| 编辑推荐: |
本文主要介绍了C/C++编译链接相关内容。 希望能为大家提供一些参考或帮助。
文章来自于知乎,由火龙果Linda编辑推荐。 |
|
前言
C语言程序从源代码到二进制行程序都经历了那些过程?本文以Linux下C语言的编译过程为例,讲解C语言程序的编译过程。
编写hello world C程序:
// hello.c
#include <stdio.h>
int main(){
printf("hello world!\n");
}
|
编译过程只需:
$ gcc hello.c # 编译
$ ./a.out # 执行
hello world!
|
这个过程如此熟悉,以至于大家觉得编译事件很简单的事。事实真的如此吗?我们来细看一下C语言的编译过程到底是怎样的。
上述gcc命令其实依次执行了四步操作:
预处理(Preprocessing)
编译(Compilation)
汇编(Assemble)
链接(Linking)

示例
为了下面步骤讲解的方便,我们需要一个稍微复杂一点的例子。假设我们自己定义了一个头文件mymath.h,实现一些自己的数学函数,并把具体实现放在mymath.c当中。然后写一个test.c程序使用这些函数。程序目录结构如下:
├── test.c
└── inc
├── mymath.h
└── mymath.c
|
程序代码如下:
// test.c
#include <stdio.h>
#include "mymath.h"// 自定义头文件
int main(){
int a = 2;
int b = 3;
int sum = add(a, b);
printf("a=%d, b=%d, a+b=%d\n", a, b, sum);
}
|
头文件定义:
// mymath.h
#ifndef MYMATH_H
#define MYMATH_H
int add(int a, int b);
int sum(int a, int b);
#endif
|
头文件实现:
// mymath.c
int add(int a, int b){
return a+b;
}
int sub(int a, int b){
return a-b;
}
|
1.预处理(Preprocessing)
预处理用于将所有的#include头文件以及宏定义替换成其真正的内容,预处理之后得到的仍然是文本文件,但文件体积会大很多。gcc的预处理是预处理器cpp来完成的,你可以通过如下命令对test.c进行预处理:
gcc -E -I./inc test.c -o test.i
|
或者直接调用cpp命令
$ cpp test.c -I./inc -o test.i
|
上述命令中-E是让编译器在预处理之后就退出,不进行后续编译过程;-I指定头文件目录,这里指定的是我们自定义的头文件目录;-o指定输出文件名。
经过预处理之后代码体积会大很多:
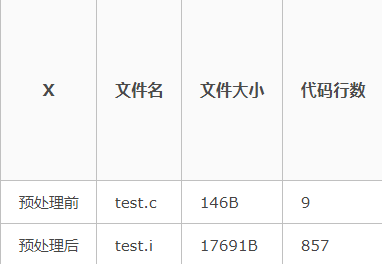
预处理之后的程序还是文本,可以用文本编辑器打开
2.编译(Compilation)
这里的编译不是指程序从源文件到二进制程序的全部过程,而是指将经过预处理之后的程序转换成特定汇编代码(assembly
code)的过程。编译的指定如下:
$ gcc -S -I./inc test.c -o test.s
|
上述命令中-S让编译器在编译之后停止,不进行后续过程。编译过程完成后,将生成程序的汇编代码test.s,这也是文本文件,内容如下:
// test.c汇编之后的结果test.s
.file "test.c"
.section .rodata
.LC0:
.string "a=%d, b=%d, a+b=%d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
movl $2, 20(%esp)
movl $3, 24(%esp)
movl 24(%esp), %eax
movl %eax, 4(%esp)
movl 20(%esp), %eax
movl %eax, (%esp)
call add
movl %eax, 28(%esp)
movl 28(%esp), %eax
movl %eax, 12(%esp)
movl 24(%esp), %eax
movl %eax, 8(%esp)
movl 20(%esp), %eax
movl %eax, 4(%esp)
movl $.LC0, (%esp)
call printf
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 4.8.2-19ubuntu1) 4.8.2"
.section .note.GNU-stack,"",@progbits
|
3.汇编(Assemble)
汇编过程将上一步的汇编代码转换成机器码(machine code),这一步产生的文件叫做目标文件,是二进制格式。gcc汇编过程通过as命令完成:
等价于:
这一步会为每一个源文件产生一个目标文件。因此mymath.c也需要产生一个mymath.o文件
4.链接(Linking)
链接过程将多个目标文以及所需的库文件(.so等)链接成最终的可执行文件(executable file)。
命令大致如下:
$ ld -o test.out test.o inc/mymath.o ...libraries...
|
上面可以看到最终连接依赖了两个文件,mymath.o test.0还有其他一些依赖库
链接的详细过程如下:
合并段
在elf文件中字节对齐是以4字节对齐的,在可执行程序中是以页的方式对齐的(一个页的大小为4k),因此如果我们在链接时将各个.o文件各个段单独的加载到可执行文件中,将会非常浪费空间:
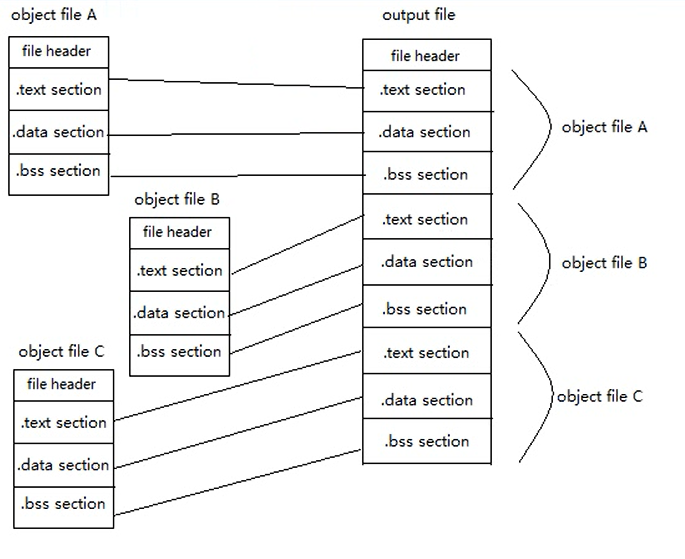
因此我们需要合并段,调整段偏移,把每个.o文件的.text段合并在一起.data段合并在一起,这样在生成的可执行文件中,各个段都只有一个,如下图,由于在链接时只需要加载代码段(.text段)和数据段(.data段和.bss段)。因此合并段之后,在系统给我们分配内存时,只需要分配两个页面大小就可以,分别存放代码和数据
调整段偏移
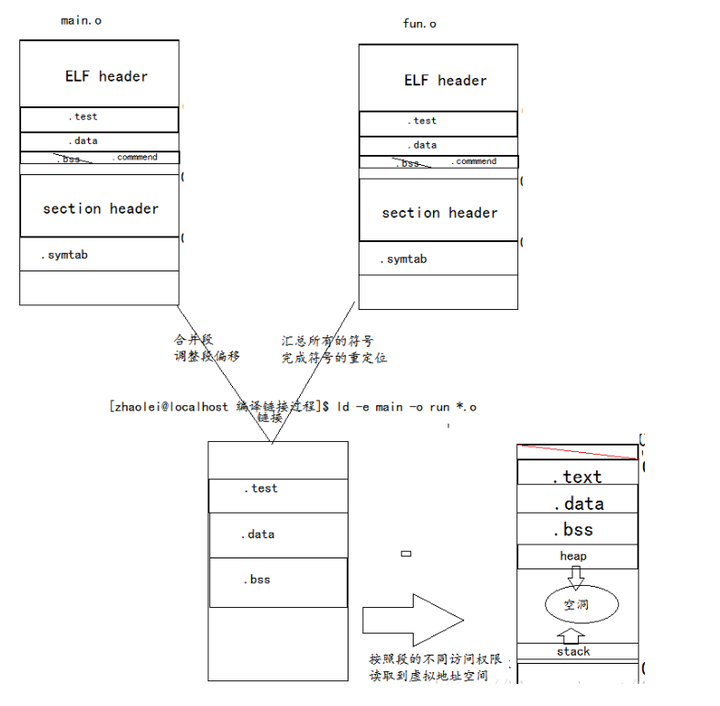
汇总所有符号
每个obj文件在编译时都会生成自己的符号表,我们要把这些符号都合并起来进行符号解析
完成符号的重定位
在进行合并段,调整段偏移时,输入文件的各个段在连接后的虚拟地址就已经确定了,这一步完成后,连接器开始计算各个符号的虚拟地址,因为各个符号在段内的相对位置是固定的,所以段内各个符号的地址也已经是确定的了,只不过连接器需要给每个符号加上一个偏移量,使他们能够调整到正确的虚拟地址,这就是符号的重定位过程
在 elf文件中,有一个叫重定位表的结构专门用来保存这些与从定位有关的信息,重定位表在elf文件中往往是一个或多个段
5.数据和指令
上面是代码编译链接的过程,得到了可执行的文件后,程序在内存中是如何运行的,数据和指令又分别是什么
所有的全局变量和静态变量都是数据,除此之外都是指令(包括局部变量)
int data1 = 10;
int data2 = 0;
int data3;
static int data4 = 10;
static int data5 = 0;
static int data6;
int main()
{
}
|
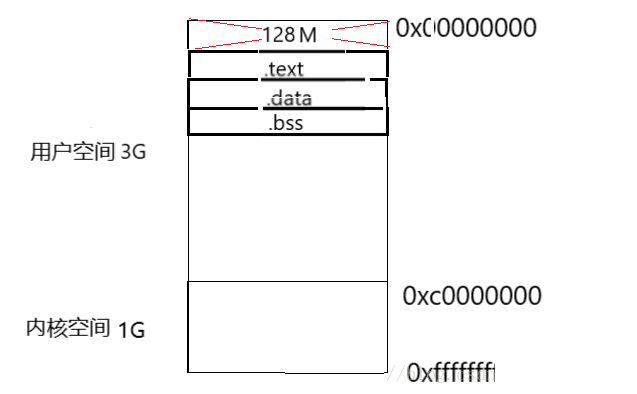
虚拟地址空间
在每个进程运行的时候,我们的操作系统都会给他分配一个固定大小的虚拟地址空间(x86,32bit,Linux内核下默认大小为4G),那这段内存分配结构如下:
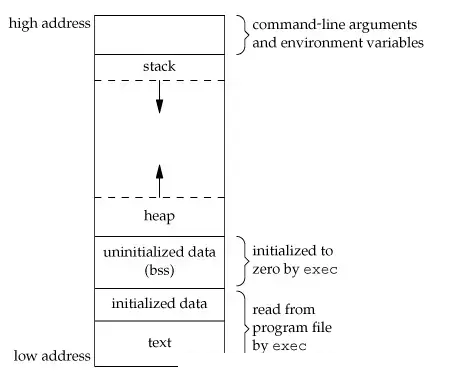
整个4G的空间有1G是供操作系统使用的内核空间,用户无法访问,还有3G是我们的用户空间,以供该虚拟地址空间上进程的运行,在这3G的用户空间中又被分成了很多段,从0地址开始的128M大小是系统的预留空间,用户也是无法访问的。
接下来是.text段,该段空间中存放的是代码,然后是.data段和.bss段,这两段里面存放的都是数据,但又有不同:data段中存放的数据是已经初始化并且初始化值不为0的数据,而.bss段中存放的是未经初始化或者初始化为0的数据(注:bssbetter
save space(更好的节省空间))
静态链接
动态链接
我们调用动态链接库有两种方法:一种是编译的时候,指明所依赖的动态链接库,这样loader可以在程序启动的时候,将所有的动态链接映射到内存中;一种是在运行过程中,通过dlopen和dlfree的方式加载动态链接库,动态将动态链接库加载到内存中。
从编程角度来讲,第一种是最方便的,效率上影响也不大。
在内存使用上有些差别:
第一种方式,一个库的代码,只要运行过一次,便会占用物理内存,之后即使再也不使用,也会占用物理内存,直到进程的终止。
第二中方式,库代码占用的内存,可以通过dlfree的方式,释放掉,返回给物理内存。
对于那些寿命很长,但又会偶尔调用各种库的进程有关。如果是这类进程,建议采用第二种方式调用动态链接库。
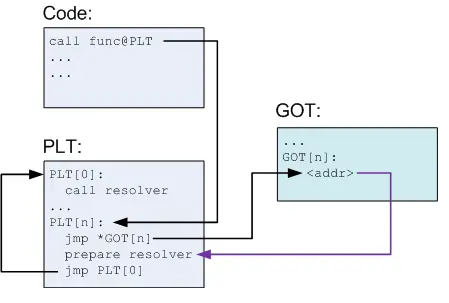
延迟绑定GOT PLT
程序运行过程中,很多函数在程序执行完也不会用到,ELF采用了一种延迟绑定的方法,就是函数第一次被用到才会进行绑定,如果没有用到就不会进行绑定,主要通过GOT(Global
Offset Table)
第一次调用:GOT表是空的,会动态解析符号的绝对地址执行,同时将地址记录在GOT表中
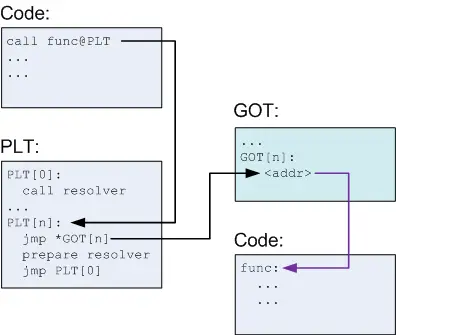
第二次调用:GOT表中已经记录了地址,直接跳转执行
GOT和PLT在内存中位置如下:
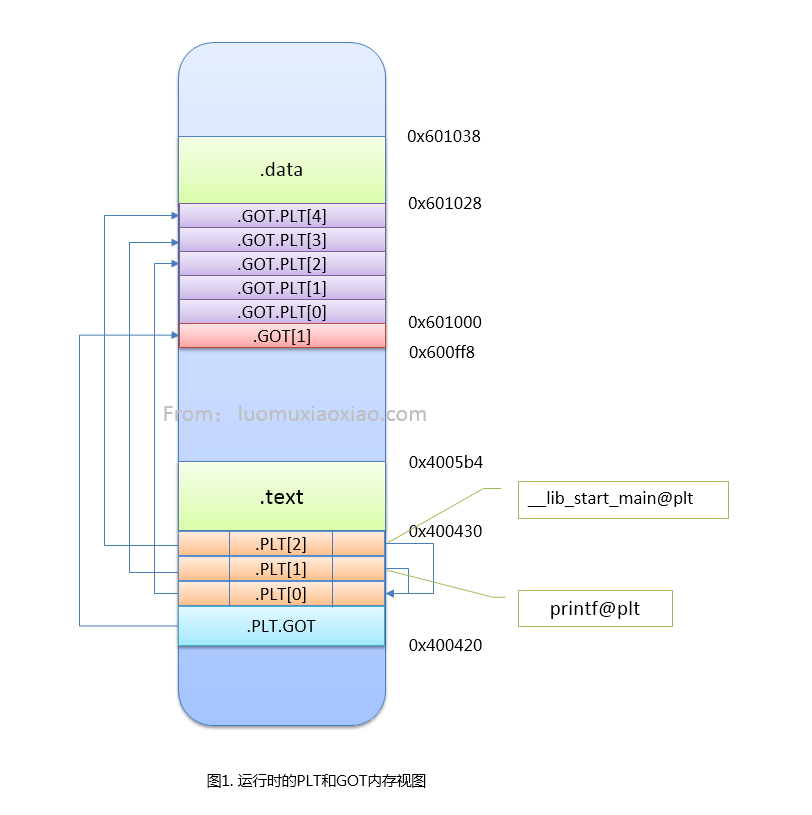
|






 订阅
订阅