| 编辑推荐: |
本文介绍
从Autosar 说汽车软件监控
,Autosar 定义的监控实体是什么
?希望对您的学习有所帮助。
本文来自于汽车与基础软件
,由火龙果软件Alice编辑,推荐。 |
|
从Autosar 说汽车软件监控
在autosar 定义中,一般的说 software monitor 指的是 通过看门狗实现的机制。(当然有OS 和 其他定时器的机制,这里我们主要说一下看门狗)。
那么在Autosar 定义的监控实体是什么呢?这里说一下解释。
检查程序被检测的点是否被运行到了,所以简单的来说,打check point的点,在定义的周期运行了,就通过。
这里需要两个check point. 开始点和结束点。结束点运行到的时间 减去 开始点运行到的时间,是否在设计范围内。
这个逻辑监控,也就是标题提到的 程序流监控,是对软件最有效的检测手段之一。可以定义多个check point. 并且定义好逻辑顺序,如1,2,3,4,5 则在软件运行的时候,1,2,3,4,5 需要依次被运行到,不可跳过 不可错序,否则认为 程序流有问题。
从e-gas 三层架构谈软件监控
在三层架构种,program flow control 在L3监控层
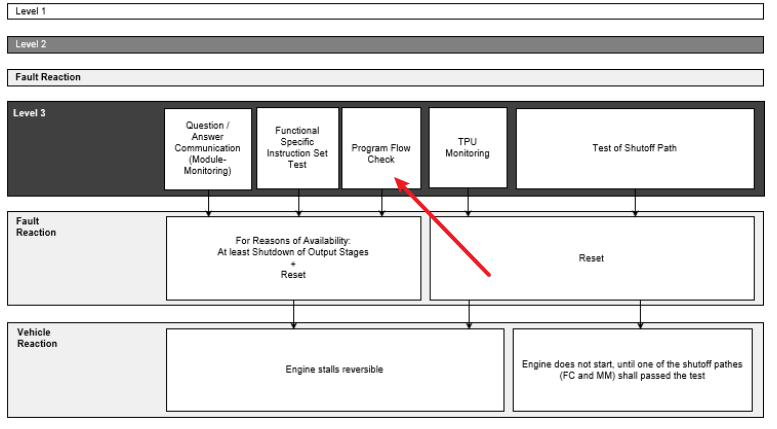
具体的需求是什么呢:
The program flow control shall verify if all monitored level2 modules are processing in fixed timeslots and in the right sequence.
就是说 所有L2层 有固定时间的,有明确顺序的程序,都可以需要被监控。

真的是 需求一句话,开发干费啦 。
代码实现
下面从三个方面说
01 看门狗在autosar 架构中位置
在autosar定义中,看门狗有自己的独立纵向协议栈。
-
WatchDog Driver
-
WatchDog Interface
-
WatchDog Management
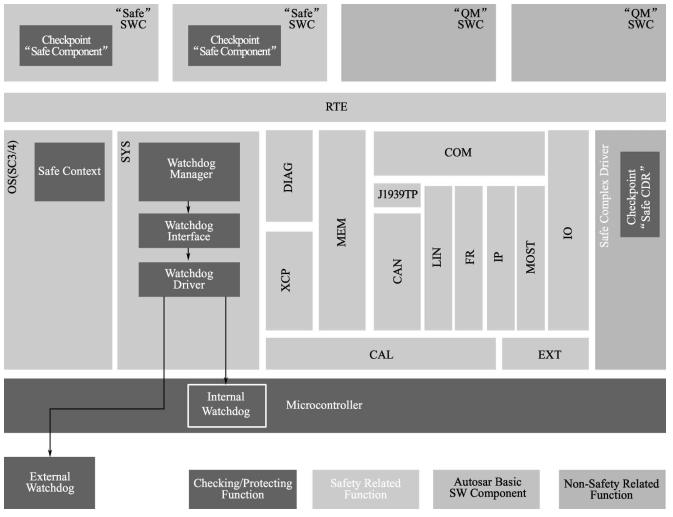
看门狗也有内狗,外狗之分。这里不一一赘述。
这里拿内部看门狗为例子。
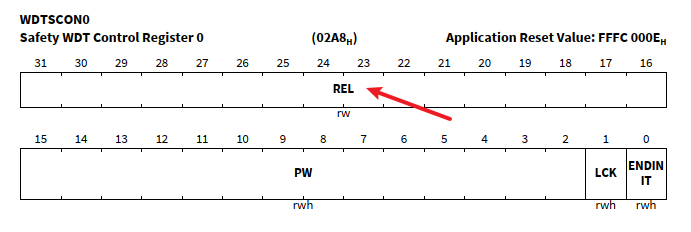
寄存器 WDTSCON0 是一个比较重要的寄存器,在使用过程中 需要对REL 也就是常说的 喂狗的计数器进行赋值。当然具体使用我们没有必要扣,这里只需要直到这个,并且Mcal的接口会使用就可以了。
/** \brief Safety WDT Control Register 0 */
typedef struct _ Ifx_SCU_WDTS_CON0_Bits
{ Ifx_Strict_32Bit ENDINIT: 1 ;
/**< \brief [0:0] End-of-Initialization Control Bit - ENDINIT (rwh) */
Ifx_Strict_32Bit LCK: 1 ;
/**< \brief [1:1] Lock Bit to Control Access to WDTxCON0 - LCK (rwh) */
Ifx_Strict_32Bit PW: 14 ;
/**< \brief [15:2] User-Definable Password Field for Access to WDTxCON0 - PW (rwh) */
Ifx_Strict_32Bit REL: 16 ;
/**< \brief [31:16] Reload Value for the WDT (also Time Check Value) - REL (rw) */
}
Ifx_SCU_WDTS_CON0_Bits; |
Mcal 接口
** Traceability : [cover parentID={F43AB8FF-39D2-4828-8E27-1580287B2E57}] ** ** ** ** Syntax : void Wdg_17_Scu_SetTriggerCondition ** **
(
** ** const uint16 timeout ** **
)
** ** ** ** Description : The function Wdg_17_Scu_SetTriggerCondition shall sets ** ** Timeout value (milliseconds) for setting the trigger ** ** counter ** ** [/cover] ** ** ** ** Service ID : 0x03 ** **
** ** Sync/Async : Synchronous ** **
** ** Reentrancy : Non Reentrant ** **
** ** Parameters(in) : timeout - Timeout value for setting the trigger counter ** ** ** ** Parameters (out) : none ** **
** ** Return value : none
|
02 看门狗在autosar中简单流程
这里大可不必多说。截一张图,简单了解一下即可。我们主要关注如何实现。
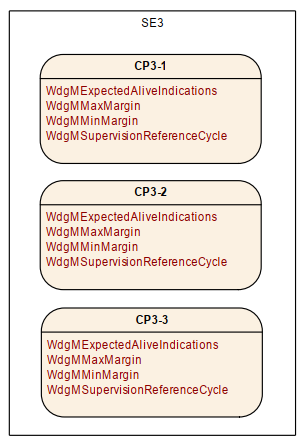
03 Alive Supervision 如何实现
在Autosar 中可以定义多个监控实体。Supervision Entity。这里叫做SE。
一个SE 可以通过一系列的监控check point 来实现一系列的监控机制。
这里假设我们设计了两个check point 分别为
CP1
CP2
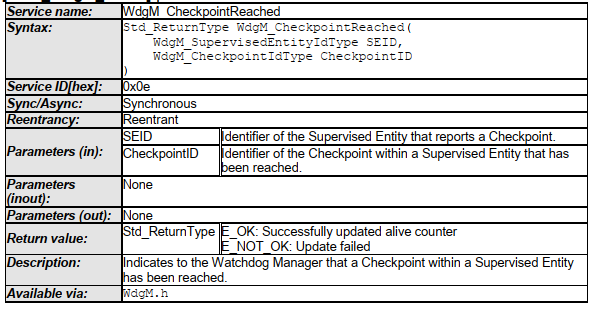
Autosar定义了一个API
* Name : WdgM_CheckpointReached
* Description : Indicates to the Watchdog Manager that a Checkpoint within a Supervised
* Entity has been reached.
* Parameters[in] : SEID, CheckpointID
* Limitations : None
* ReturnType : Std_ReturnType
|
从这个形参可以看出来,第一个是SE, 第二个是CP。
所以从使用的角度来说。只需要在需要监控的地方调用。
WdgM_CheckpointReached(WdgM_SupervisedEntityIdType SEID,
WdgM_CheckpointIdType CheckpointID) |
注意这里面监控不同的位置,需要不同的checkpoint ID。
那么这个函数具体做什么了呢?怎么就起到监控效果了呢。
这就要从这个结构体来说。
typedef struct
{
uint8 FailedAliveSupervisionRefCycleCtr; /* To track the failed reference cycles of SE*/ uint8 FailedAliveSupervisionRefCycleTol; /* Configuration Value to be copied at Mode change of WdgM from WdgM_LocalStatusParams. */ uint16 IndividualSupervisionCycleCtr; /* To track the supervision cycles of SE*/ uint32 IndividualAliveUpdateCtr; /* To track the alivecounter of SE*/ uint16 AliveSupervisionIdx; WdgM_LocalStatusType NewLocalStatus; WdgM_LocalStatusType OldLocalStatus; /* Only to be updated in WdgM_MainFunction after current Monitoring Status is reported to RTE */
}
WdgM_SupervisedEntityDynType; |
其中的
IndividualAliveUpdateCtr
在每次调用的时候会自加1.
这个需要个main函数配合使用,main函数里面同样监控这个数值,来和 约束好的上下限进行对比,如果超过上线限,则认为有问题发生。可以停止喂狗,或者是触发其他机制。
这张图可以看清楚 如何和main函数配合。
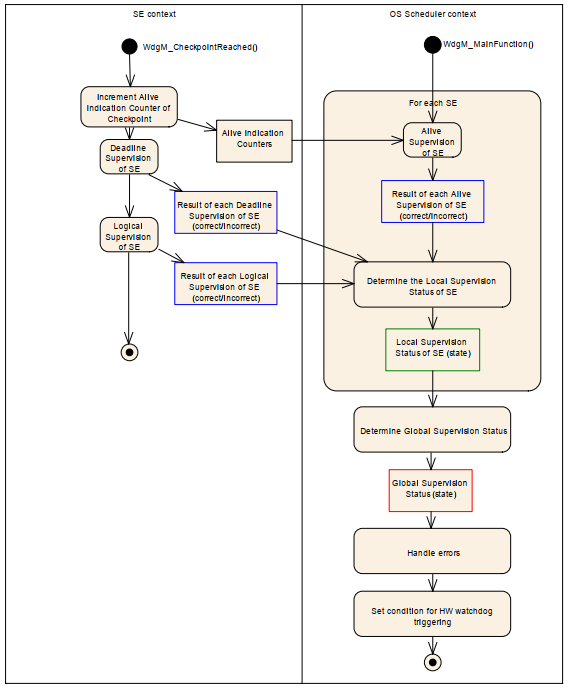
main 函数主要通过配置文件与时间的这个counter进行对比。
if (((IndividualAliveUpdateCtrCache )>= ((uint32)AliveSupervisionPtr[AliveSupervisionIdx].ExpectedAliveIndications - (uint32)AliveSupervisionPtr[AliveSupervisionIdx].MinMargin))&& ((IndividualAliveUpdateCtrCache) <= ((uint32)AliveSupervisionPtr[AliveSupervisionIdx].ExpectedAliveIndications + (uint32)AliveSupervisionPtr[AliveSupervisionIdx].MaxMargin))) |
不过这里有个东西需要注意,就是监控周期,比如10个运行周期 只需要监控一次。或者每个周期都需要监控。那么这里的Max Min 肯定是需要有不同的配置的。
假设CP1 的周期的 main的周期一致。并且配置10个周期监控一次。则 上下限可能设置为9,11
下面有两个示例图。摘来的。仅供参考。可以通过这种机制 配置我们自己的软件。

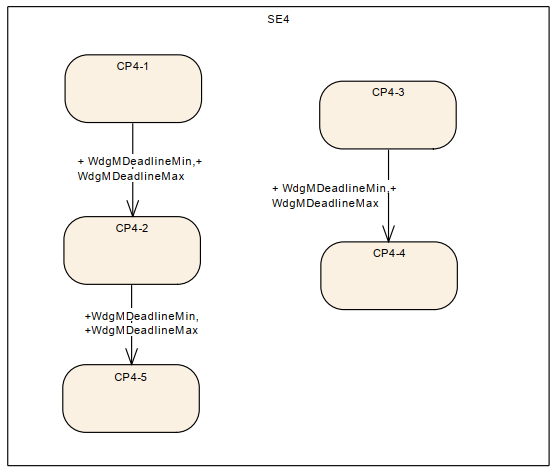
04 Deadline Supervision 如何实现
和上面一样,定义了CP0, CP1
这里也是通过一样的函数接口
WdgM_CheckpointReached(WdgM_SupervisedEntityIdType SEID,
WdgM_CheckpointIdType CheckpointID)
|
只是调用的时候,第二个参数不一样。
这里简单说一下机制。配置文件记录了CP0 和 CP1。所以当软件运行到CP0 的时候, 该机制是知道这里是初始点。
所以记录一下OS counter 这里为T1。
当软件下一次运行到CP1 的时候,机制直到这里是结束点。记录一下OS Counter 这里为T2.
直接 T2 -T1 和配置 设计的时间进行对比 即可。就可以直到 软甲你的这段运行时间是过长了 还是过短 了 还是正常。进而进行不同的操作 reaction.
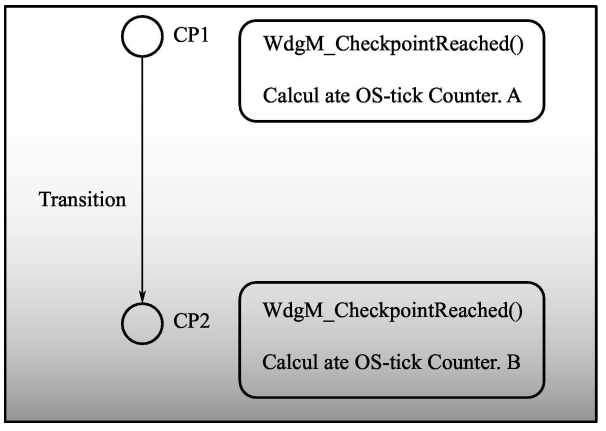
| RunningCounterValueTemp = WdgM_ConfigSetPtr->PtrToRunningCounterValue[DeadlineIdx];
if ((CheckpointID == DeadlineSupervisionPtr[DeadlineIdx].StopCheckpointId)&& (RunningCounterValueTemp != ((TickType)WDGM_PRV_C_ZERO)))
{
# if ((WDGM_RB_DEADLINE_TIMER_SELECTION) == (WDGM_RB_DEADLINE_TIMER_SELECTION_MCU)) ElapsedCounterValueTemp = RunningCounterValueTemp; /* * TRACE[BSW_SWS_AR4_0_R2_WatchDogManager_Ext-2821] */
RunningCounterValueTemp = (TickType)Mcu_Rb_GetSysTicks(); ElapsedCounterValueTemp = RunningCounterValueTemp - ElapsedCounterValueTemp; /*
* TRACE[BSW_SWS_AR4_0_R2_WatchDogManager_Ext-2861] */
/* TRACE[WDGM229] Perform checking when deadline endpoint reached*/
if ((ElapsedCounterValueTemp >= DeadlineSupervisionPtr[DeadlineIdx].DeadlineMin) && (ElapsedCounterValueTemp <= DeadlineSupervisionPtr[DeadlineIdx].DeadlineMax)) |
从这部分代码 可以看出来,Deadline Supervision 机制其实很简单。只需要计算出 ElapsedCounterValueTemp 即可。方式有很多。
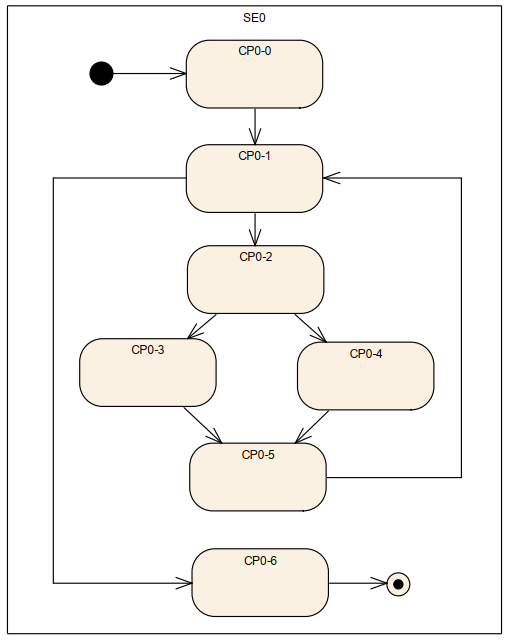
05 Logical Supervision 如何实现
Logical Supervision 也就是 ISO26262 和 E-Gas 非常推荐的 program flow control monitor 机制。对软件的监控起到非常有效的作用。
程序流监控参考循环, 也是对应监控实体的实际运行周期, 一般以WdgM监测主函数周期的整数倍来定
义。
首先说一下这里的配置流。
在配置过程中其实不是想着的那样1,2,3,4,5 而是
1到2
2到3
3到4
4到5
这样的一个过程,相当于每一个流,只有两个checkpoint。组合起来就变成了一整个程序流。
这里定义1,2,3,4,5
分别被set 到不同的位置。
当软件运行的cp1 的时候, 会记录当前节点为1, 当下一个节点运行到了3, 但是配置文件直到 上一个是1, 这一个应该是1 + const 数 不等于3, 那么机制就直到出了问题。
这里看一下代码。
当运行到一个CP点时候
| WdgM_InternalGraph_StatusDyn[InternalGraphIdx].idLastReachedCheckpoint = CheckpointID; WdgM_InternalGraph_StatusDyn[InternalGraphIdx].flgActivity = TRUE; |
先在全局变量记录一下当前的cp 和状态。
下一个CP时
| idxCPProperty_givenCP = WdgM_SupervisedEntity[SEID].idxInternalGraphCPProperty + WdgM_InternalGraph_StatusDyn[InternalGraphIdx].idLastReachedCheckpoint; idxStartDestCPs = WdgM_InternalGraph_CPProperty[idxCPProperty_givenCP].idxDestCheckpoints; nrDestCheckpoints = WdgM_InternalGraph_CPProperty[idxCPProperty_givenCP].nrDestCheckpoints; for (cntrDestCPs= 0 ;cntrDestCPs<nrDestCheckpoints;cntrDestCPs++)
{
if (WdgM_InternalGraph_DestCheckpoints[idxStartDestCPs + cntrDestCPs] == CheckpointID)
{
WdgM_InternalGraph_StatusDyn[InternalGraphIdx].idLastReachedCheckpoint = CheckpointID; break ;
} } |
通过上一个点计算出这次应该的dest 在通过start点,所以start 点 和 dest点可以计算出 这次的CP 应该是多少。
这里就给出了判断。判断是否是正确的程序流。
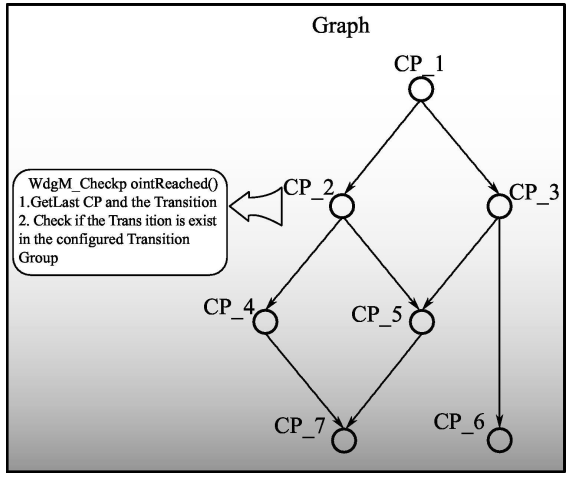
这就是三种监控的基本说明。
当然还有更详细的机制,可不同core之间的监控。后面有机会再说。 |




