| 编辑推荐: |
本文将结合自动驾驶感知中的图像视频处理实例,深入探讨推理模型和训练模型对 GPU
的不同需求。希望对您的学习有所帮助。
本文来自于微信公众号焉知汽车,由火龙果软件Linda编辑、推荐。 |
|
在自动驾驶技术飞速发展的今天,深度学习模型在自动驾驶感知领域扮演着至关重要的角色。而
GPU(图形处理器)作为加速深度学习计算的核心硬件,对于推理模型和训练模型有着截然不同的要求。本文将结合自动驾驶感知中的图像视频处理实例,深入探讨推理模型和训练模型对
GPU 的不同需求。
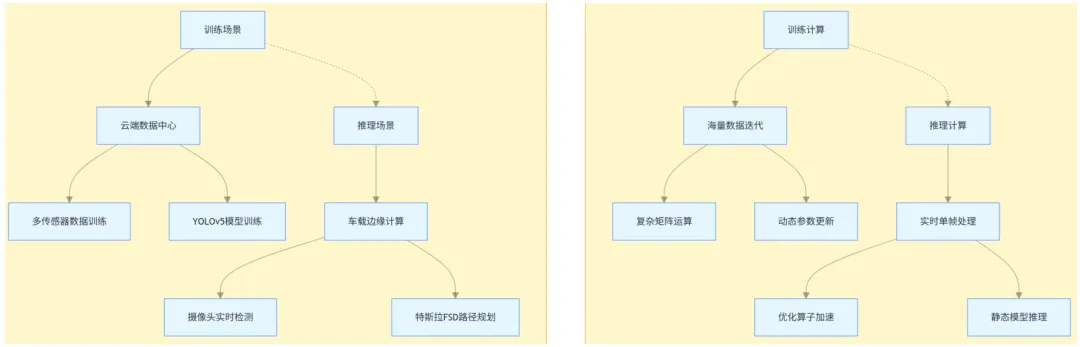
图a 典型场景示例 图b计算特性对比
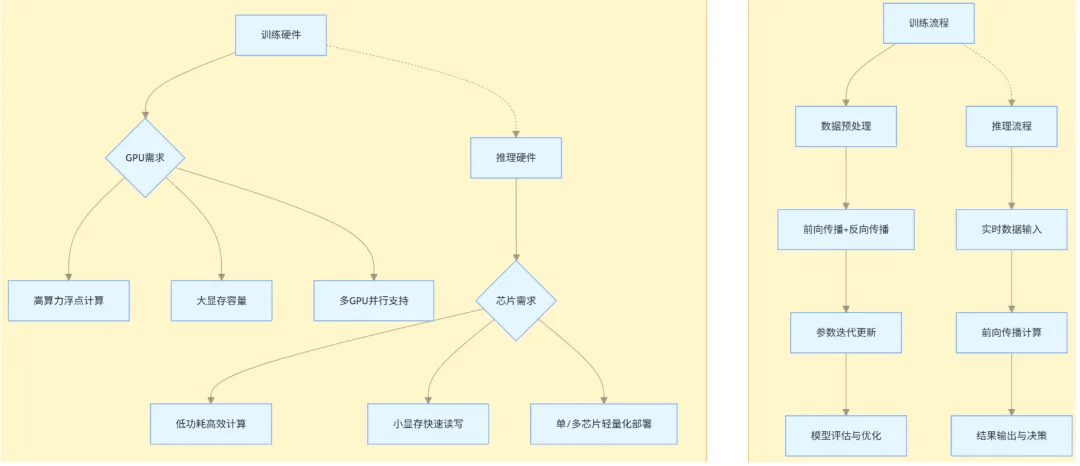
图c 训练和推理的硬件需求差异 图d 核心流程对比
一、训练模型对 GPU 的要求
1、强大的计算能力
在自动驾驶感知中,训练模型通常需要处理海量的数据来学习复杂的模式和特征。以图像目标检测模型训练为例,训练数据集可能包含数百万张标注图像,涵盖各种天气、光照和路况条件下的车辆、行人、交通标志等目标。在训练过程中,模型需要对这些图像进行反复的前向传播和反向传播计算。
假设我们使用 YOLO(You Only Look Once)系列目标检测模型进行自动驾驶场景下的目标检测训练。YOLO
模型结构复杂,包含大量的卷积层、池化层和全连接层。在训练时,每一张输入图像都要经过这些层进行计算,生成预测结果,然后通过计算预测结果与真实标注之间的损失函数(如交叉熵损失),再利用反向传播算法将损失逐层传递回网络,更新网络中的权重参数。这个过程中,一次反向传播就需要进行海量的矩阵乘法和加法运算。例如,在训练
YOLOv5 模型时,对于一张分辨率为 640×640 的 RGB 图像,仅在卷积层中,一次前向传播就可能涉及数亿次的浮点运算。
可能很多小白并不是特别清楚整个计算过程是怎样推导出GPU的计算需求的?本文将详细的进行讲解。
1.1、卷积层计算量分析
YOLOv5 模型包含大量卷积层,卷积操作是其主要计算部分。对于卷积层,其计算量主要来源于卷积核与输入特征图之间的乘法和加法运算。
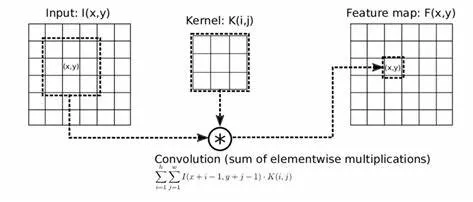
假设一个卷积层有 N 个输出通道,每个输出通道对应的卷积核大小为 K×K×Cin(Cin 为输入通道数,RGB
图像 Cin=3 ),输入特征图大小为 H×W×Cin(这里 H=W=640 ),输出特征图大小为
Hout×Wout×N 。
在不考虑填充和步长影响时,
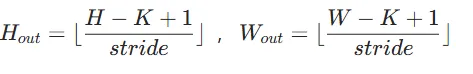
假设步长 stride = 1,则 Hout=H−K+1 ,Wout=W−K+1 。每个输出像素点的计算过程是:卷积核与输入特征图对应区域进行逐元素相乘再相加,一个输出像素点的计算量为
K×K×Cin 次乘法和 K×K×Cin−1 次加法,可近似看作 2×K×K×Cin 次浮点运算(FLOPs)。
那么该卷积层总的计算量 FLOPsconv 为:
FLOPsconv=N×Hout×Wout×2×K×K×Cin
将 H=W=640 ,Cin=3 代入,可得:
FLOPsconv=N×(640−K+1)×(640−K+1)×2×K×K×3
1.2、池化层计算量分析
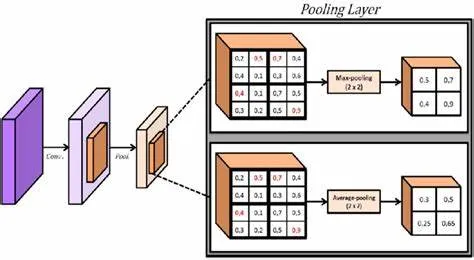
YOLOv5 模型中常用的池化层(如最大池化)计算量相对卷积层较小。以 M×M 大小的池化核为例,假设输入特征图大小为
Hin×Win×Cin ,输出特征图大小为 Hout×Wout×Cin ,在步长等于池化核大小(不重叠池化)时,
Hout=⌊MHin⌋ ,Wout=⌊MWin⌋ 。
每个输出像素点的计算是在池化核对应区域内寻找最大值,一个输出像素点的计算量可近似看作M×M 次比较操作,由于比较操作的计算复杂度远低于浮点运算,在粗略估算算力时可忽略不计。
1.3、全连接层计算量分析
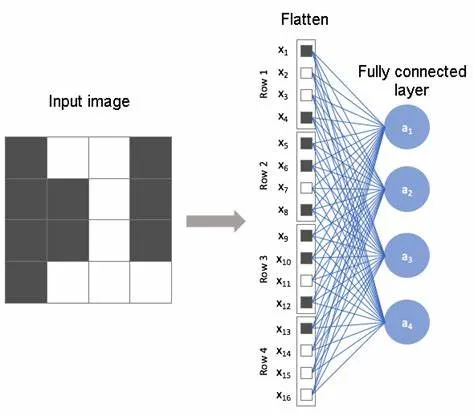
全连接层将前面卷积层和池化层提取的特征进行整合,假设全连接层输入神经元数量为 I ,输出神经元数量为
O 。每个输出神经元的计算是将所有输入神经元与对应权重相乘再相加,一个输出神经元的计算量为 I 次乘法和I−1
次加法,可近似看作 2×I 次浮点运算。那么全连接层总的计算量 FLOPsfc 为:FLOPsfc=O×2×I
1.4、总计算量与 GPU 算力关系
YOLOv5 模型处理一幅 640×640 的 RGB 图像的总计算量 Total_FLOPs 为所有卷积层、全连接层计算量之和(忽略池化层计算量,nconv
为卷积层数量):
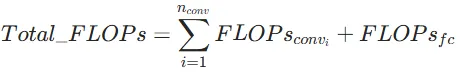
GPU 算力通常以每秒浮点运算次数(FLOPS)为单位,假设模型处理图像的时间为 t 秒,那么处理该图像所需的
GPU 算力 GPU_FLOPS 为:GPU_FLOPS=Total_FLOPs/t 。
例如,若处理一幅图像的时间 t=0.01 秒,通过上述公式计算出 Total_FLOPs=5×10^9
,则所需 GPU 算力为:
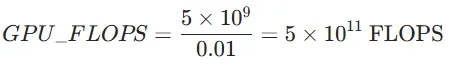
通过以上公式和计算过程,可以较为清晰地估算出 YOLO v5 模型处理一幅 640×640 图像所需的
GPU 算力,在实际应用中,可根据具体模型结构参数代入公式进行准确计算。
随着训练数据量的增加和模型复杂度的提升,所需的计算量呈指数级增长,这就要求 GPU 具备强大的浮点运算能力,例如
NVIDIA A100 GPU,其拥有高达 312 TFLOPS 的 FP32(单精度浮点数)计算性能,能够高效地处理大规模的训练计算任务。
基于如上计算方法,系统架构师在做芯片选型的时候就可以大致估算出需要的GPU算力是多少,当然在实际选型过程中,考虑到复杂场景的算力提升,还基本要预留20-50%左右的算力buffer。如果是设计的芯片架构需要适应未来系统架构升级迭代需求,还需要把算力提升20-30%。
2、大容量显存
训练模型不仅需要强大的计算能力,还需要大容量的显存来存储训练数据、中间计算结果以及模型参数。在自动驾驶的视频处理训练场景中,视频数据是按帧进行处理的,每帧图像的数据量本身就较大,如果同时处理多个视频序列,数据量会迅速累积。
2.1、存储中间计算结果预留空间 buffer
在训练过程中,除了存储原始视频数据,还需要存储模型的中间激活值(如卷积层输出的特征图)、梯度值等信息。随着训练轮次的增加,这些数据会不断占用显存。如果显存容量不足,就会导致数据频繁地在显存和内存之间交换,严重影响训练速度,甚至可能因为内存不足而导致训练中断。
在 640×640 图像的处理过程中,尤其是在 YOLOv5 模型的卷积层和全连接层计算时,会产生大量的中间计算结果。例如,每一层卷积运算后的特征图都需要存储在显存中,以供后续计算使用。假设一个卷积层输出的特征图大小为320×320×64(这里只是示例尺寸),每个像素点用
4 字节(FP32 格式)表示,那么该特征图占用的显存空间为320×320×64×4=26214400字节,约
25MB。
随着网络层数的增加,中间结果占用的显存空间不断累积。为了存储这些中间计算结果,在显存选型时,需要根据模型结构和计算流程,预留比理论计算结果存储需求多
30% - 50% 的空间 buffer。这样可以避免因中间结果过多导致显存溢出,影响计算的连续性。
2.2、应对数据突发预留缓冲 buffer
在自动驾驶场景中,数据的输入并非完全稳定。例如,当车辆快速通过隧道时,光线的剧烈变化可能导致摄像头采集的图像数据出现短暂的异常波动,数据量瞬间增大;或者在多传感器融合的场景下,传感器数据传输可能出现短暂的拥堵,导致短时间内大量数据涌入显存。
为了应对这种数据突发情况,还需额外预留 20% - 30% 的显存 buffer。综合考虑中间计算结果存储和数据突发情况,总体预留的显存
buffer 应在 50% - 80%。例如,如果通过计算得出处理一幅 640×640 图像理论上需要
1GB 显存来存储数据和中间结果,实际选型的显存容量应达到1×(1+0.5)GB到1×(1+0.8)GB,即
1.5GB 到1.8GB。
因此,训练模型通常需要大容量显存的 GPU,如 NVIDIA RTX 3090 拥有 24GB 显存,能够满足大规模视频数据训练的需求。
在实际的芯片和显存选型过程中,除了上述计算因素,还需要考虑成本、功耗、散热等多方面因素。例如,预留过多的
buffer 可能会导致芯片和显存的性能过剩,增加硬件成本和功耗;而预留 buffer 不足,则可能影响系统的稳定性和可靠性。
因此,工程师通常会在实验室环境下,模拟多种自动驾驶场景,对不同 buffer 预留比例进行测试和评估,找到性能、成本和功耗之间的最佳平衡点。同时,随着技术的发展和硬件的迭代,buffer
预留策略也需要不断优化和调整,以适应自动驾驶技术日益增长的需求。
3、多 GPU 并行计算能力
为了进一步加速训练过程,提高训练效率,通常会采用多 GPU 并行计算的方式。在自动驾驶的大规模模型训练中,如基于
Transformer 架构的多模态感知模型训练,单个 GPU 的计算能力和显存容量往往无法满足需求。以基于
Transformer 的多模态融合感知模型训练为例,该模型融合了摄像头图像、激光雷达点云等多种模态数据。在训练时,数据预处理、模型计算等任务量巨大。通过使用多
GPU 并行计算技术,如数据并行和模型并行。数据并行是将训练数据划分成多个子集,每个 GPU 负责处理一个子集的数据,然后在每个训练批次结束后,同步各个
GPU 上的模型参数,模型并行是将模型的不同部分分配到不同的 GPU 上进行计算。
例如,在一个由 8 个 NVIDIA A100 GPU 组成的集群中,采用数据并行策略训练上述多模态感知模型,能够将训练时间大幅缩短,同时也能够处理更大规模的训练数据和更复杂的模型结构。这就要求
GPU 具备良好的多 GPU 通信和协同计算能力,如支持 NVLink 高速互联技术,以实现 GPU
之间高效的数据传输和同步。
二、推理模型对 GPU 的要求
1、高效的实时计算能力
在自动驾驶的实际运行过程中,推理模型需要在极短的时间内对传感器采集到的图像和视频数据进行处理,输出感知结果,以保证车辆能够及时做出决策。例如,当车辆行驶在道路上时,摄像头每秒会采集数十帧图像,推理模型需要在每帧图像采集后的几毫秒内完成目标检测、语义分割等任务,为车辆的路径规划和控制提供准确的信息。
以实时语义分割为例,假设车辆的摄像头以 30fps 的帧率采集图像,推理模型需要在大约 33 毫秒内完成一帧图像的语义分割任务。在这个过程中,模型需要对图像中的每个像素进行分类,判断其属于道路、车辆、行人等哪一个类别。
以 DeepLabv3 + 语义分割模型为例,对于一张分辨率为 512×512 的 RGB 图像,一次推理过程涉及数百万次的计算。为了满足实时性要求,推理模型需要
GPU 具备高效的计算能力,能够快速完成这些计算任务。例如,NVIDIA Jetson AGX Xavier
虽然在计算性能上不如 NVIDIA A100,但它针对边缘计算和实时推理进行了优化,能够在低功耗的情况下实现高效的实时推理,其
INT8(整数 8 位)计算性能可达 21 TOPS,能够满足自动驾驶中许多实时推理任务的需求。
2、低功耗和轻量化
自动驾驶车辆上的硬件资源有限,尤其是电力资源,同时车辆内部空间也需要合理利用。因此,推理模型所使用的
GPU 需要具备低功耗和轻量化的特点,以适应车载环境。
例如,在一些自动驾驶的后装市场产品或小型自动驾驶设备中,会采用 NVIDIA Jetson 系列的嵌入式
GPU。Jetson Nano 功耗仅为 5 - 10 瓦,尺寸小巧,却能够提供足够的计算能力来运行一些基础的自动驾驶感知推理模型,如轻量级的目标检测模型
MobileNet - SSD。该模型通过优化网络结构,减少了参数数量和计算量,配合 Jetson
Nano 这样的低功耗 GPU,能够在满足一定精度要求的前提下,实现实时的目标检测功能,适用于对功耗和空间要求较高的车载场景。
3、优化的内存管理和快速数据读取
推理模型虽然不需要像训练模型那样处理大规模的训练数据,但也需要高效地管理内存和快速读取数据,以保证推理过程的流畅性。在自动驾驶的视频处理推理中,视频数据是连续不断输入的,推理模型需要及时读取新的视频帧数据,同时释放不再使用的内存空间。
以视频目标检测推理为例,当推理模型处理完一帧视频图像后,需要立即读取下一帧图像数据进行处理。如果内存管理不善,可能会出现内存碎片,导致数据读取速度变慢,影响推理的实时性。因此,推理模型所使用的
GPU 需要具备优化的内存管理机制,能够快速分配和释放内存。此外,GPU 与传感器(如摄像头)之间的数据传输速度也至关重要,高速的数据传输接口能够确保视频数据快速、稳定地传输到
GPU 中进行推理计算。
总 结
推理模型和训练模型在自动驾驶感知中对 GPU 的要求存在显著差异。训练模型注重强大的计算能力、大容量显存和多
GPU 并行计算能力,以处理大规模的数据和复杂的模型训练任务;而推理模型则更强调高效的实时计算能力、低功耗轻量化以及优化的内存管理和快速数据读取,以满足自动驾驶实际运行中的实时性和车载环境要求。了解这些差异,有助于在自动驾驶技术的研发和应用中,根据不同的需求选择合适的
GPU,从而提高自动驾驶系统的性能和效率。
| 





 订阅
订阅