| 编辑推荐: |
|
本文主要深度分析了autosar os 时间相关内容。希望对你的学习有帮助。
本文来自于微信公众号焉知汽车,由火龙果软件Linda编辑,推荐。 |
|
01 Os 介绍
01 Os 状态
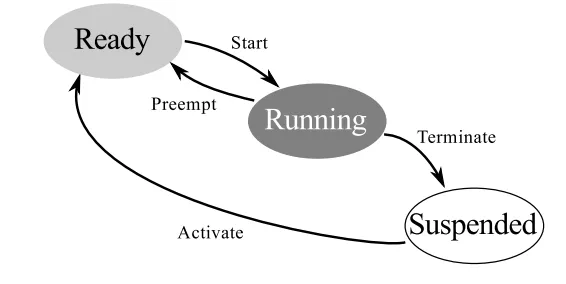
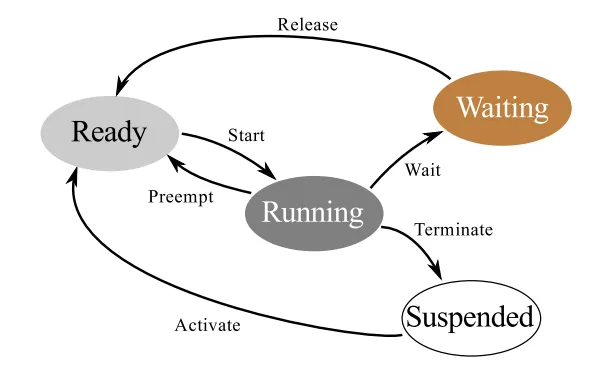
Autosar Os 的任务有两种任务,分别是扩展任务与基本任务。状态机也是不一样的。
基本任务
扩展任务
02 时间参数
任务运行的时候是个动态的过程,我们常说的运行时间,其实很笼统,很深究每个阶段的话可以分为大概下面几个阶段。请跟着下面的解释对照这个图仔细分析。
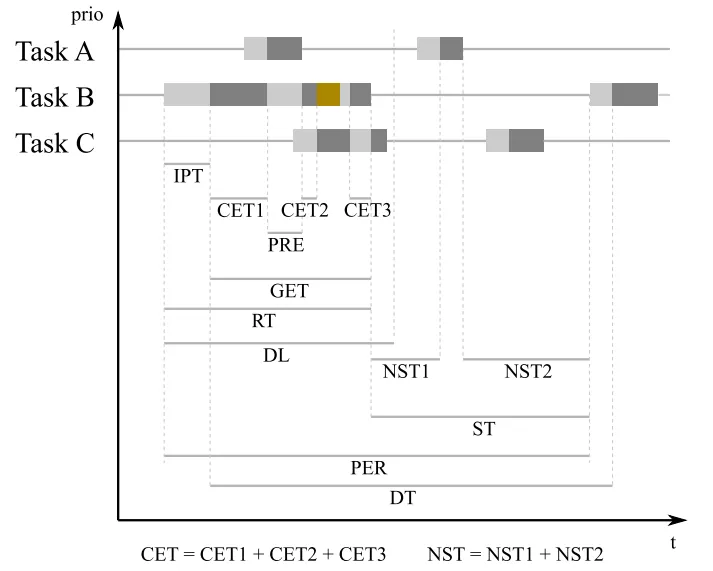
IPT - 初始化等待时间
从arivation 到 start 时间。
也就已经被调度表安排了,在ready 状态,但是这时候还没有获取CPU 资源,等到获取了CPU 资源,这一段时间
叫 IPT
CET - core执行时间
这个执行时间指的是代码真正占用CPU 并且被运行的时间之和。
其中不包括被抢占走了,也不包括状态切换比如waiting状态,因为这种情况实际上这个任务是没有获取到CPU
资源的。
这有什么用呢?
这个参数可以让我们很好的直到自己写的代码是不是存在明显的问题。
GET - gross执行时间
和上面的CET 相比,这个时间就是从开始到结束的真实时间。
包括了被抢占,包括了等待状态。
所以当一个任务不可被抢占,没有等待状态。
全部都在运行。
GET 和 CET 应该是一样的。
那么这个参数可以获取一个什么样的大概信息呢?
如果这个时间很长,那么问题可能处在他的相关任务,优先级高的,或者有event 依赖的任务。
问题不一定是处在自己。
相反前面介绍的CET 如果很高,那么问题可能就出在自己了。
RT - reponse 时间
从active 到 terminal 时间
DL - dead line
最大运行RT 时间
DT - delta time
两次start 的时间间隔,这个主要用来测量调用周期
PER - 周期
从activation 到 activation 的时间,这个是配置的。
只要调度的自身是稳定的。
这个就是稳定的,但是这个稳定不代表任务就真的被执行起来了。
可以综合上面的DT 来仔细思考以下。
ST - slack time
剩下的 run-time. 什么意思呢,举个例子一个10ms 周期调度的任务,在时刻 x 调度了则个任务。
现在是时刻x+3ms, 那么 ST 就是 10 - 3. 因为还有7ms 就下一次调度了。
也就是说当前这个任务 最多只能给运行(理论)7ms的时间了,再多就不行了。
其实要是真的运行满了,也要不行了。
NST - net slack time
还是上面的例子 x 时刻调度的, 现在x+3ms 时刻了,应该还剩7ms 啊。
但是这里需要减去优先级比他高的任务,中断的CET 时间。
假设这个CET之和是2ms. 那么 NST 就是5ms。
JIT - jitter
调度周期的偏差。
话说什么会影响这个呢?
一般来说 调度周期的这个调度的中断优先级应该是二类中断最高的优先级了。
所以影响这个的可能只有一类中断和一些关中断的操作。
或者一些不可抢占的操作。
其实这也是关中断的意思。
看似解释的比较清楚,但是有个大问题出现了。前面我们介绍了ECC task 和 BCC task.
仔细说一下两种任务的区别,优缺点。
03 ECC vs BCC
ECC任务(Extended Critical Chain Task)
ECC任务是AUTOSAR OS中的一种任务调度机制,用于支持那些具有特殊调度需求的任务。ECC任务通常涉及到复杂的调度和处理需求,适用于需要精确控制任务执行顺序和时间的场景。其主要特点包括:
扩展的关键链任务:
ECC任务可以在关键链中运行,这意味着它们可能会影响系统的实时性和调度策略。
高级调度控制:
ECC任务通常具有高级的调度控制需求,可能需要在任务调度中处理复杂的依赖关系或特定的时间约束。
实时性保障:
ECC任务常用于要求高实时性的应用场景,确保系统在关键时刻能够正确处理任务。
BCC任务(Basic Critical Chain Task)
BCC任务是另一种任务调度机制,主要用于处理相对简单的调度需求。BCC任务通常用于系统中那些对调度要求较低的任务。其主要特点包括:
基本的关键链任务:
BCC任务在关键链中运行,但其调度和执行需求相对简单,不需要复杂的调度策略。
简化的调度控制:
BCC任务的调度控制较为基础,适用于那些对调度实时性要求不是特别高的任务。
适用范围广:
BCC任务适用于大多数普通的任务场景,不需要复杂的时间管理和调度策略。
ECC和BCC任务的选择
在实际应用中,选择ECC任务还是BCC任务取决于具体的系统需求和任务调度要求:
ECC任务适用于需要复杂调度和高实时性的任务,例如处理高优先级的控制任务或实时数据处理。
BCC任务适用于调度需求较为简单的任务,例如周期性执行的监控任务或背景数据处理。
任务总结
ECC任务(Extended Critical Chain Task)适用于复杂的调度需求和高实时性要求的场景。
BCC任务(Basic Critical Chain Task)适用于相对简单的调度需求和普通任务的场景。
所以,在实现的过程中 BCC 任务是有terminal的 但是 ECC task 是没有terminal的。所以我们前面说的一些时间参数就需要改变,但是机制本身还在。
比如下面的这样的ECC 任务。使用前面的时间参数来定义的话,执行时间就无限长了。所以我们要定义新的时间信息。
for(;;){ (void)WaitEvent( Rte_Ev_Cyclic2_Main_Task_0_10ms
| Rte_Ev_Cyclic2_Main_Task_0_5ms ); (void)GetEvent(Main_Task,
&ev); (void)ClearEvent(ev & ( Rte_Ev_Cyclic2_Main_Task_0_10ms
| Rte_Ev_Cyclic2_Main_Task_0_5ms )); if ((ev &
Rte_Ev_Cyclic2_Main_Task_0_10ms) != (EventMaskType)0)
{ CanNm_MainFunction(); CanSM_MainFunction(); } if
((ev & Rte_Ev_Cyclic2_Main_Task_0_5ms) != (EventMaskType)0)
{ CanTp_MainFunction(); CanXcp_MainFunction(); }}
下面的这两个WaitEvent 的时间要特殊考虑了。
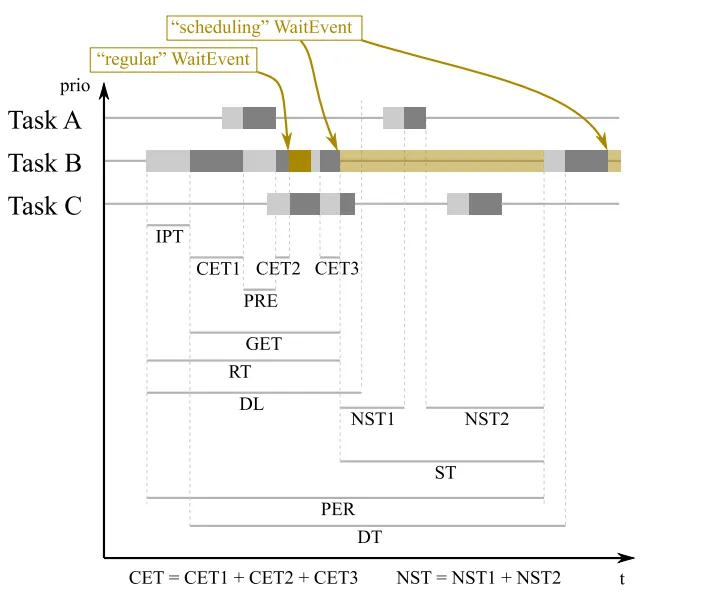
不过呢。如果ECC 也有terminal 也不是不行。不过这样可能就要牺牲实时性了。
TASK(Main_Task_10ms) // ECC{ CanNm_MainFunction();
// the following WaitEvent call is a "regular"
WaitEvent (void)WaitEvent( Can_Ev_TriggerSM_Main_Task
); CanSM_MainFunction(); TerminateTask();}TASK(Main_Task_5ms)
// BCC1{ CanTp_MainFunction(); CanXcp_MainFunction();
TerminateTask();}
02 任务的一生
01 任务激活方式
schedule table vs alarm
alarms
定期事件/任务是使用alarm触发的。alarm 机制由计数器和在达到特定计数器值时要执行的操作(或操作)组成。系统中的每个计数器都可以附加任意数量的警报。当计数器的值等于连接到计数器的警报的值时,称警报已过期。到期后,操作系统将执行与警报关联的操作
警报可以配置为过期一次。过期一次的警报称为单次警报。还可以将警报指定为定期过期。这种类型的警报称为循环警报。到期警报可以执行以下操作之一
激活任务
引发事件
执行回调函数
递增计数器
schedule table
前面alarm 也是传统嵌入式freertos 经常使用的 激活任务的一种方法。不过在autosar
os 里面有了个新的概念,叫做schedule table. 这个会在rte 配置完成之后自动生成,省去了很多具体细节的配置,也减少了出错的可能。不过弊端就是有的工程师可能Os
都正常跑起来了,也不知道自己的任务是到底如何被拉起来的。
schedule table 和前面的alram 机制一样。也是关联到计数器里面的。就是Os counter.
它是由一系列的 “到期点”组成的。当这些点到期了,也即是os counter 到达了这些点。会触发一系列的事件。这个事件可以是任务的激活(一般来说)。当然这些点可以设置为单词或者多次的。
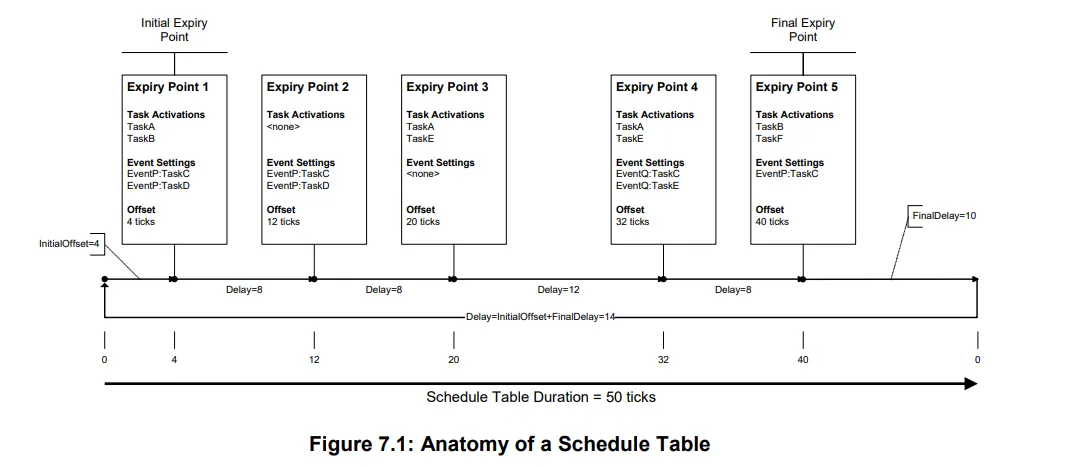
所以有了这些好处,就可以规避掉alarm的一些弊端。如果想触发具有特定时间延迟的任务,使用alarm
就会很复杂。因为为了同步,我们必须使用相同的os-counter. 并且这里也要规避掉一些 终端导致的时间便宜。为了避免这些,我们就可以使用
schedule table.
具体可以从schedule table 的API 看起。这里只是列举一下,不一一介绍,之前有文章进行了说明。
#define OSServiceId_StartScheduleTableAbs ((OSServiceIdType)61)#define
OSServiceId_StartScheduleTableRel ((OSServiceIdType)62)#define
OSServiceId_StartScheduleTableSynchron ((OSServiceIdType)63)#define
OSServiceId_SyncScheduleTable ((OSServiceIdType)64)#define
OSServiceId_SyncScheduleTableRel ((OSServiceIdType)65)#define
OSServiceId_SetScheduleTableAsync ((OSServiceIdType)66)#define
OSServiceId_StopScheduleTable ((OSServiceIdType)67)
02 schedule table 拉起过程
我们细说schedule table 的过程。上面说了任务是被schedule table的到期点触发的。但是schedule
table 又是怎么到期的呢?带着这些疑问,一步一步来。
现有盘古后有天。一切还要从上电说起。
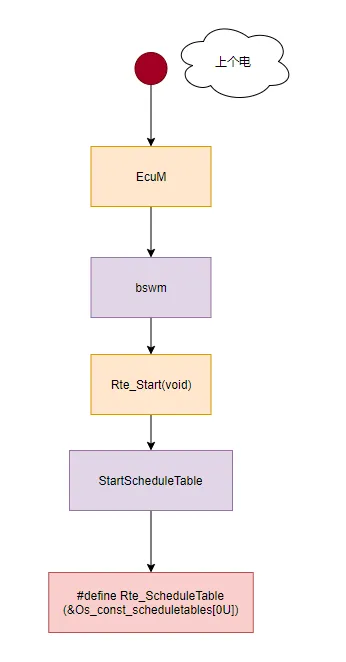
前面我们有说到schedule table 是rte 制作的时候生成的arxml(描述文件)。只不过这个东西是属于os
的,所以在os 生成代码的时候 才用到这个arxml. 这个东西应该是和rte相关的。并且在rte
起来的时候应该就会跟着起来。毕竟里面控制的实际需要运行的东西都掌握在rte的手里。
上电之后,EcuM 对外设,等都进行了初始化。BswM 也对 中间件各个模块进行了初始化,这里面就有一条是rte的start.
这里就会启动这个 schedule table. 也可以用过这个全局变量去看一下自己的schedule
table 在变量里到底是个什么样子的。
#define Rte_ScheduleTable (&Os_const_scheduletables[0U])
好像也没什么,这样schedule table 就起来了。
03 任务拉起过程
还要从最开始的os counter 开始说起。这个os counter 不仅仅是一个counter。那是一个很大的os
结构体,可以理解为os 的驱动器。这个驱动器的运行滚动是依赖于tick. 暂且我们假定这个tick
就是GTM 的 中断服务函数处理的。我们用GTM 做一个 1ms 的中断。每次1ms 都会触发一次中断。这个中断就会驱动os
counter 跑一次。好了有了这个概念,os 终于活起来了。动起来了。每秒os 都会滚动一次。L
所以我们的任务触发最开始应该来源自这个GTM 中断的发生。如下
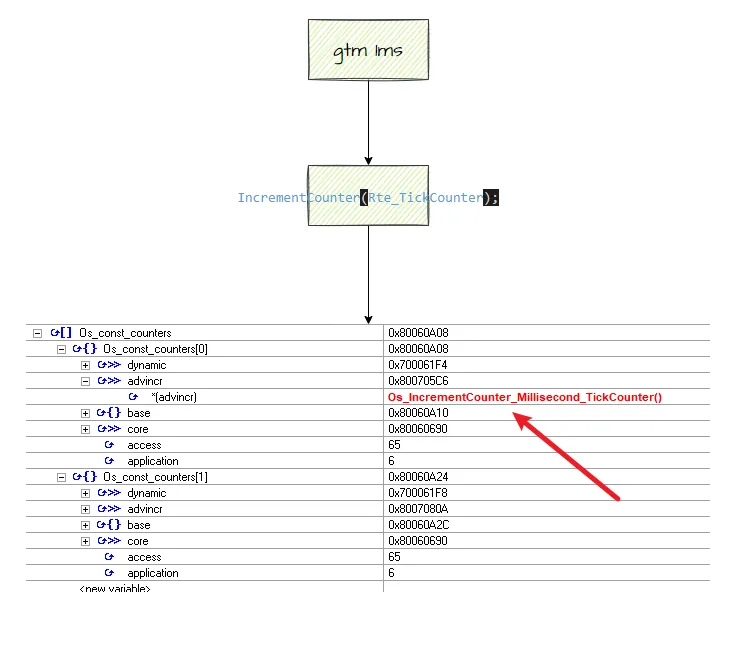
这样我们的os counter 就运行了起来。下面我们就可以从中断说起,说到任务的状态机。
说到任务的时间保护,就有必要把任务的从一开始被调度到最后结束给说清楚。知道每一个阶段是由什么发起的,知道是如何结束的,就自然知道了时间是如何被使用掉的。哪一段时间比较重要。
从中断发生到任务真正的被执行,中间大概经过了以下几个步骤。
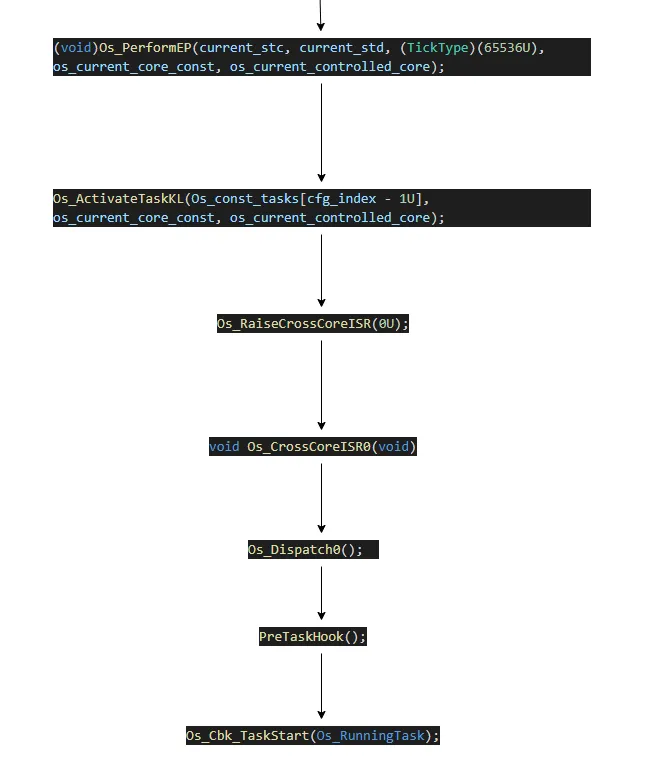
Os counter的驱动会 需要调用schedule table, 看看过期点到了哪里。又有哪些任务被挂载在这个过期点上面。这里会在一个for
中把所有的需要走到ready状态的任务都active .
for(;;) { /*lint !e716 */ cfg_index = (((*current_action
& 62U) >> 1U)); /* [MISRA 2012 Rule 10.6]
*/ /*lint !e9031 !e9034 */ if (cfg_index == 0U) {
break; /* Final */ } while (0U != Os_TestAndSet(&Os_lock_alarmaccess))
{ /* spin */ } current_std->config += 128U; OS_DSYNC();
Os_lock_alarmaccess = 0U; OS_DSYNC(); Os_ActivateTaskKL(Os_const_tasks[cfg_index
- 1U], os_current_core_const, os_current_controlled_core);
if ((*(current_action++) & 1U) != 0U) { break;
/* Final action */ /* [MISRA 2012 Rule 15.4] */ /*lint
!e9011 */ } }
就是我们常知的 active task.
说到调度的任务中断,我们有必要大概区分一下有哪些中断。我们熟知的
一类中断
二类中断
这些是层等级上划分的。其实我们还可以从另外一个角度来划分中断。从用户使用的角度,从OS 调度的角度,从跨核触发的角度。这就是三种。比如
上面说到的GTM 给OS counter 使用的中断,就应该是二类中断优先级最高的中断。
用户不适用,只是给os 使用
普通二类中断,用户使用的中断
cross core isr 配合任务调度的中断
这里就需要使用到CrossCoreISR 中断。
为什么需要CrossCore 中断
1. 多核处理系统的需求
多核处理:
在现代汽车电子系统中,多核处理器越来越常见。
Os_CrossCoreISR0用于在多个处理核心之间协调和管理中断。
它确保在一个核心上触发的中断能够正确地处理和传播到其他核心,保持系统的协调性和一致性。
2. 高效的中断管理
跨核中断管理:
在多核系统中,中断可能会涉及多个核心。
Os_CrossCoreISR0提供了一种机制来管理这些跨核中断,以确保中断处理的高效性和实时性。
这对于保持系统的实时性能和响应能力非常重要。
3. 核心间的通信与同步
协调与同步:
多核系统中的核心可能需要对共享资源或中断事件做出协调响应。
Os_CrossCoreISR0帮助管理核心间的通信和同步,确保所有相关核心能够一致地响应中断并协调处理任务。
4. 实时性能
实时要求:
汽车系统通常需要严格的实时性能,处理时间必须保持在严格的限制内。
Os_CrossCoreISR0帮助优化中断处理流程,以满足这些实时要求,确保系统能够在规定的时间内对中断做出响应。
5. 系统的一致性和安全性
保持一致性:
在复杂的多核系统中,保持系统行为的一致性和稳定性是关键。
Os_CrossCoreISR0通过提供规范化的中断处理机制,帮助确保系统在面对多核中断时能够保持一致的行为。
6. 可扩展性和灵活性
系统扩展:
随着汽车电子系统的复杂性增加,Os_CrossCoreISR0支持系统的扩展性和灵活性,使得操作系统能够适应更多的处理核心和中断需求,满足不同系统架构的要求。
这里我们拿英飞凌多核作为例子。这里有六个中断,分别是每个核心的CrossCoreIsr.
#ifndef _lint /* Lots of integer->pointer initialization
*/SRC_CPU0SB_type * const Os_CrossCoreSRCs[] = {&SRC_GPSR00,
&SRC_GPSR01, &SRC_GPSR02, &SRC_GPSR03,
&SRC_GPSR04, &SRC_GPSR05};const uint32 Os_CrossCoreTriggers[]
= {OS_INIT_SRC_GPSR00, OS_INIT_SRC_GPSR01, OS_INIT_SRC_GPSR02,
OS_INIT_SRC_GPSR03, OS_INIT_SRC_GPSR04, OS_INIT_SRC_GPSR05};#endif
Active task 后 对应的core的 中断会被拉起来。这里面需要判断是否有任务可以被调度。
want_dispatch = (Os_ReadyTasks.p0 > Os_RunningTPMask.t0)
如果说一切正常,需要被调度,则就会到了真正的调度函数。
在调度函数里面 我们才开始真正的任务启动,如下图,
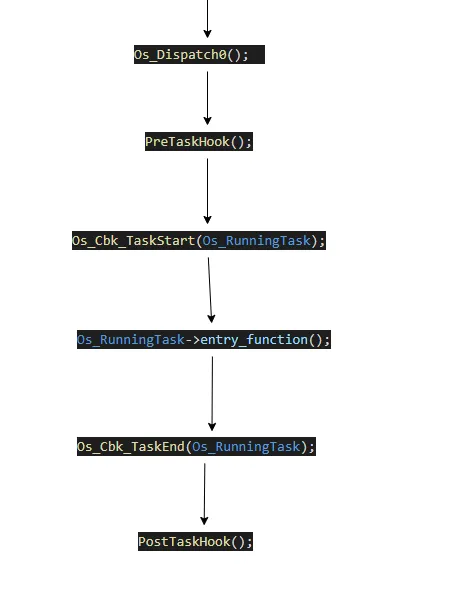
从这里也能看出来BCC 的任务 实际上可以理解为一个 “函数” 在调度函数 dispatch 函数内
从开始到结束,就是 这个任务的 运行过程。
上面的篇幅把任务的经过都说了一边,直至PostTaskHook. 我们可以在任何一处加上自己的代码
counter 计数器,看一下每一段的运行时间。就会有更深刻的理解。
当然这里面都是没考虑抢占,没考虑ECC的情况。不过大同小异,我们可以通过下面的状态机自行分析。
04 任务状态跳转(很细)
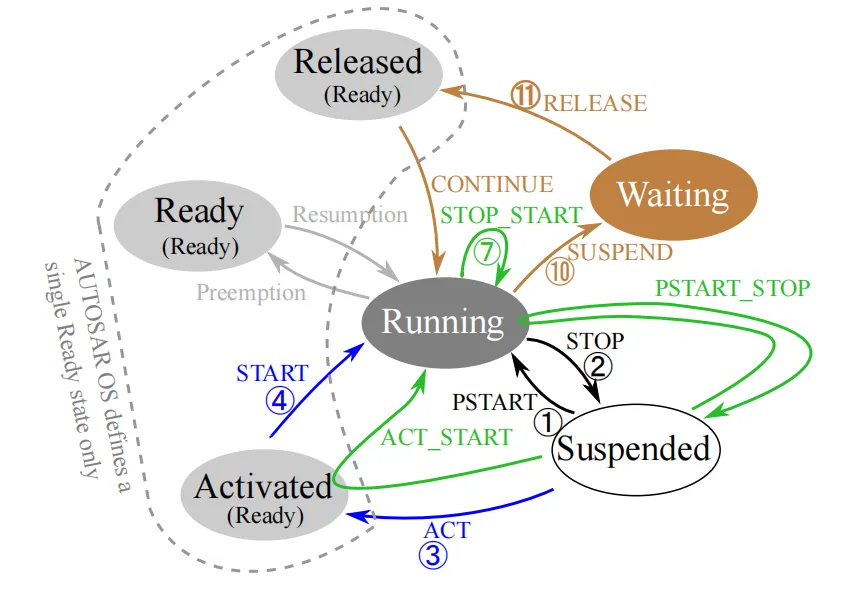
在os的定义任务里面有四种状态
ready
running
waiting
suspended
但是实际上是由不通的路径可以到相同的状态的,我们来很仔细的分析以下。
runnable
runnable 对于任务来说,其实没有很强的相关性。runnable 可以理解为代码,function,
一个小函数功能。只是放在了任务里面,任务运行了,里面的runnable 自然就运行了。不过在上面提到的ECC
任务里面就有对每一个runnable 都由一个event 的条件。比如我们下面的代码
TASK(TaskB){ MyRunnable1(); MyRunnable2(); Schedule();
MyRunnable3(); Schedule(); MyRunnable4(); MyRunnable5();
MyRunnable6(); TerminateTask();}
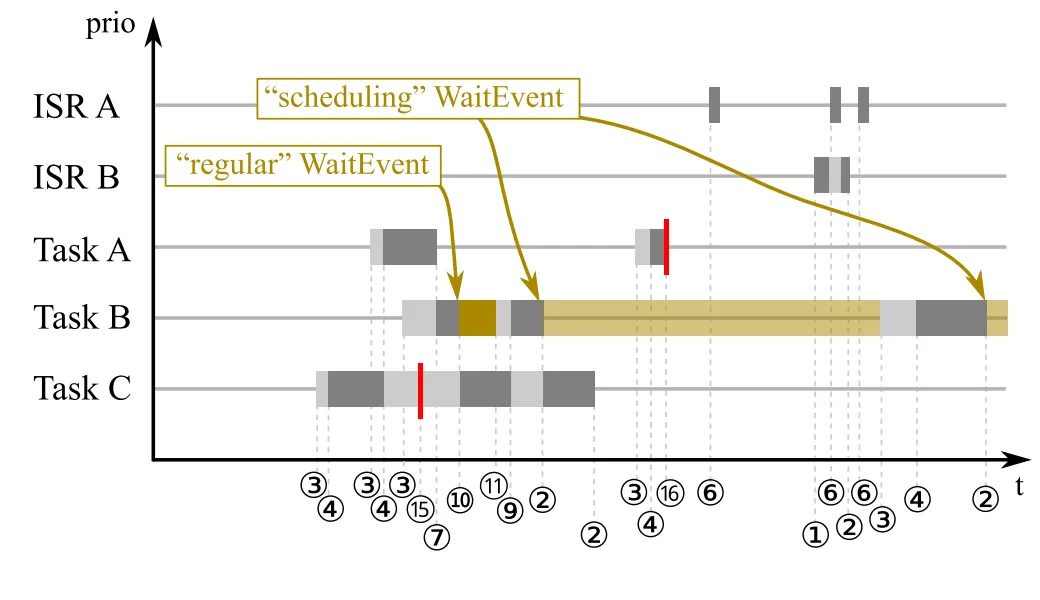
我们的每一个runnable如果都没有自己的event, 那么他的运行时序应该是这样的。
图片
如果每一个runnable的执行都有一个event 检测。则运行的时序是下图这样的。
图片
有那么一点细小的区别。
03 时间测量
在确定了应该记录的事件之后,我们现在必须考虑何时应该记录这些事件。
01 务开始与结束
我们计算CET 的三个原则
CET 他们本身是不依赖于配置的,是不应该依赖于优先级。
CET 可以用作预测最坏的情况下的静态分析
CET 可以用作计算CPU 负载
void F( void ){ ActivateTask( Task_A );}
假设F 是任务 task_B 拉起的。我们则需要完全让Task A 使用CPU 来确定Task_A
的时间。
/* Context 1: task switch to Task_A happens within
F */F( );(void)GetResource( Resource );/* Context
2: no task switch happens within F */F( );/* Task
switch to Task_A happens within ReleaseResource */(void)ReleaseResource(
Resource );
02 链式任务
在AUTOSAR OS中,任务链(Task Chaining)是一种机制,允许一个任务完成后触发另一个任务的执行。这种机制有两种主要的配置方式:一种是使用两个事件(STOP/START),另一种是使用一个事件(STOP_START)。它们之间的区别如下:
1. 使用两个事件(STOP/START)
概念:
STOP事件:
表示当前任务完成的事件。
START事件:
表示触发下一个任务的事件。
优点:
细粒度控制:
提供了更细的任务执行控制。
每个任务可以独立地发出完成信号(STOP事件)和启动下一个任务(START事件)。
灵活性:
能够更灵活地管理任务之间的链式关系。
例如,可以在不同的条件下启动和停止任务,满足复杂的任务执行逻辑。
缺点:
复杂性增加:
管理两个独立的事件会增加配置和任务管理的复杂性。
开销较高:
处理多个事件可能会带来额外的开销,包括配置和运行时处理的开销。
2. 使用一个事件(STOP_START)
概念:
STOP_START事件:
表示一个事件,它同时处理当前任务的停止和下一个任务的启动。
优点:
简化配置:
减少了需要管理的事件数量,从而简化了任务链的配置。
只需一个事件来管理任务的过渡。
减少开销:
处理一个事件比处理多个事件的开销要小,从而降低了配置和运行时的开销。
缺点:
控制粒度较粗:
将停止和启动操作合并为一个事件,可能会减少对任务过渡的细粒度控制。
在需要独立控制任务的停止和启动时,这种方式可能不够灵活。
灵活性有限:
在处理复杂任务链时,可能无法满足更多的条件或同步要求。
选择何时使用哪种方法:
两个事件(STOP/START):
适合更复杂的系统,其中任务之间需要详细的控制和更多的同步操作。
这种方法允许在任务之间进行更精确的管理和协调。
一个事件(STOP_START):
适合较简单的系统,任务链比较直观和简单的情况下使用。
这种方法简化了任务链的配置,并且通常足够满足简单的任务执行需求。
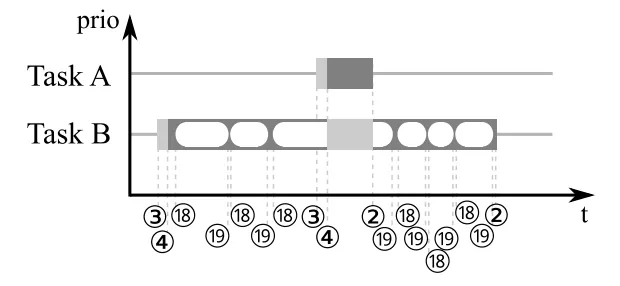
但是也能从上面看出来如果是使用两个事件。中间是可能存在时间差的。则就会出现下面的情况
在A 抢占了B 和 C 之后。A 运行完了。但是B 的event 还没有到。因为stop 和 start
是没在一起的。这时候C 可能会运行一点点时间。
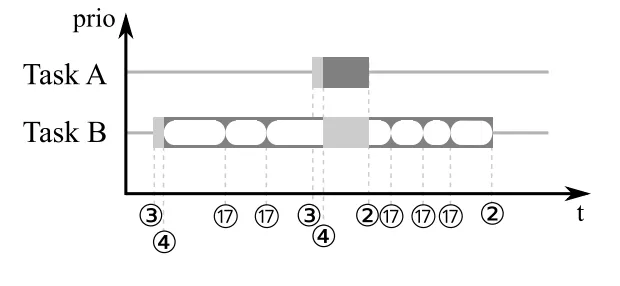
如果是使用一个Event 的方式,则不会出现这种情况。
致敬 GLIWA
Template header for mapping OS related events on trace functions
#ifndef OSTIMHOOKS_H_
#define OSTIMHOOKS_H_ (1)
#define OSTH_ACTIVATE_SPRVSR( schedId_, coreId_ )
#define OSTH_START_SPRVSR( schedId_, coreId_ )
#define OSTH_PSTART_SPRVSR( schedId_, coreId_ )
#define OSTH_STOP_SPRVSR( schedId_, coreId_ )
#define OSTH_START_STOP_SPRVSR( schedId_, coreId_ )
#define OSTH_STOP_START_SPRVSR( startSchedId_, coreId_ )
#define OSTH_STOP_PSTART_SPRVSR( startSchedId_, coreId_ )
#define OSTH_RELEASE_SPRVSR( schedId_, coreId_ )
#define OSTH_RESUME_SPRVSR( schedId_, coreId_ )
#define OSTH_SUSPEND_SPRVSR( schedId_, coreId_ )
#define OSTH_LOCK_START_SPRVSR( lockId_, coreId_ )
#define OSTH_LOCK_STOP_SPRVSR( lockId_, coreId_ )
#define OSTH_UNLOCK_SPRVSR( lockId_, coreId_ )
#define OSTH_ACTIVATE_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_START_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_PSTART_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_STOP_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_START_STOP_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_STOP_START_NOSUSP( startSchedId_, coreId_, classId_ )
#define OSTH_STOP_PSTART_NOSUSP( startSchedId_, coreId_, classId_ )
#define OSTH_RELEASE_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_RESUME_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_SUSPEND_NOSUSP( schedId_, coreId_, classId_ )
#define OSTH_LOCK_START_NOSUSP( lockId_, coreId_, classId_ )
#define OSTH_LOCK_STOP_NOSUSP( lockId_, coreId_, classId_ )
#define OSTH_UNLOCK_NOSUSP( lockId_, coreId_, classId_ )
#define OSTH_ACTIVATE_USER( schedId_, coreId_ )
#define OSTH_START_USER( schedId_, coreId_ )
#define OSTH_PSTART_USER( schedId_, coreId_ )
#define OSTH_STOP_USER( schedId_, coreId_ )
#define OSTH_START_STOP_USER( schedId_, coreId_ )
#define OSTH_STOP_START_USER( startSchedId_, coreId_ )
#define OSTH_STOP_PSTART_USER( startSchedId_, coreId_ )
#define OSTH_RELEASE_USER( schedId_, coreId_ )
#define OSTH_RESUME_USER( schedId_, coreId_ )
#define OSTH_SUSPEND_USER( schedId_, coreId_ )
#define OSTH_LOCK_START_USER( lockId_, coreId_ )
#define OSTH_LOCK_STOP_USER( lockId_, coreId_ )
#define OSTH_UNLOCK_USER( lockId_, coreId_ )
#endif
|
|






 订阅
订阅