明一点:上述例子是一个很简单的指针使用,但是即便是复杂的,比如二级指针,三级指针之类,也可以去分析其存储情况来方便我们看懂代码;就算p是二级指针或者指针数值之类的,其传入函数也后是被q所拷贝一份,也是该在什么地方分配空间就在什么地方分配空间,但是如果传入的是地址,就算是其他该类型的指针得到了了地址的数值,只要通过指针对该地址进行了修改,其原本的变量的值也会修改(变量的数值就是保存在它的地址中);之后文会对复杂的指针传参进行一个介绍和说明。
最后我们对上述的内容做一个小总结:
1.我们在编辑器里面写的所有东西都是被编辑器分配内存存储的,可以大致的分为四个区域:Head,Stack,Static/Global,和Code。所以在编写代码时,我们尤为要注意,我们所定义的变量内存是分配在哪个地方,这样方便我们去理解程序里面变量的各种变化!
2.我们在函数内部定义的变量,只要不手动分配空间其都是在stack中分配存储空间进行存储,并且每次函数运行结束后,其内存都会被释放,所以有函数外的变量和其函数内部有数值交互时,一定要注意变量数值的变化。
3.如果把我们定义的变量比作是本地的博客文件,那么指针就是可以访问我们本地博客内容的网络链接;指针保存的是变量的地址,我们可以通过指针获得该地址里面的数值并进行修改。
4.对一个所定义的指针int *p=&a;其p是a的地址,*p是a的数值;我们对*p操作,就相当于对a的数值进行该变;如果对p进行操作,就会让p会获得其他地址,此时*p就不在是a了;
5.指针也是一个数据类型,其所占据的内存是一定的,因操作系统而不同;比如当指针所占字节是4个时,那么不管它指向的类型占有多少字节,指针本身只占有四个字节,并且其保存的地址是该类型所占地址的首地址。
6.一个程序的执行,本质上就是不断的从存储的字节中获得相应的二进制数值,然后一直到最后一个结束字符(命令也是变成二进制数据保存在字节中)。也就是说把程序所有代码变成二进制存储在内存中,然后找到最开始的main函数的存储字节,然后得到里面的数据,如果该数据是给变量赋值那么就是让main函数里面相应的字节存储该值的二进制,然后继续得到下一个字节的数值,一直这样运行到结束字符。所以不懂代码是什么意思时,尤其是代码运行逻辑上没错但是有各种问题时,可以想想它的存储空间在哪以及字节保存的数值是如何变化的。
以上是对指针的一个简单介绍,主要是为后文的知识建立一个基础。在之后的文章中,会分别对指针与数组,指针与函数等等更加丰富的指针操作进行介绍与分析。但是不管指针如何在代码中被复杂的使用,我们都要知道指针在代码中指向(保存)的是什么类型数据的地址,这样才能更好的利用指针来编写程序。 |






 订阅
订阅