| 编辑推荐: |
本文主要介绍了C 语言编程 — 宏定义与预处理器指令。 希望能为大家提供一些参考或帮助。
文章来自于51CTO博客-云物互联,由火龙果Linda编辑推荐。 |
|
宏
C 语言中,宏的本质是预处理器指令。它用来将一个标识符(宏名)定义为一个字符串,被定义的字符串称为替换文本。程序在预编译阶段,所有的宏名都会被定义的字符串替换,这便是宏替换。它的功能非常强大,甚至自成一门语言,有兴趣的可以参看宏编程。宏定义通常被用来简化代码的实现,让代码的逻辑更加清晰。
宏的工作原理是定义一些参数,将这些参数复制到特定的格式(宏定义)中,通过修改宏定义(e.g. 以
#define 为开头的代码片段)或者参数,宏可以生成我们想要的代码。
预处理器
C 预处理器(C Preprocessor)简写为 CPP,又称预编译器,它并不是 C 编译器的组成部分,但是它是编译过程中一个单独的步骤。本质上,C
预处理器不过是一个文本替换工具而已,它们会指示编译器在实际的编译工作之前完成所需的预处理准备。
预处理器指令
C 语言中,所有的预处理器指令都是以 # 开头的。它必须是第一个非空字符,通常位于源文件首部。下面列出了所有重要的预处理器指令:
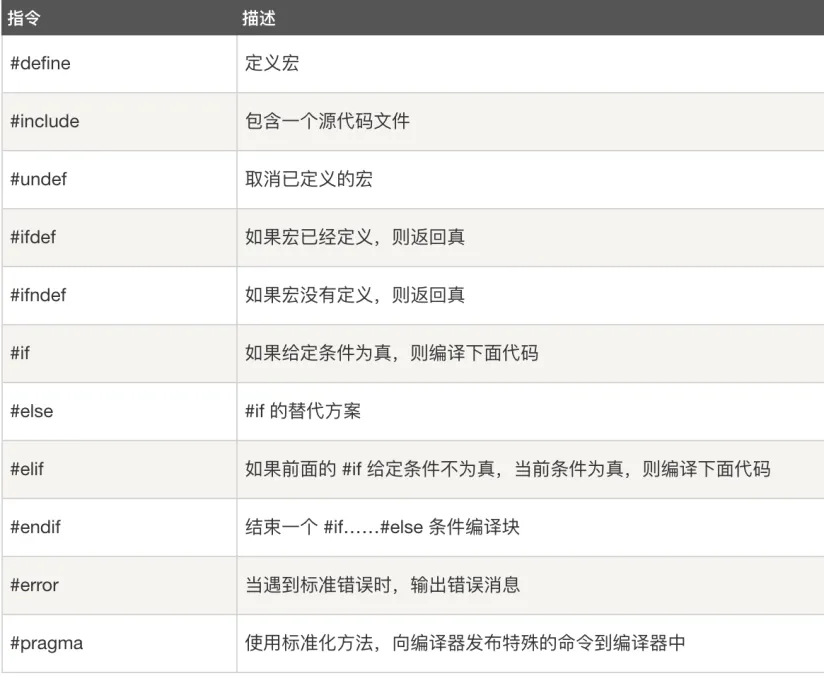
预处理器指令示例
这个指令告诉 CPP 把所有的 MAX_ARRAY_LENGTH 替换为 20。通常用于定义常量。
#define MAX_ARRAY_LENGTH 20
|
这些指令告诉 CPP 从系统库目录中获取头文件 stdio.h,并添加文本到当前的源文件中。
这些指令告诉 CPP 从本地目录中获取头文件 myheader.h,并添加内容到当前的源文件中。
这个指令告诉 CPP 取消已定义的 FILE_SIZE,并重新定义它为 42。
#undef FILE_SIZE
#define FILE_SIZE 42
|
这个指令告诉 CPP 只有当 MESSAGE 未定义时,才定义 MESSAGE。
#ifndef MESSAGE
#define MESSAGE "You wish!"
#endif
|
这个指令告诉 CPP 如果定义了 DEBUG,则执行处理语句。在编译时,如果向 gcc 编译器传递了
-DDEBUG 开关选型,这个指令就非常有用。它定义了 DEBUG,可以在编译期间随时开启或关闭。
#ifdef DEBUG
/* Your debugging statements here */
#endif
|
指令 #pragma pack(n) 用于设定结构体、联合以及类成员变量以 n 字节方式对齐。
#pragma pack(push) // 保存对齐状态
#pragma pack(4) // 设定为 4 字节对齐
struct test
{
char m1;
double m4;
int m3;
};
#pragma pack(pop) // 恢复对齐状态
|
预处理器指令运算符
CPP 提供了下列的运算符来帮助进行宏定义:
宏延续运算符:一个宏通常写在一个单行上。但是如果宏太长,一个单行容纳不下,则使用宏延续运算符 \。例如:
#define message_for(a, b) printf(#a " and " #b ": We love you!\n")
// or
#define message_for(a, b) \
printf(#a " and " #b ": We love you!\n")
|
字符串常量化运算符:在宏定义中,当需要把一个宏的参数转换为 “字符串常量” 时,则使用字符串常量化运算符
#。例如:
#include <stdio.h>
#define message_for(a, b) \
printf(#a " and " #b ": We love you!\n")
int main(void) {
message_for(Carole, Debra);
return 0;
}
|
运行:
$ ./main
Carole and Debra: We love you!
|
标记(Token)粘贴运算符:在宏定义中,标记粘贴运算符 ## 会合并两个参数。它允许将两个独立的标记被合并为一个标记。例如:
#include <stdio.h>
#define tokenpaster(n) printf ("token" #n " = %d", token##n)
int main(void) {
int token34 = 40;
tokenpaster(34);
return 0;
}
|
运行:
上述示例会从编译器产生下列的实际输出:
printf ("token34 = %d", token34);
|
将 token##n 连接为 token34。在这里,使用了字符串常量化运算符 # 和标记粘贴运算符
##。
defined() 运算符:用在常量表达式中的,用来判断一个标识符是否已经使用 #define 定义过。如果指定的标识符已定义,则值为真。
#include <stdio.h>
#if !defined (MESSAGE)
#define MESSAGE "You wish!"
#endif
int main(void) {
printf("Here is the message: %s\n", MESSAGE);
return 0;
}
|
VA_ARGS 可变参数运算符:用于简便管理打印信息。在写代码或 DEBUG 时通常需要将一些重要参数打印出来,但在发行时又不希望有这些打印,这时就用到可变参数宏了。
# define PR(...) printf(_VA_ARGS_)
...
PR("hello world\n");
// 输出结果:hello world
|
宏定义
简单宏定义
在上文中已经给出了很多的例子,简单的宏定义的格式如下:
#define <宏名>(<参数列表>) <宏体>
|
带参数的宏定义
CPP 一个强大的功能是可以使用参数化的宏来模拟函数,这里应用了 CPP 的 “字符串常量化运算符”,格式如下:
#define <宏名>(<参数列表>) <宏体>
|
EXAMPLE 1:
// 一般函数
int square(int x) {
return x * x;
}
// 使用参数化的宏来模拟函数
#define square(x) ((x) * (x))
|
EXAMPLE 2:
#include <stdio.h>
#define MAX(x,y) ((x) > (y) ? (x) : (y))
int main(void) {
printf("Max between 20 and 10 is %d\n", MAX(10, 20));
return 0;
}
|
符号吞噬问题
#define COUNT(M) M*M
int x=5;
print(COUNT(x+1));
print(COUNT(++X));
|
注意:CPP 本质上仍是进行了简单的文本替换,所以上述 EXAMPLE 3 的 COUNT(x+1)
实际上会被替换成 COUNT(x+1*x+1),得到 5+15+1=11 而不是 66=36;同理,COUNT(++x)
则被替换成了 COUNT(++x*++x),得到 67=42。
可见,千万不要在参数化的宏定义中使用 ++、- 等算数运算法。
再看一个例子:
#define foo(x) bar(x); baz(x)
if (!feral)
foo(wolf);
|
替换之后得到的结果是:
if (!feral)
bar(wolf);
baz(wolf);
|
可见 baz(wolf); 已经跳出 if 判断体了,显然是不对的。
这个问题即便加上 {} 也很难解决,例如:
#define foo(x) { bar(x); baz(x); }
if (!feral)
foo(wolf);
else
bin(wolf);
|
替换之后的结果:
if (!feral) {
bar(wolf);
baz(wolf);
}
else
bin(wolf);
|
结果就是 else 将不会被执行,依旧不对。
使用 do{}while(0) 结构
可以使用 do{}while(0) 结构来解决上述两个问题:
#define foo(x) do{ \
bar(x); \
baz(x); \
}while(0)
if (!feral)
foo(wolf);
else
bin(wolf);
|
替换之后的结果:
if (!feral)
do{ bar(x); baz(x); }while(0);
else
bin(wolf);
|
显然,结果是正确的。这个思路很简单,就是在定义多行的参数化宏时,将多条语句都固定在一个只会执行一次的
do/while 循环体内。使用 do{…}while(0) 架构后的多行的负责宏定义不再受到大括号、分号等
token 的影响,总是会按你期望的方式调用运行。
预定义的宏
C 语言中预先定义了许多宏。在编程中可以直接使用这些预定义的宏,但是不能直接修改它们。
#include <stdio.h>
int main() {
printf("File :%s\n", __FILE__ );
printf("Date :%s\n", __DATE__ );
printf("Time :%s\n", __TIME__ );
printf("Line :%d\n", __LINE__ );
printf("ANSI :%d\n", __STDC__ );
return 0;
}
|
运行:
$ ./main
File :main.c
Date :Apr 4 2020
Time :14:13:10
Line :7
ANSI :1
|
常用的宏定义
这些宏定义就像是定义好的一个个小工具函数。
防止一个头文件被重复包含
#ifndef COMDEF_H
#define COMDEF_H
// 头文件内容
#endif
|
得到指定地址上的一个字节或字(Word)
#define MEM_B(x) (*((byte *)(x)))
#define MEM_W(x) (*((word *)(x)))
|
求最大值和最小值
#define MAX(x,y) (((x)>(y)) ? (x) : (y))
#define MIN(x,y) (((x) < (y)) ? (x) : (y))
|
得到一个成员在结构体中的偏移量
#define FPOS(type,field) ((dword)&((type *)0)->field)
|
得到一个结构体中成员所占用的字节数
#define FSIZ(type,field) sizeof(((type *)0)->field)
|
按照 LSB 格式把两个字节转化为一个字(Word)
#define FLIPW(ray) ((((word)(ray)[0]) * 256) + (ray)[1])
|
得到一个字的高位和低位字节
#define WORD_LO(xxx) ((byte) ((word)(xxx) & 255))
#define WORD_HI(xxx) ((byte) ((word)(xxx) >> 8))
|
将一个字母转换为大写
#define UPCASE(c) (((c)>='a' && (c) <= 'z') ? ((c) – 0×20) : (c))
|
判断字符是不是 10 进制的数字
#define DECCHK(c) ((c)>='0' && (c)<='9')
|
判断字符是不是 16 进制的数字
#define HEXCHK(c) (((c) >= '0' && (c)<='9') ((c)>='A' && (c)<= 'F') \
((c)>='a' && (c)<='f'))
|
防止溢出的一个方法
#define INC_SAT(val) (val=((val)+1>(val)) ? (val)+1 : (val))
|
返回数组元素的个数
#define ARR_SIZE(a) (sizeof((a))/sizeof((a[0])))
|
总结
虽然宏定义很灵活,但宏定义应该简单而清晰。
宏名采用大写下划线驼峰风格。
如果需要公布某个宏,那么该宏定义应当放置在头文件中。
不要使用宏来定义新类型名,应该使用 typedef,否则容易造成错误。
给宏添加注释时使用块注释,而不要使用行注释。因为有些编译器可能会把宏后面的行注释理解为宏体的一部分。
尽量使用 const 关键字来取代宏用于定义符号常量。
对于较长的使用频率较高的重复代码片段,建议使用函数或模板而不要使用带参数的宏定义;
对于较短的重复代码片段,可以使用带参数的宏定义,这不仅是出于类型安全的考虑,而且也是优化与折衷的体现。
尽量避免在局部命名空间中定义宏,例如:函数内、类型定义内。
|






 订阅
订阅