| 编辑推荐: |
文章主要介绍了C++序列化黑魔法:数据处理的高效秘籍相关内容。 希望能为大家提供一些参考或帮助。
文章来自于微信公众号深度Linux,由火龙果Linda编辑推荐。 |
|
在C++程序开发里,数据就像活跃的精灵,在内存中灵动地跳跃、流转,支撑起程序的核心运转。但当涉及数据的存储与传输时,有个关键却常被忽视的环节
—— 序列化,悄然登场。想象一下,你正在开发一款大型多人在线游戏,游戏中角色的成长进度、技能组合、背包道具等丰富数据,都以精妙的
C++ 对象形式存在于内存中。当玩家激战正酣,想要保存进度,或是在跨服对战中实时同步角色状态时,该如何将内存里这些复杂对象,高效且无损地转化成能存储在磁盘、能在网络中传输的格式?又该如何在需要时,精准还原为内存里可操作的对象?这,正是序列化与反序列化亟待攻克的难题
。
然而,C++ 序列化绝非坦途,字节序差异、数据类型兼容、复杂对象处理等难题层出不穷,稍有不慎,便可能引发数据丢失、解析错误,让程序陷入混乱。接下来,让我们一同深入
C++ 序列化的神秘世界,探寻高效数据处理的秘籍,解锁其蕴含的强大能量 。
一、序列化简介
1.1序列化概述
在 C++ 的数据处理领域,序列化是一个极为关键的概念,起着数据存储与传输的桥梁作用。简单来说,序列化就像是把现实世界中的物品打包成一个个便于运输和存放的包裹,而反序列化则是打开包裹,还原物品本来的样子。在程序的世界里,它是将对象状态转换为可存储或传输格式(通常是字节序列)的过程,而反序列化则是将这些字节序列重新恢复成对象的操作
。
列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。序列化使其他代码可以查看或修改那些不序列化便无法访问的对象实例数据。确切地说,代码执行序列化需要特殊的权限:即指定了
SerializationFormatter 标志的 SecurityPermission。在默认策略下,通过
Internet 下载的代码或 Internet 代码不会授予该权限;只有本地计算机上的代码才被授予该权限。
当我们需要将复杂的数据结构,比如一个包含各种成员变量的类对象,保存到文件中,或者通过网络发送给其他程序时,就需要先将其序列化。因为无论是文件存储还是网络传输,它们更擅长处理简单的字节流,而不是复杂的对象结构。以一个游戏程序为例,游戏中的角色对象可能包含生命值、魔法值、装备列表、技能等级等众多属性。当玩家暂停游戏,程序需要保存当前角色的状态以便后续恢复时,就会将这个角色对象序列化后写入存档文件。而当玩家重新加载游戏时,程序再通过反序列化从存档文件中读取数据,恢复角色对象的所有属性和状态。
再比如在分布式系统中,不同的服务之间需要进行数据交互。假设一个电商系统,订单服务需要将订单信息发送给支付服务。订单信息可能是一个包含订单编号、商品列表、客户信息等复杂数据结构的对象。通过序列化,这个订单对象被转换为字节序列,能够顺利地在网络中传输,到达支付服务后再通过反序列化还原成订单对象,支付服务就能基于此进行后续的处理
。
在 C++ 的数据处理流程中,序列化充当着至关重要的角色。它使得数据能够突破内存的限制,以一种持久化的方式存在于存储设备中,或者跨越网络在不同的程序和系统之间传递,是实现高效数据存储与通信的基石,而选择合适的
C++ 序列化工具则是开启高效数据处理大门的钥匙。
1.2为何序列化在 C++ 中至关重要?
在 C++ 的应用领域中,数据处理是一项核心任务,而序列化在其中扮演着无可替代的重要角色。从数据存储的角度来看,当我们开发一个数据库管理系统时,数据库需要将各种复杂的数据结构,如
B 树节点、哈希表等,持久化到磁盘上。以 B 树节点为例,B 树是一种自平衡的多路查找树,常用于数据库索引结构。B
树节点包含多个键值对以及指向子节点的指针 。
在将 B 树节点存储到磁盘时,需要将这些复杂的数据结构序列化,因为磁盘文件系统只能处理字节流。通过序列化,B
树节点中的键值对和指针信息被转换为字节序列,存储在磁盘文件中。当数据库需要读取这个 B 树节点时,再通过反序列化将字节序列还原为内存中的
B 树节点对象,从而实现对数据库索引的高效访问和查询操作 。
在网络传输方面,以分布式游戏服务器架构为例,不同的游戏服务器节点之间需要进行大量的数据交互。假设一个大型多人在线游戏,玩家在游戏中的操作,如移动、攻击等指令,以及玩家角色的状态信息,都需要从客户端发送到游戏服务器,再由游戏服务器转发到其他相关服务器节点。这些数据在网络传输过程中,必须先进行序列化。
例如,玩家角色的状态可能包括位置坐标(x,y,z)、生命值、魔法值、装备列表等复杂信息,通过序列化将这些信息转换为字节流,能够在网络中以数据包的形式进行传输。到达目标服务器后,再通过反序列化将字节流恢复成原始的数据结构,服务器就能根据这些数据进行相应的游戏逻辑处理,如更新玩家位置、判断攻击是否命中等
。
此外,在不同平台和编程语言之间的数据交互中,序列化也起着关键的桥梁作用。例如,一个 C++ 编写的后端服务,需要与
Python 编写的前端应用进行数据通信。C++ 后端生成的数据,如用户信息、订单数据等,需要通过序列化转换为一种通用的格式,如
JSON 或 Protocol Buffers 定义的二进制格式,才能被 Python 前端正确接收和解析。
同样,Python 前端发送给 C++ 后端的请求数据,也需要经过序列化和反序列化的过程。这种跨平台、跨语言的数据交互在现代软件开发中极为常见,而序列化则是确保数据准确、高效传输的基石,使得不同的系统和组件能够协同工作,共同完成复杂的业务功能
。
二、序列化的核心工作原理
⑴序列化的方式
文本格式:JSON,XML
二进制格式:protobuf
⑵二进制序列化
序列化: 将数据结构或对象转换成二进制串的过程
反序列化:经在序列化过程中所产生的二进制串转换成数据结构或对象的过程
序列化后,数据小,传输速度快
序列化、反序列化速度快
|
⑶演示
①基本类型序列化、反序列化
int main()
{ //基本类型序列化
DataStream ds;
int n =123;
double d = 23.2;
string s = "hellow serialization";
ds << n <<d <<s;
ds.save("a.out");
}
{ //基本类型的反序列化
DataStream ds;
int n;
double d;
string s;
ds.load("a.load");
ds<<d<<s<<d;
std::cout<<n<<d<<s<<std::endl;
}
|
②复合类型数据序列化、反序列化
int main()
{
std::vector<int>v{3,2,1};
std::map<string,string>m;
m["name"] = "kitty";
m["phone"] = "12121";
m["gender"] = "male";
DataStream ds;
ds<<v<<s;
ds.save("a.out");
}
//复合类型数据反序列化
int main()
{
DataStreawm ds;
ds.load("a.out");
std::vector<int>v;
std::map<string,string>m;
ds>>v>>m;
for(auto it = v.begin();it != v.end();it++)
{
std::cout<<*it<<std::endl;
}
for(auto it = m.begin();it!= m.end;it++)
{
std::cout<<it->first<<"="<<it->second<<std::endl;
}
}
|
③自定义类的序列化、反序列化
class A:public Serialization
{//自定义类的序列化
public:
A();
~A();
A(const string & name,int age):m_name(name),m_age(age){}
void show()
{
std::cout<<m_name<<" "<<m_age<<std::endl;
}
//需要序列化的字段
SERIALIZE(m_name,m_age);
private:
string m_name;
int m_age;
}
int main()
{
A a("Hell",12);
DataStream ds;
ds<<a;
ds.save("a.out");
}
int main()
{
DataStreawm ds;
ds.load("a.out");
std::vector<int>v;
std::map<string,string>m;
ds>>v>>m;
for(auto it = v.begin();it != v.end();it++)
{
std::cout<<*it<<std::endl;
}
for(auto it = m.begin();it!= m.end;it++)
{
std::cout<<it->first<<"="<<it->second<<std::endl;
}
}
int main()
{//反序列化类的类型
DataStreawm ds;
ds.load("a.out");
std::vector<int>v;
std::map<string,string>m;
ds>>v>>m;
for(auto it = v.begin();it != v.end();it++)
{
std::cout<<*it<<std::endl;
}
for(auto it = m.begin();it!= m.end;it++)
{
std::cout<<it->first<<"="<<it->second<<std::endl;
}
}
|
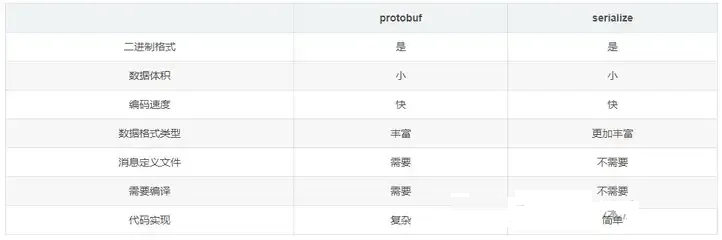
⑷Protobuf 与 srialization的区别
⑸数据类型的定义
enum DataType
{
BOOL =0,
CHAR,
INT32,
INT64,
FLOAT,
DOUBLE,
STRING,
VECTOR,
LIST,
MAP,
SET,
CUSTOM
}
|
⑹Serializable 接口类
class Serializable
{
public:
virtual void serializable (DataStream & stream) const =0;
virtual bool unserializable (DataStream & stream) =0;
}
|
SERIALIZE宏(参数化实现)
#define SERIALIZE(...) \
void serialize(DataStream & stream) const \
{ \
char type = DataStream::CUSTOM; \
stream.write((char *)&type, sizeof(char)); \
stream.write_args(__VA_ARGS__); \
} \
\
bool unserialize(DataStream & stream) \
{ \
char type; \
stream.read(&type, sizeof(char)); \
if (type != DataStream::CUSTOM) \
{ \
return false; \
} \
stream.read_args(__VA_ARGS__); \
return true; \
}
|
⑺大端与小端
字节序列:字节顺序又称为端序或尾序(Endianness),在计算机科学领域,指的是电脑内存中在数字通信链路中,组成多字节的字的字节排列顺序。
小端:little-Endian:将低序字节存储在起始地址(在低位编地址),在变量指针转换过程中地址保存不变,比如,int64*
转到 int*32,对于机器计算来说更友好和自然。
大端:Big-Endian:将高序字节存储在起始地址(高位编制),内存顺序和数字的书写顺序是一致的,对于人的直观思维比较容易理解,网络字节序统一采用Big-Endian。
⑻检测字节序
①使用库函数
#include <endian.h>
__BYTE_ORDER == __LITTLE_ENDIAN
__BYTE_ORDER == __BIG_ENDIAN
|
②通过字节存储地址判断
#include <stdio.h>
#include<string.h>
int main()
{
int n = 0x12345678;
char str[4];
memcpy(str,&n,sizeof(int));
for(int i = 0;i<sizeof(int);i++)
{
printf("%x\n",str[i]);
}
if(str[0]==0x12)
{
printf("BIG");
}else if (str[0] == 0x78){
printf("Litte");
}else{
printf("unknow");
}
}
|
三、C++ 序列化工具
对于通信系统,大多都是C/C++开发的,而C/C++语言没有反射机制,所以对象序列化的实现比较复杂,一般需要借助序列化工具。开源的序列化工具比较多,具体选择哪一个是受诸多因素约束的:
效率高;
前后向兼容性好;
支持异构系统;
稳定且被广泛使用;
接口友好;
下面将为大家详细介绍几款主流的 C++ 序列化工具:
3.1Protobuf:Google 亲儿子
Protocol Buffers(简称 Protobuf)是由 Google 开发的一种语言中立、平台中立、可扩展的序列化结构化数据的方式
。它采用二进制的序列化格式,在不同平台之间传输和保存结构化数据时表现出色。通过简单的定义文件(以.proto
为扩展名),就能够生成多种语言(包括 C++、Java、Python、Go 等)的代码,极大地简化了序列化和反序列化的操作流程。
假设我们要定义一个简单的电话簿联系人信息的数据结构。首先,创建一个.proto文件,比如addressbook.proto,在其中定义消息类型:
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
}
message AddressBook {
repeated Person people = 1;
}
|
在这个定义中,Person消息类型包含了姓名、ID、邮箱以及电话号码列表,电话号码又包含号码和类型。AddressBook消息类型则是一个联系人列表
。
接下来,使用protoc编译器将这个.proto文件编译生成 C++ 代码。假设已经安装好了protoc,并且将其添加到了系统路径中,执行编译命令:
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto
|
这里$SRC_DIR是.proto文件所在的源目录,$DST_DIR是生成的 C++ 代码输出目录。编译完成后,在$DST_DIR目录下会生成addressbook.pb.h和addressbook.pb.cc两个文件,它们包含了序列化和反序列化所需的代码
。
在 C++ 代码中使用这些生成的代码进行序列化和反序列化操作:
#include "addressbook.pb.h"
#include <iostream>
#include <fstream>
// 序列化
void Serialize() {
addressbook::AddressBook address_book;
// 添加一个联系人
addressbook::Person* person = address_book.add_people();
person->set_name("Alice");
person->set_id(1);
person->set_email("alice@example.com");
addressbook::Person::PhoneNumber* phone = person->add_phones();
phone->set_number("123-456-7890");
phone->set_type(addressbook::Person::MOBILE);
// 将AddressBook对象序列化为文件
std::fstream output("addressbook.pb", std::ios::out | std::ios::trunc | std::ios::binary);
if (!address_book.SerializeToOstream(&output)) {
std::cerr << "Failed to write address book." << std::endl;
return;
}
}
// 反序列化
void Deserialize() {
addressbook::AddressBook address_book;
// 从文件中读取并反序列化
std::fstream input("addressbook.pb", std::ios::in | std::ios::binary);
if (!address_book.ParseFromIstream(&input)) {
std::cerr << "Failed to parse address book." << std::endl;
return;
}
// 输出反序列化后的联系人信息
for (int i = 0; i < address_book.people_size(); ++i) {
const addressbook::Person& person = address_book.people(i);
std::cout << "Name: " << person.name() << std::endl;
std::cout << "ID: " << person.id() << std::endl;
std::cout << "Email: " << person.email() << std::endl;
for (int j = 0; j < person.phones_size(); ++j) {
const addressbook::Person::PhoneNumber& phone = person.phones(j);
std::cout << "Phone Number: " << phone.number();
switch (phone.type()) {
case addressbook::Person::MOBILE:
std::cout << " (Mobile)";
break;
case addressbook::Person::HOME:
std::cout << " (Home)";
break;
case addressbook::Person::WORK:
std::cout << " (Work)";
break;
}
std::cout << std::endl;
}
}
}
int main() {
Serialize();
Deserialize();
return 0;
}
|
这段代码中,Serialize函数创建了一个AddressBook对象,并添加了一个联系人及其电话号码,然后将其序列化为二进制文件。Deserialize函数从文件中读取数据并反序列化,最后输出联系人的详细信息
。
Protobuf 具有诸多显著优点。在效率方面,其序列化后的二进制数据体积小,序列化和反序列化速度快,非常适合对性能要求较高的场景,如网络通信和大数据量的存储。在兼容性上,它支持多语言,能够方便地在不同语言编写的系统之间进行数据交换
。然而,Protobuf 也存在一些缺点。它的学习曲线相对较陡,初次接触的开发者需要花费一定时间来熟悉其语法和使用方式。而且,.proto文件的定义相对固定,如果数据结构频繁变动,维护成本会较高,每次修改都需要重新编译生成代码
。
3.2Cereal:C++ 11 的得力助手
Cereal 是一个专为 C++11 设计的轻量级序列化库,它仅包含头文件,无需额外的编译步骤,使用起来非常便捷。Cereal
支持将自定义数据结构序列化成多种格式,包括二进制、XML、JSON 等,同时也能从这些格式中反序列化恢复数据
。
例如,我们定义一个简单的数据结构Student,包含姓名、年龄和成绩:
#include <cereal/cereal.hpp>
#include <cereal/archives/json.hpp>
#include <cereal/archives/binary.hpp>
#include <iostream>
#include <sstream>
#include <string>
struct Student {
std::string name;
int age;
float grade;
// 序列化函数
template <class Archive>
void serialize(Archive& ar) {
ar(name, age, grade);
}
};
|
在这个Student结构体中,定义了一个模板函数serialize,用于告诉 Cereal 如何序列化和反序列化该结构体的成员变量
。
将Student对象序列化成 JSON 格式:
void SerializeToJson() {
Student student = {"Bob", 20, 85.5f};
std::ostringstream oss;
{
cereal::JSONOutputArchive archive(oss);
archive(student);
}
std::cout << "Serialized to JSON: " << oss.str() << std::endl;
}
|
这里,std::ostringstream用于创建一个字符串流,cereal::JSONOutputArchive则将Student对象序列化为
JSON 格式并写入到字符串流中 。
从 JSON 格式反序列化:
void DeserializeFromJson() {
std::string json_str = R"({"name":"Bob","age":20,"grade":85.5})";
std::istringstream iss(json_str);
Student student;
{
cereal::JSONInputArchive archive(iss);
archive(student);
}
std::cout << "Deserialized from JSON - Name: " << student.name
<< ", Age: " << student.age
<< ", Grade: " << student.grade << std::endl;
}
|
在反序列化时,std::istringstream从给定的 JSON 字符串中读取数据,cereal::JSONInputArchive将
JSON 数据反序列化为Student对象 。
同样,也可以将Student对象序列化成二进制格式:
void SerializeToBinary() {
Student student = {"Charlie", 22, 90.0f};
std::ostringstream oss(std::ios::binary);
{
cereal::BinaryOutputArchive archive(oss);
archive(student);
}
std::string binary_data = oss.str();
std::cout << "Serialized to Binary (size): " << binary_data.size() << std::endl;
}
|
以及从二进制格式反序列化:
void DeserializeFromBinary() {
std::string binary_data = "\x07\x43\x68\x61\x72\x6c\x69\x65\x00\x16\x00\x00\x00\x41\x20\x00\x00"; // 假设的二进制数据
std::istringstream iss(binary_data, std::ios::binary);
Student student;
{
cereal::BinaryInputArchive archive(iss);
archive(student);
}
std::cout << "Deserialized from Binary - Name: " << student.name
<< ", Age: " << student.age
<< ", Grade: " << student.grade << std::endl;
}
|
Cereal 的优势在于其简单易用,对 C++11 特性的良好支持,使得它在处理 C++ 标准库中的数据结构,如std::vector、std::map等时非常方便。它适用于对灵活性要求较高,且主要在
C++ 项目内部进行数据处理的场景,例如游戏开发中的数据保存与加载、配置文件的读写等 。在游戏开发中,游戏角色的各种属性,如生命值、魔法值、装备等,都可以方便地使用
Cereal 进行序列化和反序列化,实现游戏进度的保存和加载功能 。
3.3Cista++:性能怪兽来袭
Cista++ 是一款专为 C++17 设计的高性能序列化库,它以其独特的设计理念和强大的功能在序列化领域崭露头角。Cista++
的核心特性之一是其无侵入式反射系统,这一创新机制允许开发者直接使用原生结构体进行数据交换,无需对结构体进行额外的宏定义或复杂的配置,大大简化了代码的编写过程
。例如,定义一个简单的几何图形结构体Rectangle:
struct Rectangle {
int x;
int y;
int width;
int height;
};
|
使用 Cista++ 进行序列化和反序列化时,无需为该结构体编写额外的序列化函数,Cista++ 的反射系统能够自动识别并处理结构体的成员变量。这一特性在处理大量不同类型的结构体时,能显著减少代码量和开发时间
。
Cista++ 还具备直接至文件的序列化功能,这使得它在性能上表现卓越。传统的序列化方式通常需要先将数据序列化到内存缓冲区,然后再写入文件,而
Cista++ 可以直接将数据序列化到文件中,减少了内存的使用和数据拷贝的次数,从而提高了效率,特别是在处理大规模数据时,这种优势更加明显
。在一个地理信息系统(GIS)项目中,需要存储和读取大量的地图数据,这些数据通常以复杂的数据结构表示,如包含坐标信息、地形特征等的结构体。使用
Cista++ 的直接至文件序列化功能,可以快速地将这些数据存储到磁盘上,并且在需要时能够高效地读取和反序列化,大大提升了系统的响应速度和数据处理能力
。
此外,Cista++ 支持复杂的甚至是循环引用的数据结构,这在处理一些具有复杂关系的数据时非常重要。比如在一个社交网络模拟系统中,用户之间可能存在相互关注、好友关系等复杂的引用关系,Cista++
能够正确地处理这些循环引用,确保数据的完整性和准确性 。它还通过持续的模糊测试(利用 LLVM 的
LibFuzzer)来保障其鲁棒性,确保了数据处理的安全性,使得在各种复杂环境下都能稳定运行 。基于这些特性,Cista++
在对性能敏感的场景中表现出色,如游戏开发、地理信息系统等,能够满足这些领域对高效数据处理的严格要求
。
3.4ThorsSerializer:全能小能手
ThorsSerializer 是一个功能强大的 C++ 序列化库,它专注于将数据结构序列化为二进制格式,同时也支持将数据转换为
JSON、YAML 和 BSON 等多种常见的数据格式,为开发者提供了丰富的选择,以满足不同场景下的数据处理需求
。在网络通信场景中,当需要在不同的节点之间传输数据时,ThorsSerializer 可以将数据结构快速转换为紧凑的二进制表示,从而在网络上以最小的带宽开销发送数据
。假设我们有一个表示网络消息的数据结构NetworkMessage:
struct NetworkMessage {
int messageId;
std::string sender;
std::string receiver;
std::string content;
};
|
使用 ThorsSerializer 将NetworkMessage对象序列化为二进制数据,然后通过网络发送出去,在接收端再将接收到的二进制数据反序列化为NetworkMessage对象,这样就能实现高效、准确的数据传输
。
在数据存储方面,ThorsSerializer 可以将数据结构序列化后保存到文件或数据库中,方便持久化存储和检索
。比如在一个日志管理系统中,需要将大量的日志信息存储到文件中,日志信息可能包含时间、日志级别、日志内容等数据,使用
ThorsSerializer 将这些数据结构序列化为二进制格式并保存到文件中,不仅可以节省存储空间,还能提高数据的读写效率
。
ThorsSerializer 的高性能得益于其优化的技术和算法,在序列化和反序列化过程中,能够实现高速度、低内存占用,尤其适合处理大规模数据
。它还提供了简洁直观的 API,使得开发者能够轻松地进行数据序列化操作,降低了学习成本和开发难度 。在一个分布式数据库系统中,各个节点之间需要频繁地进行数据交互和存储,使用
ThorsSerializer 的简洁 API,开发者可以快速地实现数据的序列化和反序列化功能,提高系统的开发效率和运行性能
。
此外,ThorsSerializer 具有类型安全的特性,能够避免常见的序列化错误,如溢出或隐式类型转换,确保了数据的准确性和完整性
。它还支持跨平台使用,兼容 Windows、Linux 和 macOS 等多种操作系统,使得开发者可以在不同的平台上无缝地使用该库进行数据处理
。
3.5如何选择合适的序列化工具
在 C++ 开发中,面对琳琅满目的序列化工具,如何选择最适合项目需求的工具是开发者需要谨慎思考的问题。这需要从多个维度进行综合考量,包括效率、兼容性、易用性以及适用场景等。
从效率方面来看,不同的序列化工具在序列化和反序列化的速度以及生成的序列化数据大小上存在显著差异 。例如,Protobuf
采用二进制编码,序列化后的数据体积小,在网络传输和存储时能有效减少带宽和存储空间的占用,并且其序列化和反序列化速度较快,非常适合对性能要求极高的场景,如实时通信系统、大数据存储与处理等。在一个分布式的实时监控系统中,需要频繁地将大量的监控数据(如传感器采集的温度、湿度、压力等信息)通过网络传输到服务器进行分析处理。这些数据量巨大且对传输的实时性要求很高,如果使用
Protobuf 进行序列化,就能大大减少数据传输的时间和网络带宽的消耗,提高系统的整体性能 。
而 Cista++ 则以其直接至文件的序列化功能和无侵入式反射系统,在处理大规模数据时展现出卓越的性能。它能够减少内存的使用和数据拷贝的次数,直接将数据序列化到文件中,从而提高了效率。在一个地理信息系统(GIS)项目中,需要存储和读取大量的地图数据,这些数据通常以复杂的数据结构表示,如包含坐标信息、地形特征等的结构体。使用
Cista++ 的直接至文件序列化功能,可以快速地将这些数据存储到磁盘上,并且在需要时能够高效地读取和反序列化,大大提升了系统的响应速度和数据处理能力
。
兼容性也是选择序列化工具时需要重点考虑的因素之一 。如果项目涉及到多语言开发或者需要在不同的平台之间进行数据交互,那么工具的跨语言和跨平台支持能力就至关重要。Protobuf
支持 C++、Java、Python、Go 等多种编程语言,能够方便地在不同语言编写的系统之间进行数据交换
。在一个大型的分布式电商系统中,后端服务可能使用 C++ 编写,而前端应用可能使用 Java 或 Python。在这种情况下,使用
Protobuf 进行数据的序列化和反序列化,能够确保后端生成的数据(如订单信息、用户数据等)能够准确地传输到前端,并被前端正确解析和处理,实现前后端的高效协同工作
。
易用性则直接影响到开发的效率和成本 。对于一些开发周期紧张、团队成员技术水平参差不齐的项目,选择一个易用的序列化工具尤为重要。Cereal
作为一个专为 C++11 设计的轻量级序列化库,仅包含头文件,无需额外的编译步骤,使用起来非常便捷
。它提供了直观的序列化接口,通过简单的函数调用来实现对自定义类型的支持,开发者只需关注业务逻辑,而无需花费大量时间去学习复杂的序列化语法和配置。在一个小型的游戏开发项目中,可能需要频繁地保存和加载游戏进度,使用
Cereal 就可以轻松地将游戏中的各种数据结构(如角色属性、地图信息等)进行序列化和反序列化,大大提高了开发效率
。
适用场景也是选择序列化工具的关键依据 。不同的工具在不同的场景中有着各自的优势。例如,在游戏开发中,由于游戏数据结构复杂多样,且对性能和灵活性要求较高,Cereal
和 Bitsery 等工具就比较适用。Cereal 对 C++11 标准库容器的良好支持,使得它在处理游戏中的各种数据结构(如角色的装备列表、技能树等)时非常方便;而
Bitsery 以其极致的性能和灵活的配置,能够满足游戏中对高效数据传输和状态同步的严格要求,在网络游戏的实时通信中发挥着重要作用
。
在大数据处理场景中,数据量巨大且对处理速度要求极高,Protobuf、Cista++ 等工具则更具优势。Protobuf
的高效二进制编码和良好的扩展性,使其能够在大规模数据存储和传输中表现出色;Cista++ 的高性能和对复杂数据结构的支持,能够快速地处理和分析海量的数据
。在网络通信场景中,ThorsSerializer 以其对多种数据格式的支持和高性能,能够根据不同的网络环境和需求,选择合适的序列化格式(如二进制、JSON
等),实现高效的数据传输 。
四、protobuf C++使用指导
4.1protobuf安装
在github上下载protobuf C++版本,并根据README.md的说明进行安装,此处不再赘述。
(1)定义.proto文件
proto文件即消息协议原型定义文件,在该文件中我们可以通过使用描述性语言,来良好的定义我们程序中需要用到数据格式。我们先通过一个电话簿的例子来了解下:
//AppExam.proto
syntax = "proto3";
package App;
message Person
{
string name = 1;
int32 id = 2;
string email = 3;
enum PhoneType
{
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber
{
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook
{
repeated Person person = 1;
}
|
正你看到的一样,消息格式定义很简单,对于每个字段而言可能有一个修饰符(repeated)、字段类型(bool/string/bytes/int32等)和字段标签(Tag)组成,对于repeated的字段而言,该字段可以重复多个,即用于标记数组类型,对于protobuf
v2版本,除过repeated,还有required和optional,由于设计的不合理,在v3版本把这两个修饰符去掉了。
字段标签标示了字段在二进制流中存放的位置,这个是必须的,而且序列化与反序列化的时候相同的字段的Tag值必须对应,否则反序列化会出现意想不到的问题。
(2)生成.h&.cc文件
进入protobuf的bin目录,输入命令:
./protoc -I=../../test/protobuf --cpp_out=../../test/protobuf ../../test/protobuf/AppExam.proto
|
I的值为.proto文件的目录,cpp_out的值为.h和.cc文件生成的目录,运行该命令后,在$cpp_out路径下生成了AppExam.pb.h和http://AppExam.pb.cc文件。
(3)protobuf C++ API
生成的文件中有以下方法:
// name
inline bool has_name() const;
inline void clear_name();
inline const ::std::string& name() const;
inline void set_name(const ::std::string& value);
inline void set_name(const char* value);
inline ::std::string* mutable_name();
// id
inline bool has_id() const;
inline void clear_id();
inline int32_t id() const;
inline void set_id(int32_t value);
// email
inline bool has_email() const;
inline void clear_email();
inline const ::std::string& email() const;
inline void set_email(const ::std::string& value);
inline void set_email(const char* value);
inline ::std::string* mutable_email();
// phone
inline int phone_size() const;
inline void clear_phone();
inline const ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >& phone() const;
inline ::google::protobuf::RepeatedPtrField< ::tutorial::Person_PhoneNumber >* mutable_phone();
inline const ::tutorial::Person_PhoneNumber& phone(int index) const;
inline ::tutorial::Person_PhoneNumber* mutable_phone(int index);
inline ::tutorial::Person_PhoneNumber* add_phone();
|
解析与序列化接口:
/*
序列化消息,将存储字节的以string方式输出,注意字节是二进制,而非文本;string!=text,
serializes the message and stores the bytes in the given string. Note that the bytes
are binary, not text; we only use the string class as a convenient container.
*/
bool SerializeToString(string* output) const;
//解析给定的string
bool ParseFromString(const string& data);
|
protobuf在V3版本引入Any Message Type,顾名思义,Any Message
Type可以匹配任意的Message,包含Any类型的Message可以嵌套其他的Messages而不用包含它们的.proto文件。使用Any
Message Type时,需要import文件google/protobuf/any.proto。
syntax = "proto3";
package App;
import "google/protobuf/any.proto";
message ErrorStatus
{
repeated google.protobuf.Any details = 1;
}
message NetworkErrorDetails
{
int32 a = 1;
int32 b = 2;
}
message LocalErrorDetails
{
int64 x = 1;
string y = 2;
}
|
序列化时,通过pack操作将一个任意的Message存储到Any。
// Storing an arbitrary message type in Any.
App::NetworkErrorDetails details;
details.set_a(1);
details.set_b(2);
App::ErrorStatus status;
status.add_details()->PackFrom(details);
std::string str;
status.SerializeToString(&str);
|
反序列化时,通过unpack操作从Any中读取一个任意的Message。
// Reading an arbitrary message from Any.
App::ErrorStatus status;
std::string str;
status.ParseFromString(str);
for (const google::protobuf::Any& detail : status1.details())
{
if (detail.Is<App::NetworkErrorDetails>())
{
App::NetworkErrorDetails network_error;
detail.UnpackTo(&network_error);
INFO_LOG("NetworkErrorDetails: %d, %d", network_error.a(),
network_error.b());
}
}
|
4.2protobuf的最佳实践
(1)对象序列化设计
序列化的单位为聚合或独立的实体,我们统一称为领域对象;
每个聚合可以引用其他聚合,序列化时将引用的对象指针存储为key,反序列化时根据key查询领域对象,将指针恢复为引用的领域对象的地址;
每个与序列化相关的类都要定义序列化和反序列化方法,可以通过通用的宏在头文件中声明,这样每个类只需关注本层的序列化,子对象的序列化由子对象来完成;
通过中间层来隔离protobuf对业务代码的污染,这个中间层暂时通过物理文件的分割来实现,即每个参与序列化的类都对应两个cpp文件,一个文件中专门用于实现序列化相关的方法,另一个文件中看不到protobuf的pb文件,序列化相关的cpp可以和领域相关cpp从目录隔离;
业务人员完成.proto文件的编写,Message结构要求简单稳定,数据对外扁平化呈现,一个领域对象对应一个.proto文件;
序列化过程可以看作是根据领域对象数据填充Message结构数据,反序列化过程则是根据Message结构数据填充领域对象数据;
领域对象的内部结构关系是不稳定的,比如重构,由于数据没变,所以不需要数据迁移;
当数据变了,同步修改.proto文件和序列化代码,不需要数据迁移;
当数据没变,但领域对象出现分裂或合并时,尽管概率很小,必须写数据迁移程序,而且要有数据迁移用例长在CI运行,除非该用例对应的版本已不再维护;
服务宕机后,由其他服务接管既有业务,这时触发领域对象反构,反构过程包括反序列化过程,对业务是透明的。
(2)对象序列化实战
假设有一个领域对象Movie,有3个数据成员,分别是电影名字name、电影类型type和电影评分列表scores。Movie初始化时需要输入name和type,name输入后不能rename,可以看作Movie的key,而type输入后可以通过set来变更。scores是用户看完电影后的评分列表,而子项score也是一个对象,包括分值value和评论comment两个数据成员。
下面通过代码来说明电影对象的序列化和反序列化过程:
①编写.proto文件
//AppObjSerializeExam.proto
syntax = "proto3";
package App;
message Score
{
int32 value = 1;
string comment = 2;
}
message Movie
{
string name = 1;
int32 type = 2;
repeated Score score = 3;
}
|
②领域对象的主要代码
序列化和反序列化接口是通用的,在每个序列化的类(包括成员对象所在的类)里面都要定义,因此定义一个宏,既增强了表达力又消除了重复。
// SerializationMacro.h
#define DECL_SERIALIZABLE_METHOD(T) \
void serialize(T& t) const; \
void deserialize(const T& t);
//MovieType.h
enum MovieType {HUMOR, SCIENCE, LOVE, OTHER};
/Score.h
namespace App
{
struct Score;
}
struct Score
{
Score(U32 val = 0, std::string comment = "");
operator int() const;
DECL_SERIALIZABLE_METHOD(App::Score);
private:
int value;
std::string comment;
};
//Movie.h
typedef std::vector<Score> Scores;
const std::string UNKNOWN_NAME = "Unknown Name";
struct Movie
{
Movie(const std::string& name = UNKNOWN_NAME,
MovieType type = OTHER);
MovieType getType() const;
void setType(MovieType type);
void addScore(const Score& score);
BOOL hasScore() const;
const Scores& getScores() const;
DECL_SERIALIZABLE_METHOD(std::string);
private:
std::string name;
MovieType type;
Scores scores;
};
|
类Movie声明了序列化接口,而其数据成员scores对应的具体类Score也声明了序列化接口,这就是说
序列化是一个递归的过程,一个类的序列化依赖于数据成员对应类的序列化。
(3)序列化代码实现
首先通过物理隔离来减少依赖,对于Score,有一个头文件Score.h,有两个实现文件Score.cpp和ScoreSerialization.cpp,其中ScoreSerialization.cpp为序列化代码实现文件。
//ScoreSerialization.cpp
void Score::serialize(App::Score& score) const
{
score.set_value(value);
score.set_comment(comment);
}
void Score::deserialize(const App::Score& score)
{
value = score.value();
comment = score.comment();
INFO_LOG("%d, %s", value, comment.c_str());
}
|
同理,对于Movie,有一个头文件Movie.h,有两个实现文件Movie.cpp和MovieSerialization.cpp,其中MovieSerialization.cpp为序列化代码实现文件。
//MovieSerialization.cpp
void Movie::serialize(std::string& str) const
{
App::Movie movie;
movie.set_name(name);
movie.set_type(type);
INFO_LOG("%d", scores.size());
for (size_t i = 0; i < scores.size(); i++)
{
App::Score* score = movie.add_score();
scores[i].serialize(*score);
}
movie.SerializeToString(&str);
}
void Movie::deserialize(const std::string& str)
{
App::Movie movie;
movie.ParseFromString(str);
name = movie.name(),
type = static_cast<MovieType>(movie.type());
U32 size = movie.score_size();
INFO_LOG("%s, %d, %d", name.c_str(), type, size);
google::protobuf::RepeatedPtrField<App::Score>* scores =
movie.mutable_score();
google::protobuf::RepeatedPtrField<App::Score>::iterator it =
scores->begin();
for (; it != scores->end(); ++it)
{
Score score;
score.deserialize(*it);
addScore(score);
}
}
|
五、最佳实践案例剖析
5.1案例一:游戏开发中的数据加载加速
在游戏开发领域,游戏资产的加载速度直接影响玩家的游戏体验,尤其是在游戏启动阶段,漫长的加载时间可能会让玩家失去耐心。以一款
3D 角色扮演游戏为例,游戏中包含大量的角色模型、场景地图、纹理资源等,这些资产的数据量庞大且结构复杂
。
在未使用高效序列化工具之前,游戏的加载过程较为缓慢。例如,角色模型数据可能以传统的文本格式存储,在加载时需要逐行解析文本,将各种属性(如顶点坐标、法线方向、材质信息等)转换为内存中的数据结构。这种方式不仅解析速度慢,而且在转换过程中会消耗大量的
CPU 资源,导致游戏启动时间长达数十秒甚至更久 。
为了优化这一问题,开发团队引入了 Cista++ 序列化库。Cista++ 的无侵入式反射系统和直接至文件的序列化功能在这个场景中发挥了巨大作用
。首先,对于角色模型数据,开发团队将其定义为原生结构体,利用 Cista++ 的反射系统,无需编写额外的序列化代码,就能直接对结构体进行序列化操作
。例如,定义一个角色模型结构体CharacterModel:
struct CharacterModel {
std::vector<glm::vec3> vertices;
std::vector<glm::vec3> normals;
std::vector<glm::vec2> uvs;
std::string materialName;
};
|
在加载角色模型时,Cista++ 可以直接将存储在文件中的序列化数据反序列化为CharacterModel结构体,减少了中间的数据转换步骤,大大提高了加载速度
。而且,Cista++ 的直接至文件序列化功能避免了先将数据加载到内存缓冲区再处理的过程,直接从文件中读取和反序列化数据,减少了内存的占用和数据拷贝的次数,进一步提升了加载效率
。
通过使用 Cista++,游戏的启动时间大幅缩短,从原来的 30 秒减少到了 10 秒以内,玩家能够更快地进入游戏世界,提升了游戏的整体流畅性和用户体验,吸引了更多玩家的关注和喜爱,在市场竞争中占据了更有利的地位
。
5.2案例二:分布式系统中的数据传输优化
在分布式系统中,数据需要在不同的节点之间进行频繁传输,数据量通常较大,且网络环境复杂多变,对数据传输的效率和稳定性提出了极高的要求。以一个大型电商分布式系统为例,该系统包含多个微服务模块,如订单服务、商品服务、用户服务等,这些服务分布在不同的服务器节点上,它们之间需要进行大量的数据交互
。
在订单服务中,当用户下单后,订单信息需要被发送到支付服务进行处理。订单信息可能包含订单编号、商品列表、用户信息、收货地址等复杂的数据结构
。假设使用传统的数据传输方式,如将订单信息以JSON格式进行传输,由于JSON是文本格式,数据体积较大,在网络传输过程中会占用较多的带宽资源,而且解析JSON数据也需要消耗一定的CPU时间
。在高并发的情况下,大量的订单数据传输可能会导致网络拥塞,影响系统的响应速度 。
为了解决这些问题,开发团队采用了 Protobuf 进行数据传输。首先,通过定义.proto文件来描述订单数据结构:
syntax = "proto3";
message OrderItem {
string productId = 1;
string productName = 2;
int32 quantity = 3;
float price = 4;
}
message Order {
string orderId = 1;
string userId = 2;
string shippingAddress = 3;
repeated OrderItem items = 4;
}
|
在订单服务中,当生成订单后,将订单对象序列化为 Protobuf 的二进制格式:
#include "order.pb.h"
void SendOrder(const Order& order) {
std::string serializedOrder;
order.SerializeToString(&serializedOrder);
// 通过网络发送serializedOrder到支付服务
}
|
在支付服务接收到数据后,进行反序列化操作:
#include "order.pb.h"
void ReceiveOrder(const std::string& serializedOrder) {
Order order;
order.ParseFromString(serializedOrder);
// 处理订单
}
|
Protobuf 的二进制编码格式使得序列化后的数据体积大大减小,相比 JSON 格式,数据量可减少数倍甚至更多,从而降低了网络带宽的占用
。而且,Protobuf 的序列化和反序列化速度非常快,在高并发的情况下,能够快速处理大量的订单数据,保证了系统的响应速度和稳定性
。通过使用 Protobuf,电商分布式系统在数据传输方面的性能得到了显著提升,能够更好地应对高并发的业务场景,为用户提供更优质的服务
。
六、避坑指南:使用中的常见问题与解决
在使用 C++ 序列化工具的过程中,开发者常常会遇到各种棘手的问题,这些问题若不能及时解决,可能会严重影响项目的进度和质量。下面将详细介绍一些常见问题及相应的解决方法。
6.1数据类型不匹配问题
在序列化和反序列化过程中,数据类型的一致性至关重要。不同的序列化工具对数据类型的处理方式可能略有差异,若在定义数据结构和进行序列化操作时,没有确保数据类型的严格匹配,就容易出现错误
。例如,在使用 Protobuf 时,如果.proto文件中定义的字段类型与 C++ 代码中使用的类型不一致,就会导致序列化和反序列化失败
。假设.proto文件中定义了一个int32类型的字段:
message Example {
int32 number = 1;
}
|
但在 C++ 代码中,错误地将其声明为int64类型:
#include "example.pb.h"
int main() {
Example example;
int64 wrong_number = 100;
// 错误的赋值,类型不匹配
example.set_number(wrong_number);
return 0;
}
|
这样在进行序列化或反序列化操作时,就会出现未定义行为或错误 。
解决方法是仔细检查数据结构定义和代码中的数据类型,确保二者完全一致。在使用不同语言进行数据交互时,要特别注意不同语言数据类型的对应关系,例如
Python 中的int类型在 C++ 中可能对应int32或int64,需根据实际情况进行正确的映射
。
6.2版本兼容性问题
当项目中的数据结构发生变化时,序列化工具的版本兼容性就成为一个关键问题 。以 Protobuf 为例,如果在更新.proto文件后,没有正确处理版本兼容性,旧版本的反序列化代码可能无法解析新版本序列化后的数据
。假设原来的.proto文件定义如下:
syntax = "proto3";
message User {
string name = 1;
int32 age = 2;
}
|
后来由于业务需求,需要添加一个新的字段email:
syntax = "proto3";
message User {
string name = 1;
int32 age = 2;
string email = 3;
}
|
如果此时使用旧版本的反序列化代码去解析新版本序列化后的数据,就可能会出现错误,因为旧代码不知道email字段的存在
。
为了解决版本兼容性问题,可以在.proto文件中合理使用optional关键字,对于可能添加或删除的字段,将其声明为optional,这样旧版本的代码在解析新版本数据时,能够忽略新增的optional字段
。同时,在更新数据结构后,应及时更新所有相关的序列化和反序列化代码,确保版本的一致性 。在项目开发过程中,建立良好的版本管理机制也是非常必要的,记录每次数据结构的变更和对应的版本号,以便在出现问题时能够快速定位和解决
。
6.3性能瓶颈问题
在处理大规模数据或对性能要求极高的场景下,序列化工具的性能瓶颈可能会凸显出来 。例如,某些序列化工具在序列化和反序列化复杂数据结构时,可能会消耗大量的
CPU 和内存资源,导致程序运行缓慢 。在一个处理海量日志数据的项目中,日志数据包含复杂的嵌套结构,使用了一个性能较差的序列化工具,在将日志数据序列化到文件时,速度非常慢,严重影响了系统的实时性
。
针对性能瓶颈问题,可以从多个方面进行优化 。首先,选择性能更优的序列化工具,如前面提到的 Protobuf
和 Cista++,它们在性能方面表现出色 。其次,优化数据结构,减少不必要的嵌套和冗余字段,降低序列化和反序列化的复杂度
。例如,将一些频繁访问的子结构合并成一个更大的结构体,减少结构体之间的指针引用,这样在序列化时可以减少内存的间接访问,提高效率
。还可以通过缓存优化来提高性能,例如将频繁使用的数据结构预先序列化并缓存起来,当需要时直接从缓存中读取,避免重复的序列化操作
。在多线程环境下,合理地利用并发机制,将序列化和反序列化任务分配到不同的线程中执行,充分发挥多核处理器的优势,提高整体的处理速度
。
|






 订阅
订阅